Качество распознавания тестов пользовательской модели распознавания речи
Вы можете проверить качество распознавания пользовательской модели речи в Speech Studio. Воспроизведите переданный звук и определите достоверность предоставленного результата распознавания. После успешного создания теста можно увидеть, как модель транскрибирует набор звуковых данных или сравнивает результаты из двух моделей параллельно.
Параллельное тестирование модели полезно для выявления наилучшей модели распознавания речи для приложения. Сведения об объективной мере точности, которой требуются входные данные наборов данных расшифровок, см. в статье Проверка точности модели Пользовательского распознавания речи.
Внимание
При тестировании система выполнит транскрибирование. Это важно помнить, так как цены индивидуальны для каждого предложения услуги и уровня подписки. Всегда обратитесь к официальным ценам на службы ИИ Azure для получения последних сведений.
Создание проверки
Выполните эти инструкции, чтобы создать тест:
Войдите в службу Speech Studio.
Перейдите к пользовательской речи Speech Studio>и выберите имя проекта в списке.
Выберите Тестовые модели>Создать новый тест.
Выберите Проверить качество (только аудиоданные)>Далее.
Выберите набор аудиоданных, который требуется использовать для тестирования, а затем нажмите кнопку Далее. Если наборы данных недоступны, отмените настройку и перейдите в меню Наборы данных службы "Речь”, чтобы отправить наборы данных.
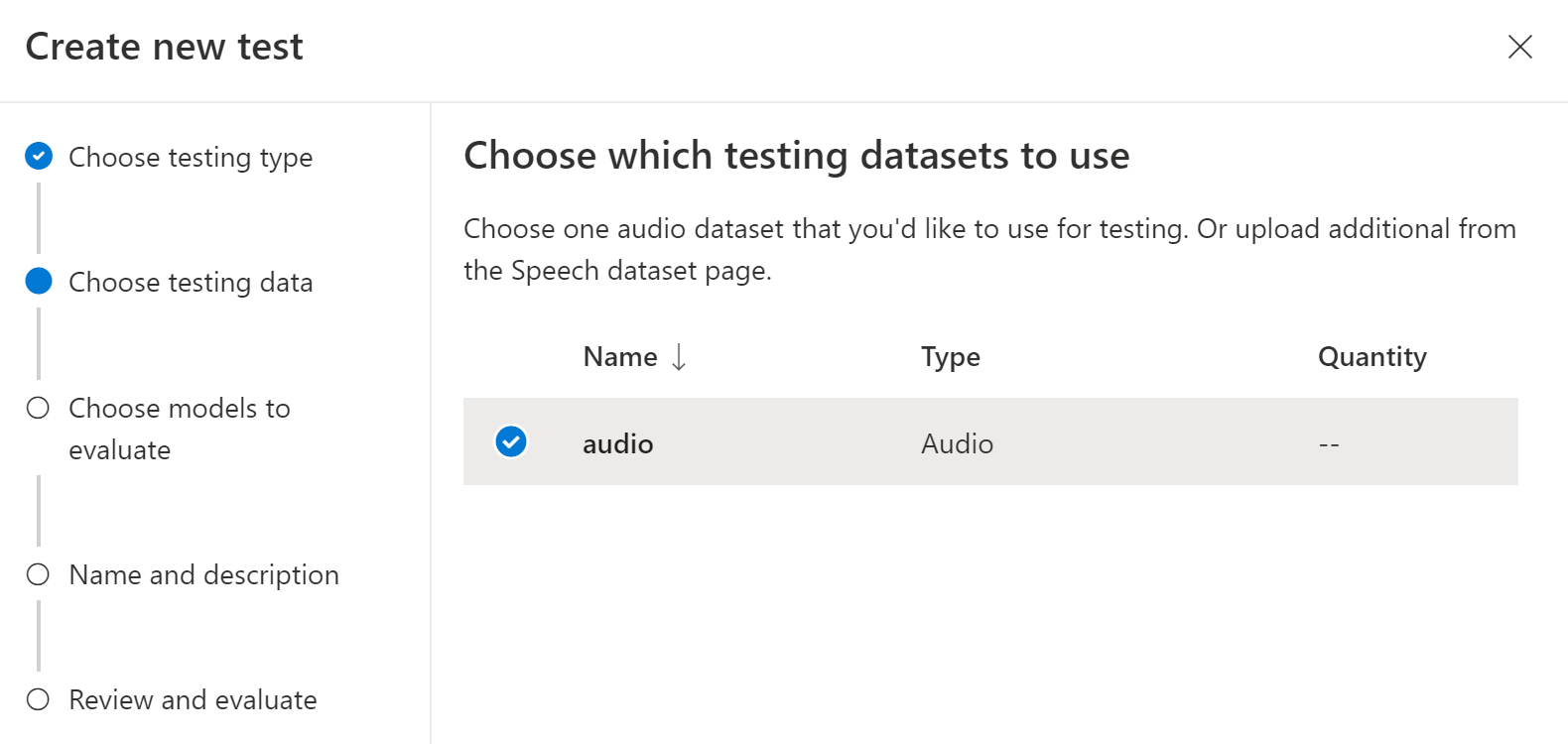
Выберите одну или две модели для оценки и сравнения точности.
Введите имя и описание теста и нажмите кнопку Далее.
Проверьте параметры, а затем выберите Сохранить и закрыть.
Чтобы создать тест, используйте команду spx csr evaluation create. Создайте параметры запроса в соответствии со следующими инструкциями:
- В качестве значения параметра
projectукажите идентификатор существующего проекта. Этот параметр рекомендуется, чтобы вы также могли просматривать тест в Speech Studio. Для получения доступных проектов выполните командуspx csr project list. - Задайте для обязательного параметра
model1значение идентификатора модели, которую нужно протестировать. - Задайте для обязательного параметра
model2значение идентификатора еще одной модели, которую нужно протестировать. Если вы не хотите сравнивать две модели, используйте одну модель дляmodel1иmodel2. - Задайте для обязательного параметра
datasetзначение идентификатора набора данных, который нужно использовать для тестирования. languageЗадайте параметр, в противном случае интерфейс командной строки службы "en-US" по умолчанию. Этот параметр должен быть языковым стандартом содержимого набора данных. Языковой стандарт нельзя будет изменить позже. Параметрlanguageинтерфейса командной строки речевой службы соответствует свойствуlocaleв запросе и ответе JSON.- Задайте обязательный параметр
name. Этот параметр — это имя, отображаемое в Speech Studio. Параметрnameинтерфейса командной строки речевой службы соответствует свойствуdisplayNameв запросе и ответе JSON.
Ниже приведен пример команды CLI службы "Речь", которая создает тест:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Вы должны получить ответ в следующем формате:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Свойство верхнего уровня self в теле ответа представляет собой URI оценки. Используйте этот URI для получения сведений о проекте и результатах теста. Этот URI также используется для обновления или удаления оценки.
Для получения справки по работе с оценками в CLI службы "Речь" выполните следующую команду:
spx help csr evaluation
Чтобы создать тест, используйте операцию Evaluations_Create преобразования речи в текстовый REST API. Создайте текст запроса в соответствии со следующими инструкциями:
- Задайте для свойства
projectзначение URI существующего проекта. Это свойство рекомендуется, чтобы вы также могли просматривать тест в Speech Studio. Вы можете сделать запрос Projects_List для получения доступных проектов. - Задайте для обязательного свойства
model1код URI модели, которую требуется протестировать. - Задайте для обязательного свойства
model2значение URI еще одной модели, которую нужно протестировать. Если вы не хотите сравнивать две модели, используйте одну модель дляmodel1иmodel2. - Задайте для обязательного свойства
datasetзначение URI набора данных, который нужно использовать для тестирования. - Задайте обязательное свойство
locale. Это свойство должно быть языковым стандартом содержимого набора данных. Языковой стандарт нельзя будет изменить позже. - Задайте обязательное свойство
displayName. Это свойство — это имя, отображаемое в Speech Studio.
Выполните HTTP-запрос POST, используя URI, как показано в следующем примере. Замените YourSubscriptionKey ключом ресурса службы "Речь" и YourServiceRegion регионом ресурса службы "Речь", а также задайте свойства текста запроса, как описано выше.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Вы должны получить ответ в следующем формате:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Свойство верхнего уровня self в теле ответа представляет собой URI оценки. Используйте этот URI для получения сведений о проекте оценке и результатах теста. Этот URI также используется для обновления или удаления оценки.
Получение результатов теста
Вы должны получить результаты теста и изучить наборы аудиоданных со сравнением с результатами расшифровки для каждой модели.
Чтобы получить результаты теста, выполните следующие действия:
- Войдите в службу Speech Studio.
- Выберите пользовательские> модели тестирования имени >проекта.
- Выберите ссылку по имени теста.
- После завершения теста с состоянием Успешно вы увидите результаты, включающие номер WER для каждой тестируемой модели.
На этой странице приведены все речевые фрагменты набора данных и показаны результаты распознавания вместе с расшифровкой из предоставленного набора данных. Вы можете переключаться между различными типами ошибок, включая вставку, удаление и замену. Прослушивая звук и сравнивая результаты распознавания в каждом столбце, вы можете решить, какая модель соответствует вашим потребностям и определить, где требуется больше обучения и улучшений.
Чтобы получить результаты теста, используйте команду spx csr evaluation status. Создайте параметры запроса в соответствии со следующими инструкциями:
- Задайте для обязательного параметра
evaluationзначение идентификатора оценки, которая должна получить результаты теста.
Ниже приведен пример команды CLI службы "Речь" для получения результатов теста:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
В тексте ответа возвращаются модели, набор аудиоданных, расшифровки и дополнительные сведения.
Вы должны получить ответ в следующем формате:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Для получения справки по работе с оценками в CLI службы "Речь" выполните следующую команду:
spx help csr evaluation
Чтобы получить результаты теста, начните с Evaluations_Get операции преобразования речи в текстовый REST API.
Выполните HTTP-запрос GET с URI, как показано в следующем примере. Замените YourEvaluationId на ИД оценки, YourSubscriptionKey — на ключ ресурса службы "Речь", а YourServiceRegion — на регион ресурса службы "Речь".
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
В тексте ответа возвращаются модели, набор аудиоданных, расшифровки и дополнительные сведения.
Вы должны получить ответ в следующем формате:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Сравнение расшифровки с аудио
Вы можете изучить выходные данные транскрибирования по каждой протестированной модели на соответствие набору входных аудиоданных. Если вы включили в тест две модели, вы можете сравнить их качество транскрибирования.
Чтобы проверить качество транскрибирования, сделайте следующее:
- Войдите в службу Speech Studio.
- Выберите пользовательские> модели тестирования имени >проекта.
- Выберите ссылку по имени теста.
- Воспроизведите аудиофайл при чтении соответствующей расшифровки моделью.
Если тестовый набор данных включал несколько звуковых файлов, в таблице отображается несколько строк. Если в тест включены две модели, расшифровки отображаются в параллельных столбцах. Различия в расшифровках между моделями отображаются шрифтом синего цвета.
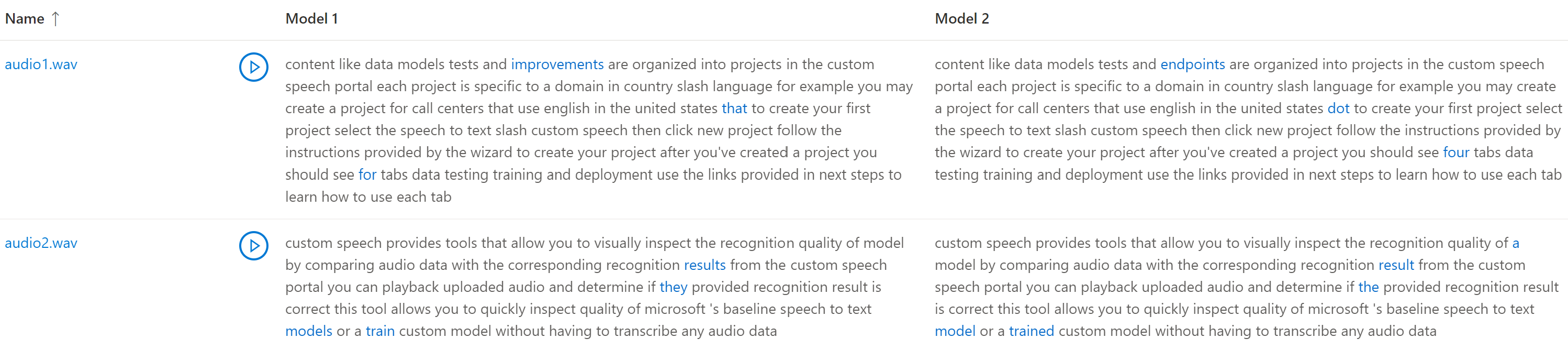
Тестовый набор аудиоданных, расшифровки и тестируемые модели возвращаются в результатах теста. Если была проверена только одна модель, model1 значение совпадает model2со значением и совпадает со transcription2значениемtranscription1.
Чтобы проверить качество транскрибирования, сделайте следующее:
- Скачайте тестовый набор аудиоданных (если у вас еще нет копии).
- Скачайте выходные расшифровки.
- Воспроизведите аудиофайл при чтении соответствующей расшифровки моделью.
Если вы сравниваете качество двух моделей, обратите особое внимание на различия в расшифровках каждой модели.
Тестовый набор аудиоданных, расшифровки и тестируемые модели возвращаются в результатах теста. Если была проверена только одна модель, model1 значение совпадает model2со значением и совпадает со transcription2значениемtranscription1.
Чтобы проверить качество транскрибирования, сделайте следующее:
- Скачайте тестовый набор аудиоданных (если у вас еще нет копии).
- Скачайте выходные расшифровки.
- Воспроизведите аудиофайл при чтении соответствующей расшифровки моделью.
Если вы сравниваете качество двух моделей, обратите особое внимание на различия в расшифровках каждой модели.
Следующие шаги
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по