В этой статье описывается, как команда разработчиков использовала метрики для поиска узких мест и повышения производительности распределенной системы. Статья основана на фактическом нагрузочном тестировании, которое было выполнено для примера приложения. Приложение находится на основе базового плана Служба Azure Kubernetes (AKS) для микрослужб, а также проекта нагрузочного теста Visual Studio, используемого для создания результатов.
Этот материал входит в цикл статей. Прочитайте первую часть здесь.
Сценарий. Вызовите несколько серверных служб для получения сведений, а затем агрегирования результатов.
Этот сценарий включает в себя приложение доставки с помощью дронов. Клиенты могут запрашивать REST API для получения последних сведений о счете. В счете содержится сводка по поставкам, пакетам и общему использованию дронов. Это приложение использует архитектуру микрослужб, выполняющуюся в AKS, и сведения, необходимые для выставления счетов, распределяются между несколькими микрослужбами.
Вместо того, чтобы клиент напрямую вызывает каждую службу, приложение реализует шаблон агрегирования шлюза . Используя этот шаблон, клиент выполняет один запрос к службе шлюза. Шлюз, в свою очередь, вызывает серверные службы параллельно, а затем объединяет результаты в одну полезную нагрузку ответа.

Тест 1. Базовая производительность
Чтобы установить базовые показатели, команда разработчиков начала с пошаговой нагрузки, которая увеличила нагрузку от одного имитированного пользователя до 40 пользователей в течение 8 минут. На следующей диаграмме, взятой из Visual Studio, показаны результаты. Фиолетовая линия показывает нагрузку пользователя, а оранжевая — пропускную способность (среднее количество запросов в секунду).

Красная линия в нижней части диаграммы показывает, что клиенту не были возвращены ошибки, что обнадеживает. Тем не менее средняя пропускная способность достигает максимума примерно на полпути через тест, а затем снижается на оставшуюся часть, даже если нагрузка продолжает увеличиваться. Это означает, что внутренней части не удается идти в ногу. Шаблон, показанный здесь, является распространенным, когда система начинает достигать пределов ресурсов. После достижения максимального значения пропускная способность на самом деле значительно снижается. Состязание за ресурсы, временные ошибки или увеличение числа исключений могут способствовать этому шаблону.
Давайте рассмотрим данные мониторинга, чтобы узнать, что происходит в системе. Следующая диаграмма взята из Application Insights. В нем отображается средняя продолжительность HTTP-вызовов из шлюза к внутренним службам.

На этой диаграмме показано, что одна операция, в частности , GetDroneUtilizationзанимает в среднем гораздо больше времени — на порядок. Шлюз выполняет эти вызовы параллельно, поэтому самая медленная операция определяет, сколько времени потребуется для завершения всего запроса.
Очевидно, что следующий шаг заключается в том, чтобы разобраться в GetDroneUtilization операции и найти узкие места. Одна из возможных вариантов — исчерпание ресурсов. Возможно, для этой конкретной серверной службы не хватает ЦП или памяти. Для кластера AKS эти сведения доступны в портал Azure с помощью функции аналитики контейнеров Azure Monitor. На следующих графиках показано использование ресурсов на уровне кластера.

На этом снимке экрана показаны среднее и максимальное значения. Важно смотреть не только на среднее, так как среднее может скрыть пики в данных. Здесь средняя загрузка ЦП остается ниже 50 %, но есть несколько пиков до 80 %. Это близко к емкости, но по-прежнему в пределах допустимых пределов. Что-то еще вызывает узкое место.
На следующей диаграмме показан истинный виновник. На этой диаграмме показаны коды HTTP-ответов из серверной базы данных службы доставки, которая в данном случае является Azure Cosmos DB. Синяя линия представляет коды успешного выполнения (HTTP 2xx), а зеленая — ошибки HTTP 429. Код возврата HTTP 429 означает, что Azure Cosmos DB временно регулирует запросы, так как вызывающий объект потребляет больше единиц ресурсов (ЕЗ), чем подготовлено.

Чтобы получить дополнительные сведения, группа разработчиков использовала Application Insights для просмотра комплексной телеметрии для репрезентативной выборки запросов. Вот один экземпляр:

В этом представлении отображаются вызовы, связанные с одним запросом клиента, а также сведения о времени и коды ответов. Вызовы верхнего уровня выполняются из шлюза к внутренним службам. Вызов GetDroneUtilization разворачивается для отображения вызовов внешних зависимостей, в данном случае к Azure Cosmos DB. Вызов красным цветом вернул ошибку HTTP 429.
Обратите внимание на большой разрыв между ошибкой HTTP 429 и следующим вызовом. Когда клиентская библиотека Azure Cosmos DB получает ошибку HTTP 429, она автоматически отключается и ожидает повтора операции. В этом представлении показано, что в течение 672 мс этой операции большая часть времени была потрачена на ожидание повторной попытки Azure Cosmos DB.
Вот еще один интересный график для этого анализа. Здесь показано потребление единиц запросов на физическую секцию и подготовленные ЕЗ на физическую секцию:

Чтобы понять этот график, необходимо понять, как Azure Cosmos DB управляет секциями. Коллекции в Azure Cosmos DB могут иметь ключ секции. Каждое возможное значение ключа определяет логическую секцию данных в коллекции. Azure Cosmos DB распределяет эти логические секции между одной или несколькими физическими секциями. Управление физическими секциями осуществляется автоматически с помощью Azure Cosmos DB. По мере хранения данных Azure Cosmos DB может перемещать логические секции в новые физические секции, чтобы распределять нагрузку между физическими секциями.
Для этого нагрузочного теста коллекция Azure Cosmos DB была подготовлена с 900 ЕЗ. На диаграмме показано 100 ЕЗ на физическую секцию, что подразумевает в общей сложности девять физических секций. Хотя Azure Cosmos DB автоматически обрабатывает сегментирование физических секций, знание количества секций может дать представление о производительности. Команда разработчиков будет использовать эти сведения позже, так как они продолжают оптимизировать. Если синяя линия пересекает фиолетовую горизонтальную линию, потребление единиц запросов превысило подготовленные ЕЗ. Именно в этой точке Azure Cosmos DB начнет регулировать вызовы.
Тест 2. Увеличение единиц ресурсов
Для второго нагрузочного теста команда масштабирует коллекцию Azure Cosmos DB с 900 до 2500 ЕЗ. Пропускная способность увеличилась с 19 запросов в секунду до 23 запросов в секунду, а средняя задержка снизилась с 669 мс до 569 мс.
| Metric | Тест 1 | Тест 2 |
|---|---|---|
| Пропускная способность (req/sec) | 19 | 23 |
| Средняя задержка (мс) | 669 | 569 |
| Успешные запросы. | 9,8 КБ | 11 КБ |
Это не огромные выгоды, но, глядя на график с течением времени, можно получить более полную картину:

В то время как предыдущий тест показал начальный всплеск, за которым следует резкое падение, этот тест показывает более согласованную пропускную способность. Однако максимальная пропускная способность не значительно выше.
Все запросы к Azure Cosmos DB возвращали состояние 2xx, а ошибки HTTP 429 были удалены:

На графике потребления единиц запросов в сравнении с подготовленными ЕЗ видно, что есть много ресурсов. На физическую секцию приходится около 275 ЕЗ, а нагрузочный тест достиг пика примерно в 100 ЕЗ, потребляемых в секунду.

Еще одна интересная метрика — количество вызовов к Azure Cosmos DB за успешную операцию.
| Metric | Тест 1 | Тест 2 |
|---|---|---|
| Вызовы на операцию | 11 | 9 |
При отсутствии ошибок количество вызовов должно соответствовать фактическому плану запроса. В этом случае операция включает межсекционный запрос, который попадает во все девять физических секций. Более высокое значение в первом нагрузочном тесте отражает количество вызовов, возвращающих ошибку 429.
Эта метрика была рассчитана путем выполнения пользовательского запроса Log Analytics:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Подводя итоги, второй нагрузочный тест показывает улучшение. Однако операция по-прежнему GetDroneUtilization занимает примерно на порядок больше времени, чем следующая самая медленная операция. Просмотр сквозных транзакций поможет объяснить, почему:

Как упоминалось ранее, GetDroneUtilization операция включает межсекционный запрос к Azure Cosmos DB. Это означает, что клиенту Azure Cosmos DB необходимо развернуть запрос к каждой физической секции и собрать результаты. Как показано в представлении сквозной транзакции, эти запросы выполняются последовательно. Операция занимает столько времени, сколько сумма всех запросов, и эта проблема только ухудшится по мере увеличения размера данных и добавления дополнительных физических секций.
Тест 3. Параллельные запросы
На основе предыдущих результатов очевидным способом снижения задержки является параллельная выдача запросов. В клиентском пакете SDK Azure Cosmos DB есть параметр, определяющий максимальную степень параллелизма.
| Значение | Описание |
|---|---|
| 0 | Без параллелизма (по умолчанию) |
| > 0 | Максимальное число параллельных вызовов |
| -1 | Клиентский пакет SDK выбирает оптимальную степень параллелизма. |
Для третьего нагрузочного теста этот параметр был изменен с 0 на -1. В следующей таблице перечислены результаты:
| Metric | Тест 1 | Тест 2 | Тест 3 |
|---|---|---|---|
| Пропускная способность (req/sec) | 19 | 23 | 42 |
| Средняя задержка (мс) | 669 | 569 | 215 |
| Успешные запросы. | 9,8 кб | 11 K | 20 тыс. |
| Регулируемые запросы | 2,72 КБ | 0 | 0 |
На графике нагрузочного теста не только общая пропускная способность значительно выше (оранжевая линия), но и пропускная способность соответствует нагрузке (фиолетовая линия).

Мы можем убедиться, что клиент Azure Cosmos DB выполняет запросы параллельно, просмотрев сквозное представление транзакций:

Интересно, что побочным эффектом увеличения пропускной способности является то, что количество ЕЗ, потребляемых в секунду, также увеличивается. Хотя Azure Cosmos DB не регулировал никакие запросы во время этого теста, потребление было близко к ограничению подготовленных единиц запросов:

Этот график может быть сигналом для дальнейшего масштабирования базы данных. Однако оказывается, что вместо этого можно оптимизировать запрос.
Шаг 4. Оптимизация запроса
Предыдущий нагрузочный тест показал лучшую производительность с точки зрения задержки и пропускной способности. Средняя задержка запроса сократилась на 68 %, а пропускная способность увеличилась на 220 %. Однако запрос между секциями является проблемой.
Проблема с межсекционными запросами заключается в том, что вы платите за единицы запроса в каждой секции. Если запрос выполняется только время от времени( например, один раз в час), это может не иметь значения. Но всякий раз, когда вы видите рабочую нагрузку с большим объемом чтения, которая включает межсекционный запрос, вы должны увидеть, можно ли оптимизировать запрос, включив ключ секции. (Возможно, потребуется изменить коллекцию, чтобы использовать другой ключ секции.)
Вот запрос для этого конкретного сценария:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Этот запрос выбирает записи, соответствующие определенному идентификатору владельца и месяцу или году. В первоначальной структуре ни одно из этих свойств не является ключом секции. Для этого клиент должен развернуть запрос к каждой физической секции и собрать результаты. Чтобы повысить производительность запросов, команда разработчиков изменила структуру, чтобы идентификатор владельца был ключом секции для коллекции. Таким образом, запрос может быть нацелен на определенную физическую секцию. (Azure Cosmos DB обрабатывает это автоматически. Вам не нужно управлять сопоставлением между значениями ключа секции и физическими секциями.)
После переключения коллекции на новый ключ секции значительно улучшилось потребление единиц запросов, что напрямую приводит к снижению затрат.
| Metric | Тест 1 | Тест 2 | Тест 3 | Тест 4 |
|---|---|---|---|---|
| Количество единиц запросов на операцию | 29 | 29 | 29 | 3.4 |
| Вызовы на операцию | 11 | 9 | 10 | 1 |
В представлении сквозной транзакции показано, что в прогнозируемом виде запрос считывает только одну физическую секцию:

Нагрузочный тест показывает улучшенную пропускную способность и задержку:
| Metric | Тест 1 | Тест 2 | Тест 3 | Тест 4 |
|---|---|---|---|---|
| Пропускная способность (req/sec) | 19 | 23 | 42 | 59 |
| Средняя задержка (мс) | 669 | 569 | 215 | 176 |
| Успешные запросы. | 9,8 КБ | 11 КБ | 20 тыс. | 29 КБ |
| Регулируемые запросы | 2,72 КБ | 0 | 0 | 0 |
Результатом повышения производительности является то, что загрузка ЦП узла становится очень высокой:
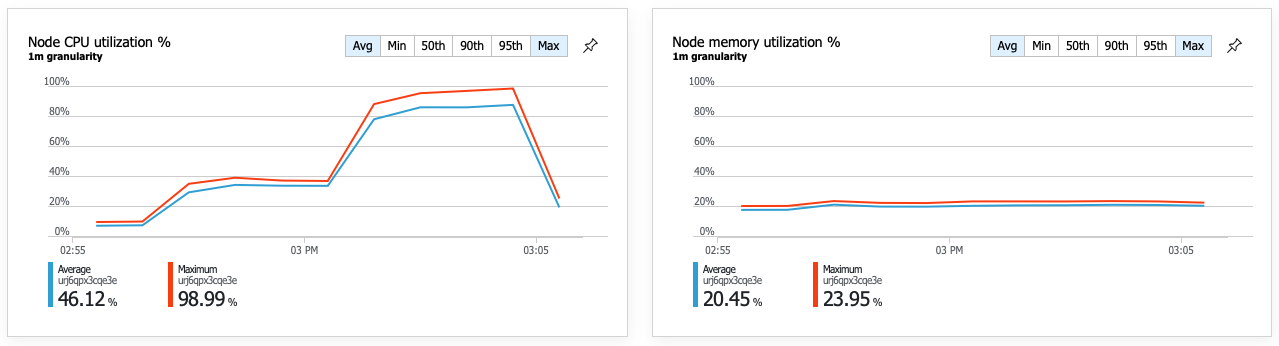
К концу нагрузочного теста средняя загрузка ЦП достигла около 90 %, а максимальная — 100 %. Эта метрика указывает, что ЦП является следующим узким местом в системе. Если требуется более высокая пропускная способность, следующим шагом может быть масштабирование службы доставки до дополнительных экземпляров.
Сводка
В этом сценарии были выявлены следующие узкие места:
- Запросы регулирования Azure Cosmos DB из-за недостаточной подготовки ЕЗ.
- Высокая задержка, вызванная запросом нескольких секций базы данных в последовательном режиме.
- Неэффективный межсекционный запрос, так как запрос не включал ключ секции.
Кроме того, использование ЦП было определено как потенциальное узкое место в более высоком масштабе. Чтобы диагностировать эти проблемы, группа разработчиков рассмотрела:
- Задержка и пропускная способность нагрузочного теста.
- Ошибки Azure Cosmos DB и потребление единиц запросов.
- Сквозное представление транзакций в Application Insight.
- Использование ЦП и памяти в аналитике контейнеров Azure Monitor.
Дальнейшие действия
Проверка антишаблонов производительности