Искусственный интеллект предлагает возможность трансформировать сегодняшнюю розничную торговлю. Разумно поверить, что розничные торговцы будут разрабатывать архитектуру взаимодействия с клиентами, поддерживаемую ИИ. Некоторые ожидания заключаются в том, что платформа, улучшенная с помощью ИИ, обеспечит рост прибыли из-за гиперперсонализации. Цифровая торговля продолжает повышать ожидания, предпочтения и поведение клиентов. Такие требования, как вовлеченность пользователей в режиме реального времени, соответствующие рекомендации и гиперперсонализация, обеспечивают скорость и удобство одним нажатием кнопки. Мы включаем аналитику в приложениях с помощью естественной речи, зрения и т. д. Эта аналитика позволяет улучшить розничную торговлю, которая увеличит ценность при нарушении того, как клиенты магазины.
Этот документ посвящен такой концепции ИИ, как концепция визуального поиска, и предлагает несколько ключевых соображений по ее реализации. Здесь предоставлено пример рабочего процесса, а его этапы сопоставлено с соответствующими технологиями Azure. Концепция основана на том, что клиенты могут использовать образ, сделанный с помощью мобильного устройства или расположенного в Интернете. Они будут проводить поиск соответствующих и подобных элементов в зависимости от намерения опыта. Таким образом, визуальный поиск повышает скорость от текстовой записи к изображению с несколькими точками метаданных, чтобы быстро получить доступ ко всем доступным элементам.
Визуальные поисковые системы
Визуальная поисковая система извлекает информацию, используя образы в качестве входных данных и часто, но не исключительно, в качестве вывода.
Системы становятся все более распространенными в сфере розничной торговли, и на это есть очень веские причины:
- Около 75% интернет-пользователей ищут изображения или видеоролики с продуктом перед совершением покупки, согласно отчету Emarketer, опубликованному в 2017 году.
- 74% потребителей также находят неэффективный поиск текста, в соответствии с отчетом Slyce (визуальной поисковой компанией) 2015 года.
Таким образом, рынок распознавания изображений будет стоить более $ 25 млрд к 2019 году, в соответствии с исследованиями рынка и рынков.
Технология уже укрепилась с крупными брендами электронной коммерции, которые также внесли значительный вклад в ее развитие. Наиболее известные ранние пользователи, вероятно:
- eBay с их поиском изображений и инструментами "Найти это на eBay" в своем приложении (сейчас это только мобильный опыт).
- Pinterest с их инструментом визуального обнаружения группы связанных элементов.
- Microsoft с визуальным поиском Bing.
Внедрение и адаптация
К счастью, чтобы получить прибыль от визуального поиска, вам не нужны огромные вычислительные мощности. Любая компания с каталогом изображений может использовать опыт ИИ от Microsoft, встроенный в его службы Azure.
API визуального поиска Bing предоставляет способ извлечения информации о контексте из изображений, идентификации ( например, домашней мебели, моды, нескольких видов продуктов и т. д.
Он также возвратит визуально похожие образы из своего собственного каталога, продукты, и где их можно купить, а также связанные с ними поисковые запросы. Хотя интересно, это будет ограниченное использование, если ваша компания не является одним из этих источников.
Bing также предоставит:
- Теги, которые позволяют вам исследовать объекты или концепции, найденные в образе.
- Ограничивающие коробки для регионов, интересующих изображение (например, для одежды или мебели).
Вы можете принять эту информацию, чтобы значительно сократить пространство поиска (и время) в каталоге продуктов компании, ограничив его такими объектами, как те, которые находятся в регионе и категории интересов.
Реализация собственного
При реализации визуального поиска необходимо учитывать несколько ключевых компонентов:
- Прием и фильтрация изображений
- Методы хранения и извлечения
- Добавление признаков, кодирования или "хеширование"
- Меры сходства или расстояния и ранжирования

Рис.1: Пример конвейера визуального поиска
Выбор рисунков
Если вы не владеете каталогом рисунков, вам может потребоваться обучить алгоритмы на открытых доступных наборах данных, таких как мода MNIST, глубокая мода и т. д. Они содержат несколько категорий продуктов и обычно используются для сравнения алгоритмов классификации и поиска изображений.

Рис. 2. Пример из набора данных DeepFashion
Фильтрация изображений
Большинство наборов данных тестовых показателей, таких как те, которые упоминание раньше, уже были предварительно обработаны.
Если вы создаете собственный тест, по крайней мере, вам потребуется, чтобы изображения имели одинаковый размер, в основном диктуется входными данными, для которых обучена ваша модель.
Во многих случаях лучше всего нормализовать светимость изображений. В зависимости от уровня детализации вашего поиска цвет может также быть лишней информацией, поэтому сокращение до черного и белого цвета поможет с временем обработки.
И последнее, но не по значению, набор данных образов должен быть сбалансирован в разных классах, которые он представляет.
База данных образов
Уровень данных является особенно деликатным компонентом вашей архитектуры. Он будет содержать следующие элементы:
- Изображения
- Метаданные изображений (размер, теги, SKU продуктов, описание)
- Данные, которые генерирует модель машинного обучения (например, числовой вектор из 4096 элементов на изображение)
Когда вы извлекаете изображения из разных источников или используете несколько моделей машинного обучения для обеспечения оптимальной производительности, то структура данных изменится. Поэтому важно выбрать технологию или комбинацию, которая может иметь дело с полуструктурированных данных и без фиксированной схемы.
Кроме того, может потребоваться минимальное количество полезных точек данных (например, идентификатор изображения или ключа, номер sku продукта, описание или поле тега).
Azure Cosmos DB обеспечивает необходимую гибкость и различные механизмы доступа для приложений, созданных на основе приложения (которые помогут в поиске в каталоге). Тем не менее нужно быть осторожным, чтобы задать наиболее оптимальную цену/производительность. Azure Cosmos DB позволяет хранить вложения документов, но общее ограничение для каждой учетной записи может оказаться дорогостоящим. Обычно рекомендуется хранить фактические файлы изображений в больших двоичных объектах и вставлять ссылку на них в базу данных. В случае Azure Cosmos DB это означает создание документа, содержащего свойства каталога, связанные с этим изображением (например, SKU, тег и т. д.), а также вложение, содержащее URL-адрес файла изображения (например, в хранилище BLOB-объектов Azure, OneDrive и т. д.).

Рис. 3. Иерархическая модель ресурсов Azure Cosmos DB
Если вы планируете воспользоваться глобальным распределением Azure Cosmos DB, обратите внимание, что оно реплика будет реплика содержать документы и вложения, но не связанные файлы. Возможно, для этого вы рассмотрите сеть распространения содержимого.
Другие применимые технологии представляют собой комбинацию базы данных SQL Azure (если фиксированная схема допустима) и BLOB-объектов, или даже таблицы Azure и BLOB-объектов для недорогого и быстрого хранения и поиска.
Извлечение признаков и кодировка
Процесс кодирования извлекает из образов базы данных важные функции и сопоставляет каждый из них с разреженным "компонентом" (вектором с множеством нулей), который может иметь тысячи компонентов. Этот вектор представляет собой числовое представление признаков (таких как края и фигуры), характеризующие рисунок. Это похоже на код.
Методы извлечения объектов обычно используют механизмы обучения передачи. Это происходит, когда вы выбираете предварительно обученную нейронную сеть, пропускаете через нее каждое изображение и сохраняете вектор функции, полученный обратно в базе данных изображений. Таким образом вы "передаете" обучение тому, кто обучил эту сеть. Корпорация Microsoft разработала и опубликовала несколько предварительно подготовленных сетей, которые широко используются для задач распознавания изображений, например, ResNet50.
В зависимости от нейронной сети вектор функций будет более или менее длинным и разреженным, поэтому требования к памяти и хранению будут различаться.
Кроме того, вы можете обнаружить, что различные сети применимы к различным категориям, поэтому реализация визуального поиска может фактически генерировать векторы признаков разного размера.
Предварительно обученные нейронные сети относительно просты в использовании, но могут быть не столь эффективными, как пользовательская модель, обученная в каталоге образов. Те предварительно подготовленные сети, как правило, предназначены для классификации базовых наборов данных, а не для поиска по вашей конкретной коллекции изображений.
Вы можете изменить и переобучить их, чтобы они производили прогнозирование категорий и плотный (т. е. меньший, не разреженный) вектор, который будет очень полезен для ограничения пространства поиска, уменьшения требований к памяти и хранилищу. Можно использовать двоичные векторы, которые часто упоминаются как "семантический хэш" — термин, полученный из методов кодирования и извлечения документов. Двоичное представление упрощает дальнейшие вычисления.
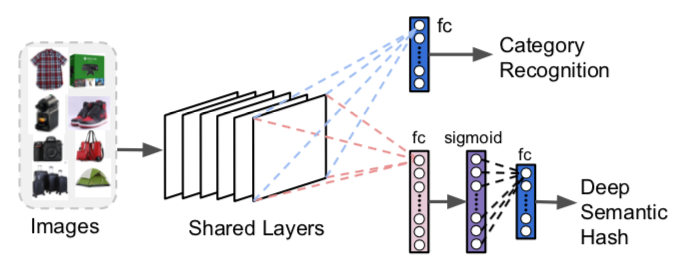
Рис. 4: Изменения в ResNet для визуального поиска — F. Yang et al., 2017 г.
Независимо от того, выбираете ли вы предварительно обученные модели или разрабатываете собственные, вам по-прежнему потребуется решить, где запускать признаки и /или обучение самой модели.
Azure предлагает несколько вариантов: виртуальные машины, пакетная служба Azure, Batch AI, кластеры Databricks. Однако во всех случаях наилучшая цена/производительность обеспечивается использованием графических процессоров.
Недавно корпорация Microsoft также анонсировала доступность FPGA для быстрого вычисления на долю стоимости GPU (проект Brainwave). Однако на момент написания этой статьи это предложение ограничено определенными сетевыми архитектурами, поэтому вам потребуется внимательно оценить их производительность.
Мера сходства или расстояние
Когда изображения представлены в векторном пространстве признаков, поиск сходства становится вопросом определения расстояния между точками в этом пространстве. Как только расстояние определено, вы можете вычислить кластеры похожих изображений и/или определить матрицы подобия. Результаты могут отличаться в зависимости от выбранного показателя расстояния. Например, наиболее распространенную евклидову меру расстояния по векторам вещественного числа легко понять: она фиксирует величину расстояния. Однако это довольно неэффективно с точки зрения вычислений.
Расстояние косинуса часто используется для сбора данных об ориентации вектора, а не его модуле.
Альтернативы, такие как расстояние Хэмминга над двоичными представлениями, жертвуют некоторой точностью эффективности и скорости.
Комбинация размера вектора и расстояния будет определять, насколько интенсивными будет вычисление и поиск.
Поиск и ранжирование
Как только подобие определено, нам нужно разработать эффективный метод для извлечения ближайших элементов N к тому, который был передан как вход, а затем вернуть список идентификаторов. Это также называется "ранжирование образов". В большом наборе данных время для вычисления каждого расстояния является запретительным, поэтому мы используем приближенные алгоритмы ближайших соседей. Для них существуют несколько библиотек с открытым кодом, поэтому вам не придется кодировать их с нуля.
Наконец, требования к памяти и вычисления определяют выбор технологии развертывания для обученной модели, а также высокий уровень доступности. Как правило, пространство поиска будет разбито на разделы, и несколько экземпляров алгоритма ранжирования будут выполняться параллельно. Один из вариантов, который обеспечивает масштабируемость и доступность — кластеры Azure Kubernetes. В этом случае рекомендуется развернуть модель ранжирования в нескольких контейнерах (обработка секции пространства поиска каждый) и нескольких узлов (для обеспечения высокой доступности).
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
Основные авторы:
- Джованни Маркетти | Диспетчер, архитекторы решений Azure
- Мария Зоротович | Глава отдела взаимодействия с клиентами, HLS и развивающихся технологий
Другие участник:
- Скотт Силли | Архитектор программного обеспечения
Следующие шаги
Реализация визуального поиска не должна быть сложной. Вы можете использовать Bing или создавать свои собственные с помощью служб Azure, в то же время пользуясь преимуществами и инструментами Microsoft в области ИИ.
Разработка
- Чтобы начать создавать настраиваемые службы, см. раздел Что такое API для визуального поиска?
- Чтобы создать первый запрос, ознакомьтесь с краткими руководствами: C# | Java | Node.js Python |
- Ознакомьтесь со справочными материалами по API для визуального поиска.
Общие сведения
- Deep Learning Image Segmentation (Сегментация образов глубокого обучения): документ корпорации Microsoft, в котором описывается процесс отделения образов от фонов
- Visual Search at Ebay (Визуальный поиска на Ebay): справочные материалы Корнелльского университета
- Visual Discovery at Pinterest (Визуальное обнаружение на Pinterest): справочные материалы Корнелльского университета
- Semantic Hashing (Семантическое хеширование) справочные материалы университета Торонто