Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Мы рекомендуем использовать облачную аналитику в Microsoft Azure для эксплуатации проектов обработки и анализа данных.
Разработка шаблона
Разработка шаблона, который объединяет набор служб для проектов обработки и анализа данных. Используйте шаблон, который объединяет набор служб для обеспечения согласованности в различных вариантах использования команд обработки и анализа данных. Рекомендуется разработать согласованную схему в виде репозитория шаблонов. Этот репозиторий можно использовать для различных проектов обработки и анализа данных в организации, чтобы сократить время развертывания.
Рекомендации по шаблонам обработки и анализа данных
Разработайте шаблон обработки и анализа данных для организации с помощью следующих рекомендаций:
Разработка набора шаблонов инфраструктуры в виде кода (IaC) для развертывания рабочей области Машинного обучения Azure. Включите такие ресурсы, как хранилище ключей, учетная запись хранения, реестр контейнеров и Application Insights.
Включите настройку хранилищ данных и целевых объектов вычислений в эти шаблоны, такие как вычислительные экземпляры, вычислительные кластеры и Azure Databricks.
Рекомендации по развертыванию
Реальное время
- Включите развертывание Фабрики данных Azure или Azure Synapse в шаблоны и службы ИИ Azure.
- Шаблоны должны предоставлять все необходимые средства для выполнения этапа исследования и начальной эксплуатации модели.
Рекомендации по начальной настройке
В некоторых случаях специалистам по обработке и анализу данных в организации может потребоваться среда для быстрого анализа по мере необходимости. Эта ситуация распространена, когда проект обработки и анализа данных официально не настроен. Например, руководитель проекта, код затрат или центр затрат, которые могут потребоваться для перекрестного начисления в Azure, может отсутствовать, поскольку данный элемент нуждается в утверждении. Пользователям в организации или команде может потребоваться доступ к среде обработки и анализа данных, чтобы понять данные и, возможно, оценить эффективность проекта. Кроме того, для некоторых проектов полная среда для науки о данных может не требоваться из-за небольшого количества продуктов данных.
В других случаях может потребоваться полный проект обработки и анализа данных с выделенной средой, управлением проектами, кодом затрат и центром затрат. Полные проекты по обработке и анализу данных полезны для нескольких участников группы, которые хотят совместно работать, делиться результатами и должны работать с моделями после успешного выполнения этапа исследования.
Процесс установки
Шаблоны следует развертывать для каждого проекта после их настройки. Каждый проект должен получать по крайней мере два экземпляра для разделения сред разработки и рабочей среды. В рабочей среде ни один человек не должен иметь доступ, и всё должно быть развернуто с помощью конвейеров непрерывной интеграции или непрерывной разработки и служебного аккаунта. Эти принципы рабочей среды важны, так как машинное обучение Azure не предоставляет детализированную модель управления доступом на основе ролей в рабочей области. Невозможно ограничить доступ пользователей к определенному набору экспериментов, конечных точек или конвейеров.
Одни и те же права доступа обычно применяются к различным типам артефактов. Важно отделять разработку от рабочей среды, чтобы предотвратить удаление рабочих конвейеров или конечных точек в рабочей области. Вместе с шаблоном необходимо создать процесс, чтобы предоставить группам продуктов данных возможность запрашивать новые среды.
Рекомендуется настроить различные службы ИИ, такие как службы ИИ Azure на основе каждого проекта. Путем настройки различных служб ИИ на основе каждого проекта развертывание происходит для каждой группы ресурсов продукта данных. Эта политика создает четкое разделение с точки зрения доступа к данным и снижает риск несанкционированного доступа к данным неправильными командами.
Сценарий потоковой передачи
Для сценариев использования в режиме реального времени и потоковой передачи развертывание следует протестировать на уменьшенной службе Azure Kubernetes (AKS). Тестирование можно использовать в среде разработки, чтобы сэкономить на затратах перед развертыванием в рабочей службе AKS или Службе приложений Azure для контейнеров. Чтобы убедиться, что службы отвечают должным образом, следует выполнить простые входные и выходные тесты.
Затем можно развернуть модели в нужной службе. Эта цель вычислительных развертываний является единственной, которая общедоступна и рекомендована для производственных нагрузок в кластере AKS. Этот шаг более необходим, если требуется поддержка графической обработки (GPU) или массива шлюзов с возможностью программирования полей. Другие собственные варианты развертывания, поддерживающие эти требования к оборудованию, в настоящее время недоступны в Машинном обучении Azure.
Для машинного обучения Azure требуется сопоставление "один к одному" с кластерами AKS. Каждое новое подключение к рабочей области Машинного обучения Azure нарушает предыдущее подключение между AKS и Машинным обучением Azure. После устранения этого ограничения мы рекомендуем развернуть центральные кластеры AKS в качестве общих ресурсов и присоединить их к соответствующим рабочим областям.
Перед перемещением модели в производственную среду AKS, необходимо разместить дополнительный тестовый экземпляр AKS для проведения стресс-тестов. Тестовая среда должна предоставить тот же вычислительный ресурс, что и рабочая среда, чтобы результаты были максимально похожи на рабочую среду.
Сценарий пакетной обработки
Не все варианты использования требуют развертывания кластера AKS. Не нужно развертывать кластер AKS, если в сценарии использования требуется только регулярное оценивание больших объемов данных или оно основано на событии. Например, большие объемы данных могут быть основаны на том, когда данные попадают в определенную учетную запись хранения. Конвейеры машинного обучения Azure и вычислительные кластеры Машинного обучения Azure должны использоваться для развертывания во время этих типов сценариев. Эти конвейеры данных должны быть организованы и выполнены в Data Factory.
Определение правильных вычислительных ресурсов
Перед развертыванием модели в Машинном обучении Azure в AKS пользователю необходимо указать ресурсы, такие как ЦП, ОЗУ и GPU, которые должны быть выделены для соответствующей модели. Определение этих параметров может быть сложным и емким процессом. Чтобы определить хороший набор параметров, необходимо выполнить стресс-тесты с различными конфигурациями. Этот процесс можно упростить с помощью функции профилирования модели
Чтобы безопасно обновить модели в Машинном обучении Azure, команды должны использовать контролируемый компонент развертывания (предварительная версия), чтобы свести к минимуму время простоя и обеспечить согласованность конечной точки REST модели.
Лучшие практики и рабочий процесс в области MLOps
Включение примера кода в репозитории для обработки и анализа данных
Вы можете упростить и ускорить проекты по науке о данных, если у ваших команд есть определенные артефакты и передовые практики. Рекомендуется создавать артефакты, которые все команды обработки и анализа данных могут использовать при работе с Машинным обучением Azure и соответствующими инструментами среды продуктов данных. Инженеры по обработке данных и машинному обучению должны создавать и предоставлять артефакты.
Эти артефакты должны включать:
Примеры записных книжек, которые показывают, как:
- Загрузка, подключение и работа с продуктами данных.
- Логирование метрик и параметров.
- Отправка заданий обучения в вычислительные кластеры.
Артефакты, необходимые для операционизации:
- Примеры конвейеров машинного обучения Azure
- Примеры Azure Pipelines
- Для выполнения конвейеров требуется больше скриптов
Документация
Использование хорошо разработанных артефактов для эксплуатации конвейеров
Артефакты могут ускорить исследовательские и внедренческие этапы проектов в области data science. Стратегия ответвления в DevOps может помочь масштабировать эти артефакты во всех проектах. Поскольку эта настройка содействует использованию Git, пользователи и весь процесс автоматизации могут извлечь выгоду из предоставленных артефактов.
Совет
Примеры конвейеров машинного обучения Azure должны создаваться с помощью пакета SDK для программного обеспечения Python или на основе языка YAML. Новый опыт работы с YAML будет более перспективным, так как продуктовая команда Azure Machine Learning в настоящее время работает над новым пакетом SDK и интерфейсом командной строки (CLI). Группа продуктов машинного обучения Azure уверена, что YAML будет служить языком определения для всех артефактов в Машинном обучении Azure.
Образцы конвейеров не работают в готовом виде для каждого проекта, но их можно использовать в качестве базы. Вы можете настроить примеры конвейеров для проектов. Конвейер должен включать наиболее важные аспекты каждого проекта. Например, конвейер может ссылаться на целевой объект вычислений, эталонные продукты данных, определять параметры, определять входные данные и определять шаги выполнения. Для Azure Pipelines необходимо выполнить тот же процесс. Azure Pipelines также должен использовать пакет SDK машинного обучения Azure или CLI.
Конвейеры должны продемонстрировать, как:
- Подключитесь к рабочему пространству из конвейера DevOps.
- Проверьте, доступен ли необходимый вычислительный ресурс.
- Загрузите задание.
- Зарегистрируйте и разверните модель.
Артефакты не всегда подходят для всех проектов и могут потребовать настройки, но наличие основы может ускорить внедрение и развертывание проекта.
Структура репозитория MLOps
У вас могут возникнуть ситуации, когда пользователи теряют отслеживание того, где они могут находить и хранить артефакты. Чтобы избежать этих ситуаций, следует запросить больше времени для взаимодействия и создания структуры папок верхнего уровня для стандартного репозитория. Все проекты должны соответствовать структуре папок.
Заметка
Основные понятия, упомянутые в этом разделе, можно использовать в локальных средах, Amazon Web Services, Palantir и Azure.
Предлагаемая структура папок верхнего уровня для репозитория MLOps (операции машинного обучения) показана на следующей схеме:
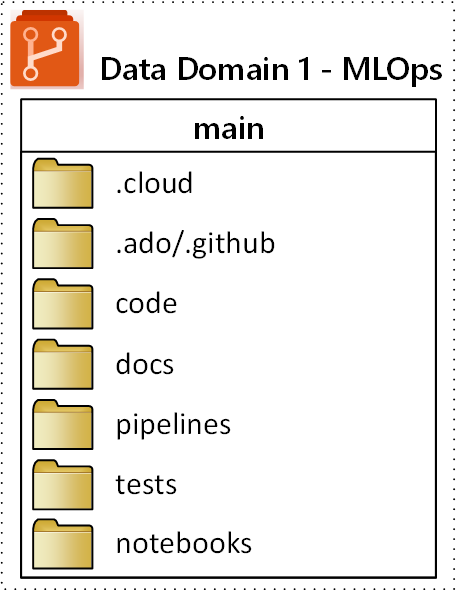
Следующие цели применяются к каждой папке в репозитории:
| Папка | Цель |
|---|---|
.cloud |
Сохраните код и артефакты, относящиеся к облаку, в этой папке. Артефакты включают файлы конфигурации для рабочей области Машинного обучения Azure, включая определения целевых объектов вычислений, задания, зарегистрированные модели и конечные точки. |
.ado/.github |
Храните в этой папке артефакты Azure DevOps или GitHub, такие как конвейеры YAML или владельцы кода. |
code |
Включите фактический код, разработанный в рамках проекта в этой папке. Эта папка может содержать пакеты Python и некоторые скрипты, используемые для соответствующих шагов конвейера машинного обучения. Рекомендуется разделять отдельные шаги, которые необходимо выполнить в этой папке. Распространенными этапами являются предварительная обработка, обучение моделии регистрация модели. Определите зависимости, такие как зависимости Conda, образы Docker или другие для каждой папки. |
docs |
Используйте эту папку в целях документации. В этой папке хранятся файлы и изображения Markdown для описания проекта. |
pipelines |
Хранение определений конвейеров машинного обучения Azure в YAML или Python в этой папке. |
tests |
Написание модульных и интеграционных тестов, которые необходимо выполнить для обнаружения ошибок и проблем в начале проекта в этой папке. |
notebooks |
Разделите записные книжки Jupyter от основного проекта Python в этой папке. В папке каждый пользователь должен иметь вложенную папку для проверки записных книжек и предотвращения конфликтов слиянием Git. |