Руководство. Выполнение поиска по сходству векторов в Azure OpenAI с помощью Кэш Azure для Redis
В этом руководстве описаны основные варианты использования поиска сходства векторов. Вы будете использовать внедрения, созданные службой Azure OpenAI, и встроенные возможности поиска векторов уровня Enterprise Кэш Azure для Redis для запроса набора данных фильмов для поиска наиболее релевантного соответствия.
В этом руководстве используется набор данных "Википедия фильм графиков", который содержит описания сюжетов более 35000 фильмов из Википедии, охватывающих годы 1901-2017. Набор данных содержит сводку по сюжету для каждого фильма, а также метаданные, такие как год выпуска фильма, режиссеры, основной актер и жанр. Вы следуйте инструкциям руководства по созданию внедрения на основе сводки графиков и использования других метаданных для выполнения гибридных запросов.
В этом руководстве описано следующее:
- Создание экземпляра Кэш Azure для Redis, настроенного для векторного поиска
- Установите Azure OpenAI и другие необходимые библиотеки Python.
- Скачайте набор данных фильма и подготовьте его к анализу.
- Используйте модель внедрения текста ada-002 (версия 2) для создания внедрения.
- Создание векторного индекса в Кэш Azure для Redis
- Используйте совместное сходство с результатами поиска ранжирования.
- Используйте функции гибридного запроса через RediSearch , чтобы префильтровать данные и сделать векторный поиск еще более эффективным.
Важно!
В этом руководстве вы узнаете, как создать Jupyter Notebook. Вы можете следовать этому руководству с файлом кода Python (.py) и получить аналогичные результаты, но вам потребуется добавить все блоки кода в этом руководстве в .py файл и выполнить один раз, чтобы просмотреть результаты. Другими словами, Jupyter Notebook предоставляет промежуточные результаты при выполнении ячеек, но это не следует ожидать при работе в файле кода Python.
Важно!
Если вы хотите продолжить работу в завершенной записной книжке Jupyter, скачайте файл записной книжки Jupyter с именем tutorial.ipynb и сохраните его в новой папке redis-vector .
Необходимые компоненты
- подписка Azure — создайте бесплатную учетную запись.
- Доступ, предоставленный Azure OpenAI в требуемой подписке Azure Сейчас, необходимо подать заявку на доступ к Azure OpenAI. Вы можете подать заявку на доступ к Azure OpenAI, выполнив форму по адресу https://aka.ms/oai/access.
- Python версии 3.7.1 или более поздней версии
- Записные книжки Jupyter (необязательно)
- Ресурс Azure OpenAI с развернутой моделью text-embedding-ada-002 (версия 2). Эта модель в настоящее время доступна только в определенных регионах. Инструкции по развертыванию модели см. в руководстве по развертыванию ресурсов.
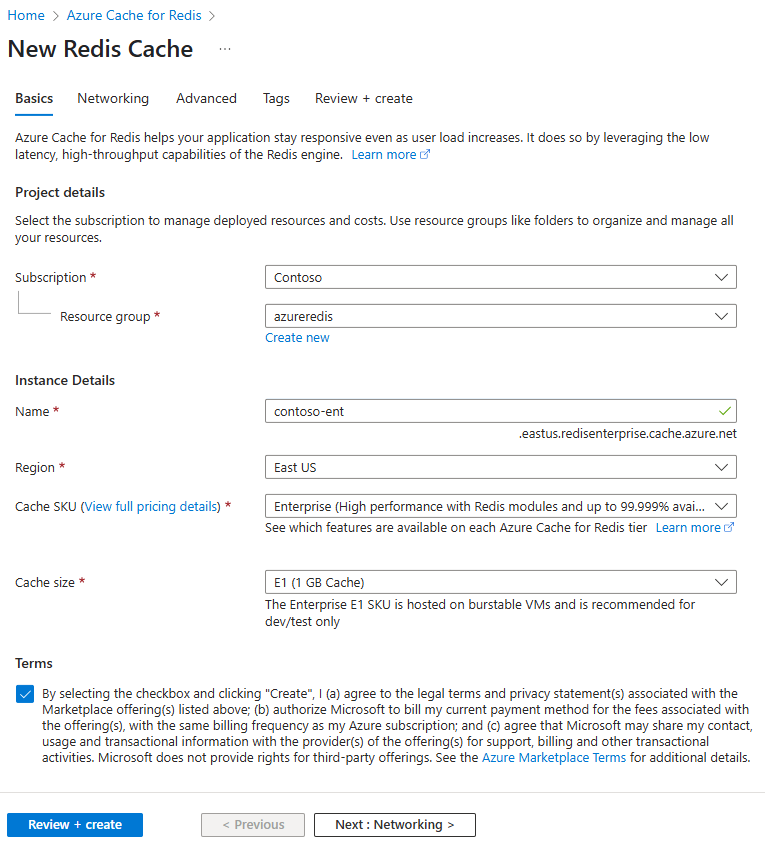
Создание экземпляра Кэш Azure для Redis
Следуйте инструкциям из краткого руководства по созданию кэша Redis Enterprise. На странице "Дополнительно" убедитесь, что вы добавили модуль RediSearch и выбрали политику корпоративного кластера. Все остальные параметры могут соответствовать умолчанию, описанному в кратком руководстве.
Создание кэша занимает несколько минут. Вы можете перейти к следующему шагу в то же время.
Настройка среды разработки
Создайте папку на локальном компьютере с именем redis-vector в расположении, где обычно сохраняются проекты.
Создайте файл Python (tutorial.py) или записную книжку Jupyter (tutorial.ipynb) в папке.
Установите необходимые пакеты Python:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Скачивание набора данных
Откройте браузер и перейдите по адресу https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Войдите или зарегистрируйтесь в Kaggle. Для скачивания файла требуется регистрация.
Выберите ссылку "Скачать " в Kaggle, чтобы скачать файл archive.zip .
Извлеките файл archive.zip и переместите wiki_movie_plots_deduped.csv в папку redis-vector.
Импорт библиотек и настройка сведений о подключении
Чтобы успешно выполнить вызов к Azure OpenAI, вам потребуется конечная точка и ключ. Для подключения к Кэш Azure для Redis также требуется конечная точка и ключ.
Перейдите к ресурсу Azure OpenAI в портал Azure.
Найдите конечную точку и ключи в разделе "Управление ресурсами". Скопируйте конечную точку и ключ доступа, так как они потребуются для проверки подлинности вызовов API. Пример конечной точки:
https://docs-test-001.openai.azure.com. Вы можете использоватьKEY1илиKEY2.Перейдите на страницу обзора ресурса Кэш Azure для Redis в портал Azure. Скопируйте конечную точку.
Найдите ключи Access в разделе Параметры. Скопируйте ключ доступа. Вы можете использовать
PrimaryилиSecondary.Добавьте следующий код в новую ячейку кода:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Обновите значение и значения ключей
API_KEYRESOURCE_ENDPOINTи конечных точек из развертывания Azure OpenAI.DEPLOYMENT_NAMEследует задать имя развертывания с помощьюtext-embedding-ada-002 (Version 2)модели внедрения иMODEL_NAMEбыть используемой конкретной моделью внедрения.Обновите
REDIS_ENDPOINTиREDIS_PASSWORDиспользуя значение конечной точки и ключа из экземпляра Кэш Azure для Redis.Важно!
Настоятельно рекомендуется использовать переменные среды или диспетчер секретов, например Azure Key Vault , чтобы передать сведения о ключе API, конечной точке и имени развертывания. Эти переменные задаются в виде открытого текста в целях простоты.
Выполните ячейку кода 2.
Импорт набора данных в pandas и обработка данных
Затем вы считываете CSV-файл в кадр данных Pandas.
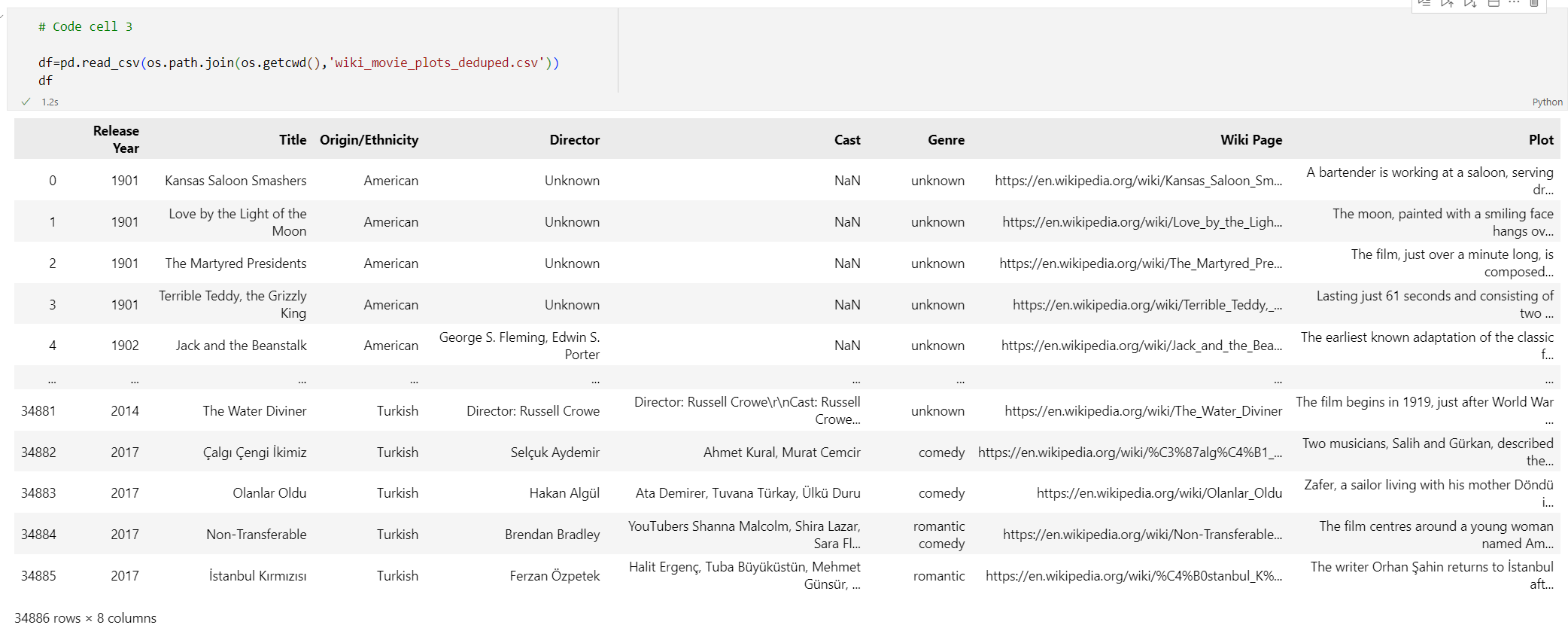
Добавьте следующий код в новую ячейку кода:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfВыполните ячейку кода 3. Должен появиться следующий результат:
Затем обработайте данные, добавив
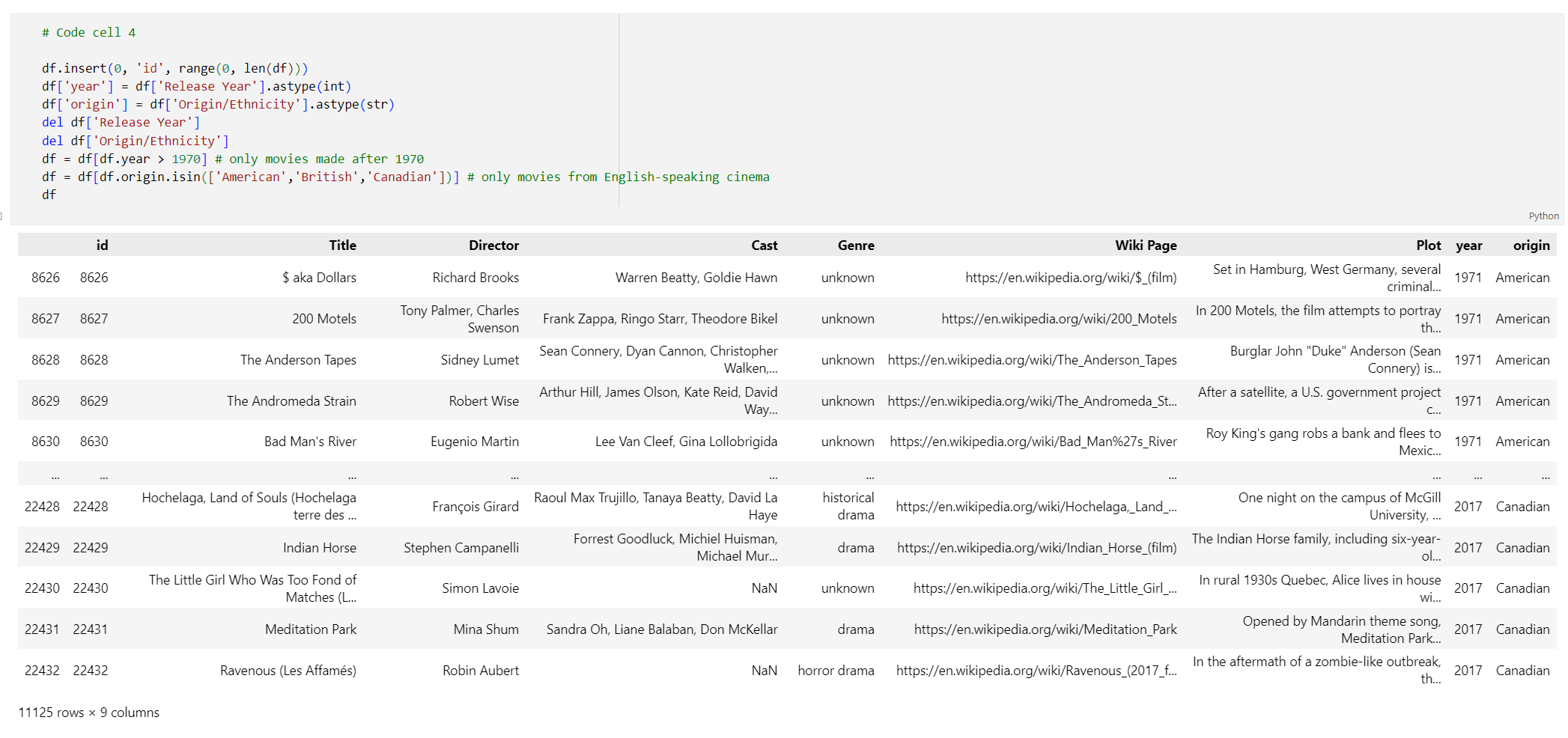
idиндекс, удаляя пробелы из заголовков столбцов, и фильтрует фильмы, чтобы принимать только фильмы, сделанные после 1970 года и из англоязычных стран. Этот шаг фильтрации уменьшает количество фильмов в наборе данных, что снижает затраты и время, необходимые для создания внедрения. Вы можете изменить или удалить параметры фильтра на основе ваших предпочтений.Чтобы отфильтровать данные, добавьте следующий код в новую ячейку кода:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfВыполните ячейку кода 4. Должны отобразиться следующие результаты:
Создайте функцию для очистки данных, удаляя пробелы и препинания, а затем используйте ее для кадра данных, содержащего график.
Добавьте следующий код в новую ячейку кода и выполните его:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Наконец, удалите все записи, содержащие описания графиков, которые слишком длинны для модели внедрения. (Другими словами, для них требуется больше маркеров, чем ограничение на 8192 маркера.) затем вычислите количество маркеров, необходимых для создания внедрения. Это также влияет на цены на внедрение поколения.
Добавьте следующий код в новую ячейку кода:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Выполните ячейку кода 6. Вы должны увидеть следующий результат:
Number of movies: 11125 Number of tokens required:7044844Важно!
Ознакомьтесь с ценами на Службу Azure OpenAI, чтобы свести затраты на создание внедрения на основе количества необходимых маркеров.


Загрузка кадра данных в LangChain
Загрузите кадр данных в LangChain с помощью DataFrameLoader класса. После того как данные будут использоваться в документах LangChain, гораздо проще использовать библиотеки LangChain для создания внедрения и проведения поиска сходства. Задайте для этого столбца диаграмму таким page_content_column образом, чтобы внедрения создавались в этом столбце.
Добавьте следующий код в новую ячейку кода и выполните его:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Создание внедрения и загрузка их в Redis
Теперь, когда данные были отфильтрованы и загружены в LangChain, вы создадите внедренные элементы, чтобы запросить график для каждого фильма. Следующий код настраивает Azure OpenAI, создает внедрения и загружает векторы внедрения в Кэш Azure для Redis.
Добавьте следующий код в новую ячейку кода:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Выполните ячейку кода 8. Это может занять более 30 минут. Также
redis_schema.yamlсоздается файл. Этот файл полезен, если вы хотите подключиться к индексу в Кэш Azure для Redis экземпляре без повторного создания внедрения.
Важно!
Скорость создания внедрения зависит от квоты, доступной модели Azure OpenAI. Квота 240k токенов в минуту займет около 30 минут для обработки маркеров 7M в наборе данных.
Выполнение запросов векторного поиска
Теперь, когда набор данных, API службы Azure OpenAI и экземпляр Redis настроены, можно выполнять поиск по векторам. В этом примере возвращаются первые 10 результатов для данного запроса.
Добавьте следующий код в файл кода Python:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Выполните ячейку кода 9. Должен появиться следующий результат:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Оценка сходства возвращается вместе с порядковый рейтинг фильмов по сходству. Обратите внимание, что более конкретные запросы имеют оценки сходства, уменьшая их быстрее вниз по списку.
Гибридные поиски
Так как RediSearch также предоставляет широкие возможности поиска поверх векторного поиска, можно фильтровать результаты по метаданным в наборе данных, таким как жанр фильма, приведение, год выпуска или директор. В этом случае фильтруйте на основе жанра
comedy.Добавьте следующий код в новую ячейку кода:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Выполните ячейку кода 10. Должен появиться следующий результат:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
С помощью Кэш Azure для Redis и Службы Azure OpenAI можно использовать внедрение и векторный поиск для добавления мощных возможностей поиска в приложение.
Очистка ресурсов
Если вы хотите продолжить использовать ресурсы, созданные в этой статье, сохраните группу ресурсов.
В противном случае, если вы закончите работу с ресурсами, можно удалить созданную группу ресурсов Azure, чтобы избежать расходов.
Важно!
Удаление группы ресурсов — процесс необратимый. Группа ресурсов и все содержащиеся в ней ресурсы удаляются без возможности восстановления. Будьте внимательны, чтобы случайно не удалить не ту группу ресурсов или не те ресурсы. Если вы создали ресурсы внутри существующей группы ресурсов, содержащей ресурсы, которые необходимо сохранить, можно удалить каждый ресурс по отдельности, а не удалить группу ресурсов.
Удаление группы ресурсов
Войдите на портал Azure и щелкните Группы ресурсов.
Выберите группу ресурсов, которую нужно удалить.
Если существует множество групп ресурсов, используйте фильтр для любого поля... введите имя группы ресурсов, созданной для этой статьи. Выберите группу ресурсов в списке результатов.
Выберите команду Удалить группу ресурсов.
Подтвердите операцию удаления группы ресурсов. Введите имя группы ресурсов, которую необходимо удалить, и щелкните Удалить.
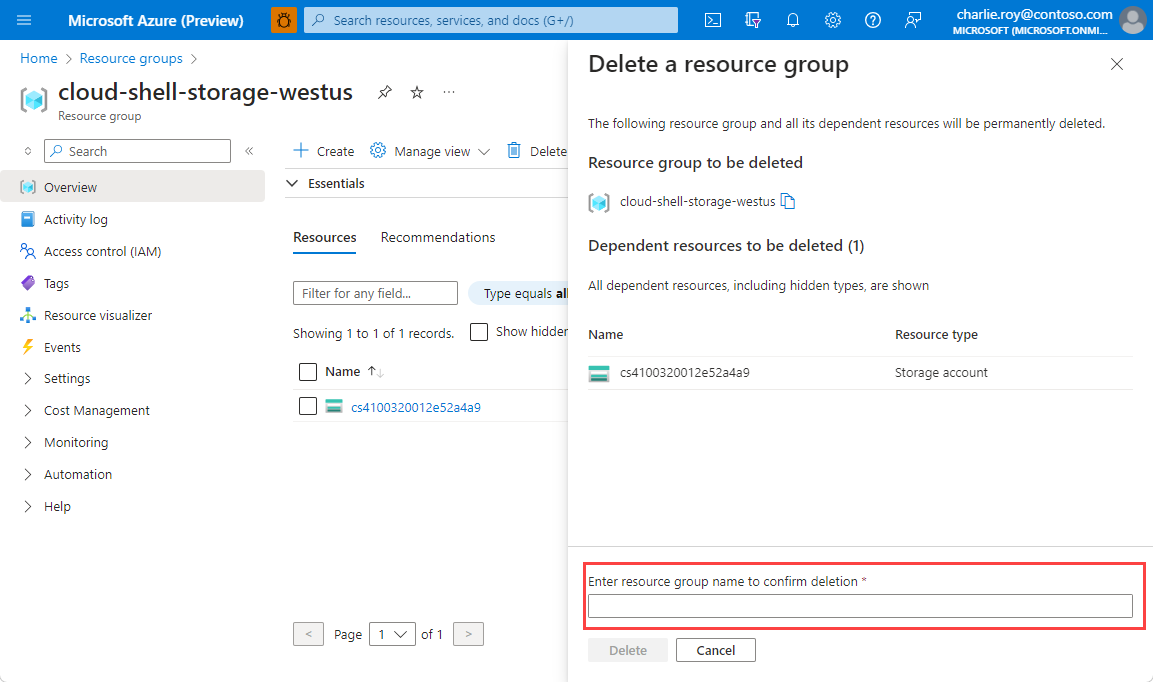
Через некоторое время группа ресурсов и все ее ресурсы будут удалены.
См. также
- Подробнее о Кэше Azure для Redis
- Дополнительные сведения о возможностях поиска векторов Кэш Azure для Redis
- Дополнительные сведения о внедрении, созданных службой Azure OpenAI
- Дополнительные сведения о подобии косинуса
- Узнайте, как создать приложение на основе ИИ с помощью OpenAI и Redis
- Создание приложения Q&A с помощью семантических ответов
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по