Успешность облачного решения зависит от его надежности. Надежность в широком смысле можно определить как вероятность того, что система будет работать должным образом в течение указанного времени в соответствии с заданными условиями среды. Обеспечение надежности сайта при проектировании (SRE) — это набор принципов и рекомендаций по созданию масштабируемых и высоконадежных программных систем. SRE все чаще используется во время разработки цифровых служб, чтобы обеспечить более высокую надежность.
Дополнительные сведения о стратегиях SRE см. в разделе AZ-400: разработка стратегии обеспечения надежности сайта при проектировании (SRE).
Потенциальные варианты использования
Основные понятия, приведенные в этой статье, относятся к:
- Облачным службам на основе API.
- Общедоступным веб-приложениям.
- Рабочим нагрузкам на основе Интернета вещей или на основе событий.
Архитектура

Скачайте файл PowerPoint этой архитектуры.
Рассматриваемая здесь архитектура — это архитектура масштабируемой платформы API. Решение состоит из нескольких микрослужб, использующих разнообразные базы данных и службы хранилища, включая решения SaaS (программное обеспечение как услуга), такие как Dynamics 365 и Microsoft 365.
В этой статье рассматривается решение, которое реализует высокоуровневые варианты использования marketplace и электронной коммерции для демонстрации блоков, показанных на схеме. Варианты использования:
- Обзор продукта.
- Регистрация и вход в систему.
- Просмотр содержимого, например, новостных статей.
- Управление заказами и подписками.
Клиентские приложения, такие как веб-приложения, мобильные приложения и даже приложения служб, используют службы платформы API с помощью унифицированного пути доступа https://api.contoso.com.
Компоненты
- Azure Front Door предоставляет защищенную единую точку входа для всех запросов, которые отправляются к решению. Дополнительные сведения см. в разделе Общие сведения об архитектуре маршрутизации.
- Управление API Azure предоставляет уровень управления поверх всех опубликованных API. Политики Управления API Azure можно использовать для применения дополнительных возможностей на уровне API, таких как ограничение доступа, кэширование и преобразование данных. Управление API поддерживает автомасштабирование на уровнях "Стандартный" и "Премиум".
- Служба Azure Kubernetes (AKS) — это реализация кластеров Kubernetes с открытым кодом в Azure. Размещенная в Azure служба Kubernetes отвечает за критические задачи, в частности за мониторинг работоспособности и техническое обслуживание. Так как главными узлами Kubernetes управляет платформа Azure, вы администрируете и обслуживаете только узлы агентов. В этой архитектуре все микрослужбы развертываются в AKS.
- Шлюз приложений Azure представляет собой службу контроллера доставки приложений. Он работает на уровне 7, уровне приложения и обладает различными возможностями балансировки нагрузки. Контроллер объекта ingress Шлюза приложений (AGIC) — это приложение Kubernetes, которое позволяет клиентам Службы Azure Kubernetes (AKS) использовать собственную подсистему балансировки нагрузки уровня 7 Шлюза приложений Azure, чтобы предоставлять доступ к облачному программному обеспечению через Интернет. Автомасштабирование и избыточность между зонами поддерживаются в SKU версии 2.
- В Службе хранилища Azure, Azure Data Lake Storage, Azure Cosmos DB и Azure SQL может храниться как структурированное, так и неструктурированное содержимое. Контейнеры и базы данных Azure Cosmos DB могут быть созданы с автомасштабируемой пропускной способностью.
- Microsoft Dynamics 365 — это предложение SaaS (программное обеспечение как услуга) от корпорации Майкрософт, которое предоставляет несколько бизнес-приложений в сферах обслуживания клиентов, продаж, маркетинга и финансов. В этой архитектуре Dynamics 365 преимущественно используется для управления каталогами продуктов и обслуживанием клиентов. Единицы масштабирования обеспечивают устойчивость приложений Dynamics 365.
- Microsoft 365 (ранее Office 365) используется в качестве системы управления корпоративным содержимым, созданной на основе Office 365 SharePoint Online. Эта система используется для создания, администрирования и публикации содержимого, такого как мультимедийные ресурсы и документы.
Альтернативные варианты
Так как это решение использует архитектуру на основе микрослужб с высокой степенью масштабируемости, вы можете использовать следующие альтернативные варианты для уровня вычислений:
- Функции Azure для бессерверных служб API
- Микрослужбы на основе Java для Azure Spring Apps
Подходящий уровень надежности
Степень надежности, необходимая для решения, зависит от бизнес-контекста. Розничный магазин, который работает 14 часов в день и в котором на этот период приходится пиковое использование системы, отличается от онлайн-магазина, который принимает заказы круглосуточно, с точки зрения требований. Рекомендации SRE можно адаптировать для обеспечения подходящего уровня надежности.
Надежность определяется и измеряется с помощью целей уровня обслуживания (SLO), которые определяют целевой уровень надежности для службы. Достижение целевого уровня гарантирует удовлетворение потребителей. Цели уровня обслуживания могут развиваться или изменяться в зависимости от потребностей бизнеса. Однако владельцы служб должны постоянно оценивать надежность в соответствии с SLO для обнаружения проблем и выполнения корректирующих действий. SLO обычно определяются как процентное улучшение за период.
Еще один важный термин, о котором следует сказать, — это индикатор уровня обслуживания (SLI), представляющий собой метрику, используемую для расчета SLO. SLI основаны на аналитических сведениях, полученных на основе данных, собранных по мере использования службы клиентом. SLI всегда измеряются с точки зрения клиента.
SLO и SLI всегда связаны друг с другом и обычно определяются итеративно. SLO определяются основными бизнес-целями, тогда как SLI определяются тем, что можно измерить при реализации службы.
Отношение между отслеживаемой метрикой, SLI и SLO показано ниже:
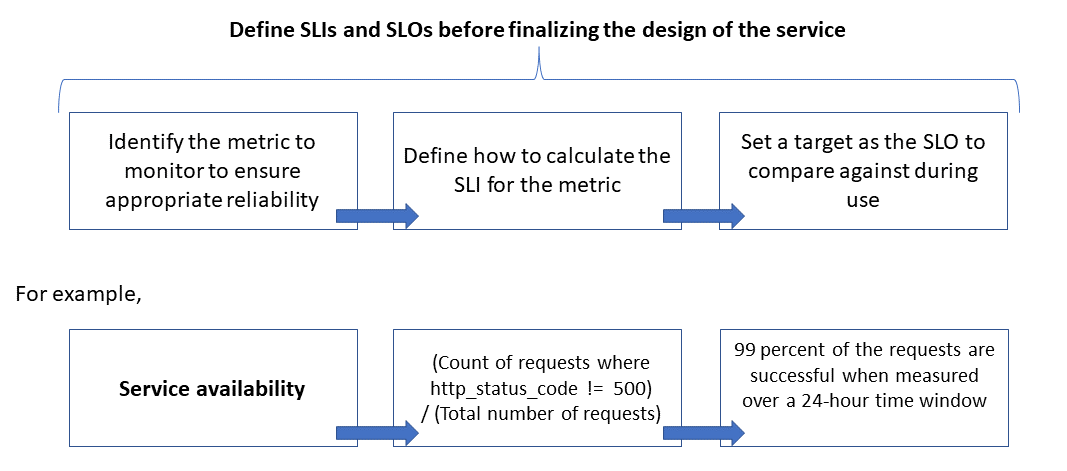
Подробное объяснение приведено в разделе Определение метрик SLI для расчета SLO.
Моделирование ожидаемой масштабируемости и производительности
Для программной системы производительность обычно обозначает общую скорость реагирования системы при выполнении действия в течение определенного времени, а масштабируемость означает способность системы справляться с повышенной пользовательской нагрузкой без снижения производительности.
Система считается масштабируемой, если базовые ресурсы предоставляются динамически для поддержки увеличения нагрузки. Облачные приложения должны создаваться с поддержкой масштабирования, при этом иногда трудно оценить конкретный объем трафика. Сезонные пиковые нагрузки могут увеличивать требования к масштабированию, особенно если служба обрабатывает запросы от нескольких клиентов.
Рекомендуется проектировать приложения таким образом, чтобы облачные ресурсы масштабировались автоматически по мере необходимости для удовлетворения нагрузки. По сути, система должна адаптироваться к увеличению рабочей нагрузки путем подготовки или выделения ресурсов в пошаговом режиме для удовлетворения спроса. Масштабируемость относится не только к вычислительным экземплярам, но и к другим элементам, таким как хранилище данных и инфраструктура обмена сообщениями.
В этой статье показано, как обеспечить достаточную надежность облачного приложения за счет моделирования масштабирования и производительности в сценариях рабочей нагрузки и использования полученных результатов для определения мониторов, SLI и SLO.
Рекомендации
Рекомендации по созданию масштабируемых и надежных приложений см. в описании критериев Надежность и Эффективность работы в разделе Платформа Azure с продуманной архитектурой.
В этой статье рассматривается применение методов моделирования масштабирования и производительности для точной настройки архитектуры и структуры решения. Эти методы определяют изменения в потоках транзакций для оптимального взаимодействия с пользователем. Используйте нефункциональные требования решения в качестве основы своих технических решений. Отправка выполняется так:
- Выявление требований к масштабируемости.
- Моделирование ожидаемой нагрузки.
- Определение SLI и SLO для пользовательских сценариев.
Примечание.
Azure Application Insights в составе Azure Monitor является мощным инструментом для управления производительностью приложений (APM), который можно легко интегрировать с приложениями для отправки данных телеметрии и анализа метрик, относящихся к приложению. Azure Application Insights также предоставляет готовые панели мониторинга и обозреватель метрик, которые можно использовать для анализа данных в целях изучения бизнес-потребностей.
Сбор требований к масштабируемости
Предположим, что у нас есть следующие метрики пиковой нагрузки:
- Число потребителей, использующих платформу API: 1 500 000
- Число активных потребителей в час (30 % от 1 500 000): 450 000
- Процент нагрузки для каждого действия:
- Просмотр продукта: 75 %
- Регистрация, включая создание профиля, и вход в систему: 10 %
- Управление заказами и подписками: 10 %
- Просмотр содержимого: 5 %
Нормальная пиковая нагрузка создает следующие требования к масштабированию для API, размещенных на платформе:
- Микрослужба продукта: около 500 запросов в секунду (RPS)
- Микрослужба профилирования: около 100 RPS
- Микрослужбы заказов и платежей: около 100 RPS
- Микрослужба содержимого: около 50 RPS
Эти требования к масштабированию не учитывают сезонные и случайные пиковые нагрузки, а также пиковые нагрузки во время специальных событий, таких как маркетинговые акции. Во время пиковых нагрузок для некоторых действий пользователей масштабирование должно поддерживать увеличение нагрузки до 10 раз по сравнению с нормальной пиковой нагрузкой. Учитывайте эти ограничения и ожидания при выборе вариантов проектирования для микрослужб.
Определение метрик SLI для расчета SLO
Метрики SLI указывают степень, до которой служба работают удовлетворительно. Эта степень может быть выражена как отношение числа хороших событий к общему числу событий.
Для службы API события ссылаются на зависящие от приложения метрики, которые захватываются во время выполнения в виде данных телеметрии или обработанных данных. В этом примере используются следующие метрики SLI:
| Метрическая | Description |
|---|---|
| Availability | Был ли запрос обработан API |
| Задержка | Время, в течение которого API обрабатывает запрос и возвращает ответ |
| Пропускная способность | Число запросов, обработанных API |
| Частота успешного выполнения | Число запросов, успешно обработанных API |
| Частота ошибок | Количество ошибок для запросов, обработанных API |
| Актуальность | Количество раз, когда пользователь получал последние данные для операций чтения в API, несмотря на то, что базовое хранилище данных обновляется с определенной задержкой записи |
Примечание.
Обязательно определите все дополнительные SLI, которые важны для вашего решения.
Ниже приведены примеры SLI:
- (Число запросов, выполненных успешно менее чем за 1 000 мс)/(число запросов)
- (Число результатов поиска, которые возвращают результат в течение трех секунд, все продукты, опубликованные в каталоге)/(число запросов поиска)
Определив SLI, укажите, какие события или данные телеметрии должны быть записаны для их измерения. Например, для измерения доступности вы собираете события, указывающие, успешно ли служба API обработала запрос. Для служб на основе HTTP успешный или неудачный результат определяется с помощью кодов состояния HTTP. Соответствующие коды должны быть предоставлены при проектировании и реализации API. Как правило, метрики SLI являются важными входными данными для реализации API.
Для облачных систем можно получить некоторые метрики, используя поддержку диагностики и мониторинга для ресурсов. Azure Monitor — это комплексное решение для сбора, анализа и использования телеметрии от облачных служб. В зависимости от требований SLI для вычисления метрик можно использовать дополнительные данные мониторинга.
Использование распределения процентилей
Некоторые SLI рассчитываются с помощью метода распределения процентилей. Это позволяет получить лучшие результаты при наличии выбросов, которые могут искажать результаты для других методов, таких как средние или медианные распределения.
Например, предположим, что метрика представляет собой задержку запросов API и пороговое значение для оптимальной производительности равно трем секундам. Отсортированное время отклика в течение часа для запросов API показывает, что на выполнение небольшой части запросов требуется более трех секунд. Время выполнения большей части запросов укладывается в ограничение. Это ожидаемое поведение системы.
Распределение процентилей предназначено для исключения выбросов, вызванных периодическими проблемами. Например, если правильные отклики службы находятся в 90-м или 95-м процентиле, SLO считается удовлетворенной.
Выбор правильных периодов измерения
Период измерения для определения SLO очень важен. Чтобы результаты были осмысленными с точки зрения взаимодействия с пользователем, период измерения должен включать действие, а не время простоя. Это окно может составлять от пяти минут до 24 часов в зависимости от того, как вы хотите отслеживать и рассчитывать метрику SLI.
Настройка процесса управления производительностью
Управление производительностью API должно осуществляться с момента начала использования API до тех пор, пока API не будет признан нерекомендуемым или его использование не будет прекращено. Необходимо настроить надежный процесс управления, чтобы проблемы с производительностью были обнаружены и устранены до того, как они приведут к серьезным проблемам, влияющим на бизнес.
Элементы управления производительностью описаны ниже:
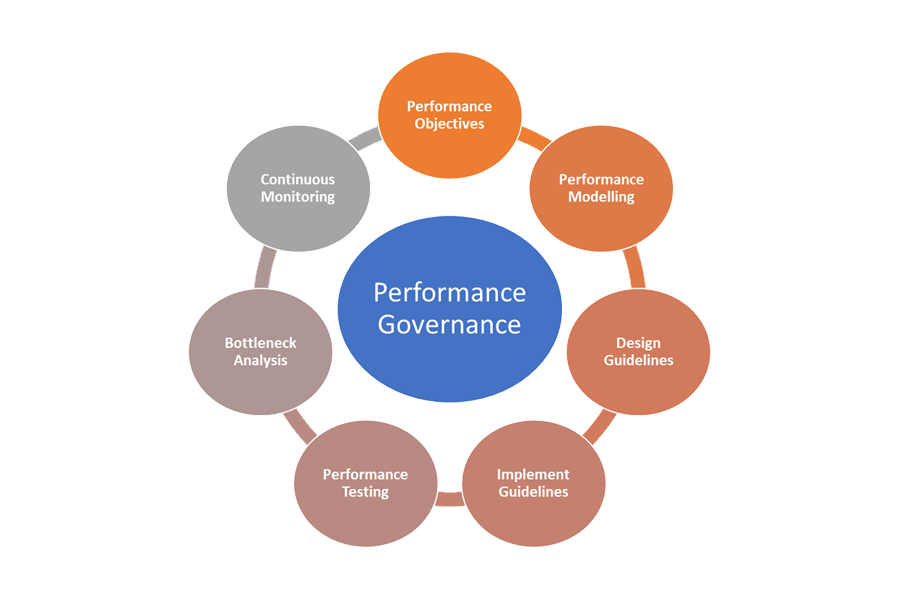
- Цели производительности: определите мотивирующие SLO производительности для бизнес-сценариев.
- Моделирование производительности: определите критически важные для бизнеса рабочие процессы и транзакции и проведите моделирование, чтобы оценить последствия, связанных с производительностью. Запишите эти сведения на детализированном уровне, чтобы получить более точные прогнозы.
- Рекомендации по проектированию: подготовьте рекомендации для обеспечения производительности при проектировании и для изменения соответствующих бизнес-процессов. Убедитесь в том, что команды понимают эти рекомендации.
- Рекомендации по реализации: реализуйте рекомендации по проектированию для обеспечения производительности в отношении компонентов решения, включая инструментирование для сбора метрик. Проведите анализ проектирования с точки зрения производительности. Важно отслеживать все эти элементы управления с помощью элементов невыполненной работы по архитектуре для различных команд.
- Тестирование производительности: проведите нагрузочное тестирование и нагрузочные испытания в соответствии с распределением профиля нагрузки для сбора метрик, относящихся к работоспособности платформы. Вы также можете провести эти тесты для ограниченной нагрузки, чтобы оценить выполнение требований к инфраструктуре решения.
- Анализ узких мест: используйте проверки кода и анализ кода для выявления, анализа и исключения узких мест, связанных с производительностью, в различных компонентах. Определите требуемые улучшения горизонтального или вертикального масштабирования для поддержки пиковых нагрузок.
- Непрерывный мониторинг: настройте инфраструктуру непрерывного мониторинга и оповещений в рамках процессов DevOps. Следите за тем, чтобы соответствующие команды получали уведомления о значительном увеличении времени отклика по сравнению с эталонным.
- Управление производительностью: настройте управление производительностью, включающее четко определенные процессы и команды, чтобы обеспечить выполнение SLO, связанных с производительностью. Проверяйте соответствие требованиям после каждого выпуска, чтобы избежать снижения производительности из-за обновлений сборки. Периодически выполняйте проверки, чтобы оценить любое повышение нагрузки и определить обновление решения.
Обязательно повторяйте эти шаги в ходе разработки решения в рамках процесса прогрессивной подготовки.
Отслеживание целей и ожиданий в отношении производительности в невыполненной работе
Отслеживайте цели в отношении производительности, чтобы убедиться в том, что они выполняются. Фиксируйте детализированные и подробные истории пользователей для последующего отслеживания. Это поможет гарантировать высокий приоритет действий по управлению производительностью для команд разработки.
Установка мотивирующих SLO для целевого решения
Ниже приведены примеры мотивирующих SLO для рассматриваемого решения платформы API:
- Реагирует на 95 % всех запросов на чтение (READ), поступающих за день, в течение одной секунды.
- Реагирует на 95 % всех запросов на создание (CREATE) и обновление (UPDATE), поступающих за день, в течение трех секунд.
- Реагирует на 99 % всех запросов, поступающих за день, в течение пяти секунд без сбоев.
- Реагирует на 99,9 % всех запросов, поступающих за день, в течение пяти минут.
- Менее одного процента запросов в течение пикового часового окна завершаются с ошибкой.
SLO можно адаптировать в соответствии с требованиями конкретного приложения. Однако очень важно иметь достаточную детализацию данных, чтобы обеспечить надежность.
Измерение начальных SLO на основе данных из журналов
Журналы мониторинга создаются автоматически при использовании службы API. Предположим, что для данных за одну неделю получены следующие результаты:
- Число запросов: 123 456
- Число успешных запросов: 123 204
- Задержка для 90-го процентиля: 497 мс
- Задержка для 95-го процентиля: 870 мс
- Задержка для 99-го процентиля: 1024 мс
Эти данные позволяют получить следующие начальные SLI:
- Доступность = (123 204 / 123 456) = 99,8 %
- Задержка = не менее 90 % запросов было обслужено в течение 500 мс
- Задержка = около 98 % запросов было обслужено в течение 1000 мс
Предположим, что во время планирования целевое значение мотивирующего SLO для задержки составляет: 90 % запросов, обрабатываемых в течение 500 мс с долей успешных запросов 99 %, в течение одной недели. С помощью данных журнала можно легко определить, было ли достигнуто целевое значение SLO. Если выполнять такой анализ в течение нескольких недель, вы сможете начать отслеживать тенденции для соответствия SLO.
Указания по устранению технических рисков
Используйте следующий контрольный список рекомендаций, чтобы снизить риски для масштабируемости и производительности:
- Выполняйте проектирование с учетом масштабируемости и производительности.
- Учитывайте требования к масштабированию для каждого пользовательского сценария и каждой рабочей нагрузки, включая сезонные изменения и пиковые значения.
- Моделирование производительности для выявления системных ограничений и узких мест
- Управляйте техническим долгом.
- Выполняйте подробную трассировку метрик производительности.
- Используйте сценарии для запуска таких инструментов как K6.io, Karate и JMeter в промежуточной среде разработки — например, с диапазоном пользовательских нагрузок от 50 до 100 запросов в секунду. Это позволит получить сведения для выявления проблем с проектированием и реализацией из журналов.
- Интегрируйте сценарии автоматических тестов в процессы непрерывного развертывания (CD) для обнаружения ошибок сборки.
- Ориентируйтесь на рабочую среду.
- Настройте пороговые значения автомасштабирования на основе статистики работоспособности.
- Предпочитайте горизонтальное масштабирование вертикальному.
- Выполняйте упреждающее масштабирование для поддержки сезонных изменений нагрузки.
- Старайтесь использовать развертывания на основе кольца.
- Используйте бюджеты на ошибки для проведения экспериментов.
Цены
Надежность, эффективность работы и оптимизация затрат связаны друг с другом. Службы Azure, используемые в архитектуре, помогают снизить затраты, так как они автоматически масштабируются в соответствии с изменяющимися пользовательскими нагрузками.
Для AKS можно начать с виртуальных машин стандартного размера для пула узлов. После этого можно отслеживать требования к ресурсам во время разработки или эксплуатации и изменять размер виртуальных машин соответствующим образом.
Оптимизация затрат является одним из критериев Платформы Microsoft Azure с продуманной архитектурой. Дополнительные сведения см. в разделе Обзор критерия "Оптимизация затрат". Чтобы предварительно оценить стоимость продуктов и конфигураций Azure, воспользуйтесь калькулятором цен.
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Автор субъекта:
- Subhajit Chatterjee | Главный инженер программного обеспечения
Следующие шаги
- Документация по Azure
- Хорошо разработанная платформа Microsoft Azure
- Стиль архитектуры микрослужб
- Проектирование для горизонтального масштабирования
- Выбор вычислительной службы Azure для приложения
- Шаблоны проектирования и реализации
- Архитектура микрослужб в Службе Azure Kubernetes
- Что такое Azure Front Door?
- Сведения о службе "Управление API"
- Что такое контроллер входящего трафика Шлюз приложений?
- Служба Azure Kubernetes
- Автоматическое масштабирование и Шлюз приложений, избыточный между зонами, версии 2
- Автоматическое масштабирование кластера в соответствии с потребностями приложений в службе Kubernetes Azure (AKS)
- Создание контейнеров и баз данных Azure Cosmos DB с пропускной способностью автомасштабирования
- Документация по Microsoft Dynamics 365
- Документация по Microsoft 365
- Документация по проектированию надежности сайта
- AZ-400: разработка стратегии "Проектирование надежности сайта" (SRE)