Более быстрые циклы выпуска являются одним из основных преимуществ архитектур микрослужб. Но без хорошего процесса CI/CD вы не сможете достичь гибкости, которую обещают микрослужбы. В этой статье описываются проблемы и рекомендуются некоторые подходы к решению проблемы.
Что такое CI/CD?
Когда мы говорим о CI/CD, мы говорим о нескольких связанных процессах: непрерывная интеграция, непрерывная поставка и непрерывное развертывание.
Непрерывная интеграция. Изменения кода часто объединяются в ветвь main. Автоматизированные процессы сборки и тестирования гарантируют, что код в main ветви всегда является рабочим.
Непрерывная поставка. Все изменения кода, которые передают процесс CI, автоматически публикуются в рабочей среде. Для развертывания в рабочей среде может потребоваться утверждение вручную, в противном случае оно выполняется автоматически. В результате этого код всегда будет готов к развертыванию в рабочей среде.
Непрерывное развертывание. Изменения кода, прошедшие два предыдущих шага, автоматически развертываются в рабочей среде.
Ниже приведены некоторые цели надежного процесса CI/CD для архитектуры микрослужб:
Каждая команда может создавать и развертывать службы, которыми она владеет независимо, не влияя на другие команды и не нарушая их работу.
Перед развертыванием новой версии службы в рабочей среде она развертывается в средах разработки, тестирования и контроля качества для проверки. Шлюзы качества применяются на каждом этапе.
Новую версию службы можно развернуть параллельно с предыдущей версией.
Заданы достаточные политики контроля доступа.
Для контейнерных рабочих нагрузок можно доверять образам контейнеров, развернутых в рабочей среде.
Почему важен надежный конвейер CI/CD
В традиционном монолитном приложении существует один конвейер сборки, выходными данными которого является исполняемый файл приложения. Все данные разработки поступают в этот конвейер. При обнаружении ошибки с высоким приоритетом необходимо интегрировать, протестировать и опубликовать исправление, из-за чего может быть отложен выпуск новых функций. Вы можете устранить эти проблемы, используя хорошо факторированные модули и использование ветвей функций, чтобы свести к минимуму влияние изменений кода. Но так как объем данных приложения со временем увеличивается и оно становится более сложным, а также добавляются дополнительные функции, процесс выпуска для монолитного приложения становится нестабильным и часто нарушается.
Принципы работы с микрослужбами предусматривают, что цепочка выпуска не может быть длинной, когда каждая команда должна становиться в очередь. Команда, создающая службу "A", может выпустить обновление в любое время, не ожидая объединения, тестирования и развертывания изменений в службе "B".
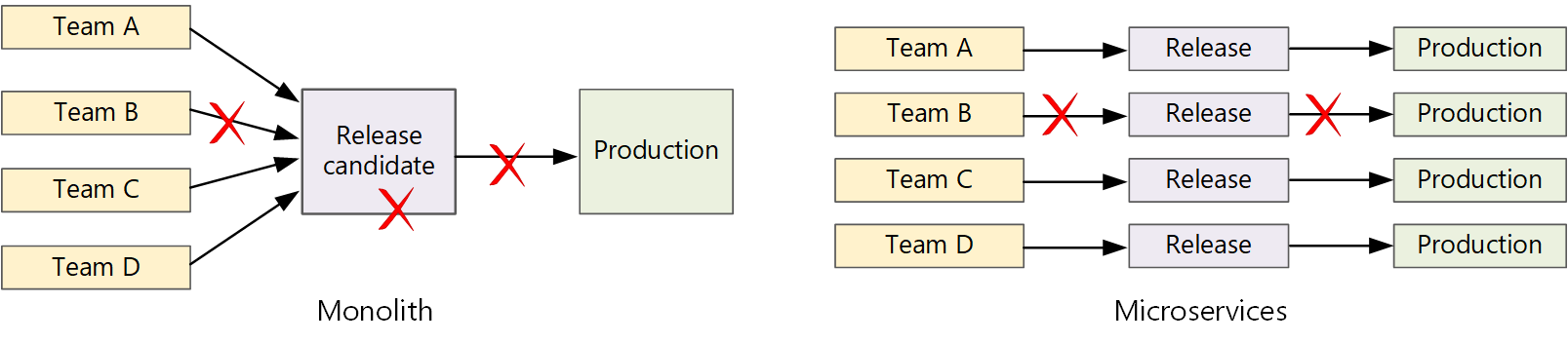
Для достижения высокой скорости выпуска конвейер выпуска должен быть автоматизирован и высоконадежным, чтобы свести к минимуму риски. Если вы выпускаете в рабочую среду один или несколько раз в день, регрессии или перебои в работе служб должны быть редкими. В то же время в случае развертывания неправильного обновления необходимо располагать надежным способом быстро выполнить откат или накат до предыдущей версии службы.
Сложности
Множество небольших независимых баз кода. Каждая команда отвечает за создание собственной службы со своим собственным конвейером сборки. В некоторых организациях команды могут использовать отдельные репозитории кода. Отдельные репозитории могут привести к ситуации, когда знания о том, как создать систему, распределяются между командами, и никто в организации не знает, как развернуть приложение целиком. Например, что происходит в сценарии аварийного восстановления, если необходимо быстро выполнить развертывание в новый кластер?
Устранение рисков. Используйте единый и автоматизированный конвейер для создания и развертывания служб, чтобы эти знания не были "скрыты" в каждой команде.
Множество языков программирования и платформ. При том, что каждая команда использует свой собственный набор технологий, могут возникнуть сложности в создании процесса сборки, применимого для всей организации. Процесс сборки должен быть достаточно гибким, чтобы любая команда могла использовать его независимо от выбранного языка программирования или платформы.
Устранение рисков. Контейнеризация процесса сборки для каждой службы. Таким образом, системе сборки просто необходимо иметь возможность запускать контейнеры.
Интеграция и нагрузочное тестирование. Так как команды выпускают обновления независимо друг от друга, с разработкой надежного и комплексного тестирования могут возникнуть сложности, особенно если у службы есть зависимости от других служб. Кроме того, запуск полного рабочего кластера может быть дорогостоящим, поэтому маловероятно, что каждая команда будет запускать собственный полный кластер в рабочих масштабах только для тестирования.
Управление выпусками. Каждая команда должна иметь возможность развернуть обновление в рабочей среде. Это не означает, что у каждого участника команды есть на это разрешения. Но при наличии централизованной роли диспетчера выпусков может снизиться скорость развертываний.
Устранение рисков. Чем больше автоматизированный и надежный процесс CI/CD, тем меньше необходимости в центральном органе. С другой стороны, могут применяться различные политики для выпуска обновлений основных компонентов и небольших исправлений ошибок. Децентрализованность не означает нулевое управление.
Обновления службы. Обновление службы до новой версии не должно нарушать работу других служб, зависящих от нее.
Устранение рисков. Используйте такие методы развертывания, как сине-зеленый выпуск или канареечного выпуска для некриминационных изменений. Для критических изменений API разверните новую версию параллельно с предыдущей версией. Таким образом, службы, использующие предыдущий API, можно обновить и протестировать для нового API. См. раздел Обновление служб ниже.
Сравнение Monorepo и нескольких репозиторий
Прежде чем создавать рабочий процесс CI/CD, необходимо знать, как будет структурирована база кода и как ею управлять.
- Работают ли команды в отдельных репозиториях или в monorepo (один репозиторий)?
- Что такое стратегия создания ветви?
- Кто может отправлять код в рабочую среду? Существует ли роль менеджера выпуска?
Подход единого репозитория получил приоритет, но есть определенные преимущества и недостатки.
| Единый репозиторий | Несколько репозиториев | |
|---|---|---|
| Преимущества | Общий доступ к коду Простой способ стандартизировать код и средства Простой рефакторинг кода Обнаруживаемость – единое представление кода |
Очистка владельца в команде Потенциально меньше конфликтов слияния Помогает применить разделение микрослужб |
| Проблемы | Изменение совместного использования кода может повлиять на несколько микрослужб Большая вероятность конфликтов слияния Инструментарий необходимо масштабировать в большую базу кода Управление доступом Более сложный процесс развертывания |
Труднее совместно использовать код Труднее применять стандарты кодирования Управление зависимостями Диффузная база кода, низкая обнаруживаемость Отсутствие общей инфраструктуры |
Обновление служб
Есть различные стратегии обновления службы, которая уже находится в рабочей среде. Здесь рассматриваются три распространенных варианта: последовательное обновление, "сине-зеленое" развертывание и ранний выпуск.
Последовательное обновление.
В последовательном обновлении развертываются новые экземпляры службы, которые сразу же начинают получать запросы. При появлении новых экземпляров предыдущие экземпляры удаляются.
Пример: В Kubernetes последовательные обновления являются поведением по умолчанию при обновлении спецификации pod для развертывания. Контроллер развертывания создает новый набор реплик для обновленных модулей pod. Затем он масштабирует новый набор реплик, при этом уменьшая масштаб старого набора реплик, чтобы сохранить необходимое количество реплик. Пока не готовы новые модули pod, старые модули не удаляются. Kubernetes хранит журнал обновления, чтобы при необходимости можно было откатить обновление.
Пример: Azure Service Fabric по умолчанию использует стратегию последовательного обновления. Эта стратегия лучше всего подходит для развертывания версии службы с новыми функциями без изменения существующих API. Service Fabric запускает развертывание обновления, обновив тип приложения до подмножества узлов или домена обновления. Затем выполняется накат до следующего домена обновления, пока не будут обновлены все домены. Если не удается обновить домен обновления, тип приложения выполняет откат до предыдущей версии во всех доменах. Имейте в виду, что тип приложения с несколькими службами (и если все службы обновляются в рамках одного развертывания обновления) может приводить к сбою. Если не удается обновить одну службу, выполняется откат всего приложения до предыдущей версии, а другие службы не обновляются.
Одной из проблем последовательного обновления является то, что во время обновления и старая, и новая версии выполняются и получают трафик. В течение этого периода любой запрос может перенаправляться в одну из двух версий.
Для критических изменений API рекомендуется поддерживать обе версии параллельно, пока не будут обновлены все клиенты предыдущей версии. См. раздел Управление версиями API.
"Сине-зеленое" развертывание
При "сине-зеленом" развертывании новая версия развертывается параллельно с предыдущей версией. После проверки новой версии весь трафик сразу же переходит из предыдущей версии в новую. После переключения трафика выполняется мониторинг приложения на наличие проблем. Если что-то пойдет не так, можно вернуться обратно к старой версии. При условии, что проблем нет, старую версию можно удалить.
В более традиционных монолитных или n-уровневых приложениях "сине-зеленое" развертывание обычно подразумевает подготовку двух идентичных сред. Вы развернете новую версию в промежуточной среде, а затем перенаправите трафик клиента в промежуточную среду, например, переключив виртуальные IP-адреса. В архитектуре микрослужб обновления выполняются на уровне микрослужб, поэтому обычно обновление развертывается в той же среде и используется механизм обнаружения служб для переключения.
Пример. В Kubernetes для выполнения "сине-зеленых" развертываний не нужно подготавливать отдельный кластер. Вместо этого можно воспользоваться селекторами. Создайте ресурс развертывания с новой спецификацией pod и другим набором меток. Создайте это развертывание, не удаляя предыдущее развертывание и не изменяя службу, которая указывает на него. После запуска новых модулей pod можно обновить селектор службы в соответствии с новым развертыванием.
Одним из недостатков сине-зеленого развертывания является то, что во время обновления выполняется в два раза больше модулей pod для службы (текущая и следующая). Если для модулей pod требуется больший объем ресурсов ЦП или памяти, может потребоваться временно развернуть кластер, чтобы справиться с потреблением ресурсов.
Ранний выпуск
В раннем выпуске обновленная версия развертывается в небольшое количество клиентов. Затем отслеживается поведение новой службы, прежде чем развернуть ее для всех клиентов. Так вы можете выполнить медленный выпуск контролируемым способом, наблюдать за реальными данными, а также обнаруживать проблемы, прежде чем они затронут всех клиентов.
Ранний выпуск сложнее в управлении, чем "сине-зеленое" развертывание или последовательное обновление, так как необходимо динамически направлять запросы в разные версии службы.
Пример. В Kubernetes можно настроить службу для охвата двух наборов реплика (по одному для каждой версии) и настроить счетчики реплика вручную. Тем не менее этот подход не детализирован из-за того, как Kubernetes распределяет нагрузку между модулями pod. Например, если у вас всего 10 реплик, можно сдвинуть трафик только с шагом 10 %. При использовании ПО слоя взаимодействия между службами можно использовать правила маршрутизации для реализации более сложной стратегии раннего выпуска.
Дальнейшие действия
- Схема обучения: определение и реализация непрерывной интеграции
- Учебный курс. Введение в непрерывную поставку
- Архитектура микрослужб
- Разработка приложений с использованием микрослужб