В этой статье описывается, как команда разработчиков использовала метрики для поиска узких мест и повышения производительности распределенной системы. Статья основана на фактическом нагрузочном тестировании, которое мы выполнили для примера приложения. Приложение используется на основе базовых показателей Служба Azure Kubernetes (AKS) для микрослужб.
Этот материал входит в цикл статей. Читайте первую часть здесь.
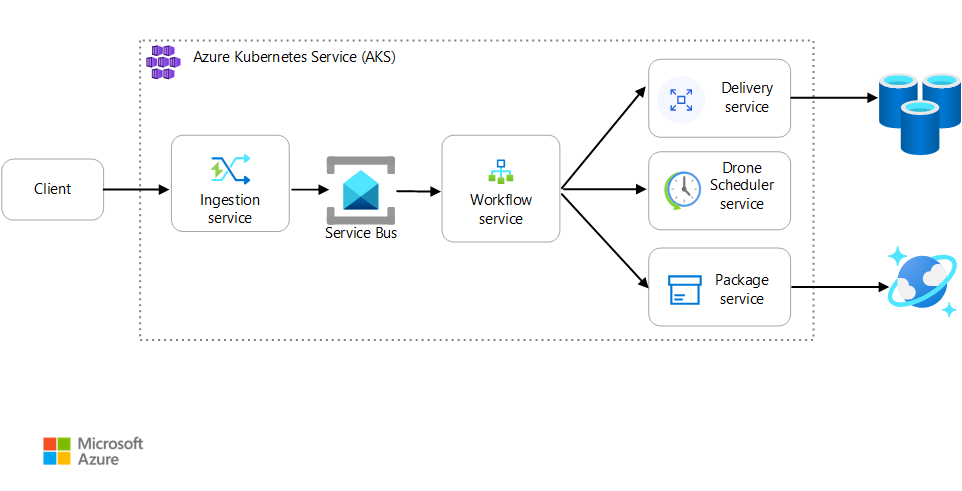
Сценарий. Клиентское приложение инициирует бизнес-транзакцию, которая включает несколько шагов.
Этот сценарий включает в себя приложение доставки с помощью дронов, которое выполняется в AKS. Клиенты используют веб-приложение для планирования доставки с помощью дронов. Для каждой транзакции требуется выполнить несколько шагов, выполняемых отдельными микрослужбами на внутренней части:
- Служба доставки управляет доставкой.
- Служба "Планировщик дронов" планирует отправку беспилотных летательных аппаратов.
- Служба пакетов управляет пакетами.
Существуют две другие службы: служба приема, которая принимает клиентские запросы и помещает их в очередь для обработки, и служба рабочего процесса, которая координирует шаги в рабочем процессе.
Дополнительные сведения об этом сценарии см. в статье Проектирование архитектуры микрослужб.
Тест 1. Базовые показатели
Для первого нагрузочного теста команда создала кластер AKS с шестью узлами и развернула три реплики каждой микрослужбы. Нагрузочный тест представлял собой нагрузочный тест, начинающийся с двух имитированных пользователей и набирающий до 40 имитированных пользователей.
| Параметр | Значение |
|---|---|
| Узлы кластера | 6 |
| Модули pod | 3 на службу |
На следующем графике показаны результаты нагрузочного теста, как показано в Visual Studio. Фиолетовая линия отображает нагрузку пользователя, а оранжевая линия — общее количество запросов.
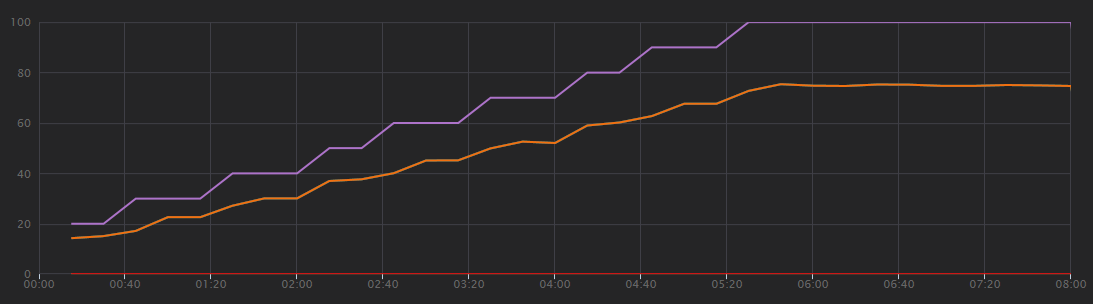
Первое, что следует понять в этом сценарии, заключается в том, что клиентские запросы в секунду не являются полезной метрикой производительности. Это связано с тем, что приложение обрабатывает запросы асинхронно, поэтому клиент сразу же получает ответ. Код ответа всегда имеет значение HTTP 202 (принято), что означает, что запрос был принят, но обработка не завершена.
Мы действительно хотим знать, соответствует ли серверная часть скорости запросов. Очередь служебной шины может поглощать пики, но если серверная часть не может справиться с постоянной нагрузкой, обработка будет все больше и больше отставать.
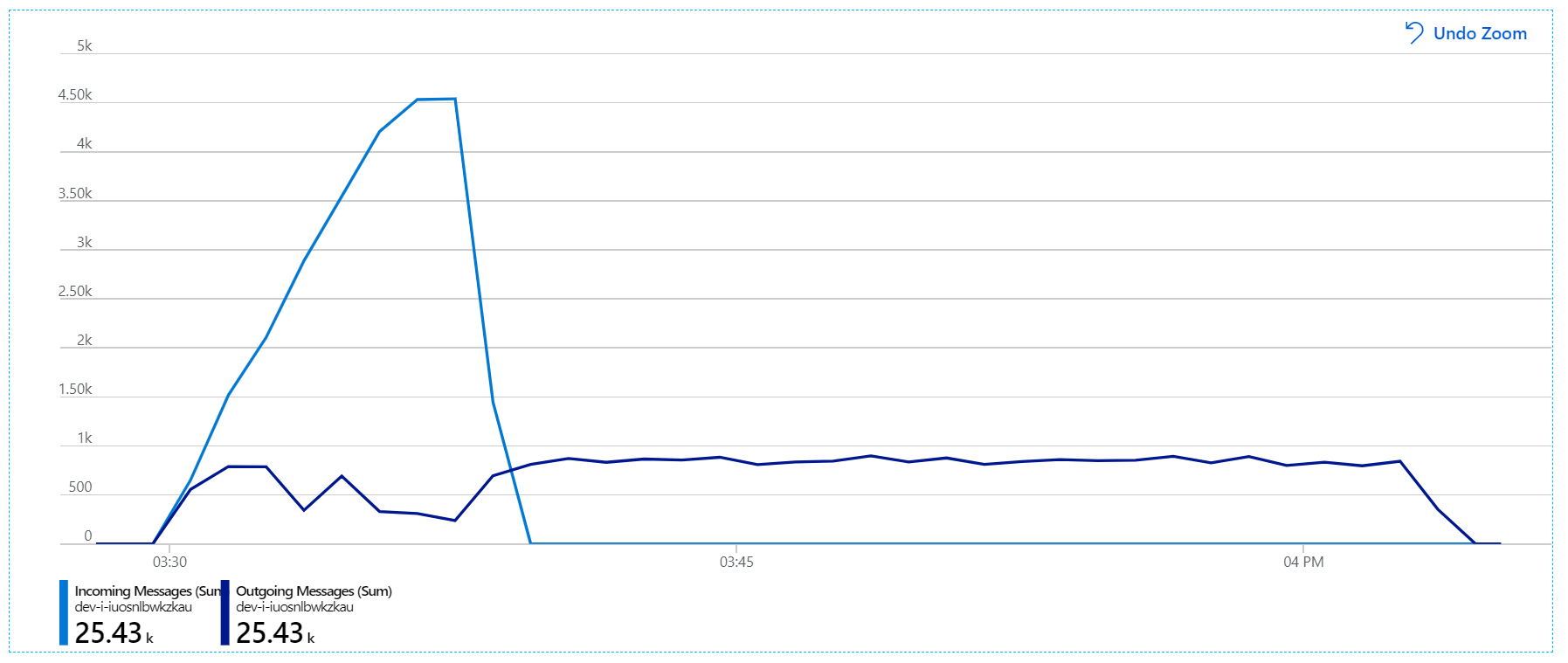
Ниже приведен более информативный график. Он отображает количество входящих и исходящих сообщений в очереди служебной шины. Входящие сообщения отображаются светло-синим цветом, а исходящие — темно-синим:
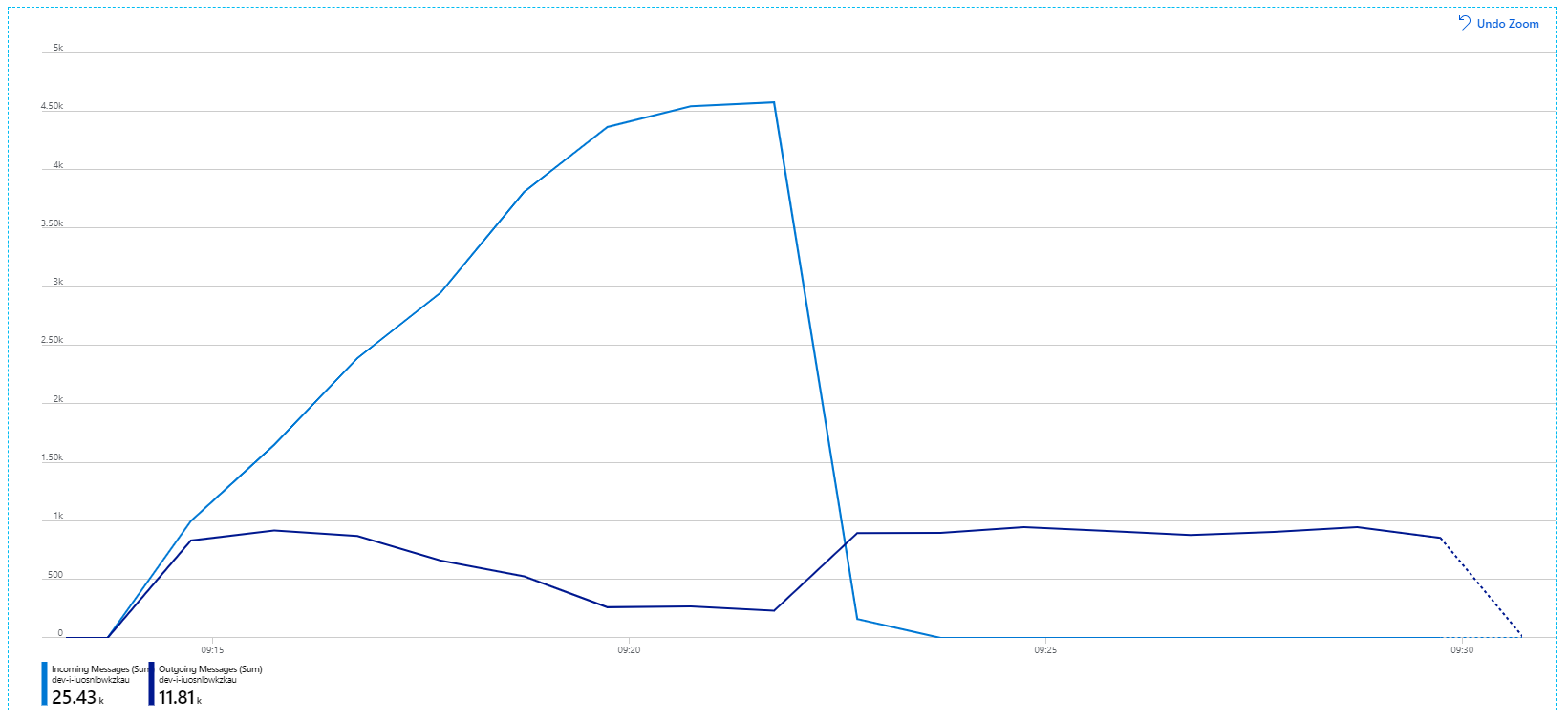
На этой диаграмме показано, что частота входящих сообщений увеличивается, достигает пика, а затем возвращается к нулю в конце нагрузочного теста. Но количество исходящих сообщений достигает пика в начале теста, а затем фактически снижается. Это означает, что служба рабочих процессов, которая обрабатывает запросы, не выполняется. Даже после завершения нагрузочного теста (около 9:22 на графике) сообщения по-прежнему обрабатываются, так как служба рабочего процесса продолжает очищать очередь.
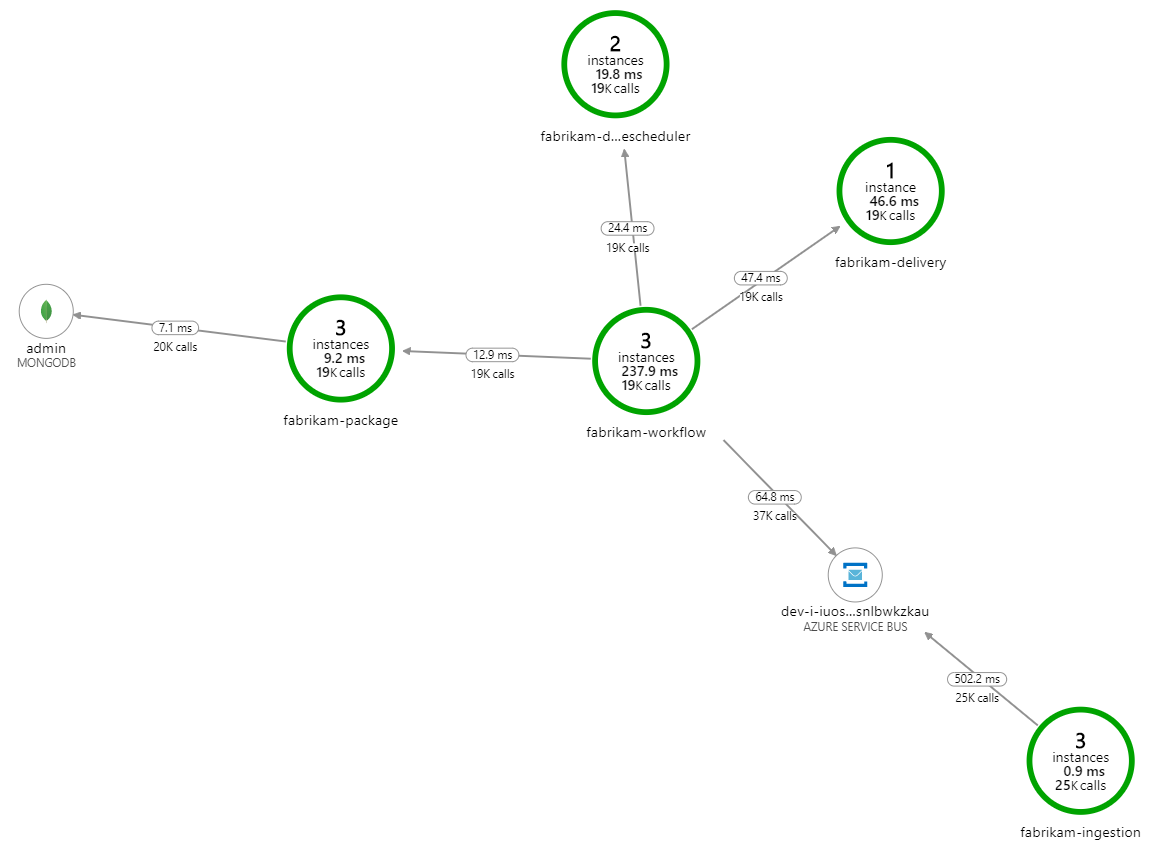
Что замедляет обработку? Первое, что нужно найти, — это ошибки или исключения, которые могут указывать на системную проблему. На карте приложений в Azure Monitor отображается график вызовов между компонентами. Это быстрый способ определить проблемы, а затем щелкнуть, чтобы получить дополнительные сведения.
Конечно, карта приложений показывает, что служба рабочего процесса получает ошибки от службы доставки:
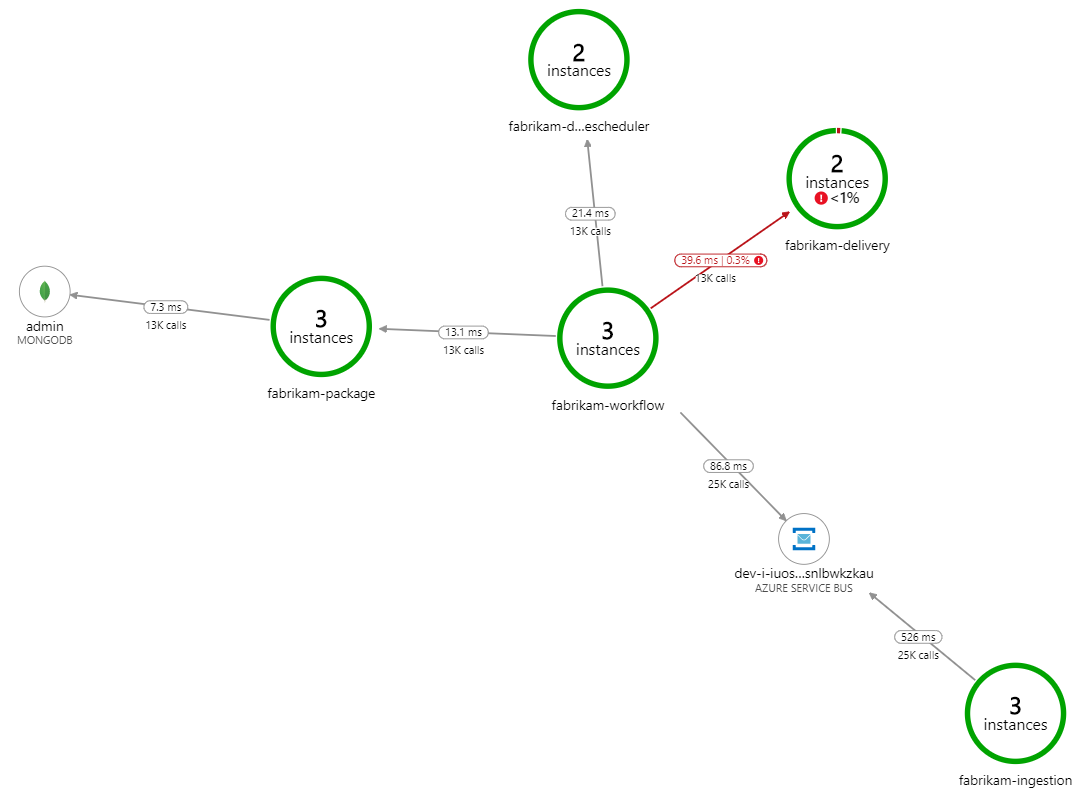
Чтобы просмотреть дополнительные сведения, можно выбрать узел в графе и щелкнуть сквозное представление транзакций. В этом случае это показывает, что служба доставки возвращает ошибки HTTP 500. Сообщения об ошибках указывают на то, что возникает исключение из-за ограничения памяти в Кэш Azure для Redis.
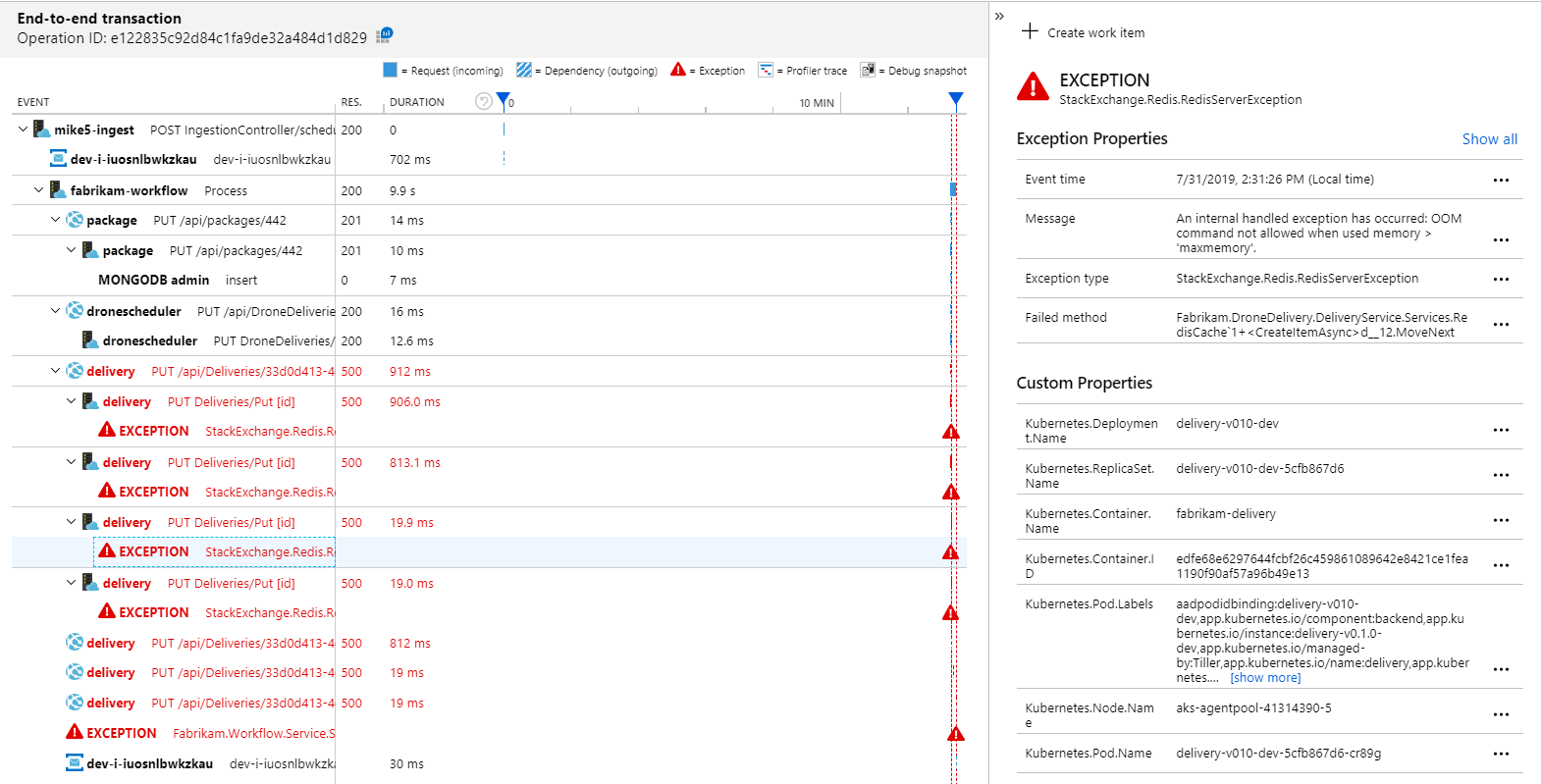
Вы можете заметить, что эти вызовы Redis не отображаются на карте приложений. Это связано с тем, что библиотека .NET для Application Insights не имеет встроенной поддержки отслеживания Redis как зависимости. (Список поддерживаемых встроенных элементов см. в статье Автоматическое сбор зависимостей.) В качестве резервного варианта можно использовать API TrackDependency для отслеживания любой зависимости. Нагрузочное тестирование часто выявляет такие пробелы в телеметрии, которые можно исправить.
Тест 2. Увеличение размера кэша
Для второго нагрузочного теста группа разработчиков увеличила размер кэша в Кэш Azure для Redis. (См. раздел Масштабирование Кэш Azure для Redis.) Это изменение устранило исключения нехватки памяти, и теперь на карте приложений отображается ноль ошибок:
Однако в обработке сообщений по-прежнему наблюдается резкое запаздывание. На пике нагрузочного теста скорость входящих сообщений превышает 5× скорость исходящих сообщений:
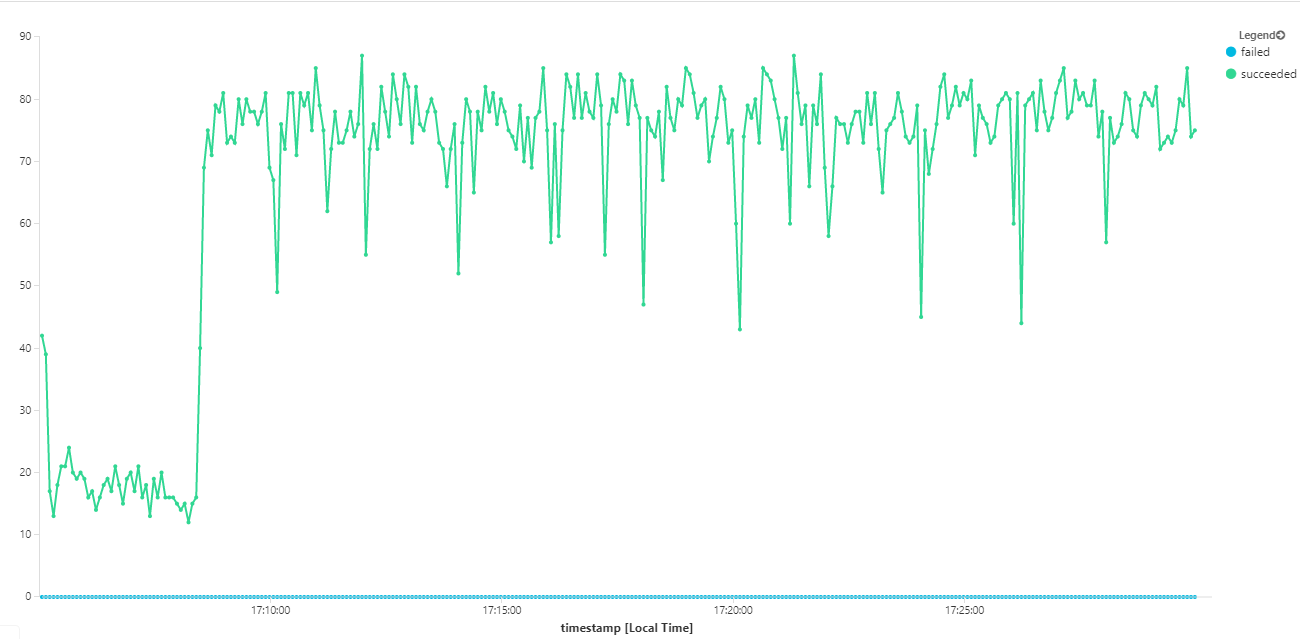
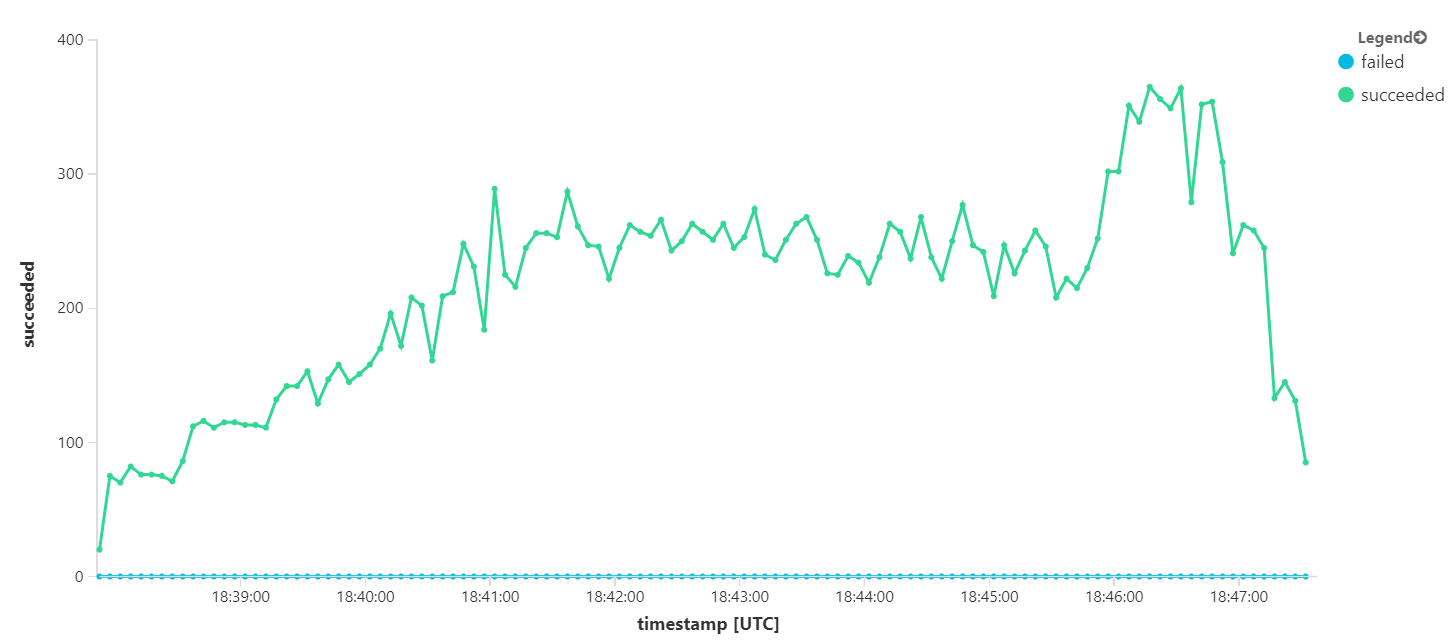
На следующем графике измеряется пропускная способность с точки зрения завершения сообщений, то есть скорость, с которой служба рабочего процесса помечает сообщения служебной шины как завершенные. Каждая точка на графе представляет 5 секунд данных, показывая максимальную пропускную способность около 16 секунд в секунду.
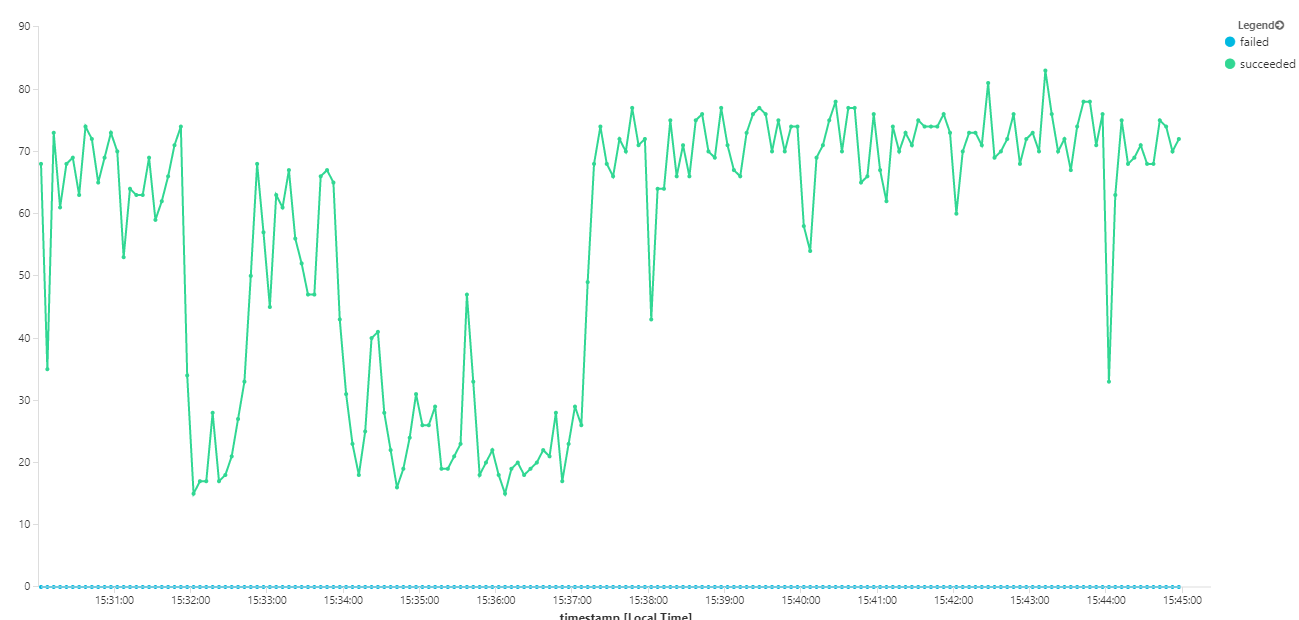
Этот граф был создан путем выполнения запроса в рабочей области Log Analytics на языке запросов Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Тест 3. Горизонтальное масштабирование серверных служб
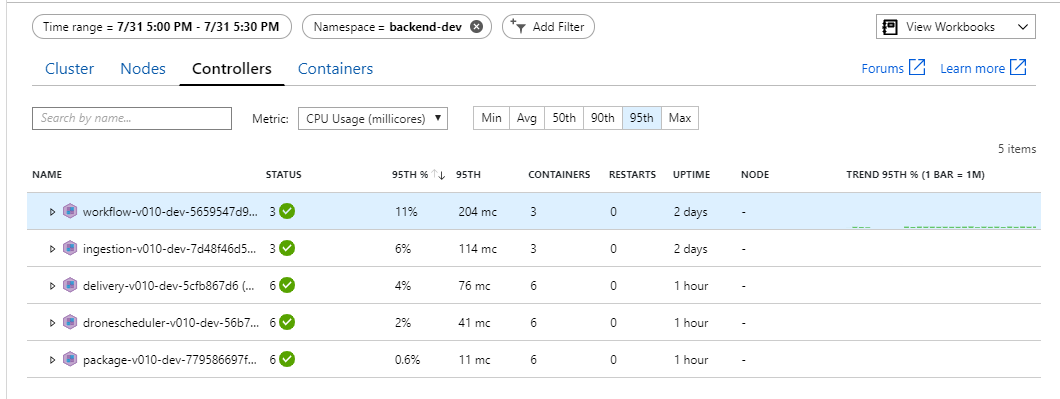
Похоже, что это узкое место является внутренней частью. Следующий простой шаг — масштабировать бизнес-службы (планировщик пакетов, доставки и дронов) и проверить, повысится ли пропускная способность. Для следующего нагрузочного теста команда масштабирует эти службы с трех до шести реплик.
| Параметр | Значение |
|---|---|
| Узлы кластера | 6 |
| Служба приема | 3 реплики |
| Служба рабочих процессов | 3 реплики |
| Пакеты, доставка, службы планировщика дронов | 6 реплик каждая |
К сожалению, этот нагрузочный тест показывает лишь скромное улучшение. Исходящие сообщения по-прежнему не поспевает за входящими сообщениями:
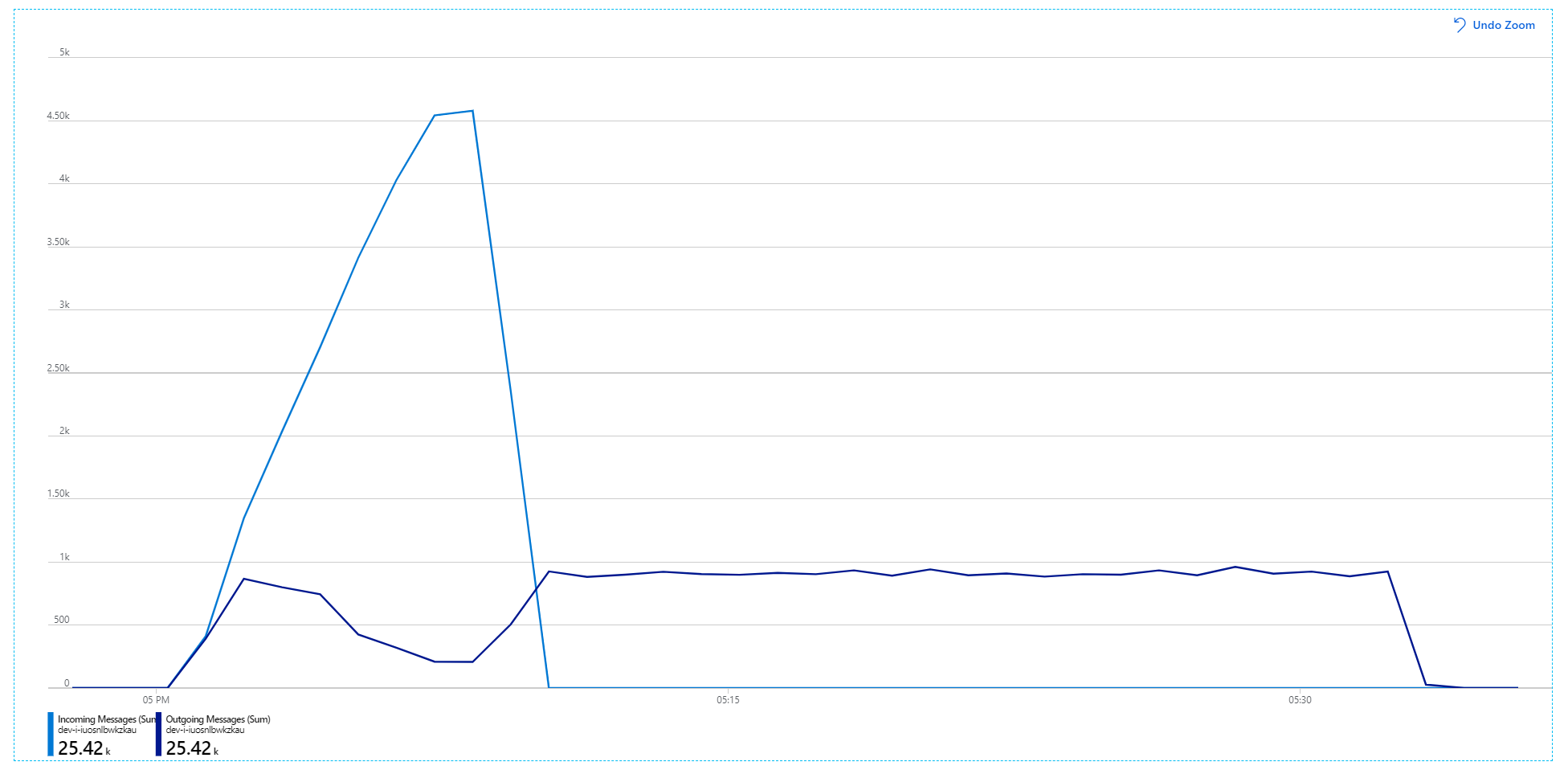
Пропускная способность является более согласованной, но достигнутое максимальное значение примерно такое же, как и в предыдущем тесте:
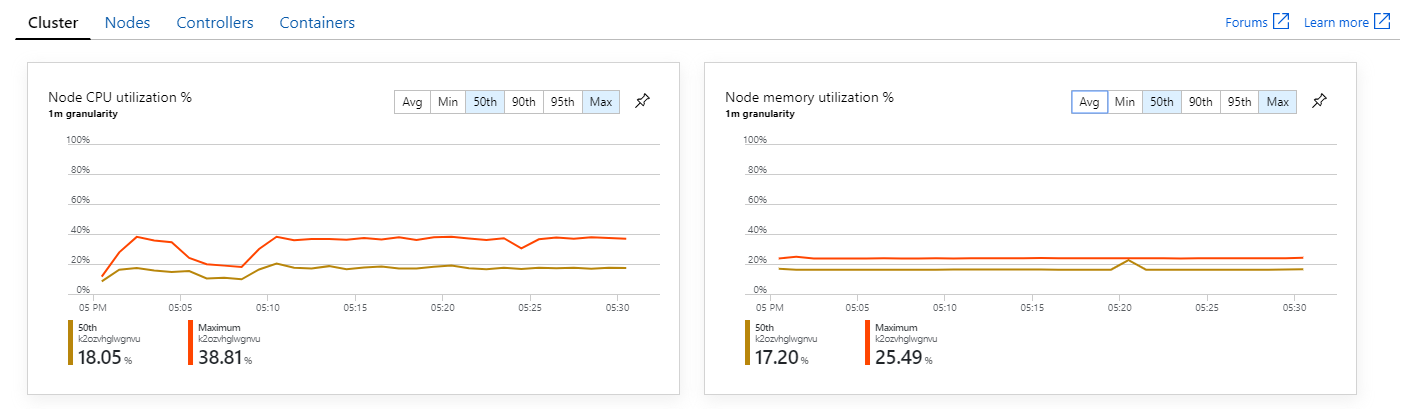
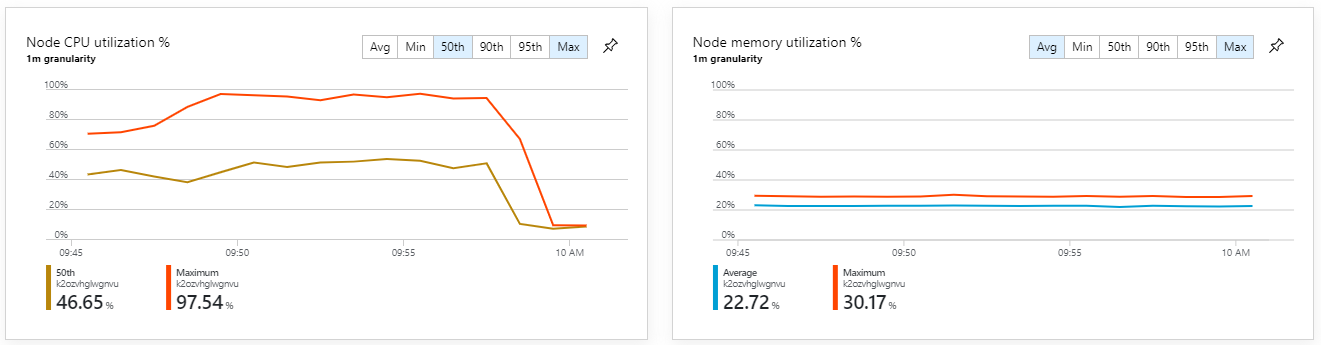
Кроме того, если взглянуть на аналитику контейнеров Azure Monitor, выясним, что проблема не вызвана нехваткой ресурсов в кластере. Во-первых, метрики уровня узла показывают, что загрузка ЦП остается менее 40 % даже на 95-м процентиле, а использование памяти составляет около 20 %.
В среде Kubernetes отдельные модули pod могут быть ограничены ресурсами, даже если узлы не являются. Но в представлении уровня pod показано, что все объекты pod работоспособны.
Из этого теста кажется, что простое добавление дополнительных модулей pod в внутренний элемент не поможет. Следующим шагом является более внимательное изучение службы рабочих процессов, чтобы понять, что происходит при обработке сообщений. Application Insights показывает, что средняя продолжительность работы службы Process рабочего процесса составляет 246 мс.
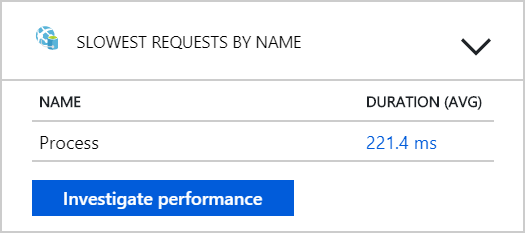
Мы также можем выполнить запрос, чтобы получить метрики для отдельных операций в каждой транзакции:
| target | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| доставки | 37 | 57 |
| Пакет | 12 | 17 |
| dronescheduler | 21 | 41 |
Первая строка в этой таблице представляет очередь служебной шины. Другие строки — это вызовы серверных служб. Для справки ниже приведен запрос Log Analytics для этой таблицы:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
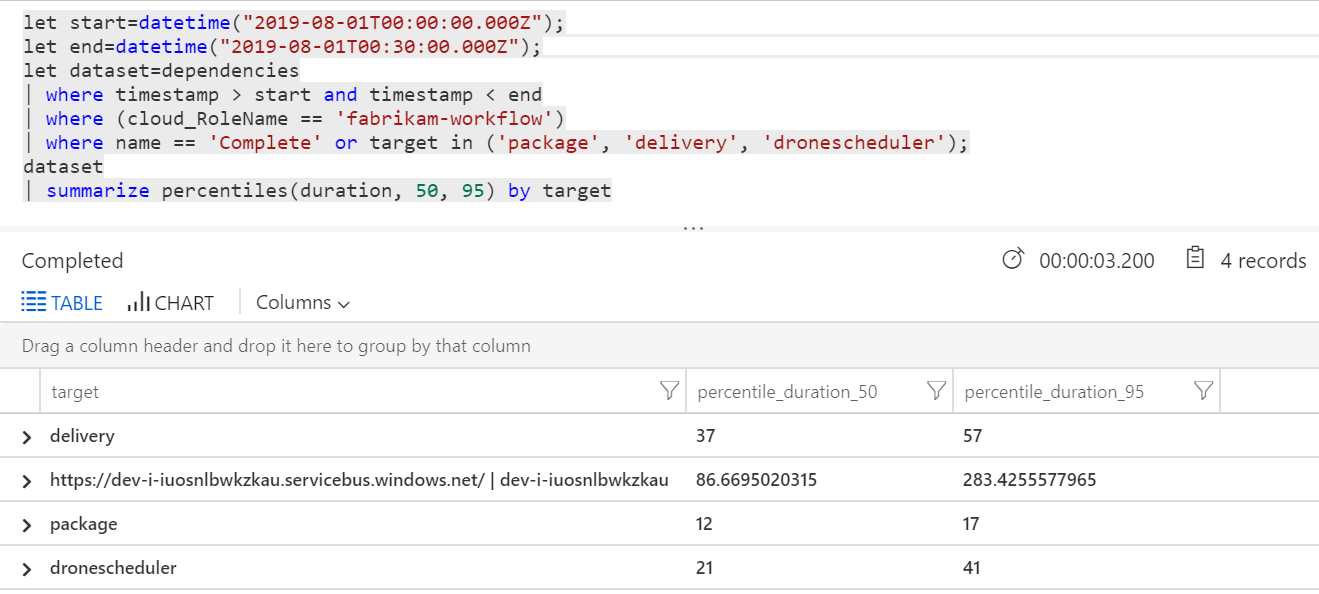
Эти задержки выглядят разумными. Но вот основные сведения: если общее время операции составляет около 250 мс, это задает строгую верхнюю границу о том, как быстро сообщения могут обрабатываться в последовательном режиме. Таким образом, ключом к повышению пропускной способности является больший параллелизм.
Это должно быть возможно в этом сценарии по двум причинам:
- Это сетевые вызовы, поэтому большая часть времени тратится на ожидание завершения ввода-вывода.
- Сообщения независимы и не должны обрабатываться по порядку.
Тест 4. Увеличение параллелизма
Для этого теста команда сосредоточилась на увеличении параллелизма. Для этого они скорректировали два параметра в клиенте служебной шины, используемом службой рабочих процессов:
| Параметр | Описание | Значение по умолчанию | Новое значение |
|---|---|---|---|
MaxConcurrentCalls |
Максимальное количество сообщений для параллельной обработки. | 1 | 20 |
PrefetchCount |
Количество сообщений, которые клиент получит заранее в свой локальный кэш. | 0 | 3000 |
Дополнительные сведения об этих параметрах см. в статье Рекомендации по повышению производительности с помощью обмена сообщениями служебной шины. При выполнении теста с этими параметрами получена следующая диаграмма:
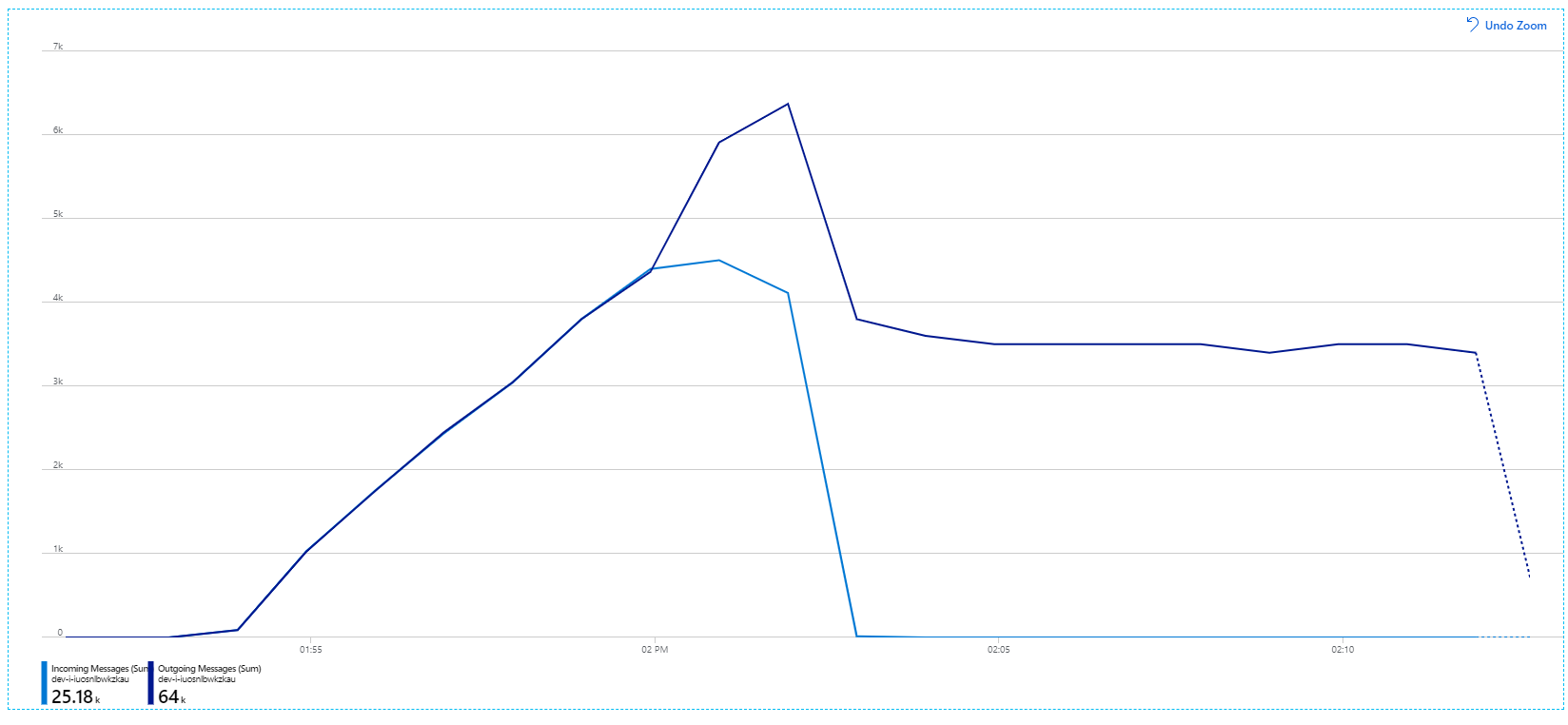
Помните, что входящие сообщения отображаются светло-синим цветом, а исходящие — темно-синим.
На первый взгляд, это очень странный граф. В течение некоторого времени скорость исходящих сообщений точно отслеживает скорость входящего трафика. Но затем, примерно в 2:03, скорость входящих сообщений отключается, в то время как количество исходящих сообщений продолжает расти, фактически превышая общее количество входящих сообщений. Это кажется невозможным.
Ключ к этой тайне можно найти в представлении Зависимости в Application Insights. На этой диаграмме перечислены все вызовы, которые служба рабочего процесса совершила в служебную шину:
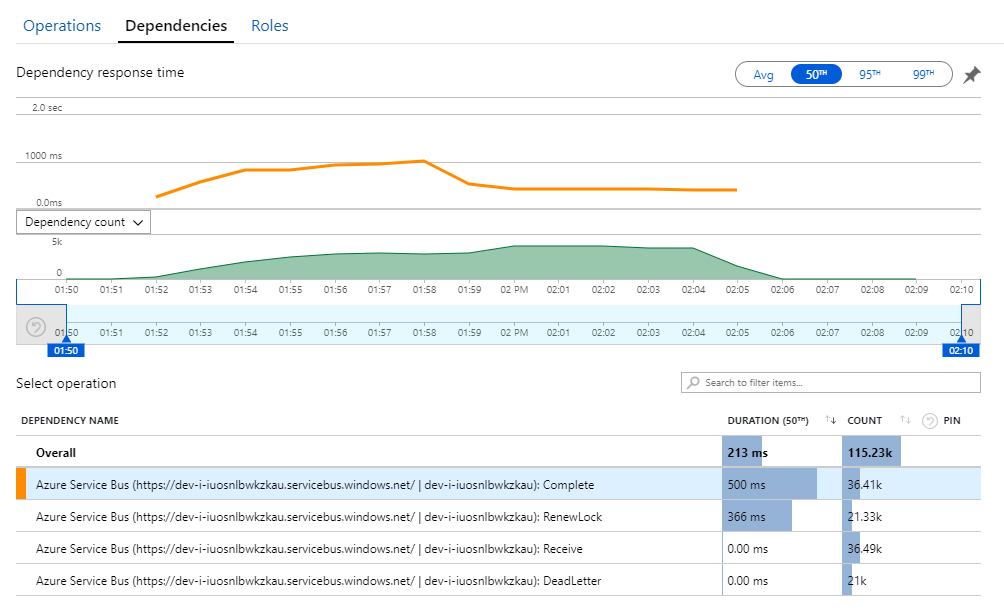
Обратите внимание, что запись для DeadLetter. Эти вызовы указывают, что сообщения попадают в очередь недоставленных сообщений служебной шины.
Чтобы понять, что происходит, необходимо понять семантику Peek-Lock в служебной шине. Когда клиент использует Peek-Lock, служебная шина атомарно извлекает и блокирует сообщение. Пока блокировка удерживается, сообщение гарантированно не будет доставлено другим получателям. Если срок действия блокировки истекает, сообщение становится доступным для других получателей. После максимального количества попыток доставки (которое можно настроить), служебная шина помещает сообщения в очередь недоставленных сообщений, где их можно будет проверить позже.
Помните, что служба рабочих процессов выполняет предварительную выборку больших пакетов сообщений — 3000 сообщений за раз). Это означает, что общее время обработки каждого сообщения больше, что приводит к истечению времени ожидания сообщений, возврату в очередь и, в конечном итоге, в очереди недоставленных сообщений.
Это поведение также можно увидеть в исключениях, где записываются многочисленные MessageLostLockException исключения:
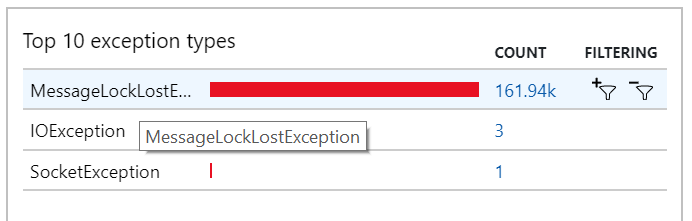
Тест 5. Увеличение длительности блокировки
Для этого нагрузочного теста длительность блокировки сообщений была задана равным 5 минутам, чтобы избежать превышения времени ожидания блокировки. График входящих и исходящих сообщений теперь показывает, что система не отстает от скорости входящих сообщений:
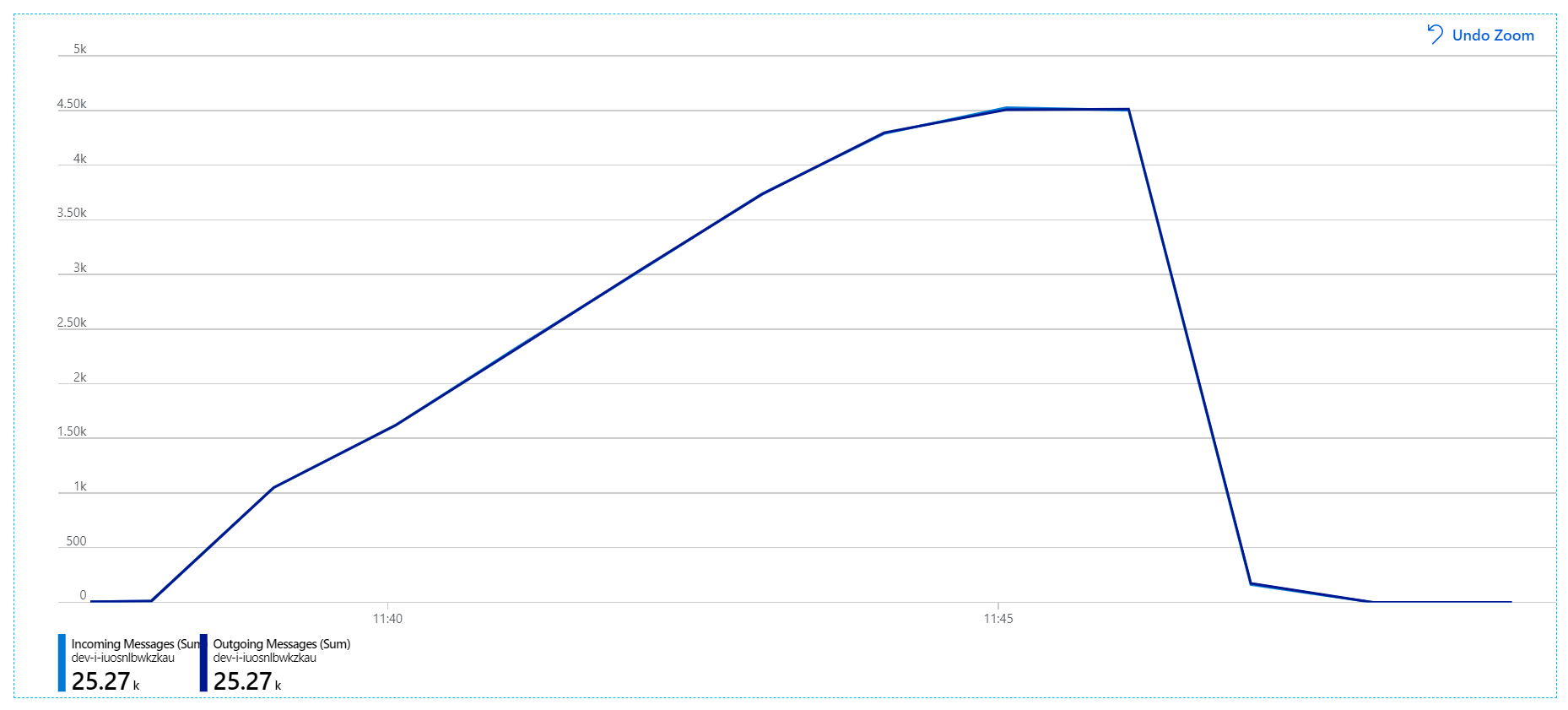
За общую продолжительность 8-минутного нагрузочного теста приложение выполнило 25 тыс. операций с пиковой пропускной способностью 72 операций/с, что на 400 % увеличивает максимальную пропускную способность.
Однако выполнение того же теста с большей продолжительностью показало, что приложение не может поддерживать эту скорость:
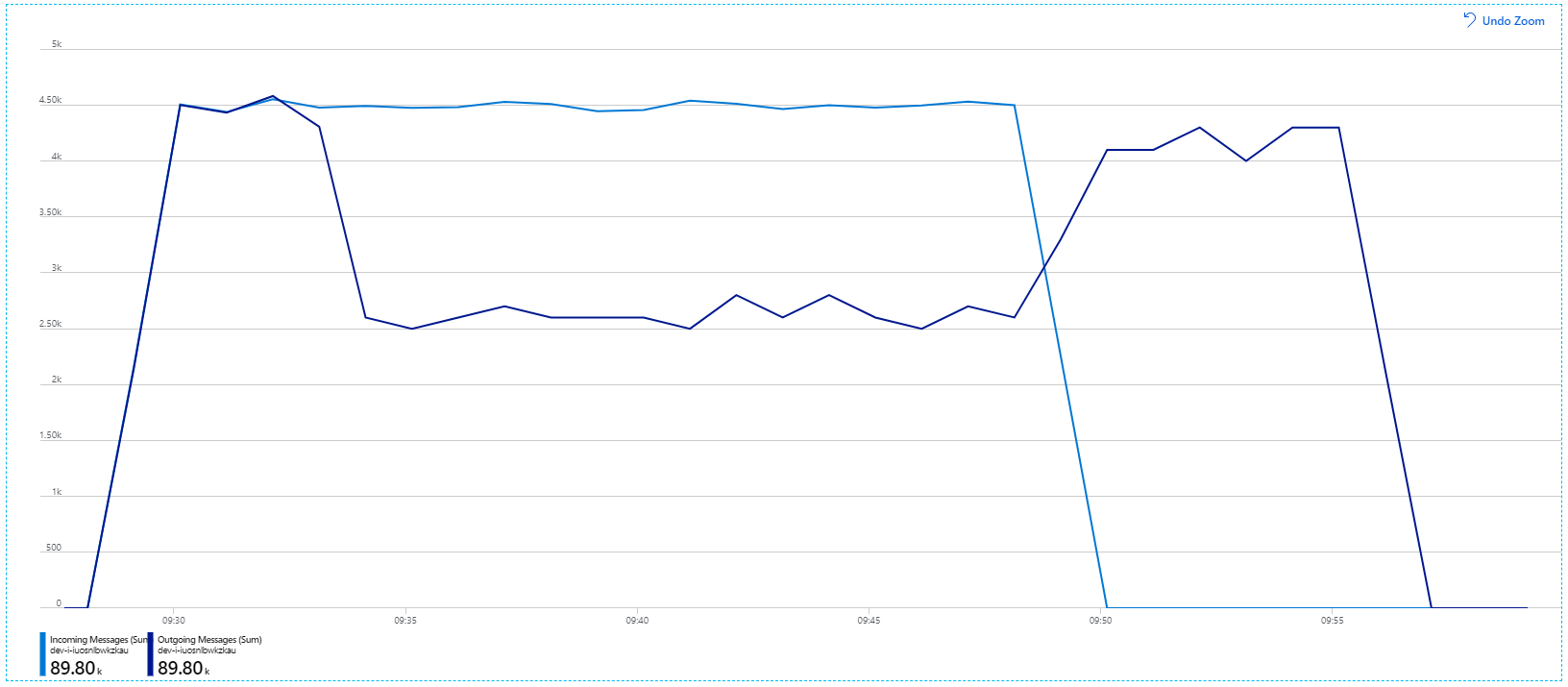
Метрики контейнера показывают, что максимальная загрузка ЦП близка к 100 %. На этом этапе приложение будет привязано к ЦП. Масштабирование кластера может повысить производительность в отличие от предыдущей попытки горизонтального масштабирования.
Тест 6. Горизонтальное масштабирование серверных служб (снова)
Для окончательного нагрузочного теста в серии команда масштабирует кластер Kubernetes и модули pod следующим образом:
| Параметр | Значение |
|---|---|
| Узлы кластера | 12 |
| Служба приема | 3 реплики |
| Служба рабочих процессов | 6 реплик |
| Пакеты, доставка, службы планировщика дронов | 9 реплик каждая |
Этот тест привел к более высокой устойчивой пропускной способности без значительных задержек в обработке сообщений. Кроме того, загрузка ЦП узла осталась ниже 80 %.
Сводка
В этом сценарии были выявлены следующие узкие места:
- Исключения нехватки памяти в Кэш Azure для Redis.
- Отсутствие параллелизма при обработке сообщений.
- Недостаточная длительность блокировки сообщений, что приводит к превышению времени ожидания блокировки и добавлению сообщений в очередь недоставленных сообщений.
- Нехватка ЦП.
Для диагностики этих проблем команда разработчиков использовала следующие метрики:
- Частота входящих и исходящих сообщений служебной шины.
- Схема приложений в Application Insights.
- Ошибки и исключения.
- Пользовательские запросы Log Analytics.
- Использование ЦП и памяти в аналитике контейнеров Azure Monitor.
Дальнейшие действия
Дополнительные сведения о проектировании этого сценария см. в разделе Проектирование архитектуры микрослужб.