Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Сетка данных — это захватывающий новый подход к проектированию и разработке архитектуры данных. В отличие от традиционной архитектуры данных, сетка данных отделяет ответственность между функциональными доменами данных , которые сосредоточены на создании продуктов данных и команде платформы, ориентированной на технические возможности. Это разделение обязанностей должно отражаться на вашей платформе. Необходимо обеспечить баланс между предоставлением возможностей, не зависящих от домена, и позволением командам домена моделировать, обрабатывать и распространять свои данные в организации.
Выбор правильного уровня гранулярности домена и правил для разделения с использованием платформ не является лёгкой задачей. В этой статье содержится несколько сценариев, которые предоставляют подробные рекомендации.
Аналитика в масштабе облака
Если вы хотите создать сетку данных с помощью Azure, рекомендуется внедрить облачную аналитику. Эта платформа является развертываемой эталонной архитектурой и поставляется с шаблонами с открытым исходным кодом и рекомендациями. Архитектура аналитики в масштабе облака имеет два основных стандартных блока, которые являются основными для всех вариантов развертывания:
- Площадка управления данными: Основа архитектуры данных. Он содержит все критически важные возможности для управления данными, таких как каталог данных, происхождение данных, каталог API, управление главными данными и т. д.
- Площадки для данных: Подписки, на которых размещаются решения для аналитики и искусственного интеллекта. Они включают ключевые возможности для размещения платформы аналитики.
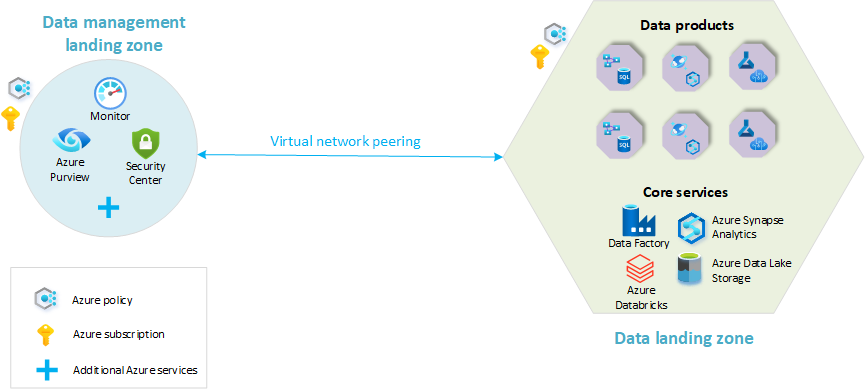
На следующей схеме представлен обзор облачной платформы аналитики с целевой зоной управления данными и одной целевой зоной размещения данных. На схеме представлены не все службы Azure. Это было упрощено, чтобы выделить основные понятия организации ресурсов в этой архитектуре.
Платформа аналитики на основе облака не является явной в отношении конкретного типа архитектуры данных, которую необходимо подготовить. Его можно использовать для многих распространенных облачных аналитических решений, включая корпоративные хранилища данных, озёра данных, озеро-дом данных и сетевые данные. Все примеры решений в этой статье используют архитектуру сетки данных.
Понять, что все архитектуры соответствуют принципам сетки данных: владение доменом, данные как продукт, самостоятельная платформа данных и федеративное управление вычислениями. Различные пути могут привести к сетке данных. Нет единого правильного или неправильного ответа. Необходимо сделать правильные компромиссы для потребностей вашей организации.
Одна целевая зона для данных
Самый простой шаблон развертывания для построения сетевой архитектуры данных включает одну зону приземления управления данными и одну зону приземления данных. Архитектура данных в таком сценарии будет выглядеть следующим образом:

В этой модели все функциональные домены данных находятся в одной целевой зоне данных. Одна подписка содержит стандартный набор служб. Группы ресурсов отделяют разные домены данных и продукты данных. Стандартные службы данных, такие как Azure Data Lake Store и Azure Logic Apps, применяются ко всем доменам.
Все домены данных соответствуют принципам сетки данных: данные соответствуют собственности на домен, а данные обрабатываются как продукты. Платформа полностью самообслуживания, несмотря на то, что есть ограниченные варианты услуг. Все домены должны строго придерживаться и соответствовать одинаковым принципам управления данными.
Этот вариант развертывания может быть полезен для небольших компаний или новых проектов, которые хотят использовать сеточную архитектуру данных, но не усложнять их. Это развертывание также может быть отправной точкой для организации, которая планирует создать что-то более сложное. В этом случае спланируйте расширение в несколько зон приземления на более позднее время.
Согласованные зоны для исходной системы и зоны для потребителей
В предыдущей модели мы не учитывали другие подписки или локальные приложения. Вы можете немного изменить предыдущую модель, добавив зону приземления, выровненную по исходной системе, для управления всеми входящими данными. Подключение данных — это сложный процесс, поэтому полезно использовать две целевые зоны данных. Подключение остается одной из самых сложных частей использования данных на большом уровне. Подключение также часто требует дополнительных средств для решения интеграции, так как ее проблемы отличаются от проблем интеграции. Это помогает различать предоставление данных и использование данных.

В архитектуре слева на схеме службы обеспечивают подключение всех данных, таких как CDC, службы для получения данных из API или службы для работы с озером данных для динамического создания наборов данных. Службы на этой платформе могут извлекать данные из локальных, облачных сред или поставщиков SaaS. Этот тип платформы обычно также имеет больше накладных расходов, так как существует больше связей с базовыми операционными приложениями. Возможно, вам стоит рассматривать это иначе, чем использование данных.
В архитектуре справа от схемы организация оптимизирует потребление и содержит службы, ориентированные на преобразование данных в значение. Эти службы могут включать машинное обучение, отчеты и т. д.
Эти домены архитектуры соответствуют всем принципам сетки данных. Домены имеют права владения данными и могут напрямую распространять данные в другие домены.
Зоны-хабы, общие и специальные зоны данных
Следующий вариант развертывания — это еще одна итерация предыдущего проекта. Это развертывание следует топологии управляемой сетки: данные распределяются через центральный концентратор, в котором данные секционируются на домен, логически изолированы и не интегрированы. В этой модели используется собственная зона приземления данных (независимая от домена) и она может принадлежать централизованной группе управления данными, контролирующей распределение данных в другие домены. Узел также предоставляет услуги, которые упрощают внедрение данных.

Для доменов, требующих стандартных служб для использования, анализа и создания новых данных, используйте универсальную целевую зону данных. Эта отдельная подписка содержит стандартный набор служб. Кроме того, примените виртуализацию данных, так как большинство продуктов данных уже сохраняются в концентраторе, и вам не требуется больше дублирования данных.
Это развертывание позволяет использовать "специальные": дополнительные зоны приземления, которые можно подготовить, когда логически группировать домены невозможно. Они могут потребоваться, если применяются региональные или юридические границы, или когда у ваших доменов есть уникальные и контрастные требования. Они также могут потребоваться в ситуациях, когда строгое глобальное управление дочерней компанией применяется за исключением зарубежных мероприятий.
Если вашей организации необходимо контролировать, какие данные распределяются и используются доменами, развертывание концентратора является хорошим вариантом. Это также вариант, если вы решаете временные и не изменяющиеся проблемы для крупных потребителей данных. Вы можете строго стандартизировать дизайн продукта на основе данных, который позволяет вашим доменам совершать путешествия во времени и выполнять повторные доставки. Эта модель особенно распространена в финансовой отрасли.
Функциональные и региональные зоны приёма данных
Подготовка нескольких целевых зон данных позволяет группировать функциональные домены на основе согласованности и эффективности работы и совместного использования данных. Все целевые зоны данных соответствуют одному и тому же аудиту и элементам управления, но вы по-прежнему можете иметь гибкие и конструктивные изменения между различными целевыми зонами данных.

Определите функциональные домены данных, которые необходимо логически сгруппировать для общей целевой зоны данных. Например, можно реализовать те же шаблоны, если у вас есть региональные границы. Владение, безопасность или юридические границы могут заставить вас разделять домены. Гибкость, темпы изменений и разделение или продажа возможностей также важны для рассмотрения.
Дополнительные рекомендации и лучшие практики можно найти в доменах данных.
Разные зоны посадки не работают изолированно. Они могут подключаться к озерам данных, размещенным в других зонах. Это позволяет доменам совместно работать в вашей организации. Чтобы смешивать различные технологии хранилищ данных, вы можете также применить полиглотную сохранность. Сохраняемость polyglot позволяет доменам напрямую считывать данные из других доменов без дублирования данных.
При развертывании нескольких зон приземления данных следует учитывать, что каждая зона приземления данных требует затрат на управление. Необходимо применить пиринг виртуальной сети между всеми целевыми зонами данных, управлять дополнительными частными конечными точками и т. д.
Развертывание нескольких зон приема данных - это хороший вариант, если ваша архитектура данных обширна. Вы можете добавить в архитектурное решение дополнительные зоны приземления для удовлетворения общих потребностей различных доменов. Эти дополнительные целевые зоны используют пиринг между виртуальными сетями для подключения как к целевой зоне управления данными, так и ко всем остальным целевым зонам. Пиринг позволяет совместно использовать наборы данных и ресурсы в целевых зонах. Разделение данных между отдельными зонами позволяет распределять рабочие нагрузки между подписками и ресурсами Azure. Этот подход помогает органично реализовать сетку данных.
Крупномасштабное предприятие, требующее различных зон управления данными
Крупные предприятия, работающие в глобальном масштабе, могут иметь контрастные требования к управлению данными между различными частями организации. Для решения этой проблемы можно развернуть несколько контуров управления данными и зон размещения данных. На следующей схеме показан пример этой архитектуры:

Несколько зон приземления для управления данными должны оправдывать ваши затраты и сложность интеграции. Например, другая целевая зона управления данными может иметь смысл в ситуациях, когда метаданные и данные вашей организации ни в коем случае не должны быть доступны кому-либо за пределами вашей организации.
Заключение
Переход к сетке данных — это культурный сдвиг с учетом нюансов, компромиссов и рекомендаций. Вы можете использовать облачную аналитику для получения рекомендаций и исполняемых ресурсов. Эталонные архитектуры этой статьи предлагают начальные точки для запуска реализации.