Управление бюджетами, затратами и квотами для Машинного обучения Azure в масштабе организации
При управлении затратами на вычислительные ресурсы Машинного обучения Azure в масштабах организации с большим количеством рабочих нагрузок, команд и пользователей необходимо решать множество задач администрирования и оптимизации.
В этой статье представлены рекомендации по оптимизации затрат, управлению бюджетами и совместному использованию квоты в службе Машинного обучения Azure. В них содержатся ценные сведения об опыте и уроках, полученных во время работы в командах машинного обучения в корпорации Майкрософт, а также при сотрудничестве с клиентами. Вы изучите следующие темы:
- оптимизировать ресурсы вычислений в соответствии с требованиями рабочей нагрузки;
- оптимально использовать бюджет команды;
- планировать, контролировать и публиковать бюджеты, затраты и квоты в масштабах предприятия.
Оптимизация вычислений в соответствии с требованиями к рабочей нагрузке
При запуске нового проекта машинного обучения может потребоваться провести исследования, чтобы получить точное представление о требованиях к вычислительным ресурсам. В этом разделе приводятся рекомендации по определению подходящего номера SKU виртуальной машины (ВМ) для обучения, вывода или работы.
Определение объема вычислительных ресурсов для обучения
Требования разных проектов к оборудованию для рабочей нагрузки для обучения могут отличаться. Для удовлетворения этих требований вычислительная среда Машинного обучения Azure предлагает различные типы виртуальных машин.
- Общего назначения: предоставляет сбалансированное соотношение ресурсов ЦП и памяти.
- Оптимизировано для памяти: высокое соотношение ресурсов памяти и ЦП.
- Оптимизация для вычислений: предоставляет высокое соотношение ресурсов ЦП и памяти.
- Высокопроизводительные вычисления: обеспечивает производительность, масштабируемость и экономичность высочайшего класса для различных реальных рабочих нагрузок HPC.
- Экземпляры с графическими процессорами (GPU): специализированные виртуальные машины, предназначенные для ресурсоемкой отрисовки изображений и редактирования видео, а также для обучения моделей и формирования выводов с помощью глубокого обучения.
Возможно, вы не знакомы с требованиями к вычислительным ресурсам. В этом сценарии рекомендуется использовать один из следующих экономичных вариантов по умолчанию. Они предназначены для упрощенного тестирования и для обучения рабочих нагрузок.
| Тип | Размер виртуальной машины | Технические характеристики |
|---|---|---|
| ЦП | Standard_DS3_v2 | 4 ядра, 14 ГБ ОЗУ, 28 ГБ хранилища |
| GPU | Standard_NC6 | 6 ядер, 56 ГБ ОЗУ, 380 ГБ хранилища, графический процессор NVIDIA Tesla K80 |
Получить оптимальный размер виртуальной машины для вашего сценария можно методом проб и ошибок. Ниже приведены некоторые аспекты, которые следует учитывать.
- Если вам нужен ЦП:
- При работе с большими наборами данных используйте виртуальную машину, оптимизированную для памяти.
- Используйте оптимизированную для вычислений виртуальную машину, если вы выполняете заданные в реальном времени или другие задачи, учитывающие задержку.
- Используйте виртуальную машину с большим числом ядер и объемом ОЗУ, чтобы ускорить обучение.
- Если вам нужен GPU, ознакомьтесь с оптимизированными для GPU размерами виртуальных машин для получения сведений о выборе виртуальной машины.
- Если вы выполняете распределенное обучение, используйте размеры виртуальных машин с несколькими графическими процессорами.
- Если вы выполняете распределенное обучение на нескольких узлах, используйте графические процессоры с подключениями NVLink.
Выбрав тип виртуальной машины и номер SKU, который лучше всего подходит для рабочей нагрузки, оцените сравнимые номера SKU виртуальных машин как компромиссы между производительностью ЦП/графических процессоров и ценами. С точки зрения управления затратами задание может эффективно выполняться на нескольких SKU.
Некоторые графические процессоры, например семейство NC и NC_Promo SKU, в частности, предоставляют возможности, аналогичные другим графическим процессорам, такие как низкая задержка и возможность параллельного управления несколькими вычислительными рабочими нагрузками. Они доступны со скидками по сравнению с некоторыми другими графическими процессорами. Тщательный выбор номеров SKU виртуальных машин для рабочей нагрузки может значительно снизить затраты в итоге.
Следует помнить о важности уровня использования — большее число графических процессоров не обязательно помогает ускорить получение результатов. Вместо этого следует убедиться, что графический процессор полностью используется. Например, дважды проверьте потребность в NVIDIA CUDA. Хотя это может потребоваться для высокопроизводительного выполнения на GPU, задание может не зависеть от него.
Определение объема вычислительных ресурсов для вывода
Требования к вычислениям для сценариев вывода отличаются от сценариев обучения. Доступные варианты зависят от того, требуется ли для сценария автономный вывод в пакетном режиме или онлайн-вывод в режиме реального времени.
Для сценариев вывода в режиме реального времени рассмотрите следующие рекомендации.
- Используйте возможности профилирования в модели Машинного обучения Azure, чтобы определить, сколько ресурсов ЦП и памяти необходимо выделить модели при ее развертывании в качестве веб-службы.
- Если вы выполняете вывод в реальном времени, но вам не требуется высокая доступность, выполните развертывание в службе Экземпляры контейнеров Azure (без выбора номера SKU).
- Если вы выполняете вывод в реальном времени, но вам нужен высокий уровень доступности, выполните развертывание в службе Экземпляры контейнеров Azure.
- Если вы используете традиционные модели машинного обучения и получаете < 10 запросов в секунду, начните с SKU ЦП. SKU серии F часто оказываются работоспособным вариантом.
- Если вы используете модели глубокого обучения и получаете > 10 запросов в секунду, попробуйте использовать номер SKU NVIDIA GPU (NCasT4_v3 часто работает хорошо) с Triton.
Для сценариев пакетного вывода в режиме реального времени рассмотрите следующие рекомендации.
- При использовании конвейеров Машинного обучения Azure для пакетной обработки следуйте указаниям из раздела Определение объема вычислительных ресурсов для обучения, чтобы выбрать первоначальный размер виртуальной машины.
- Оптимизируйте затраты и производительность, выполняя горизонтальное масштабирование. Один из ключевых методов оптимизации затрат и производительности — распараллеливание рабочей нагрузки с помощью этапа параллельного выполнения в Машинном обучении Azure. Этот шаг конвейера позволяет использовать множество небольших узлов для параллельного выполнения задачи, что дает возможность для горизонтального масштабирования. Однако при параллелизации возникает дополнительная нагрузка. В зависимости от рабочей нагрузки и степени параллелизма, которая может быть достигнута, это может выступать или не выступать в качестве опционального варианта.
Определение размера для вычислительного экземпляра
Для интерактивной разработки рекомендуется использовать вычислительный экземпляр Машинного обучения Azure. Это предложение вычислительного экземпляра (CI) предоставляет вычислительные ресурсы одного узла, которые привязываются к одному пользователю и могут использоваться в качестве облачной рабочей станции.
Некоторые организации запрещают использование рабочих данных на локальных рабочих станциях, применяют ограничения среды рабочей станции или ограничивают установку пакетов и зависимостей в корпоративной ИТ-среде. Вычислительный экземпляр можно использовать в качестве рабочей станции для преодоления этих ограничений. Он предоставляет безопасную среду с доступом к рабочим данным и работает с образами, которые поставляются с популярными пакетами и предварительно установленными инструментами анализа и обработки данных.
При запуске вычислительного экземпляра пользователь оплачивает вычислительные ресурсы ВМ, Load Balancer (цен. категория "Стандартный") (с правилами балансировки нагрузки входящего и исходящего трафика, а также обработанными данными), диск операционной системы (управляемый SSD-диск P10, цен. категория "Премиум"), временный диск (тип зависит от выбранного размера виртуальной машины) и общедоступный IP-адрес. Для экономии затрат рассмотрите следующие рекомендации.
- Завершайте работу вычислительного экземпляра, когда он не используется.
- Работа с образцом данных в вычислительном экземпляре и горизонтально увеличивайте масштаб до вычислительных кластеров для работы с полным набором данных
- Отправляйте экспериментальные задания в локальном режиме целевого объекта вычислений в вычислительном экземпляре при разработке или тестировании, а также при переключении на общую вычислительную мощность при отправке заданий в полном масштабе. Например, это могут быть многие эпохи, полный набор данных и поиск гиперпараметров.
Если остановить вычислительный экземпляр, прекращается выставление счетов за часы вычислений виртуальных машин, временные диски и обработку данных в Load Balancer (цен. категория "Стандартный"). Примечание. Пользователь по-прежнему оплачивает диск ОС и правила Load Balancer (цен. категория "Стандартный") для исходящего трафика даже при остановке вычислительного экземпляра. Все данные, размещенные на диске ОС, сохраняются с после остановки и перезапуска.
Настройка выбранного размера ВМ с помощью мониторинга использования вычислительных ресурсов
Вы можете просмотреть сведения о потреблении и использовании вычислительных ресурсов Машинного обучения Azure с помощью Azure Monitor. Вы можете просматривать сведения о развертывании и регистрации моделей, сведения о квотах, такие как активные и неактивные узлы, сведения о запусках, таких как отмененные и завершенные запуски, а также информацию об использовании ресурсов GPU и ЦП.
На основе аналитики сведений о мониторинге вы можете лучше спланировать или скорректировать использование ресурсов в группе. Например, если вы видите много бездействующих узлов за последнюю неделю, вы можете вместе с соответствующими владельцами рабочей области обновить конфигурацию кластера, чтобы предотвратить дополнительные затраты. Преимущества анализа шаблонов использования могут помочь в прогнозировании затрат и улучшении бюджета.
Вы можете получить доступ к этим метрикам непосредственно на портале Azure. Перейдите в рабочую область Машинного обучения Azure и выберите Метрики в разделе "Мониторинг" на левой панели. Затем можно выбрать сведения о том, что вы хотите просмотреть, например метрики, агрегирование и период времени. Дополнительные сведения см. на странице документации Мониторинг Машинного обучения Azure.
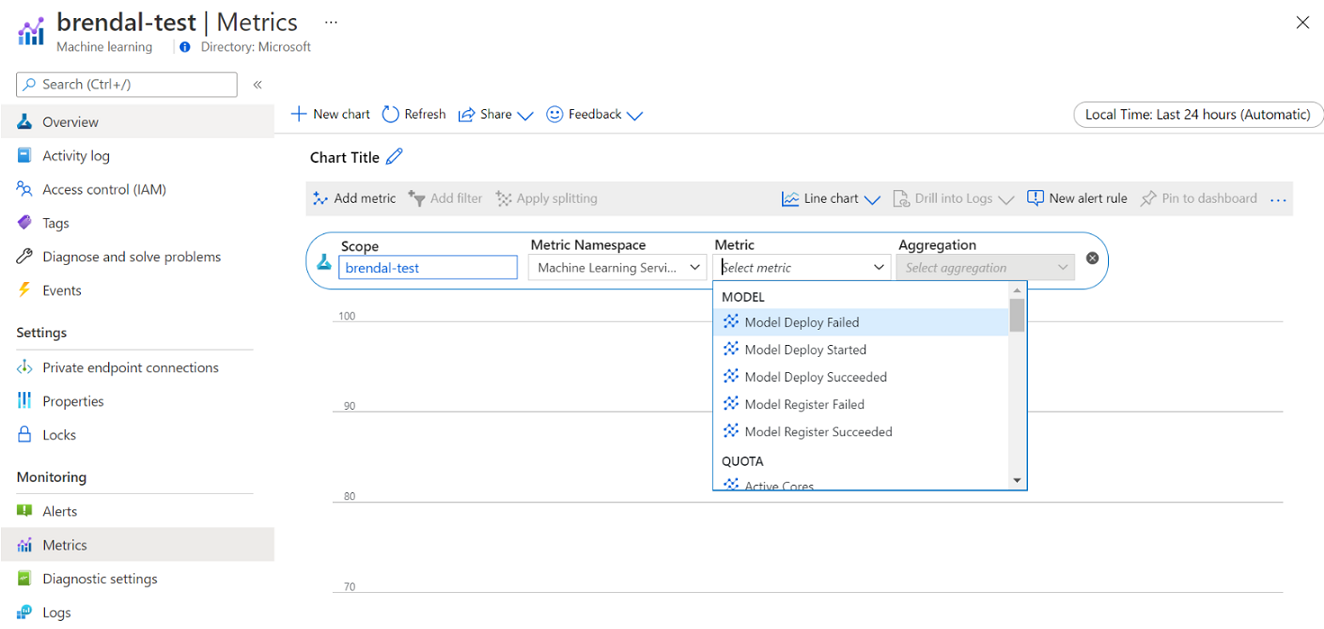
Переключение между локальной, одноузловой и многоузловой вычислительной средой при разработке
В течение жизненного цикла машинного обучения применяются различные требования к вычислениям и инструментарию. Для удовлетворения этих требований со службой Машинного обучения Azure можно взаимодействовать с помощью пакета SDK и интерфейса командной строки практически из любой предпочтительной конфигурации рабочей станции.
Чтобы сократить расходы и продуктивно работать, рекомендуется:
- Клонировать базу кода экспериментов локально с помощью Git и отправлять задания в облачную вычислительную среду, используя пакет SDK или интерфейс командной строки Машинного обучения Azure.
- Если набор данных крупный, рассмотрите возможность управления образцом данных на локальной рабочей станции, оставив полный набор данных в облачном хранилище.
- Параметризируйте базу кода экспериментов, чтобы настроить выполнение заданий с различным количеством эпох или с наборами данных разного размера.
- Не нужно жестко кодировать путь к папке набора данных. Затем можно легко повторно использовать ту же базу кода с различными наборами данных, а также в контексте выполнения в локальной и облачной среде.
- Начальную загрузку экспериментальных заданий выполняйте в локальном режиме целевого объекта вычислений при разработке или тестировании. При отправке заданий в полном масштабе переключайтесь на общие ресурсы вычислительного кластера.
- Если набор данных крупный, работайте с выборкой данных в локальной среде или на рабочей станции вычислительного экземпляра и переключайтесь на облачную вычислительную среду Машинного обучения Azure при работе с полным набором данных.
- Если выполнение заданий отнимает много времени, рассмотрите возможность оптимизации базы кода для распределенного обучения, чтобы обеспечить горизонтальное масштабирование.
- Проектируйте распределенные обучающие рабочие нагрузки для обеспечения эластичности узлов, чтобы гибко использовать вычислительные среды с одним узлом и несколькими узлами, а также упростить использование вычислительных ресурсов, которые могут быть замещены.
Объединение типов вычислительных ресурсов с помощью конвейеров Машинного обучения Azure
При оркестрации рабочих процессов машинного обучения можно определить конвейер с несколькими шагами. Каждый шаг в конвейере может выполняться в собственном типе вычислительной среды. Это позволит оптимизировать производительность и затраты в соответствии с различными требованиями к вычислениям в рамках жизненного цикла машинного обучения.
Оптимальное использование бюджета команды
В то время как решения о выделении бюджета могут выходить за пределы контроля отдельной команды, ей обычно позволяют использовать выделенный бюджет в соответствии с наилучшими потребностями. За счет эффективной балансировки приоритета задания, производительности и стоимости команда может достичь более высокой степени использования кластера, снизить общие затраты и использовать больше часов вычислений из одного бюджета. Это может привести к повышению производительности команды.
Оптимизация затрат на общие вычислительные ресурсы
Ключом к оптимизации затрат на общие вычислительные ресурсы является обеспечение их полного использования. Ниже приведены некоторые советы по оптимизации затрат на общие ресурсы.
- При использовании вычислительных экземпляров их следует включать только при наличии кода для выполнения. Отключите их, если они не используются.
- При использовании вычислительных кластеров установите минимальное число узлов равным 0, а максимальное число узлов определите на основе ограничений бюджета. Используйте калькулятор цен Azure, чтобы рассчитать стоимость полного использования одного узла виртуальной машины для выбранного номера SKU. При автоматическом масштабировании все узлы вычислений будут масштабироваться, если они не используются. Масштабирование выполняется только до количества узлов, для которых у вас есть бюджет. Можно настроить автомасштабирование, чтобы масштабировать все вычислительные узлы.
- Отслеживайте использование ресурсов, таких как ЦП и GPU, при обучении моделей. Если ресурсы не используются полностью, измените код, чтобы лучше использовать ресурсы, или переключитесь на виртуальные машины меньшего размера или более дешевые виртуальные машины.
- Оцените, можно ли создать общие вычислительные ресурсы для вашей команды, чтобы избежать проблем с производительностью, вызванной операциями масштабирования кластера.
- Оптимизируйте политики времени ожидания автомасштабирования вычислительного кластера на основе метрик использования.
- Квоты рабочей области используются для управления объемом вычислительных ресурсов, к которым у отдельных рабочих областей есть доступ.
Введите приоритеты планирования, создав кластеры для нескольких номеров SKU виртуальных машин.
В соответствии с ограничениями квот и бюджета команда должна своевременно выполнять задания и затраты, чтобы обеспечить своевременное выполнение важных заданий, а также использовать бюджет наилучшим образом.
Для поддержки оптимального использования вычислительных ресурсов рекомендуется создавать кластеры различных размеров с низким приоритетом и выделенными приоритетами виртуальных машин. В вычислительных средах с низким приоритетом используются избыточные ресурсы в Azure, которые предоставляются со скидками. К сожалению, эти ВМ могут быть замещены в любое время, когда поступит запрос с более высоким приоритетом.
Используя кластеры разного размера и приоритета, можно ввести понятие приоритета планирования. Например, если экспериментальные и производственные задания конкурируют за одну и ту же квоту графического процессора NC, приоритет может быть отдан рабочему заданию. В этом случае запустите рабочее задание в выделенном вычислительном кластере, а экспериментальное задание — в кластере с низким приоритетом. Когда квота закончится, экспериментальное задание будет замещено на более приоритетное рабочее задание.
Помимо приоритета виртуальных машин рассмотрите возможность выполнения заданий на различных SKU виртуальных машин. Возможно, задание выполняется дольше на экземпляре виртуальной машины с GPU P40, чем на GPU V100. Однако так как экземпляры виртуальных машин V100 могут быть заняты или квоты могут быть полностью использованы, время выполнения на P40 может быть меньше с точки зрения пропускной способности задания. Вы также можете выполнять задания с более низким приоритетом в менее производительных и более дешевых экземплярах виртуальных машин с точки зрения управления затратами.
Завершайте запуск на ранних этапах, если обучение не сходится
Если вы непрерывно экспериментируете, чтобы улучшить модель по сравнению с базовыми показателями, вы можете выполнять различные запуски экспериментов с немного отличающимися конфигурациями. Для одного запуска можно изменить входные наборы данных. Для другого можно изменить гиперпараметр. Не все изменения могут быть так же эффективны, как другие. Вы обнаружите, что изменение не повлияло на качество обучения модели. Чтобы определить, сходится ли обучение, отслеживайте ход обучения во время выполнения. Для этого можно, например, записывать метрики производительности в журнал после каждой эпохи обучения. Рассмотрите возможность раннего завершения задания, чтобы освободить ресурсы и бюджет для другой версии.
Планирование, контроль и совместное использование бюджетов, затрат и квот
По мере расширения числа вариантов использования и команд машинного обучения в организации, требуется повышать эксплуатационную зрелость ИТ-отдела и отдела финансов, а также улучшать координацию между отдельными командами машинного обучения, чтобы обеспечить эффективные операции. Управление ресурсами и квотами в масштабах компании становится важным методом для устранения дефицита вычислительных ресурсов и расходов на управление.
В этом разделе обсуждаются рекомендации по планированию, контролю и совместному использованию бюджетов, затрат и квот в масштабах предприятия. Они основаны на опыте управления множеством обучающих ресурсов на базе GPU для машинного обучения в корпорации Майкрософт.
Анализ затрат на ресурсы с помощью Машинного обучения Azure
Одна из самых серьезных проблем, с которой сталкиваются администраторы при планировании требуемых вычислительных ресурсов, — это начало работы с чистого листа без исторических данных в качестве базового плана. В практическом смысле большинство проектов будет начинаться с небольшого бюджета.
Чтобы понять, на что уходит бюджет, важно знать, откуда берутся затраты на Машинное обучение Azure.
- Пользователи Машинного обучения Azure платят только за использование вычислительной инфраструктуры и не платят за вычисления.
- Вместе с рабочей областью Машинного обучения Azure также создаются несколько других ресурсов, позволяющих реализовать Машинное обучение Azure: Key Vault, Application Insights, служба хранилища Azure и Реестр контейнеров Azure. Они используются в Машинном обучении Azure, и вы платите за эти ресурсы.
- Существуют затраты, связанные с управляемыми вычислительными средами, такими как кластеры обучения, вычислительные экземпляры и управляемые конечные точки вывода. С этими управляемыми ресурсами вычислений следует учитывать следующие затраты на инфраструктуру: виртуальные машины, виртуальная сеть, подсистема балансировки нагрузки, пропускная способность и хранилище.
Отслеживание шаблонов расходов и улучшение отчетов с помощью тегов
Администратор istrator часто хотят отслеживать затраты на различные ресурсы в Машинное обучение Azure. Тег — это естественное решение этой проблемы и соответствует общему подходу, используемому Azure и многими другими поставщиками облачных служб. Благодаря поддержке тегов теперь можно увидеть разбивку затрат на уровне вычислений, поэтому предоставление доступа к более детальному представлению для улучшения мониторинга затрат, улучшения отчетов и повышения прозрачности.
Тег позволяет размещать настраиваемые теги в рабочих областях и вычислениях (из шаблонов Azure Resource Manager и Студия машинного обучения Azure) для дальнейшего фильтрации этих ресурсов в Microsoft Cost Management на основе этих тегов для наблюдения за шаблонами расходов. Эту функцию лучше всего использовать для внутренних сценариев резервной оплаты. Кроме того, теги могут быть полезны для записи метаданных или сведений, связанных с вычислением, таких как проект, команда или определенный код выставления счетов. Это делает тег очень полезным для измерения того, сколько денег вы тратите на разные ресурсы, и, следовательно, получение более глубокой информации о затратах и шаблонах расходов между командами или проектами.
Существуют также внедренные системные теги, размещенные на вычислительных ресурсах, которые позволяют фильтровать на странице "Анализ затрат" тегом "Тип вычислений", чтобы увидеть мудрое распределение вычислительных расходов и определить, какая категория вычислительных ресурсов может быть присвоена большинству затрат. Это особенно полезно для получения большей видимости для обучения и вывода шаблонов затрат.
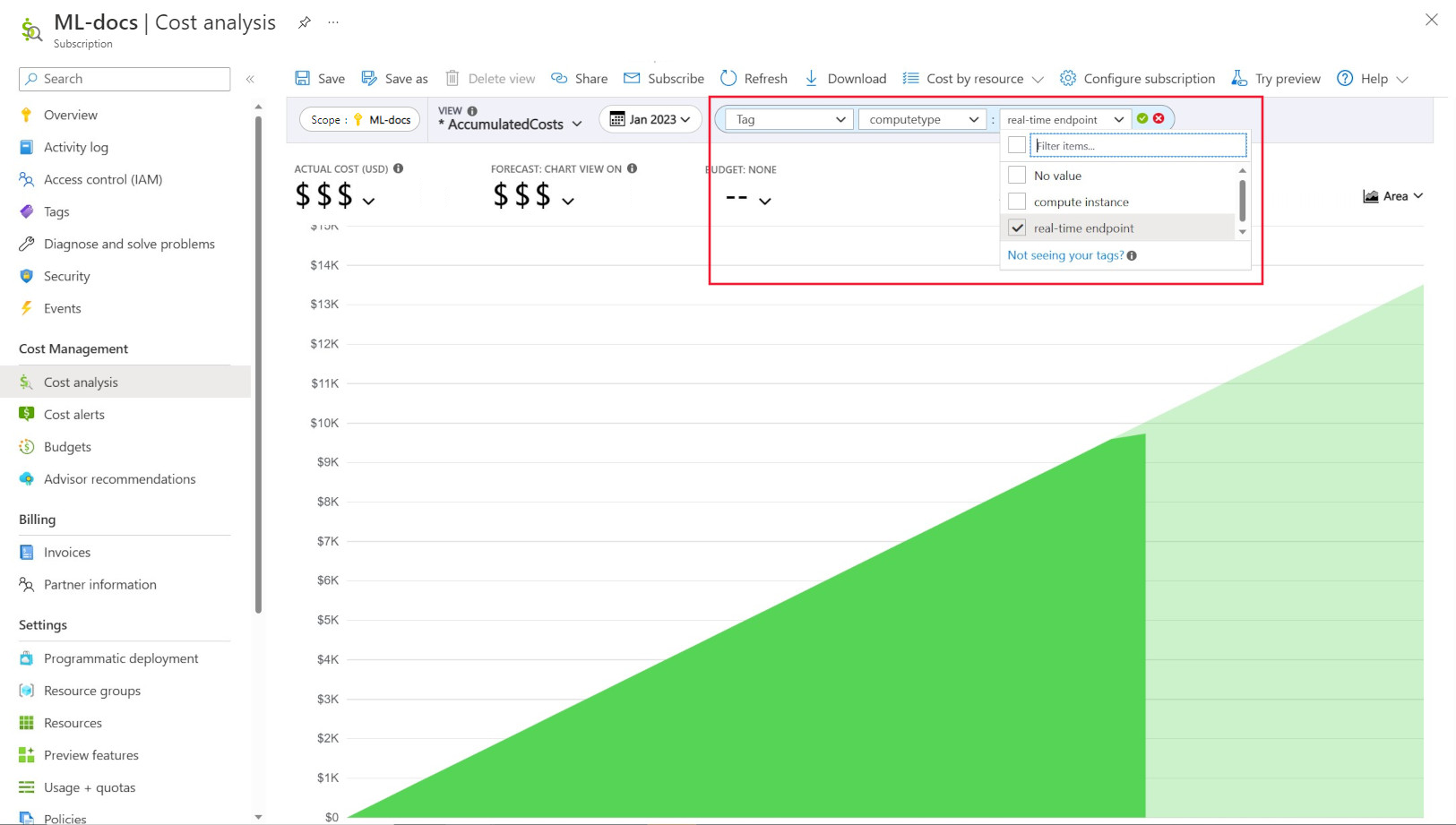
Управление использованием вычислительных ресурсов и его ограничение с помощью политики
При управлении средой Azure с большим количеством рабочих нагрузок может оказаться сложной задачей отслеживать затраты на ресурсы. Политика Azure помогает контролировать затраты на ресурсы и управлять ими благодаря ограничению определенных шаблонов использования в среде Azure.
В конкретном случае для Машинного обучения Azure рекомендуется настроить политики, чтобы разрешить использование только конкретных номеров SKU виртуальных машин. Политики позволяют предотвратить и контролировать выбор дорогостоящих виртуальных машин. Политики также можно использовать для принудительного применения номеров SKU виртуальных машин с низким приоритетом.
Выделение квот и управление ими на основе бизнес-приоритетов
Azure позволяет устанавливать ограничения на распределение квот на уровне подписки и рабочей области Машинного обучения Azure. С помощью управления доступом на основе ролей (RBAC) в Azure можно определить, кто может управлять квотами, чтобы обеспечить использование ресурсов и предсказуемость затрат.
Доступность квоты GPU может быть ограничена в рамках подписок. Чтобы обеспечить высокий уровень использования квоты в рабочих нагрузках, мы рекомендуем следить за тем, чтобы использовалась лучшая квота, и назначать ее различным рабочим нагрузкам.
Корпорация Майкрософт периодически определяет, можно ли более эффективно использовать и выделять квоты GPU в различных командах машинного обучения, оценивая потребности в ресурсах в сравнении с бизнес-приоритетами.
Резервируйте ресурсы заранее
Если вы точно оценили, сколько вычислительных ресурсов будут использоваться в течение следующего года или нескольких лет, можно приобрести Azure Reserved VM Instances со скидкой. Их можно купить на один год или на три года. Так как экземпляры Azure Reserved VM Instances предоставляются со скидкой, затраты на оплату по мере использования могут значительно снизиться.
Машинное обучение Azure поддерживает зарезервированные экземпляры вычислений. Скидки применяются к управляемым вычислительным ресурсам Машинного обучения Azure автоматически.
Управление хранением данных
Каждый раз, когда выполняется конвейер машинного обучения, на каждом шаге конвейера могут создаваться промежуточные наборы данных для кэширования и повторного использования. Увеличение объема выходных данных этих конвейеров машинного обучения может стать целью организации, в которой выполняются многие эксперименты машинного обучения.
Специалисты по обработке и анализу данных обычно не тратят время на очистку создаваемых промежуточных наборов данных. Со временем объем создаваемых данных будет расти. Служба хранилища Azure позволяет улучшить управление жизненным циклом данных. Используя возможности управления жизненным циклом Хранилища BLOB-объектов Azure, вы можете настроить общие политики для перемещения данных, не используемых в качестве автономных неструктурированных уровней хранилища, и снижения затрат.
Рекомендации по оптимизации затрат на инфраструктуру
Сеть
Затраты на сеть Azure связаны с исходящей пропускной способностью из центров обработки данных Azure. Весь входящий трафик в центре обработки данных Azure обрабатывается бесплатно. Чтобы снизить затраты на сеть, необходимо развернуть все ресурсы в одном регионе центра обработки данных, когда это возможно. Если вы можете развернуть рабочую область Машинного обучения Azure и вычислительные ресурсы в том же регионе, где находятся ваши данные, вы сможете снизить затраты и повысить производительность.
Вам может потребоваться частное подключение между локальной сетью и сетью Azure, чтобы создать гибридную облачную среду. ExpressRoute позволяет сделать это, но учитывая высокую стоимость ExpressRoute, для сокращения расходов можно отказаться от гибридного облака и перенести все ресурсы в облако Azure.
Реестр контейнеров Azure
Ниже приводятся ключевые факторы оптимизации затрат на Реестр контейнеров Azure:
- Требуемая пропускная способность для загрузки образа Docker из Реестра контейнеров в Машинное обучение Azure.
- Требования к корпоративным функциям безопасности, таким Приватный канал Azure.
Для рабочих сценариев, в которых требуется высокая пропускная способность или корпоративная безопасность, рекомендуется использовать SKU категории "Премиум" для Реестра контейнеров Azure.
Для сценариев разработки и тестирования, в которых пропускная способность и безопасность менее важны, рекомендуется использовать SKU категории "Стандартный" или "Премиум".
Не рекомендуется выбирать SKU категории "Базовый" Р+еестра контейнеров Azure для Машинного обучения Azure. Это связано с низкой пропускной способностью и небольшим размером хранилища, которое может быть закончиться из-за относительно большого размера образов Docker для Машинного обучения Azure (1 ГБ и более).
Учет типа вычислительных ресурсов при выборе регионов Azure
При выборе региона для вычислительных ресурсов учитывайте доступность квот. В популярных и более крупных регионах, таких как Восточная часть США, Западная часть США и Западная Европа, значения квот по умолчанию и доступность большинства процессоров и GPU обычно выше, чем в других регионах с более строгими ограничениями ресурсов.
Подробнее
Следующие шаги
Дополнительные сведения о том, как организовывать и настраивать среды Машинного обучения Azure, см. в разделе Организация и настройка сред Машинного обучения Azure.
Дополнительные сведения о рекомендациях по DevOps для машинного обучения при использовании службы Машинного обучения Azure см. в разделе Руководство по DevOps для машинного обучения.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по