Краткое руководство: пользовательская классификация текста
Используйте эту статью, чтобы приступить к созданию проекта пользовательской классификации текста, в котором можно выполнять обучение настраиваемых моделей для классификации текста. Модель представляет собой программный продукт с функциями искусственного интеллекта, обученный для выполнения определенной задачи. Для этой системы модели классифицируют текст, а для обучения этих моделей используются данные с тегами.
Пользовательская классификация текстов поддерживает проекты двух типов:
- Классификация по одной метке — каждому документу из набора данных можно назначить только один класс. Например, сценарий фильма можно классифицировать только как "Романтический фильм" или "Комедия".
- Классификация по нескольким меткам — каждому документу из набора данных можно назначить несколько классов. Например, сценарий фильма можно классифицировать как "Комедия" или "Романтический фильм" и "Комедия".
В этом кратком руководстве вы можете с помощью предоставленных примеров наборов данных создать классификацию с использованием нескольких меток, позволяющую назначить сценариям фильмов одну или несколько категорий. Можно также использовать набор данных для классификации с использованием одной метки, позволяющий отнести отрывки научных работ к одной из заданных предметных областей.
Необходимые компоненты
- Подписка Azure — создайте бесплатную учетную запись.
Создание нового ресурса языка ИИ Azure и учетной записи хранения Azure
Прежде чем использовать настраиваемую классификацию текста, необходимо создать ресурс языка искусственного интеллекта Azure, который предоставит учетные данные, необходимые для создания проекта и начала обучения модели. Кроме того, вам потребуется учетная запись хранения Azure, чтобы отправить в нее набор данных, который будет использоваться для создания модели.
Важно!
Чтобы быстро приступить к работе, рекомендуется создать новый ресурс языка искусственного интеллекта Azure, выполнив действия, описанные в этой статье. Эти действия помогут одновременно создать ресурс службы "Язык" и учетную запись хранения, так как проще сделать это сейчас, чем потом.
Если вы хотите использовать уже существующий ресурс, его нужно подключить к учетной записи хранения.
Создание ресурса на портале Azure
Перейдите к портал Azure, чтобы создать новый ресурс языка искусственного интеллекта Azure.
В появившемся окне выберите настраиваемую классификацию текста и распознавание именованных сущностей из пользовательских функций. Нажмите кнопку "Продолжить", чтобы создать ресурс в нижней части экрана.
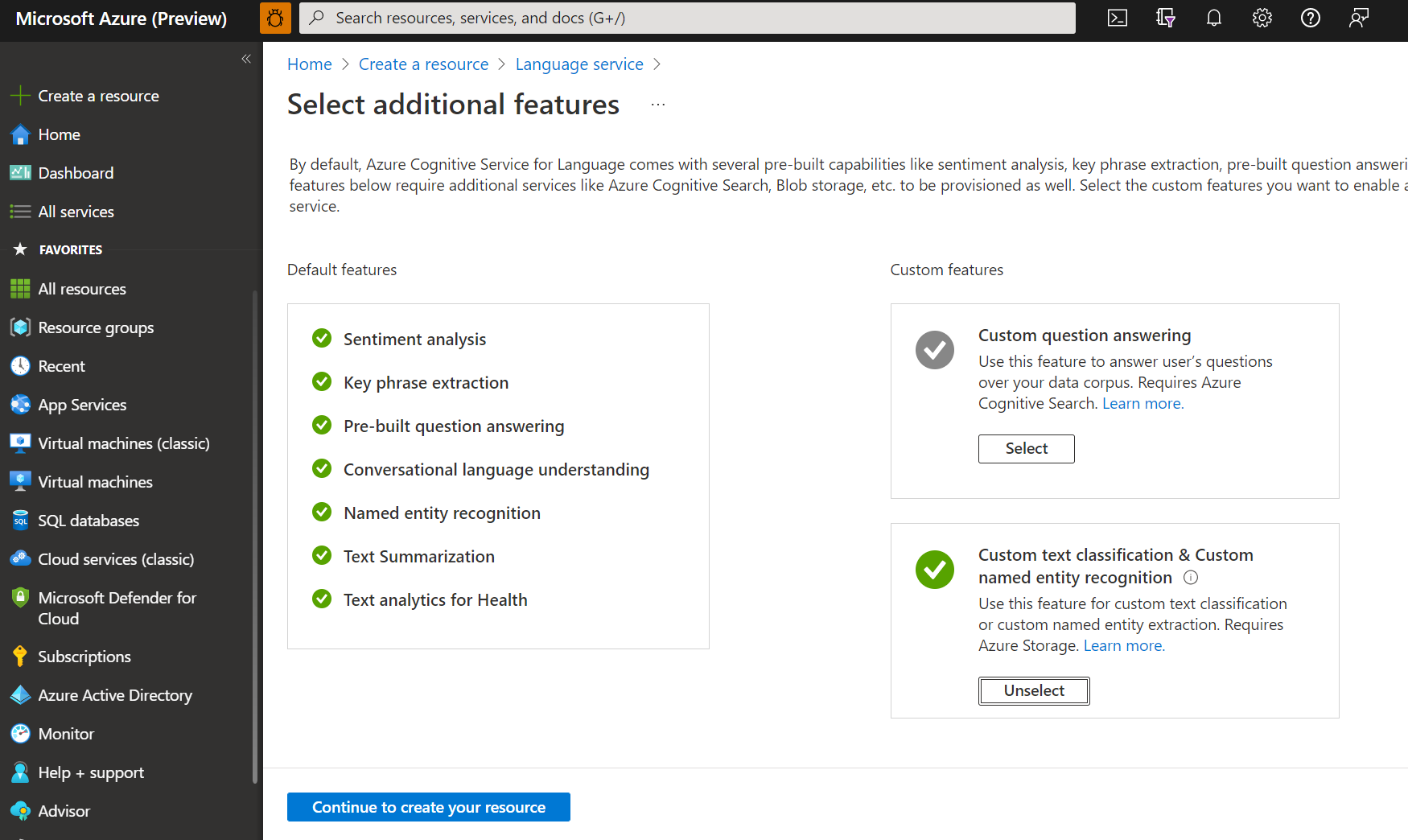
Создайте ресурс службы "Язык" с приведенными ниже сведениями.
Имя. Обязательное значение Отток подписок Вашу подписку Azure. Группа ресурсов Группа ресурсов, которая будет содержать ваш ресурс. Можно использовать существующую группу или создать новую. Регион Один из поддерживаемых регионов. Например, "Запад США 2". Имя. Имя ресурса. Ценовая категория Одна из поддерживаемых ценовых категорий. Вы можете использовать уровень "Бесплатный" (F0), чтобы поработать со службой. Если появится сообщение Ваша учетная запись входа не является владельцем выбранной группы ресурсов учетной записи хранения, значит, ваша учетная запись должна иметь роль владельца, назначенную группе ресурсов, — только тогда вы сможете создать ресурс службы "Язык". Обратитесь за помощью к владельцу подписки Azure.
Вы можете определить владельца подписки Azure, выполнив поиск в группе ресурсов и следуя ссылке на связанную подписку. Затем:
- Выберите вкладку контроль доступа (IAM)
- Выбор назначений ролей
- Фильтрация по роли:владелец.
В разделе "Настраиваемая классификация текста" и "Распознавание именованных сущностей" выберите существующую учетную запись хранения или выберите новую учетную запись хранения. Обратите внимание, что значения для учетной записи хранения предназначены для того, чтобы помочь вам начать работу, и не обязательно должны использоваться в рабочих средах. Чтобы избежать задержек при создании проекта, подключитесь к учетным записям хранения в том же регионе, что и ресурс Языка.
Значение для учетной записи хранения Рекомендуемое значение Storage account name Любое имя Storage account type Standard LRS Убедитесь, что флажок Уведомление об ответственном применении ИИ установлен. В нижней части страницы выберите Review + create (Проверить и создать).

Отправка примера данных в контейнер BLOB-объектов
Когда вы создадите учетную запись хранения Azure и подключите ее к ресурсу службы "Язык", нужно будет отправить документы из примера набора данных в корневой каталог контейнера. Эти документы будут использоваться для обучения модели.
Скачайте пример набора данных для проектов классификации по нескольким меткам.
Откройте файл ZIP и извлеките папку с документами.
Предоставленный пример набора данных содержит около 200 документов, каждый из которых представляет собой краткое содержание фильма. Каждый документ принадлежит одному или нескольким из следующих классов:
- "Детектив"
- "Drama"
- "Триллер"
- "Комедия"
- "Боевик"
На портале Azure перейдите к созданной учетной записи хранения и выберите ее. Это можно сделать, щелкнув служба хранилища учетные записи и введя имя учетной записи хранения в фильтр для любого поля.
Если группа ресурсов не отображается, убедитесь, что фильтр "Подписка равен всем".
В учетной записи хранения в меню слева выберите Контейнеры под пунктом Хранилище данных. На появившемся экране нажмите + Контейнер. Присвойте контейнеру имя example-data и оставьте Уровень общего доступа, установленный по умолчанию.
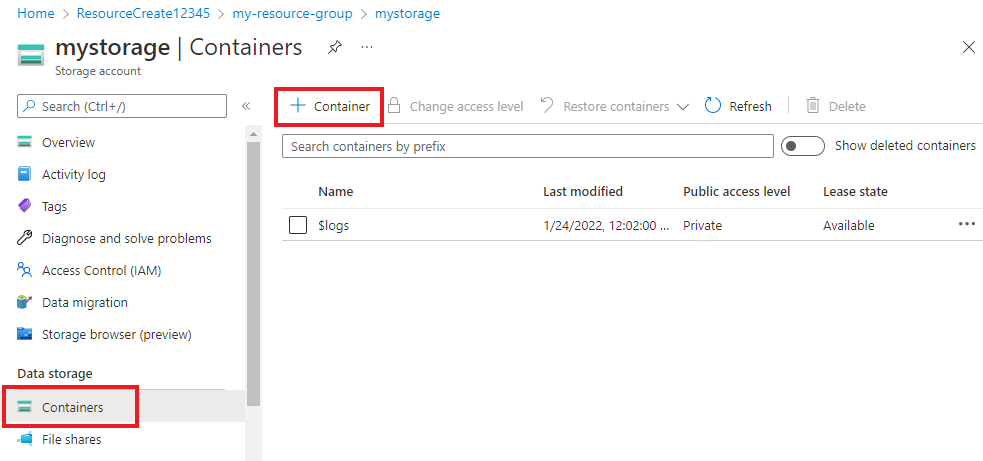
Когда контейнер будет создан, выберите его. Затем нажмите кнопку "Отправить", чтобы выбрать
.txtскачанные ранее файлы..json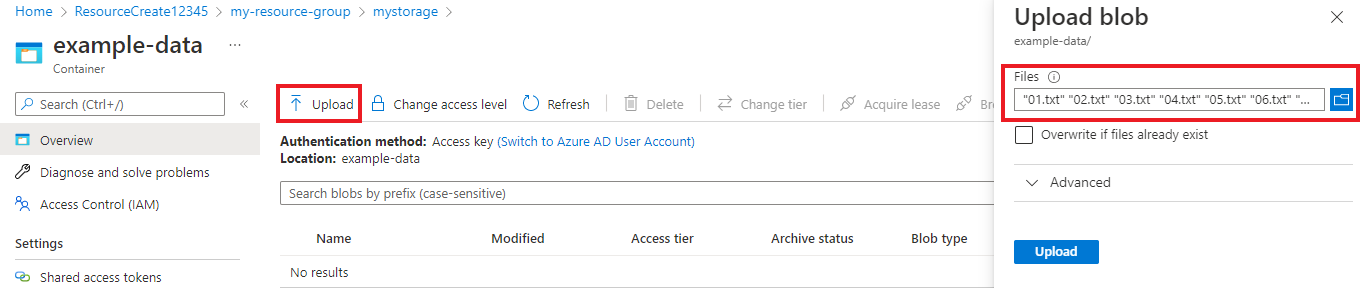


Создание пользовательского проекта классификации текстов
После настройки контейнера ресурсов и хранилища создайте новый проект пользовательской классификации текстов. Проект — это рабочая область для создания настраиваемых моделей машинного обучения на основе данных. Получить доступ к вашему проекту можете только вы и другие пользователи, у которых есть доступ к используемому ресурсу службы "Язык".
Войдите в Студию Языка. Появится окно, где можно выбрать свою подписку и ресурс служб "Язык". Выберите свой языковой ресурс.
В разделе Классификация текста в Студии Языка выберите Пользовательская классификация текстов.
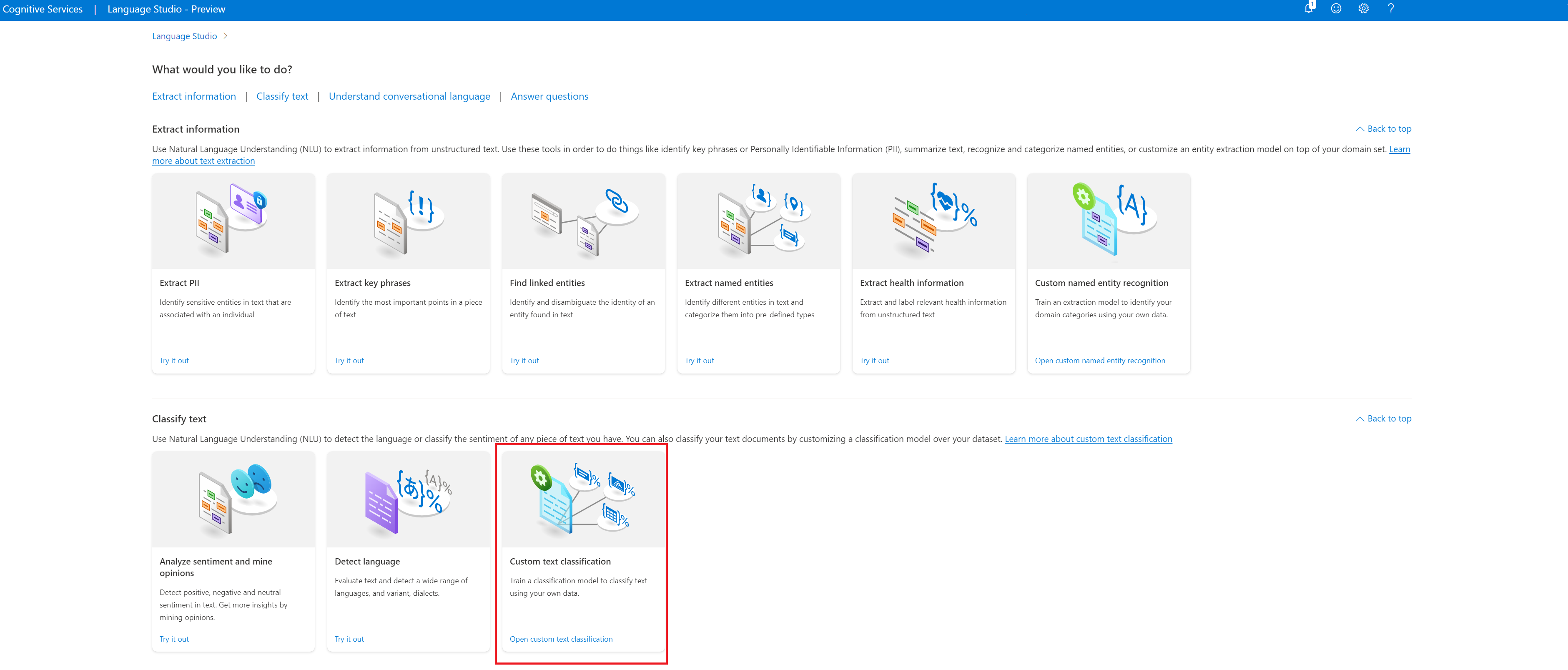
Щелкните Create new project (Создать новый проект) в меню в верхней части страницы проектов. Создав проект, вы сможете добавлять метки к данным, а также обучать, оценивать, улучшать и развертывать модели.
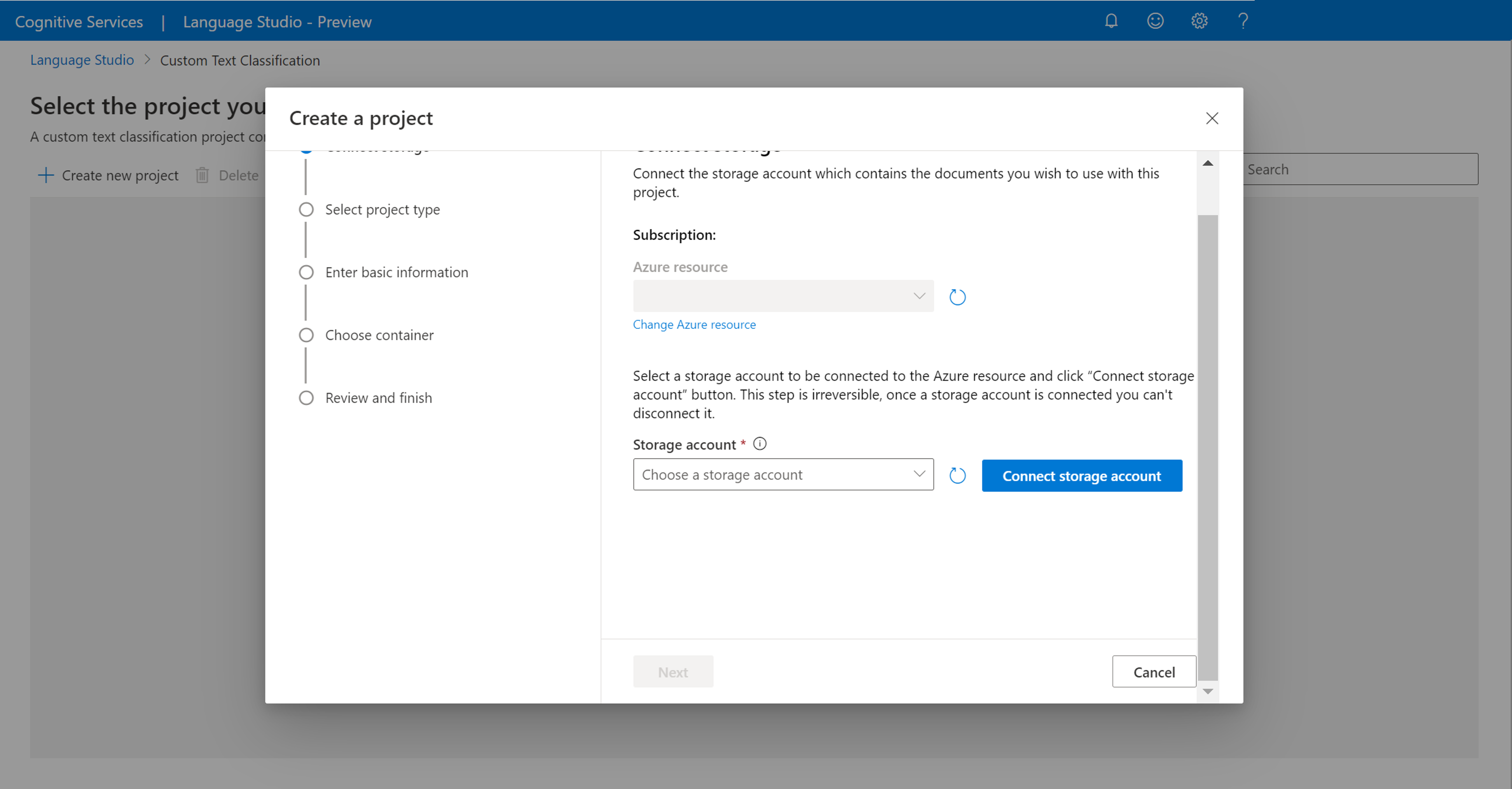
После нажатия кнопки Создать новый проект появится окно, где можно подключить учетную запись хранения. Если вы уже подключили учетную запись хранения, отобразится подключенная учетная запись хранения. Если нет, выберите учетную запись хранения в раскрывающемся списке и выберите Подключение учетную запись хранения. Это позволит задать необходимые роли для учетной записи хранения. На этом шаге может появиться ошибка, если вы не назначены в качестве владельца учетной записи хранения.
Примечание.
- Этот шаг нужно выполнить только один раз для каждого нового используемого ресурса Языка.
- Этот процесс необратим. Если учетная запись хранения будет подключена к ресурсу службы "Язык", ее нельзя будет отключить позже.
- Вы можете подключить ресурс службы "Язык" только к одной учетной записи хранения.
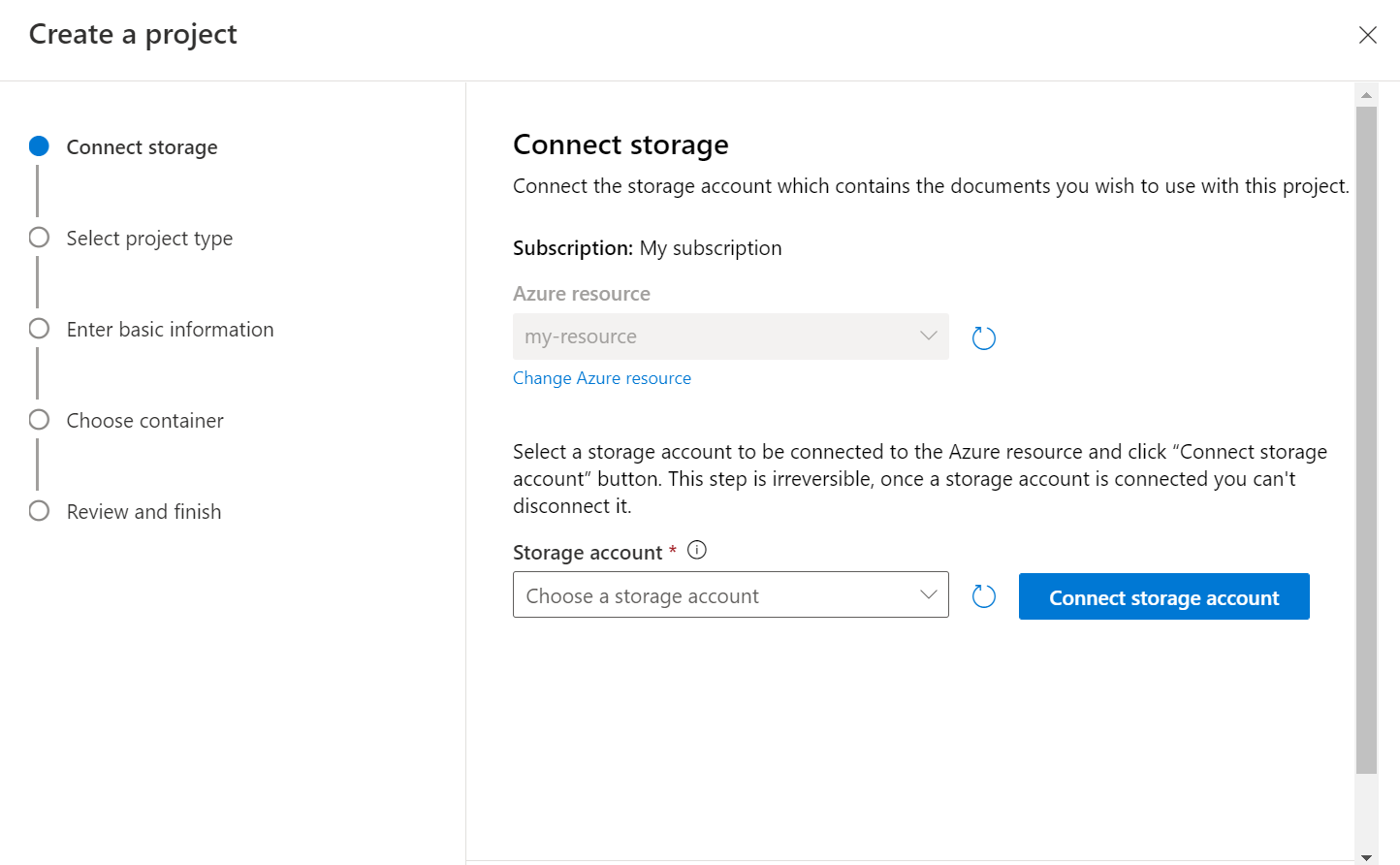
Выберите тип проекта. Вы можете создать проект Классификация по нескольким меткам, в котором каждый документ может принадлежать одному или нескольким классам, или проект Классификация по одной метке, в котором каждый документ может принадлежать только одному классу. Выбранный тип нельзя изменить позже. Дополнительные сведения о типах проектов.
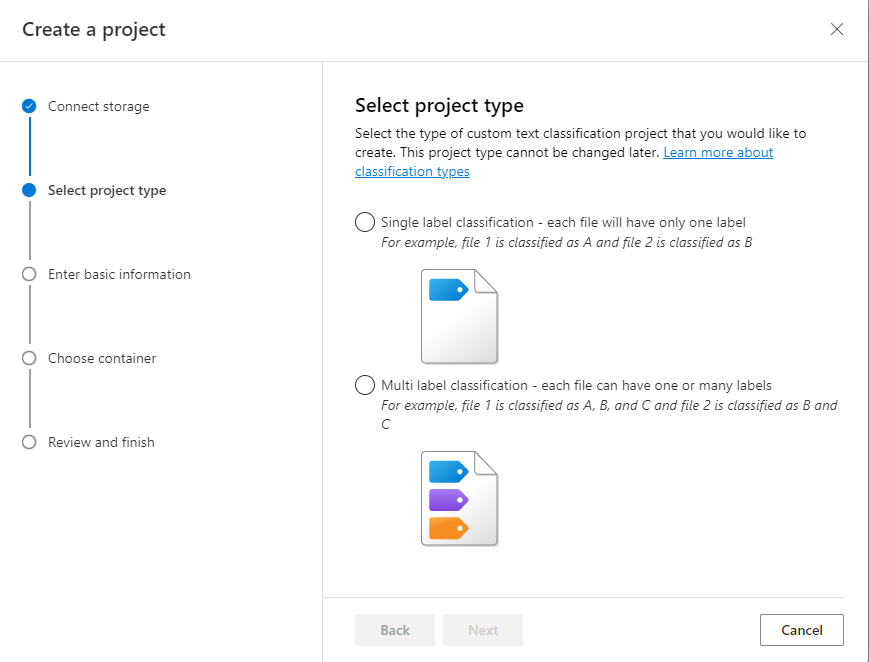
Введите сведения о проекте, включая имя, описание и язык документов в проекте. Если вы используете пример набора данных, выберите английский язык. Вы не сможете изменить имя проекта на более поздних этапах. Выберите Далее.
Совет
Набор данных не обязательно должен быть полностью на одном языке. У вас может быть несколько документов с разными поддерживаемыми языками. Если набор данных содержит документы с разными языками или если во время выполнения предполагается использовать тексты на разных языках, выберите параметр Включить многоязычный набор данных при вводе основных сведений о проекте. Этот параметр можно включить позже на странице Параметры проекта.
Выберите контейнер, в который отправили набор данных.
Примечание.
Если вы уже наклеили данные, убедитесь, что он соответствует поддерживаемму формату и выберите "Да", мои документы уже помечены, и я отформатировал файл меток JSON и выберите файл меток в раскрывающемся меню ниже.
Если вы используете один из примеров наборов данных, используйте включенный
webOfScience_labelsFileилиmovieLabelsjson-файл. Затем выберите Далее.Проверьте введенные данные и щелкните Create Project (Создать проект).




Обучение модели
Как правило, после создания проекта вы маркируете документы в подключенном к проекту контейнере. При работе с этим кратким руководством вы импортировали пример набора данных с метками и инициализировали проект, используя пример JSON-файла с метками.
Чтобы начать обучение модели в студии службы "Язык", сделайте следующее:
Выберите элемент Задания обучения в меню слева.
В верхнем меню выберите Запустить задание на обучение.
Щелкните Train a new model (Обучить новую модель) и введите имя модели в текстовое поле. Можно также перезаписать существующую модель. Для этого выберите соответствующий параметр и укажите модель, которую требуется перезаписать, в раскрывающемся меню. Перезапись обученной модели необратима, но это не повлияет на развернутые модели до тех пор, пока вы не развернете новую модель.

Выберите метод разделения данных. Вы можете выбрать вариант Automatically splitting the testing set from training data (Автоматическое выделение тестового набора из обучающих данных), при котором система разделит данные с метками на обучающий и тестовый наборы в указанной вами пропорции. Кроме того, можно использовать разделение данных обучения и тестирования вручную. Этот параметр включается только в том случае, если вы добавили документы в набор тестирования во время маркировки данных. Дополнительные сведения о разделении данных см. в разделе Обучение модели.
Нажмите кнопку Обучить.
Если выбрать идентификатор задания обучения из списка, на боковой панели появится область, где можно проверка ход обучения, состояние задания и другие сведения для этого задания.
Примечание.
- Модели будут создаваться только с помощью успешно завершенных заданий обучения.
- Время обучения модели может занять от нескольких минут до нескольких часов на основе размера помеченных данных.
- В каждый момент времени может выполняться только одно задание на обучение. Нельзя запустить другое задание обучения в том же проекте до тех пор, пока не будет завершено выполнение задания.

Развертывание модели
Обычно после обучения модели изучаются сведения об оценке и вносятся необходимые улучшения. В этом кратком руководстве вы просто развернете модель и предоставите себе к ней доступ в студии службы "Язык". Можно также вызвать API прогнозирования.
Чтобы развернуть модель в студии службы "Язык", выполните следующие действия.
В меню слева выберите Развертывание модели.
Выберите " Добавить развертывание", чтобы запустить новое задание развертывания.
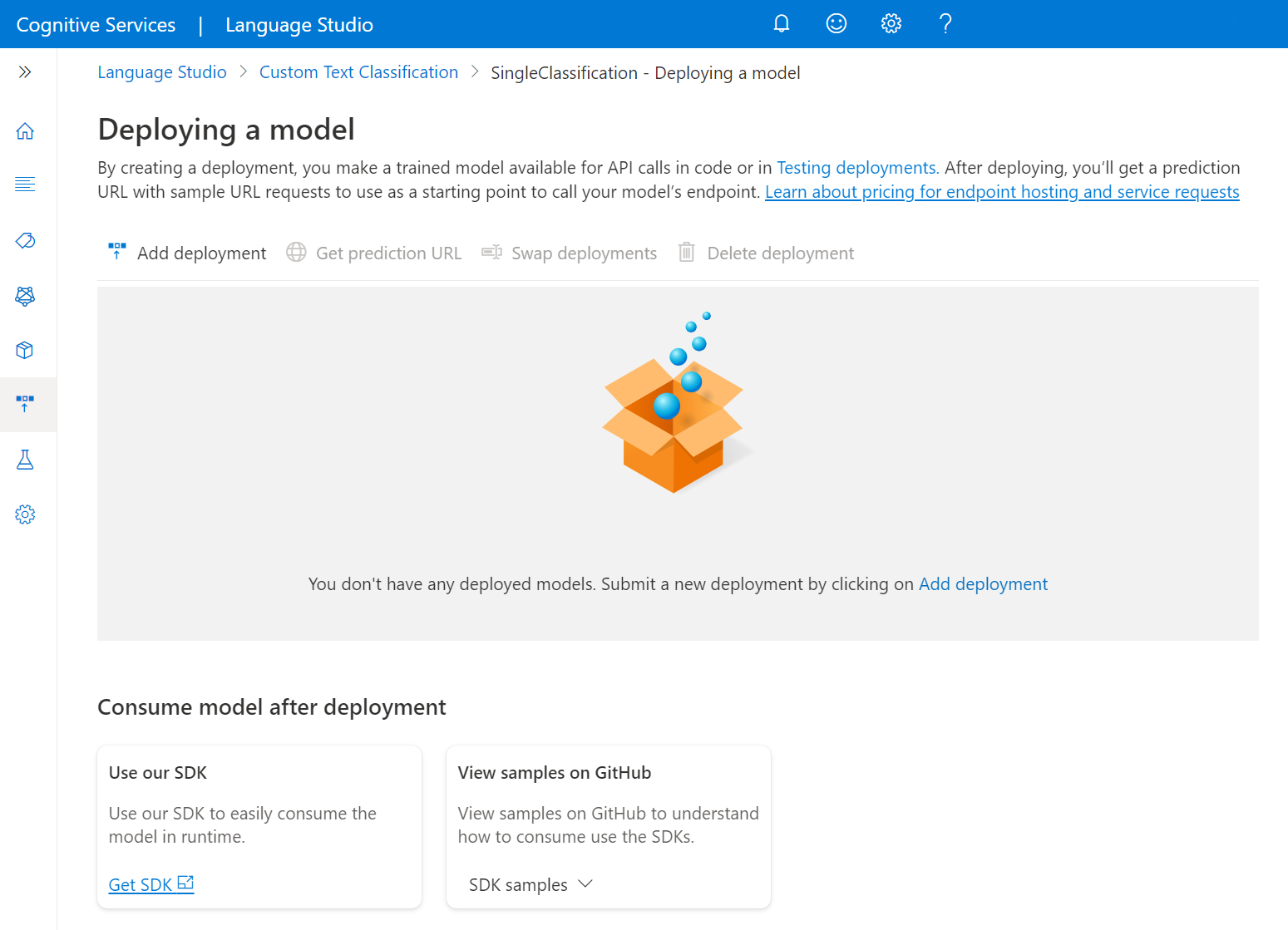
Выберите Создать развертывание, чтобы создать развертывание и назначить обученную модель из раскрывающегося списка ниже. Можно также выбрать вариант Overwrite an existing deployment (Перезаписать существующее развертывание) и выбрать обученную модель, которую требуется назначить развертыванию, в раскрывающемся списке ниже.
Примечание.
Для перезаписи существующего развертывания не требуется вносить изменения в вызов API прогнозирования, но полученные результаты будут основаны на новой назначенной модели.
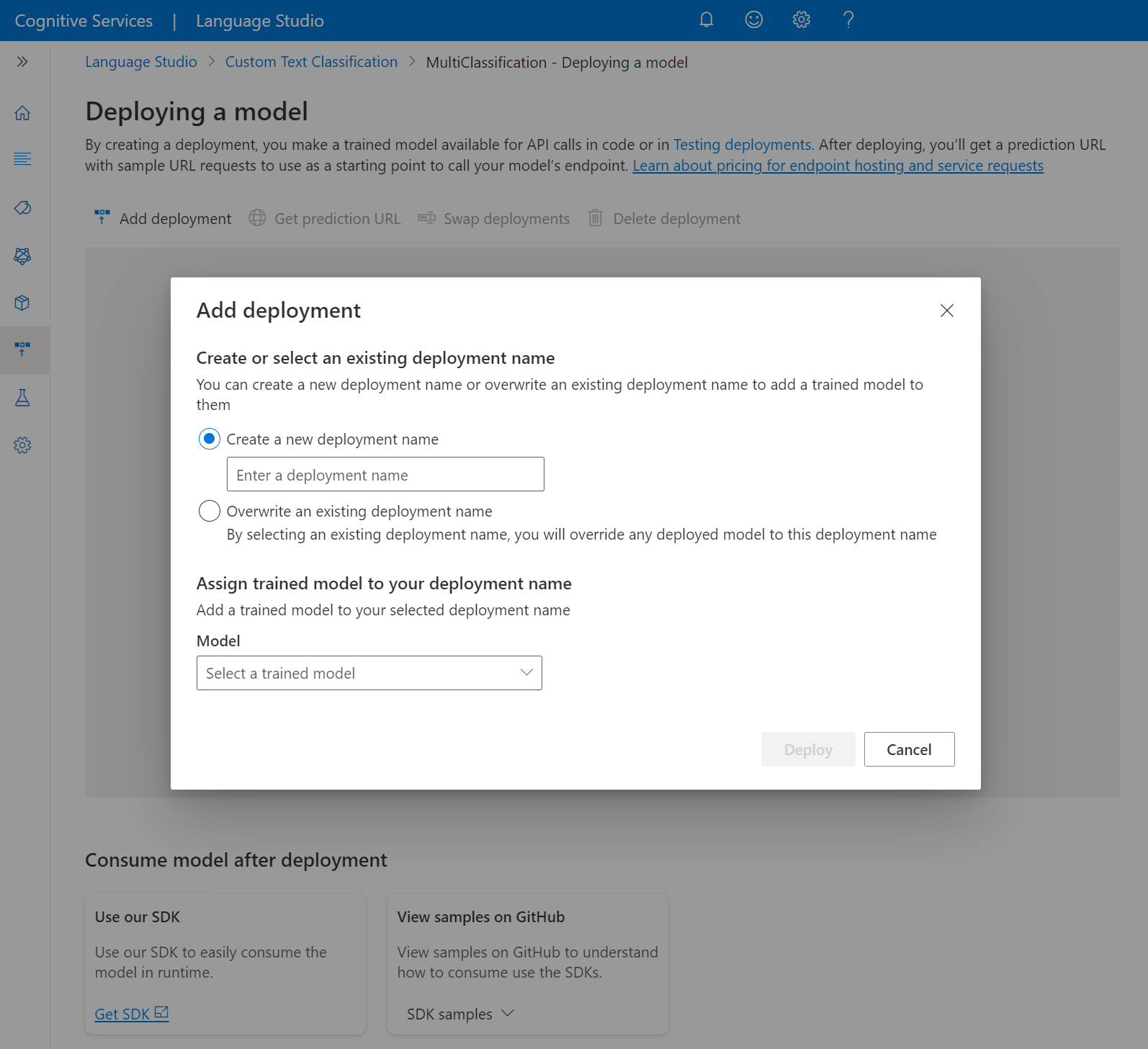
Выберите "Развернуть" , чтобы запустить задание развертывания.
После успешного развертывания рядом с ним появится дата окончания срока действия. Окончание срока действия развертывания означает, что модель становится недоступной для использования в целях прогнозирования, что обычно происходит через двенадцать месяцев после окончания срока действия конфигурации обучения.


Тестирование модели
Развернутую модель можно начать использовать для классификации текста с помощью API прогнозирования. В этом кратком руководстве вы будете использовать студию службы "Язык" для отправки задачи пользовательской классификации текстов и визуализации результатов. Загруженный ранее пример набора данных содержит некоторые тестовые документы, которые можно использовать на этом шаге.
Чтобы протестировать развернутые модели в студии службы "Язык", выполните следующие действия.
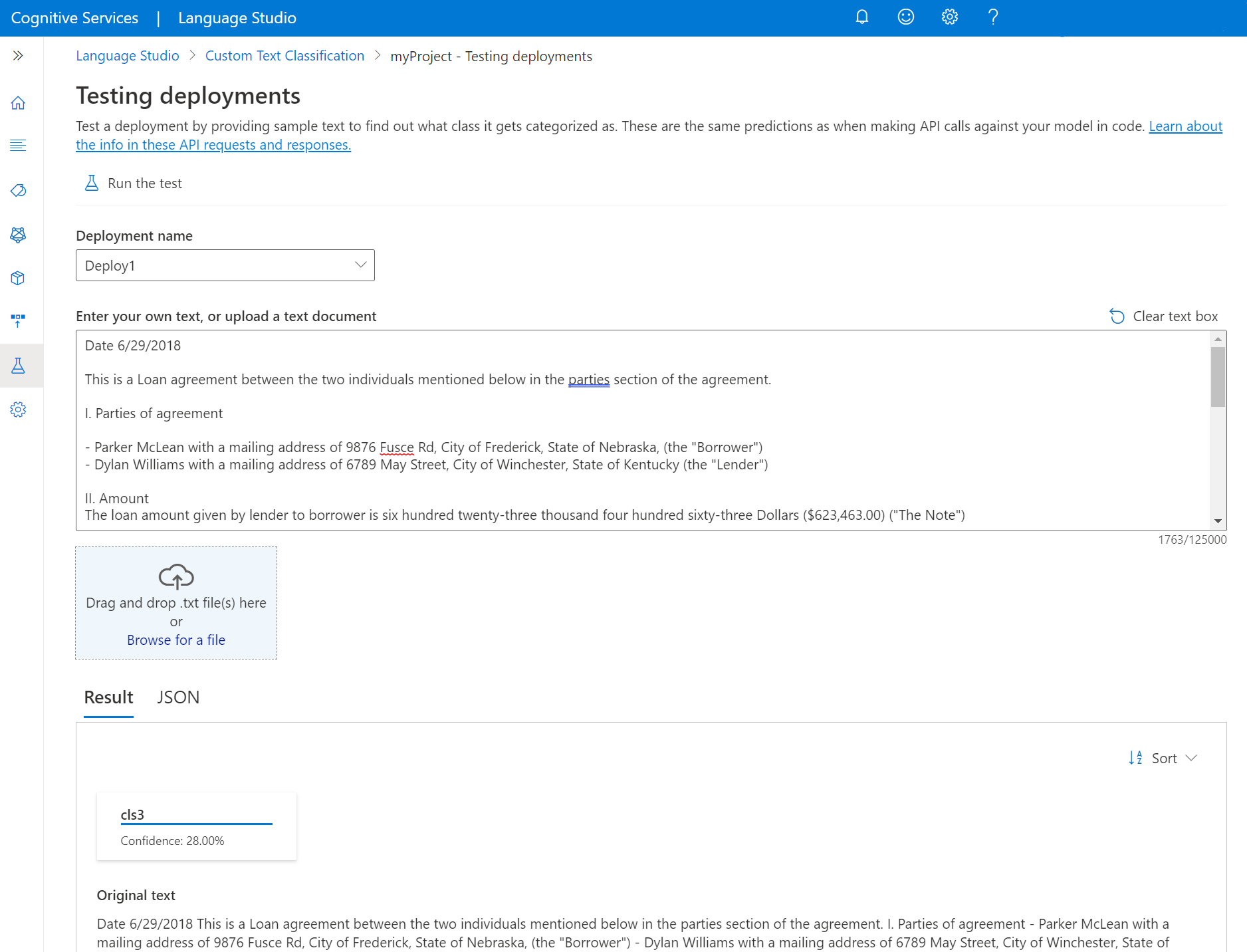
В меню в левой части экрана выберите Testing deployments (Тестирование развертываний).
Выберите развертывание, которое нужно протестировать. Можно тестировать только модели, назначенные развертываниям.
Для многоязычных проектов выберите язык текста, который вы тестируете, из раскрывающегося списка языков.
Выберите развертывание, которое требуется запросить или протестировать, из раскрывающегося списка.
Введите текст, который требуется отправить в запросе, или отправьте документ
.txt, который требуется использовать. Если вы используете один из примеров наборов данных, можно использовать один из включенных TXT-файлов.Выберите "Запустить тест " в верхнем меню.
На вкладке Результат можно увидеть спрогнозированные классы для текста. Вы также можете просмотреть ответ JSON на вкладке JSON. Следующий пример предназначен для проекта классификации по одной метке. Проект классификации нескольких меток может возвращать в результате несколько классов.

Очистка проектов
Если проект вам больше не нужен, вы можете удалить его с помощью Студии Языка. Выберите настраиваемую классификацию текста в верхней части и выберите проект, который вы хотите удалить. Выберите "Удалить" из верхнего меню, чтобы удалить проект.
Необходимые компоненты
- Подписка Azure — создайте бесплатную учетную запись.
Создание нового ресурса языка ИИ Azure и учетной записи хранения Azure
Прежде чем использовать настраиваемую классификацию текста, необходимо создать ресурс языка искусственного интеллекта Azure, который предоставит учетные данные, необходимые для создания проекта и начала обучения модели. Кроме того, вам потребуется учетная запись хранения Azure, в которую вы отправите набор данных для создания модели.
Важно!
Чтобы быстро приступить к работе, мы рекомендуем создать новый ресурс языка искусственного интеллекта Azure, выполнив действия, описанные в этой статье, что позволит вам создать ресурс языка и создать и /или подключить учетную запись хранения одновременно, что проще, чем позже.
Если вы хотите использовать уже существующий ресурс, его нужно подключить к учетной записи хранения.
Создание ресурса на портале Azure
Перейдите к портал Azure, чтобы создать новый ресурс языка искусственного интеллекта Azure.
В появившемся окне выберите настраиваемую классификацию текста и распознавание именованных сущностей из пользовательских функций. Нажмите кнопку "Продолжить", чтобы создать ресурс в нижней части экрана.
Создайте ресурс службы "Язык" с приведенными ниже сведениями.
Имя. Обязательное значение Отток подписок Вашу подписку Azure. Группа ресурсов Группа ресурсов, которая будет содержать ваш ресурс. Можно использовать существующую группу или создать новую. Регион Один из поддерживаемых регионов. Например, "Запад США 2". Имя. Имя ресурса. Ценовая категория Одна из поддерживаемых ценовых категорий. Вы можете использовать уровень "Бесплатный" (F0), чтобы поработать со службой. Если появится сообщение Ваша учетная запись входа не является владельцем выбранной группы ресурсов учетной записи хранения, значит, ваша учетная запись должна иметь роль владельца, назначенную группе ресурсов, — только тогда вы сможете создать ресурс службы "Язык". Обратитесь за помощью к владельцу подписки Azure.
Вы можете определить владельца подписки Azure, выполнив поиск в группе ресурсов и следуя ссылке на связанную подписку. Затем:
- Выберите вкладку контроль доступа (IAM)
- Выбор назначений ролей
- Фильтрация по роли:владелец.
В разделе "Настраиваемая классификация текста" и "Распознавание именованных сущностей" выберите существующую учетную запись хранения или выберите новую учетную запись хранения. Обратите внимание, что значения для учетной записи хранения предназначены для того, чтобы помочь вам начать работу, и не обязательно должны использоваться в рабочих средах. Чтобы избежать задержек при создании проекта, подключитесь к учетным записям хранения в том же регионе, что и ресурс Языка.
Значение для учетной записи хранения Рекомендуемое значение Storage account name Любое имя Storage account type Standard LRS Убедитесь, что флажок Уведомление об ответственном применении ИИ установлен. В нижней части страницы выберите Review + create (Проверить и создать).
Отправка примера данных в контейнер BLOB-объектов
Когда вы создадите учетную запись хранения Azure и подключите ее к ресурсу службы "Язык", нужно будет отправить документы из примера набора данных в корневой каталог контейнера. Эти документы будут использоваться для обучения модели.
Скачайте пример набора данных для проектов классификации по нескольким меткам.
Откройте файл ZIP и извлеките папку с документами.
Предоставленный пример набора данных содержит около 200 документов, каждый из которых представляет собой краткое содержание фильма. Каждый документ принадлежит одному или нескольким из следующих классов:
- "Детектив"
- "Drama"
- "Триллер"
- "Комедия"
- "Боевик"
На портале Azure перейдите к созданной учетной записи хранения и выберите ее. Это можно сделать, щелкнув служба хранилища учетные записи и введя имя учетной записи хранения в фильтр для любого поля.
Если группа ресурсов не отображается, убедитесь, что фильтр "Подписка равен всем".
В учетной записи хранения в меню слева выберите Контейнеры под пунктом Хранилище данных. На появившемся экране нажмите + Контейнер. Присвойте контейнеру имя example-data и оставьте Уровень общего доступа, установленный по умолчанию.
Когда контейнер будет создан, выберите его. Затем нажмите кнопку "Отправить", чтобы выбрать
.txtскачанные ранее файлы..json
Получение ключей и конечной точки ресурса
Перейдите на страницу обзора ресурса на портале Azure
В меню слева выберите Ключи и конечная точка. Конечная точка и ключ вам понадобятся для запросов API.

Создание пользовательского проекта классификации текстов
После настройки контейнера ресурсов и хранилища создайте новый проект пользовательской классификации текстов. Проект — это рабочая область для создания настраиваемых моделей машинного обучения на основе данных. Получить доступ к вашему проекту можете только вы и другие пользователи, у которых есть доступ к используемому ресурсу службы "Язык".
Активация задания импорта проектов
Отправьте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы импортировать файл меток. Убедитесь, что файл меток соответствует допустимому формату.
Если проект с таким именем уже существует, данные этого проекта заменяются.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Узнайте больше о других доступных версиях API. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст
Используйте следующий код JSON в запросе. Замените значения заполнителей ниже собственными значениями.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Ключ. | Заполнитель | Значение | Пример |
|---|---|---|---|
| api-version | {API-VERSION} |
Версия вызываемого API. Используемая здесь версия должна совпадать с версией API в URL-адресе. Узнайте больше о других доступных версиях API. | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
| projectKind | customMultiLabelClassification |
Тип проекта. | customMultiLabelClassification |
| language | {LANGUAGE-CODE} |
Строка, указывающая код языка для документов, используемых в проекте. Если проект является многоязычным, выберите код языка большинства документов. См. дополнительные сведения о поддержке нескольких языков. | en-us |
| multilingual | true |
Логическое значение, которое позволяет иметь документы на нескольких языках в наборе данных. После развертывания модели вы можете отправить к ней запрос на любом поддерживаемом языке (не обязательно включенном в обучающие документы). См. дополнительные сведения о поддержке нескольких языков. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Имя контейнера хранилища Azure, в который вы отправили документы. | myContainer |
| Классы | [] | Массив, который содержит все классы, имеющиеся в проекте. Это классы, по которым будут классифицироваться документы. | [] |
| документов | [] | Массив, содержащий все документы в проекте и классы, помеченные для этого документа. | [] |
| Расположение | {DOCUMENT-NAME} |
Расположение документов в контейнере хранилища. Так как все документы находятся в корне контейнера, это должно быть имя документа. | doc1.txt |
| набор данных | {DATASET} |
Тестовый набор, в который будет перемещен этот документ при разделении перед обучением. Дополнительные сведения о разделении данных см. в разделе Обучение модели. Возможные значения для этого поля: Train и Test. |
Train |
После отправки запроса API вы получите ответ 202, указывающий, что задание было отправлено правильно. Извлеките значение operation-location из заголовков ответа. Оно будет иметь следующий формат:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес будет использоваться для получения состояния задания импорта.
Возможные сценарии ошибок для этого запроса:
- выбранный ресурс не имеет необходимых разрешений для учетной записи хранения;
- указанный
storageInputContainerNameне существует; - используется недопустимый код языка или тип кода языка не является строковым;
- Значение
multilingualявляется строкой, а не логическим значением.
Получение сведений о состоянии задания на импорт
Используйте следующий запрос GET, чтобы получить состояние импорта проекта. Замените значения заполнителей ниже собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{JOB-ID} |
Идентификатор для поиска состояния обучения модели. Значение заголовка location, полученное на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Узнайте больше о других доступных версиях API. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Обучение модели
Как правило, после создания проекта вы присваиваете теги документам в подключенном к проекту контейнере. В этом кратком руководстве вы импортировали пример набора данных с тегами и инициализировали проект, используя пример JSON-файла с тегами.
Начало обучения модели
После импорта проекта можно начать обучение модели.
Отправьте запрос POST, используя следующий URL-адрес, заголовки и текст JSON, чтобы отправить задание обучения. Замените значения заполнителей ниже собственными значениями.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Узнайте больше о других доступных версиях API. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте следующий код JSON в тексте запроса. После завершения обучения модель получит имя {MODEL-NAME}. Модели создаются только в результате успешных заданий обучения.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Ключ. | Заполнитель | Значение | Пример |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Имя модели, которое будет назначено ей после успешного обучения. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Это версия модели, которая будет использоваться для обучения модели. | 2022-05-01 |
| evaluationOptions | Возможность разделять данные по наборам для обучения и тестирования. | {} |
|
| kind | percentage |
Методы разделения. Возможные значения: percentage или manual. Дополнительные сведения см. в статье об обучении модели. |
percentage |
| trainingSplitPercentage | 80 |
Процент помеченных тегами данных, которые будут включены в набор для обучения. Рекомендуемое значение — 80. |
80 |
| testingSplitPercentage | 20 |
Процент помеченных тегами данных, которые будут включены в набор для тестирования. Рекомендуемое значение — 20. |
20 |
Примечание.
trainingSplitPercentage и testingSplitPercentage требуются только в том случае, если для Kind задано значение percentage, а сумма процентных значений должна быть равна 100.
После отправки запроса API вы получите ответ 202, указывающий, что задание было отправлено правильно. Извлеките значение location из заголовков ответа. Оно будет иметь следующий формат:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес позволяет получить текущее состояние обучения.
Получение состояния задания обучения
Обучение может занять от 10 до 30 минут. Следующий запрос можно использовать для регулярного опроса состояния задания обучения, пока оно не будет успешно завершено.
Используйте следующий запрос GET, чтобы получить состояние хода обучения модели. Замените значения заполнителей ниже собственными значениями.
Запросить URL-адрес
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{JOB-ID} |
Идентификатор для поиска состояния обучения модели. Значение заголовка location, полученное на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье о жизненном цикле модели. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Развертывание модели
Обычно после обучения модели изучаются сведения об оценке и вносятся необходимые улучшения. В этом кратком руководстве вы просто развернете модель и предоставите себе к ней доступ в студии службы "Язык". Можно также вызвать API прогнозирования.
Отправка задания развертывания
Отправьте запрос PUT, используя следующий URL-адрес, заголовки и текст JSON, чтобы отправить задание развертывания. Замените значения заполнителей ниже собственными значениями.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{DEPLOYMENT-NAME} |
Имя развертывания. Это значение учитывает регистр. | staging |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Узнайте больше о других доступных версиях API. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст запроса
Используйте следующий код JSON в тексте запроса. Используйте имя модели, назначаемое развертыванию.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Ключ. | Заполнитель | Значение | Пример |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Имя модели, которое будет назначено развертыванию. Имена можно назначить только успешно обученным моделям. Это значение учитывает регистр. | myModel |
После отправки запроса API вы получите ответ 202, указывающий, что задание было отправлено правильно. Извлеките значение operation-location из заголовков ответа. Оно будет иметь следующий формат:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} используется для идентификации запроса, так как эта операция является асинхронной. Этот URL-адрес можно использовать для получения состояния развертывания.
Получение состояния задания развертывания
Используйте следующий запрос GET для запроса состояния задания развертывания. Используйте URL-адрес, полученный на предыдущем шаге, или замените приведенные ниже значения заполнителей собственными значениями.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{DEPLOYMENT-NAME} |
Имя развертывания. Это значение учитывает регистр. | staging |
{JOB-ID} |
Идентификатор для поиска состояния обучения модели. Это значение находится в заголовке location, полученном на предыдущем шаге. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Узнайте больше о других доступных версиях API. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Значение |
|---|---|
Ocp-Apim-Subscription-Key |
Ключ к ресурсу. Используется для проверки подлинности запросов API. |
Текст ответа
После отправки запроса вы получите следующий ответ. Продолжайте опрос этой конечной точки до тех пор, пока значение параметра Состояние не изменится на "Выполнено". Необходимо получить код 200, указывающий на успешное выполнение запроса.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Классификация текста
Успешно развернутую модель можно начать использовать для классификации текста с помощью API прогнозирования. Загруженный ранее пример набора данных содержит некоторые тестовые документы, которые можно использовать на этом шаге.
Отправка задачи пользовательской классификации текста
Используйте этот запрос POST для запуска задачи классификации текста.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Дополнительные сведения о других доступных версиях API см. в статье Жизненный цикл модели. | 2022-05-01 |
Заголовки
| Ключ | Стоимость |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ, который предоставляет доступ к этому API. |
Текст
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Ключ. | Заполнитель | Значение | Пример |
|---|---|---|---|
displayName |
{JOB-NAME} |
Имя задания. | MyJobName |
documents |
[{},{}] | Список документов для запуска задач. | [{},{}] |
id |
{DOC-ID} |
Имя или идентификатор документа. | doc1 |
language |
{LANGUAGE-CODE} |
Строка, указывающая код языка для документа. Если этот ключ не указан, служба будет использовать язык по умолчанию проекта, выбранный во время создания проекта. Список всех поддерживаемых языков см. в статье Поддержка языков. | en-us |
text |
{DOC-TEXT} |
Задача документа, для которого будут выполняться задачи. | Lorem ipsum dolor sit amet |
tasks |
Список задач, которые мы хотим выполнить. | [] |
|
taskName |
CustomMultiLabelClassification | Имя задачи | CustomMultiLabelClassification |
parameters |
Список параметров, которые нужно передать задаче. | ||
project-name |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Имя развертывания. Это значение учитывает регистр. | prod |
Response
Вы получите ответ 202, указывающий на успешное выполнение. Извлеките значение operation-location из заголовков ответа.
operation-location имеет следующий формат:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Этот URL-адрес можно использовать для запроса состояния завершения задачи и получения результатов после ее завершения.
Получение результатов выполнения задачи
Используйте следующий запрос GET, чтобы запросить состояние или результаты задания классификации текста.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. | 2022-05-01 |
Заголовки
| Ключ | Стоимость |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ, который предоставляет доступ к этому API. |
Текст ответа
Ответ будет содержать документ JSON с приведенными ниже параметрами.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Очистка ресурсов
Если проект больше не нужен, его можно удалить с помощью следующего запроса DELETE. Замените значения заполнителей собственными значениями.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Заполнитель | Значение | Пример |
|---|---|---|
{ENDPOINT} |
Конечная точка для проверки подлинности запроса API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Имя проекта. Это значение учитывает регистр. | myProject |
{API-VERSION} |
Версия вызываемого API. Указанное здесь значение определяет последнюю выпущенную версию модели. Узнайте больше о других доступных версиях API. | 2022-05-01 |
Заголовки
Используйте следующий заголовок для проверки подлинности запроса.
| Ключ | Стоимость |
|---|---|
| Ocp-Apim-Subscription-Key | Ключ к ресурсу. Используется для проверки подлинности запросов API. |
После отправки запроса API вы получите ответ 202, означающий успешное выполнение (развертывание удалено). Ответ будет содержать заголовок Operation-Location, используемый для проверки состояния задания.
Следующие шаги
После создания модели пользовательской классификации текста можно выполнить следующие действия.
Когда вы начнете создавать собственные проекты пользовательской классификации текста, воспользуйтесь практическими руководствами, чтобы получить дополнительные сведения о разработке моделей.