Модели обработки документов
Внимание
- Выпуски общедоступной предварительной версии Document Intelligence предоставляют ранний доступ к функциям, которые находятся в активной разработке.
- Функции, подходы и процессы могут изменяться до общедоступной доступности на основе отзывов пользователей.
- Общедоступная предварительная версия клиентских библиотек Аналитики документов по умолчанию использует rest API версии 2024-02-29-preview.
- Общедоступная предварительная версия 2024-02-29-preview в настоящее время доступна только в следующих регионах Azure:
- Восточная часть США
- Западная часть США2
- Западная Европа
Это содержимое относится к:v4.0 (предварительная версия) | Предыдущие версии:![]()
![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Это содержимое относится к:v3.1 (GA)Последняя версия![]() :v4.0 (предварительная версия) | | Предыдущие версии:
:v4.0 (предварительная версия) | | Предыдущие версии:![]()
![]() v3.0
v3.0![]() версии 2.1
версии 2.1
Это содержимое относится к:v3.0 (GA) | Последние версии:![]() v4.0 (предварительная версия)
v4.0 (предварительная версия)![]() 3.1 | Предыдущая версия:
3.1 | Предыдущая версия:![]()
![]() v2.1
v2.1
Это содержимое относится к:v2.1 Последняя версия![]() :
:![]() v4.0 (предварительная версия) |
v4.0 (предварительная версия) |
Azure AI Document Intelligence поддерживает широкий спектр моделей, позволяющих добавлять интеллектуальную обработку документов в приложения и потоки. Вы можете использовать предварительно созданную модель для конкретного домена или обучить пользовательскую модель, адаптированную к конкретным бизнес-потребностям и вариантам использования. Аналитика документов может использоваться с клиентскими библиотеками REST API или Python, C#, Java и JavaScript.
Общие сведения о модели
В следующей таблице показаны доступные модели для каждого текущего предварительного и стабильного API:
| Тип модели | Модель | • 2024-02-29-preview &маркер 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Модели анализа документов | Чтение | ✔️ | ✔️ | ✔️ | Н/Д |
| Модели анализа документов | Макет | ✔️ | ✔️ | ✔️ | ✔️ |
| Модели анализа документов | Документ общего назначения; | перемещен в макет** | ✔️ | ✔️ | Н/Д |
| Предварительно созданные модели | Контракт | ✔️ | ✔️ | Недоступно | Недоступно |
| Предварительно созданные модели | Медицинское страхование карта | ✔️ | ✔️ | ✔️ | Н/Д |
| Предварительно созданные модели | Удостоверение | ✔️ | ✔️ | ✔️ | ✔️ |
| Предварительно созданные модели | Счет-фактура | ✔️ | ✔️ | ✔️ | ✔️ |
| Предварительно созданные модели | Получения | ✔️ | ✔️ | ✔️ | ✔️ |
| Предварительно созданные модели | Налог США 1040* | ✔️ | ✔️ | Недоступно | Недоступно |
| Предварительно созданные модели | US 1098 Tax* | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | US 1099 Tax* | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | Налог НА W2 США | ✔️ | ✔️ | ✔️ | Н/Д |
| Предварительно созданные модели | US Ипотека 1003 URLA | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | Сводка по ипотеке США 1008 | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | Раскрытие информации о закрытии ипотеки США | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | Свидетельство о браке | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | Кредитная карта | ✔️ | Недоступно | н/д | Недоступно |
| Предварительно созданные модели | Визитная карточка | устарело | ✔️ | ✔️ | ✔️ |
| Пользовательская модель классификации | Настраиваемый классификатор | ✔️ | ✔️ | Недоступно | Недоступно |
| Пользовательская модель извлечения | Настраиваемая нейронная | ✔️ | ✔️ | ✔️ | Н/Д |
| Модель customextraction | Пользовательский шаблон | ✔️ | ✔️ | ✔️ | ✔️ |
| Пользовательская модель извлечения | Пользовательский состав | ✔️ | ✔️ | ✔️ | ✔️ |
| Все модели | Возможности надстройки | ✔️ | ✔️ | Недоступно | Недоступно |
* — содержит вложенные модели. Сведения о модели см. в разделе о поддерживаемых вариантах и подтипах.
| Возможность надстройки | Надстройка или бесплатная | • 2024-02-29-preview &маркер [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-2024-02-29-preview&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Извлечение свойств шрифта | Надстройка | ✔️ | ✔️ | Недоступно | Недоступно |
| Извлечение формул | Надстройка | ✔️ | ✔️ | Недоступно | Недоступно |
| Извлечение высокого разрешения | Надстройка | ✔️ | ✔️ | Недоступно | Недоступно |
| Извлечение штрихкодов | Бесплатно | ✔️ | ✔️ | Недоступно | Недоступно |
| Распознавание языка | Бесплатно | ✔️ | ✔️ | Недоступно | Недоступно |
| Пары "ключ — значение" | Бесплатно | ✔️ | Недоступно | н/д | Недоступно |
| Поля запроса | Надстройка* | ✔️ | Недоступно | н/д | Недоступно |
Функции анализа моделей
| Model ID | Извлечение содержимого | Поля запроса | Абзацы | Роли абзаца | Метки выделения | Таблицы | Пары "Ключ-значение" | Языки | Штрихкоды | Анализ документов | Формулы* | Шрифт стиля* | Высокое разрешение* |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | O | O | O | O | O | |||||||
| prebuilt-layout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| prebuilt-document | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |
| prebuilt-businessCard | ✓ | ✓ | ✓ | ||||||||||
| предварительно созданный контракт | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-invoice | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | ||
| prebuilt-receipt | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| предварительно созданная кредитная карта | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1099(варианты) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1040(варианты) | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - Включен O - Необязательный
* - Премиум функции влечет за собой дополнительные расходы
Надстройка* — поля запросов отличаются от других функций надстройки. Подробные сведения см. в разделе Цены.
| Модель | Description |
|---|---|
| Модели анализа документов | |
| Чтение OCR | Извлеките печатный и рукописный текст, включая слова, расположения и обнаруженные языки. |
| Анализ макета | Извлеките элементы макета текста и документа, такие как таблицы, знаки выделения, заголовки разделов и многое другое. |
| Предварительно созданные модели | |
| Медицинское страхование карта | Автоматизация процессов здравоохранения путем извлечения страховщика, члена, рецепта, номера группы и других ключевых сведений из карта медицинского страхования США. |
| Модели налоговых документов США | Обработка налоговых форм США для извлечения сотрудников, работодателей, заработной платы и других сведений. |
| Модели ипотечных документов США | Обработка ипотечных форм США для извлечения кредита заемщика и информации о собственности. |
| Контракт | Извлечение соглашений и сведений о стороне. |
| Счет-фактура | Автоматизация счетов. |
| Получения | Извлечение данных о получении из квитанций. |
| Документ удостоверения (идентификатор) | Извлеките поля удостоверений (идентификатор) из лицензий водителя США и международных паспортов. |
| Визитная карточка | Сканируйте бизнес-карта, чтобы извлечь ключевые поля и данные в приложения. |
| Пользовательские модели | |
| Пользовательская модель (обзор) | Извлечение данных из форм и документов, относящихся к вашему бизнесу. Настраиваемые модели обучаются именно для ваших данных и вариантов использования. |
| Пользовательские модели извлечения | • Пользовательские модели шаблонов используют подсказки макета для извлечения значений из документов и подходят для извлечения полей из строго структурированных документов с определенными визуальными шаблонами. • Пользовательские нейронные модели обучены различным типам документов для извлечения полей из структурированных, полуструктурированных и неструктурированных документов. |
| Пользовательская модель классификации | Пользовательская модель классификации может классифицировать каждую страницу во входном файле, чтобы определить документы внутри и также определить несколько документов или несколько экземпляров одного документа в входном файле. |
| Составные модели | Объединение нескольких пользовательских моделей в одну модель для автоматизации обработки различных типов документов с одной составной моделью. |
Для всех моделей, кроме бизнес-карта модели, аналитика документов теперь поддерживает возможности надстроек, чтобы обеспечить более сложный анализ. Эти необязательные возможности можно включить и отключить в зависимости от сценария извлечения документов. Для общедоступной версии API доступны 2023-07-31 семь возможностей надстройки:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax models
Сведения о модели
В этом разделе описаны выходные данные, которые можно ожидать от каждой модели. Обратите внимание, что вы можете расширить выходные данные большинства моделей с помощью функций надстройки.
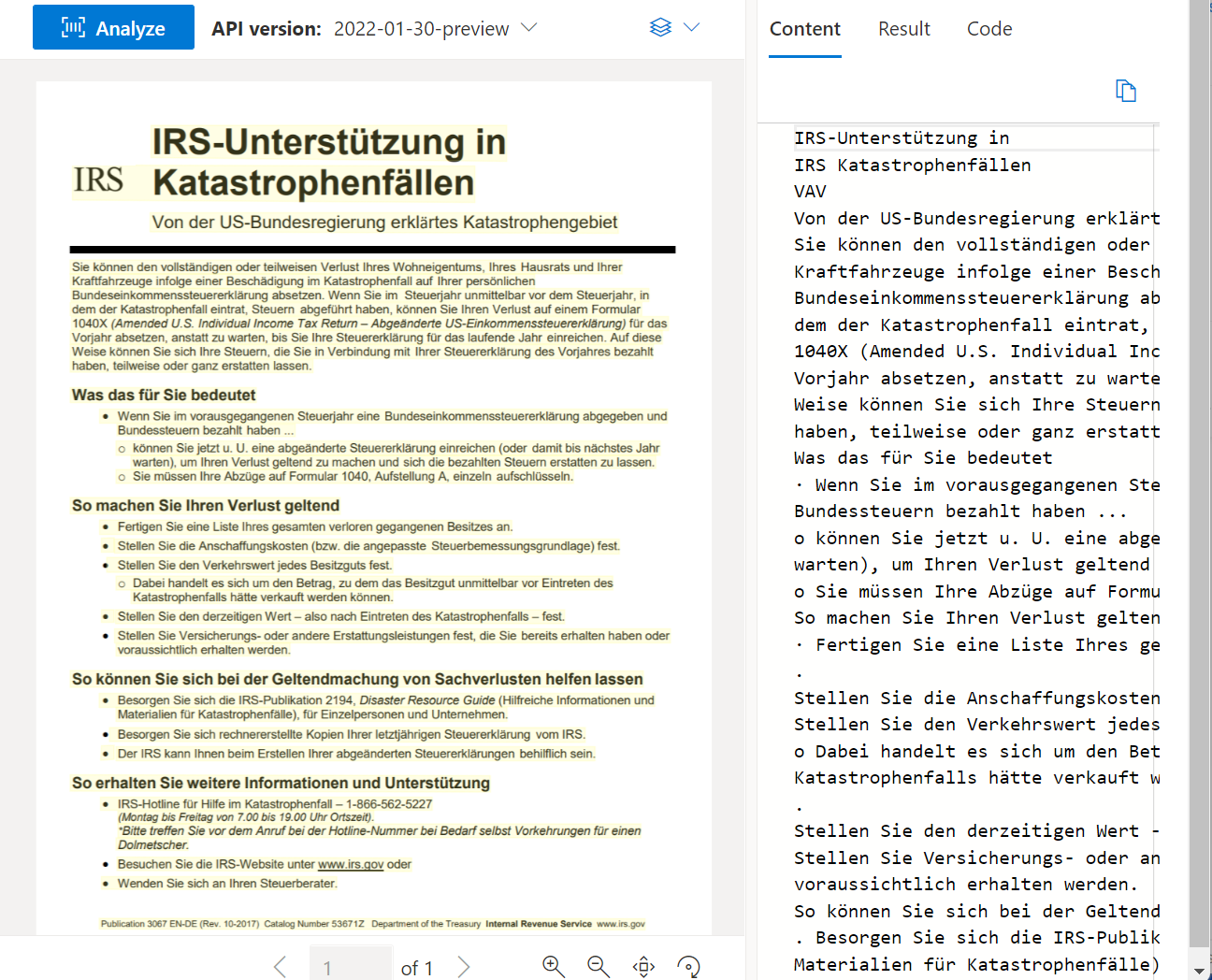
Чтение OCR

API чтения анализирует и извлекает строки, слова, их расположения, обнаруженные языки и рукописный стиль при обнаружении.
Пример документа, обработанный с помощью Студии аналитики документов:
Анализ макета
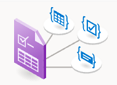
Модель анализа макета анализирует и извлекает текст, таблицы, знаки выделения и другие элементы структуры, такие как заголовки, заголовки разделов, заголовки страниц, нижние колонтитулы страницы и многое другое.
Пример документа, обработанный с помощью Студии аналитики документов:
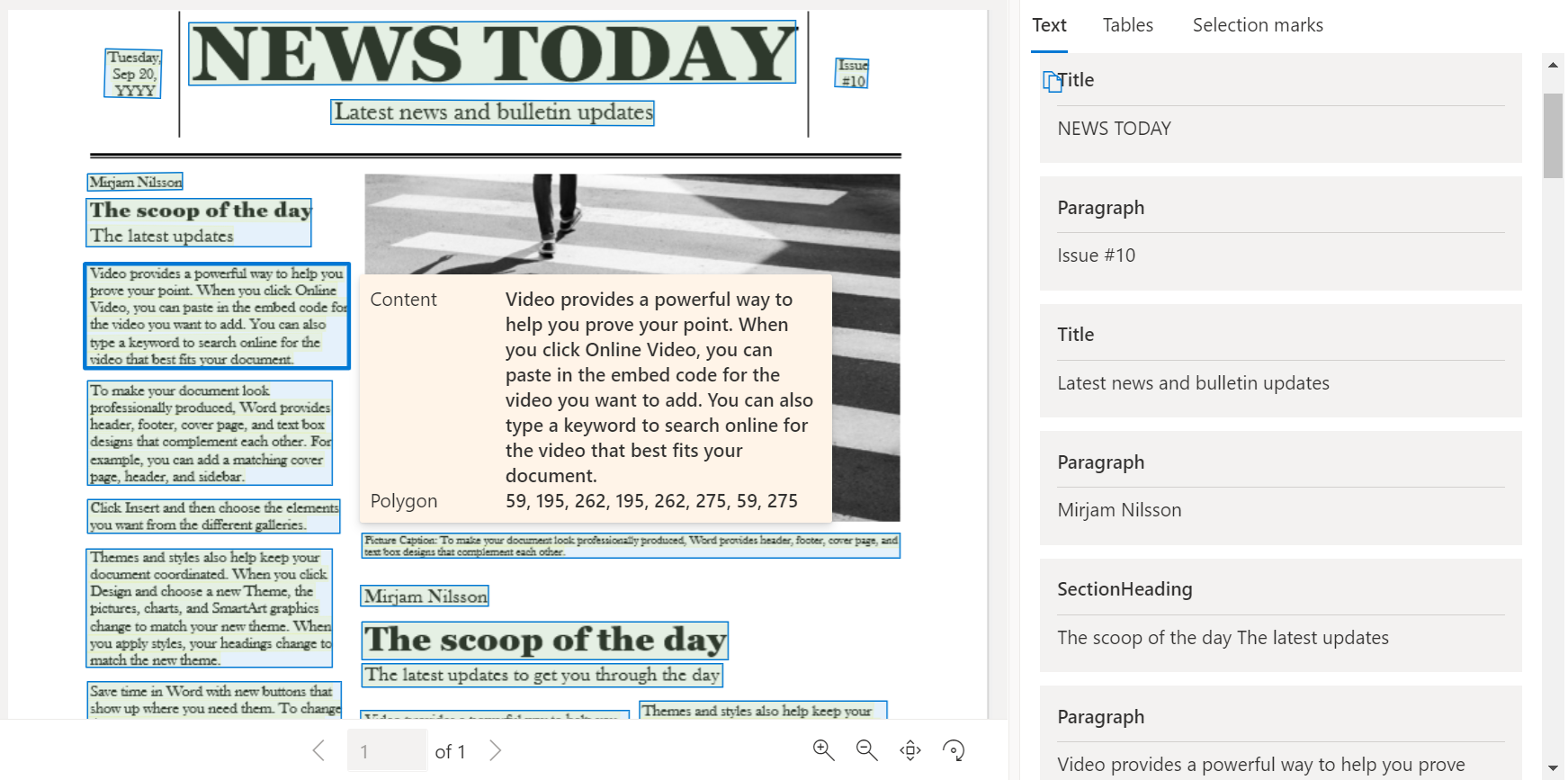
Медицинское страхование карта
![]()
Модель медицинского страхования карта объединяет мощные возможности оптического распознавания символов (OCR) с моделями глубокого обучения для анализа и извлечения ключевых сведений из карта медицинского страхования США.
Пример медицинского страхования США карта обработан с помощью Document Intelligence Studio:

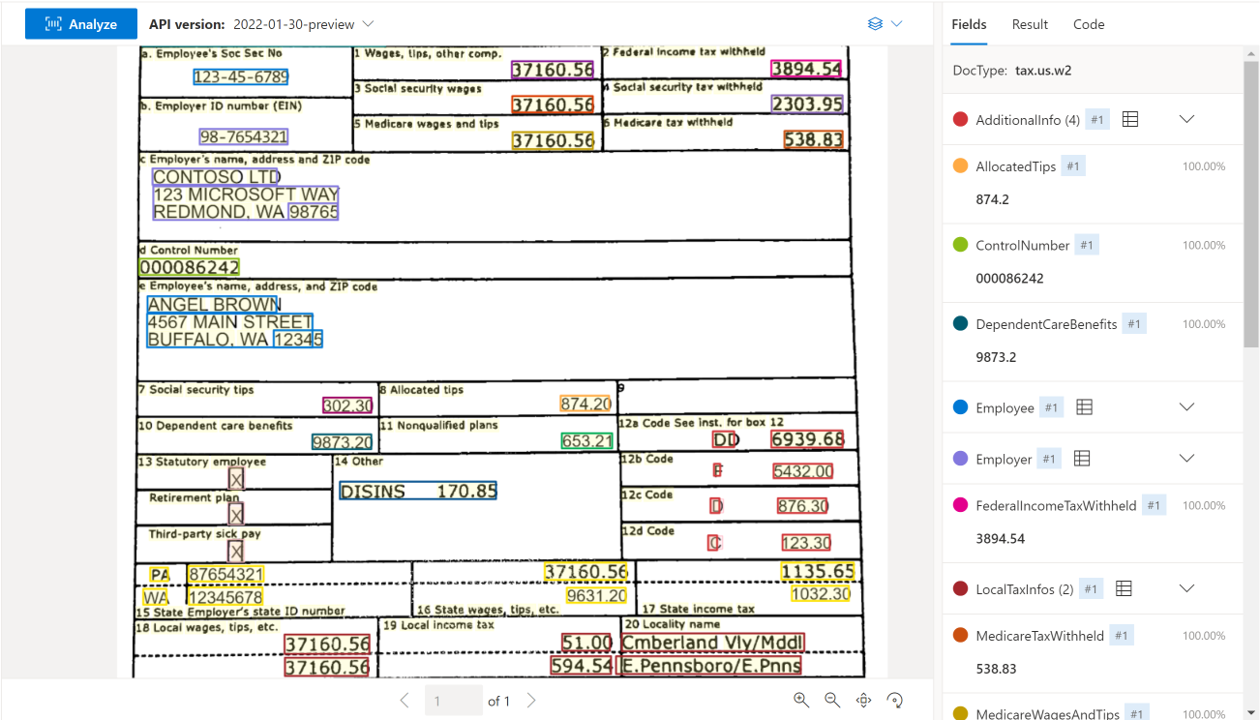
Налоговые документы США

Модели налоговых документов США анализируют и извлекают ключевые поля и элементы строки из выбранной группы налоговых документов. API поддерживает анализ налоговых документов НА английском языке США различных форматов и качества, включая захваченные телефоном изображения, сканированные документы и цифровые PDF-файлы. В настоящее время поддерживаются следующие модели:
| Модель | Description | Идентификатор модели |
|---|---|---|
| Налог США W-2 | Извлечение сведений о компенсации с налогом. | prebuilt-tax.us.W-2 |
| Налог США 1040 | Извлечение сведений об ипотечных интересах. | prebuilt-tax.us.1040(варианты) |
| Налог США 1098 | Извлечение сведений об ипотечных интересах. | prebuilt-tax.us.1098(варианты) |
| Налог США 1099 | Извлечение дохода, полученного из источников, отличных от работодателя. | prebuilt-tax.us.1099(варианты) |
Пример документа W-2, обработанный с помощью Document Intelligence Studio:
Ипотечные документы США

Модели ипотечных документов США анализируют и извлекают ключевые поля, включая заемщика, кредит и информацию о собственности из выбранной группы ипотечных документов. API поддерживает анализ документов ипотеки на английском языке США различных форматов и качества, включая изображения, захваченные телефоном, сканированные документы и цифровые PDF-файлы. В настоящее время поддерживаются следующие модели:
| Модель | Description | Идентификатор модели |
|---|---|---|
| Лицензионное соглашение 1003 (EULA) | Извлечение кредита, заемщика, сведений о собственности. | prebuilt-mortgage.us.1003 |
| Сводный документ 1008 | Извлечение заемщика, продавца, имущества, ипотеки и подзаписи подробностей. | prebuilt-mortgage.us.1008 |
| Закрытие раскрытия | Извлечение закрывающих, транзакционных затрат и сведений о кредите. | prebuilt-mortgage.us.closingDisclosure |
| Свидетельство о браке | Извлечение сведений о браке для заявителей совместного займа. | предварительно созданные-бракCertificate |
| Налог США W-2 | Извлеките сведения о налогооблагаемой компенсации для проверки дохода. | prebuilt-tax.us.W-2 |
Пример документа о закрытии раскрытия, обработанного с помощью Document Intelligence Studio:

Contract
![]()
Модель контракта анализирует и извлекает ключевые поля и элементы линии из договорных соглашений, включая стороны, юрисдикции, идентификатор контракта и название. В настоящее время модель поддерживает документы контракта на английском языке.
Пример контракта, обработанный с помощью Document Intelligence Studio:

Счет

Модель счета автоматизирует обработку счетов для извлечения имени клиента, адреса выставления счетов, даты выполнения и суммы, элементов строки и других ключевых данных. В настоящее время модель поддерживает счета на английском, испанском, немецком, французском, итальянском, португальском и голландском языках.
Пример счета, обработанный с помощью Document Intelligence Studio:

Получение
Используйте модель квитанций для сканирования квитанций о продажах для имени продавца, дат, элементов строки, количества и итогов от печатных и рукописных квитанций. Версия 3.0 также поддерживает обработку квитанций об одностраничных отелях.
Пример квитанции, обработанный с помощью Document Intelligence Studio:

Документ удостоверения (идентификатор)

Используйте модель удостоверения (ID) для обработки лицензий водителя США (все 50 штатов и округа Колумбия) и биография графических страниц из международных паспортов (за исключением виз и других документов для путешествий) для извлечения ключевых полей.
Пример лицензии водителя США, обработанный с помощью Document Intelligence Studio:

Свидетельство о браке
![]()
Используйте модель сертификата брака для обработки сертификатов браков США для извлечения ключевых полей, включая лиц, дату и расположение.
Пример сертификата о браке США, обработанный с помощью Document Intelligence Studio:

Кредитная карта
![]()
Используйте модель кредитной карта для обработки кредитных и дебетовых карта для извлечения ключевых полей.
Пример кредитной карта обработан с помощью Document Intelligence Studio:

Пользовательские модели

Пользовательские модели могут быть широко классифицированы по двум типам. Пользовательские модели классификации, поддерживающие классификацию типа документа и пользовательские модели извлечения, которые могут извлекать определенную схему из определенного типа документа.

Пользовательские модели документов анализируют и извлекают данные из форм и документов, относящихся к вашей организации. Они обучены распознавать поля формы в отдельном содержимом и извлекать пары "ключ-значение" и табличные данные. Чтобы приступить к работе, вам потребуется только один пример типа формы.
Пользовательская модель версии 3.0 поддерживает обнаружение подписей в пользовательских шаблонах (форме) и межстраничных таблицах как в шаблонах, так и в нейронных моделях.
Пример пользовательского шаблона, обработанного с помощью Document Intelligence Studio:
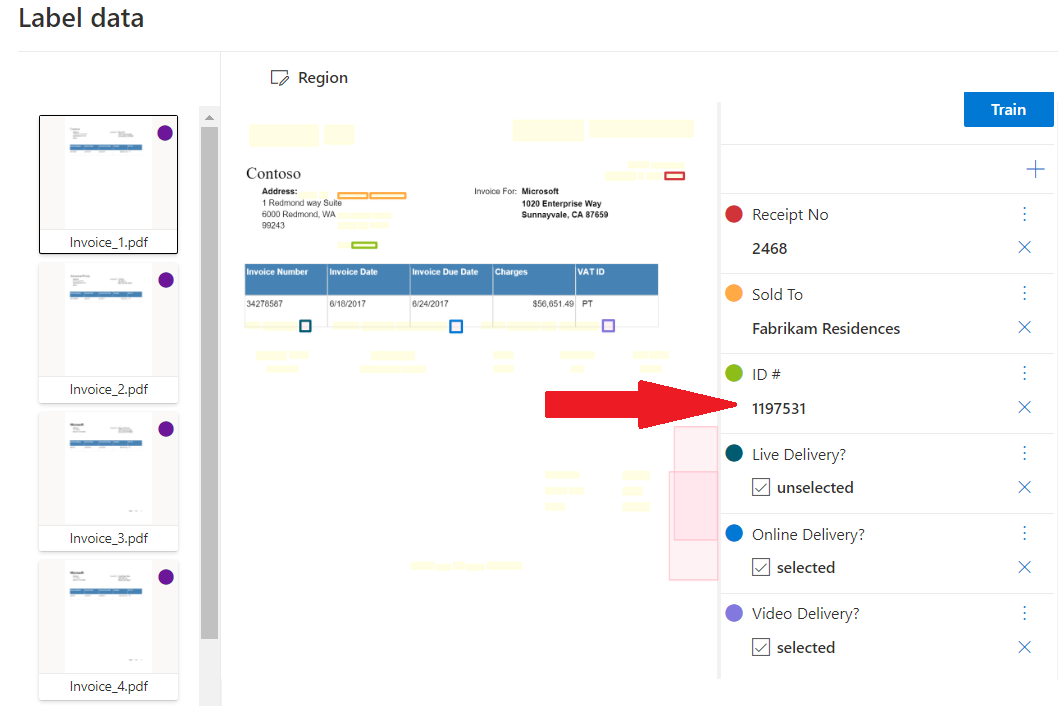
Настраиваемая функция извлечения

Пользовательская модель извлечения может быть одной из двух типов, пользовательского шаблона или пользовательского нейронного. Чтобы создать пользовательскую модель извлечения, наклейте набор данных документов со значениями, которые требуется извлечь и обучить модель в помеченном наборе данных. Для начала работы вам потребуется всего пять примеров формы или документа одного типа.
Пример пользовательского извлечения, обработанный с помощью Document Intelligence Studio:

Настраиваемый классификатор

Пользовательская модель классификации позволяет определить тип документа перед вызовом модели извлечения. Модель классификации доступна начиная с 2023-07-31 (GA) API. Для обучения пользовательской модели классификации требуется по крайней мере два отдельных класса и не менее пяти выборок для каждого класса.
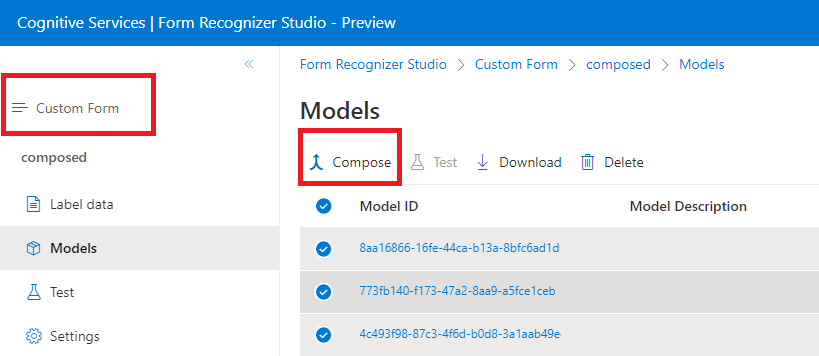
Составные модели
Составная модель создается на основе коллекции настраиваемых моделей, которые назначаются одной модели, созданной из ваших типов форм. Вы можете назначить несколько пользовательских моделей составной модели с одним идентификатором модели. Вы можете назначить до 200 обученных пользовательских моделей одной составной модели.
Диалоговое окно создания модели в Document Intelligence Studio:
Требования к входным данным
Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Поддерживаемые форматы файлов:
Модель PDF Изображение:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) и HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-02-29-preview) В файлах формата PDF и TIFF обрабатывается до 2000 страниц (с подпиской уровня "Бесплатный" обрабатываются только первые две страницы).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ бесплатного уровня (F0).
Изображения должны иметь размеры в пределах от 50 x 50 до 10 000 x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту о
8точке в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и 1G-МБ для нейронной модели.
Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1GBне более 10 000 страниц.
Примечание.
Пример средства маркировки данных не поддерживает файлы в формате BMP. Это ограничение средства, а не службы аналитики документов.
Миграция между версиями
Узнайте, как использовать аналитику документов версии 3.0 в приложениях, следуя руководству по миграции с помощью аналитики документов версии 3.1
| Модель | Description |
|---|---|
| Анализ документов | |
| Макет | Извлечение текста и сведений о макете из документов. |
| Предварительно созданная | |
| Счет-фактура | Извлечение ключевых данных из счетов на английском и испанском языках. |
| Получения | Извлечение ключевых данных из квитанций на английском языке. |
| Удостоверение | Извлечение ключевых данных из американских водительских прав и заграничных паспортов. |
| Визитная карточка | Извлечение ключевых данных из визитных карточек на английском языке. |
| Пользовательское | |
| Пользовательское | Извлечение данных из форм и документов, относящихся к вашему бизнесу. Настраиваемые модели обучаются именно для ваших данных и вариантов использования. |
| Составленная | Создание коллекции настраиваемых моделей и назначение их одной модели, созданной на основе типов форм. |
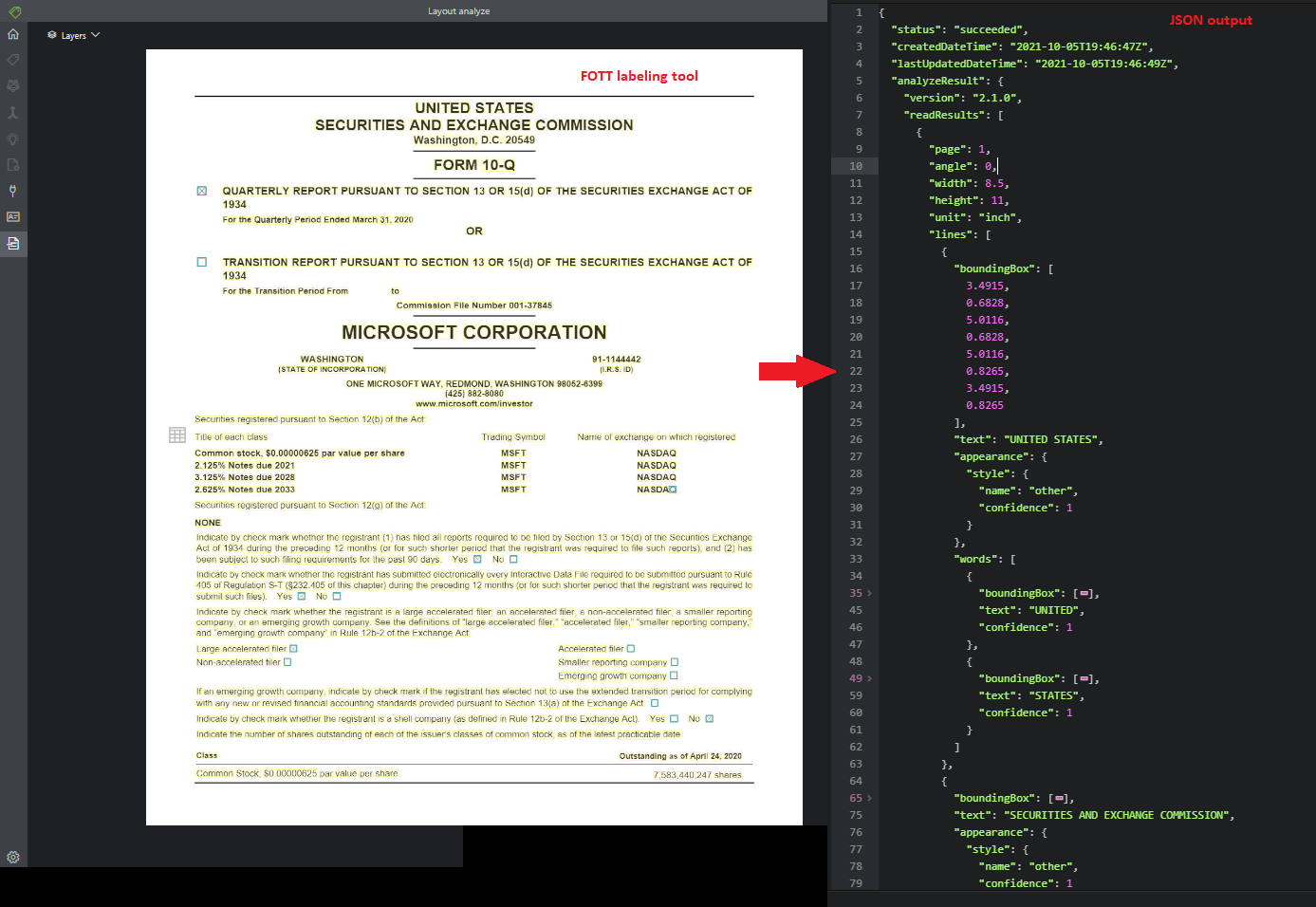
Макет
API макета анализирует и извлекает из документов текст, таблицы и заголовки, метки выделения и сведения о структуре.
Пример документа, обработанный с помощью средства маркировки образца:
Счет
Модель счета анализирует и извлекает ключевые сведения из счетов продажи. Этот API анализирует счета в различных форматах и извлекает ключевые сведения (например, имя заказчика, адрес выставления счета, дату и сумму оплаты).
Пример счета, обработанный с помощью средства маркировки образца:
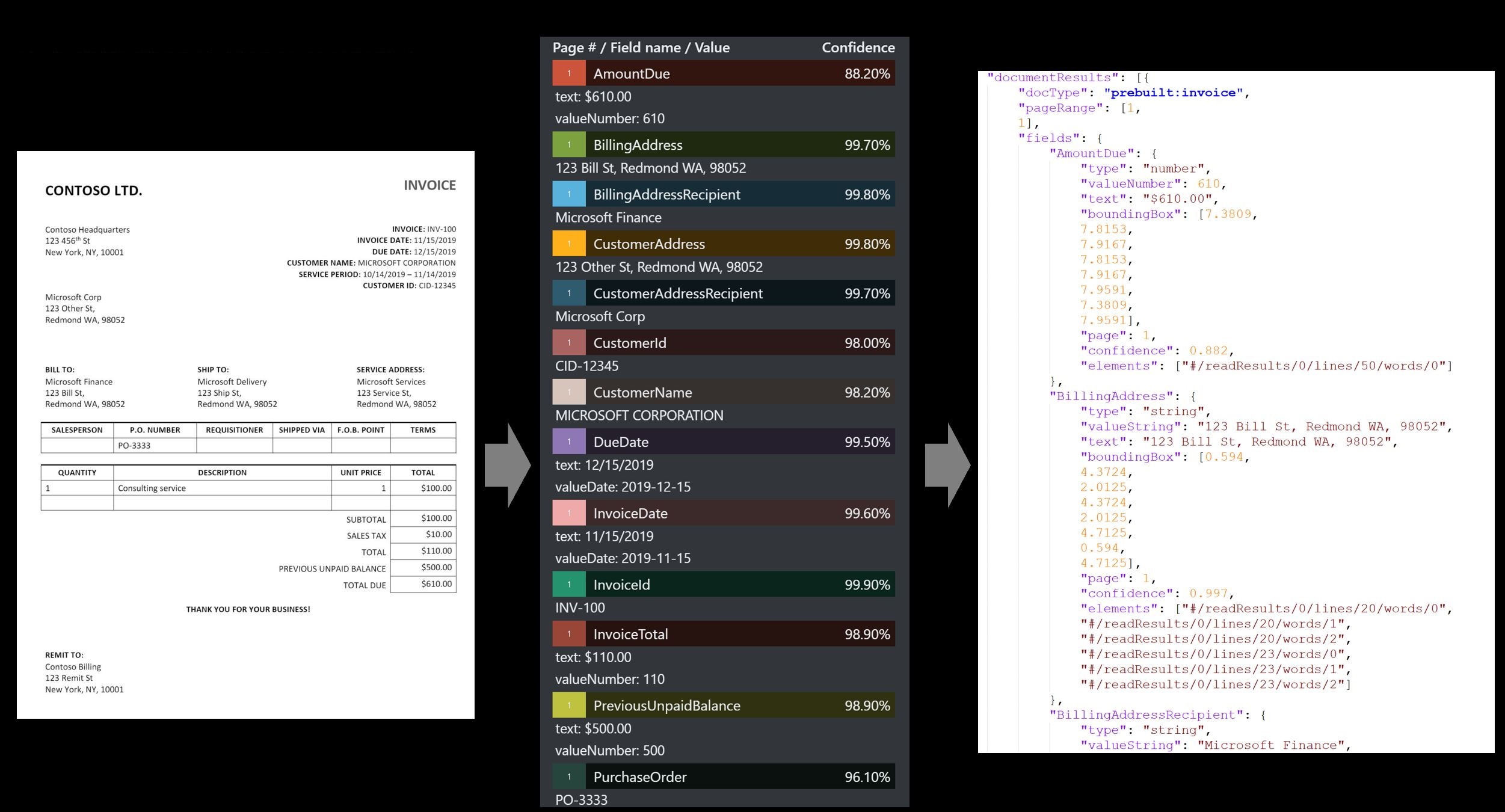
Получение
- Модель квитанции анализирует и извлекает ключевые данные из печатных и рукописных чеков.
Пример квитанции, обработанный с помощью средства маркировки примера:
Удостоверение
Модель удостоверения анализирует и извлекает ключевые данные из следующих документов:
Водительское удостоверение США (все 50 штатов и округ Колумбия)
Страницы с биографическими данными из международных паспортов (за исключением виз и других выездных документов). Этот API анализирует удостоверяющие документы и извлекает
Пример лицензии драйвера США, обработанный с помощью средства маркировки примера:
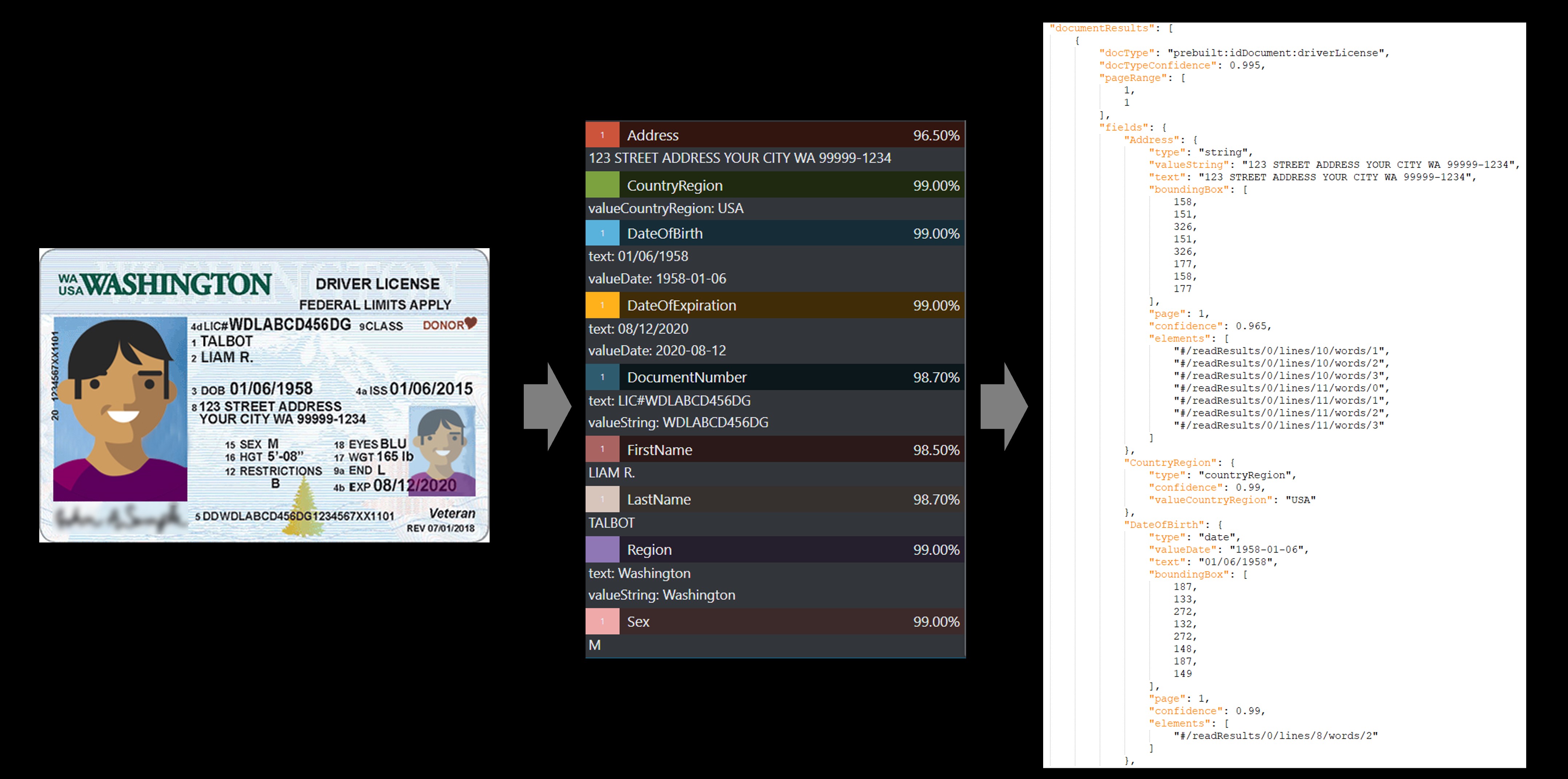
Визитная карточка
Модель визитной карточки анализирует и извлекает ключевые данные с изображений визитных карточек.
Пример бизнес-карта обработан с помощью средства маркировки примеров:
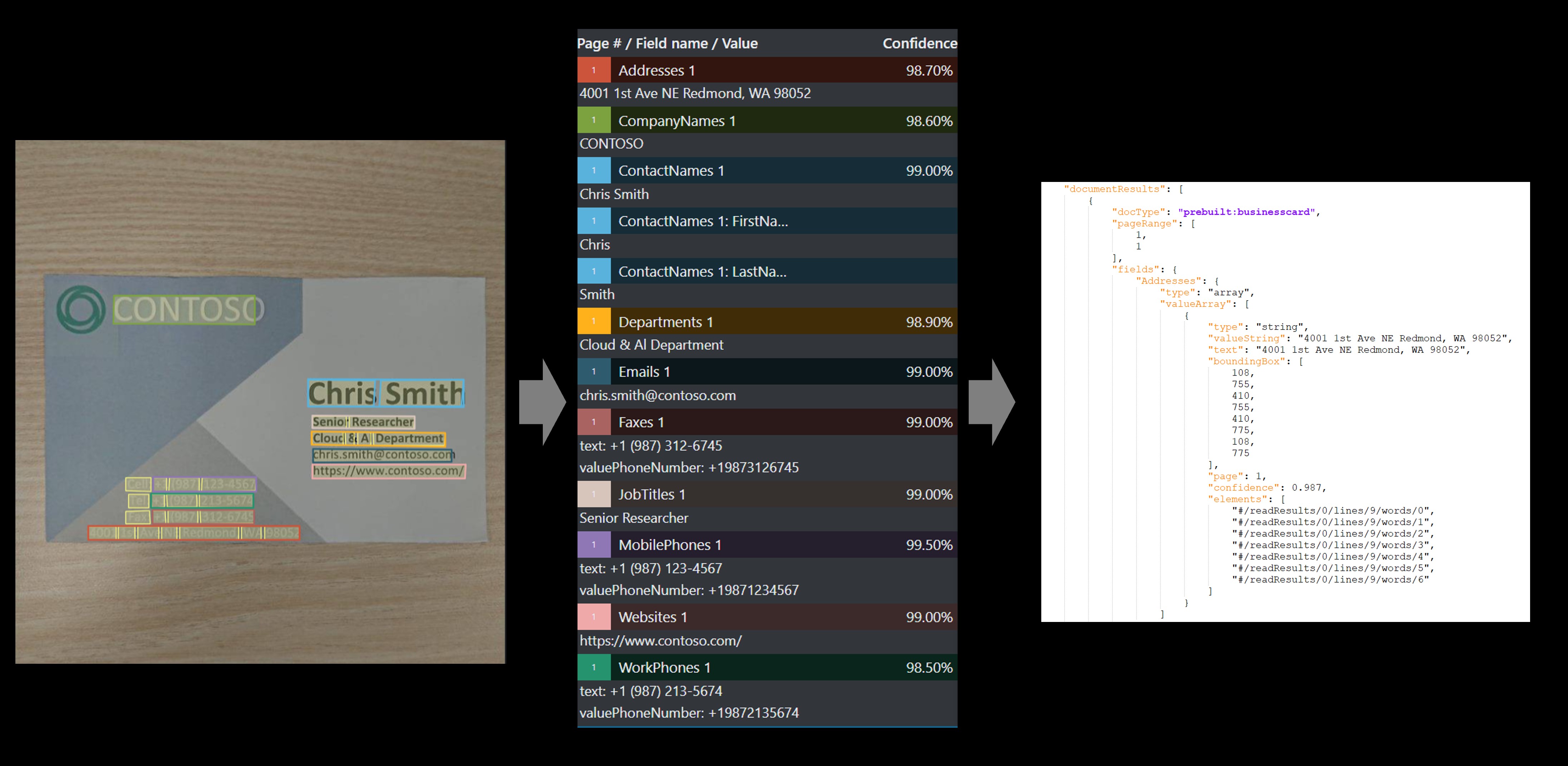
Пользовательское
- Пользовательские модели анализируют и извлекают данные из форм и документов, характерных для вашей компании. API — это программа машинного обучения, обученная для распознавания полей форм в определенном содержимом, а также извлечения пар "ключ-значение" и данных таблиц. Для начала работы необходимо лишь пять примеров одного типа формы, и настраиваемую модель можно обучить на наборах данных с метками или без таких наборов данных.
Пример пользовательской обработки модели с помощью средства маркировки примеров:
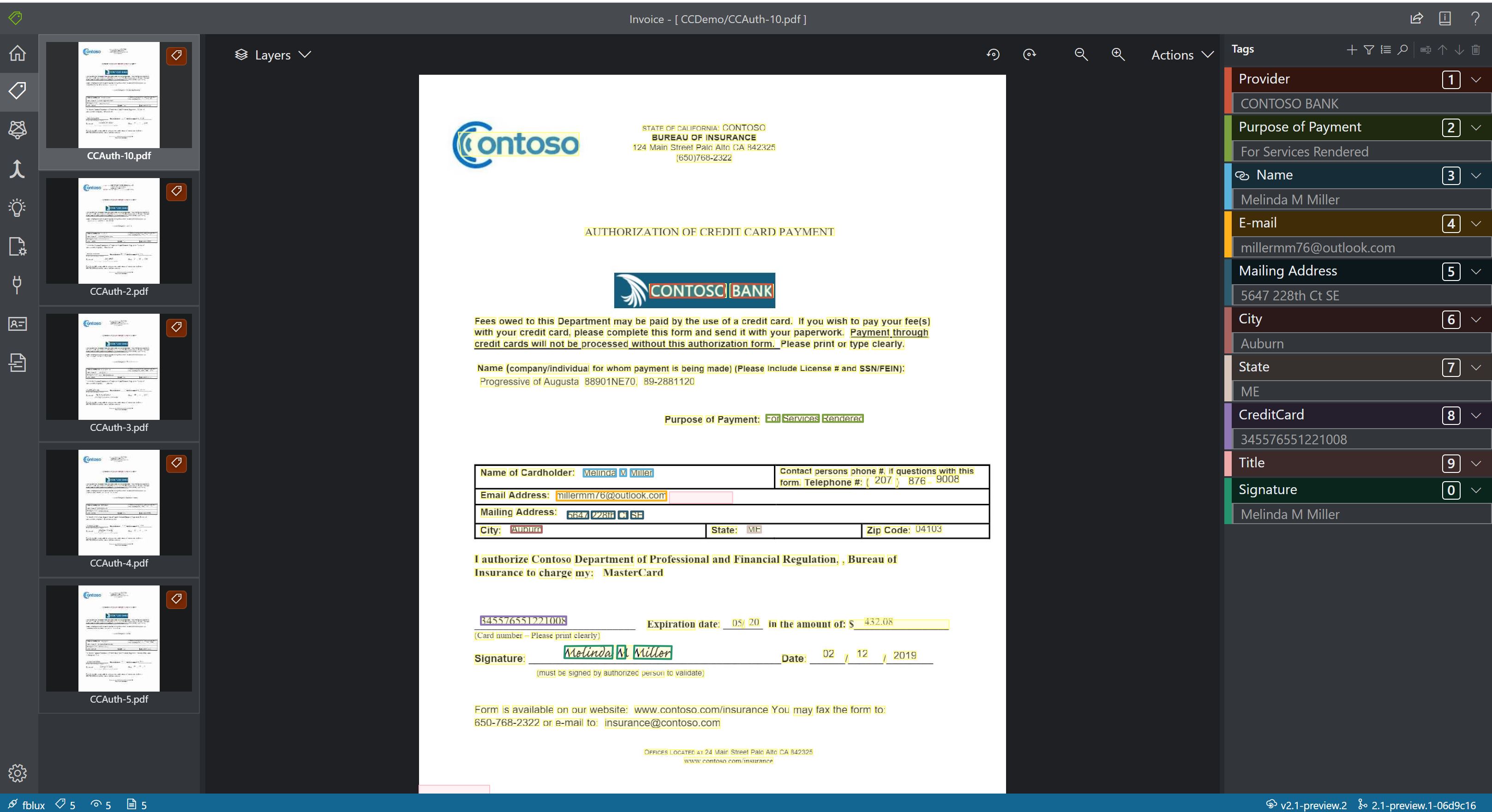
Составная настраиваемая модель
Составная модель создается на основе коллекции настраиваемых моделей, которые назначаются одной модели, созданной из ваших типов форм. Вы можете назначить несколько пользовательских моделей составной модели с одним идентификатором модели. Вы можете назначить для одной составной модели до 100 обученных настраиваемых моделей.
Диалоговое окно создания модели с помощью средства маркировки примера:
Извлечение данных модели
| Модель | Извлечение текста | Распознавание языка | Метки выделения | Таблицы | Пунктах | Роли абзаца | Пары "ключ-значение" | Поля |
|---|---|---|---|---|---|---|---|---|
| Макет | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Счет-фактура | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Получения | ✓ | ✓ | ✓ | |||||
| Удостоверение | ✓ | ✓ | ✓ | |||||
| Визитная карточка | ✓ | ✓ | ✓ | |||||
| Настраиваемая форма | ✓ | ✓ | ✓ | ✓ | ✓ |
Требования к входным данным
Для получения наилучших результатов предоставьте одну четкую фотографию или скан-копию документа высокого качества.
Поддерживаемые форматы файлов:
Модель PDF Изображение:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) и HTMLЧитать ✔ ✔ ✔ Макет ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Документ общего назначения ✔ ✔ Готовое ✔ ✔ Настраиваемая функция извлечения ✔ ✔ Настраиваемая классификация ✔ ✔ ✔ (2024-02-29-preview) В файлах формата PDF и TIFF обрабатывается до 2000 страниц (с подпиской уровня "Бесплатный" обрабатываются только первые две страницы).
Размер файла для анализа документов составляет 500 МБ для платного уровня (S0) и 4 МБ бесплатного уровня (F0).
Изображения должны иметь размеры в пределах от 50 x 50 до 10 000 x 10 000 пикселей.
Если PDF-файлы заблокированы паролем, перед отправкой необходимо снять блокировку.
Минимальная высота извлекаемого текста составляет 12 пикселей для изображения размером 1024 x 768 пикселей. Это измерение соответствует тексту о
8точке в 150 точек на дюйм (DPI).Для обучения пользовательской модели максимальный объем обучающих данных составляет 500 страниц для пользовательской модели шаблона и 50 000 страниц для пользовательской нейронной модели.
Для обучения пользовательской модели извлечения общий размер обучающих данных составляет 50 МБ для модели шаблона и 1G-МБ для нейронной модели.
Для обучения пользовательской модели классификации общий размер обучающих данных составляет
1GBне более 10 000 страниц.
Примечание.
Пример средства маркировки данных не поддерживает файлы в формате BMP. Это ограничение средства, а не службы аналитики документов.
Миграция между версиями
Вы можете узнать, как использовать аналитику документов версии 3.0 в приложениях, следуя руководству по миграции с помощью аналитики документов версии 3.1.
Следующие шаги
Попробуйте обработать собственные формы и документы с помощью Document Intelligence Studio.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.
Попробуйте обработать собственные формы и документы с помощью средства проверки меток для аналитики документов.
Выполните краткое руководство по анализу документов и начните создавать приложение для обработки документов на выбранном языке разработки.