Распределенные приложения и службы, работающие в облаке, по своей природе представляют собой сложные программные компоненты, состоящие из множества частей. В рабочей среде важно иметь возможность отслеживать, как именно пользователи работают с вашей системой, следить за использованием ресурсов и отслеживать общую работоспособность и производительность системы. Эту диагностическую информацию можно использовать, чтобы упростить обнаружение и устранение проблем, а также выявлять потенциальные проблемы и предотвращать их возникновение.
Сценарии мониторинга и диагностики
Мониторинг позволяет лучше понять, насколько хорошо работает система, является одной из важнейших составляющих процесса обеспечения должного качества обслуживания. К наиболее распространенным сценариям сбора данных мониторинга относятся следующие.
- Поддержание работоспособности системы.
- Отслеживание доступности системы и элементов ее компонентов.
- Поддержание определенного уровня производительности, чтобы гарантировать отсутствие резкого снижения пропускной способности системы при возрастании объема работы.
- Обеспечение соответствия системы всем соглашениям об уровне обслуживания, заключенным с клиентами.
- Защита конфиденциальности и безопасности системы, ее пользователей и их данных.
- Отслеживание операций, выполняемых в целях аудита или обеспечения соответствия нормативным требованиям.
- Мониторинг повседневного использования системы помогает выявлять тенденции, которые при отсутствии своевременных мер могут привести к проблемам.
- Отслеживание возникающих проблем в рамках всего цикла — от исходного отчета до анализа возможных причин, корректировки, последующего обновления программного обеспечения и развертывания.
- Трассировка операций и отладка выпусков программного обеспечения.
Примечание.
Этот список не является исчерпывающим. Этот документ посвящен именно этим сценариям, поскольку они отражают наиболее распространенные ситуации с мониторингом, однако могут существовать и другие сценарии, которые меньше распространены либо характерны именно для вашей среды.
В следующих разделах данные сценарии описаны более подробно. Информация по каждому сценарию приводится в следующем формате.
- Краткий обзор сценария.
- Типовые требования для этого сценария.
- Необработанные данные инструментирования, необходимые для поддержки этого сценария, и возможные источники таких данных.
- Способы анализа и объединения этих данных для получения полезной диагностической информации.
Мониторинг работоспособности
Система является работоспособной, если она выполняется и может обрабатывать запросы. Мониторинг работоспособности предназначен для создания моментального снимка текущего состояния работоспособности системы, чтобы можно было проверить правильность работы всех компонентов системы.
Требования для мониторинга работоспособности
В случае если любая часть системы считается неработоспособной, необходимо быстро (в течение нескольких секунд) оповестить об этом оператора. Оператор должен иметь возможность определить, какие части системы работают нормально, а в каких частях возникают неполадки. Работоспособность системы можно определить с помощью сигнала светофора:
- красный цвет для неработоспособного состояния (система остановилась);
- желтый цвет для частично работоспособного состояния (система работает с ограниченными возможностями);
- зеленый цвет для полностью работоспособного состояния.
Комплексная система мониторинга работоспособности позволяет оператору выполнять детализацию по системе для просмотра состояния работоспособности подсистем и компонентов. Например, если вся система является частично работоспособной, оператор должен иметь возможность углубиться в подробности и выяснить, какие функции в настоящее время недоступны.
Требования к источникам данных, инструментированию и сбору данных
Необработанные данные, необходимые для реализации мониторинга работоспособности, могут создаваться в рамках следующих процессов:
- Трассировка выполнения запросов пользователей. Эти сведения можно использовать для определения того, какие запросы выполнены успешно, какие завершились со сбоем и сколько времени занимает выполнение каждого запроса.
- Мониторинг искусственных пользователей. Этот процесс имитирует действия пользователя и выполняет ряд стандартных действий. Результаты каждого действия следует регистрировать.
- Ведение журнала исключений, ошибок и оповещений. Эти сведения могут регистрироваться в результате выполнения трассировочных операторов, внедренных в код приложения, а также при извлечении сведений из журналов событий любой из служб, на которые ссылается система.
- Мониторинг работоспособности служб сторонних поставщиков, используемых в системе. Для этого может потребоваться получение и анализ данных о работоспособности, предоставляемых этими службами, а такая информация может предлагаться в нескольких форматах.
- Мониторинг конечной точки. Этот механизм более подробно описан в разделе "Мониторинг доступности".
- Сбор сведений о производительности окружающей среды, таких как фоновое использование ЦП или операции ввода-вывода (включая сеть).
Анализ данных о работоспособности
Основная задача мониторинга работоспособности заключается в том, чтобы быстро определить, работает ли система. Горячий анализ непосредственных данных может вызвать оповещение в случае обнаружения неработоспособности критического компонента (Например, не удается ответить на последовательную серию ping.) Затем оператор может предпринять соответствующее действие по исправлению.
Более сложные системы могут включать в себя прогнозирующий элемент, который выполняет холодный анализ недавних и текущих рабочих нагрузок. Холодный анализ позволяет выявить тенденции и определить, останется ли система работоспособной или требуются дополнительные ресурсы. Этот прогнозирующий элемент должен быть основан на критических метриках производительности, таких как:
- частота выполнения запросов, направляемых в каждую службу или подсистему;
- время отклика для таких запросов;
- объем данных, передаваемых в каждую службу и из нее.
Если значение любой метрики превышает указанный порог, система может выдать оповещение, чтобы позволить оператору или функции автоматического масштабирования (если она доступна) предпринять профилактические действия, необходимые для поддержания работоспособности системы. Для выполнения этих действий могут потребоваться дополнительные ресурсы, перезапуск одной или нескольких неработающих служб или применение регулирования к запросам с более низким приоритетом.
Мониторинг доступности
В полностью работоспособной системе должны быть доступны все составляющие ее компоненты и подсистемы. Мониторинг доступности тесно связан с мониторингом работоспособности, однако, если мониторинг работоспособности обеспечивает немедленное представление текущего состояния работоспособности системы, то он отвечает за отслеживание доступности системы и ее компонентов в целях формирования статистических данных, касающихся бесперебойной работы системы.
Во многих системах некоторые компоненты (например, база данных) имеют встроенную избыточность, чтобы обеспечить быструю отработку отказа в случае серьезной ошибки или потери подключения. В идеальном варианте пользователи не должны знать о том, что возникла такая ошибка, однако, с точки зрения мониторинга доступности, необходимо собрать как можно больше данных о таких сбоях, чтобы попытаться определить причину и предпринять корректирующие действия, направленные на предотвращение возникновения подобной проблемы в дальнейшем.
Данные, необходимые для отслеживания доступности, могут зависеть от ряда факторов более низкого уровня, многие из которых могут относиться к приложению, системе и среде. Эффективная система мониторинга собирает данные о доступности, соответствующие этим низкоуровневым факторам, и затем выполняет их статистическую обработку, чтобы сформировать общее представление о системе. Например, в системе электронной коммерции бизнес-функции, позволяющие клиенту размещать заказы, могут зависеть от репозитория, в котором хранятся сведения о заказе, и платежной системы, которая обрабатывает денежные операции для оплаты таких заказов. Таким образом, доступность той части системы, которая отвечает за размещение заказов, является функцией доступности репозитория и подсистемы оплаты.
Требования для мониторинга доступности
Оператор также должен иметь возможность просматривать исторические данные о доступности каждой системы и подсистемы и использовать эту информацию для выявления каких-либо тенденций, которые могут стать причиной периодических сбоев одной или нескольких подсистем (например, когда сбой служб происходит в определенное время дня, соответствующее часам максимальной нагрузки).
Решение для мониторинга предоставляет текущие и исторические данные о доступности каждой подсистемы. Кроме того, оно должно обеспечивать возможность быстрого оповещения оператора в случае, когда происходит сбой одной или нескольких служб либо пользователям не удается подключиться к службам. Это требует не только мониторинга каждой службы, но и проверки действий, выполняемых каждым пользователем, если такие действия заканчиваются неудачей при попытке взаимодействия со службой. В некоторой степени сбой подключения является нормальным и может быть вызван временными ошибками, однако может оказаться удобным разрешить системе выдавать оповещение, если за конкретный период времени для заданной подсистемы возникло определенное число ошибок подключения.
Требования к источникам данных, инструментированию и сбору данных
Как и в случае с мониторингом работоспособности, необработанные данные, необходимые для обеспечения мониторинга доступности, могут создаваться в результате мониторинга искусственных пользователей, а также регистрации любых исключений, ошибок и оповещений, которые могут возникать в системе. Кроме того, данные о доступности можно получить с помощью мониторинга конечной точки. Приложение может предоставлять одну или несколько конечных точек работоспособности, каждая из которых тестирует доступ к функциональной области в системе. Система мониторинга может проверять связь с каждой конечной точки по определенному расписанию и собирать полученные результаты (успех или сбой).
Все случаи истекшего времени ожидания, сбоев подключения к сети и повторных попыток соединения следует регистрировать. Все данные должны иметь метки времени.
Анализ данных о доступности
Данные инструментирования необходимо статистически обработать и сопоставить, чтобы обеспечить выполнение следующих типов анализа.
- Немедленная доступность системы и подсистем.
- Число сбоев доступности системы и подсистем. В идеале оператор должен иметь возможность сопоставлять сбои с определенными действиями, определяя, что именно произошло при сбое системы.
- Историческое представление частоты сбоев системы или любой подсистемы за любой заданный период, а также загрузка системы (например количество запросов пользователей) во время сбоя.
- Причины недоступности системы или любой подсистемы. Причиной может служить потеря подключения, истечение времени ожидания при наличии подключения и возвращение ошибок в подключенном состоянии.
С помощью следующей формулы можно вычислить процент доступности службы за период времени:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Это полезно для выполнения соглашений об уровне обслуживания (Мониторинг об уровне обслуживания подробно описан далее в этом руководстве.) Определение простоя зависит от службы. Например, служба сборки Visual Studio Team Services определяет время простоя как период (общее количество накопленных минут), во время которого служба сборки недоступна. Минута считается недоступной, если непрерывные HTTP-запросы к службе сборки на выполнение операций, отличных от операций, инициируемых клиентом, в течение всей минуты приводят к появлению кода ошибки или не возвращают ответ.
Отслеживание производительности
По мере возрастания нагрузки на систему из-за увеличения числа пользователей и размера наборов данных, используемых этими пользователями, становится более вероятным сбой одного или нескольких компонентов. Часто сбою компонента предшествует снижение производительности. Если вам удается обнаружить такое снижение, можно предпринять упреждающие меры для исправления ситуации.
Производительность системы зависит от ряда факторов. Каждый фактор обычно измеряется с помощью ключевых показателей эффективности (KPI), например по количеству транзакций базы данных в секунду или объему сетевых запросов, успешно обработанных в заданный период. Некоторые из этих ключевых показателей эффективности могут быть определены непосредственно из мер производительности, в то время как другие могут выводиться из сочетания разных метрик.
Примечание.
Для определения низкой или высокой производительности требуется осознавать тот уровень производительности, с которым способна работать система. Для этого необходимо наблюдать за системой во время ее работы в условиях обычной загрузки и собирать данные по каждому ключевому показателю эффективности за некоторый период времени. Это может включать в себя запуск системы с имитацией нагрузки в тестовой среде и сбор соответствующих данных перед развертыванием системы в рабочей среде.
Следует также убедиться, что мониторинг в целях определения производительности не превратится в нагрузку для системы. Можно динамически настраивать уровень детализации для данных, собираемых процессом мониторинга производительности.
Требования для мониторинга производительности
Чтобы оценить производительность системы, оператору обычно требуется просмотреть следующие сведения:
- Уровни откликов для запросов пользователей.
- Число параллельных запросов пользователей.
- Объем сетевого трафика.
- Значения скорости выполнения бизнес-транзакций.
- Среднее время обработки запросов.
Полезно также предоставить средства, позволяющие оператору выявлять корреляции, например:
- сравнение количества одновременно работающих пользователей со значениями времени задержки запросов (сколько времени необходимо для начала обработки запроса после отправки его пользователем);
- сравнение количества одновременно работающих пользователей со средним временем отклика (сколько времени необходимо для завершения запроса после начала его обработки);
- сравнение объема запросов с числом ошибок обработки.
Кроме этих функциональных сведений высокого уровня, оператор также должен иметь возможность получить подробную информацию о производительности каждого компонента в системе. Эти данные обычно предоставляются с помощью низкоуровневых счетчиков производительности, отслеживающих такие данные, как:
- использование памяти;
- число потоков;
- время обработки ЦП;
- длина очереди запросов;
- число операций и ошибок ввода-вывода для диска или сети;
- число записанных или считанных байтов;
- индикаторы ПО промежуточного слоя, такие как длина очереди.
Все визуализации должны позволять оператору указать период времени; Отображаемые данные могут быть моментальным снимком текущей ситуации или историческим представлением производительности.
Оператор должен иметь возможность создавать оповещения по любой мере производительности для любого конкретного значения в рамках любого заданного интервала времени.
Требования к источникам данных, инструментированию и сбору данных
Высокоуровневые данные о производительности (пропускная способность, число одновременных пользователей, количество бизнес-транзакций, частота возникновения ошибок и т. п.) можно собрать, отслеживая ход выполнения запросов пользователей по мере их получения и прохождения через систему. Это подразумевает включение трассировочного оператора в ключевых точках кода приложения вместе с данными синхронизации. Все ошибки, исключения и оповещения следует регистрировать вместе с достаточным объемом данных, позволяющим соотнести их с вызвавшими их запросами. Другим полезным источником является журнал служб Internet Information Services (IIS).
Если это возможно, следует также собирать данные о производительности для всех внешних систем, используемых приложением. Эти внешние системы могут предоставлять свои собственные счетчики производительности или другие функции для запроса данных о производительности. Если это невозможно, запишите сведения, такие как время начала и окончания каждого запроса, выполняемого для внешней системы, вместе с состоянием операции (успех, ошибка или оповещение). Например, для регистрации времени запросов можно использовать принцип секундомера: включите таймер при запуске запроса, а затем остановите таймер при завершении запроса.
Низкоуровневые данные о производительности для отдельных компонентов в системе можно получить с помощью таких функций и служб, как счетчики производительности Windows и диагностика Azure.
Анализ данных о производительности
Большая часть работы по анализу состоит из агрегирования данных о производительности по типу запроса пользователя или подсистеме или службе, в которую отправляется каждый запрос. В качестве примера запроса пользователя можно привести добавление элемента в корзину для покупок или выполнение процедуры оформления заказа в системе электронной коммерции.
Другим распространенным требованием является суммирование данных о производительности по выбранным процентилям. Например, оператор может определить время отклика для 99 % запросов, 95 % запросов и 70 % запросов. Для каждого процентиля могут быть заданы целевые показатели соглашения об уровне обслуживания или другой набор целевых показателей. Текущие результаты должны предоставляться практически в режиме реального времени, чтобы способствовать немедленному обнаружению проблем, а также статистически обрабатываться за более длительные периоды.
В случае проблем с задержкой, влияющих на производительность, оператор должен быстро определить причину возникновения узкого места, проверяя задержку каждого из действий, выполняемого каждым запросом. Таким образом, данные о производительности должны предоставлять средства для сопоставления мер производительности для каждого действия, позволяющие привязать их к определенному запросу.
В зависимости от требований к визуализации может быть полезно создавать и хранить куб данных, содержащий представления необработанных данных. На основе этого куба можно выполнять сложные специализированные запросы и анализ сведений о производительности.
Мониторинг безопасности
Во всех коммерческих системах, содержащих конфиденциальные данные, должна быть реализована структура безопасности. Сложность механизма обеспечения безопасности обычно зависит от уровня конфиденциальности данных. В системе, где требуется проверка подлинности пользователей, необходимо регистрировать следующее:
- все попытки входа в систему независимо от того, были ли они успешными или нет;
- все операции, выполняемые авторизованным пользователем, а также сведения обо всех ресурсах, к которым он обращался;
- время, когда пользователь завершил сеанс и вышел из системы.
Мониторинг может помочь в обнаружении атак на систему. Например, большое количество неудачных попыток входа может указывать на атаку методом подбора. Непредвиденный всплеск запросов может быть результатом атаки типа "отказ в обслуживании" (DDoS). Вы должны быть готовы осуществлять мониторинг всех запросов ко всем ресурсам, независимо от источника этих запросов. Система с уязвимостью входа может случайно предоставлять ресурсы внешним пользователям, не требуя от них фактического входа в систему.
Требования для мониторинга безопасности
Наиболее важные аспекты мониторинга безопасности заключаются в том, чтобы оператор мог быстро осуществлять следующие задачи.
- Обнаружение попыток вторжения со стороны сущности, не прошедшей проверку подлинности.
- Выявление попыток сущностей выполнить операции с данными, к которым им не был предоставлен доступ.
- Определение того, подвергается ли система или ее часть атаке извне или изнутри (например, прошедший проверку подлинности пользователь-злоумышленник может попытаться перевести систему в нерабочее состояние).
Для удовлетворения этих требований оператор должен получать уведомление о следующих ситуациях:
- повторяющиеся попытки входа в систему, предпринятые с использованием одной и той же учетной записи за указанный период времени;
- повторяющиеся попытки доступа к запрещенному ресурсу, предпринятые с использованием одной и той же учетной записи за указанный период времени;
- возникновение большого количества не прошедших проверку подлинности или неавторизованных запросов за указанный период времени.
Сведения, предоставляемые оператору, должны включать адрес узла источника для каждого запроса. Если нарушения безопасности регулярно исходят из определенного диапазона адресов, эти узлы можно заблокировать.
Ключевую роль в обеспечении безопасности системы играет возможность быстро выявить действия, отличающиеся от обычных. Такие сведения, как количество неудачных или успешных запросов на вход, можно отобразить визуально, чтобы определить, существует ли всплеск активности в необычном времени. (например пользователи, которые входят в систему в 3 часа ночи и выполняют большое число операций, хотя их рабочий день начинается в 9 утра). Эти сведения также могут пригодиться при настройке автоматического масштабирования по времени. Например, если оператор обнаруживает, что большое число пользователей регулярно входит в систему в определенное время дня, он может предусмотреть запуск дополнительных служб проверки подлинности для обработки этой нагрузки, а затем завершить такие дополнительные службы после спада пиковой нагрузки.
Требования к источникам данных, инструментированию и сбору данных
Фактор безопасности охватывает все аспекты большинства распределенных систем, а соответствующие необходимые данные с большой вероятностью создаются в нескольких точках всей системы. Для сбора сведений о безопасности, полученных в результате событий, вызванных приложением, сетевым оборудованием, серверами, брандмауэрами, антивирусным программным обеспечением и другими элементами предотвращения вторжений, можно применить подход SIEM (Security Information and Event Management).
Мониторинг безопасности может включать в себя данные из средств, которые не являются частью вашего приложения, например программ, определяющих сканирование портов внешними организациями, или сетевых фильтров, обнаруживающих попытки получить несанкционированный доступ к приложению и данным.
Во всех случаях собранные данные должны позволять администратору определить природу любой атаки и принять соответствующие меры противодействия.
Анализ данных безопасности
Особенность мониторинга безопасности заключается в разнообразии источников, из которых получаются данные. Различные форматы и уровни детализации часто требуют сложного анализа, позволяющего объединить собранные данные в согласованный поток информации. За исключением самых простых случаев (например, обнаружение большого количества неудачных попыток входа или повторных попыток получения несанкционированного доступа к важным ресурсам), сложная автоматическая обработка данных безопасности может оказаться невозможной. Вместо этого может быть более предпочтительно записывать данные в исходной форме, только с добавлением меток времени, в безопасное хранилище для ручного анализа.
Мониторинг соглашений об уровне обслуживания
Многие коммерческие системы, поддерживающие оплату клиентами, предоставляют гарантии относительно производительности системы в виде соглашений об уровне обслуживания. По существу соглашения об уровне обслуживания гарантируют, что система может обрабатывать определенный объем работы в течение согласованного времени без потери важных данных. Мониторинг соглашений об уровне обслуживания отвечает за то, что система способна обеспечить соответствие количественным показателям, закрепленным в соглашении об уровне обслуживания.
Примечание.
Мониторинг соглашений об уровне обслуживания тесно связан с мониторингом работоспособности. Если мониторинг производительности отвечает за обеспечение оптимальной работы системы, то мониторинг соглашения об уровне обслуживания регулируется договорным обязательством, которое определяет, что именно понимается под оптимальной работой.
Соглашения об уровне обслуживания часто определяются на основе следующих показателей.
- Общая доступность системы. Например, организация может гарантировать, что система будет доступна 99,9 % всего времени; это равнозначно не более чем 9 часам простоя за год или примерно 10 минутам в неделю.
- Оперативная пропускная способность. Этот аспект часто выражается в виде одного или нескольких ключевых максимальных уровней, например гарантии того, что система будет способна поддерживать до 100 000 одновременных запросов пользователей или обрабатывать 10 000 одновременных бизнес-транзакций.
- Оперативное время отклика. Система также может давать гарантии относительно скорости обработки запросов, например, что 99 % всех бизнес-транзакций будет выполнено в течение 2 секунд и никакая отдельная транзакция не будет выполняться более 10 секунд.
Примечание.
Некоторые контракты для коммерческих систем также могут включать соглашения об уровне обслуживания, касающиеся поддержки клиентов, например, ответ на все обращения в службу поддержки будет дан в течение пяти минут, а 99 % всех проблем будут полностью устранены в течение одного рабочего дня. Ключом к соблюдению таких соглашений об уровне обслуживания является эффективное отслеживание вопросов (описывается далее в этом разделе).
Требования для мониторинга соглашений об уровне обслуживания
На самом высоком уровне оператор должен иметь возможность мгновенно определить, соответствует ли система заключенным соглашениям об уровне обслуживания. Если она им не соответствует, он должен иметь возможность выполнить детализацию и изучить базовые факторы, чтобы определить причину недостаточной производительности.
К типичным индикаторам высокого уровня, которые можно представить визуально, относятся следующие.
- Процент времени работы службы.
- Пропускная способность приложения (измеряется с точки зрения успешных транзакций или операций в секунду).
- Число успешно выполненных и завершившихся ошибкой запросов приложения.
- Число сбоев, исключений и оповещений для приложений и систем.
Все эти индикаторы должны фильтроваться по указанному периоду времени.
Облачное приложение, скорее всего, будет состоять из нескольких подсистем и компонентов. Оператор должен иметь возможность выбрать высокоуровневый индикатор и увидеть, как на него влияет работоспособность базовых элементов. Например, если время работы всей системы становится меньше приемлемого значения, оператор должен иметь возможность углубиться в подробности и определить, какие элементы вызвали этот сбой.
Примечание.
Время работы системы должно быть определено самым тщательным образом. В системе, где используется избыточность для обеспечения максимальной доступности, отдельные экземпляры элементов могут выйти из строя, однако при этом система может оставаться работоспособной. Время работы системы, представленное функцией мониторинга работоспособности, должно показывать совокупное время работы каждого элемента и не обязательно должно показывать, что система была фактически остановлена. Кроме того, ошибки можно изолировать, поэтому, даже если недоступна определенная система, остальная часть системы может остаться доступной, несмотря на сокращение функциональных возможностей (сбой в системе электронной коммерции может помешать клиенту размещать заказы, однако при этом клиент по-прежнему сможет просматривать каталог продуктов).
Для реализации оповещений система должна иметь возможность вызвать событие, если любой высокоуровневый индикатор превышает заданное пороговое значение. Низкоуровневые детали различных факторов, которые составляют высокоуровневый индикатор, должны быть доступны в виде контекстных данных для системы оповещений.
Требования к источникам данных, инструментированию и сбору данных
Необработанные данные, необходимые для обеспечения мониторинга соглашений об уровне обслуживания, аналогичны тем данным, которые требуются для мониторинга производительности, а также некоторым аспектам мониторинга работоспособности и доступности (Дополнительные сведения см. в этих разделах.) Эти данные можно записать, выполнив следующие действия.
- Мониторинг конечных точек.
- Ведение журнала исключений, ошибок и оповещений.
- Трассировка выполнения запросов пользователей.
- Мониторинг доступности служб сторонних поставщиков, используемых в системе.
- Использование метрик и счетчиков производительности.
Все данные должны быть синхронизированы и иметь метки времени.
Анализ данных соглашения об уровне обслуживания
Необходимо выполнить статистическую обработку данных инструментирования, чтобы сформировать общую картину по производительности системы. Кроме того, объединенные данные обеспечивают детализацию, позволяющую проверить производительность базовых подсистем. Например, вы должны иметь возможность:
- вычислить общее количество запросов пользователей за указанный период времени и определить долю успешных и неудачных запросов;
- объединить время отклика запросов пользователей для формирования общего представления о значениях времени отклика системы;
- анализировать ход выполнения запросов пользователя, разбивая общее время отклика заданного запроса на значения времени отклика отдельных рабочих элементов в этом запросе;
- определить общую доступность системы как процентное отношение времени работы за любой конкретный период;
- анализировать процентное отношение времени доступности отдельных компонентов и служб в системе. Для этого может потребоваться анализ журналов, создаваемых службами сторонних разработчиков.
Многие коммерческие системы должны выдавать сравнение реальной производительности с показателями, заданными в соглашении об уровне обслуживания для указанного периода, который обычно составляет один месяц. Эти сведения можно использовать для расчета кредитов или других видов выплат для клиентов, если в данном периоде требования соглашения об уровне обслуживания не выполняются. Можно вычислить доступность для службы с помощью методики, описанной в разделе Анализ данных о доступности.
Для внутренних целей организация также может отслеживать количество и характер инцидентов, вызвавших сбой службы. Изучение способов быстрого исправления или полного устранения таких проблем поможет сократить время простоя и обеспечить соответствие соглашениям об уровне обслуживания.
Аудит
В зависимости от характера приложения могут существовать законодательные или другие юридические ограничения, задающие требования к аудиту операций, выполняемых пользователями, и к регистрации всего доступа к данным. Аудит может предоставить доказательства, связывающие клиентов с определенными запросами; неподдельность является важным фактором во многих системах электронной коммерции, помогающим поддерживать доверительные отношения между клиентом и организацией, ответственной за приложения или службы.
Требования к аудиту
Аналитик должен иметь возможность трассировки последовательности бизнес-операций, выполняемых пользователями, чтобы можно было воссоздать действия этих пользователей. Это может потребоваться просто в целях документирования либо для проведения судебной экспертизы.
Сведения аудита являются строго конфиденциальными, так как с большой вероятностью включают в себя данные, идентифицирующие пользователей системы и выполняемые ими задачи. По этой причине сведения аудита, скорее всего, будут отображаться в виде отчетов, доступных только доверенным аналитикам, а не с помощью интерактивной системы, поддерживающей графические операции детализации. Аналитик должен иметь возможность создавать разнообразные отчеты, например список всех действий пользователей, выполняемых во время указанного периода, с подробным описанием хронологии деятельности каждого пользователя, а также список последовательности операций, выполняемых с одним или несколькими ресурсами.
Требования к источникам данных, инструментированию и сбору данных
К основным источникам информации для аудита могут относиться следующие.
- Система безопасности, управляющая проверкой подлинности пользователей.
- Журналы трассировки, в которых регистрируются действия пользователей.
- Журналы безопасности, отслеживающие все идентифицируемые и неидентифицируемые сетевые запросы.
Формат данных аудита и способ их хранения могут определяться нормативными требованиями. Например, может быть запрещено очищать данные любым способом (Он должен быть записан в исходном формате.) Доступ к репозиторию, где он хранится, должен быть защищен, чтобы предотвратить изменение.
Анализ данных аудита
Аналитик должен иметь доступ к необработанным данным целиком в их исходном виде. Помимо необходимости в создании общих отчетов аудита, средства, используемые для анализа таких данных, вероятнее всего, будут специализированными и внешними по отношению к системе.
Мониторинг использования
Мониторинг использования отслеживает, как именно используются функции и компоненты приложения. Оператор может использовать собранные данные в следующих целях:
Определение того, какие функции используются чаще всего, и выявление потенциальных проблемных мест в системе. Элементы с высоким трафиком могут выиграть от функционального секционирования и даже репликации для более равномерного распределения нагрузки. С помощью этих сведений оператор может также выяснить, какие функции используются редко и являются кандидатами на удаление или замену в будущих версиях системы.
Получение сведений об операционных событиях в системе в условиях обычной работы. Например, на веб-сайте электронной коммерции можно регистрировать статистические сведения о количестве транзакций и наборе ответственных за них клиентов. Эту информацию можно использовать для планирования емкости на случай роста числа клиентов.
Определение (возможно, косвенным образом) удовлетворенности пользователей производительностью или функциональностью системы. Например, если большое количество клиентов в системе электронной коммерции регулярно отказываются от заполненных корзин, это может указывать на проблему с оформлением заказов.
Создание данных для выставления счетов. Коммерческое приложение или мультитенантная служба могут взимать с клиентов плату за те ресурсы, которые они используют.
Применение квот. Если пользователь в мультитенантной системе превышает свою платную квоту на время обработки или использование ресурса за указанный период, их доступ может быть ограничен, а к их обработке может применяться регулирование.
Требования для мониторинга использования
Чтобы оценить использование системы, оператору обычно требуется просмотреть следующие сведения:
- число запросов, обрабатываемых каждой подсистемой и направленных каждому ресурсу;
- работа, выполняемая каждым пользователем;
- объем хранилища данных, занимаемый каждым пользователем;
- ресурсы, к которым обращается каждый пользователь.
Кроме того, оператор должен иметь возможность создавать графы, например с отображением пользователей, больше всего нуждающихся в ресурсах, или ресурсов или системных функций, доступ к которым осуществляется чаще всего.
Требования к источникам данных, инструментированию и сбору данных
Отслеживание использования можно выполнять на относительно высоком уровне, регистрируя время начала и окончания каждого запроса, а также характер запроса (чтение, запись и так далее, в зависимости от ресурса). Эти сведения можно получить следующими способами.
- Трассировка действий пользователей.
- Сбор данных со счетчиков производительности, измеряющих уровень использования для каждого ресурса.
- Мониторинг потребления ресурсов каждым пользователем.
В рамках сбора данных необходимо также иметь возможность идентификации пользователей, которые отвечают за выполнение операций, и ресурсов, которые эти операции применяют. Собранные сведения должны быть достаточно подробными, чтобы обеспечивать точное выставление счетов.
Отслеживание проблем
Клиенты и другие пользователи могут сообщить о проблемах в случае непредвиденных событий или поведения в системе. Отслеживание вопросов подразумевает управление такими проблемами, сопоставление их с мерами по устранению базовых неполадок в системе и информирование пользователей о возможных решениях.
Требования для отслеживания вопросов
Для отслеживания вопросов операторы часто используют отдельную систему, которая позволяет записывать и вносить в отчет сведения о неполадках, полученные от пользователей. Эта информация может включать в себя такие сведения, как задачи, которые пользователь пытался выполнить, симптомы проблемы, последовательность событий, а также любые выданные ошибки или оповещения.
Требования к источникам данных, инструментированию и сбору данных
Исходным источником данных для отслеживания вопросов является пользователь, который первым сообщает о проблеме. Пользователь может иметь возможность предоставить дополнительные данные:
- аварийный дамп (если приложение содержит компонент, который выполняется на настольной системе пользователя);
- моментальный снимок экрана;
- дата и время возникновения ошибки, а также другие сведения о среде, такие как расположение.
Эти сведения можно использовать для отладки, а также для формирования невыполненной работы для будущих версий программного обеспечения.
Анализ данных отслеживания вопросов
Разные пользователи могут сообщать об одинаковой проблеме, и система отслеживания вопросов должна сопоставлять схожие отчеты друг с другом.
Ход выполнения процесса отладки следует регистрировать относительно каждого отчета о проблемах, а после разрешения проблемы клиент может быть уведомлен о решении.
Если пользователь сообщает о распознанной проблеме, для которой в системе отслеживания вопросов есть известное решение, оператор должен иметь возможность немедленно оповестить пользователя о таком решении.
Трассировка операций и отладка выпусков программного обеспечения
Когда пользователь сообщает о проблеме, ему часто известно только непосредственное влияние этой проблемы на его операции, поэтому пользователь может сообщить оператору, отвечающему за обслуживание системы, только о происшествиях для своего конкретного случая. Эти происшествия обычно являются симптомами, указывающими на одну или несколько базовых проблем. Во многих случаях аналитику необходимо изучить хронологию базовых операций для установления причины проблемы (этот процесс называется анализом первопричин).
Примечание.
Анализ основных причин может помочь выявить неэффективные решения, принятые на стадии разработки приложения. В таких ситуациях может быть возможно переработать затронутые элементы и развернуть их в рамках одной из следующих версий. Этот процесс требует тщательного контроля, а также подробного мониторинга обновленных компонентов.
Требования для трассировки и отладки
Для трассировки непредвиденных событий и других проблем крайне важно, чтобы данные мониторинга предоставляли достаточно сведений для того, чтобы аналитик мог отследить происхождение этих проблем и воссоздать последовательность произошедших событий. Эта информация должна быть достаточной для выявления основной причины возникших проблем. После этого разработчик сможет внести необходимые изменения и предотвратить повторное появление данной проблемы.
Требования к источникам данных, инструментированию и сбору данных
Устранение неполадок может включать в себя трассировку всех методов (и их параметров), вызванных в рамках операции для построения дерева, показывающего логический поток через систему при выполнении клиентом определенного запроса. Исключения и оповещения, созданные системой в результате этого потока, должны перехватываться и регистрироваться в журнале.
Для поддержки отладки система может предоставлять обработчики, позволяющие оператору получать сведения о состоянии в критические моменты в системе или выводить подробные сведения в пошаговом режиме по мере выполнения выбранной операции. Запись данных с таким уровнем детализации может создать дополнительную нагрузку на систему, поэтому данный процесс должен быть временным. В основном он используется при возникновении крайне необычной последовательности событий, которую трудно воспроизвести, либо в том случае, когда требуется тщательный мониторинг нового выпуска одного или нескольких элементов в системе, чтобы убедиться, что они работают должным образом.
Конвейер мониторинга и диагностики
Мониторинг крупномасштабной распределенной системы представляет собой нетривиальную задачу, поэтому не следует рассматривать каждый из сценариев, описанных в предыдущем разделе, по отдельности. Скорее всего, данные диагностики и мониторинга, необходимые в каждой ситуации, будут в значительной мере перекрываться, хотя для таких данных может потребоваться различная обработка. По этой причине следует использовать целостное представление для мониторинга и диагностики.
Весь процесс мониторинга и диагностики можно представить в виде конвейера, который состоит из этапов, показанных на рисунке 1.
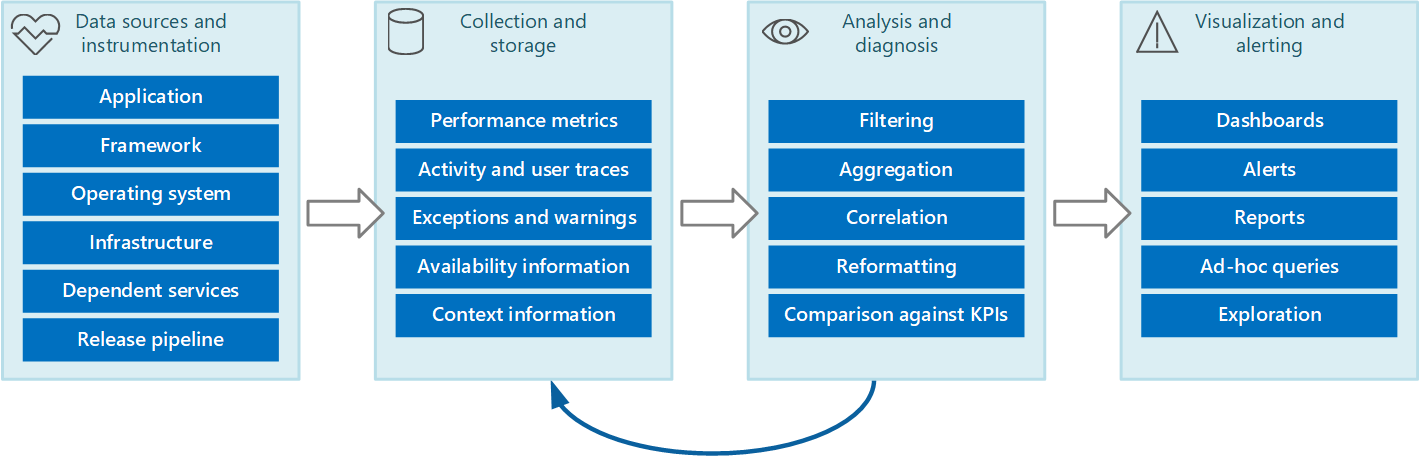
Рис. 1. Этапы конвейера мониторинга и диагностики
На рисунке 1 показано, как данные мониторинга и диагностики могут поступать из различных источников. На этапе инструментирования и сбора определяются необходимые источники данных, данные для записи, способы записи и конечный формат этих данных, который упростит их дальнейший анализ. На этапе анализа и диагностики принимаются необработанные данные, из которых формируются полезные сведения — на их основе оператор определяет состояние системы. Исходя из полученных сведений, оператор принимает решения о возможных действиях и снова передает результаты на этап инструментирования и сбора. На этапе визуализации и оповещения выдается представление, отражающее состояние системы. За счет нескольких панелей мониторинга данные в этом представлении могут отображаться практически в режиме реального времени. Представление может включать отчеты, графики и диаграммы, демонстрирующие изменение данные и помогающие определять долгосрочные тенденции. Если сведения указывают на то, что ключевой показатель эффективности с большой вероятностью выйдет за допустимые границы, этот этап также позволяет инициировать отправку оповещения оператору. В некоторых случаях оповещение также может использоваться для запуска автоматизированного процесса, который пытается выполнить корректирующие действия, такие как автоматическое масштабирование.
Обратите внимание, что эти действия составляют непрерывный процесс, где этапы выполняются параллельно. В идеальном варианте все этапы должны быть динамически настраиваемыми. В некоторые моменты, особенно в том случае, когда система развернута недавно или испытывает проблемы, может потребоваться чаще собирать расширенные данные. В других случаях должна быть возможность вернуться к записи важной информации базового уровня, чтобы убедиться, что система работает правильно.
Кроме того, процесс мониторинга следует рассматривать как динамическое и непрерывное решение, которое можно подвергнуть точной настройке и усовершенствовать с учетом обратной связи. Например, начать можно с измерения множества факторов для определения работоспособности системы. Анализируя данные с течением времени, вы сможете уточнить ситуацию, отбросив незначительные параметры и, минимизировав фоновые помехи, сосредоточиться на необходимых данных.
Источники данных диагностики и мониторинга
Сведения, используемые в процессе мониторинга, могут поступать из нескольких источников, как показано на рисунке 1. На уровне приложения данные поступают из журналов трассировки, включенных в код системы. Разработчики должны следовать стандартной процедуре для отслеживания потока управления в рамках своего кода. Например, при входе в метод можно выдавать сообщение трассировки, указывающее имя метода, текущее время, значение каждого параметра и другие необходимые сведения. Также может иметь смысл регистрация времени входа и выхода.
Следует регистрировать в журнале все исключения и оповещения, а также обеспечить сохранение полной трассировки любых вложенных исключений и оповещений. В идеальном случае необходимо также зафиксировать сведения, идентифицирующие запустившего код пользователя вместе с информацией о корреляции действий (для отслеживания запросов при их прохождении через систему), а также зарегистрировать попытки получения доступа ко всем ресурсам, таким как очереди сообщений, базы данных, файлы и другие зависимые службы. Эти сведения можно использовать для контроля использования и аудита.
Библиотеки и платформы используются во многих приложениях для выполнения общих задач, таких как доступ к хранилищу данных или связь по сети. Возможно, эти платформы можно настроить на выдачу собственных сообщений трассировки и необработанной диагностической информации, например количества транзакций и количества успешных и неудачных операций передачи данных.
Примечание.
Многие современные платформы автоматически публикуют события производительности и трассировки, поэтому для фиксации этой информации достаточно просто предоставить средства для ее извлечения и сохранения в таком месте, где ее можно обработать и проанализировать.
Операционная система, в которой выполняется приложение, может быть источником низкоуровневых системных сведений, таких как счетчики производительности, указывающие скорость ввода-вывода, использование памяти и ЦП. Кроме того, могут выводиться ошибки операционной системы (например, сбой при открытии файла).
Следует также учитывать базовую инфраструктуру и компоненты, на основе которых выполняется система. Виртуальные машины, виртуальные сети и службы хранилищ — все они могут быть источниками важных счетчиков производительности уровня инфраструктуры и других диагностических данных.
Если приложение использует другие внешние службы, такие как веб-сервер или система управления базами данных, эти службы могут опубликовать свои собственные данные трассировки, журналы и счетчики производительности. В качестве примера для операций отслеживания, выполняемых в базе данных SQL Server, можно назвать динамические административные представления SQL Server, а в качестве примера записи запросов, отправленных на веб-сервер, — журналы трассировки IIS.
По мере изменения компонентов системы и развертывания новых версий важно иметь возможность сопоставлять проблемы, события и метрики с каждой из версий. Эти сведения должны привязываться к конвейеру выпуска, чтобы можно было быстро отслеживать и исправлять проблемы с определенной версией компонента.
Проблемы безопасности могут возникнуть в системе в любой момент. Например, пользователь может пытаться войти в систему с использованием неверного имени пользователя или пароля. Прошедший проверку подлинности пользователь может получить несанкционированный доступ к ресурсу или пользователь может предоставить недействительный или устаревший ключ для доступа к зашифрованным данным. Связанные с безопасностью сведения об успешных и неудачных запросах следует всегда заносить в журнал.
Раздел Инструментирование приложения содержит дополнительные инструкции относительно сведений, которые следует фиксировать. Для первоначального сбора этих сведений можно использовать различные стратегии:
Мониторинг приложения/системы. Эта стратегия использует внутренние источники в приложении, платформе приложений, операционной системе и инфраструктуре. Код приложения может создавать собственные данные мониторинга в важные моменты в течение жизненного цикла клиентского запроса. Приложение может включать трассировочные операторы, которые можно выборочно включать или отключать согласно условиям. Может также присутствовать и возможность вставки динамической информации с помощью инфраструктуры диагностики. Обычно эти платформы предоставляют подключаемые модули, которые могут подключаться к различным точкам инструментирования в коде и фиксировать данные трассировки в этих точках.
Кроме того, код или базовая инфраструктура могут вызывать события в критически важных точках. Агенты мониторинга, настроенные на прослушивание этих событий, могут записывать сведения о событии.
Мониторинг реальных пользователей. В данном подходе регистрируется взаимодействие между пользователем и приложением, а также отслеживается поток каждого запроса и отклика. Эта информация может иметь двойное назначение: она может применяться для измерения использования каждого пользователя и определения того, получают ли пользователи достаточное качество обслуживания (например, малое время отклика, низкую задержку и минимальное число ошибок). Собранные данные можно использовать для определения проблемных областей, где наиболее часто происходят сбои, и элементов, где система замедляется, возможно, из-за наличия проблемных мест в приложении или иной формы узкого места. Если внимательно отнестись к реализации данного подхода, можно получить возможность воссоздания проходящих через приложение потоков пользователей в целях отладки и тестирования.
Внимание
Данные, зафиксированные посредством мониторинга реальных пользователей, необходимо считать строго конфиденциальными, так как они могут содержать конфиденциальные материалы. Если зафиксированные данные сохраняются, это должно быть осуществлено безопасным образом. Если вы хотите использовать данные для мониторинга производительности или отладки, сначала отключите все персональные данные.
Мониторинг искусственных пользователей. В рамках этого подхода вы создаете собственный тестовый клиент, который имитирует пользователя и выполняет ряд типичных операций с возможностью их настройки. Вы можете отслеживать производительность тестового клиента для определения состояния системы. Вы также можете использовать несколько экземпляров тестового клиента в рамках операции нагрузочного тестирования, чтобы установить, как система реагирует на работу и какие выходные данные мониторинга создаются в таких условиях.
Примечание.
Мониторинг реальных и искусственных пользователей можно реализовать, включив код, который осуществляет трассировку и синхронизацию выполнения вызовов методов и других важных частей приложения.
Профилирование. Этот подход ориентирован главным образом на мониторинг и повышение производительности приложений. Вместо работы на функциональном уровне, характерной для мониторинга реальных и искусственных пользователей, он фиксирует сведения более низкого уровня во время работы приложения. Профилирование можно реализовать посредством периодической выборки состояния выполнения приложения (определяя то, в какой части кода приложение выполняется в определенный момент времени) или с помощью инструментирования, которое вставляет зонды в важные участки кода (например в начало и конец вызова метода) и регистрирует, какие методы вызывались, в какое время и как сколько времени заняло выполнение каждого из них. Затем эти данные можно проанализировать, чтобы определить, какие части приложения могут вызывать снижение производительности.
Мониторинг конечных точек. Эта методика использует одну или несколько диагностических конечных точек, предоставляемых приложением специально для обеспечения мониторинга. Конечная точка обеспечивает связь с кодом приложения и может возвращать сведения о работоспособности системы. Различные конечные точки могут быть ориентированы на различные аспекты функциональности. Можно создать свой собственный диагностический клиент, который отправляет периодические запросы в эти конечные точки и интерпретирует ответы. См. дополнительные сведения о шаблоне мониторинга конечных точек работоспособности.
Для максимального охвата следует использовать эти методы в сочетании друг с другом.
Инструментирование приложения
Инструментирование является важной частью процесса мониторинга. Принимать осмысленные решения относительно производительности и работоспособности системы можно только в случае регистрации данных, обосновывающих такие решения. Сведения, собранные с помощью инструментирования, должны быть достаточными для оценки производительности, диагностики проблем и принятия решений, не создавая необходимости входа на удаленный рабочий сервер для выполнения трассировки (и отладки) вручную. Данные инструментирования обычно состоят из метрик и данных, записанных в журналы трассировки.
Содержимое журнала трассировки может быть результатом записи текстовых данных в приложение или создания двоичных данных в результате события трассировки (если приложение использует трассировку событий Windows — ETW). Кроме того, оно может формироваться из системных журналов, где регистрируются события, поступающие из различных частей инфраструктуры, например с веб-сервера. Текстовые сообщения в журнале должны быть удобочитаемы, но при этом написаны в таком формате, который позволяет легко выполнять синтаксический анализ с помощью автоматизированной системы.
Следует также классифицировать журналы — нужно не записывать все данные трассировки в один журнал, а использовать отдельные журналы для записи выходных данных трассировки, относящихся к различным аспектам работы системы. Это позволяет быстро фильтровать сообщения журнала путем чтения соответствующего журнала вместо обработки одного длинного файла. Никогда не записывайте в один журнал сведения, к которым предъявляются различные требования по безопасности (например, данные аудита и данные отладки).
Примечание.
Журнал можно реализовать в виде файла в файловой системе или хранить в другом формате, например в виде большого двоичного объекта в хранилище больших двоичных объектов. Сведения журнала также следует хранить в более структурированном виде, например в форме строк в таблице.
Метрики обычно являются просто мерами или счетчиками некоторого аспекта или ресурса в системе в определенное время, имеющими один или несколько сопоставленных тегов или измерений (иногда их называют выборкой). Отдельный экземпляр метрики не представляет большой ценности сам по себе. Метрики необходимо регистрировать в течение времени. При этом важная задача заключается в том, чтобы определить, какие метрики следует регистрировать и как часто это необходимо делать. Слишком частое создание данных для метрик может стать причиной значительной дополнительной нагрузки на систему, а слишком редкая регистрация метрик может привести к пропуску обстоятельств, повлекших за собой важные события. Все эти аспекты зависят от конкретной метрики. Например, уровень использования ЦП на сервере может значительно отличаться по разным секундам, однако высокая загрузка становится проблемой, только если она длится несколько минут.
Сведения о корреляции данных
Можно легко наблюдать за счетчиками производительности системного уровня, фиксировать метрики для ресурсов и получать сведения о трассировке приложений из различных файлов журнала. При этом некоторые виды мониторинга требуют, чтобы конвейер мониторинга включал этап анализа и диагностики, позволяющий выполнять корреляцию данных из различных источников. В необработанных данных эти сведения могут принимать различные формы, поэтому процесс анализа должен быть снабжен достаточным количеством данных инструментирования, чтобы иметь возможность сопоставить эти разные формы. Например, на уровне платформы приложения задача может быть идентифицирована по идентификатору потока, а в приложении те же действия могут быть связаны с идентификатором пользователя, выполняющего эту задачу.
Кроме того, маловероятно, что существует полноценное сопоставление между потоками и запросами пользователей, поскольку асинхронные операции могут повторно использовать одни и те же потоки для выполнения операций от имени более чем одного пользователя. Ситуацию усложняет и то, что во время прохождения через систему один запрос может обрабатываться несколькими потоками. Если возможно, сопоставьте каждый запрос с уникальным идентификатором действия, который распространяется через систему в рамках контекста запроса (методика создания и включения идентификаторов действия в данные трассировки будет зависеть от технологии, применяемой для сбора данных трассировки).
Все данные мониторинга следует снабжать единообразной меткой времени. Для обеспечения согласованности регистрируйте даты и время в формате UTC. Это поможет упростить трассировку последовательностей событий.
Примечание.
Компьютеры, работающие в разных часовых поясах и сетях, могут быть не синхронизированы между собой, поэтому при корреляции данных инструментирования, охватывающих несколько компьютеров, не следует полагаться только на метки времени.
Какие сведения должны входить в данные инструментирования
Принимая решение о том, какие именно данные инструментирования требуется собирать, необходимо учитывать следующие моменты:
Сведения, зафиксированные событиями трассировки, должны быть пригодны для чтения как компьютером, так и человеком. Для этих сведений следует применять четко определенные схемы, чтобы упростить автоматическую обработку сведений журналов в рамках всей системы и обеспечить согласованное чтение журналов персоналом, отвечающим за эксплуатацию и техническое обеспечение. Включите сведения о среде, например среду развертывания, компьютер, на котором выполняется процесс, сведения о процессе и стек вызовов.
Профилирование следует включать только в случае необходимости, так как оно может создавать значительную нагрузку на систему. Профилирование с использованием инструментирования регистрирует событие (например вызов метода) каждый раз, когда оно возникает, в то время как выборка регистрирует только выбранные события. Такой выбор может осуществляться по времени (каждые n секунд) или по частоте (после каждых n запросов). Если события происходят очень часто, профилирование с использованием инструментирования может вызвать излишнюю нагрузку, что само по себе негативно скажется на общей производительности. В этом случае предпочтительнее может оказаться подход с выборкой. Однако в случае малой частоты возникновения событий выборка может пропустить их, поэтому в данном случае инструментирование может оказаться более уместным подходом.
Предоставьте достаточный контекст, чтобы позволить разработчику или администратору определить источник каждого запроса. Он может содержать определенный вид идентификатора действий, идентифицирующий экземпляр запроса, а также сведения, которые можно использовать для корреляции этого действия с выполняемыми вычислительными операциями и применяемыми ресурсами. Обратите внимание, что эта работа может выходить за границы процесса или компьютера. Для отслеживания использования контекст должен также включать (явно или косвенно через другую связанную информацию) ссылку на клиента, который вызвал выполнение запроса. Этот контекст предоставляет ценную информацию о состоянии приложения на момент регистрации данных мониторинга.
Регистрируйте все запросы, а также расположения или области, из которых эти запросы выполняются. Эта информация может помочь определить, существуют ли проблемные места, привязанные к определенному расположению, а также предоставить данные, которые могут быть полезны при определении потребности в секционировании приложения или используемых им данных.
Тщательно регистрируйте и фиксируйте сведения об исключениях. Часто критически важная отладочная информация теряется из-за неправильно реализованной обработки исключений. Регистрируйте все сведения об исключениях, вызываемых приложением, в том числе все внутренние исключения и другие контекстные сведения, включая стек вызовов, если это возможно.
Обеспечьте согласованность данных, фиксируемых различными элементами приложения, так как это может помочь при анализе событий и их сопоставлении с запросами пользователей. Рассмотрите возможность использования комплексного и настраиваемого пакета ведения журналов, чтобы осуществлять сбор данных, а не надеяться на то, что разработчики реализуют один и тот же подход в различных частях системы. Собирайте данные из счетчиков производительности, например объем выполненных операций ввода-вывода, использование сети, число запросов, использование памяти и ЦП. Некоторые службы инфраструктуры могут предоставлять свои собственные счетчики производительности, например количество подключений к базе данных, скорость выполнения транзакций, а также число успешных и неудачных транзакций. Приложения также могут определять свои собственные счетчики производительности.
Регистрируйте в журнале все вызовы к внешним службам, таким как системы баз данных, веб-службы или другие службы уровня системы, предоставляемые в составе инфраструктуры. Регистрируйте сведения о времени выполнения каждого вызова, а также о его успешном или неудачном результате. Если это возможно, фиксируйте сведения обо всех повторных попытках и сбоях для любых возникающих временных ошибок.
Обеспечение совместимости с системами телеметрии
Во многих случаях сведения, созданные с помощью инструментирования, выдаются в виде ряда событий и передаются в отдельную систему телеметрии для обработки и анализа. Система телеметрии обычно не привязана к конкретному приложению или технологии, однако она ожидает, что сведения будут следовать определенному формату, который обычно определяется схемой. Схема фактически указывает контракт, определяющий типы и поля данных, которые система телеметрии может принимать. Схема должна быть обобщенной, чтобы обеспечить прием данных, поступающих с разных платформ и устройств.
Общая схема должна включать в себя поля, которые являются общими для всех событий инструментирования, например имя события, время события, IP-адрес отправителя и сведения, необходимые для корреляции с другими событиями (например идентификатор пользователя, идентификатор устройства и идентификатор приложения). Помните, что события могут возникать на любом числе устройств, поэтому схема не должна быть привязана к типу устройства. Кроме того, события для одного приложения могут быть вызваны несколькими различными устройствами; приложение может поддерживать перенос данных или другие формы распределения между разными устройствами.
Схема также может включать в себя поля домена, имеющие отношение к конкретному сценарию, который является общим для различных приложений. Это может быть информация об исключениях, событиях начала и окончания приложения, а также об успешном выполнении или сбое вызовов API веб-службы. Все приложения, использующие один и тот же набор полей домена, должны выдавать одинаковый набор событий, позволяя сформировать единый набор отчетов и средств аналитики.
Наконец, схема может содержать настраиваемые поля для фиксирования сведений о событиях, относящихся к конкретному приложению.
Рекомендации для инструментирования приложений
В следующем списке представлены рекомендации по инструментированию распределенного приложения, работающего в облаке.
Обеспечьте простоту чтения и анализа журналов. По возможности используйте структурированное ведение журналов. Используйте краткие и содержательные сообщения журнала.
Во всех журналах определите источник, а также предоставьте контекст и сведения о синхронизации при записи каждого элемента журнала.
Используйте один часовой пояс и формат для всех меток времени. Это поможет сопоставить события для операций, охватывающих оборудование и службы в различных географических регионах.
Классифицируйте журналы и записывайте сообщения в соответствующий файл журнала.
Не раскрывайте конфиденциальные сведения о системе и личные сведения о пользователях. Очистите эти сведения перед регистрацией, убедившись при этом, что релевантные сведения сохранены. Например, удалите идентификатор и пароль изо всех строк подключения базы данных, но запишите остальную информацию в журнал, чтобы аналитик мог определить, что система обращается к нужной базе данных. Регистрируйте все критические исключения, но позвольте администратору включать и отключать ведение журналов для исключений и оповещений более низкого уровня. Кроме того, фиксируйте и регистрируйте все сведения о логике повторных попыток. Эти данные могут пригодиться при мониторинге временных состояний работоспособности системы.
Осуществляйте трассировку вызовов процесса, например запросов к внешним веб-службам или базе данных.
Не смешивайте сообщения журнала с различными требованиями к безопасности в одном файле журнала. Например, записывайте в один журнал данные отладки и данные аудита.
За исключением событий аудита, все вызовы ведения журнала должны быть самостоятельными операциями, которые не препятствуют выполнению бизнес-операций. События аудита являются исключением, поскольку они играют критически важную роль для бизнеса и могут быть классифицированы в качестве основной части бизнес-операций.
Ведение журнала должно быть расширяемым и не иметь прямых зависимостей от конкретной цели. Например, вместо записи данных с помощью System.Diagnostics.Trace определите абстрактный интерфейс (такой как ILogger), предоставляющий методы ведения журнала, которые можно реализовать с помощью любых соответствующих средств.
Все процедуры ведения журнала должны быть отказоустойчивыми и не вызывать никаких каскадных ошибок. Ведение журнала не должно вызывать никаких исключений.
Рассматривайте инструментирование как непрерывный итеративный процесс и просматривайте журналы на регулярной основе, а не только в случае возникновения проблемы.
Сбор и хранение данных
Этап сбора в рамках процесса мониторинга отвечает за получение информации, главным образом посредством инструментирования, форматирование этих данных, служащее для облегчения их использования на этапе анализа и диагностики, и сохранение преобразованных данных в надежном хранилище. Данные инструментирования, собираемые из различных частей распределенной системы, могут храниться в различных расположениях и форматах. Например, код приложения может создавать файлы журнала трассировки и данные журнала событий приложения, в то время как сведения счетчиков производительности, которые отслеживают ключевые аспекты инфраструктуры, используемой приложением, можно фиксировать с помощью других технологий. Все компоненты сторонних производителей и служб, используемых приложением, могут предоставлять данные инструментирования в различных форматах, применяя файлы трассировки, больших двоичных объектов хранилища или даже пользовательского хранилища данных.
Сбор данных часто выполняется путем реализации службы сбора, которая может выполняться автономно от приложения, создающего данные инструментирования. На рисунке 2 показан пример такой архитектуры с акцентом на подсистеме сбора данных инструментирования.
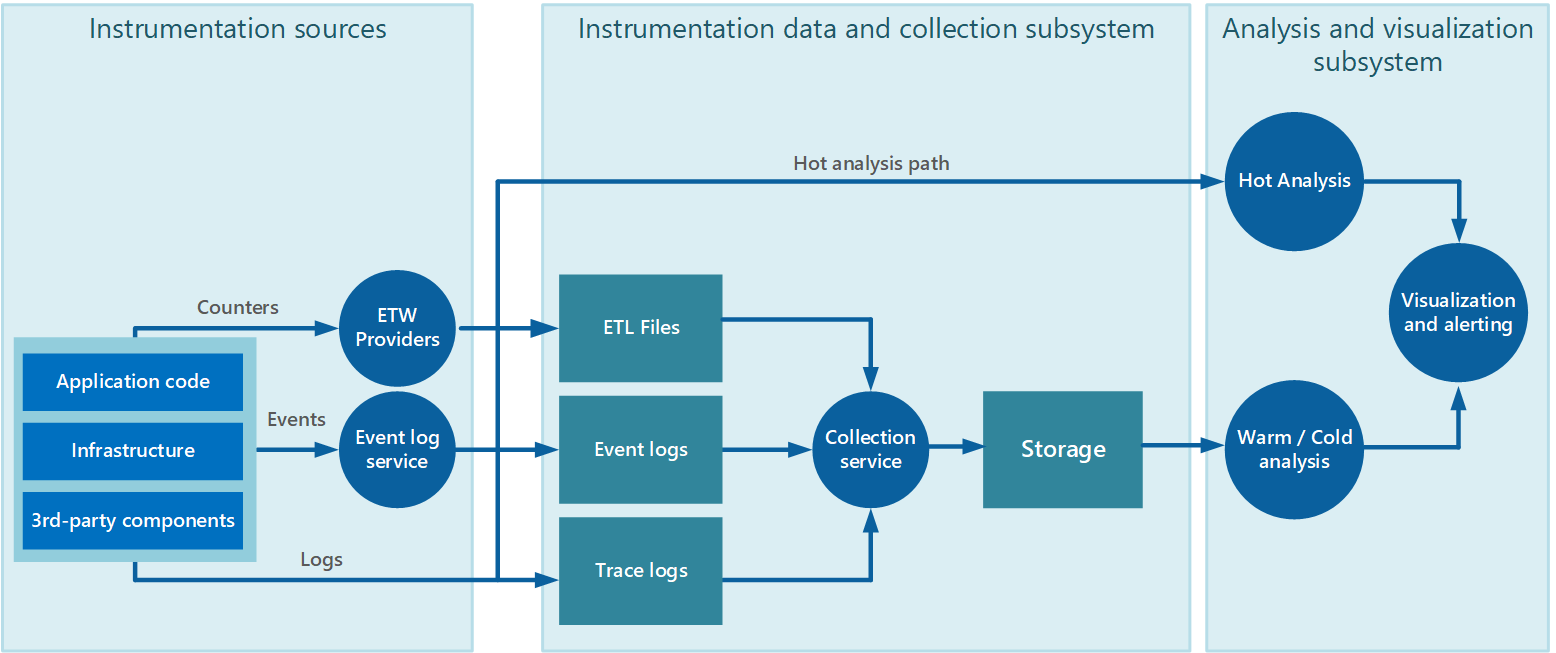
Рис. 2. Сбор данных инструментирования
Обратите внимание, что данное представление заметно упрощено. Служба сбора необязательно является отдельным процессом и может состоять из множества частей, работающих на разных компьютерах, как описано в следующих разделах. Кроме того, если анализ некоторых данных телеметрии необходимо выполнить быстро (горячий анализ, как описано в разделе Поддержка горячего, теплого и холодного анализа далее в этом документе), локальные компоненты, работающие за пределами службы сбора, могут выполнять задачи анализа немедленно. На рисунке 2 показана такая ситуация для выбранных событий. После аналитической обработки результаты могут направляться непосредственно в подсистему визуализации и оповещений. Данные, подвергаемые теплому или холодному анализу, в ожидании обработки находятся в хранилище.
Для приложений и служб Azure система диагностики Azure предоставляет одно возможное решение для фиксации данных. Система диагностики Azure собирает данные из указанных ниже источников для каждого вычислительного узла, выполняет статистическую обработку, а затем отправляет их в службу хранилища Azure.
- Журналы IIS
- Журналы неудачно завершенных запросов IIS
- журналы событий Windows;
- Счетчики производительности
- Аварийные дампы
- Журналы инфраструктуры системы диагностики Azure
- Пользовательские журналы ошибок
- .NET EventSource
- Трассировка событий Windows на основе манифестов
Дополнительные сведения см. в статье Azure: основы телеметрии и устранения неполадок.
Стратегии для сбора данных инструментирования
Учитывая эластичный характер облака, а также во избежание необходимости ручного извлечения данных телеметрии из каждого узла в системе следует обеспечить передачу данных в центральное расположение и последующую их консолидацию. В системе, которая охватывает несколько центров обработки данных, может быть удобно сначала собрать, консолидировать и сохранить данные в отдельных регионах, а затем выполнить статистическую обработку этих данных в единой центральной системе.
Чтобы оптимальнее использовать пропускную способность, можно переносить менее срочные данные фрагментами, такими как пакеты. Однако данные не следует задерживать на неопределенно долгое время, особенно в том случае, если они содержат информацию, учитывающую временной контекст.
Извлечение и отправка данных инструментирования
Подсистема сбора данных инструментирования может либо активно извлекать данные инструментирования из различных журналов и других источников для каждого экземпляра приложения (модель извлечения), либо выступать в качестве пассивного получателя, ожидая отправки данных из компонентов, составляющих каждый экземпляр приложения (модель отправки).
Один из способов реализации модели извлечения заключается в использовании агентов мониторинга, выполняемых локально для каждого экземпляра приложения. Агент мониторинга — это отдельный процесс, который периодически извлекает данные телеметрии,собранные на локальном узле, и записывает эту информацию в централизованное хранилище, которое является общим для всех экземпляров данного приложения. Это механизм реализуется системой диагностики Azure. Каждый экземпляр веб-роли или рабочей роли Azure можно настроить для фиксации диагностической информации и других сведений трассировки, которые хранятся локально. Агент мониторинга, выполняемый параллельно с каждым экземпляром, копирует указанные данные в службе хранилища Azure. Дополнительные сведения об этом процессе см. на странице Включение диагностики для виртуальных машин и облачных служб Azure. Некоторые элементы, такие как журналы IIS, аварийные дампы и журналы настраиваемых ошибок, записываются в хранилище больших двоичных объектов, а данные из журнала событий Windows, событий трассировки событий Windows и счетчиков производительности — в табличное хранилище. Данный механизм показан на рисунке 3.

Рис. 3. Использование агента мониторинга для извлечения информации и записи ее в общее хранилище
Примечание.
Использование агента мониторинга идеально подходит для сбора данных инструментирования, которые извлекаются из источника данных естественным образом, например сведений из административных представлений SQL Server или длины очереди в служебной шине Azure.
Описанный способ позволяет сохранять данные телеметрии для небольшого приложения, выполняемого на ограниченном числе узлов в одном расположении. При этом сложное, крупномасштабное и глобальное облачное приложение может легко создавать огромные объемы данных из сотен рабочих ролей и веб-ролей, сегментов баз данных и других служб. Этот стремительный поток данных может легко превысить пропускную способность ввода-вывода, доступную в едином центральном расположении. Поэтому ваше решение телеметрии должно быть масштабируемым, чтобы не превратиться в узкое место при расширении системы. Кроме того, в идеале в нем должна быть предусмотрена определенная степень избыточности, снижающая риск потери важных данных мониторинга (например, данных аудита или выставления счетов) в случае отказа части системы.
Решить это проблему можно путем внедрения очередей, как показано на рисунке 4. В этой архитектуре локальный агент мониторинга (если он может быть настроен соответствующим образом) или служба сбора пользовательских данных (если это невозможно) помещает данные в очередь, а отдельный асинхронный процесс (служба записи в хранилище на рисунке 4) принимает данные из этой очереди и записывает их в общее хранилище. Очередь сообщений подходит для данного сценария, так как предоставляет минимум одну семантику, гарантирующую, что после помещения в очередь данные не будут потеряны. Службу записи в хранилище можно реализовать с помощью отдельной рабочей роли.
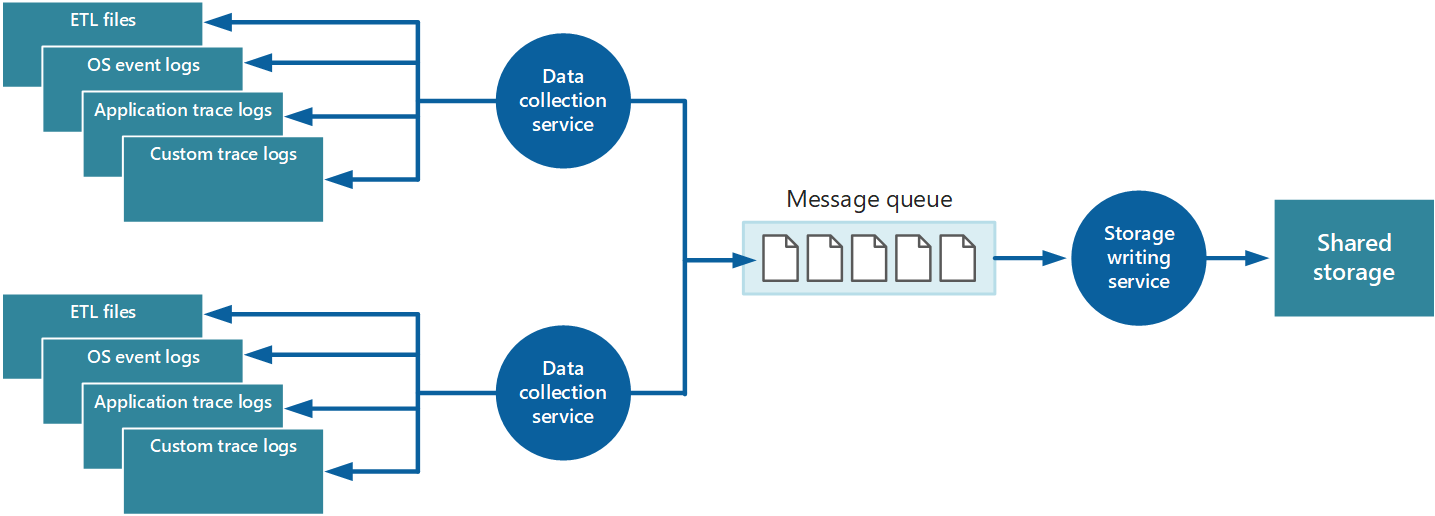
Рис. 4. Использование очереди для буферизации данных инструментирования
Локальная служба сбора данных может добавлять данные в очередь сразу же после их получения. Очередь выступает в качестве буфера, и служба записи в хранилище может извлекать и записывать данные в приемлемом для нее темпе. По умолчанию очередь работает по принципу FIFO, однако если сообщения содержат данные, которые должны обрабатываться быстрее, продвижение по очереди можно ускорить, назначив сообщениям приоритеты. Дополнительную информацию см. в статье Шаблон очереди с приоритетом. Кроме того, в зависимости от необходимой формы аналитической обработки можно использовать различные каналы (например разделы служебной шины) для передачи данных в различные назначения.
Для обеспечения масштабируемости можно запустить несколько экземпляров службы записи в хранилище. При наличии большого количества событий можно использовать концентратор событий для подготовки данных к отправке в различные вычислительные ресурсы для обработки и хранения.
Консолидация данных инструментирования
Данные инструментирования, полученные службой сбора данных из одного экземпляра приложения, предоставляют локальное представление о работоспособности и производительности этого экземпляра. Для оценки общей работоспособности системы необходимо консолидировать некоторые аспекты данных из локальных представлений. Это можно сделать после сохранения данных, однако в некоторых случаях это можно осуществить и во время сбора данных. Вместо записи непосредственно в общее хранилище данные инструментирования можно передать через отдельную службу консолидации данных, которая объединяет данные и выступает в качестве фильтра и процесса очистки. Например, данные инструментирования, включающие в себя одни и те же данные корреляции, например идентификатор действия, можно совместить (Возможно, пользователь начинает выполнять бизнес-операцию на одном узле, а затем передается другому узлу в случае сбоя узла или в зависимости от того, как настроена балансировка нагрузки.) Этот процесс также может обнаруживать и удалять повторяющиеся данные (всегда возможно, если служба телеметрии использует очереди сообщений для отправки данных инструментирования в хранилище). На рисунке 5 показан пример этой структуры.
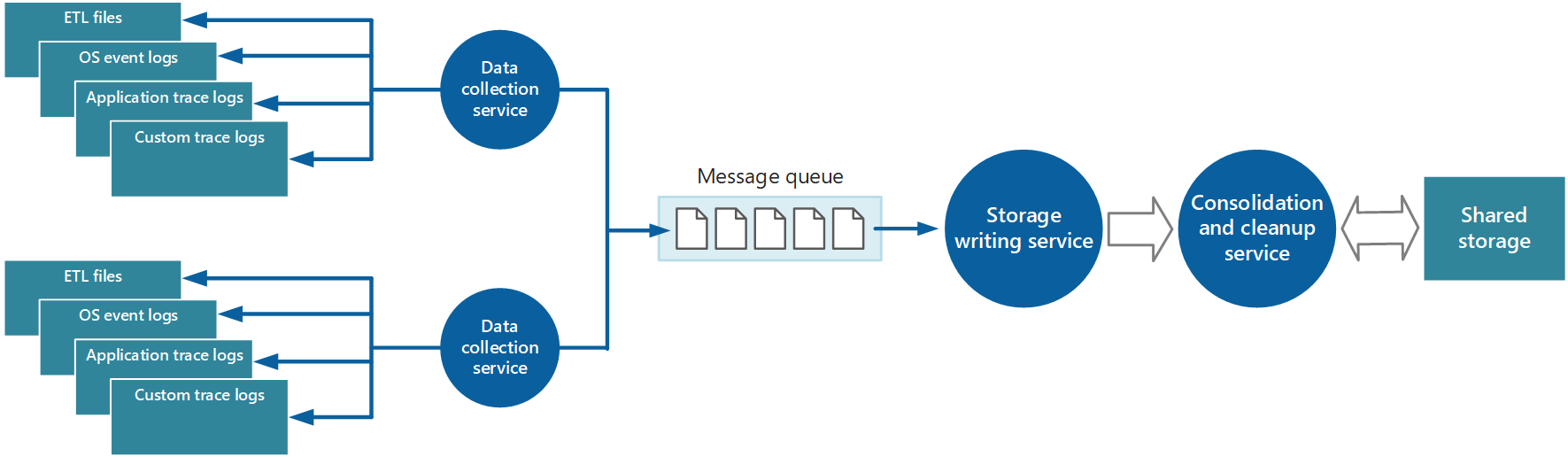
Рис. 5. Использование отдельной службы для консолидации и очистки данных инструментирования
Хранение данных инструментирования
В рамках предыдущего обсуждения было дано довольно упрощенное представление о способе хранения данных инструментирования. На самом деле имеет смысл хранить различные типы данных с использованием технологий, которые лучше всего подходят для каждого из этих типов.
Например, табличное хранилище и хранилище больших двоичных объектов Azure имеют некоторое сходство механизмов доступа, однако для них действуют ограничения, касающиеся доступных операций, кроме того, эти хранилища значительно отличаются по степени детализации содержащихся в них данных. Если необходимо выполнять больше аналитических операций или требуются возможности полнотекстового поиска по данным, может быть удобнее использовать то хранилище, возможности которого оптимизированы под определенные типы запросов и доступа к данным. Например:
- Данные счетчика производительности можно сохранять в базу данных SQL для проведения расширенного анализа.
- Журналы трассировки лучше хранить в Azure Cosmos DB.
- Сведения о безопасности можно записывать в HDFS.
- Сведения, для которых необходим полнотекстовый поиск, можно хранить с помощью гибкого поиска (который также может ускорить поиск благодаря расширенным возможностям индексирования).
Вы можете внедрить дополнительную службу, которая периодически получает данные из общего хранилища, секционирует и фильтрует эти данные, а затем записывает их в соответствующий набор хранилищ данных, как показано на рисунке 6. Альтернативный подход заключается в том, чтобы включить эту функциональность в процесс консолидации и очистки и записать данные непосредственно в эти хранилища сразу после получения, вместо помещения их в промежуточное общее хранилище. Каждый подход имеет свои преимущества и свои недостатки. Реализация отдельной службы секционирования уменьшает нагрузку на службу консолидации и очистки и позволяет при необходимости повторно создать хотя бы часть секционированных данных (в зависимости от объема данных, находящихся в общем хранилище). Однако это требует дополнительных ресурсов и может создать задержку между данными инструментирования, получаемыми из каждого экземпляра приложения, и данными, преобразуемыми в практическую информацию.
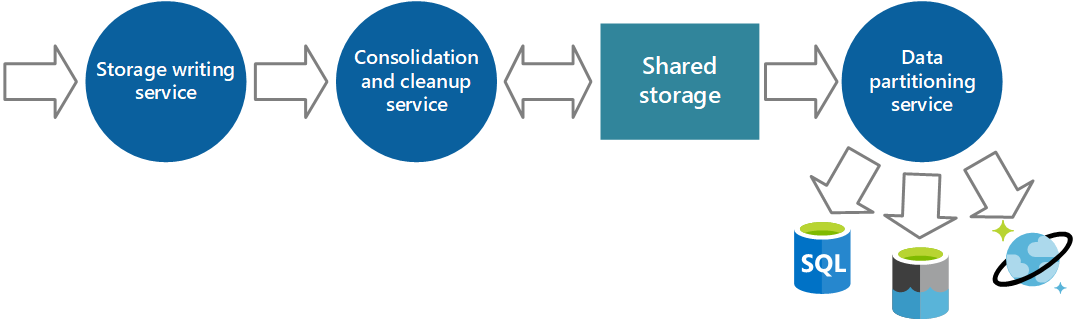
Рис. 6. Секционирование данных в соответствии с требованиями к анализу и хранилищу
Одни и те же данные инструментирования могут потребоваться для нескольких целей. Например, счетчики производительности можно использовать для предоставления исторической информации о производительности системы за определенный период, а также можно объединять эти сведения с другими данными об использовании в целях получения данных для выставления счетов для клиента. В таких ситуациях одни и те же данные могут отправляться сразу в несколько назначений, например база данных документов, которая может выступать в качестве долгосрочного хранилища данных для выставления счетов и многомерного хранилища для обработки сложного анализа производительности.
Следует также учитывать, как срочно нужно получить данные. Данные, которые предоставляют сведения для выдачи оповещений, необходимо получать быстро, поэтому они должны храниться в быстродействующем хранилище и индексироваться либо структурироваться для оптимизации запросов, выполняемых системой оповещений. В некоторых случаях службе телеметрии, которая собирает данные на каждом узле, может потребоваться форматировать и сохранить данные локально, чтобы локальный экземпляр системы оповещений мог быстро выдавать уведомления о любых неполадках. Те же данные могут подготавливаться к отправке в службу записи в хранилище, показанную на предыдущих схемах, и храниться централизованно, если это необходимо для других целей.
Сведения, используемые для более взвешенного анализа, ведения отчетов и выявления тенденций, относятся к менее срочным и могут храниться таким способом, который поддерживает интеллектуальный анализ данных и специализированные запросы. Дополнительные сведения см. в разделе Поддержка горячего, теплого и холодного анализа далее в этом документе.
Ротация журналов и удержание данных
Инструментирование может создавать значительные объемы данных. Эти данные могут храниться в нескольких местах, начиная с необработанных файлов журналов, файлов трассировки, а также других сведений, фиксируемых на каждом узле, и заканчивая консолидированным, очищенным и секционированным представлением этих данных, находящимся в общем хранилище. В некоторых случаях после обработки и передачи данных может производиться удаление исходных необработанных данных с каждого узла. В других случаях может быть необходимо или удобно сохранить эти необработанные данные. Например, данные, созданные в целях отладки, сначала лучше оставить в необработанном виде, однако после исправления ошибок эти данные довольно быстро удаляются.
Данные о производительности часто имеют более длительный жизненный цикл, чтобы их можно было использовать для выявления тенденций производительности и для планирования емкости. Консолидированное представление этих данных обычно хранится в системе в течение ограниченного времени для обеспечения быстрого доступа, после чего оно может быть заархивировано или удалено. Данные, собранные для отслеживания использования и выставления счетов клиентам, может потребоваться хранить неограниченное время. Кроме того, нормативные документы могут требовать архивации и сохранения сведений, собранных в целях аудита и обеспечения безопасности. Эти данные также являются конфиденциальными, что может потребовать их шифрования или иной защиты от незаконного изменения. Никогда не следует записывать такую информацию, как пароли пользователей или другие сведения, которые можно использовать для мошенничества с идентификацией. Все эти сведения следует удалять из данных перед их сохранением.
Понижающая выборка
Для отслеживания долгосрочных тенденций полезно сохранять исторические данные. Вместо сохранения старых данных целиком можно попытаться выполнить понижающую выборку данных, чтобы уменьшить их разрешение и снизить расходы на хранение. Например, вместо сохранения поминутных показателей эффективности можно консолидировать данные старше одного месяца в виде почасового представления.
Рекомендации для сбора и хранения сведений журналов
В следующем списке представлены рекомендации по сбору и хранению сведений журналов:
Агент мониторинга или служба сбора данных должны запускаться в виде внепроцессной службы и быть простыми для развертывания.
Все выходные данные агента мониторинга или службы сбора данных должны иметь формат, не зависящий от компьютера, операционной системы или сетевого протокола. Например, выводите информацию в формате с самоописанием, таком как JSON, MessagePack или Protobuf, а не в формате ETL-ETW. Применение стандартного формата позволяет системе создавать конвейеры обработки; компоненты, которые осуществляют чтение, преобразование и вывод данных в согласованном формате, можно легко интегрировать.
Процесс мониторинга и сбора данных должен быть отказоустойчивым и никогда не вызывать каскадных ошибок.
В случае временного сбоя при отправке данных в приемник агент мониторинга или служба сбора данных должны быть готовы переупорядочить данные телеметрии, чтобы сначала отправлялись самые новые сведения (агент мониторинга или служба сбора данных могут самостоятельно определить, следует ли удалить более старые данные или сохранить их локально и дослать позже).
Анализ данных и диагностика неполадок
Важной частью процесса мониторинга и диагностики является анализ собранных данных для получения представления об общей работоспособности системы. Вы должны определять собственные ключевые показатели эффективности и метрики производительности, и важно понимать, как именно можно структурировать собранные данные в соответствии с потребностями анализа. Кроме того, важно понимать, как соотносятся данные, зафиксированные в различных метриках и файлах журнала, поскольку эта информация может играть ключевое значение при отслеживании последовательности событий и помочь диагностировать возникающие проблемы.
Как описано в разделе Консолидация данных инструментирования, данные для каждой части системы обычно фиксируются локально, однако в общем случае их необходимо объединить с данными, созданными в других частях системы. Такая информация требует тщательной корреляции, чтобы обеспечить точное совмещение данных. Например, данные об использовании для операции могут охватывать узел, где размещен веб-сайт, к которому подключается пользователь, узел, где выполняется отдельная служба, к которой осуществляется доступ в рамках данной операции, а также хранилище данных, располагающееся на еще одном узле. Эти данные должны быть связаны вместе, чтобы давать общее представление об использовании ресурсов и обработке для этой операции. Некоторую предварительную обработку и фильтрацию данных можно осуществлять на том узле, где эти данные фиксируются, однако статистическая обработка и форматирование лучше выполнять на центральном узле.
Поддержка горячего, теплого и холодного анализа
Анализ и переформатирование данных для визуализации, отчетов и оповещений могут быть сложным процессом, который использует свой собственный набор ресурсов. Некоторые виды мониторинга строго ограничены во времени и требуют реализации немедленного анализа данных. Это называется горячим анализом. В качестве примера можно привести анализы, необходимые для выдачи оповещений и некоторых аспектов мониторинга безопасности (например обнаружения атак на систему). Данные, необходимые для этих целей, должны быть оперативно доступны и структурированы для обеспечения эффективной обработки. В некоторых случаях может потребоваться переместить аналитическую обработку на отдельные узлы, где хранятся соответствующие данные.
Другие виды анализа менее ограничены во времени и могут потребовать выполнения некоторых вычислений и статистической обработки после получения необработанных данных. Это называется теплым анализом. К этой категории часто относится анализ производительности. В данном случае отдельное и изолированное событие производительности, скорее всего, не будет статистически значимым (Это может быть вызвано внезапным пиком или сбоем.) Данные из серии событий должны обеспечить более надежную картину производительности системы.
Теплый анализ может также использоваться для диагностики проблем с работоспособностью. Событие работоспособности обычно обрабатывается с применением горячего анализа и может немедленно вызвать оповещение. Оператор должен иметь возможность детализировать причины для события работоспособности, изучив данные из теплого пути. Эти данные должны содержать информацию о событиях, которые ведут к проблеме, вызванной событием работоспособности.
Некоторые типы мониторинга создают данные в течение более длительного периода, поэтому анализ может выполняться позднее, возможно, в соответствии с ранее определенным графиком. В некоторых случаях анализ может потребовать сложной фильтрации больших объемов данных, собранных за некоторый период времени. Это называется холодным анализом. Основное требование заключается в том, что после фиксации данные должны храниться в безопасном месте. Например, мониторинг использования и аудит требуют наличия точного представления о состоянии системы в обычные моменты времени, однако эта информация о состоянии недоступна для обработки сразу после сбора.
Холодный анализ можно применять в целях предоставления данных для прогнозного анализа работоспособности. Исторические сведения, собранные за указанный период, можно использовать совместно с текущими данными о работоспособности (полученные путем горячего анализа) для определения тенденций, которые вскоре могут привести к проблемам с работоспособностью. В этих случаях может потребоваться выдавать оповещение, чтобы разрешить выполнение корректирующего действия.
Корреляция данных
Данные, зафиксированные функцией инструментирования, могут представлять собой моментальный снимок состояния системы, однако задача анализа состоит в том, чтобы сделать их пригодными для принятия практических решений. Например:
- что именно вызвало активное выполнение операций ввода-вывода на уровне системы в определенное время?
- Является ли это результатом большого количества операций с базой данных?
- Затронуло ли это время отклика базы данных число транзакций в секунду и время отклика приложений в том же участке кода?
Если это так, то одно из корректирующих действий, позволяющее снизить нагрузку, может заключаться в сегментировании данных по нескольким серверам. Кроме того, из-за ошибки на любом уровне системы могут возникать исключения, а исключение на одном уровне часто вызывает ошибку на уровне выше.
По этим причинам необходимо иметь возможность сопоставлять различные типы данных мониторинга на каждом уровне для получения общего представления о состоянии системы и приложений, которые в ней выполняются. Затем можно использовать эту информацию для принятия решений о том, правильно ли функционирует система, и для определения способов улучшения качества этой системы.
Как описано в разделе Сведения о корреляции данных, необходимо убедиться, что необработанные данные инструментирования включают в себя достаточно контекста и действий об идентификаторах действий, чтобы обеспечить необходимую статистическую обработку коррелирующих событий. Кроме того, эти данные могут храниться в различных форматах и может потребоваться проанализировать эти сведения для преобразования их в стандартный формат для анализа.
Устранение неполадок и диагностика проблем
Диагностика должна позволять определить причину ошибки или непредвиденного поведения, включая выполнение анализа основных причин. Необходимые сведения обычно включают в себя следующее:
- Подробные сведения из журналов событий и трассировок для всей системы или заданной подсистемы в рамках указанного интервала.
- Полные трассировки стека, которые вызваны исключениями и сбоями любого указанного уровня, возникающими в системе или заданной подсистеме в рамках указанного периода.
- Аварийные дампы для всех процессов, завершившихся сбоем в любом месте системы или в заданной подсистеме в рамках указанного интервала.
- Журналы изменений, которые регистрируют операции, выполняемые всеми пользователями либо выбранными пользователями в рамках указанного периода.
Чтобы выполнить анализ данных для устранения неполадок, часто требуются углубленные технические знания об архитектуре системы и различных компонентах, составляющих такое решение. В результате этот процесс часто требует значительного вовлечения пользователя для интерпретации данных, выявления причины возникающих проблем и подбора подходящей стратегии их устранения. Возможно, будет уместно просто сохранить копию этих сведений в исходном формате и предоставить ее специалисту для холодного анализа.
Визуализация данных и выдача оповещений
Важным аспектом любой системы мониторинга является возможность представления данных таким образом, чтобы оператор мог быстро выявить любые тенденции или проблемы, а также возможность быстрого оповещения оператора о значительном событии, которое может потребовать его внимания.
Представление данных может принимать различные формы, включая визуализацию с помощью панелей мониторинга, выдачу оповещений и ведение отчетов.
Визуализация с помощью панелей мониторинга
Наиболее распространенным способом визуализации данных является использование панелей мониторинга, которые могут отображать информацию в виде ряда диаграмм, графиков и других графических средств. Эти элементы можно параметризовать, а аналитик должен быть в состоянии выбрать важные параметры (например период времени) для любой конкретной ситуации.
Панели мониторинга можно упорядочить иерархически. Панели мониторинга верхнего уровня дают общее представление по каждому аспекту системы, однако оператор может выполнить детализацию, углубившись в подробности. Например, панель мониторинга, которая дает общее представление дискового ввода-вывода для системы, должна позволять аналитику просматривать скорости ввода-вывода для каждого отдельного диска, чтобы выяснить, является ли одно или несколько устройств источниками непропорционального объема трафика. В идеале панель мониторинга также должна отображать связанные сведения, такие как источник каждого запроса (пользователь или действие), создающего эти операции ввода-вывода. Затем эту информацию можно использовать, чтобы определить, требуется ли (и как именно) равномернее распределить нагрузку между устройствами и будет ли система работать лучше при добавлении дополнительных устройств.
Панель мониторинга также может допускать использование цветового кодирования или других визуальных средств для выделения значений, которые являются аномальными или выходят за пределы ожидаемого диапазона. В предыдущем примере:
- Диск, у которого скорость ввода-вывода уже длительное время находится на максимальном уровне, можно выделить красным цветом.
- Диск, у которого скорость ввода-вывода периодически недолго находится на максимальном уровне, можно выделить желтым цветом.
- Диск, работающий в обычном режиме, можно выделить зеленым цветом.
Обратите внимание, что для эффективной работы системы панелей мониторинга ей требуются необработанные данные. Если вы создаете собственную систему панелей мониторинга или используете панель мониторинга, разработанную другой организацией, следует понимать, какие данные инструментирования необходимо собирать, какая степень детализации необходима и как именно форматировать эти данные для дальнейшего использования панелью мониторинга.
Хорошая панель мониторинга не только отображает сведения, но и позволяет аналитику задавать специализированные вопросы в отношении этих сведений. Некоторые системы предоставляют средства управления, с помощью которых оператор может выполнять эти задачи и просматривать данные. Кроме того, в зависимости от того, какой репозиторий используется для хранения этих сведений, может быть доступна возможность непосредственного запроса этих данных или их импорта в такие средства, как Microsoft Excel, для дальнейшего анализа и составления отчетов.
Примечание.
Доступ к панелям мониторинга следует предоставить только авторизованному персоналу, поскольку содержащаяся в них информация может представлять собой коммерческую тайну. Также следует защитить базовые данные, представленные в панели мониторинга, чтобы запретить пользователям изменять их.
Выдача оповещений
Оповещения — это процесс анализа данных мониторинга и инструментирования с выдачей уведомления в случае обнаружения значительного события.
Функция оповещений позволяет гарантировать работоспособность и безопасность системы, а также ее реагирование на запросы. Она является важной частью любой системы, которая дает пользователям гарантии относительно производительности, доступности и конфиденциальности, а также требует немедленного принятия мер на базе определенных данных. Может потребоваться уведомить оператора о событии, вызвавшем оповещение. Оповещения также можно использовать для вызова системных функций, таких как автоматическое масштабирование.
Оповещения обычно зависят от следующих данных инструментирования.
- События безопасности. Если журналы событий указывают на то, что происходят повторяющиеся сбои проверки подлинности или авторизации, система может находиться под атакой, и оператор должен быть проинформирован.
- Метрики производительности. Система должна быстро реагировать на превышение какой-либо метрикой заданного порогового значения.
- Сведения о доступности. В случае обнаружения сбоя может потребоваться быстро перезагрузить одну или несколько подсистем либо выполнить отработку отказа на резервный ресурс. Повторяющиеся ошибки в подсистеме могут указывать на наличие более серьезных проблем.
Операторы могут получать оповещения по многим каналам, таким как электронная почта, сообщения на пейджер или SMS-сообщения. Оповещение также может включать сведения о том, как именно возникла данная критическая ситуация. Во многих системах оповещений поддерживаются группы подписчиков, поэтому всем операторам, которые являются членами одной группы, может быть отправлен одинаковый набор оповещений.
Система оповещений должна быть настраиваемой, а соответствующие значения из базовых данных инструментирования могут предоставляться в качестве параметров. Такой подход позволяет оператору фильтровать данные и сосредоточиться на тех пороговых значениях или сочетаниях значений, которые представляют для него интерес. Обратите внимание, что в некоторых случаях системе оповещений могут предоставляться необработанные данные инструментирования, хотя в других случаях будет более уместно предоставлять статистически обработанные данные (например, оповещение может выдаваться, если уровень использования ЦП для узла превышает значение 90 % в течение последних 10 минут). Сведения, представленные системе оповещений, также должны включать все соответствующие сводные и контекстные сведения, поскольку они помогают снизить вероятность выдачи оповещений по ложноположительным событиям.
Отчетность
Ведение отчетов используется для создания общего представления системы и может включать в себя исторические данные, а также актуальные сведения. Требования к ведению отчетов делятся на две большие категории: операционные отчеты и отчеты о безопасности.
Операционные отчеты обычно включают в себя следующие аспекты.
- Статистическая обработка, позволяющая понять использование ресурсов в рамках всей системы или указанных подсистем в течение заданного интервала.
- Определение тенденций использования ресурсов для всей системы или указанных подсистем в течение заданного периода.
- Мониторинг исключений, возникших во всей системе или в указанных подсистемах в течение заданного периода.
- Определение эффективности приложения с точки зрения развернутых ресурсов и возможности сокращения объема этих ресурсов (и связанных с ними расходов) без негативного влияния на производительность.
Отчеты о безопасности посвящены отслеживанию использования системы клиентом и могут содержать следующие данные:
- Аудит операций пользователя. для этого требуется регистрировать отдельные запросы каждого пользователя с указанием даты и времени. Данные должны быть структурированы, чтобы администратор мог быстро воссоздать последовательность операций, выполненных конкретным пользователем в течение указанного времени.
- Отслеживание использования ресурсов пользователем. для этого требуется регистрировать, каким образом и как долго каждый запрос пользователя осуществляет доступ к различным ресурсам, из которых состоит система. Администратор должен иметь возможность использовать эти данные для создания отчета по применению для конкретного пользователя за указанный период времени, например для выставления счетов.
Во многих случаях отчеты могут создаваться процессами пакетной обработки согласно заданному расписанию (Задержка обычно не является проблемой.) Но они также должны быть доступны для создания на нерегламентированной основе при необходимости. Например, если вы храните данные в реляционной базе данных, например Базе данных SQL Azure, можно использовать такое средство, как SQL Server Reporting Services, для извлечения и форматирования данных и представления их в виде набора отчетов.
Следующие шаги
- Общие сведения о службе Azure Monitor
- Наблюдение, диагностика и устранение неисправностей хранилища Microsoft Azure
- Обзор оповещений в Microsoft Azure
- Просмотр уведомлений о работоспособности служб на портале Azure
- Что такое Azure Application Insights?
- Диагностика производительности для виртуальных машин Azure
- Скачайте и установите средства SQL Server Data Tools (SSDT) для Visual Studio
Связанные ресурсы
- Руководстве по автомасштабированию описано, как уменьшить издержки на управление, позволив оператору реже отслеживать производительность системы и принимать решения о добавлении или удалении ресурсов.
- В статье Шаблон мониторинга конечной точки работоспособности описана реализация функциональных проверок в приложении, к которым внешние средства могут регулярно получать доступ через предоставленные конечные точки.
- В статье Шаблон очереди с приоритетом показано, как назначать приоритет сообщениям в очереди, чтобы более срочные запросы принимались и обрабатывались раньше менее срочных.