Обучение настраиваемой модели с использованием примера средства маркировки данных
Это содержимое относится к:![]() v2.1.
v2.1.
Совет
- Для повышения качества и расширенного качества модели попробуйте в Студии аналитики документов версии 3.0.
- Студия версии 3.0 поддерживает любую модель, обученную с помощью маркированных данных версии 2.1.
- Подробные сведения о переходе с версии 2.1 на версию 3.0 см. в руководстве по миграции API.
- Чтобы приступить к работе с версией 3.0, ознакомьтесь с нашими краткими руководствами по пакетам SDK для REST API или C#, Java, JavaScript или Python.
В этой статье вы используете REST API аналитики документов с помощью средства маркировки примера для обучения пользовательской модели с данными, помеченными вручную.
Необходимые компоненты
Для выполнения этого проекта потребуются следующие ресурсы:
- Подписка Azure — создайте бесплатную учетную запись.
- После получения подписки Azure создайте ресурс аналитики документов в портал Azure, чтобы получить ключ и конечную точку. После развертывания ресурса выберите элемент Перейти к ресурсу.
- Вам потребуется ключ и конечная точка из ресурса, создаваемого для подключения приложения к API аналитики документов. Вставьте ключ и конечную точку в код далее в кратком руководстве.
- Используйте бесплатную ценовую категорию (
F0), чтобы опробовать службу, а затем выполните обновление до платного уровня для рабочей среды.
- Минимум шесть документов одного типа. Эти данные используются для обучения модели и тестирования формы. Для выполнения инструкций из этого краткого руководства можно использовать образец набора данных (скачайте и разархивируйте файл sample_data.zip). Передайте файлы для обучения в корневой каталог контейнера Хранилища BLOB-объектов в учетной записи хранения Azure со стандартным уровнем производительности.
Создание ресурса аналитики документов
Перейдите к портал Azure и создайте новый ресурс аналитики документов. На панели Создать укажите следующие сведения:
| Сведения о проекте | Description |
|---|---|
| Подписка | Выберите подписку Azure, для которой предоставлен доступ. |
| Группа ресурсов | Группа ресурсов Azure, которая содержит ваш ресурс. Вы можете создать новую группу или добавить к имеющейся группе. |
| Регион | Расположение ресурса служб ИИ Azure. Разные расположения могут увеличивать задержку, но не влияют на доступность среды выполнения ресурса. |
| Имя | Описательное имя ресурса. Рекомендуется использовать описательное имя, например Имя_распознавателя_документов. |
| Ценовая категория | Плата за ресурс будет зависеть от выбранной ценовой категории и показателей использования. Дополнительные сведения см. на странице с ценами API-интерфейсов. |
| Проверить и создать | Нажмите кнопку "Проверить и создать", чтобы развернуть ресурс на портале Azure. |
Получение ключа и конечной точки
Когда ресурс аналитики документов завершит развертывание, найдите и выберите его из списка всех ресурсов на портале. Ключ и конечная точка будут располагаться на странице Key and Endpoint (Ключ и конечная точка) ресурса в разделе Управление ресурсами. Сохраните их во временном расположении, прежде чем продолжать работу.
Попробуйте
Попробуйте использовать средство аналитики документов в Интернете:
Вам нужна подписка Azure (создайте ее бесплатно) и конечную точку ресурса аналитики документов и ключ, чтобы попробовать службу аналитики документов.
Настройка примера средства маркировки данных
Примечание.
Если данные хранилища стоят за виртуальной сетью или брандмауэром, необходимо развернуть средство аналитики документов за виртуальной сетью или брандмауэром и предоставить доступ, создав управляемое удостоверение, назначаемое системой.
Вы используете подсистему Docker для запуска средства маркировки образца. Чтобы настроить контейнер Docker, сделайте следующее. Ознакомьтесь с общими сведениями о Docker и контейнерах.
Совет
Средство маркировки документов OCR также доступно в виде проекта с открытым исходным кодом на сайте GitHub. Это средство представляет собой веб-приложение TypeScript, созданное с помощью React + Redux. Чтобы узнать больше или внести свой вклад, см. репозиторий средства маркировки документов OCR. Чтобы попробовать средство в Интернете, перейдите на веб-сайт средства аналитики документов.
Для начала установите Docker на главный компьютер. В этом руководстве показано, как использовать локальный компьютер в качестве узла. Если вы хотите использовать службу размещения Docker в Azure, ознакомьтесь с руководством Развертывание примера средства маркировки данных.
Главный компьютер должен отвечать следующим требованиям к аппаратному обеспечению.
Контейнер Минимальная конфигурация Рекомендуемая конфигурация Пример средства создания меток 2ядро, 4 ГБ памяти4ядро, 8 ГБ памятиУстановите Docker на компьютере, выполнив соответствующие инструкции для вашей операционной системы:
Получите контейнер для примера средства маркировки данных с помощью команды
docker pull.docker pull mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1Теперь все готово к тому, чтобы запустить контейнер с помощью команды
docker run.docker run -it -p 3000:80 mcr.microsoft.com/azure-cognitive-services/custom-form/labeltool:latest-2.1 eula=acceptЭта команда предоставляет средство маркировки примера через веб-браузер. Перейдите по адресу
http://localhost:3000.
Примечание.
Вы также можете пометить документы и обучать модели с помощью REST API аналитики документов. См. сведения о том, как выполнять обучение на основе меток и анализ с использованием REST API и Python.
Настройка входных данных
Для начала убедитесь, что все обучающие документы имеют одинаковый формат. Если у вас есть формы в разных форматах, рассортируйте их по вложенным папкам соответствующим образом. При обучении необходимо направить API в вложенную папку.
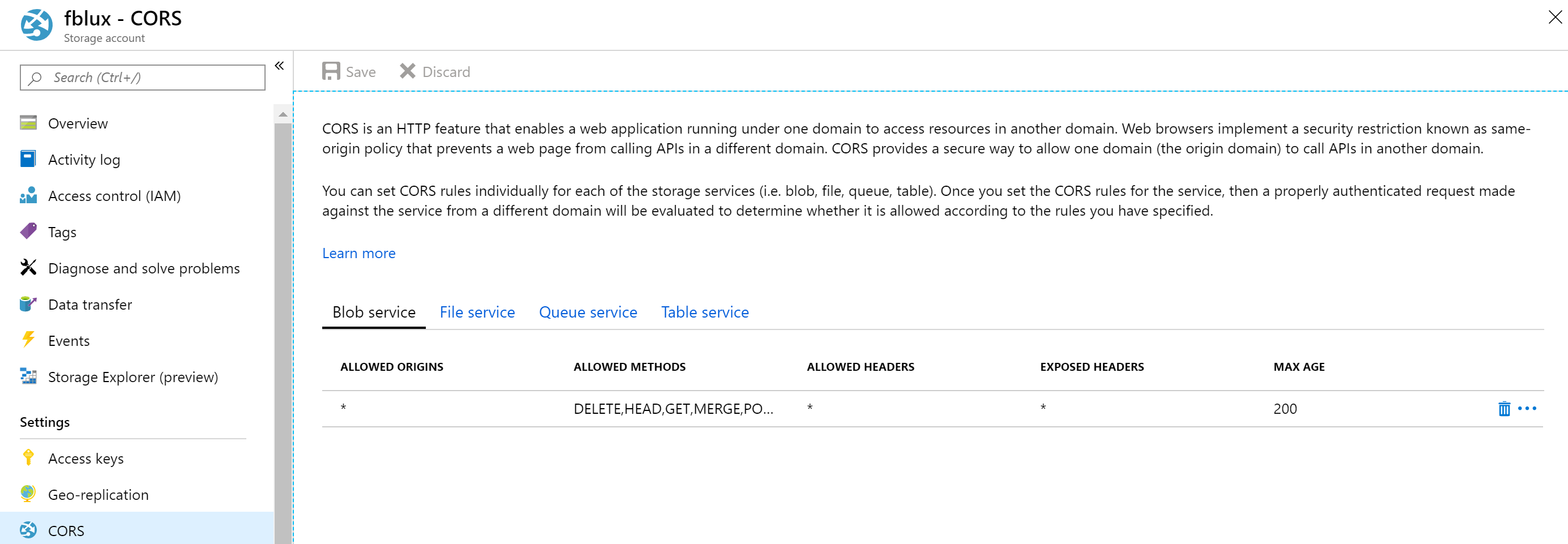
Настройка общего доступа к ресурсам независимо от источника (CORS)
Включите CORS для учетной записи хранения. Перейдите к учетной записи хранения на портале Azure и выберите вкладку CORS на панели слева. В нижней строке укажите следующие значения. Выбрать Сохранить наверху.
- Разрешенные источники = *
- Допустимые методы = [выберите все]
- Допустимые заголовки = *
- Предоставляемые заголовки = *
- Максимальный возраст = 200
Подключение к примеру средства маркировки данных
Пример средства маркировки данных подключается к источнику данных (где размещены отправленные вами формы) и к целевому объекту (где будет размещать созданные метки и выходные данные).
Подключения можно настраивать и совместно использовать для нескольких проектов. При этом используется расширяемая модель поставщика, что позволяет легко добавлять новых поставщиков источника и назначения.
Чтобы создать новое подключение, щелкните значок Новые подключения (электрическая вилка) на панели навигации слева.
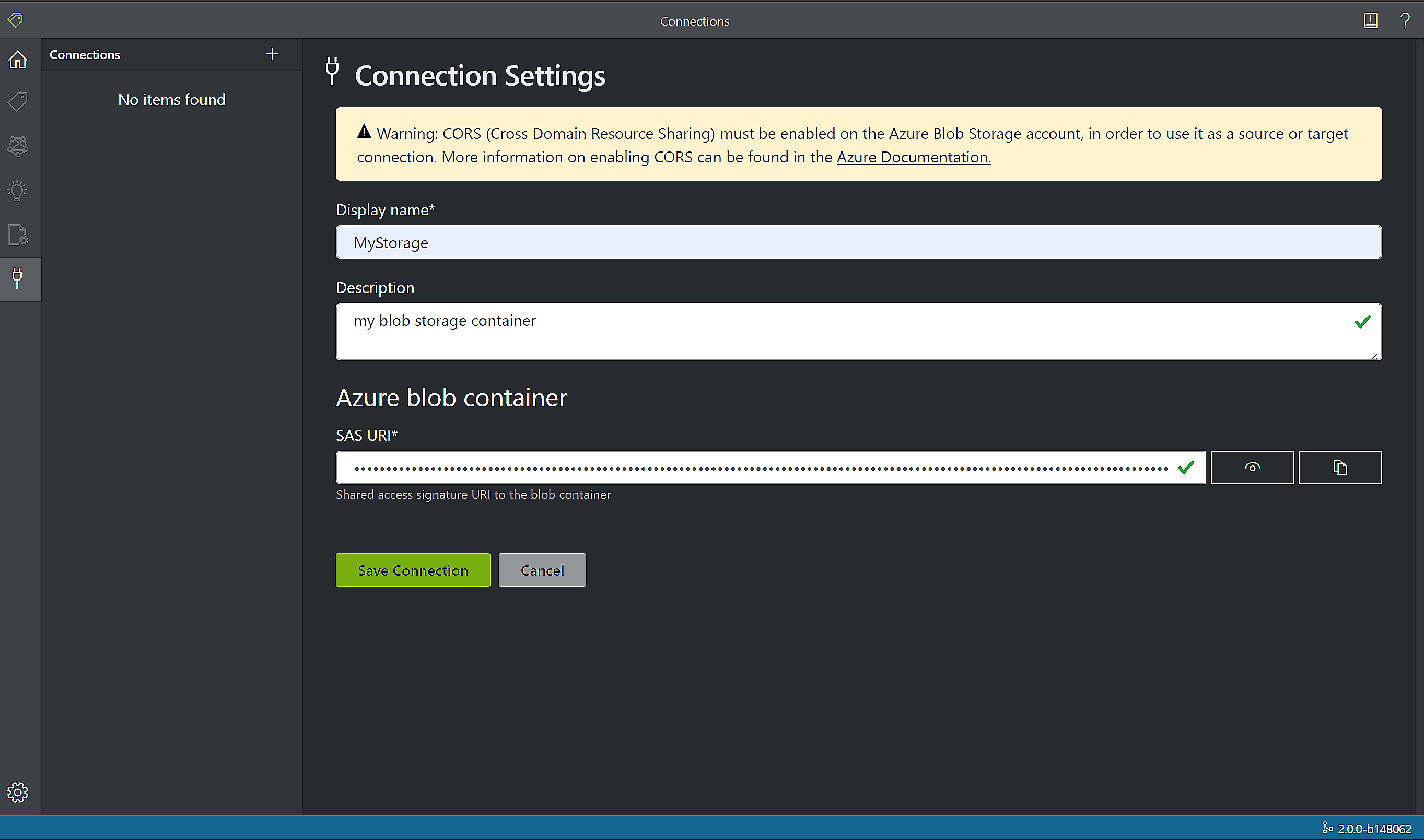
Заполните поля следующими значениями.
Отображаемое имя — имя подключения.
Описание — описание проекта.
Подписанный URL-адрес — указывает на контейнер хранилища BLOB-объектов Azure. Чтобы получить URL-адрес SAS для данных обучения пользовательской модели, перейдите к ресурсу хранилища в портал Azure и выберите вкладку Обозреватель службы хранилища. Перейдите к контейнеру, щелкните правой кнопкой мыши и выберите "Получить подписанный URL-адрес". Важно получить SAS для вашего контейнера, а не для самой учетной записи хранения. Убедитесь, что заданы разрешения на чтение, запись, удаление и перечисление, а затем щелкните Создать. Затем скопируйте во временное расположение значение из раздела URL-адрес. Оно должно быть в таком формате:
https://<storage account>.blob.core.windows.net/<container name>?<SAS value>.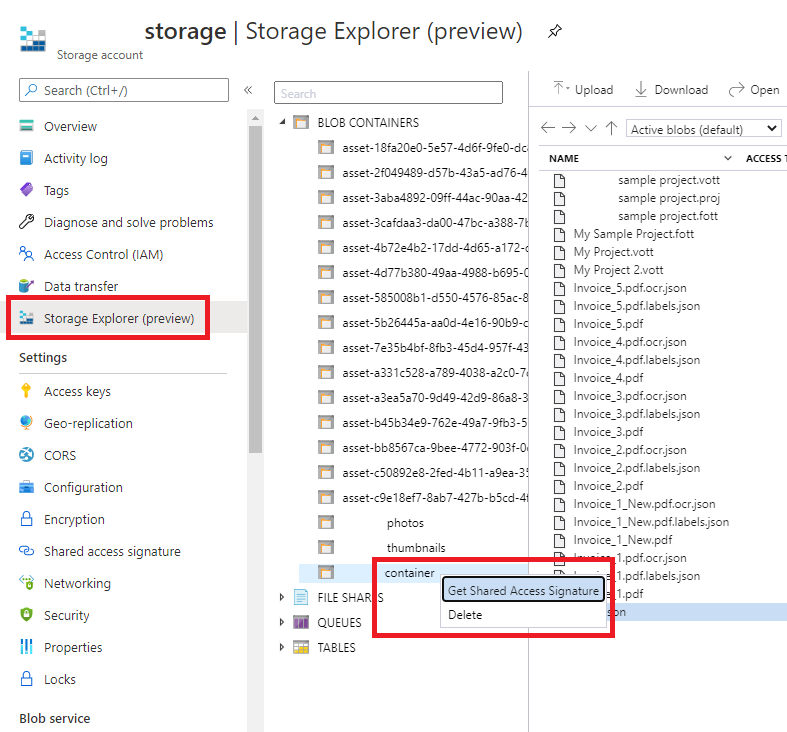
Создание нового проекта
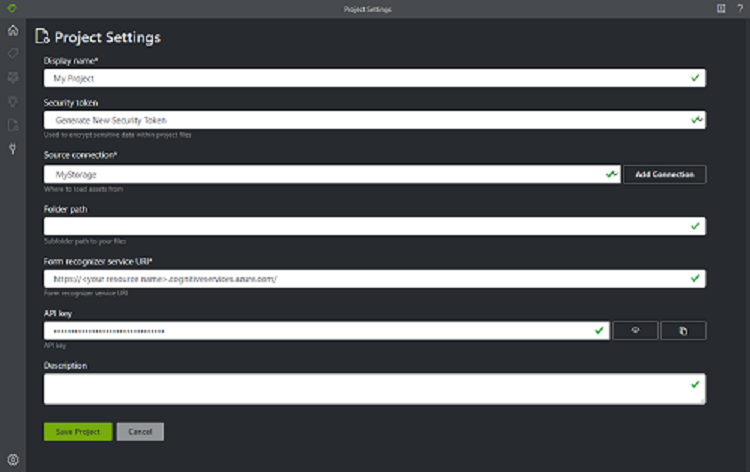
В примере средства маркировки данных конфигурации и параметры хранятся в проектах. Создайте новый проект и заполните поля следующими значениями.
- Отображаемое имя — имя проекта.
- Маркер безопасности — нужен для хранения конфиденциальных параметров проекта, таких как ключи или другие общие секреты. Каждый проект создает маркер безопасности, который можно использовать для шифрования и расшифровки параметров конфиденциальных проектов. Маркеры безопасности можно найти в разделе параметров приложения, который открывается щелчком по значку шестеренки в нижней части панели навигации слева.
- Подключение к источнику — в нашем примере это подключение к хранилищу BLOB-объектов Azure, которое вы создали на предыдущем шаге и хотите использовать для этого проекта.
- Путь к папке (необязательно) — нужен, если исходные формы находятся во вложенной папке контейнера больших двоичных объектов.
- Uri службы аналитики документов — URL-адрес конечной точки аналитики документов.
- Ключ — ключ аналитики документов.
- Описание — описание проекта (необязательно).
Создание меток для форм
При создании или открытии проекта открывается главное окно редактора тегов. Редактор тегов разделен на три сегмента.
- Область просмотра версии 3.0 с возможностью изменения размера содержит прокручиваемый список форм из подключенного источника.
- Главная панель редактора позволяет применять теги.
- Панель редактора тегов позволяет пользователям изменять, блокировать, переупорядочивать и удалять теги.
Выявление текста и таблиц
Выберите Выполнить анализ непросмотренных документов на панели слева, чтобы получить сведения о тексте и таблицах для каждого документа. Средство маркировки рисует ограничивающие прямоугольники вокруг каждого текстового элемента.
Средство маркировки также показывает, какие таблицы были извлечены автоматически. Щелкните значок таблицы или сетки в левой части документа, чтобы увидеть извлеченную таблицу. В этом кратком руководстве, так как содержимое таблицы извлекается автоматически, мы не помечаем содержимое таблицы, а не полагаться на автоматическое извлечение.
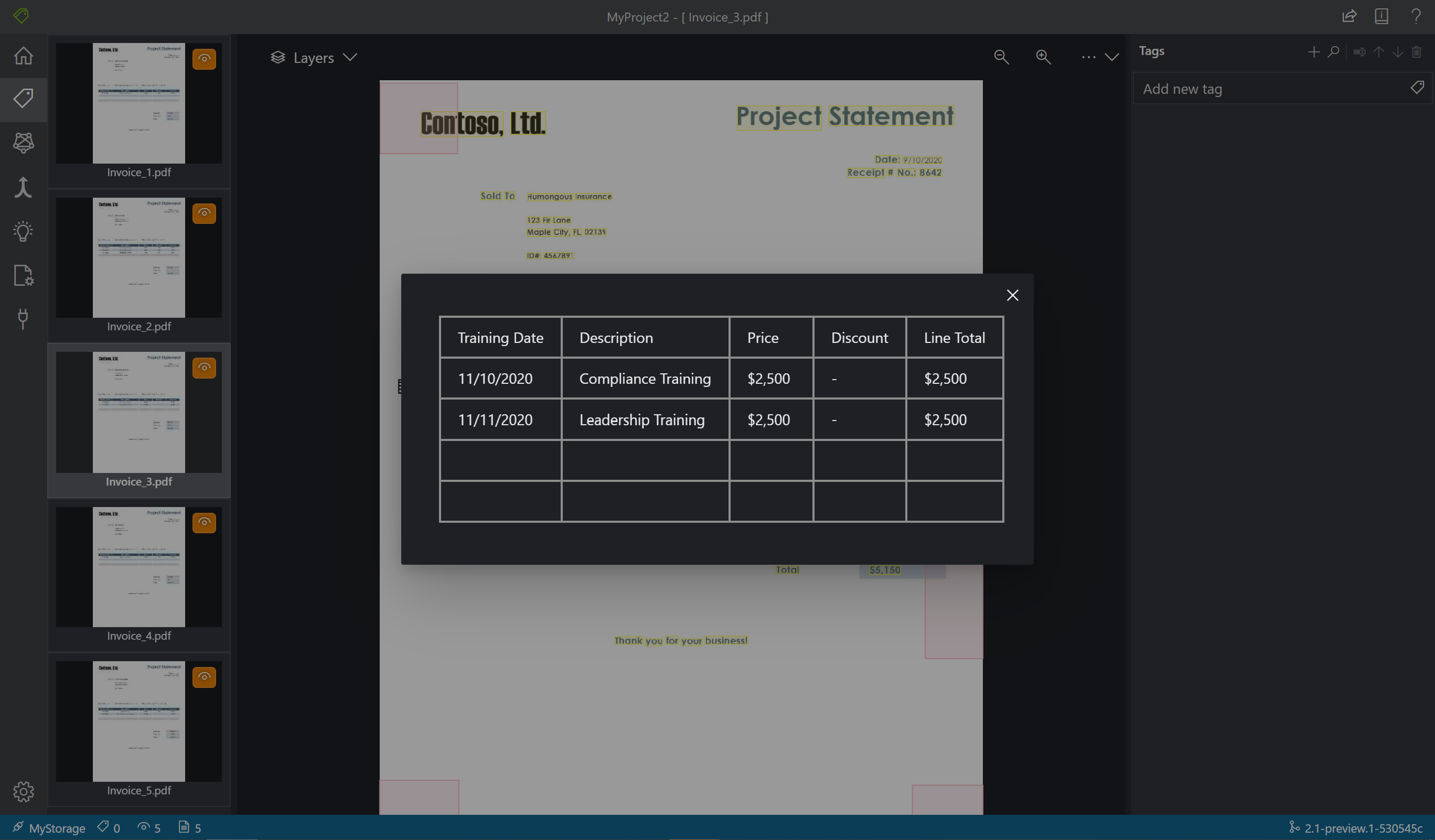
В версии 2.1, если в учебном документе нет введенного значения, вы можете прямоугольником обозначить зону, где должно находиться это значение. Используйте элемент Область рисования в левом верхнем углу окна, чтобы обозначить регион для присвоения меток.
Применение меток к тексту
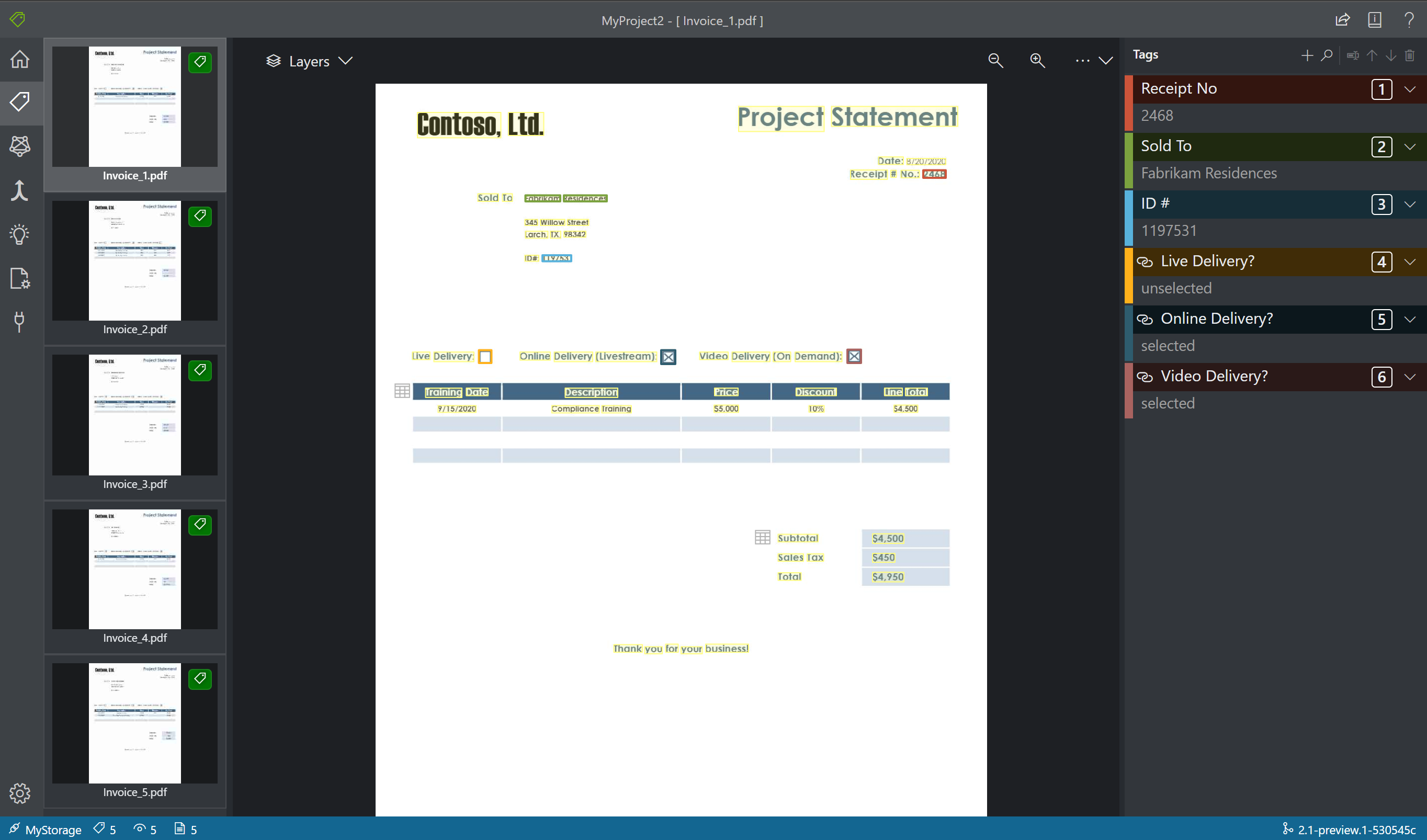
Затем вы создадите теги (метки) и примените их к текстовым элементам, которые нужно проанализировать моделью.
- Во-первых, с помощью панели редактора тегов создайте теги (метки), которые вы хотите определить.
- Щелкните +, чтобы создать новый тег.
- Введите имя тега.
- Нажмите клавишу ВВОД, чтобы сохранить тег.
- В основном редакторе выберите слова из выделенных текстовых элементов или обозначенного вами региона.
- Щелкните тег, который вы хотите применить, или нажмите соответствующую клавишу на клавиатуре. Клавиши с цифрами позволяют быстро присвоить любой из первых десяти тегов. Чтобы изменить порядок тегов, используйте значки со стрелками вверх и вниз на панели редактора тегов.
- Выполните следующие действия, чтобы пометить как минимум пять форм.
Совет
При создании меток для форм воспользуйтесь следующими советами:
- К каждому выбранному текстовому элементу можно применить только один тег.
- Каждый тег может применяться только один раз на каждую страницу. Если значение встречается несколько раз в одной и той же форме, создайте разные теги для каждого экземпляра. Например: "счет# 1", "счет# 2" и т. д.
- Теги не могут охватывать несколько страниц.
- Помечайте значения, отображаемые в форме; не пытайтесь разделить значение на две части двумя разными тегами. Например, поле адреса должно быть помечено одним тегом, даже если оно охватывает несколько строк.
- Не включайте в поля с тегами ключи — только значения.
- Данные таблицы должны обнаруживаться автоматически и будут доступны в окончательном выходном JSON-файле. Однако если модели не удается обнаружить все данные таблицы, вы можете также пометить эти поля вручную. Пометьте каждую ячейку в таблице другой меткой. Если в формах есть таблицы с разным количеством строк, обязательно пометьте по крайней мере одну форму с максимально возможной таблицей.
- Чтобы искать, переименовывать, упорядочивать и удалять теги, используйте кнопки справа от значка +.
- Чтобы снять примененный тег, не удаляя его, выберите прямоугольник с тегом в представлении документа и нажмите клавишу Delete.
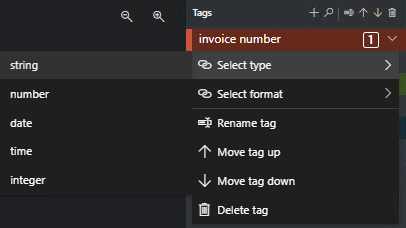
Определение типов значений тегов
Вы можете задать ожидаемый тип данных для каждого тега. Откройте контекстное меню справа от тега и выберите тип. Эта функция позволяет алгоритму обнаружения делать предположения, повышающие точность обнаружения текста. Он также гарантирует, что обнаруженные значения возвращаются в стандартизованном формате в окончательных выходных данных JSON. Сведения о типе значения сохраняются в файле fields.json по тому же пути, что и файлы меток.
Сейчас поддерживаются следующие типы и разновидности значений:
stringno-whitespaces,alphanumeric(по умолчанию);
numbercurrency(по умолчанию);- Отформатировано как значение с плавающей запятой.
- Пример: 1234.98 в документе форматируется в 1234.98 в выходных данных
datedmy,mdy,ymd(по умолчанию).
timeinteger- Отформатировано как целое значение.
- Пример: 1234.98 в документе форматируется в 123498 выходных данных.
selectionMark
Примечание.
См. следующие правила форматирования даты:
Чтобы форматирование даты работало, необходимо указать формат (dmy, mdy, ymd).
В качестве разделителей даты можно использовать следующие символы: , - / . \. Пробелы нельзя использовать в качестве разделителя. Например:
- 01,01,2020
- 01-01-2020
- 01/01/2020
День и месяц могут быть записаны одной или двумя цифрами, а год может быть двух- или четырехзначным:
- 1-1-2020
- 1-01-20
Если строка даты состоит из восьми цифр, разделитель необязателен:
- 01012020
- 01 01 2020
Месяц также может быть записан как его полное или сокращенное название. Если используется название, символы-разделители необязательны. Однако этот формат может распознаваться менее точно, чем другие.
- 01/янв/2020
- 01янв2020
- 01 янв 2020
Таблицы меток (только в версии 2.1)
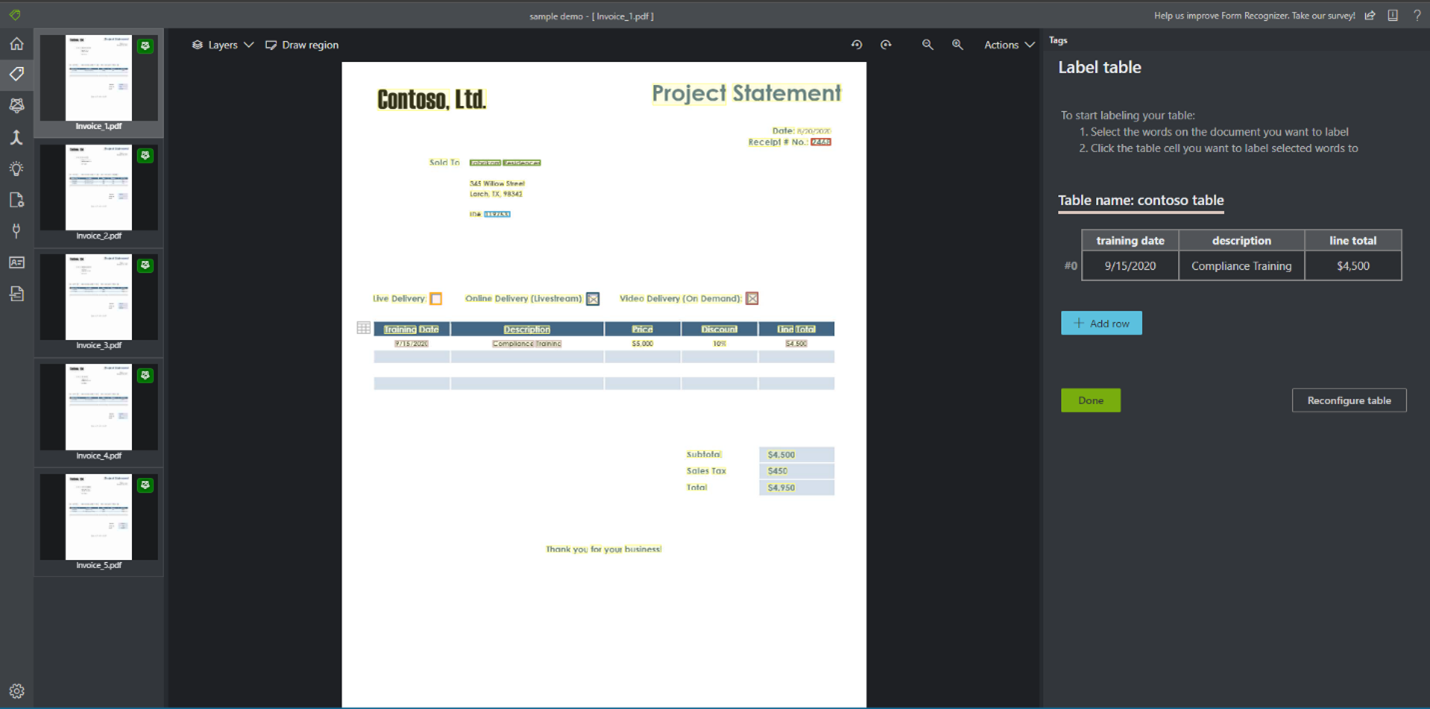
Иногда лучше обозначить блок данных как таблицу, а не отдельные пары "ключ — значение". В этом случае можно создать тег таблицы, выбрав Добавить тег таблицы. Укажите, имеет ли таблица фиксированное количество строк или переменное число строк в зависимости от документа и определите схему.
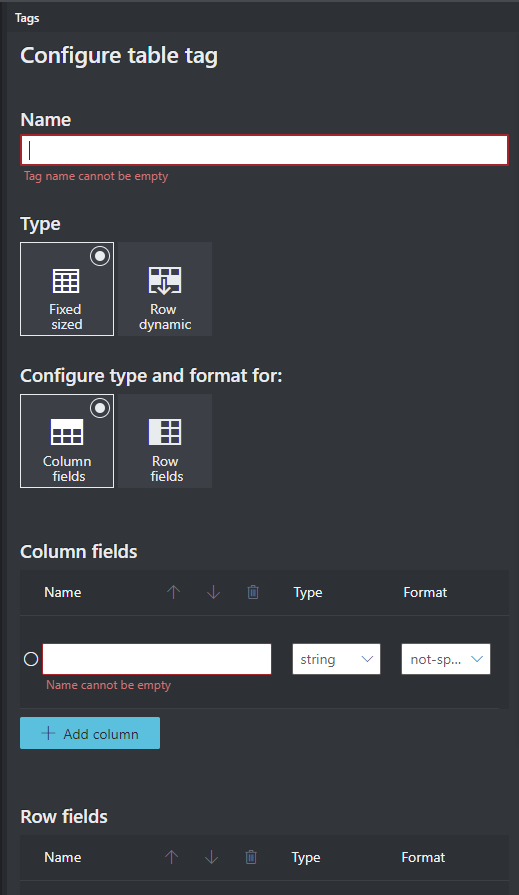
Определив тег для таблицы, перейдите к присвоению тегов значениям в ячейках.
обучение пользовательской модели;
Щелкните значок обучения на панели слева, чтобы открыть страницу "Обучение". Затем нажмите кнопку Обучение, чтобы начать обучение модели. После завершения процесса обучения вы увидите следующие сведения:
- Идентификатор модели, которую вы создали и обучили. Каждый вызов обучения создает новую модель с уникальным идентификатором. Скопируйте эту строку в безопасное расположение; Вам потребуется, если вы хотите выполнять вызовы прогнозирования с помощью REST API или клиентской библиотеки.
- Средняя точность, как характеристика точности модели. Точность моделей можно улучшить, присвоив метки большему числу форм и повторно выполнив обучение, чтобы создать новую модель. Мы рекомендуем для начала создать метки для пяти форм и добавлять новые формы по мере необходимости.
- Список тегов и оценка точности для каждого из них.
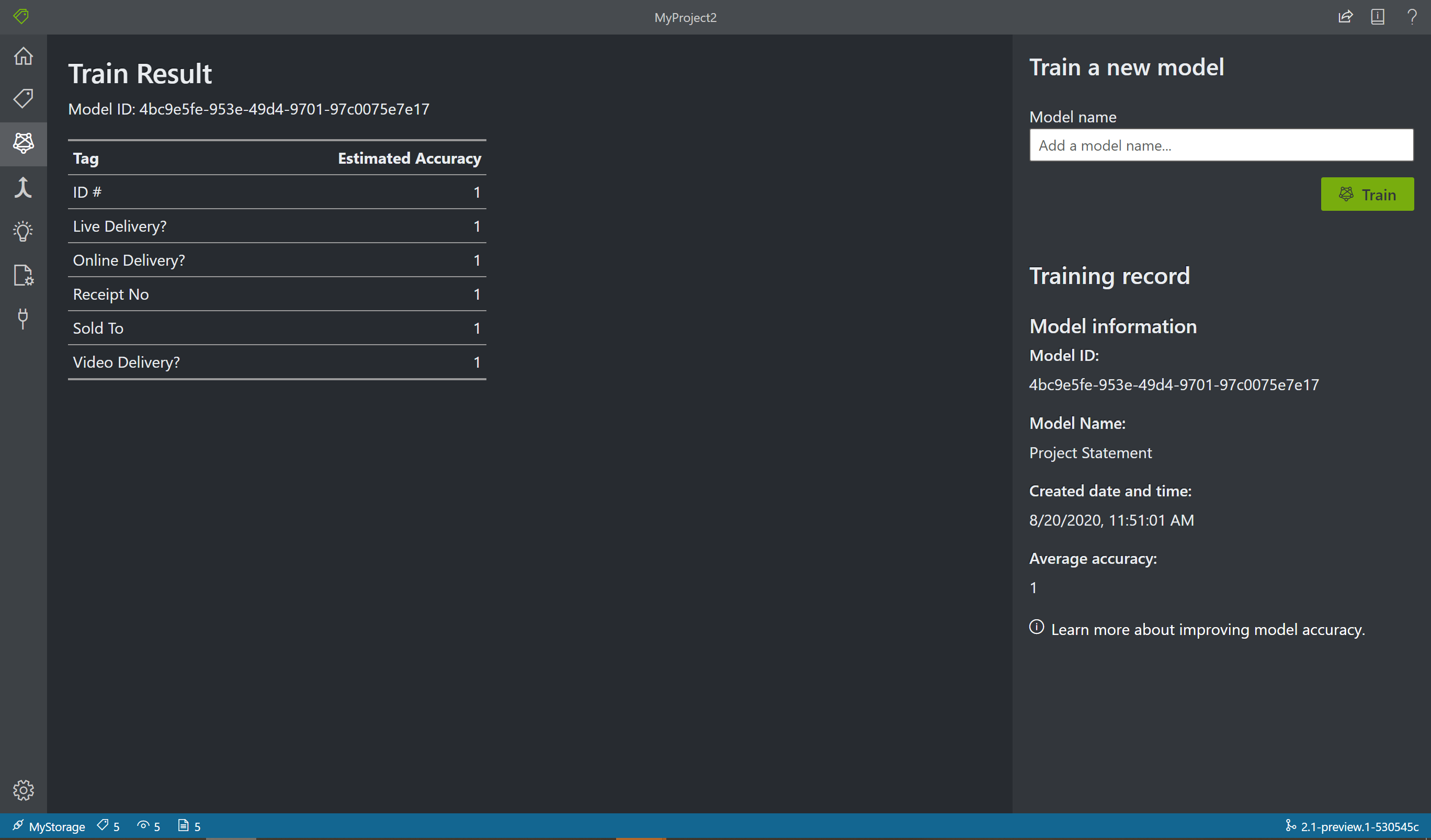
Когда обучение завершится, оцените значение средней точности. Если это низко, необходимо добавить дополнительные входные документы и повторить действия по маркировке. Документы, которые вы уже помечены, остаются в индексе проекта.
Совет
Вы также можете выполнить процесс обучения, используя вызов REST API. Узнать, как это сделать, можно в разделе Обучение с помощью меток и Python.
Создание обученных моделей
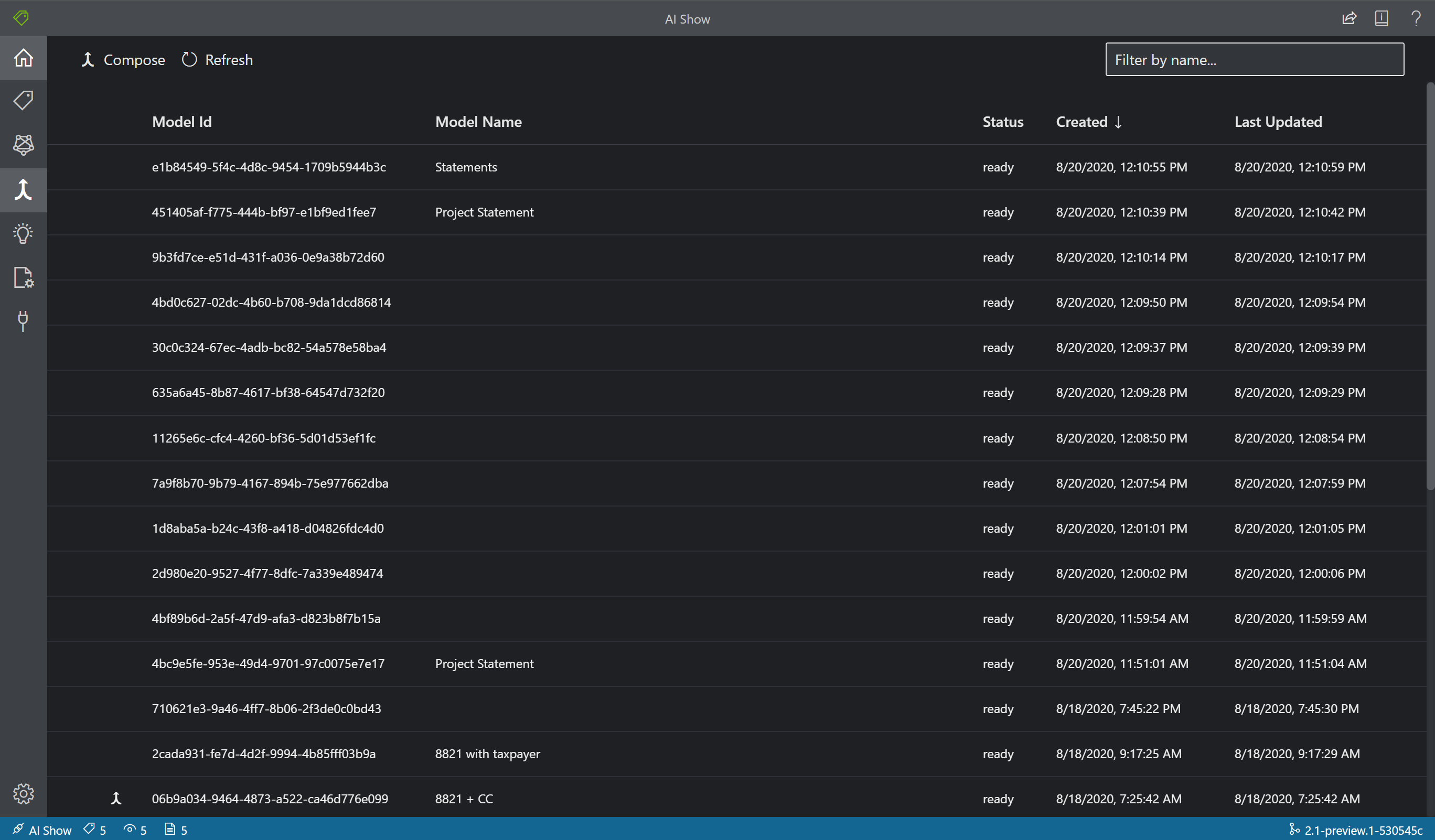
С помощью Model Compose можно создавать до 200 моделей с одним идентификатором модели. При вызове анализа с помощью составленного modelIDдокумента аналитика документов классифицирует отправленную форму, выберите лучшую модель сопоставления, а затем возвращает результаты для этой модели. Это очень удобная операция, если входящие документы могут относиться к одному из нескольких шаблонов.
- Чтобы создать модели в средстве создания меток образца, выберите значок "Создание модели" (стрелка слияния) на панели навигации.
- Выберите модели, которые вы хотите создать вместе. Модели со значком со стрелками уже являются составными моделями.
- Нажмите кнопку Создать. Во всплывающем окне присвойте имя новой составленной модели и щелкните Составить.
- После завершения операции новая модель появится в списке.
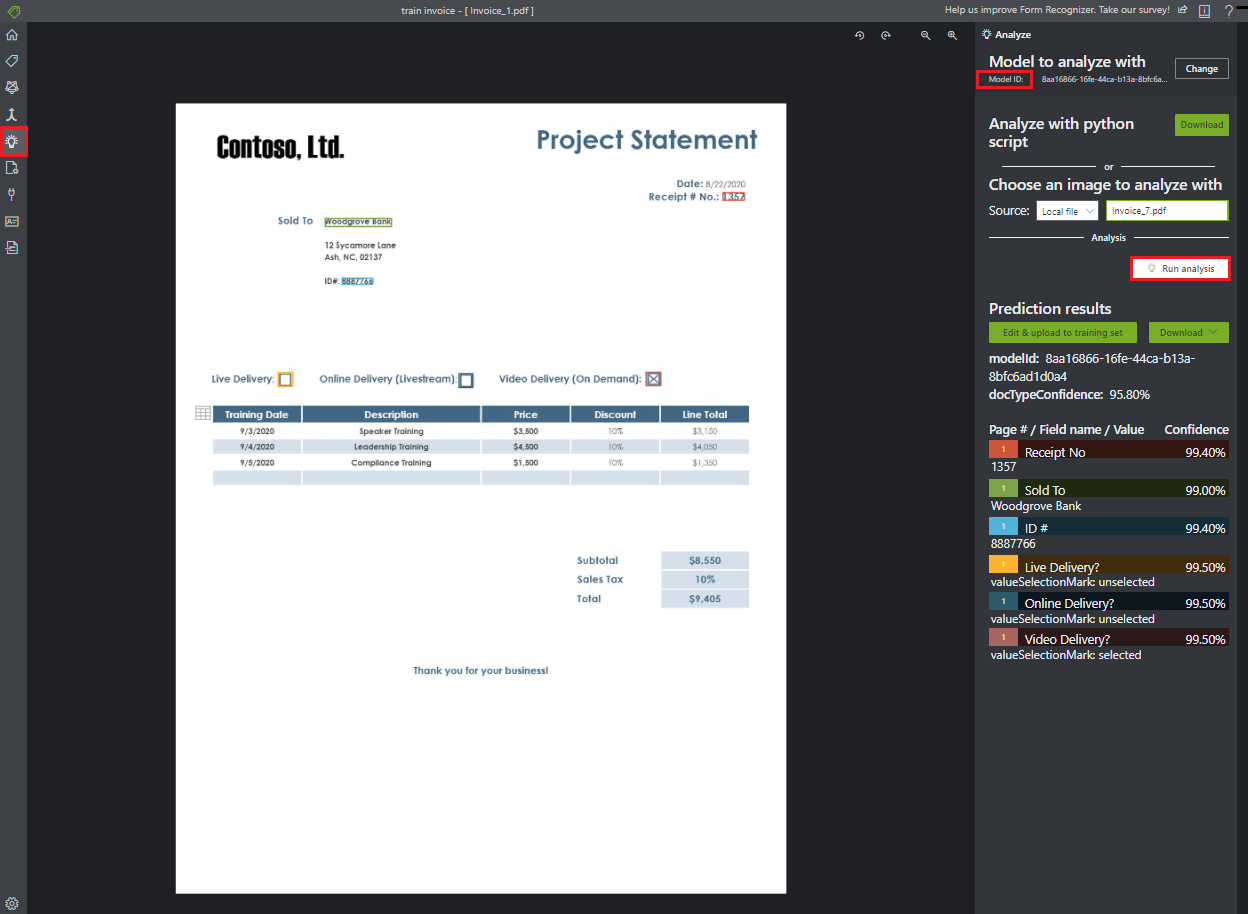
Анализ формы
Щелкните значок "Анализ" на панели навигации, чтобы протестировать модель. Выберите исходный локальный файл. Найдите и выберите файл из примера набора данных, который вы ранее распаковали в тестовую папку. Теперь нажмите кнопку Run analysis (Выполнить анализ), чтобы получить пары "ключ-значение", прогнозы текста и таблиц для документа. Средство применяет теги в ограничивающих полях и сообщает о достоверности каждого тега.
Совет
Вы также можете обратиться к API анализа, используя вызов REST. Узнать, как это сделать, можно в разделе Обучение с помощью меток и Python.
Улучшение результатов
В зависимости от оценки точности может потребоваться дополнительное обучение для улучшения модели. Завершив прогнозирование, проверьте значения достоверности для каждого из примененных тегов. Если среднее значение точности при обучении было велико, но вы получаете низкие оценки достоверности или неточные результаты, добавьте в учебный набор выбранный для прогнозирования файл, присвойте ему метки и выполните обучение еще раз.
Показатели средней точности, оценки достоверности и фактической точности могут быть нестабильными, если анализируемые документы отличаются от тех, которые использовались для обучения. Не забывайте, что некоторые документы выглядят одинаковыми для людей, но при этом отличаются для моделей ИИ. Например, если ваша форма имеет два варианта оформления и в наборе для обучения использовалось 20 % варианта А и 80 % варианта Б, на этапе прогнозирования оценки достоверности для документов варианта А будут, скорее всего, ниже.
Сохранение и возобновление проекта
Чтобы возобновить проект в другое время или в другом браузере, вам нужно сохранить маркер безопасности этого проекта и повторно ввести его позже.
Получение учетных данных проекта
Перейдите на страницу параметров проекта (значок ползунка) и запишите имя маркера безопасности. Теперь перейдите к параметрам приложения (значок шестеренки), где отображаются все маркеры безопасности в текущем экземпляре браузера. Найдите маркер безопасности нужного проекта, а затем скопируйте и сохраните его имя и значение ключа в безопасном расположении.
Восстановление учетных данных проекта
Если вы хотите возобновить проект, создайте подключение к тому же контейнеру хранилища BLOB-объектов. Для этого повторите шаги. Затем перейдите на страницу параметров приложения (значок шестеренки) и проверьте, есть ли там маркер безопасности нужного проекта. Если его нет, добавьте новый маркер безопасности и скопируйте в него имя и ключ из предыдущего шага. Щелкните Сохранить, чтобы сохранить параметры.
Возобновление проекта
Наконец, перейдите на главную страницу (значок дома) и щелкните Открыть облачный проект. Затем выберите подключение к хранилищу BLOB-объектов и выберите файл проекта .fott . Приложение загружает все параметры проекта, так как он имеет маркер безопасности.
Следующие шаги
В этом кратком руководстве вы узнали, как использовать средство создания меток для аналитики документов для обучения модели с данными, помеченными вручную. Если вы хотите создать собственную служебную программу для присвоения меток, воспользуйтесь REST API, предназначенными для обучения с использованием данных с метками.