Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Если вы хотите тщательно оценить производительность создаваемых моделей и приложений ИИ при применении к существенному набору данных, можно инициировать процесс оценки. Во время этой оценки модель или приложение тестируются с помощью заданного набора данных, а его производительность количественно измеряется как с математическими метриками, так и с помощью ИИ. Этот запуск оценки предоставляет подробные сведения о возможностях и ограничениях приложения.
Для выполнения этой оценки можно использовать функцию оценки на портале Azure AI Foundry, комплексную платформу, которая предлагает средства и функции для оценки производительности и безопасности модели создания искусственного интеллекта. На портале Azure AI Foundry вы можете регистрировать, просматривать и анализировать подробные метрики оценки.
В этой статье вы узнаете, как создать выполнение оценки для модели или тестового набора данных со встроенными метриками оценки из пользовательского интерфейса Azure AI Foundry. Для повышения гибкости можно установить пользовательский поток оценки и использовать пользовательскую функцию оценки . Вы также можете использовать пользовательскую функцию оценки для выполнения пакетного выполнения без какой-либо оценки.
Предпосылки
- Тестовый набор данных в одном из следующих форматов: CSV или JSON Lines (JSONL).
- Подключение Azure OpenAI. Развертывание одной из этих моделей: модель GPT-3.5, модель GPT-4 или модель Davinci. Требуется только при выполнении оценки качества с поддержкой ИИ.
Создание оценки со встроенными метриками оценки
Выполнение оценки позволяет создавать выходные данные метрик для каждой строки данных в тестовом наборе данных. Вы можете выбрать одну или несколько метрик оценки, чтобы оценить выходные данные из различных аспектов. Вы можете создать процесс оценки на страницах каталога оценки или модели в портале Azure AI Foundry. Откроется мастер настройки оценки, показывающий, как запустить выполнение оценки.
На странице оценки
В раскрывающемся меню слева выберите "Оценка>создать новую оценку".

На странице каталога моделей
В раскрывающемся меню слева выберите каталог моделей.
Перейдите к модели.
Перейдите на вкладку "Тесты".
Выберите "Попробовать с собственными данными". Этот вариант открывает панель оценки модели, где можно провести оценку для выбранной модели.


Целевой объект оценки
При запуске оценки на странице "Оценка " сначала необходимо выбрать целевой объект оценки. Указав соответствующий целевой объект оценки, мы можем адаптировать оценку к определенной природе приложения, обеспечивая точность и соответствующие метрики. Мы поддерживаем два типа целевых показателей оценки:
- Точно настроенная модель: этот выбор оценивает выходные данные, созданные выбранной моделью и определяемым пользователем запросом.
- Набор данных: выходные данные, созданные моделью, уже находятся в тестовом наборе данных.

Настройка тестовых данных
При вводе мастера создания оценки можно выбрать из предварительно созданных наборов данных или отправить новый набор данных для оценки. Тестовый набор данных должен иметь созданные моделью выходные данные, которые будут использоваться для оценки. Предварительный просмотр тестовых данных отображается на правой панели.
Выберите существующий набор данных: можно выбрать тестовый набор данных из установленной коллекции наборов данных.
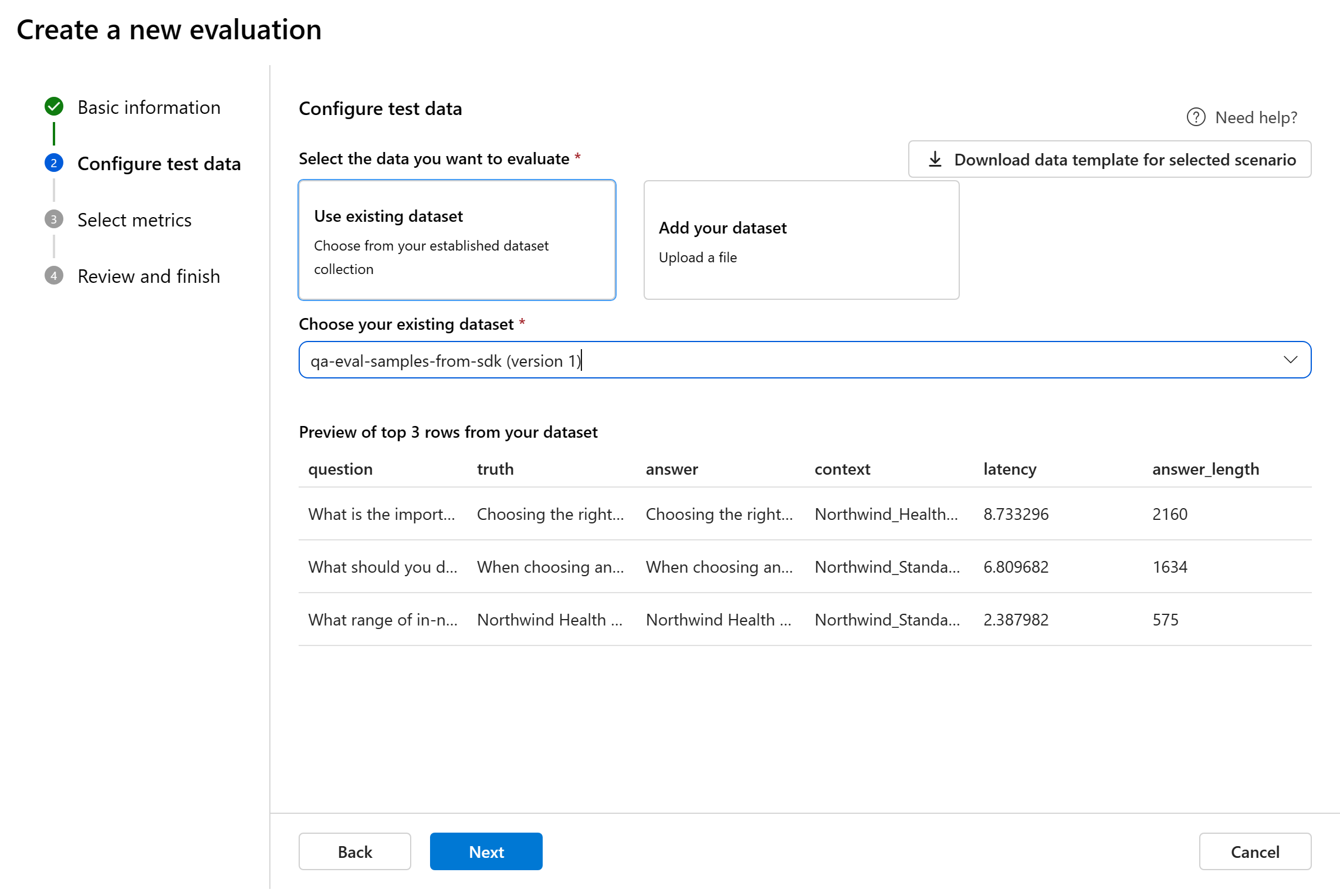
Добавьте новый набор данных: отправьте файлы из локального хранилища. Поддерживаются только форматы ФАЙЛОВ CSV и JSONL. Предварительный просмотр тестовых данных отображается на правой панели.
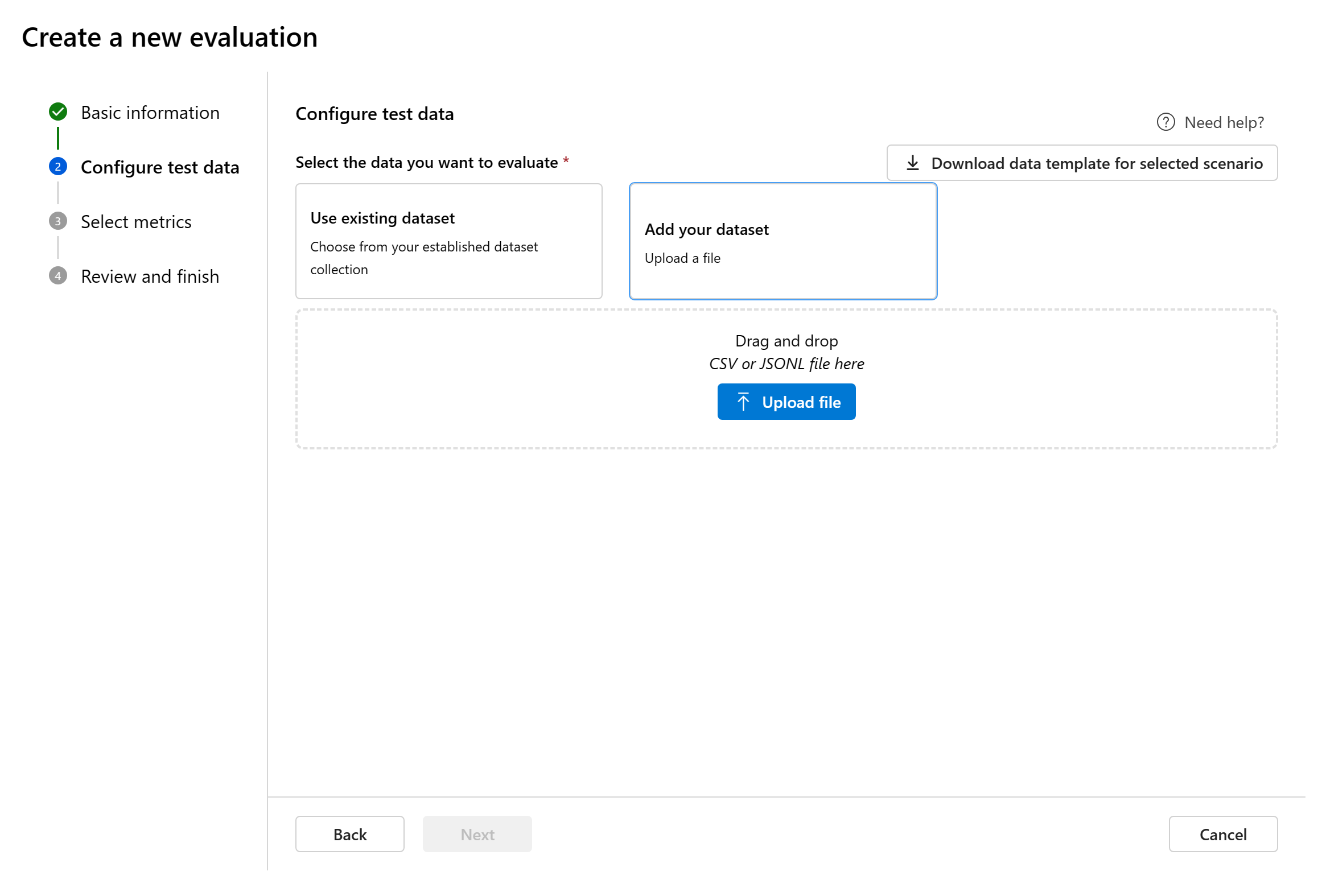


Настройка условий тестирования
Мы поддерживаем три типа метрик, курируемых корпорацией Майкрософт, для упрощения комплексной оценки приложения:
- Качество ИИ (СИ) — эти метрики оценивают общее качество и согласованность созданного содержимого. Для того чтобы запустить эти метрики, вам необходимо развертывание модели для их оценки.
- Качество ИИ (NLP): эти метрики обработки естественного языка (NLP) являются математическими, и они также оценивают общее качество созданного содержимого. Для них часто требуются данные о реальных значениях, но они не требуют развертывания модели для оценки.
- Метрики риска и безопасности: эти метрики сосредоточены на выявлении потенциальных рисков содержимого и обеспечении безопасности созданного содержимого.

При добавлении критериев тестирования различные метрики будут использоваться в рамках оценки. Вы можете обратиться к таблице для полного списка метрик, для которых мы предлагаем поддержку в каждом сценарии. Дополнительные сведения о определениях метрик и их вычислении см. в разделе "Что такое оценщики?".
| Качество ИИ (СИ) | Качество ИИ (NLP) | Метрики риска и безопасности |
|---|---|---|
| Подобие, релевантность, согласованность, fluency, GPT сходства | F1 score, ROUGE score, BLEU score, GLEU score, METEOR score (оценочные метрики) | Содержимое, связанное с самостоятельной вредом, ненавистное и несправедливое содержимое, насильственное содержимое, сексуальное содержимое, защищенный материал, непрямая атака |
При выполнении оценки качества с поддержкой ИИ необходимо указать модель GPT для процесса вычисления или оценки.

Метрики качества ИИ (NLP) — это математически основанные измерения, которые оценивают производительность приложения. Они часто требуют данных истины для вычисления. ROUGE — это семейство метрик. Для вычисления показателей можно выбрать тип ROUGE. Различные типы метрик ROUGE предлагают способы оценки качества создания текста. ROUGE-N измеряет перекрытие n-граммов между кандидатом и справочными текстами.

Для оценки риска и безопасности вам не нужно организовывать развертывание. Портал Azure AI Foundry подготавливает модель GPT-4, которая может генерировать оценки степени риска содержания и соответствующие объяснения, чтобы вы могли оценить ваше приложение на предмет потенциальных вредов, связанных с содержанием.
Замечание
Метрики риска и безопасности с поддержкой ИИ размещаются в оценках безопасности Azure AI Foundry и доступны только в следующих регионах: Восточная часть США 2, Центральная Франция, Южная Великобритания, Центральная Швеция.

Осторожность
Пользователи, которые ранее управляли развертываниями моделей и выполняли оценки с помощью, oai.azure.comа затем подключены к платформе разработчика Azure AI Foundry, имеют эти ограничения при использовании ai.azure.com:
- Эти пользователи не могут просматривать свои оценки, созданные с помощью API OpenAI Azure. Чтобы просмотреть эти оценки, они должны вернуться в
oai.azure.com. - Эти пользователи не могут использовать API OpenAI Azure для выполнения вычислений в Azure AI Foundry. Вместо этого они должны продолжать использовать
oai.azure.comдля этой задачи. Однако они могут использовать вычислители Azure OpenAI, доступные непосредственно в Azure AI Foundry (ai.azure.com) в параметре для создания оценки набора данных. Возможность тонкой настройки оценки модели не поддерживается, если развертывание является миграцией из Azure OpenAI в Azure AI Foundry.
Для сценария загрузки набора данных и использования собственного хранилища существует несколько требований к конфигурации:
- Проверка подлинности учетной записи должна осуществляться через Microsoft Entra ID.
- Хранилище должно быть добавлено в учетную запись. Добавление его в проект приводит к ошибкам службы.
- Пользователи должны добавить свой проект в учетную запись хранения с помощью управления доступом на портале Azure.
Дополнительные сведения о создании оценок с помощью оценщиков OpenAI в хабе Azure OpenAI см. в статье Как использовать Azure OpenAI в оценке моделей Azure AI Foundry.
Сопоставление данных
Сопоставление данных для оценки. Для каждой добавленной метрики необходимо указать, какие столбцы данных в наборе данных соответствуют входным данным, необходимым в оценке. Различные метрики оценки требуют различных типов входных данных для точных вычислений.
Во время оценки ответ модели оценивается по ключевым входным данным, таким как:
- Запрос: обязательный для всех метрик.
- Контекст: необязательно.
- Эталонные данные: необязательны, но требуются для оценки качества ИИ (NLP).
Эти сопоставления обеспечивают точное выравнивание данных и критериев оценки.

Требования к метрику запросов и ответов
Рекомендации по конкретным требованиям сопоставления данных для каждой метрики см. в этой таблице:
| Единица измерения | Запрос | Ответ | Контекст | Земля истина |
|---|---|---|---|---|
| Обоснованность | Обязательный: Str | Обязательный: Str | Обязательный: Str | Не применяется |
| Согласованность | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Беглость | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Актуальность | Обязательный: Str | Обязательный: Str | Обязательный: Str | Не применяется |
| Сходство GPT | Обязательный: Str | Обязательный: Str | Не применяется | Обязательный: Str |
| Оценка F1 | Не применяется | Обязательный: Str | Не применяется | Обязательный: Str |
| Оценка BLEU | Не применяется | Обязательный: Str | Не применяется | Обязательный: Str |
| Оценка GLEU | Не применяется | Обязательный: Str | Не применяется | Обязательный: Str |
| ОЦЕНКА МЕТЕОРА | Не применяется | Обязательный: Str | Не применяется | Обязательный: Str |
| Оценка ROUGE | Не применяется | Обязательный: Str | Не применяется | Обязательный: Str |
| Контент, связанный с самоповреждением | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Ненавистное и несправедливое содержимое | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Насильственное содержимое | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Сексуальное содержимое | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Защищаемый материал | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
| Непрямая атака | Обязательный: Str | Обязательный: Str | Не применяется | Не применяется |
- Запрос: запрос, запрашивающий конкретные сведения.
- Ответ: ответ на запрос, созданный моделью.
- Контекст: источник, на который основан ответ. (Пример: основные документы.)
- Эталонный ответ: ответ на запрос, составленный человеком, который служит истинным ответом.
Проверка и завершение
После завершения всех необходимых конфигураций можно указать необязательное имя для оценки. Затем можно просмотреть выполнение оценки и выбрать Отправить, чтобы отправить результаты.

Тонко настроенная оценка модели
Чтобы создать новую оценку для выбранного развертывания модели, можно использовать модель GPT для создания примеров вопросов или выбрать из установленной коллекции наборов данных.

Настройка тестовых данных для точно настроенной модели
Настройте тестовый набор данных, используемый для оценки. Этот набор данных отправляется в модель для создания ответов для оценки. У вас есть два варианта настройки тестовых данных:
- Создание примера вопросов
- Использование существующего набора данных (или отправка нового набора данных)
Создание примера вопросов
Если у вас нет набора данных, который легко доступен и требуется выполнить оценку с небольшим примером, выберите развертывание модели, которую вы хотите оценить на основе выбранного раздела. Поддерживаются модели Azure OpenAI и другие открытые модели, совместимые с бессерверным развертыванием API, например с моделями семейства Meta Llama и Phi-3.
Этот раздел помогает адаптировать созданное содержимое к интересующей вас области. Запросы и ответы создаются в режиме реального времени, и их можно повторно создать по мере необходимости.
Используйте ваш набор данных
Вы также можете выбрать из установленной коллекции наборов данных или отправить новый набор данных.

Выбор метрик оценки
Чтобы настроить критерии тестирования, нажмите кнопку "Далее". При выборе условий добавляются метрики и необходимо сопоставить столбцы набора данных с необходимыми полями для оценки. Эти сопоставления обеспечивают точное выравнивание данных и критериев оценки.
Выбрав нужные критерии теста, можно просмотреть оценку, при необходимости изменить имя оценки, а затем нажмите кнопку "Отправить". Перейдите на страницу оценки, чтобы просмотреть результаты.

Замечание
Созданный набор данных сохраняется в хранилище BLOB-объектов проекта после создания ознакомительного запуска.
Просмотр и управление вычислителями в библиотеке оценщиков
Сведения и состояние оценщиков можно увидеть в одном месте в библиотеке оценщиков. Вы можете просматривать и управлять оценщиками, курируемыми компанией Майкрософт.
Библиотека вычислителя также включает управление версиями. При необходимости можно сравнить различные версии работы, восстановить предыдущие версии и упростить совместную работу с другими пользователями.
Чтобы использовать библиотеку вычислителя на портале Azure AI Foundry, перейдите на страницу оценки проекта и перейдите на вкладку библиотеки оценки.

Чтобы просмотреть дополнительные сведения, можно выбрать имя вычислителя. Вы можете просмотреть имя, описание и параметры, а также проверить все файлы, связанные с оценщиком. Ниже приведены некоторые примеры оценщиков, курируемых корпорацией Майкрософт.
- Для оценки производительности и качества, курируемых корпорацией Майкрософт, можно просмотреть запрос заметки на странице сведений. Эти запросы можно адаптировать к собственному варианту использования. Измените параметры или критерии в соответствии с вашими данными и целями в пакете SDK для оценки ИИ Azure. Например, можно выбрать Groundedness-Evaluator и проверить файл запроса, который показывает, как мы вычисляем метрику.
- Для оценщиков рисков и безопасности, курируемых корпорацией Майкрософт, можно увидеть определение метрик. Например, вы можете выбрать "Оценщик контента, связанного с самоповреждением", чтобы узнать, что это означает, и понять, как корпорация Майкрософт определяет уровни серьезности.
Связанный контент
Узнайте больше о том, как оценить созданные приложения ИИ: