Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Microsoft Fabric
Azure Data Factory
Организации обычно должны собирать данные из нескольких источников в различных форматах и перемещать их в один или несколько хранилищ данных. Назначение может быть не таким же типом хранилища данных, что и источник, и данные часто должны быть сформированы, очищаются или преобразуются перед загрузкой.
Различные инструменты, службы и процессы помогают решить эти проблемы. Независимо от подхода, необходимо координировать работу и применять преобразования данных в конвейере данных. В следующих разделах описаны распространенные методы и методики для этих задач.
Извлечение, преобразование, загрузка (ETL)
Извлечение, преобразование, загрузка (ETL) — это процесс интеграции данных, который объединяет данные из различных источников в единое хранилище данных. На этапе преобразования данные изменяются в соответствии с бизнес-правилами с помощью специализированного механизма. Это часто включает промежуточные таблицы, которые временно хранят данные по мере обработки и в конечном итоге загружаются в место назначения.
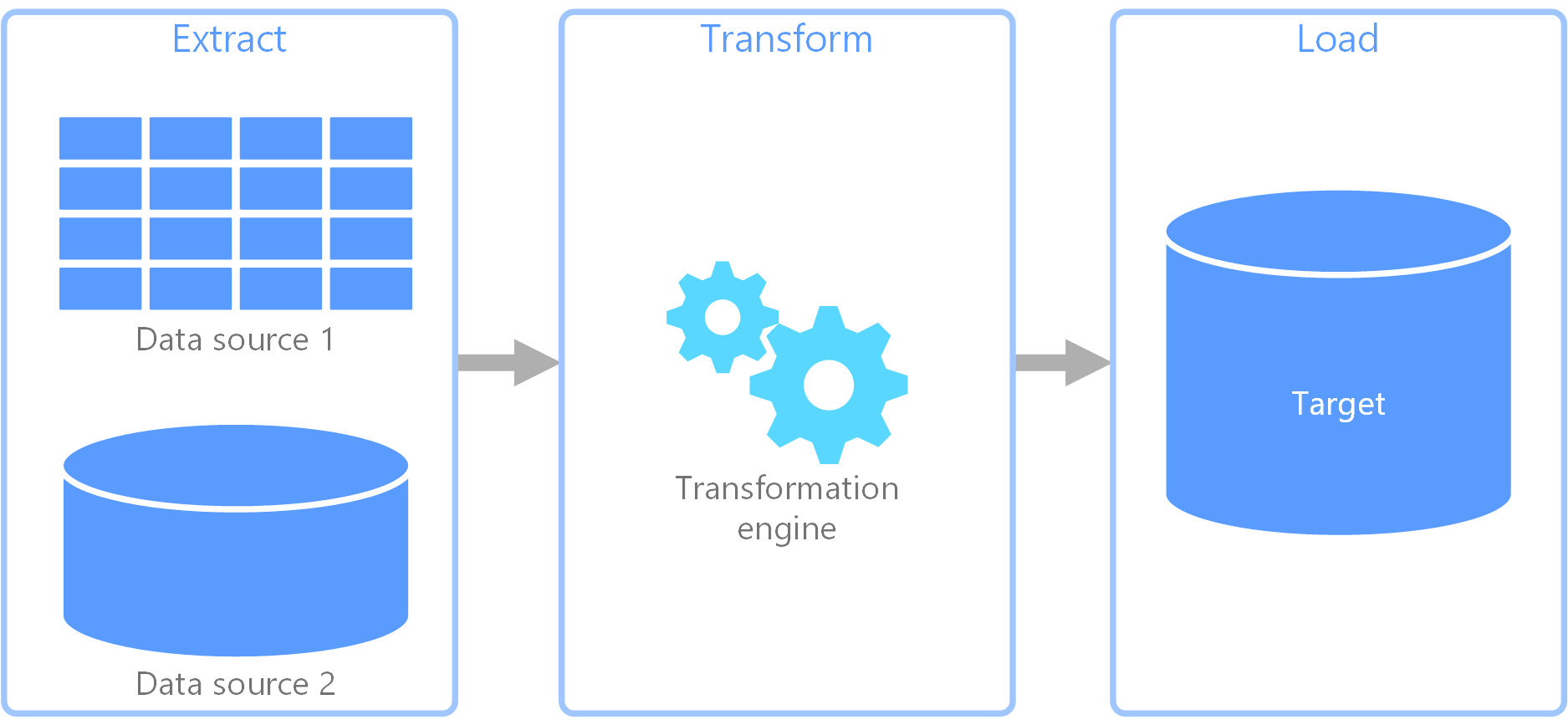
Обычно в процессе преобразования данных применяются различные операции (например, фильтрация, сортировка, агрегирование, объединение, очистка, дедупликация и проверка данных).
Часто три этапа ETL выполняются параллельно, чтобы сэкономить время. Например, при извлечении данных процесс преобразования может работать с данными, уже полученными и подготовить их к загрузке, а процесс загрузки может начать работу над подготовленными данными, а не ожидать завершения всего процесса извлечения. Обычно вы разрабатываете параллелизацию вокруг границ секции данных (дата, клиент, ключ сегмента), чтобы избежать конфликтов на запись и включить идемпотентные повторные попытки.
Соответствующая служба:
Другие средства.
Извлечение, загрузка, преобразование (ELT)
Извлечение, загрузка, преобразование (ELT) отличается от ETL исключительно в том месте, где происходит преобразование. В конвейере ELT преобразование происходит в целевом хранилище данных. В этом случае для преобразования данных вместо специальной подсистемы используются средства обработки целевого хранилища данных. Это упрощает архитектуру за счет удаления механизма преобразования из конвейера. Еще одним преимуществом этого подхода является то, что масштабирование целевого хранилища данных также улучшает производительность конвейера ELT. Тем не менее ELT работает надлежащим образом, только если целевая система имеет достаточную производительность для эффективного преобразования данных.
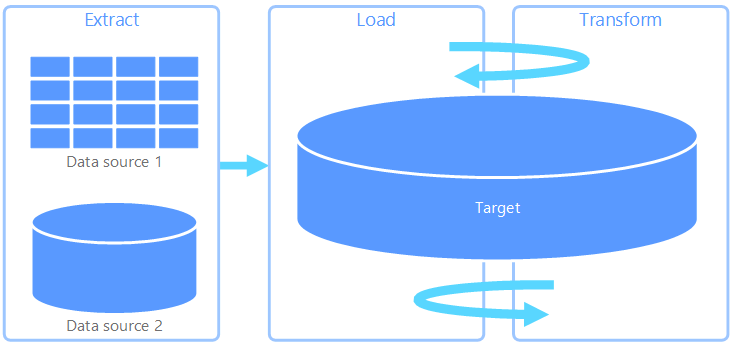
Обычно конвейер ELT применяется для обработки больших объемов данных. Например, можно начать с извлечения исходных данных в неструктурированные файлы в масштабируемом хранилище, например распределенную файловую систему Hadoop (HDFS), хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения. Затем можно использовать такие технологии, как Spark, Hive или PolyBase, для запроса исходных данных. Ключевой особенностью ELT является то, что хранилище данных, используемое для выполнения преобразования, — это то же хранилище, в котором данные в конечном счете потребляются. Это хранилище данных считывается непосредственно из масштабируемого хранилища, а не загружает данные в отдельное хранилище. Этот подход пропускает шаги копирования данных, присутствующих в ETL, что часто может занять много времени для больших наборов данных. Некоторые рабочие нагрузки материализуют преобразованные таблицы или представления для повышения производительности запросов или применения правил управления; ELT не всегда подразумевает чисто виртуализированные преобразования.
Заключительный этап конвейера ELT обычно преобразует исходные данные в формат, который эффективнее для типов запросов, которые должны поддерживаться. Например, данные могут быть секционированы по часто отфильтрованным ключам. ELT также может использовать оптимизированные форматы хранения, такие как Parquet, который является форматом хранилища столбцов, который упорядочивает данные по столбцам для включения сжатия, отправки предиката и эффективной аналитической проверки.
Соответствующая служба Майкрософт:
Выбор ETL или ELT
Выбор между этими подходами зависит от ваших требований.
Выберите ETL, когда:
- Необходимо выгрузить тяжелые преобразования от ограниченной целевой системы.
- Для сложных бизнес-правил требуются специализированные механизмы преобразования
- Требования к нормативным или нормативным требованиям обязаны курируемые промежуточные аудиты перед загрузкой
Выберите ELT, когда:
- Целевая система — это современное хранилище данных или lakehouse с эластичным масштабированием вычислений
- Необходимо сохранить необработанные данные для анализа и дальнейшего развития схемы
- Преимущества логики преобразования от собственных возможностей целевой системы
Поток данных и поток управления
В контексте конвейеров данных поток управления обеспечивает обработку набора задач в правильном порядке. Для этого используется управление очередностью. Эти ограничения можно рассматривать как соединители на схеме рабочего процесса, как показано на следующем рисунке. Каждая задача имеет результат (успешное завершение, сбой или завершение). Любая последующая задача не инициирует обработку до тех пор, пока ее предшественник не завершится с одним из этих результатов.
Потоки управления выполняют потоки данных в качестве задачи. В рамках задачи потока данных данные извлекаются из источника, преобразовываются и загружаются в хранилище данных. Выходные данные одной задачи потока данных могут использоваться в качестве входных данных для следующей задачи потока данных, а эти потоки могут выполняться одновременно. В отличие от потоков управления, нельзя добавлять ограничения между задачами в потоке данных. Однако вы можете добавить средство просмотра данных для наблюдения за данными по мере их обрабатывания каждой задачей.
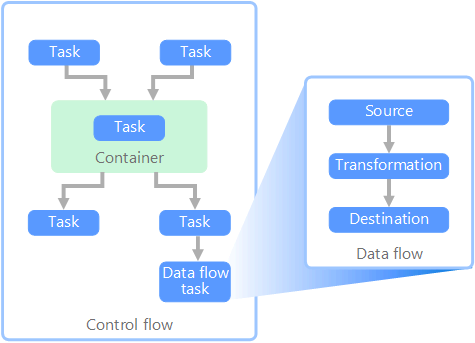
На схеме существует несколько задач в потоке управления, одна из которых является задачей потока данных. Одна из задач вложена в контейнер. Контейнеры можно использовать для обеспечения структуры задач, тем самым формируя единицу работы. Одним из примеров является повторение элементов в коллекции (например, файлы в папке или инструкции базы данных).
Соответствующая служба:
Обратное ETL
Обратный ETL — это процесс перемещения преобразованных, моделиированных данных из аналитических систем в операционные инструменты и приложения. В отличие от традиционного ETL, который передает данные из операционных систем в аналитику, обратный ETL активирует аналитические сведения путем отправки проверенных данных обратно в место, где бизнес-пользователи могут действовать с ним. В обратном конвейере ETL данные передаются из хранилищ данных, озерных домов или других аналитических хранилищ в операционные системы, такие как:
- Платформы управления отношениями клиентов (CRM)
- Средства автоматизации маркетинга
- Системы поддержки клиентов
- Базы данных рабочей нагрузки
Подход по-прежнему следует процессу извлечения, преобразования и загрузки. Этап преобразования заключается в том, что вы преобразуете из определенного формата, используемого хранилищем данных или другой системой аналитики для выравнивания по целевой системе.
Пример см. в статье об обратном извлечении, преобразовании и загрузке (ETL) с помощью Azure Cosmos DB для NoSQL .
Потоковая передача данных и архитектуры горячего пути
Если вам нужен лямбда-горячий путь или архитектуры Kappa, вы можете подписаться на источники данных по мере создания данных. В отличие от ETL или ELT, которые работают с наборами данных в запланированных пакетах, потоковая передача в режиме реального времени обрабатывает данные по мере поступления, обеспечивая немедленную аналитику и действия.
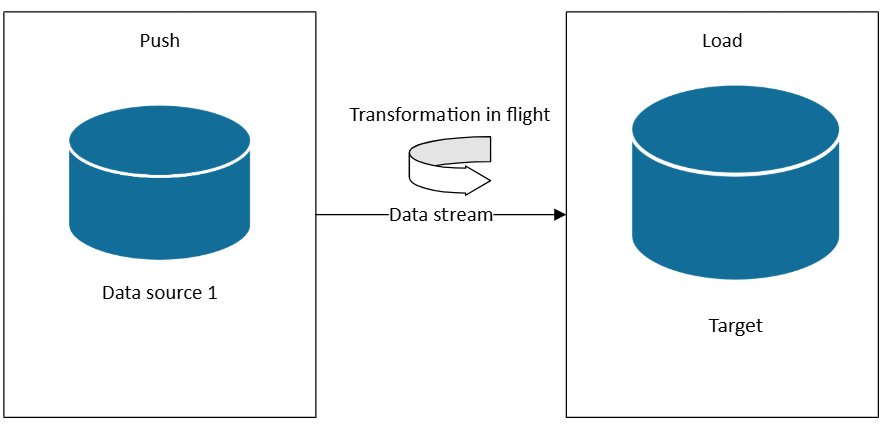
В архитектуре потоковой передачи данные передаются из источников событий в брокер сообщений или концентратор событий (например, Центры событий Azure или Kafka), а затем обрабатываются обработчиком потоков (например, Fabric Real-Time Intelligence, Azure Stream Analytics или Apache Flink). Обработчик применяет такие преобразования, как фильтрация, агрегирование, обогащение или присоединение с эталонными данными ( все в движении), прежде чем маршрутизация результатов в подчиненные системы, такие как панели мониторинга, оповещения или базы данных.
Этот подход идеально подходит для сценариев, когда низкая задержка и непрерывные обновления критически важны, например:
- Мониторинг производственного оборудования для аномалий
- Обнаружение мошенничества в финансовых сделках
- Питание панелей мониторинга в режиме реального времени для логистики или операций
- Активация оповещений на основе пороговых значений датчика
Рекомендации по надежности потоковой передачи
- Использование контрольных точек для обеспечения по крайней мере один раз обработки и восстановления после сбоев
- Преобразования проектирования, которые должны быть идемпотентными для обработки потенциальной повторяющейся обработки
- Реализация подложки для поздних событий и обработки вне порядка
- Используйте очереди недоставленных писем для сообщений, которые не могут быть обработаны
Выбор технологий
Хранилища данных:
Конвейер и оркестрация:
- Оркестрация конвейеров
- Фабрика данных Microsoft Fabric (современная оркестрация)
- Фабрика данных Azure (гибридные и нефакционные сценарии)
Lakehouse и современная аналитика: