Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Пользовательский перевод позволяет создавать систему перевода, которая отражает терминологию и стиль конкретной отрасли, отрасли и предметной области. Обучить и развернуть пользовательскую систему несложно, для этого не нужны навыки программирования. Настраиваемая система перевода легко интегрируется в существующие приложения, рабочие процессы и веб-сайты и доступна в Azure через ту же облачную облачную службу API перевода текста Microsoft, которая ежедневно выполняет миллиарды переводов.
Пользовательский перевод позволяет создать систему перевода, которая полностью отражает уникальный язык вашего бизнеса, отраслевую терминологию и стиль, характерный для вашего домена. С интуитивно понятным интерфейсом обучение, тестирование и развертывание вашей пользовательской модели становится простым и не требует опыта в программировании. Легко интегрируйте адаптированную систему перевода в существующие приложения, рабочие процессы и веб-сайты, поддерживаемые облачной службой API перевода текстов Azure AI, которая обеспечивает миллиарды переводов каждый день.
Платформа позволяет пользователям создавать и публиковать пользовательские системы перевода на английском языке. Пользовательский переводчик поддерживает более 100 языков, которые сопоставляют непосредственно с языками, доступными для нейронного машинного перевода (NMT). Полный список см. в разделе"Поддержка языка переводчика".
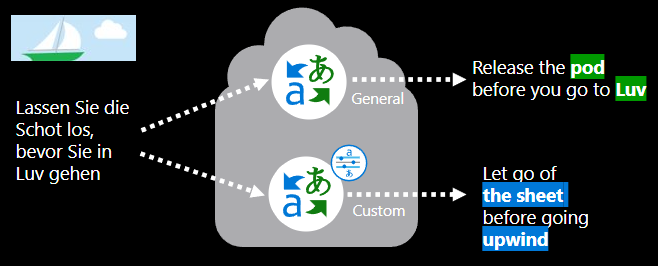
Подходит ли вам пользовательская модель перевода?
Хорошо запрограммированная пользовательская модель перевода обеспечивает точные, специализированные переводы, обучаясь на ранее переведенных документах из соответствующей предметной области. Этот подход гарантирует, что в контексте используются специализированные термины и фразы, создавая естественные переводы, которые уважают грамматические нюансы целевого языка.
Помните, что для разработки полной пользовательской модели перевода требуется значительный объем обучающих данных, как правило, не менее 10 000 параллельных предложений. Если у вас недостаточно данных для обучения комплексной модели, можно рассмотреть возможность создания модели на основе исключительно словаря, чтобы получить необходимую терминологию, или вы можете полагаться на высококачественные, готовые переводы, предлагаемые API для перевода текста.
В конечном счете, если вам нужны переводы, которые отражают конкретный язык вашей отрасли, и у вас есть широкие учебные ресурсы, пользовательская модель перевода может быть идеальным выбором для вашей организации.
В чем заключается обучение пользовательской модели перевода?
Для создания пользовательской модели перевода требуется:
Понимание варианта использования.
Получение переведенных данных, относящихся к предметной области (лучше, если это будут переводы, выполненные человеком).
Оценка качества перевода или перевода на целевой язык.
Как оценить мой вариант использования?
Первый шаг к формированию источника профессиональных обучающих данных — четкое понимание вашего варианта использования и того, что вы будете считать успехом. При этом нужно учесть ряд факторов.
Указан ли нужный результат и как он измеряется?
Определяется ли ваш бизнес-домен?
Есть ли у вас предложения, относящиеся к предметной области похожие по терминологии и стилю?
Предполагает ли ваш вариант использования несколько предметных областей? Если да, следует ли создавать одну систему перевода или несколько?
Есть ли у вас требования, влияющие на регион расположения неактивных данных и данных в процессе передачи?
Есть ли целевые пользователи в одном или нескольких регионах?
Как предоставлять исходные данные?
Поиск качественных данных в домене часто сопряжен с трудностями, которые зависят от классификации пользователей. Ниже приведены некоторые вопросы, которые вы можете задать самостоятельно при оценке доступных для вас данных:
Имеются ли у вашей компании предыдущие данные перевода, которые можно использовать? Предприятия часто обладают большим объемом данных перевода, накопленных на протяжении многих лет при использовании человеческого перевода.
Есть ли у вас огромное количество одноязычных данных? Одноязычные данные — это данные только на одном языке. Если да, можно ли получить переводы для этих данных?
Можно ли просканировать веб-порталы, чтобы собрать исходные предложения и синтезировать их перевод на целевой язык?
Что следует использовать для учебных материалов?
| Исходный материал | Что он делает | Правила для выполнения |
|---|---|---|
| Двуязычные учебные документы | Обучает систему применять вашу терминологию и стиль. | Будьте снисходительны. Любой предметный перевод, выполненный человеком, будет лучше машинного. Добавляйте и удаляйте документы по ходу работы и постарайтесь улучшить оценку BLEU. |
| Настройка документов | Помогает научиться применять параметры нейронного машинного перевода. | Будьте строги. Создайте их, чтобы быть оптимальным представителем того, что вы собираетесь перевести в будущем. |
| Проверка документов | Позволяет вычислить оценку BLEU. | Будьте строги. Составляйте тестовые документы так, чтобы они были оптимально соответствовали тому, что вы собираетесь переводить в будущем. |
| Словарь фраз | Принудительно выдает заданный перевод в течение всего времени. | Ставьте ограничения. Словарь фраз учитывает регистр, а все слова и фразы, занесенные в список, переводятся указанным способом. Во многих случаях лучше не использовать словарь фраз и дать системе возможность обучиться. |
| Словарь предложений | Принудительно выдает заданный перевод в течение всего времени. | Будьте строги. В словаре предложений не учитывается регистр, и он хорошо подходит для коротких предложений, которые нередко встречаются в предметной области. Чтобы засчитывалось совпадение со словарем предложений, запись в словаре должна полностью и точно совпадать с полученным предложением. Если совпадает только часть предложения, запись не соответствует. |
Что такое оценка BLEU?
BLEU (двуязычная оценка недоумение) — это алгоритм для оценки точности или точности текста, переведенного с одного языка на другой. Пользовательский перевод использует метрику BLEU для оценки точности перевода.
Оценка BLEU — это число от 0 до 100. Нулевой показатель указывает на некачественный перевод, который совершенно не соответствует справочному. Оценка 100 означает идеальный перевод, идентичный справочному. Необязательно стремиться к результату 100 — оценка BLEU между 40 и 60 указывает на высокое качество перевода.
Что произойдет, если я не буду отправлять данные для настройки или тестирования?
Предложения, используемые для настройки и тестирования, оптимально соответствуют тому, что вы собираетесь переводить в будущем. Если вы не отправляете данные о настройке или тестировании, настраиваемый перевод автоматически исключает предложения из обучающих документов для использования в качестве данных настройки и тестирования.
| Создано системой | Выбор вручную |
|---|---|
| Удобный процесс. | Обеспечивает точную настройку для будущих потребностей. |
| Хороший выбор, если вы уверены, что обучающие данные оптимально соответствуют тому, что вы планируете переводить. | Предоставляет больше свободы при формировании обучающих данных. |
| Легко выполнить заново при расширении или сокращении предметной области. | Позволяет использовать больше данных и лучше соответствует предметной области. |
| Меняются при каждом цикле обучения. | Не меняется при повторных циклах обучения. |
Как обучающие материалы обрабатываются с помощью пользовательского перевода?
Для подготовки к обучению документы проходят ряд шагов обработки и фильтрации. Знание процесса фильтрации может помочь понять количество предложений, отображаемых, а также шаги, которые можно предпринять, чтобы подготовить учебные документы для обучения с помощью пользовательского перевода. Ниже приведены шаги фильтрации.
Выравнивание предложений
Если ваш документ не находится в формате
XLIFF,XLSX,TMXилиALIGN, настраиваемый перевод сопоставляет предложения исходных и целевых документов друг с другом, предложение за предложением. Переводчик не производит выравнивание документов — он следует соглашению об именовании, чтобы найти соответствующий документ на другом языке. В исходном тексте пользовательский перевод пытается найти соответствующее предложение на целевом языке. Он использует разметку документа, например внедренные теги HTML, чтобы упростить выравнивание.Если вы видите большое несоответствие между количеством предложений в исходных и целевых документах, исходный документ не может быть параллельным или не может быть выровнен. Если в паре документов разница в количестве предложений составляет более 10%, проверьте документы и убедитесь, что они параллельны.
Настройка и тестирование извлечения данных
Данные для настройки и тестирования являются необязательными. Если он не указан, система удаляет соответствующий процент из обучающих документов, используемых для настройки и тестирования. Удаление происходит динамически в рамках процесса обучения. Поскольку этот этап осуществляется в ходе обучения, отправленные документы не затрагиваются. После успешного обучения можно просмотреть окончательные счетчики предложений для каждой категории данных — обучение, настройка, тестирование и словарь.
Фильтр длины
- Удаляет предложения только из одного слова с обеих сторон.
- Удаляет предложения, включающие больше 100 слов, с обеих сторон. Кроме китайского, японского и корейского.
- Удаляет предложения, содержащие меньше трех символов. Кроме китайского, японского и корейского.
- Удаляет предложения с более чем 2000 символами для китайского, японского, корейского.
- Удаляет предложения, где буквы и цифры занимают менее 1%.
- Удаляет записи словаря, содержащие более 50 слов.
Пробел
- Заменяет любую последовательность символов пробела, включая табуляцию и переход на новую строку, одним пробелом.
- Удаляет начальные и конечные пробелы в предложении.
Конечный знак препинания в предложении
Заменяет несколько знаков препинания в конце предложения одним знаком. Нормализация японских символов.
Преобразует буквы и цифры полной ширины в символы половинной ширины.
Неэкранированные теги XML
Преобразует неэкранированные теги в экранированные:
Тег превращается в < & lt; > & gt; & & ампер; Недопустимые знаки
Настраиваемый перевод удаляет предложения, содержащие символ ЮникодА U+FFFD. Символ U+FFFD указывает на сбой преобразования кодировки.
Недопустимые HTML-теги
Пользовательский перевод удаляет допустимые теги во время обучения. Недопустимые теги вызывают непредсказуемые результаты и должны быть удалены вручную.
Какие действия следует предпринять перед отправкой данных?
- Удалите предложения с недопустимой кодировкой.
- Удалите управляющие символы Юникода.
- При необходимости выравнивайте предложения (исходные и целевые).
- Удалите исходные и целевые предложения, которые не соответствуют исходному и целевому языкам.
- Если исходные и целевые предложения используют смешанные языки, убедитесь, что непереведенные слова оставлены намеренно, например, если это названия организаций и продуктов.
- Избегайте ошибок обучения модели, убедившись, что грамматика и типография правильны.
- Имеет одно исходное предложение, сопоставленное с одним целевым предложением. Хотя учебный процесс обрабатывает исходные и целевые строки, содержащие несколько предложений, сопоставление "один к одному" рекомендуется.
- Удалите недопустимые ТЕГИ HTML перед отправкой обучающих данных.
Как оценить результаты?
После успешного обучения модели можно просмотреть оценку BLEU модели и оценку базовой модели BLEU на странице сведений о модели. Мы используем один и тот же набор тестовых данных для создания оценки BLEU модели и базовой оценки BLEU. Эти данные помогут вам принять обоснованное решение о том, какая модель лучше подходит для вашего варианта использования.