Настройка сбора и оптимизации затрат в аналитике контейнеров с помощью правила сбора данных
В этой статье описывается настройка сбора данных в аналитике контейнеров с помощью правила сбора данных (DCR) для кластера Kubernetes. Сюда входят предустановленные конфигурации для оптимизации затрат. При подключении кластера к аналитике контейнеров создается DCR. Этот DCR используется контейнерным агентом для определения сбора данных для кластера.
DCR в основном используется для настройки сбора данных о производительности и инвентаризации данных и настройки оптимизации затрат.
Конкретная конфигурация, которая может выполняться с помощью DCR, включает:
- Включение и отключение фильтрации коллекции и пространства имен для данных о производительности и инвентаризации.
- Определение интервала сбора данных о производительности и инвентаризации
- Включение и отключение коллекции Системного журнала
- Выбор схемы журнала
Внимание
Полная настройка сбора данных в аналитике контейнеров может потребовать редактирования DCR и ConfigMap для кластера, так как каждый метод позволяет настроить другой набор параметров.
Сведения о настройке сбора данных в аналитике контейнеров с помощью ConfigMap см. в разделе "Настройка сбора данных" с помощью ConfigMap . Клиенты не должны удалять или вручную изменять свой ресурс DCR.
Необходимые компоненты
- Кластеры AKS должны использовать управляемое удостоверение, назначаемое системой или назначаемое пользователем. Если кластер использует субъект-службу, необходимо обновить кластер, чтобы использовать управляемое удостоверение, назначаемое системой, или управляемое удостоверение, назначаемое пользователем.
Настройка сбора данных
DCR, созданный при включении аналитики контейнеров, называется MSCI-cluster-region-cluster-cluster-name><<>. Его можно просмотреть в портал Azure, выбрав пункт "Правила сбора данных" в меню "Монитор" в портал Azure. Вместо непосредственного изменения DCR следует использовать один из методов, описанных ниже, для настройки сбора данных. Дополнительные сведения о различных доступных параметрах, используемых каждым методом, см . в параметрах сбора данных.
Предупреждение
Интерфейс аналитики контейнеров по умолчанию зависит от всех существующих потоков данных. Удаление одного или нескольких потоков по умолчанию делает интерфейс аналитики контейнеров недоступным, и вам необходимо использовать другие средства, такие как панели мониторинга Grafana и запросы журналов для анализа собранных данных.
Вы можете использовать портал Azure для включения оптимизации затрат в существующем кластере после включения аналитики контейнеров или включить аналитику контейнеров в кластере вместе с оптимизацией затрат.
Выберите кластер в портал Azure.
Выберите параметр "Аналитика" в разделе "Мониторинг" в меню.
Если аналитика контейнеров уже включена в кластере, нажмите кнопку "Параметры мониторинга". В противном случае выберите "Настройка Azure Monitor " и ознакомьтесь с разделом "Включить мониторинг в кластере Kubernetes" с помощью Azure Monitor , чтобы получить подробные сведения о включении мониторинга.
Для AKS и Kubernetes с поддержкой Arc выберите использовать управляемое удостоверение , если кластер еще не перенесен на проверку подлинности управляемого удостоверения.
Выберите один из предустановок затрат, описанных в предустановках затрат.
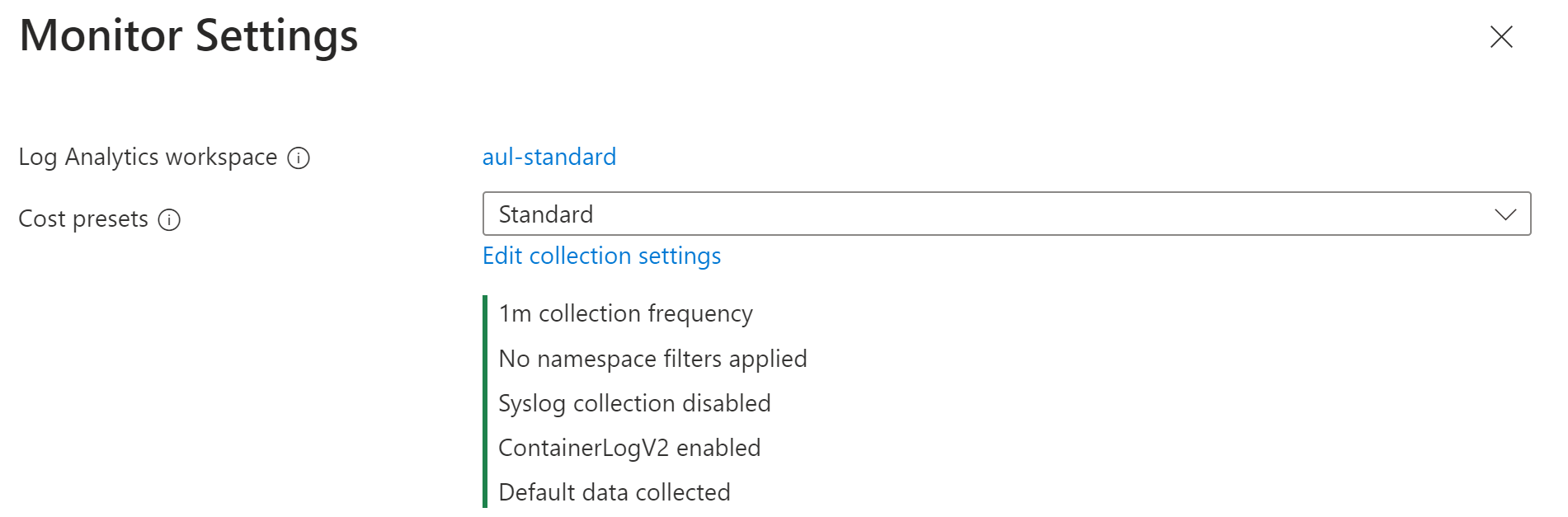
Если вы хотите настроить параметры, нажмите кнопку "Изменить параметры коллекции". Дополнительные сведения о каждом параметре см . в параметрах сбора данных. Собранные данные см. ниже.
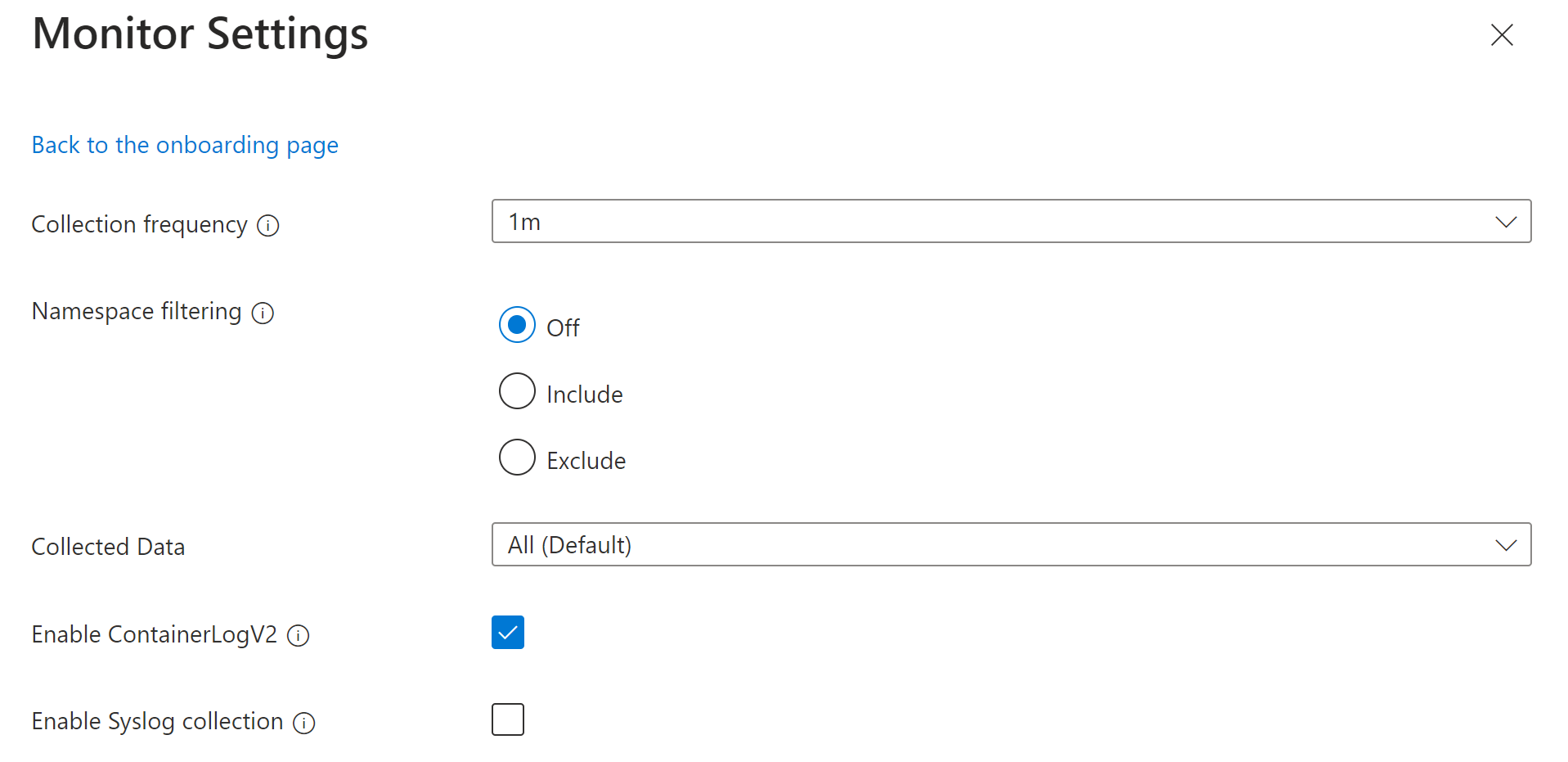
Нажмите кнопку "Настроить", чтобы сохранить параметры.



Предустановки затрат
При использовании портал Azure для настройки оптимизации затрат можно выбрать из следующих предварительно настроенных конфигураций. Вы можете выбрать один из этих параметров или указать собственные настраиваемые параметры. По умолчанию аналитика контейнеров использует предустановку "Стандартный".
| Предустановка затрат | Частота сбора | Фильтры пространства имен | Сбор сообщений системного журнала | Собранные данные |
|---|---|---|---|---|
| Стандартные | 1 м | нет | Не включено | Все стандартные таблицы аналитики контейнеров |
| Оптимизированные для затрат | 5 м | Исключает kube-system, gatekeeper-system, azure-arc | Не включено | Все стандартные таблицы аналитики контейнеров |
| Системный журнал | 1 м | нет | Включено по умолчанию | Все стандартные таблицы аналитики контейнеров |
| Журналы и события | 1 м | нет | Не включено | ContainerLog/ContainerLogV2 KubeEvents KubePodInventory |
Собранные данные
Параметр "Собранные данные" позволяет выбрать таблицы, заполненные для кластера. Это эквивалент streams параметра при выполнении конфигурации с помощью ИНТЕРФЕЙСА командной строки или ARM. Если выбрать любой вариант, отличный от всех (по умолчанию), интерфейс аналитики контейнеров становится недоступным, и необходимо использовать Grafana или другие методы для анализа собранных данных.

| Группировка | Таблицы | Примечания. |
|---|---|---|
| Все (по умолчанию) | Все стандартные таблицы аналитики контейнеров | Требуется для включения визуализаций аналитики контейнеров по умолчанию |
| Производительность | Perf, InsightsMetrics | |
| Журналы и события | ContainerLog или ContainerLogV2, KubeEvents, KubePodInventory | Рекомендуется, если вы включили управляемые метрики Prometheus |
| Рабочие нагрузки, развертывания и hpAs | InsightsMetrics, KubePodInventory, KubeEvents, ContainerInventory, ContainerNodeInventory, KubeNodeInventory, KubeServices | |
| Постоянные тома | InsightsMetrics, KubePVInventory |
Параметры сбора данных
В следующей таблице описываются поддерживаемые параметры сбора данных и имя, используемое для каждого из различных вариантов подключения.
| Имя | Описание |
|---|---|
| Частота сбора CLI: intervalРУКА: dataCollectionInterval |
Определяет частоту сбора данных агентом. Допустимые значения: 1 млн – 30 млн в интервалах 1 млн. Значение по умолчанию — 1 млн. Если значение находится за пределами допустимого диапазона, значение по умолчанию равно 1 м. |
| Фильтрация пространства имен CLI: namespaceFilteringModeРУКА: namespaceFilteringModeForDataCollection |
Включить: собирает только данные из значений в поле пространств имен. Исключение. Собирает данные из всех пространств имен, за исключением значений в поле пространств имен. Off: игнорирует все выбранные пространства имен и собирает данные во всех пространствах имен. |
| Фильтрация пространства имен CLI: namespacesРУКА: namespacesForDataCollection |
Массив пространств имен Kubernetes разделенных запятыми для сбора данных инвентаризации и perf на основе пространства именFilteringMode. Например, пространства имен = ["kube-system", "default"] с параметром Include собирают только эти два пространства имен. С параметром "Исключить" агент собирает данные из всех других пространств имен, за исключением kube-system и по умолчанию. С параметром Off агент собирает данные из всех пространств имен, включая kube-system и по умолчанию. Недопустимые и неопознанные пространства имен игнорируются. |
| Включение ContainerLogV2 CLI: enableContainerLogV2РУКА: enableContainerLogV2 |
Логический флаг для включения схемы ContainerLogV2. Если задано значение true, журналы stdout/stderr отправляются в таблицу ContainerLogV2 . В противном случае журналы контейнеров отправляются в таблицу ContainerLog , если иное не указано в ConfigMap. При указании отдельных потоков необходимо включить соответствующую таблицу для ContainerLog или ContainerLogV2. |
| Собранные данные CLI: streamsРУКА: streams |
Массив потоков таблиц аналитики контейнеров. См. поддерживаемые потоки выше в сопоставлении таблиц. |
Применимые таблицы и метрики
Параметры для фильтрации частоты сбора и пространства имен не применяются ко всем данным аналитики контейнеров. В следующих таблицах перечислены таблицы в рабочей области Log Analytics, используемой аналитикой контейнеров и метриками, которые собираются вместе с параметрами, применяемыми к каждому.
Примечание.
Эта функция настраивает параметры для всех таблиц аналитики контейнеров, за исключением ContainerLog и ContainerLogV2. Чтобы настроить параметры для этих таблиц, обновите ConfigMap, описанный в параметрах сбора данных агента.
| Имя таблицы | Интервал? | Пространства имен? | Замечания |
|---|---|---|---|
| ContainerInventory | Да | Да | |
| ContainerNodeInventory | Да | Нет | Параметр сбора данных для пространств имен не применяется, так как узел Kubernetes не является ресурсом с областью действия пространства имен |
| KubeNodeInventory | Да | Нет | Параметр сбора данных для пространств имен не является применимым узлом Kubernetes не является ресурсом области имен |
| KubePodInventory | Да | Да | |
| KubePVInventory | Да | Да | |
| KubeServices | Да | Да | |
| KubeEvents | No | Да | Параметр сбора данных для интервала не применим для событий Kubernetes |
| Производительность | Да | Да | Параметр сбора данных для пространств имен не применим для связанных метрик узла Kubernetes, так как узел Kubernetes не является объектом области имен. |
| InsightsMetrics | Да | Да | Параметры сбора данных применимы только для метрик, которые собирают следующие пространства имен: container.azm.ms/kubestate, container.azm.ms/pv и container.azm.ms/gpu |
| Пространство имен метрик | Интервал? | Пространства имен? | Замечания |
|---|---|---|---|
| Insights.container/nodes | Да | Нет | Узел не является ресурсом с областью действия пространства имен |
| Insights.container/pods | Да | Да | |
| Insights.container/containers | Да | Да | |
| Insights.container/persistentvolumes | Да | Да |
Потоковые значения
При указании таблиц для сбора с помощью CLI или ARM необходимо указать имя потока, соответствующее определенной таблице в рабочей области Log Analytics. В следующей таблице перечислены имена потока для каждой таблицы.
Примечание.
Если вы знакомы со структурой правила сбора данных, имена потоков в этой таблице указываются в разделе dataFlows DCR.
| Stream | Таблица аналитики контейнеров |
|---|---|
| Microsoft-ContainerInventory | ContainerInventory |
| Microsoft-ContainerLog | Журнал контейнера |
| Microsoft-ContainerLogV2 | ContainerLogV2 |
| Microsoft-ContainerNodeInventory | ContainerNodeInventory |
| Microsoft-InsightsMetrics | InsightsMetrics |
| Microsoft-KubeEvents | KubeEvents |
| Microsoft-KubeMonAgentEvents | KubeMonAgentEvents |
| Microsoft-KubeNodeInventory | KubeNodeInventory |
| Microsoft-KubePodInventory | KubePodInventory |
| Microsoft-KubePVInventory | KubePVInventory |
| Microsoft-KubeServices | KubeServices |
| Microsoft-Perf | Производительность |
Влияние на визуализации и оповещения
Если в настоящее время вы используете приведенные выше таблицы для других пользовательских оповещений или диаграмм, изменение параметров сбора данных может снизить эти возможности. Если вы исключаете пространства имен или сокращаете частоту сбора данных, просмотрите существующие оповещения, панели мониторинга и книги с помощью этих данных.
Чтобы проверить наличие оповещений, ссылающихся на эти таблицы, выполните следующий запрос Azure Resource Graph:
resources
| where type in~ ('microsoft.insights/scheduledqueryrules') and ['kind'] !in~ ('LogToMetric')
| extend severity = strcat("Sev", properties["severity"])
| extend enabled = tobool(properties["enabled"])
| where enabled in~ ('true')
| where tolower(properties["targetResourceTypes"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["targetResourceType"]) matches regex 'microsoft.operationalinsights/workspaces($|/.*)?' or tolower(properties["scopes"]) matches regex 'providers/microsoft.operationalinsights/workspaces($|/.*)?'
| where properties contains "Perf" or properties contains "InsightsMetrics" or properties contains "ContainerInventory" or properties contains "ContainerNodeInventory" or properties contains "KubeNodeInventory" or properties contains"KubePodInventory" or properties contains "KubePVInventory" or properties contains "KubeServices" or properties contains "KubeEvents"
| project id,name,type,properties,enabled,severity,subscriptionId
| order by tolower(name) asc
Следующие шаги
- См. статью "Настройка сбора данных в аналитике контейнеров" с помощью ConfigMap для настройки сбора данных с помощью ConfigMap вместо DCR.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по