Обзор автомасштабирования кластера в Служба Azure Kubernetes (AKS)
Чтобы обеспечить соответствие требованиям приложений в Служба Azure Kubernetes (AKS), может потребоваться настроить количество узлов, выполняющих рабочие нагрузки. Компонент автомасштабирования кластера наблюдает за модулями pod в кластере, которые не могут быть запланированы из-за ограничений ресурсов. Когда средство автомасштабирования кластера обнаруживает незапланированные модули pod, оно масштабирует число узлов в пуле узлов в соответствии с требованиями приложения. Он также регулярно проверяет узлы, которые не имеют запланированных модулей pod и масштабируют количество узлов по мере необходимости.
В этой статье показано, как работает автомасштабирование кластера в AKS. Он также предоставляет рекомендации, рекомендации и рекомендации при настройке автомасштабирования кластера для рабочих нагрузок AKS. Если вы хотите включить, отключить или обновить автомасштабирование кластера для рабочих нагрузок AKS, см. раздел "Использование автомасштабирования кластера" в AKS.
Сведения о средстве автомасштабирования кластера
Кластеры часто нуждаются в том, чтобы автоматически масштабироваться для изменения требований приложений, таких как между рабочими днями и вечерами или выходными. Кластеры AKS могут масштабироваться следующим образом:
- Автомасштабирование кластера периодически проверяет наличие модулей pod, которые не могут быть запланированы на узлах из-за ограничений ресурсов. При возникновении такой ситуации число узлов в кластере автоматически повышается. При использовании средства автомасштабирования кластера отключается возможность масштабирования вручную. Дополнительные сведения см. в статье о том, как масштабировать работу?.
- Функция горизонтального автомасштабирования pod использует сервер метрик в кластере Kubernetes для мониторинга спроса на ресурсы модулей pod. Если приложению нужно больше ресурсов, количество pod автоматически увеличивается в соответствии с требованиями.
- Средство автомасштабирования вертикального модуля pod автоматически задает запросы ресурсов и ограничения на контейнеры для каждой рабочей нагрузки на основе предыдущего использования, чтобы обеспечить планирование модулей pod на узлах с необходимыми ресурсами ЦП и памяти.
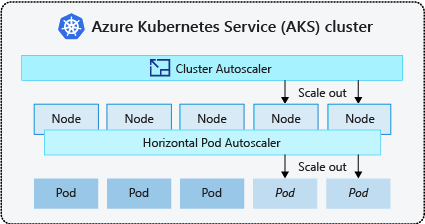
Это распространенная практика включения автомасштабирования кластера для узлов и вертикального автомасштабирования pod или горизонтального автомасштабирования pod для модулей pod. Если включить автомасштабирование кластера, он применяет указанные правила масштабирования, если размер пула узлов меньше минимального количества узлов, до максимального количества узлов. Автомасштабирование кластера ожидает, пока новый узел не понадобится в пуле узлов или пока узел не будет безопасно удален из текущего пула узлов. Дополнительные сведения см. в статье о том, как уменьшить масштаб работы?
Лучшие методики и рекомендации
- При реализации зон доступности с помощью автомасштабирования кластера рекомендуется использовать один пул узлов для каждой зоны. Параметр можно задать
--balance-similar-node-groupsдляTrueподдержания сбалансированного распределения узлов между зонами для рабочих нагрузок во время операций увеличения масштаба. Если этот подход не реализован, операции уменьшения масштаба могут нарушить баланс узлов между зонами. - Для кластеров с более чем 400 узлами рекомендуется использовать Azure CNI или наложение Azure CNI.
- Для эффективного запуска рабочих нагрузок одновременно в пулах точечных и фиксированных узлов рекомендуется использовать расширяющие средства приоритета. Этот подход позволяет планировать модули pod на основе приоритета пула узлов.
- При назначении запросов ЦП и памяти на модулях pod следует соблюдать осторожность. Автомасштабирование кластера масштабируется на основе ожидающих модулей pod, а не нагрузки на ЦП или память на узлах.
- Для кластеров одновременно с размещением длительных рабочих нагрузок, таких как веб-приложения, и коротких или временных рабочих нагрузок заданий, рекомендуется разделить их на отдельные пулы узлов с расширяющимися правилами affinity/или с помощью PriorityClass, чтобы предотвратить ненужную очистку узлов или уменьшить масштаб операций.
- В пуле узлов с поддержкой автомасштабирования уменьшайте масштаб узлов, удаляя рабочие нагрузки, а не уменьшая количество узлов вручную. Это может быть проблематично, если пул узлов уже находится в максимальной емкости или если на узлах выполняются активные рабочие нагрузки, что может привести к неожиданному поведению автомасштабирования кластера.
- Узлы не масштабируется, если модули pod имеют значение PriorityClass ниже -10. Приоритет -10 зарезервирован для чрезмерной подготовки модулей pod. Дополнительные сведения см. в разделе "Использование автомасштабирования кластера с приоритетом pod и предварительным применением".
- Не сочетайте другие механизмы автомасштабирования узлов, например автомасштабирование масштабируемых наборов виртуальных машин, с автомасштабированием кластера.
- Автомасштабирование кластера может быть не в состоянии уменьшить масштаб, если модули pod не могут перемещаться, например в следующих ситуациях:
- Непосредственно созданный модуль pod, не поддерживаемый объектом контроллера, например Deployment или ReplicaSet.
- Бюджет прерывания pod (PDB), который слишком строгий и не позволяет количеству модулей pod упасть ниже определенного порогового значения.
- если pod использует селекторы узла или свойства удаления сходства, которые невозможно выполнить, так как они запланированы на другом узле. Дополнительные сведения см. в статье о том, какие типы модулей pod могут запретить автомасштабированию кластера удалять узел?.
Внимание
Не изменяйте отдельные узлы в пулах узлов с автомасштабированием. Все узлы в одной группе узлов должны иметь единую емкость, метки, таинты и системные модули pod, работающие на них.
- Автомасштабирование кластера не несет ответственности за применение максимального количества узлов в пуле узлов кластера независимо от рекомендаций по планированию pod. Если любой субъект автомасштабирования, отличный от кластера, устанавливает количество пулов узлов на число, превышающее настроенное максимальное значение автомасштабирования кластера, автомасштабирование кластера не удаляет узлы автоматически. Поведение автомасштабирования кластера остается в пределах области удаления только узлов, не имеющих запланированных модулей pod. Единственной целью конфигурации максимального количества узлов кластера является применение верхнего предела для операций увеличения масштаба. Это не влияет на рекомендации по уменьшению масштаба.
Профиль автомасштабирования кластера
Профиль автомасштабирования кластера — это набор параметров, которые управляют поведением автомасштабирования кластера. Профиль автомасштабирования кластера можно настроить при создании кластера или обновлении существующего кластера.
Оптимизация профиля автомасштабирования кластера
Вы должны точно настроить параметры профиля автомасштабирования кластера в соответствии с конкретными сценариями рабочей нагрузки, а также учитывать компромиссы между производительностью и затратами. В этом разделе приведены примеры, демонстрирующие эти компромиссы.
Важно отметить, что параметры профиля автомасштабирования кластера являются кластерными и применяются ко всем пулам узлов с поддержкой автомасштабирования. Любые действия масштабирования, выполняемые в одном пуле узлов, могут повлиять на поведение автомасштабирования других пулов узлов, что может привести к непредвиденным результатам. Убедитесь, что вы применяете согласованные и синхронизированные конфигурации профилей во всех соответствующих пулах узлов, чтобы обеспечить получение нужных результатов.
Пример 1. Оптимизация производительности
Для кластеров, обрабатывающих значительные и временные рабочие нагрузки с основным акцентом на производительность, рекомендуется увеличить scan-interval и уменьшить.scale-down-utilization-threshold Эти параметры помогают пакетировать несколько операций масштабирования в один вызов, оптимизируя время масштабирования и использование квот вычислений чтения и записи. Это также помогает снизить риск быстрого уменьшения масштаба операций на неиспользуемых узлах, повышая эффективность планирования pod. Кроме того, увеличьте ok-total-unready-countи max-total-unready-percentage.
Для кластеров с модулями pod daemonset рекомендуется задать значение ignore-daemonset-utilization true, которое эффективно игнорирует использование узлов по модулям pod daemonset и сводит к минимуму ненужные операции уменьшения масштаба. См. профиль для временных рабочих нагрузок
Пример 2. Оптимизация затрат
Если требуется оптимизированный для затрат профиль, рекомендуется задать следующие конфигурации параметров:
- Уменьшите
scale-down-unneeded-time, что является временем, когда узел должен быть ненужным, прежде чем он может уменьшить масштаб. - Уменьшите
scale-down-delay-after-addвремя ожидания после добавления узла, прежде чем рассматривать его для уменьшения масштаба. - Увеличьте значение
scale-down-utilization-threshold, которое является пороговым значением использования для удаления узлов. - Увеличьте
max-empty-bulk-deleteмаксимальное количество узлов, которые можно удалить в одном вызове. - Установите
skip-nodes-with-local-storageзначение false. - Увеличение
ok-total-unready-countиmax-total-unready-percentage.
Распространенные проблемы и рекомендации по устранению рисков
Просмотр сбоев масштабирования и масштабирования не активируемых событий с помощью интерфейса командной строки или портала.
Не активируя операции масштабирования
| Основные причины | Рекомендации по устранению рисков |
|---|---|
| Конфликты сходства узлов PersistentVolume, которые могут возникать при использовании автомасштабирования кластера с несколькими зонами доступности или когда зона постоянного тома pod отличается от зоны узла. | Используйте один пул узлов для каждой зоны доступности и включите --balance-similar-node-groups. Вы также можете задать volumeBindingMode поле WaitForFirstConsumer в спецификации pod, чтобы предотвратить привязку тома к узлу до создания тома с помощью тома. |
| Ограничения и конфликты сходства узлов | Оцените ограничения, назначенные узлам, и просмотрите терпимые действия, определенные в модулях pod. При необходимости внесите изменения в оттенки и терпимые меры, чтобы обеспечить эффективное планирование модулей pod на узлах. |
Сбои операций масштабирования
| Основные причины | Рекомендации по устранению рисков |
|---|---|
| Исчерпание IP-адресов в подсети | Добавьте другую подсеть в ту же виртуальную сеть и добавьте другой пул узлов в новую подсеть. |
| Исчерпание основной квоты | Утвержденная квота ядра исчерпана. Запросить увеличение квоты. Средство автомасштабирования кластера вводит экспоненциальное состояние обратной передачи в определенной группе узлов при возникновении нескольких неудачных попыток увеличения масштаба. |
| Максимальный размер пула узлов | Увеличьте максимальные узлы в пуле узлов или создайте новый пул узлов. |
| Запросы и вызовы, превышающие ограничение скорости | См . слишком много ошибок запросов 429. |
Сбои операций уменьшения масштаба
| Основные причины | Рекомендации по устранению рисков |
|---|---|
| Pod, предотвращающий очистку узлов или не удается вытеснить pod | • Просмотр типов модулей pod может препятствовать уменьшению масштаба. • Для модулей pod, использующих локальное хранилище, например hostPath и emptyDir, установите флаг skip-nodes-with-local-storage falseпрофиля автомасштабирования кластера. • В спецификации pod задайте для заметки cluster-autoscaler.kubernetes.io/safe-to-evict trueзначение . • Проверьте PDB, так как это может быть ограничивающим. |
| Минимальный размер пула узлов | Уменьшите минимальный размер пула узлов. |
| Запросы и вызовы, превышающие ограничение скорости | См . слишком много ошибок запросов 429. |
| Операции записи заблокированы | Не вносите никаких изменений в полностью управляемую группу ресурсов AKS (см . политики поддержки AKS). Удалите или сбросьте все блокировки ресурсов, которые вы ранее применили к группе ресурсов. |
Другие проблемы
| Основные причины | Рекомендации по устранению рисков |
|---|---|
| PriorityConfigMapNotMatchedGroup | Убедитесь, что все группы узлов, требующие автомасштабирования, добавляются в файл конфигурации расширителя. |
Пул узлов в резервном режиме
Пул узлов в резервном режиме появился в версии 0.6.2 и приводит к тому, что автомасштабирование кластера отключается от масштабирования пула узлов после сбоя.
В зависимости от того, сколько времени операции масштабирования возникли сбои, может потребоваться до 30 минут, прежде чем предпринять другую попытку. Вы можете сбросить состояние обратного отключения пула узлов, отключив и повторно включив автомасштабирование.

Azure Kubernetes Service
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по