Подсистема приема данных, не зависящая от данных
В этой статье описывается, как реализовать сценарии механизма приема данных, используя сочетание задач копирования на основе PowerApps, Azure Logic Apps и задач копирования на основе метаданных в Фабрика данных Azure.
Сценарии механизма приема данных не зависят от технических (неконструкционных) пользователей, публикующих ресурсы данных в Data Lake для дальнейшей обработки. Для реализации этого сценария необходимо иметь возможности подключения, которые позволяют:
- Регистрация ресурса данных
- Подготовка рабочих процессов и запись метаданных
- Планирование приема
Вы можете увидеть, как взаимодействуют эти возможности:
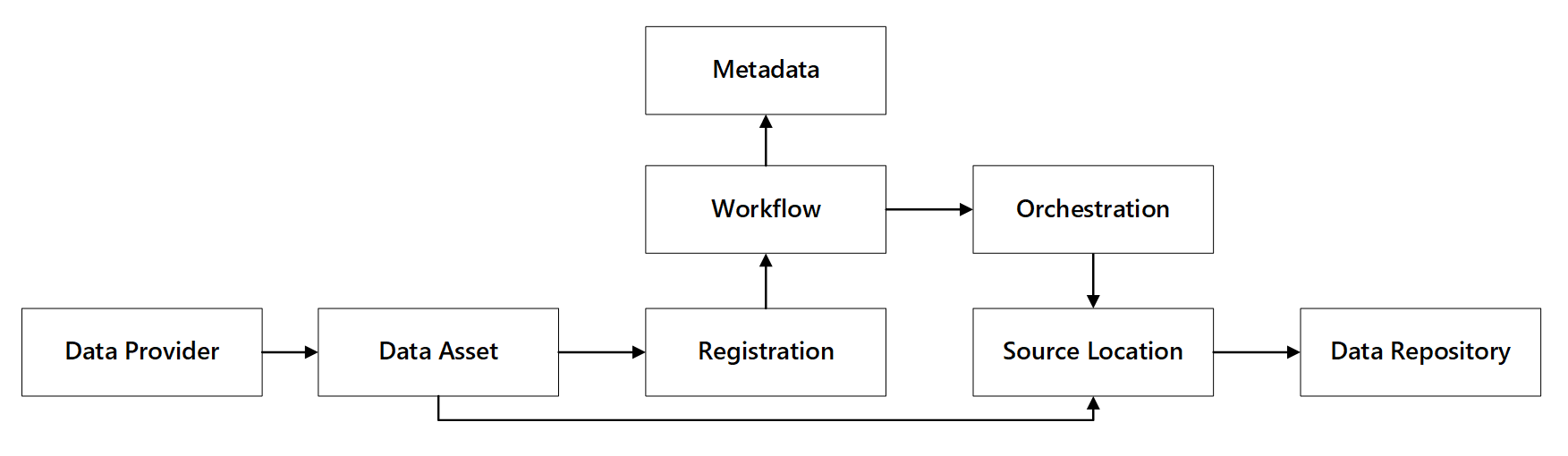
Рис. 1. Возможности регистрации данных.
На следующей схеме показано, как реализовать этот процесс с помощью сочетания служб Azure:
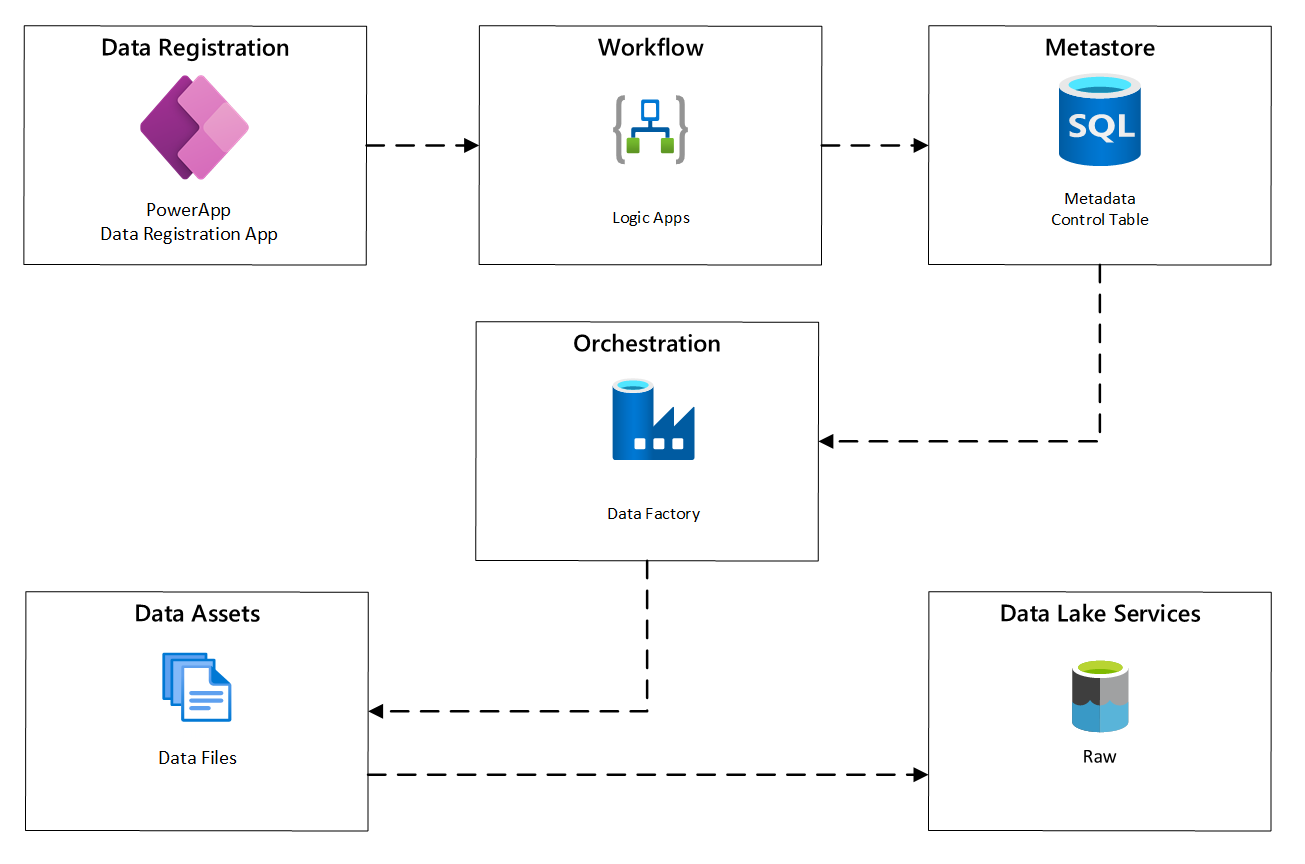
Рис. 2. Автоматизированный процесс приема.
Регистрация ресурса данных
Чтобы предоставить метаданные, используемые для автоматического приема данных, требуется регистрация ресурса данных. Данные, которые вы захватываете, содержат:
- Технические сведения: имя ресурса данных, исходная система, тип, формат и частота.
- Сведения об управлении: владелец, стюарды, видимость (для целей обнаружения) и конфиденциальность.
PowerApps используется для записи метаданных, описывающих каждый ресурс данных. Используйте приложение на основе модели, чтобы ввести сведения, которые сохраняются в настраиваемой таблице Dataverse. При создании или обновлении метаданных в Dataverse запускается автоматизированный поток облака, вызывающий дальнейшие шаги обработки.
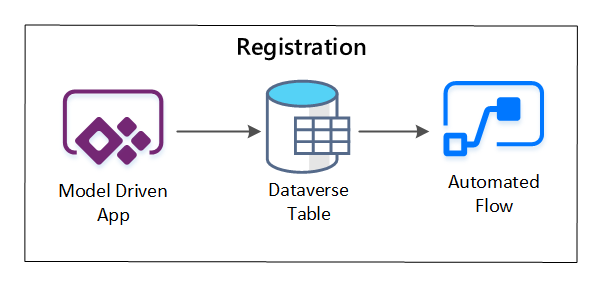
Рис. 3. Регистрация ресурса данных.
Рабочий процесс подготовки или запись метаданных
На этапе рабочего процесса подготовки вы проверяете и сохраняете данные, собранные на этапе регистрации в хранилище метаданных. Выполняются как технические, так и бизнес-проверки, в том числе:
- Проверка входного канала данных
- Активация рабочего процесса утверждения
- Обработка логики для активации сохраняемости метаданных в хранилище метаданных
- Аудит действий
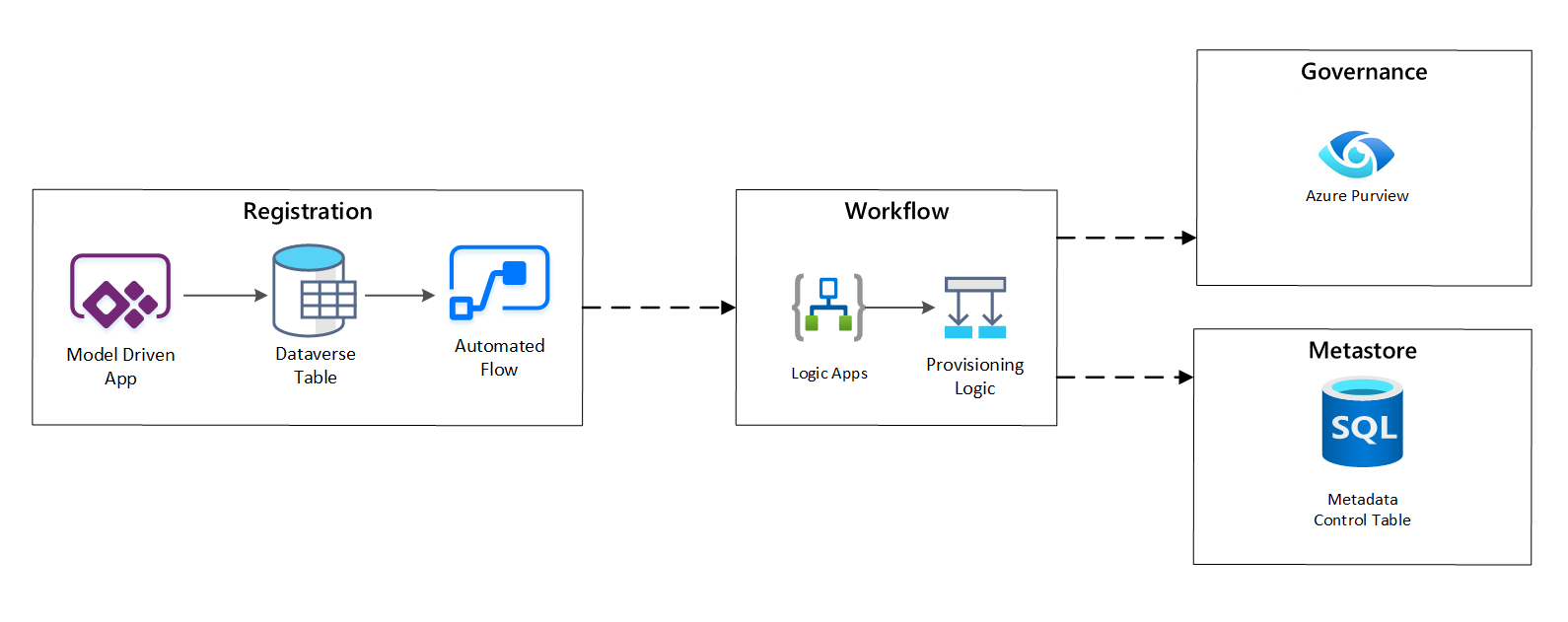
Рис. 4. Рабочий процесс регистрации.
После утверждения запросов приема рабочий процесс использует REST API Azure Purview для вставки источников в Azure Purview.
Подробный рабочий процесс для подключения продуктов данных
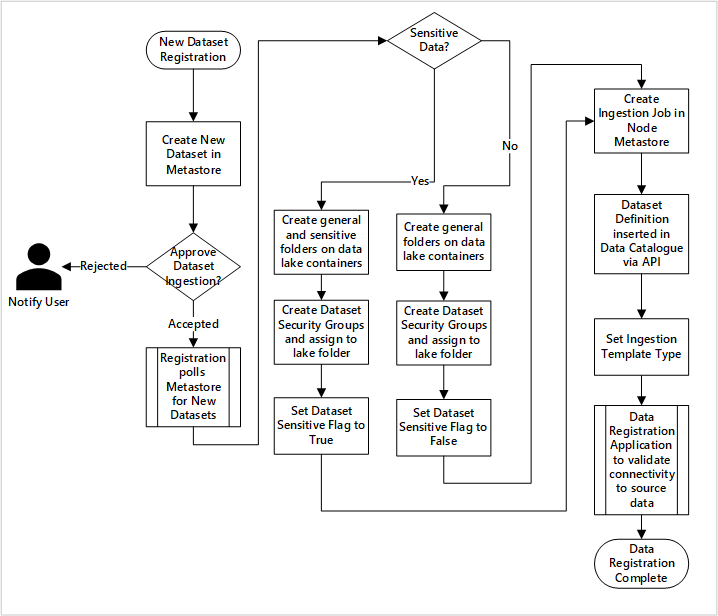
Рис. 5. Прием новых наборов данных (автоматизирован).
На рисунке 5 показан подробный процесс регистрации для автоматизации приема новых источников данных:
- Сведения об источнике регистрируются, включая рабочие и фабрики данных.
- Фиксируются ограничения формы, формата и качества данных.
- Команды приложений данных должны указывать, учитывает ли данные (личные данные) Эта классификация управляет процессом создания папок озера данных для приема необработанных, обогащенных и курируемых данных. Исходные имена необработанных и обогащенных данных и имена продуктов данных курируются.
- Субъект-служба и группы безопасности создаются для приема и предоставления доступа к набору данных.
- Задание приема создается в хранилище метаданных Фабрики данных в целевой зоне данных.
- API вставляет определение данных в Azure Purview.
- После проверки источника данных и утверждения командой операций сведения публикуются в хранилище метаданных Фабрики данных.
Планирование приема
В Фабрика данных Azure задачи копирования, управляемые метаданными, предоставляют функциональные возможности, позволяющие конвейерам оркестрации управлять строками в таблице управления, хранящейся в База данных SQL Azure. Средство копирования данных можно использовать для предварительного создания конвейеров, управляемых метаданными.
После создания конвейера рабочий процесс подготовки добавляет записи в таблицу управления для поддержки приема из источников, определяемых метаданными регистрации ресурса данных. Конвейеры Фабрика данных Azure и База данных SQL Azure, содержащие хранилище метаданных таблицы управления, могут существовать в каждой целевой зоне данных для создания новых источников данных и приема их в целевые зоны данных.
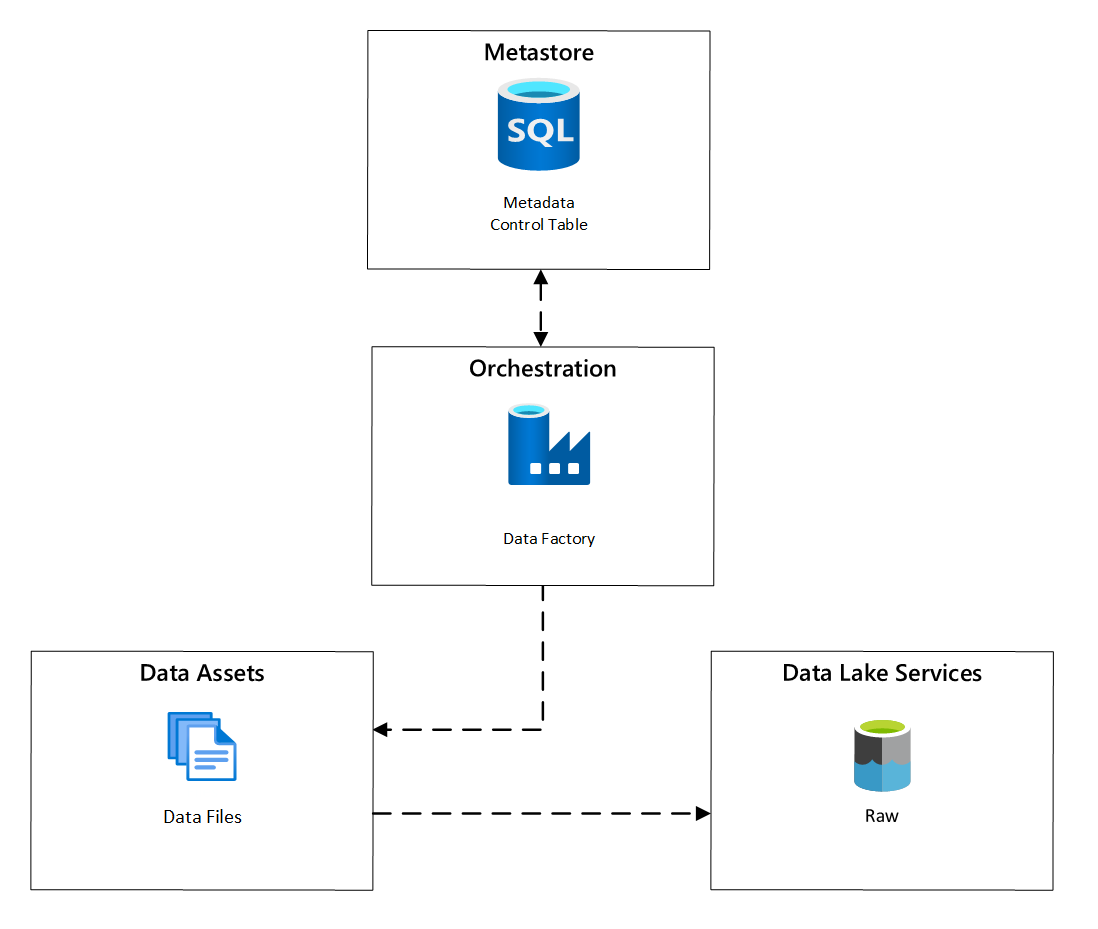
Рис. 6. Планирование приема ресурсов данных.
Подробный рабочий процесс приема новых источников данных
На следующей схеме показано, как извлечь зарегистрированные источники данных в хранилище метаданных фабрики данных База данных SQL и способ приема данных.
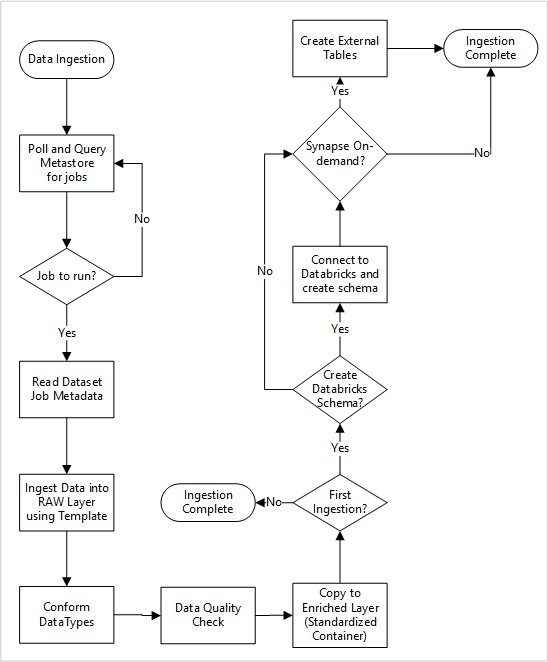
Главный конвейер фабрики данных считывает конфигурации из хранилища метаданных фабрики данных База данных SQL, а затем выполняет итеративно с правильными параметрами. Данные перемещается из источника в необработанный слой в Azure Data Lake без изменений. Фигура данных проверяется на основе хранилища метаданных фабрики данных. Форматы файлов преобразуются в формат Apache Parquet или Avro, а затем копируются в обогащенный слой.
Данные, которые принимаются при приеме, подключаются к рабочей области обработки и анализа данных Azure Databricks, а определение данных создается в хранилище метаданных Apache Hive целевой зоны данных.
Если вам нужно использовать бессерверный пул SQL Azure Synapse для предоставления данных, пользовательское решение должно создавать представления по данным в озере.
Если требуется шифрование на уровне строк или столбцов, пользовательское решение должно приземлить данные в озере данных, а затем принимать данные непосредственно во внутренние таблицы в пулах SQL и настраивать соответствующую безопасность для вычислительных ресурсов пулов SQL.
Захваченные метаданные
При использовании автоматического приема данных можно запрашивать связанные метаданные и создавать панели мониторинга:
- Отслеживайте задания и последние метки времени загрузки данных для продуктов данных, связанных с их функциями.
- Отслеживайте доступные продукты данных.
- Наращивание объемов данных.
- Получение сведений о сбоях заданий в режиме реального времени.
Операционные метаданные можно использовать для отслеживания следующего:
- Задания, шаги заданий и их зависимости.
- Производительность заданий и журнал производительности.
- Рост объема данных.
- Сбои заданий.
- Изменения метаданных источника.
- Бизнес-функции, зависящие от продуктов данных.
Использование REST API Azure Purview для обнаружения данных
REST API Azure Purview следует использовать для регистрации данных во время первоначального приема. API можно использовать для отправки данных в каталог данных вскоре после приема.
Дополнительные сведения см. в статье об использовании REST API Azure Purview.
Регистрация источников данных
Используйте следующий вызов API для регистрации новых источников данных:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
Параметры URI для источника данных:
| имени | Обязательно | Type | Описание |
|---|---|---|---|
accountName |
Истина | Строка | Имя учетной записи Azure Purview |
dataSourceName |
Истина | Строка | Имя источника данных |
Использование REST API Azure Purview для регистрации
В следующих примерах показано, как использовать REST API Azure Purview для регистрации источников данных с полезными данными:
Регистрация источника данных Azure Data Lake Storage 2-го поколения:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Регистрация источника данных Базы данных SQL:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Примечание.
<collection-name> — Это текущая коллекция, существующая в учетной записи Azure Purview.
Создание проверки
Узнайте, как создать учетные данные для проверки подлинности источников в Azure Purview перед настройкой и выполнением проверки.
Используйте следующий вызов API для проверки источников данных:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
Параметры URI для проверки:
| имени | Обязательно | Type | Описание |
|---|---|---|---|
accountName |
Истина | Строка | Имя учетной записи Azure Purview |
dataSourceName |
Истина | Строка | Имя источника данных |
newScanName |
Истина | Строка | Имя новой проверки |
Использование REST API Azure Purview для сканирования
В следующих примерах показано, как использовать REST API Azure Purview для сканирования источников данных с полезными данными:
Проверка источника данных Azure Data Lake Storage 2-го поколения:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Проверка источника данных Базы данных SQL:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Используйте следующий вызов API для проверки источников данных:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run