Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье вы узнаете, как настроить профессиональный голос с помощью портала Azure AI Foundry.
Внимание
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. После обучения модели голосовой связи в поддерживаемом регионе вы можете скопировать профессиональную голосовую модель в ресурс Azure AI Foundry в другом регионе по мере необходимости. Дополнительные сведения см. в сносках в таблице службы "Речь".
Длительность обучения зависит от того, сколько данных вы используете. В среднем для настройки профессионального голоса требуется около 40 часов вычислений. С помощью ресурса Azure AI Foundry standard (S0) можно одновременно обучать четыре голоса. Если этот предел достигнут, подождите, пока хотя бы одна из моделей завершит обучение, а затем повторите попытку.
Примечание.
Хотя общее количество часов, необходимых для каждого метода обучения, зависит от одной и той же цены на единицу. Дополнительные сведения см. в разделе о ценах на настраиваемую нейронную подготовку.
Выбор метода обучения
После проверки файлов данных используйте их для создания пользовательской голосовой модели. При создании пользовательского голоса вы можете обучить его одним из следующих методов:
Нейронный: создайте голос на том же языке данных обучения.
Нейронный — кросслингвальный: создайте голос, который говорит на другом языке, отличном от обучающих данных. Например, с
zh-CNпомощью обучающих данных можно создать голос, который говоритen-US.Язык обучающих данных и целевого языка должен быть одним из языков, которые поддерживаются для перекрестного обучения голосовой связи. Вам не нужно подготавливать обучающие данные на целевом языке, но тестовый скрипт должен находиться на целевом языке.
Нейронная — много стилей: создайте пользовательский голос, который говорит в разных стилях и с различными эмоциями, не добавляя новые обучающие данные. Несколько стилей голоса полезны для игровых персонажей, беседных чат-ботов, аудиокниг, средств чтения содержимого и многое другое.
Чтобы создать несколько стилей голоса, необходимо подготовить набор общих обучающих данных, по крайней мере 300 речевых фрагментов. Выберите один или несколько предустановленных стилей речи целевого объекта. Вы также можете создать несколько пользовательских стилей, предоставив примеры стилей, по крайней мере 100 речевых фрагментов на стиль, в качестве дополнительных обучающих данных для одного голоса. Поддерживаемые стили предустановок зависят от разных языков. Просмотрите доступные стили предустановок на разных языках.
Нейронная — многоязычная (предварительная версия): создайте голос, который говорит на нескольких языках, используя данные обучающих материалов на одном языке. Например, используя основные тренировочные данные
en-US, можно создать голос, который говорит на вторичных языках, таких какen-US,de-DE,zh-CNи т. д.Основной язык обучающих данных и вторичных языков должен находиться на языках, поддерживаемых для обучения многоязычной голосовой связи. Вам не нужно подготавливать обучающие данные на дополнительных языках.
Язык обучающих данных должен быть одним из языков, поддерживаемых для пользовательского голосового, кросслингвального или нескольких стилей обучения.
Натренируйте пользовательскую голосовую модель
Чтобы создать пользовательский голос на портале Azure AI Foundry, выполните следующие действия для одного из следующих методов:
- Невральный
- Нейронная — перекрестный лингвальный
- Нейронная — многоуровневая
- Нейронная — многоязычная (предварительная версия)
- Нейронная — голосовая связь HD (предварительная версия)
Войдите на портал Azure AI Foundry.
Выберите Тонкая настройка в левой области и выберите Тонкая настройка службы ИИ.
Выберите задачу профессиональной настройки голосовой связи (по имени модели), которую вы начали, как описано в статье о создании профессиональной голосовой связи.
Выберите Тренировать модель>+ Тренировать модель.
Выберите Neural в качестве метода обучения для модели. Чтобы использовать другой метод обучения, ознакомьтесь с Нейронная — кросслингвальная, Нейронная — мультстиль , Нейронная — многоязычная (предварительная версия) или Нейронная — HD речь (предварительная версия).
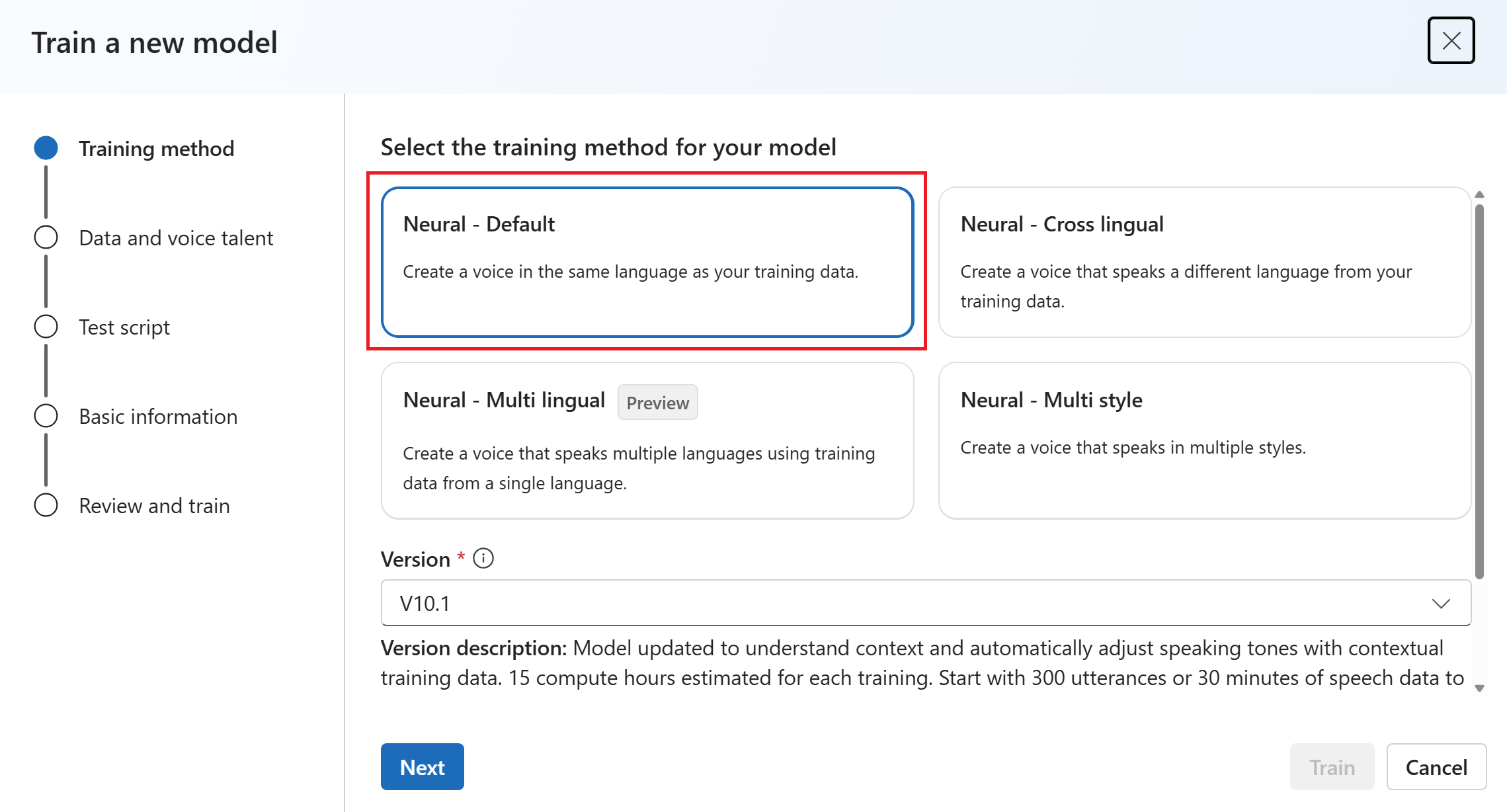
Выберите версию рецепта обучения для модели. По умолчанию выбрана последняя версия. Поддерживаемые функции и время обучения могут отличаться по версии. Как правило, мы рекомендуем последнюю версию. В некоторых случаях можно выбрать более раннюю версию, чтобы сократить время обучения. Дополнительные сведения о двуязычной подготовке и различиях между языковыми стандартами см . в двуязычной подготовке .
Выберите Далее.
Выберите данные, которые вы хотите использовать для обучения. Дубликаты аудиофайлов не будут использоваться в обучении. Убедитесь, что данные, которые вы выбрали, не содержат одинаковых звуковых имен в нескольких .zip файлах.
Вы можете выбрать только успешно обработанные наборы данных для обучения. Если в списке не отображается набор обучения, проверьте состояние обработки данных.
Выберите файл говорящего с оператором голосового таланта, соответствующий динамику в обучающих данных.
Выберите Далее.
Выберите тестовый скрипт и нажмите кнопку "Далее".
- Каждое обучение создает 100 примеров звуковых файлов автоматически, чтобы протестировать модель с помощью скрипта по умолчанию.
- Кроме того, можно выбрать " Добавить собственный скрипт теста " и предоставить собственный скрипт тестирования до 100 речевых фрагментов, чтобы протестировать модель без дополнительных затрат. Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования. Дополнительные сведения см. в статье о требованиях к скрипту тестирования.
Введите имя модели голосовой связи. Тщательно выбирайте имя. Имя модели используется в качестве голосового имени в запросе синтеза речи в пакете SDK и входных данных SSML. Разрешены только буквы, цифры и несколько знаков препинания. Используйте разные имена для разных нейронных голосовых моделей.
При необходимости введите описание , чтобы определить модель. Обычное использование описания заключается в записи имен данных, используемых для создания модели.
Установите флажок, чтобы принять условия использования, а затем нажмите кнопку "Далее".
Просмотрите параметры и выберите поле для принятия условий использования.
Выберите "Обучение ", чтобы начать обучение модели.

Двуязычное обучение
Если выбрать тип обучения нейронных данных , вы можете обучить голос для выступления на нескольких языках. , zh-CNzh-HKи языковые стандарта поддерживают двуязычное обучение для голоса, чтобы говорить как на китайском, так и zh-TW на английском языках. В зависимости от ваших обучающих данных синтезированный голос может говорить на английском языке с английским собственным акцентом или английским с тем же акцентом, что и данные обучения.
Примечание.
Чтобы в локали zh-CN голос мог говорить по-английски с тем же акцентом, что и образец данных, необходимо загрузить английские данные в набор обучения контекстный, или выбрать Chinese (Mandarin, Simplified), English bilingual при создании проекта, или указать локаль zh-CN (English bilingual) для данных набора обучения через REST API.
В вашем контекстном наборе обучения включите по крайней мере 100 предложений или 10 минут английского содержимого и не превышайте объем китайского содержимого.
В следующей таблице показаны различия между языковыми стандартами:
| Языковой стандарт Speech Studio | Языковой стандарт REST API | Двуязычная поддержка |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Если образец данных содержит английский, синтезированный голос говорит на английском языке с английским собственным акцентом вместо того же акцента, что и выборка данных, независимо от объема данных английского языка. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Если вы хотите, чтобы синтезированный голос говорил на английском языке с тем же акцентом, что и выборка данных, рекомендуется включить более 10 % данных английского языка в обучающий набор. В противном случае акцент на английском языке может быть не идеальным. |
Chinese (Cantonese, Simplified) |
zh-HK |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10 % английских данных в учебном наборе. В противном случае он по умолчанию используется для английского собственного акцента. Пороговое значение 10 % вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые отправленные данные английского языка отклоняются из-за дефектов и не соответствуют пороговой значению 10 %, синтезированный голос по умолчанию используется для английского собственного акцента. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10 % английских данных в учебном наборе. В противном случае он по умолчанию используется для английского собственного акцента. Пороговое значение 10 % вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые отправленные данные английского языка отклоняются из-за дефектов и не соответствуют пороговой значению 10 %, синтезированный голос по умолчанию используется для английского собственного акцента. |



Мониторинг процесса обучения
В таблице обучения модели появится новая запись, соответствующая вновь созданной модели. Состояние отражает процесс преобразования данных в голосовую модель, как описано в этой таблице:
| Состояние | Значение |
|---|---|
| Обработка | Идет создание голосовой модели. |
| Выполнено | Голосовая модель создана и может быть развернута. |
| Неудачно | При обучении голосовой модели произошел сбой. Причиной сбоя могут быть, например, незамеченные проблемы с данными или неполадки в сети. |
| Отменено | Обучение модели голосовой связи отменено. |
Пока состояние модели — обработка, можно выбрать модель, а затем выбрать команду "Отмена обучения ", чтобы отменить обучение. Плата за отмененное обучение не взимается.

После успешного обучения модели можно просмотреть сведения о модели и протестировать голосовую модель.
Переименование модели
Чтобы переименовать модель, необходимо клонировать ее. Невозможно переименовать модель напрямую.
- Выберите модель.
- Выберите модель клонирования , чтобы создать клон модели с новым именем в текущем проекте.
- Введите новое имя в окне «Клонированная модель голоса».
- Нажмите кнопку "Отправить". Текстовый нейрон автоматически добавляется в качестве суффикса в имя новой модели.
Тестирование голосовой модели
После успешной сборки модели голосовой связи можно использовать созданные примеры звуковых файлов для его тестирования перед развертыванием.
Примечание.
Нейронная — многоязычная (предварительная версия) и нейронная — голосовая связь HD (предварительная версия) не поддерживают этот тип тестирования.
Качество голоса зависит от многих факторов, таких как:
- Размер набора обучающих данных.
- Качество записи.
- Правильность транскрипции.
- Насколько хорошо записанный голос в обучающих данных соответствует индивидуальному шаблону для вашего предполагаемого варианта использования.
Выберите DefaultTests в разделе "Тестирование", чтобы прослушивать образец звуковых файлов. Примеры тестов по умолчанию включают 100 примеров звуковых файлов, созданных автоматически во время обучения, чтобы помочь вам протестировать модель. Помимо этих 100 звуковых файлов, предоставляемых по умолчанию, собственные речевые фрагменты скрипта тестирования также добавляются в набор DefaultTests . Это дополнение составляет не более 100 речевых фрагментов. Плата за тестирование с помощью DefaultTests не взимается.
Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования модели, выберите Add test scripts (Добавить тестовые скрипты).
Перед отправкой тестового скрипта проверьте требования к скрипту тестирования. Плата за дополнительное тестирование с помощью пакетного синтеза взимается на основе количества оплачиваемых символов. См . цены на распознавание речи ВИ Azure.
В разделе "Добавить тестовые скрипты" выберите "Обзор файла ", чтобы выбрать собственный скрипт, а затем нажмите кнопку "Добавить ", чтобы отправить его.
Требования к скрипту тестирования
Тестовый скрипт должен быть файлом .txt размером менее 1 МБ. В число поддерживаемых форматов кодирования входят: ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE и UTF-16-BE.
В отличие от файлов обучающего транскрибирования, скрипт теста должен исключить идентификатор высказываний, который является именем файла каждого высказывания. В противном случае эти идентификаторы будут озвучены.
Ниже приведен пример набора речевых фрагментов в одном файле .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Для каждого абзаца речевого фрагмента создается отдельный звуковой файл. Если вы хотите объединить все предложения в один файл, объедините их в один абзац.
Примечание.
Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования.
Обновление версии подсистемы для голосовой модели
Текст Azure для подсистем речи обновляется от времени, чтобы записать последнюю языковую модель, которая определяет произношение языка. После обучения голоса вы можете применить голос к новой языковой модели, обновив до последней версии двигателя.
- Когда будет доступна новая подсистема, вам будет предложено обновить модель нейронного голоса.
- Перейдите на страницу сведений о модели и следуйте инструкциям на экране, чтобы установить последнюю версию подсистемы.
- Кроме того, выберите " Установить последнюю версию подсистемы ", чтобы обновить модель до последней версии ядра. Плата за обновление подсистемы не взимается. Предыдущие версии сохраняются.
- Вы можете проверить все версии подсистемы для модели из списка версий подсистемы или удалить ее, если она больше не нужна.
Обновленная версия автоматически устанавливается по умолчанию. Но вы можете изменить версию по умолчанию, выбрав версию из раскрывающегося списка и выбрав "Задать в качестве значения по умолчанию".
Если вы хотите протестировать каждую версию подсистемы голосовой модели, можно выбрать версию из списка, а затем выберите DefaultTests в разделе "Тестирование ", чтобы прослушивать образец звуковых файлов. Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования текущей версии подсистемы, сначала убедитесь, что версия задана по умолчанию, а затем выполните действия, описанные в разделе "Тестирование голосовой модели".
Обновление подсистемы создает новую версию модели без дополнительных затрат. После обновления версии подсистемы для голосовой модели необходимо развернуть новую версию, чтобы создать новую конечную точку. Вы можете развернуть только версию по умолчанию.
После создания новой конечной точки необходимо передать трафик в новую конечную точку в продукте.
Дополнительные сведения о возможностях и ограничениях этой функции и рекомендациях по улучшению качества модели см. в разделе "Характеристики и ограничения" для использования пользовательского голоса.
Копирование голосовой модели в другой проект
Примечание.
В этом контексте "проект" относится к задаче тонкой настройки, а не к проекту Azure AI Foundry.
После обучения вы можете скопировать голосовую модель в другой проект для одного региона или другого региона.
Например, можно скопировать профессиональную модель голоса, которая была обучена в одном регионе, для использования в проекте для другого региона. Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах.
Чтобы скопировать пользовательскую голосовую модель в другой проект:
- На вкладке Обучение модели выберите голосовую модель, которую необходимо скопировать, а затем выберите Копировать в проект.
- Выберите подписку, целевой регион, ресурс подключенной службы ИИ (ресурс ИИ Foundry) и целевую задачу точной настройки, в которую вы хотите скопировать модель.
- Выберите Копировать в, чтобы скопировать модель.
- Выберите модель представления в сообщении уведомления об успешном копировании.
Перейдите к проекту, в котором вы скопировали модель для развертывания копии модели.
Следующие шаги
Из этой статьи вы узнаете, как настроить профессиональный голос на портале Speech Studio.
Внимание
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. После обучения голосовой модели в поддерживаемом регионе его можно скопировать в ресурс AI Foundry для распознавания речи в другом регионе по мере необходимости. Дополнительные сведения см. в сносках в таблице службы "Речь".
Длительность обучения зависит от того, сколько данных вы используете. В среднем для настройки профессионального голоса требуется около 40 часов вычислений. Пользователи со стандартной подпиской (S0) могут одновременно обучать четыре голоса. Если этот предел достигнут, подождите, пока хотя бы одна из моделей завершит обучение, а затем повторите попытку.
Примечание.
Хотя общее количество часов, необходимых для каждого метода обучения, зависит от одной и той же цены на единицу. Дополнительные сведения см. в разделе о ценах на настраиваемую нейронную подготовку.
Выбор метода обучения
После проверки файлов данных используйте их для создания пользовательской голосовой модели. При создании пользовательского голоса вы можете обучить его одним из следующих методов:
Нейронный: создайте голос на том же языке данных обучения.
Нейронный — кросслингвальный: создайте голос, который говорит на другом языке, отличном от обучающих данных. Например, с
zh-CNпомощью обучающих данных можно создать голос, который говоритen-US.Язык обучающих данных и целевого языка должен быть одним из языков, которые поддерживаются для перекрестного обучения голосовой связи. Вам не нужно подготавливать обучающие данные на целевом языке, но тестовый скрипт должен находиться на целевом языке.
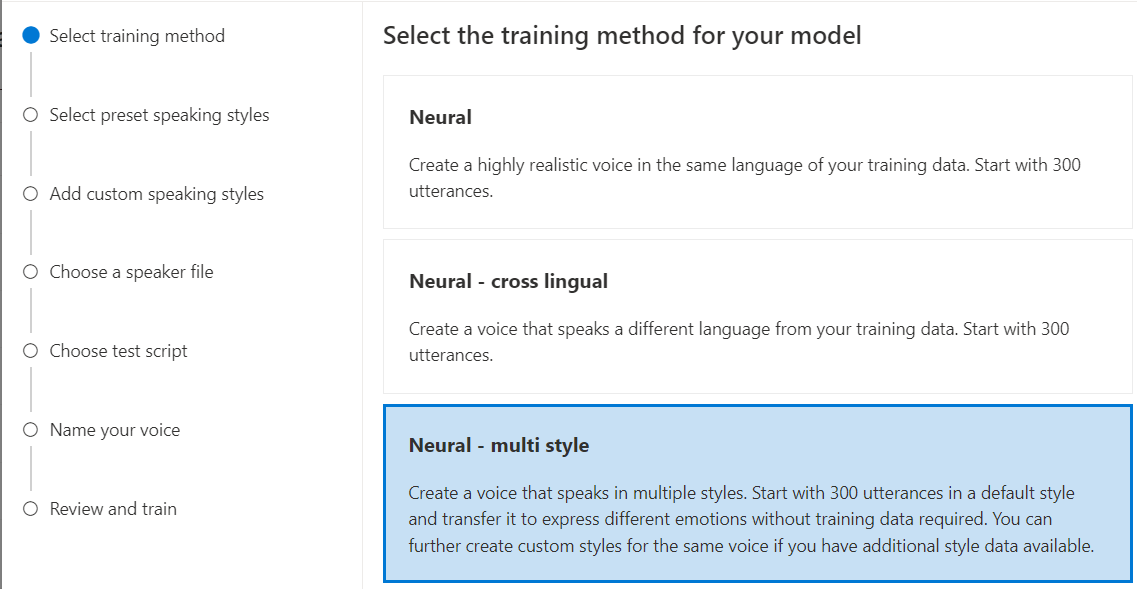
Нейронная — много стилей: создайте пользовательский голос, который говорит в разных стилях и с различными эмоциями, не добавляя новые обучающие данные. Несколько стилей голоса полезны для игровых персонажей, беседных чат-ботов, аудиокниг, средств чтения содержимого и многое другое.
Чтобы создать несколько стилей голоса, необходимо подготовить набор общих обучающих данных, по крайней мере 300 речевых фрагментов. Выберите один или несколько предустановленных стилей речи целевого объекта. Вы также можете создать несколько пользовательских стилей, предоставив примеры стилей, по крайней мере 100 речевых фрагментов на стиль, в качестве дополнительных обучающих данных для одного голоса. Поддерживаемые стили предустановок зависят от разных языков. Просмотрите доступные стили предустановок на разных языках.
Нейронная — многоязычная (предварительная версия): создайте голос, который говорит на нескольких языках, используя данные обучающих материалов на одном языке. Например, используя основные тренировочные данные
en-US, можно создать голос, который говорит на вторичных языках, таких какen-US,de-DE,zh-CNи т. д.Основной язык обучающих данных и вторичных языков должен находиться на языках, поддерживаемых для обучения многоязычной голосовой связи. Вам не нужно подготавливать обучающие данные на дополнительных языках.
Нейронная — голосовая связь HD (предварительная версия): создайте голос HD на том же языке обучающих данных. Нейронные HD-голоса Azure основаны на языковых моделях (Large Language Models, LLM) и оптимизированы для ведения динамичных разговоров. Дополнительные сведения об нейронных голосах HD см. здесь.
Язык обучающих данных должен быть одним из языков, поддерживаемых для пользовательского голосового, кросслингвального или нескольких стилей обучения.
Натренируйте пользовательскую голосовую модель
Чтобы создать пользовательский голос в Speech Studio, выполните следующие действия для одного из следующих методов:
- Невральный
- Нейронная — перекрестный лингвальный
- Нейронная — многоуровневая
- Нейронная — многоязычная (предварительная версия)
- Нейронная — голосовая связь HD (предварительная версия)
Войдите в службу Speech Studio.
Выберите >
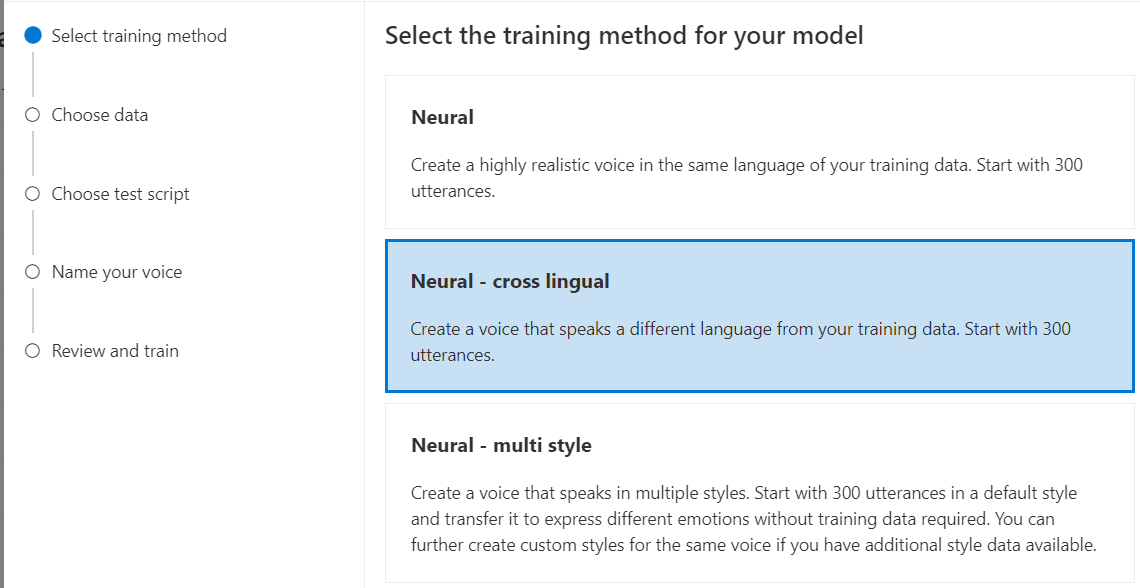
Выберите "Нейрон" в качестве метода обучения для модели и нажмите кнопку "Далее". Сведения об использовании другого метода обучения см. в разделе "Нейронная - межъязыковая" или "Нейронная - многостилевая" или "Нейронная - многоязыковая (предварительная версия)" или "Нейронная - голос HD (предварительная версия)".
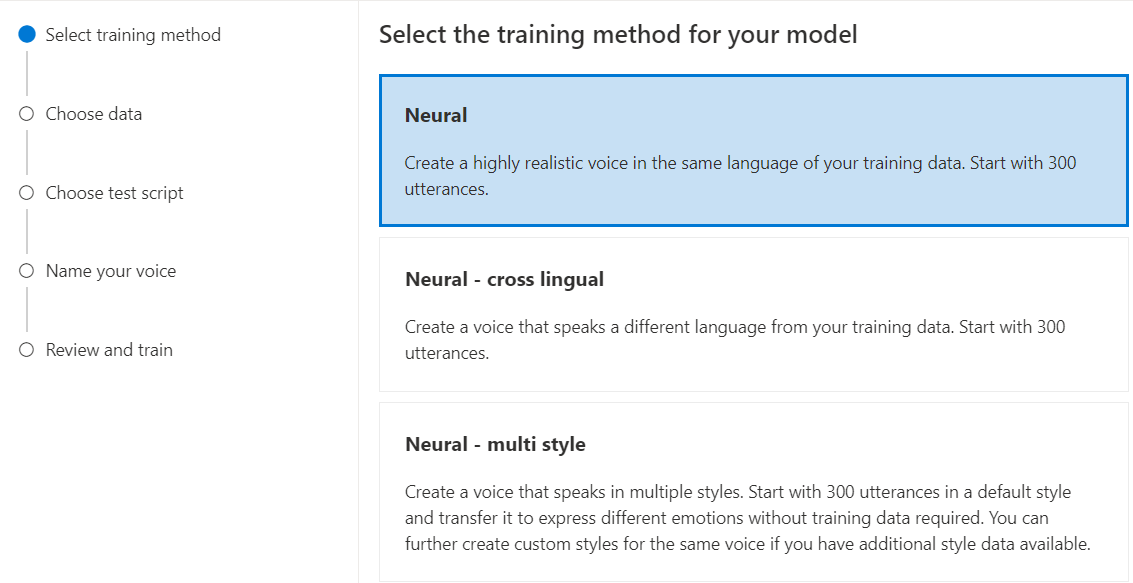
Выберите версию рецепта обучения для модели. По умолчанию выбрана последняя версия. Поддерживаемые функции и время обучения могут отличаться по версии. Как правило, мы рекомендуем последнюю версию. В некоторых случаях можно выбрать более раннюю версию, чтобы сократить время обучения. Дополнительные сведения о двуязычной подготовке и различиях между языковыми стандартами см . в двуязычной подготовке .
Примечание.
Версии моделей
V3.0,V7.0иV8.0будут прекращены к 25 июля 2025 г. Модели голосовой связи, уже созданные в этих устаревших версиях, не будут затронуты.Выберите данные, которые вы хотите использовать для обучения. Дубликаты аудиофайлов не будут использоваться в обучении. Убедитесь, что данные, которые вы выбрали, не содержат одинаковых звуковых имен в нескольких .zip файлах.
Вы можете выбрать только успешно обработанные наборы данных для обучения. Если в списке не отображается набор обучения, проверьте состояние обработки данных.
Выберите файл говорящего с оператором голосового таланта, соответствующий динамику в обучающих данных.
Выберите Далее.
Каждое обучение создает 100 примеров звуковых файлов автоматически, чтобы протестировать модель с помощью скрипта по умолчанию.
При необходимости можно также выбрать " Добавить собственный скрипт теста" и предоставить собственный скрипт теста до 100 речевых фрагментов, чтобы протестировать модель без дополнительных затрат. Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования. Дополнительные сведения см. в статье о требованиях к скрипту тестирования.
Введите имя, чтобы определить модель. Тщательно выбирайте имя. Имя модели используется в качестве голосового имени в запросе синтеза речи в пакете SDK и входных данных SSML. Разрешены только буквы, цифры и несколько знаков препинания. Используйте разные имена для разных нейронных голосовых моделей.
При необходимости введите описание , чтобы определить модель. Обычное использование описания заключается в записи имен данных, используемых для создания модели.
Выберите Далее.
Просмотрите параметры и выберите поле для принятия условий использования.
Нажмите кнопку "Отправить ", чтобы начать обучение модели.
Двуязычное обучение
Если выбрать тип обучения нейронных данных , вы можете обучить голос для выступления на нескольких языках. , zh-CNzh-HKи языковые стандарта поддерживают двуязычное обучение для голоса, чтобы говорить как на китайском, так и zh-TW на английском языках. В зависимости от ваших обучающих данных синтезированный голос может говорить на английском языке с английским собственным акцентом или английским с тем же акцентом, что и данные обучения.
Примечание.
Чтобы в локали zh-CN голос мог говорить по-английски с тем же акцентом, что и образец данных, необходимо загрузить английские данные в набор обучения контекстный, или выбрать Chinese (Mandarin, Simplified), English bilingual при создании проекта, или указать локаль zh-CN (English bilingual) для данных набора обучения через REST API.
В вашем контекстном наборе обучения включите по крайней мере 100 предложений или 10 минут английского содержимого и не превышайте объем китайского содержимого.
В следующей таблице показаны различия между языковыми стандартами:
| Языковой стандарт Speech Studio | Языковой стандарт REST API | Двуязычная поддержка |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Если образец данных содержит английский, синтезированный голос говорит на английском языке с английским собственным акцентом вместо того же акцента, что и выборка данных, независимо от объема данных английского языка. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Если вы хотите, чтобы синтезированный голос говорил на английском языке с тем же акцентом, что и выборка данных, рекомендуется включить более 10 % данных английского языка в обучающий набор. В противном случае акцент на английском языке может быть не идеальным. |
Chinese (Cantonese, Simplified) |
zh-HK |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10 % английских данных в учебном наборе. В противном случае он по умолчанию используется для английского собственного акцента. Пороговое значение 10 % вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые отправленные данные английского языка отклоняются из-за дефектов и не соответствуют пороговой значению 10 %, синтезированный голос по умолчанию используется для английского собственного акцента. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10 % английских данных в учебном наборе. В противном случае он по умолчанию используется для английского собственного акцента. Пороговое значение 10 % вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые отправленные данные английского языка отклоняются из-за дефектов и не соответствуют пороговой значению 10 %, синтезированный голос по умолчанию используется для английского собственного акцента. |
Мониторинг процесса обучения
В таблице обучения модели появится новая запись, соответствующая вновь созданной модели. Состояние отражает процесс преобразования данных в голосовую модель, как описано в этой таблице:
| Состояние | Значение |
|---|---|
| Обработка | Идет создание голосовой модели. |
| Выполнено | Голосовая модель создана и может быть развернута. |
| Неудачно | При обучении голосовой модели произошел сбой. Причиной сбоя могут быть, например, незамеченные проблемы с данными или неполадки в сети. |
| Отменено | Обучение модели голосовой связи отменено. |
Пока состояние модели — обработка, можно выбрать команду "Отмена обучения", чтобы отменить модель голосовой связи. Плата за отмененное обучение не взимается.
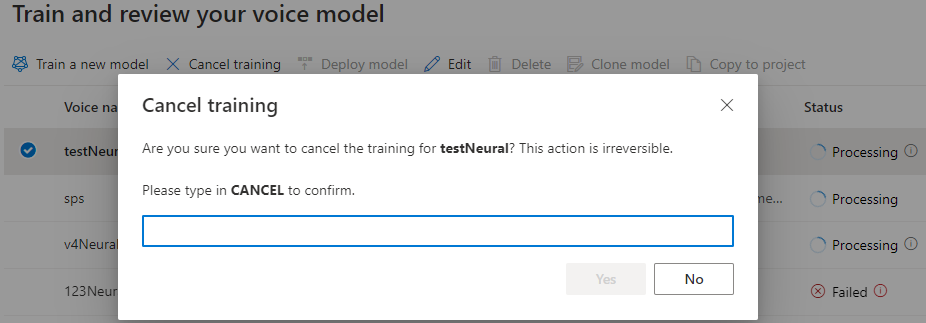
После успешного обучения модели можно просмотреть сведения о модели и протестировать голосовую модель.
Вы можете использовать средство создания аудиоконтентов в Speech Studio для создания звука и точной настройки развернутого голоса. Если применимо для голоса, можно выбрать один из нескольких стилей.
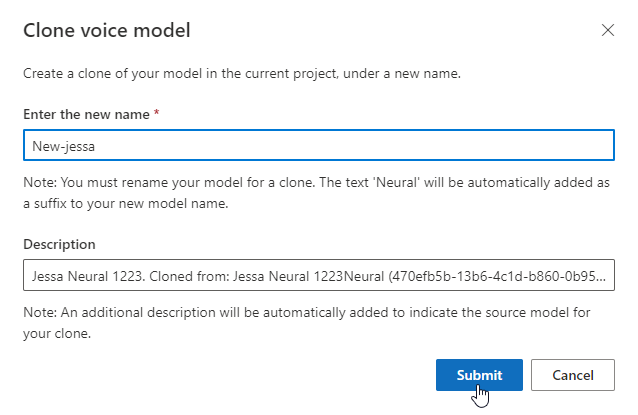
Переименование модели
Если вы хотите переименовать созданную модель, выберите "Клонировать модель", чтобы создать клон модели с новым именем в текущем проекте.
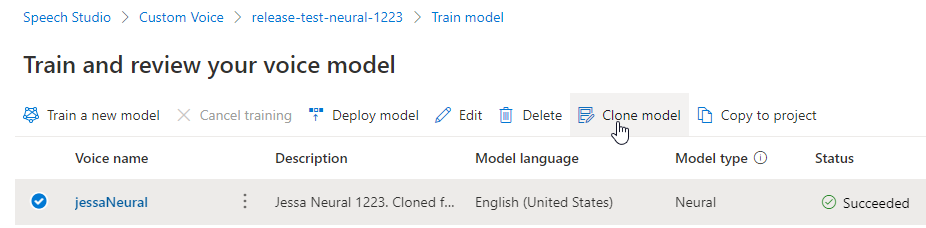
Введите новое имя в окне "Клонировать голосовую модель " и нажмите кнопку "Отправить". Текстовый нейрон автоматически добавляется в качестве суффикса в имя новой модели.
Тестирование голосовой модели
После успешной сборки модели голосовой связи можно использовать созданные примеры звуковых файлов для его тестирования перед развертыванием.
Примечание.
Нейронная — многоязычная (предварительная версия) и нейронная — голосовая связь HD (предварительная версия) не поддерживают этот тип тестирования.
Качество голоса зависит от многих факторов, таких как:
- Размер набора обучающих данных.
- Качество записи.
- Правильность транскрипции.
- Насколько хорошо записанный голос в обучающих данных соответствует индивидуальному шаблону для вашего предполагаемого варианта использования.
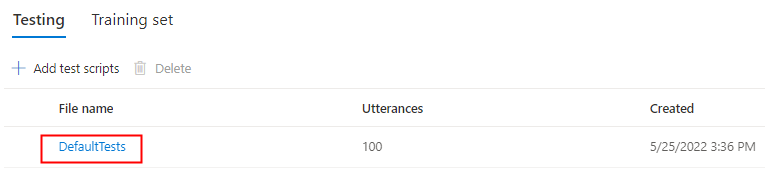
Выберите DefaultTests в разделе "Тестирование", чтобы прослушивать образец звуковых файлов. Примеры тестов по умолчанию включают 100 примеров звуковых файлов, созданных автоматически во время обучения, чтобы помочь вам протестировать модель. Помимо этих 100 звуковых файлов, предоставляемых по умолчанию, собственные речевые фрагменты скрипта тестирования также добавляются в набор DefaultTests . Это дополнение составляет не более 100 речевых фрагментов. Плата за тестирование с помощью DefaultTests не взимается.
Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования модели, выберите Add test scripts (Добавить тестовые скрипты).
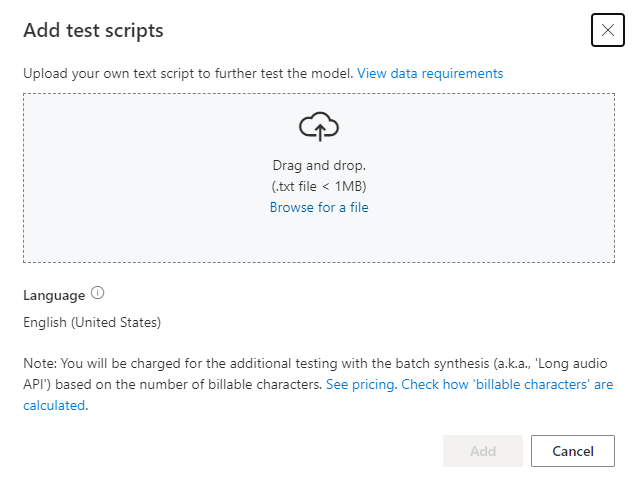
Перед отправкой тестового скрипта проверьте требования к скрипту тестирования. Плата за дополнительное тестирование с помощью пакетного синтеза взимается на основе количества оплачиваемых символов. См . цены на распознавание речи ВИ Azure.
В разделе "Добавить тестовые скрипты" выберите "Обзор файла ", чтобы выбрать собственный скрипт, а затем нажмите кнопку "Добавить ", чтобы отправить его.
Требования к скрипту тестирования
Тестовый скрипт должен быть файлом .txt размером менее 1 МБ. В число поддерживаемых форматов кодирования входят: ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE и UTF-16-BE.
В отличие от файлов обучающего транскрибирования, скрипт теста должен исключить идентификатор высказываний, который является именем файла каждого высказывания. В противном случае эти идентификаторы будут озвучены.
Ниже приведен пример набора речевых фрагментов в одном файле .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Для каждого абзаца речевого фрагмента создается отдельный звуковой файл. Если вы хотите объединить все предложения в один файл, объедините их в один абзац.
Примечание.
Созданные звуковые файлы — это сочетание скриптов автоматического тестирования и пользовательских скриптов тестирования.
Обновление версии подсистемы для голосовой модели
Текст Azure для подсистем речи обновляется от времени, чтобы записать последнюю языковую модель, которая определяет произношение языка. После обучения голоса вы можете применить голос к новой языковой модели, обновив до последней версии двигателя.
Когда будет доступна новая подсистема, вам будет предложено обновить модель нейронного голоса.

Перейдите на страницу сведений о модели и следуйте инструкциям на экране, чтобы установить последнюю версию подсистемы.

Кроме того, выберите " Установить последнюю версию подсистемы ", чтобы обновить модель до последней версии ядра.
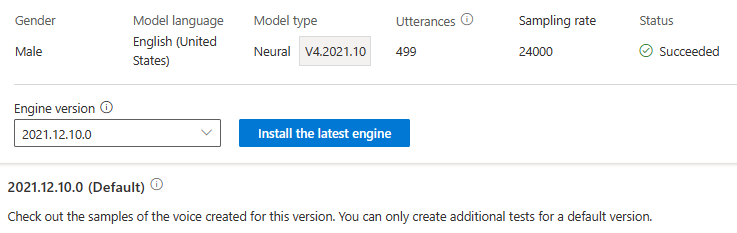
Плата за обновление подсистемы не взимается. Предыдущие версии сохраняются.
Вы можете проверить все версии подсистемы для модели из списка версий подсистемы или удалить ее, если она больше не нужна.
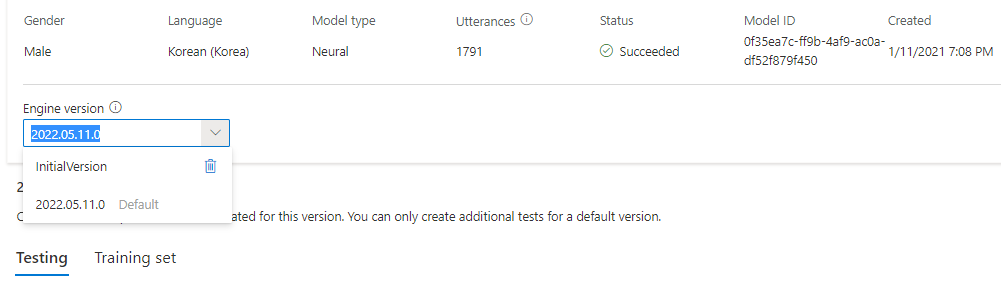
Обновленная версия автоматически устанавливается по умолчанию. Но вы можете изменить версию по умолчанию, выбрав версию из раскрывающегося списка и выбрав "Задать в качестве значения по умолчанию".
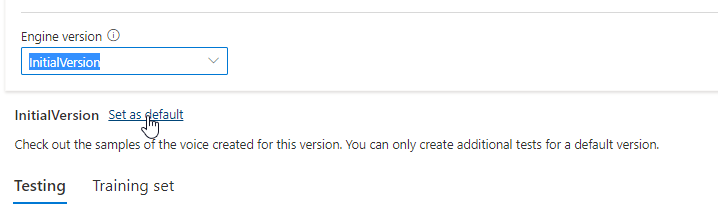

Если вы хотите протестировать каждую версию подсистемы голосовой модели, можно выбрать версию из списка, а затем выберите DefaultTests в разделе "Тестирование ", чтобы прослушивать образец звуковых файлов. Если вы хотите отправить собственные тестовые скрипты для дальнейшего тестирования текущей версии подсистемы, сначала убедитесь, что версия задана по умолчанию, а затем выполните действия, описанные в разделе "Тестирование голосовой модели".
Обновление подсистемы создает новую версию модели без дополнительных затрат. После обновления версии подсистемы для голосовой модели необходимо развернуть новую версию, чтобы создать новую конечную точку. Вы можете развернуть только версию по умолчанию.
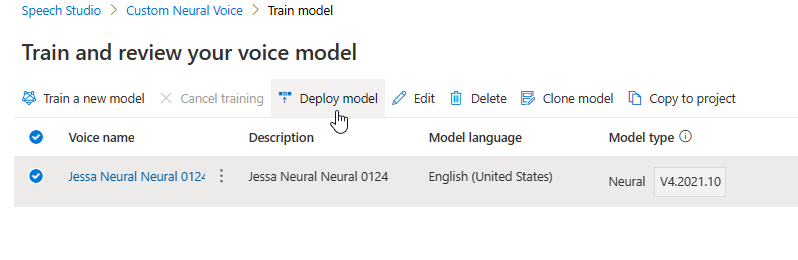
После создания новой конечной точки необходимо передать трафик в новую конечную точку в продукте.
Дополнительные сведения о возможностях и ограничениях этой функции и рекомендациях по улучшению качества модели см. в разделе "Характеристики и ограничения" для использования пользовательского голоса.
Копирование голосовой модели в другой проект
Вы можете скопировать голосовую модель в другой проект для того же или другого региона. Например, можно скопировать модель нейронной голоса, обученную в одном регионе, в проект для другого региона.
Примечание.
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. Вы можете скопировать нейронную голосовую модель из этих регионов в другие регионы. Дополнительные сведения см. в регионах для пользовательского голоса.
Чтобы скопировать пользовательскую голосовую модель в другой проект:
На вкладке Обучение модели выберите голосовую модель, которую необходимо скопировать, а затем выберите Копировать в проект.
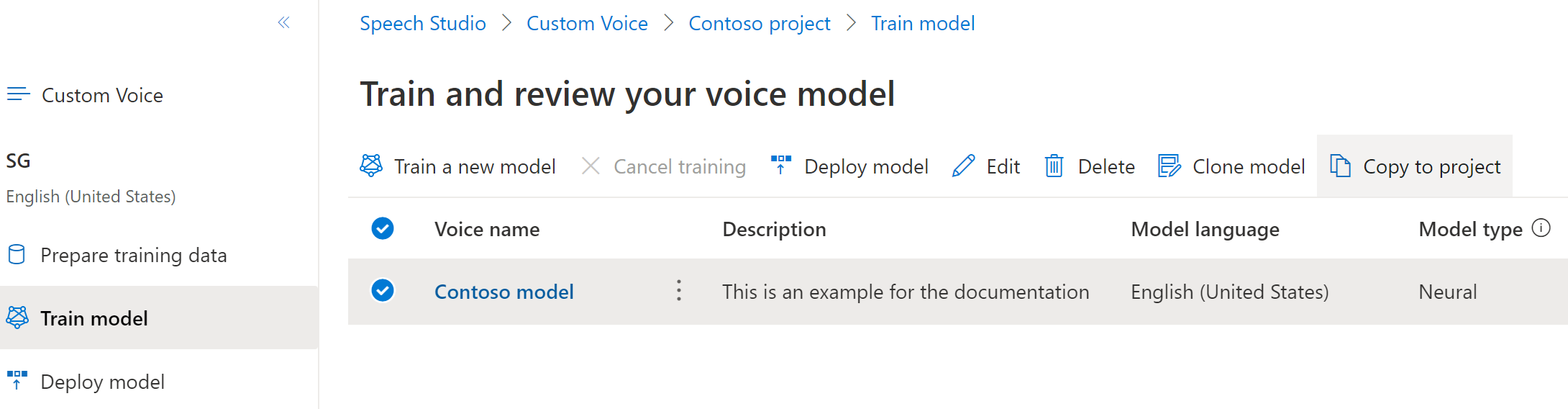
Выберите подписку, регион, ресурс службы "Речь" и проект, где нужно скопировать модель. Если речевой ресурс и проект находятся не в целевом регионе, сначала необходимо их создать.
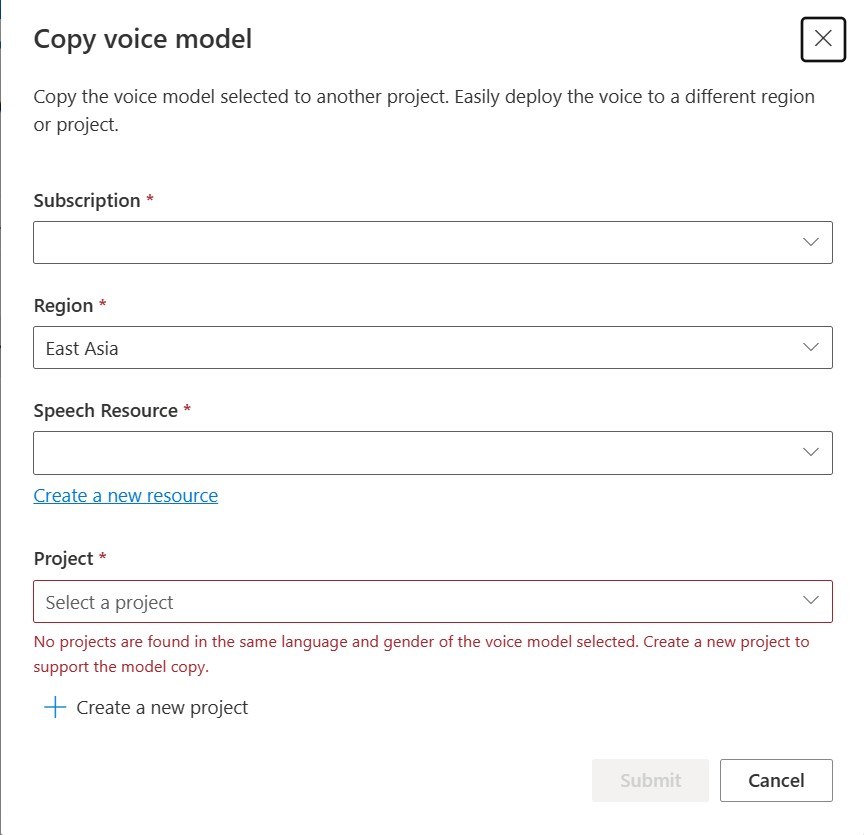
Нажмите кнопку Отправить, чтобы скопировать модель.
Выберите модель представления в сообщении уведомления об успешном копировании.
Перейдите к проекту, в котором вы скопировали модель для развертывания копии модели.
Следующие шаги
В этой статье вы узнаете, как настроить профессиональный голос с помощью пользовательского API голосовой связи.
Внимание
Профессиональная настройка голосовой связи в настоящее время доступна только в некоторых регионах. После обучения голосовой модели в поддерживаемом регионе его можно скопировать в ресурс AI Foundry в другом регионе по мере необходимости. Дополнительные сведения см. в сносках в таблице службы "Речь".
Длительность обучения зависит от того, сколько данных вы используете. В среднем для настройки профессионального голоса требуется около 40 часов вычислений. Пользователи со стандартной подпиской (S0) могут одновременно обучать четыре голоса. Если этот предел достигнут, подождите, пока хотя бы одна из моделей завершит обучение, а затем повторите попытку.
Примечание.
Хотя общее количество часов, необходимых для каждого метода обучения, зависит от одной и той же цены на единицу. Дополнительные сведения см. в разделе о ценах на настраиваемую нейронную подготовку.
Выбор метода обучения
После проверки файлов данных используйте их для создания пользовательской голосовой модели. При создании пользовательского голоса вы можете обучить его одним из следующих методов:
Нейронный: создайте голос на том же языке данных обучения.
Нейронный — кросслингвальный: создайте голос, который говорит на другом языке, отличном от обучающих данных. Например, с
fr-FRпомощью обучающих данных можно создать голос, который говоритen-US.Язык обучающих данных и целевого языка должен быть одним из языков, которые поддерживаются для перекрестного обучения голосовой связи. Вам не нужно подготавливать обучающие данные на целевом языке, но тестовый скрипт должен находиться на целевом языке.
Нейронная — много стилей: создайте пользовательский голос, который говорит в разных стилях и с различными эмоциями, не добавляя новые обучающие данные. Несколько стилей голоса полезны для игровых персонажей, беседных чат-ботов, аудиокниг, средств чтения содержимого и многое другое.
Чтобы создать несколько стилей голоса, необходимо подготовить набор общих обучающих данных, по крайней мере 300 речевых фрагментов. Выберите один или несколько предустановленных стилей речи целевого объекта. Вы также можете создать несколько пользовательских стилей, предоставив примеры стилей, по крайней мере 100 речевых фрагментов на стиль, в качестве дополнительных обучающих данных для одного голоса. Поддерживаемые стили предустановок зависят от разных языков. Просмотрите доступные стили предустановок на разных языках.
- Нейронная — голосовая связь HD (предварительная версия): создайте голос HD на том же языке обучающих данных. Нейронные HD-голоса Azure основаны на языковых моделях (Large Language Models, LLM) и оптимизированы для ведения динамичных разговоров. Дополнительные сведения об нейронных голосах HD см. здесь.
Язык обучающих данных должен быть одним из языков, которые поддерживаются для пользовательского голосового, межъязыкового обучения, обучения различным стилям или HD-голосу.
Создание голосовой модели
- Невральный
- Нейронная — перекрестный лингвальный
- Нейронная — многоуровневая
- Нейронная — многоязычная (предварительная версия)
- Нейронная — голосовая связь HD (предварительная версия)
Чтобы создать нейронный голос, используйте операцию Models_Create пользовательского голосового API. Создайте текст запроса в соответствии со следующими инструкциями:
- Задайте обязательное свойство
projectId. См. статью о создании проекта. - Задайте обязательное свойство
consentId. См . добавление согласия на голосовые таланты. - Задайте обязательное свойство
trainingSetId. См. статью о создании обучаемого набора. - Задайте требуемое свойство
kindрецептаDefaultдля обучения нейронного голоса. Тип рецепта указывает метод обучения и не может быть изменен позже. Чтобы использовать другой метод обучения, см. Нейронный - межъязыковой или нейронный - мультистильный или нейронный - HD голос (предварительный просмотр). Дополнительные сведения о двуязычной подготовке и различиях между языковыми стандартами см . в двуязычной подготовке . - Задайте обязательное свойство
voiceName. Тщательно выбирайте имя. Имя голоса используется в запросе синтеза речи в пакете SDK и входных данных SSML. Разрешены только буквы, цифры и несколько знаков препинания. Используйте разные имена для разных нейронных голосовых моделей. - При необходимости задайте
descriptionсвойство для описания голоса. Описание голоса можно изменить позже.
Выполните HTTP-запрос PUT с помощью URI, как показано в следующем Models_Create примере.
- Замените
YourResourceKeyключом ресурса службы речи. - Замените
YourResourceRegionрегион ресурсов службы "Речь". - Замените
JessicaModelIdидентификатором модели по своему усмотрению. Конфиденциальный идентификатор регистра будет использоваться в URI модели и не может быть изменен позже.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Вы должны получить ответ в следующем формате:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V10.0"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Двуязычное обучение
Если выбрать тип обучения нейронных данных , вы можете обучить голос для выступления на нескольких языках. , zh-CNzh-HKи языковые стандарта поддерживают двуязычное обучение для голоса, чтобы говорить как на китайском, так и zh-TW на английском языках. В зависимости от ваших обучающих данных синтезированный голос может говорить на английском языке с английским собственным акцентом или английским с тем же акцентом, что и данные обучения.
Примечание.
Чтобы в локали zh-CN голос мог говорить по-английски с тем же акцентом, что и образец данных, необходимо загрузить английские данные в набор обучения контекстный, или выбрать Chinese (Mandarin, Simplified), English bilingual при создании проекта, или указать локаль zh-CN (English bilingual) для данных набора обучения через REST API.
В вашем контекстном наборе обучения включите по крайней мере 100 предложений или 10 минут английского содержимого и не превышайте объем китайского содержимого.
В следующей таблице показаны различия между языковыми стандартами:
| Языковой стандарт Speech Studio | Языковой стандарт REST API | Двуязычная поддержка |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Если образец данных содержит английский, синтезированный голос говорит на английском языке с английским собственным акцентом вместо того же акцента, что и выборка данных, независимо от объема данных английского языка. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Если вы хотите, чтобы синтезированный голос говорил на английском языке с тем же акцентом, что и выборка данных, рекомендуется включить более 10 % данных английского языка в обучающий набор. В противном случае акцент на английском языке может быть не идеальным. |
Chinese (Cantonese, Simplified) |
zh-HK |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10 % английских данных в учебном наборе. В противном случае он по умолчанию используется для английского собственного акцента. Пороговое значение 10 % вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые отправленные данные английского языка отклоняются из-за дефектов и не соответствуют пороговой значению 10 %, синтезированный голос по умолчанию используется для английского собственного акцента. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Если вы хотите обучить синтезированный голос, способный говорить на английском языке с тем же акцентом, что и образец данных, обязательно предоставьте более 10 % английских данных в учебном наборе. В противном случае он по умолчанию используется для английского собственного акцента. Пороговое значение 10 % вычисляется на основе данных, принятых после успешной отправки, а не данных перед отправкой. Если некоторые отправленные данные английского языка отклоняются из-за дефектов и не соответствуют пороговой значению 10 %, синтезированный голос по умолчанию используется для английского собственного акцента. |
Доступные стили предустановок на разных языках
В следующей таблице перечислены различные предустановленные стили в соответствии с различными языками.
| Стиль речи | Язык (языковой стандарт) |
|---|---|
| сердитый | Английский (США) (en-US)Японский (Япония) ( ja-JP1) Китайский (Мандарин, упрощенное письмо) ( zh-CN) 1 |
| спокойный | Китайский (Мандарин, упрощенное письмо) (zh-CN) 1 |
| чат | Китайский (Мандарин, упрощенное письмо) (zh-CN) 1 |
| бодрый | Английский (США) (en-US)Японский (Япония) ( ja-JP1) Китайский (Мандарин, упрощенное письмо) ( zh-CN) 1 |
| недовольный | Китайский (Мандарин, упрощенное письмо) (zh-CN) 1 |
| возбужденный | Английский (США) (en-US) |
| боязливый | Китайский (Мандарин, упрощенное письмо) (zh-CN) 1 |
| учетной | Английский (США) (en-US) |
| многообещающий | Английский (США) (en-US) |
| грустный | Английский (США) (en-US)Японский (Япония) ( ja-JP1) Китайский (Мандарин, упрощенное письмо) ( zh-CN) 1 |
| крики | Английский (США) (en-US) |
| серьёзный | Китайский (Мандарин, упрощенное письмо) (zh-CN) 1 |
| ошеломлённый | Английский (США) (en-US) |
| недружественный | Английский (США) (en-US) |
| шепчущий | Английский (США) (en-US) |
1 Стиль нейронного голоса доступен в общедоступной предварительной версии. Стили в общедоступной предварительной версии доступны только в этих регионах службы: восточная часть США, Западная Европа и Юго-Восточная Азия.
Получение состояния обучения
Чтобы получить состояние обучения голосовой модели, используйте Models_Get операцию пользовательского API голосовой связи. Создайте URI запроса в соответствии со следующими инструкциями:
Выполните HTTP-запрос GET с помощью URI, как показано в следующем Models_Get примере.
- Замените
YourResourceKeyключом ресурса службы речи. - Замените
YourResourceRegionрегион ресурсов службы "Речь". - Замените
JessicaModelId, если вы указали другой идентификатор модели на предыдущем шаге.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Текст ответа должен быть получен в следующем формате.
Примечание.
Рецепт kind и другие свойства зависят от того, как вы обучили голос. В этом примере тип рецепта предназначен Default для обучения нейронного голоса.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Может потребоваться ждать несколько минут до завершения обучения. В конечном итоге состояние изменится на либо SucceededFailed.