Моделирование работоспособности для рабочих нагрузок
Облачные приложения создают большие объемы операционных данных, что затрудняет быстрое определение и устранение проблем. Распространенной причиной этой проблемы является отсутствие базовых показателей работоспособности, настроенных в соответствии с функциональными возможностями рабочей нагрузки, и невозможность обнаружить отклонение от этих базовых показателей.
Моделирование работоспособности — это упражнение, которое объединяет бизнес-контекст с необработанными данными мониторинга для количественной оценки общей работоспособности рабочей нагрузки. Это помогает задать базовый план, по которому можно отслеживать рабочую нагрузку. Следует учитывать такие данные, как телеметрия, из компонентов инфраструктуры и приложений. Моделирование работоспособности также может включать другие сведения, необходимые для достижения целевых показателей качества рабочей нагрузки.
Проблемы с производительностью или снижение производительности могут привести к отклонению от ожидаемого рабочего состояния. Моделируя работоспособность рабочей нагрузки, вы можете выявлять смещения и принимать обоснованные операционные решения, которые учитывают влияние на бизнес.
Моделирование работоспособности устраняет разрыв между племенными операционными знаниями и практическими аналитическими сведениями. Это помогает эффективно управлять критически важными проблемами. Эта концепция имеет важное значение для обеспечения максимальной надежности и операционной эффективности.
В этом руководстве содержатся практические рекомендации по моделированию работоспособности, включая создание модели, которая оценивает работоспособность среды выполнения рабочей нагрузки и всех ее подсистем.
| Терминология | Определение |
|---|---|
| Моделирование работоспособности | Упражнение по наблюдаемости, использующее бизнес-контекст для интерпретации данных мониторинга как состояний работоспособности. |
| Модель обеспечения работоспособности | Графическое представление логических сущностей и их связей для заданного область. Каждый узел имеет определение состояния работоспособности для рационализации данных мониторинга в модели. |
| Сущность работоспособности | Логический компонент, представляющий отдельную единицу системы, логическую комбинацию нескольких связанных сущностей или общую систему. |
| Исправное состояние | Определенное и измеримое состояние, которое предоставляет значимые операционные аналитические сведения о работоспособности сущности. |
| Сигнал работоспособности | Отдельные потоки данных, которые предоставляют аналитические сведения о рабочем поведении сущности. |
| Модель моделей | Агрегированное моделирование область, в котором сущности представляют различные модели работоспособности для систем компонентов. |
Мы рекомендуем watch это видео, чтобы получить общее представление о моделировании работоспособности.
Что такое работоспособности, моделирование работоспособности и модель работоспособности?
Термин работоспособность относится к рабочему состоянию сущности и ее зависимостям. Эта сущность может быть отдельной единицей системы, логическим сочетанием нескольких связанных сущностей или общей системой.
Рекомендуется представлять работоспособность в одном из трех состояний:
Работоспособность: оптимально работает и соответствует требованиям к качеству
Понижение производительности: демонстрирует меньшее, чем работоспособное поведение, что указывает на потенциальные проблемы
Неработоспособен: в критическом состоянии и требует немедленного внимания
Примечание
Вы можете представить работоспособность с помощью оценки, а не состояний, чтобы обеспечить большую степень детализации данных.
Состояния работоспособности создаются путем объединения данных мониторинга с сведениями о предметной области. Каждое состояние должно быть определено и должно быть измеримым. Состояния работоспособности вычисляются с помощью сигналов работоспособности, которые представляют собой отдельные потоки данных, предоставляющие аналитические сведения о рабочем поведении сущности. Сигналы могут включать метрики, журналы, трассировки или другие характеристики качества. Например, сигнал работоспособности для сущности виртуальной машины может отслеживать метрику использования ЦП. Другие сигналы для этой сущности могут включать использование памяти, задержку сети или частоту ошибок.
При определении сигналов работоспособности учитывайте нефункциональные требования для рабочей нагрузки. В примере использования ЦП включите ожидаемые пороговые значения для каждого состояния работоспособности. Если использование превышает допустимое пороговое значение в соответствии с требованиями рабочей нагрузки, система переходит с работоспособности на пониженную или неработоспособную. Эти изменения состояния запускают соответствующие оповещения или действия.
Для моделирования работоспособности требуется, чтобы у сущностей были четко определенные состояния, производные от нескольких сигналов о работоспособности и контекстуализованные для рабочей нагрузки. Например, определение работоспособности для виртуальной машины может быть следующим:
Работоспособность. Основные нефункциональные требования и целевые показатели, такие как время отклика, использование ресурсов и общая производительность системы, полностью удовлетворены. Например, 95 % запросов обрабатываются в течение 500 миллисекундах. Рабочая нагрузка оптимально использует ресурсы виртуальной машины, такие как ЦП, память и хранилище, и поддерживает баланс между требованиями рабочей нагрузки и доступной емкостью. Взаимодействие с пользователем находится на ожидаемом уровне.
Снижение производительности. Ресурсы не работают оптимально, но по-прежнему работают. Например, на диске хранилища возникают проблемы с регулированием. Пользователи могут столкнуться с медленными ответами.
Неработоспособно. Деградация выходит за допустимые пределы. Ресурсы больше не реагируют и не доступны, а система больше не соответствует приемлемым уровням производительности. Взаимодействие с пользователем серьезно пострадало.
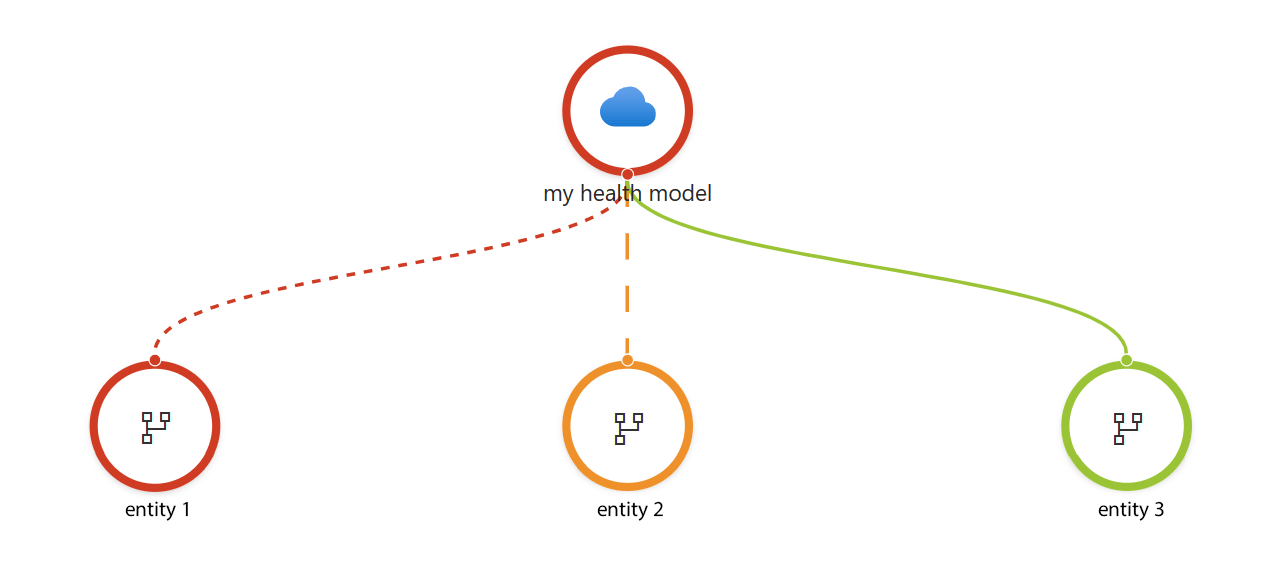
Результатом моделирования работоспособности является модель или графическое представление логических сущностей и их связей для архитектуры рабочей нагрузки. Каждый узел имеет определение состояния работоспособности.
Важно!
Моделирование работоспособности — это абстрактная концепция, которую можно реализовать и применить в разных областях, если вы хорошо понимаете бизнес-сценарии.

На изображении:
Сущности являются логическими компонентами рабочей нагрузки, представляющими аспекты системы. Они могут быть компонентами инфраструктуры, такими как серверы, базы данных и сети. Они также могут быть определенными модулями приложений, модулями pod, службами или микрослужбами. Кроме того, сущности могут записывать взаимодействия с пользователем и системные потоки в рабочей нагрузке.
Примечание
Потоки пользователей и систем обобщают нефункциональные требования в бизнес-сценариях, в которых используются компоненты приложения и инфраструктуры. Эта сводка отражает ценность приложения для бизнеса.
Связи между сущностями зеркало цепями зависимостей в системе. Например, модуль приложения может вызывать определенные компоненты инфраструктуры, образующие связь.
Рассмотрим сценарий, в котором рабочая нагрузка электронной коммерции испытывает всплеск сообщений о сбоях в очереди Служебная шина Azure, что приводит к сбою платежей. Эта проблема является критической для организации из-за подразумеваемой потери дохода. Хотя разработчик приложения может понять влияние этого всплеска метрик на платежи, эти знания не часто используются в рабочей группе.
Модель работоспособности может дать операторам немедленный обзор проблемы и ее последствий. Поток оплаты зависит от служебной шины, которая является одним из компонентов рабочей нагрузки. Визуальное представление показывает сниженное состояние экземпляра служебной шины и его влияние на поток оплаты. Операторы могут понять важность проблемы и сосредоточить свои усилия по исправлению на этом конкретном компоненте.
Моделирование работоспособности было важно в предыдущем сценарии следующими способами:
Это позволило сократить время обнаружения (TTD) и время устранения (TTM) за счет более быстрой изоляции проблем, что привело к более быстрому обнаружению проблем и их устранению.
Операторы получали оповещения на основе состояний работоспособности, что уменьшило ненужный шум. Операторы получили уведомления, предоставляющие определенный контекст о влиянии бизнеса на платежи.
Цепочки зависимостей помогли операторам полностью понять степень операционных проблем. Эти знания ускорили оценку влияния и привели к приоритетным ответам. Операторы также легко выявляют каскадные или коррелированные проблемы.
Операторы проводили действия после инцидента с точностью, так как модель работоспособности предоставляла аналитические сведения о первопричинах аномалий и конкретных сигналах работоспособности, которые были задействованы.
Это сделало данные мониторинга значимыми для всех участников команды. Она преодолела разрыв между знаниями племен и общими аналитическими сведениями.
Организация использовала модель работоспособности в качестве базового плана для будущих инвестиций в операции на основе ИИ для получения интеллектуальной аналитики.
Схема модели работоспособности
Модели работоспособности предоставляют отдельную схему данных, оптимизированную для вариантов использования наблюдаемости. Эта схема выполняет моделирование работоспособности из абстрактной концепции в измеримое решение. Моделируя конкретные требования, цели и контекст архитектуры, вы можете адаптировать данные о работоспособности к уникальному сценарию.

Работоспособности — это относительная концепция данных. Каждая модель представляет данные о работоспособности, которые являются уникальными и приоритетными для контекстных область, даже если в ней используется один и тот же набор сущностей. То, что является работоспособным в определенном сценарии, может значительно отличаться в других контекстах.
Например, рассмотрим ресурсы Azure одного типа в рабочей нагрузке.
- Виртуальная машина A запускает приложение, чувствительное к ЦП.
- Виртуальная машина B обрабатывает ресурсоемкую службу.
Определения работоспособности для этих компьютеров отличаются. Метрики использования ЦП, скорее всего, влияют на состояние работоспособности виртуальной машины A, а виртуальная машина B может приоритизировать метрики, связанные с памятью.
Важно!
Модель работоспособности не должна обрабатывать все сбои одинаково. Он должен четко различать ожидаемые или временные, но восстанавливаемые сбои и истинное аварийное состояние.
Создание модели работоспособности
Первый шаг к созданию модели работоспособности — это упражнение по логическому проектированию, которое обычно включает действия, описанные в следующих разделах.

Оценка структуры рабочей нагрузки
Начните это упражнение по логическому проектированию, оценив следующие компоненты структуры рабочей нагрузки.
Компоненты инфраструктуры, такие как вычислительные кластеры и базы данных
Компоненты приложений, выполняемые на вычислительных ресурсах, и соответствующие им компоненты
Логические или физические зависимости между компонентами
Например, модель работоспособности для приложения электронной коммерции должна представлять текущее состояние критически важных процессов, таких как вход пользователя, извлечение заказа и платежи.
Контекстуализация с использованием бизнес-требований
Оцените относительную важность и общее влияние каждого потока на организацию. Учитывайте такие факторы, как взаимодействие с пользователем, безопасность и эффективность работы. Например, в большинстве сценариев сбой процесса оплаты, скорее всего, имеет большее значение, чем сбой процесса отчетности.
Определите пути эскалации для обработки проблем, связанных с каждым потоком. Дополнительные сведения см. в статье Оптимизация структуры рабочей нагрузки с помощью потоков.
Примечание
Вы понимаете ценность моделирования работоспособности только при внедрении бизнес-сценариев и контекста. Затем можно рационализировать влияние рабочих проблем на бизнес.
Сопоставление с метриками надежности
Найдите соответствующие метрики надежности в структуре приложения.
Рассмотрите возможность определения индикаторов уровня обслуживания (SPI) и целей уровня обслуживания (SLO) для всего приложения и его отдельных бизнес-процессов. Эти SPI и SLO должны соответствовать конкретным сигналам работоспособности, рассматриваемым для вашей модели работоспособности. Таким образом вы создадите комплексное определение работоспособности, которое точно отражает достижение приемлемого уровня обслуживания для приложения.
Важно!
SPI и SLO являются критическими сигналами о работоспособности. Они создают понятное определение работоспособности, которое отражает нужный уровень обслуживания, а также другие атрибуты качества. Вы также можете определить цели работоспособности служб (SHOS), чтобы зафиксировать состояние работоспособности, которого вы хотите достичь за агрегированный диапазон времени.
Определение сигналов работоспособности
Чтобы создать комплексную модель работоспособности, сопоставляйте различные типы данных мониторинга, включая метрики, журналы и трассировки. Таким образом вы гарантируете, что концепция работоспособности точно отражает состояние среды выполнения определенной сущности или всей рабочей нагрузки.
Использование метрик и журналов платформы
В контексте моделирования работоспособности важно собирать метрики и журналы на уровне платформы из базовых ресурсов Azure. К этим метрикам относятся процент загрузки ЦП, вход в сеть и выход из сети, а также количество операций с диском в секунду. Эти данные можно использовать в модели работоспособности для обнаружения и прогнозирования потенциальных проблем при сохранении надежной среды.
Кроме того, этот подход помогает различать временные сбои или временные сбои, а также непереходные сбои или постоянные проблемы.
Примечание
Рекомендуется настроить все ресурсы приложения для направления журналов диагностики и метрик в выбранную технологию агрегирования журналов. Создание ограничений с помощью Политика Azure для обеспечения согласованности параметров диагностики в приложении и принудительного применения выбранной конфигурации для каждой службы Azure.
Добавление журналов приложений
Журналы приложений являются важным источником данных диагностика для модели работоспособности. Ниже приведены некоторые рекомендации по ведению журнала приложений.
Используйте семантическое или структурированное ведение журнала. Структурированные журналы упрощают автоматическое использование и анализ данных журнала в большом масштабе.
Рассмотрите возможность хранения метрик ресурсов Azure и диагностика данных в рабочей области Журналы Azure Monitor, а не в учетной записи хранения. С помощью этого метода можно создавать сигналы работоспособности с помощью запросов Kusto для эффективной оценки.
Данные журнала в рабочей среде. Сбор комплексных данных во время работы приложения в рабочей среде. Достаточные сведения необходимы для оценки работоспособности и диагностики всех обнаруженных проблем в рабочей среде.
Регистрируют события на границах службы. Включите идентификатор корреляции, который пересекает границы службы. Если транзакция включает несколько служб и одна из них завершается сбоем, идентификатор корреляции помогает отслеживать запросы в приложении и определить причину сбоя.
Используйте асинхронное ведение журнала. Избегайте синхронных операций ведения журнала, которые могут блокировать код приложения. Асинхронное ведение журнала обеспечивает доступность, предотвращая невыполненную работу запросов во время записи в журнал.
Отделяйте ведение журнала приложений от аудита. Ведение журналов аудита отдельно от журналов диагностики. Несмотря на то, что записи аудита соответствуют нормативным требованиям или нормативным требованиям, сохранение их различий предотвращает удаление транзакций.
Реализация распределенной трассировки
Реализуйте распределенную трассировку, сопоставляя данные телеметрии в критически важных системных потоках. Коррелированные данные телеметрии предоставляют аналитические сведения о сквозных транзакциях и необходимы для эффективного анализа первопричин (RCA) при возникновении сбоев.
Использование проб работоспособности
Реализуйте и запустите пробы работоспособности за пределами приложения, чтобы явно проверка работоспособности и скорости реагирования приложения. Используйте ответы пробы в качестве сигналов в модели работоспособности.
Вы можете реализовать пробы работоспособности, измеряя время отклика от приложения в целом или из его отдельных компонентов. Пробы могут запускать процессы для измерения задержки и проверка доступности или извлечения сведений из приложения. Дополнительные сведения см. в статье Шаблон мониторинга конечных точек работоспособности.
Большинство подсистем балансировки нагрузки поддерживают выполнение проб работоспособности, которые выполняют проверку работоспособности, которая проверяет связь конечных точек приложений с настроенными интервалами. Кроме того, можно использовать внешнюю службу наблюдения. Служба наблюдения объединяет проверки работоспособности между несколькими компонентами рабочей нагрузки. Watchdogs также может размещать код, который выполняет немедленное исправление известных состояний работоспособности.
Внедрение методов структурного и функционального мониторинга
Структурный мониторинг включает в себя предоставление приложению семантических журналов и метрик. Приложение собирает эти метрики напрямую, включая текущее потребление памяти, задержку запросов и другие соответствующие данные на уровне приложения.
Упростите процессы мониторинга с помощью функционального мониторинга. Этот подход ориентирован на измерение служб платформы и их влияние на общее взаимодействие с пользователем. В отличие от структурного мониторинга, функциональный мониторинг не требует подробных знаний о системе. Он проверяет внешне видимое поведение приложения. Этот подход полезен для оценки SLO и SPI.
Моделирование структуры
Представлять идентифицированную структуру приложения в виде сущностей и связей. Сопоставьте сигналы работоспособности с конкретными компонентами для количественной оценки состояний работоспособности на уровне сущности. Учитывайте важность компонентов, чтобы определить, как состояния работоспособности должны распространяться по модели. Например, компоненты отчетов могут быть не столь важными, как другие компоненты, что по-разному влияет на общую работоспособность рабочей нагрузки.
Настройка интерактивных оповещений
Используйте вычислимые состояния работоспособности для активации оповещений и автоматического действия. Работоспособность должна быть интегрирована в существующие операционные модули Runbook в качестве основного принципов наблюдаемости данных.
Как правило, существует сопоставление "один к одному" между данными мониторинга и правилами генерации оповещений, что может привести к нежелательным результатам, таким как штормы оповещений и окружающий шум оповещений. Например, в вычислительном кластере большие объемы оповещений на уровне виртуальной машины на основе использования ЦП и количества ошибок могут перегрузить операторов во время сбоев и вызвать задержки в разрешении. Аналогичным образом, если настроено большое количество оповещений, окружающий шум оповещений часто приводит к тому, что оповещения игнорируются или игнорируются.
Модель работоспособности предусматривает разделение между данными мониторинга и правилами генерации оповещений. Определение работоспособности объединяет множество сигналов в одно состояние работоспособности, что уменьшает количество оповещений, чтобы операторы могли сосредоточиться исключительно на важных для организации оповещениях. Рассмотрим сценарий электронной коммерции. Вы можете настроить оповещение для отправки уведомлений об изменениях в работоспособности потока платежей, а не об изменениях в базовых ресурсах, таких как очередь служебной шины.
Примечание
Возможность оповещения на всех уровнях модели работоспособности обеспечивает гибкость для различных пользователей рабочей нагрузки. Владельцы приложений и менеджеры по продуктам могут получать оповещения об изменениях состояния работоспособности в ключевых бизнес-сценариях или во всей рабочей нагрузке. Операторы могут получать оповещения на основе работоспособности компонентов инфраструктуры или приложений.
Визуализация модели
Создавайте визуальные представления, такие как таблицы или графики, чтобы эффективно передавать текущее состояние и журнал модели работоспособности. Убедитесь, что визуализация соответствует бизнес-контексту и предоставляет полезные сведения.
При визуализации модели работоспособности рассмотрите возможность применения подхода светофора , чтобы состояния работоспособности сразу были полезны в цепочках зависимостей.
Назначьте зеленый цвет для работоспособности, желтый — для пониженного состояния и красный — для неработоспособности. Быстро определяя состояния, закодированные цветом, можно эффективно определить первопричину любого ухудшения работы приложения.
Примечание
При создании панели мониторинга для модели здравоохранения рекомендуется учитывать требования к специальным возможностям для людей с ограниченными возможностями зрения. Рекомендации по созданию схем см. в разделе Схемы проектирования архитектуры.
Внедрение модели работоспособности
После создания модели работоспособности рассмотрите следующие варианты использования, чтобы обеспечить обнаружение и интерпретацию сбоев или операционных проблем.
Применимость к различным ролям
Моделирование работоспособности может предоставлять сведения, относящиеся к функциям заданий или ролям в одном контексте рабочей нагрузки. Например, роли DevOps могут потребоваться сведения о работоспособности операций. Сотрудник службы безопасности может больше беспокоиться о сигналах вторжения и воздействии на безопасность. Администратор базы данных, скорее всего, заинтересован только в подмножестве модели приложения через ресурсы базы данных.
Настраивать аналитические сведения о работоспособности для различных заинтересованных лиц. Рассмотрите возможность создания отдельных моделей из перекрывающихся наборов данных.
Непрерывная проверка
Используйте модель работоспособности для оптимизации процессов тестирования и проверки, таких как нагрузочное тестирование и тестирование хаоса. Вы можете проверить рабочее состояние среды выполнения во время тестирования и оценить эффективность модели в сценариях масштабирования и сбоя, включив модели работоспособности в жизненный цикл проектирования.
Работоспособности организации
Хотя моделирование работоспособности обычно связано с количественной оценки состояний работоспособности для отдельных приложений, его применимость выходит за рамки этого область.
На уровне отдельной рабочей нагрузки модели работоспособности обеспечивают основу для наблюдаемости приложений и операционной аналитики. Каждое приложение может иметь собственную модель работоспособности, которая фиксирует значение каждого состояния работоспособности в контексте.
Вы можете объединить несколько моделей работоспособности в высокоуровневую конструкцию, создав модель моделей. Например, вы можете создать наблюдаемый объем бизнес-подразделения или всего облачного пространства, используя модели работоспособности в качестве компонентов в более крупной модели. Модели работоспособности представляют рабочие нагрузки в пространстве как узлы в графе верхнего уровня. Используйте связи в этой модели для отслеживания зависимостей между приложениями, включая потоки данных, взаимодействие служб и общую инфраструктуру.
Рассмотрим розничную компанию, которая имеет различные приложения для электронной коммерции, платежей и обработки заказов. Каждое из этих приложений можно определить как независимую модель работоспособности, чтобы количественно определить, что означает работоспособность для этой рабочей нагрузки. Затем можно использовать родительскую модель для сопоставления всех этих моделей работоспособности компонентов как сущностей и отслеживания влияния на взаимодействие между приложениями с помощью цепочек зависимостей. Например, если приложение электронной коммерции становится неработоспособным, это оказывает каскадное влияние на приложение для оплаты.
Тенденции работоспособности и ИИ для ИТ-операций
Моделирование работоспособности предоставляет количественные операционные базовые показатели, настроенные на определенный бизнес-контекст. ИИ для ИТ-операций (AIOps) — это популярный способ повышения эффективности работы. Данные о работоспособности являются базовыми входными данными для моделей машинного обучения для анализа тенденций в области здравоохранения. Например, модели машинного обучения могут:
Извлекайте дополнительные аналитические сведения из изменений состояния и рекомендуете действия.
Анализ тенденций работоспособности с течением времени для прогнозирования проблем и уточнения модели.
Поддержание модели работоспособности
Поддержание модели работоспособности — это непрерывная инженерная деятельность, которая соответствует разработке и эксплуатации приложения. По мере развития приложения убедитесь, что модель работоспособности развивается параллельно.
Кроме того, модели работоспособности следует рассматривать как артефакты рабочей нагрузки, которые следует интегрировать в жизненный цикл разработки. Внедрение инфраструктуры как кода (IaC) для согласованного управления моделью работоспособности с управлением версиями. Используйте автоматизацию, чтобы модель обновлялась при добавлении или удалении компонентов инфраструктуры и приложений из рабочей нагрузки.
Данные о работоспособности со временем постепенно уменьшаются. Чтобы оптимизировать эффективность работы и свести к минимуму затраты, избегайте хранения данных о работоспособности в течение 30 дней. При необходимости можно архивировать данные в соответствии с требованиями аудита или в сценариях, в которых предполагается долгосрочный анализ шаблонов в ИИ для ИТ-операций.
Примечание
При архивации данных о работоспособности убедитесь, что они связаны с состоянием конфигурации модели. Интерпретация изменений состояния может быть сложной задачей без этого контекста.
Связанные ссылки
- Сведения о реализации проб работоспособности в ASP.NET см. в разделе Проверки работоспособности в ASP.NET Core.
- Сведения о мониторинге метрик см. в статье Общие сведения о метриках Azure Monitor.
- Сведения об использовании Application Insights см. в разделе Application Insights.
- Рекомендации по проектированию и рекомендации, относящиеся к критически важным рабочим нагрузкам, см. в статье Моделирование работоспособности и наблюдаемость для критически важных рабочих нагрузок в Azure.
- Практические навыки см. в статье Проектирование модели работоспособности для критически важной рабочей нагрузки.
Следующий шаг
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по