Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:
![]() Nosql
Nosql
![]() Mongodb
Mongodb
![]() Гремлин
Гремлин
Внимание
Зеркальное отображение Azure Cosmos DB в Microsoft Fabric теперь доступно для API NoSql. Эта функция предоставляет все возможности Azure Synapse Link с более высокой аналитической производительностью, возможность объединения ресурсов данных с Fabric OneLake и открытие доступа к данным в формате Delta Parquet. Если вы рассматриваете Azure Synapse Link, рекомендуется попробовать зеркальное отображение для оценки общего соответствия вашей организации. Начало работы с зеркальным отображением в Microsoft Fabric.
Чтобы приступить к работе с Azure Synapse Link, посетите раздел "Начало работы с Azure Synapse Link"
Хранилище аналитических данных Azure Cosmos DB — это полностью изолированное хранилище столбцов, позволяющее выполнять крупномасштабный анализ операционных данных в Azure Cosmos DB без каких-либо последствий для транзакционных рабочих нагрузок.
Хранилище транзакций Azure Cosmos DB не зависит от схемы и позволяет выполнять итерации по транзакционным приложениям без необходимости управлять схемой или индексами. В отличие от этого, аналитическое хранилище Azure Cosmos DB разработано с целью оптимизации производительности аналитических запросов. В этой статье подробно описывается аналитическое хранилище.
Сложности крупномасштабного анализа операционных данных
Многомодельные операционные данные в контейнере Azure Cosmos DB хранятся в индексированном транзакционном хранилище на основе строк. Формат хранилища строк предназначен для ускорения операций чтения и записи транзакций при миллисекундном времени для ответа и оперативных запросов. В случае расширения набора данных выполнение больших и сложных аналитических запросов может быть дорогостоящим относительно подготовленной пропускной способности данных, сохраненных в этом формате. Высокий уровень потребления подготовленной пропускной способности, в свою очередь, влияет на производительность рабочих нагрузок транзакций, которые используются приложениями и службами в реальном времени.
Обычно для анализа больших объемов данных операционные данные извлекаются из хранилища транзакций Azure Cosmos DB и хранятся на отдельном уровне данных. Например, данные хранятся в хранилище данных или озере данных в подходящем формате. Эти данные позже используются для крупномасштабной аналитики и анализа с помощью вычислительных подсистем, таких как кластеры Apache Spark. Разделение аналитических данных от операционных данных приводит к задержкам для аналитиков, которые хотят использовать самые последние данные.
Конвейеры ETL также усложняются при обработке обновлений операционных данных по сравнению с обработкой только новых принимаемых операционных данных.
Аналитическое хранилище для столбцов
Аналитическое хранилище Azure Cosmos DB устраняет трудности и задержки, возникающие при использовании традиционных конвейеров ETL. Аналитическое хранилище Azure Cosmos DB может автоматически синхронизировать операционные данные с отдельным хранилищем столбцов. Формат хранилища столбцов подходит для выполнения крупномасштабных аналитических запросов оптимизированным образом, что приводит к сокращению задержки таких запросов.
Используя Azure Synapse Link, можно создавать решения HTAP без ETL, напрямую связываясь с аналитическим хранилищем Azure Cosmos DB из Synapse Analytics. Благодаря этому можно выполнять крупномасштабную аналитику на операционных данных почти в реальном времени.
Возможности аналитического хранилища
При включении аналитического хранилища в контейнере Azure Cosmos DB новое хранилище столбцов создается на основе операционных данных в контейнере. Это хранилище столбцов сохраняется отдельно от хранилища транзакций, ориентированного на строки для этого контейнера, в учетной записи хранения, полностью управляемой Azure Cosmos DB, во внутренней подписке. Клиентам не нужно тратить время на администрирование хранилища. Операции вставки, обновления и удаления для операционных данных автоматически синхронизируются с аналитическим хранилищем. Для синхронизации данных не требуется канал изменений или ETL.
Хранилище столбцов для аналитических рабочих нагрузок в операционных данных
Аналитические рабочие нагрузки обычно содержат агрегаты и последовательные проверки выбранных полей. Аналитическое хранилище данных хранится в основном порядке столбца, что позволяет сериализовать значения каждого поля вместе, где это применимо. Такой формат сокращает количество операций ввода-вывода, необходимых для сканирования или вычислений статистики по конкретным полям. Он значительно сокращает время отклика запросов для больших наборов данных.
Например, если рабочие таблицы имеют следующий формат:
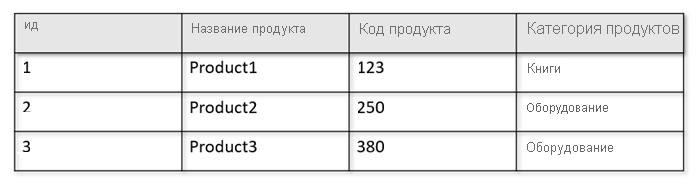
Хранилище строк сохраняет приведенные выше данные в сериализованном формате в строке на диске. Этот формат позволяет быстрее считывать транзакционные операции, записывать и операционные запросы, например "Возвращать сведения о продукте 1". Однако по мере роста набора данных и необходимости выполнять сложные аналитические запросы к данным, такие запросы могут оказаться дорогостоящими. Например, если вы хотите получить тенденции продаж для продукта в категории "Оборудование"по разным подразделениям и месяцам, необходимо выполнить сложный запрос. Крупные проверки этого набора данных могут оказаться затратными в плане подготовленной пропускной способности и могут повлиять на производительность транзакционных рабочих нагрузок, обеспечивающих работу приложений и служб в режиме реального времени.
Аналитическое хранилище, которое является хранилищем столбцов, лучше подходит для таких запросов, так как оно сериализует похожие поля данных вместе и сокращает число операций ввода-вывода на диск.
На следующем рисунке показано хранилище транзакций и хранилище аналитических столбцов в Azure Cosmos DB:
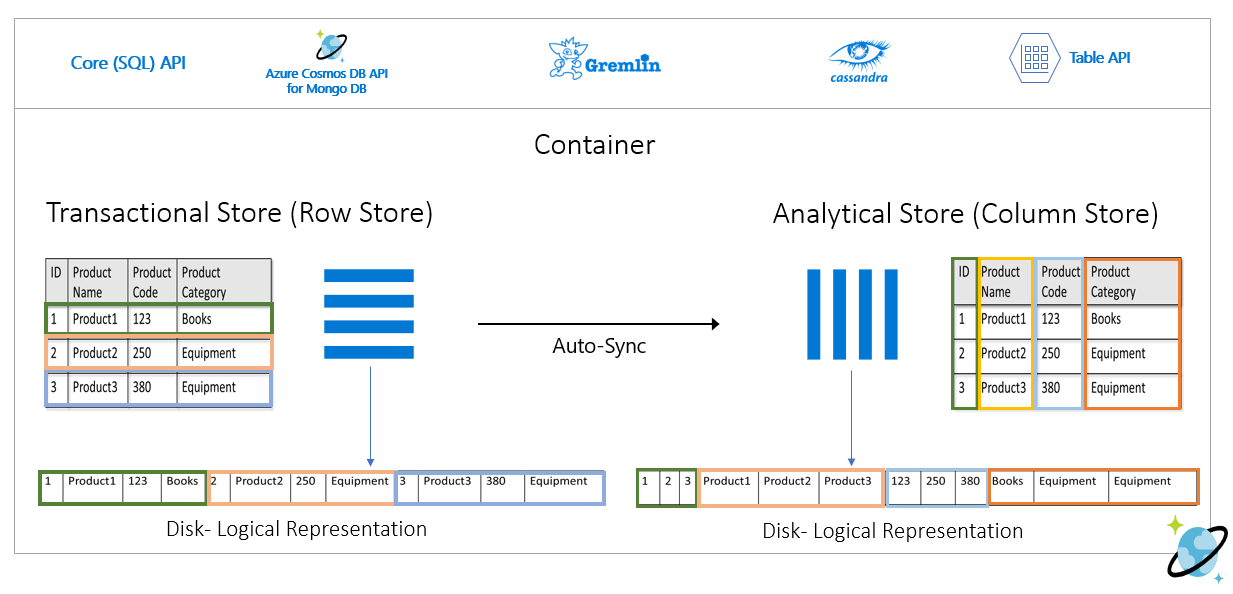
Несвязанная производительность для аналитических рабочих нагрузок
Аналитические запросы не влияют на производительность транзакционных рабочих нагрузок, так как аналитическое хранилище отделено от хранилища транзакций. Для аналитического хранилища не требуется выделять отдельные единицы запроса (ЕЗ).
Автосинхронизация
Автоматическая синхронизация — это полностью управляемая возможность Azure Cosmos DB, при которой операции вставки, обновления и удаления в операционных данных автоматически синхронизируются из хранилища транзакций в аналитическое хранилище практически в реальном времени. Задержка автоматической синхронизации обычно составляет менее 2 минут. В случае базы данных с общей пропускной способностью с большим количеством контейнеров задержка автоматической синхронизации отдельных контейнеров может быть дольше и составлять до 5 минут.
В конце каждого выполнения процесса автоматической синхронизации ваши данные о транзакциях будут немедленно доступны для сред выполнения Azure Synapse Analytics.
Пулы Spark в Azure Synapse Analytics могут считывать все данные, включая самые последние обновления, из таблиц Spark, которые обновляются автоматически, или с помощью команды
spark.read, которая всегда считывает последнее состояние данных.Бессерверные пулы SQL в Azure Synapse Analytics могут считывать все данные, включая самые последние обновления, из представлений, которые обновляются автоматически, или с помощью
SELECTи командOPENROWSET, которые всегда считывают последнее состояние данных.
Примечание.
Данные о транзакциях будут синхронизированы с аналитическим хранилищем, даже если срок жизни транзакции (TTL) меньше 2 минут.
Примечание.
Обратите внимание, что при удалении контейнера также удаляется аналитическое хранилище.
Масштабируемость и эластичность
Хранилище транзакций Azure Cosmos DB использует горизонтальное секционирование для эластичного масштабирования хранилища и пропускной способности без простоя. Горизонтальное секционирование в хранилище транзакций обеспечивает масштабируемость и эластичность при автоматической синхронизации, чтобы обеспечить синхронизацию данных с аналитическим хранилищем почти в реальном времени. Синхронизация данных выполняется независимо от объема трафика транзакций, который составляет 1000 операций/с или 1 000 000 операций/с, и не влияет на подготовленную пропускную способность в хранилище транзакций.
Автоматическая работа с обновлениями схемы
Хранилище транзакций Azure Cosmos DB не зависит от схемы и позволяет выполнять итерации по транзакционным приложениям без необходимости управлять схемой или индексами. В отличие от этого, аналитическое хранилище Azure Cosmos DB разработано с целью оптимизации производительности аналитических запросов. Благодаря возможности автоматической синхронизации Azure Cosmos DB управляет выводом схемы поверх последних обновлений из хранилища транзакций. Она также управляет готовым представлением схемы в аналитическом хранилище, которое выполняет обработку вложенных типов данных.
В случае эволюции схемы, когда со временем добавляются новые свойства, аналитическое хранилище автоматически представляет объединенную схему для всех предыдущих версий схем в хранилище транзакций.
Примечание.
В контексте аналитического хранилища мы рассматриваем следующие структуры как свойство:
- "Элементы" JSON или "пары строка-значение с разделителем
:". - Объекты JSON с разделителями
{и}. - Массивы JSON с разделителями
[и].
Ограничения схемы
Приведенные ниже ограничения применимы к операционным данным в Azure Cosmos DB при включении автоматического определения и представления схемы в аналитическом хранилище.
Вы можете иметь не более 1000 свойств во всех вложенных уровнях в схеме документов, при это глубина вложения не может превышать 127 уровней.
- В аналитическом хранилище представлены только первые 1000 свойств.
- В аналитическом хранилище представлены только первые 127 уровней вложенности.
- Первый уровень документа JSON — это его уровень корня
/. - Свойства на первом уровне документа будут представлены в виде столбцов.
Пример сценариев.
- Если первый уровень документа имеет 2000 свойств, процесс синхронизации будет представлять первые 1000 из них.
- Если в документах есть пять уровней с 200 свойствами в каждом из них, процесс синхронизации будет представлять все свойства.
- Если в документах есть 10 уровней с 400 свойствами в каждом из них, процесс синхронизации будет полностью представлять два первых уровня и только половину третьего уровня.
Приведенный ниже гипотетический документ содержит 4 свойства и 3 уровня.
- Уровнями являются
root,myArrayи вложенная структура внутриmyArray. - Свойствами являются
id,myArray,myArray.nested1иmyArray.nested2. - В представлении аналитического хранилища будет 2 столбца:
idиmyArray. С помощью функции Spark или T-SQL можно представить в виде столбцов также вложенные структуры.
- Уровнями являются
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Хотя документы JSON (и коллекции и контейнеры Azure Cosmos DB) чувствительны к регистру с точки зрения уникальности, аналитическое хранилище не является.
-
В одном документе. Имена свойств на одном уровне должны быть уникальными при сравнении без учета регистра. Например, следующий документ JSON содержит "Name" и "name" на одном и том же уровне. Хотя это допустимый документ JSON, он не удовлетворяет ограничению уникальности и поэтому не будет полностью представлен в аналитическом хранилище. В этом примере "Name" и "name" одинаковы при сравнении без учета регистра. В аналитическом хранилище будет представлен только
"Name": "fred", так как он является первым экземпляром. При этом"name": "john"не будет представлен вообще.
{"id": 1, "Name": "fred", "name": "john"}-
В других документах. Свойства на одном и том же уровне и с тем же именем, но в разных случаях будут представлены в одном столбце с использованием формата имени первого вхождения. Например, следующие документы JSON содержат
"Name"и"name"на одном и том же уровне. Так как формат первого документа —"Name", именно он будет использоваться для представления имени свойства в аналитическом хранилище. Другими словами, именем столбца в аналитическом хранилище будет"Name"."fred"и"john"будут представлены в столбце"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}-
В одном документе. Имена свойств на одном уровне должны быть уникальными при сравнении без учета регистра. Например, следующий документ JSON содержит "Name" и "name" на одном и том же уровне. Хотя это допустимый документ JSON, он не удовлетворяет ограничению уникальности и поэтому не будет полностью представлен в аналитическом хранилище. В этом примере "Name" и "name" одинаковы при сравнении без учета регистра. В аналитическом хранилище будет представлен только
В первом документе коллекции определена схема первоначального аналитического хранилища.
- Документы, содержащие больше свойств по сравнению с исходной схемой, создадут новые столбцы в аналитическом хранилище.
- Удалить столбцы невозможно.
- Удаление всех документов в коллекции не приводит к сбросу схемы аналитического хранилища.
- Управление версиями схем отсутствует. В аналитическом хранилище вы увидите последнюю версию, выводимую из хранилища транзакций.
В настоящее время Azure Synapse Spark не может считывать свойства, имена которых содержат перечисленные ниже специальные знаки. На бессерверный Azure Synapse SQL это не влияет.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
Примечание.
Пробелы также указаны в сообщении об ошибке Spark, возвращаемом при достижении этого ограничения. Но мы добавили специальную обработку для пробелов. Ознакомьтесь с дополнительными сведениями в пунктах ниже.
- Если у вас есть имена свойств, используя указанные выше символы, альтернативные варианты:
- Заранее измените модель данных, чтобы избежать этих символов.
- Так как в настоящее время мы не поддерживаем сброс схемы, вы можете изменить приложение, чтобы добавить избыточное свойство с похожим именем без таких символов.
- С помощью канала изменений создайте материализованное представление контейнера без этих символов в именах свойств.
- Используйте параметр Spark
dropColumn, чтобы проигнорировать затронутые столбцы и загрузить все остальные столбцы в DataFrame. Синтаксис:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Azure Synapse Spark теперь поддерживает свойства с пробелами в именах. Для этого необходимо использовать параметр Spark
allowWhiteSpaceInFieldNamesдля загрузки затронутых столбцов в DataFrame, сохраняя исходное имя. Синтаксис:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
Следующие типы данных BSON не поддерживаются и не будут представлены в аналитическом хранилище:
- Десятичная 128
- Регулярное выражение
- Указатель базы данных
- JavaScript
- Символ
- МинКлюч/МаксКлюч
При использовании строк даты и времени, соответствующих стандарту ISO 8601 UTC, следует ожидать следующее поведение:
- Пулы Spark в Azure Synapse представляют эти столбцы как
string. - Бессерверные пулы SQL в Azure Synapse представляют эти столбцы как
varchar(8000).
- Пулы Spark в Azure Synapse представляют эти столбцы как
Свойства с типами
UNIQUEIDENTIFIER (guid)представлены какstringв аналитическом хранилище и для правильной визуализации должны быть преобразованы вVARCHAR(в SQL) или вstring(в Spark).Бессерверные пулы SQL в Azure Synapse поддерживают результирующие наборы с количеством столбцов не более 1000. Предоставляемые вложенные столбцы также учитываются в этом ограничении. Рекомендуется рассмотреть эту информацию в архитектуре и моделировании транзакционных данных.
Если переименовать свойство в одном или многих документах, оно будет считаться новым столбцом. Если выполнить одно и то же переименование во всех документах в коллекции, все данные будут перенесены в новый столбец, а старый столбец будет представлен значениями
NULL.
Представление схемы
Существует два метода представления схемы в аналитическом хранилище, допустимый для всех контейнеров в учетной записи базы данных. Они имеют компромиссы между простотой взаимодействия с запросом и удобством более инклюзивного представления столбцов для полиморфных схем.
- Четко определенное представление схемы, параметр по умолчанию для учетных записей API для NoSQL и Gremlin.
- Полное представление схемы точности, параметр по умолчанию для учетных записей API для MongoDB.
Четко определенное представление схемы
Четко определенное представление схемы создает простое табличное представление данных, не зависящих от схемы, в хранилище транзакций. Четко определенное представление схемы имеет следующие факторы.
- Первый документ определяет базовую схему и свойства всегда должны иметь одинаковый тип во всех документах. Единственными исключениями являются:
- Для бессерверных пулов SQL в Azure Synapse: от
NULLдо любого другого типа данных. Первый экземпляр, не имеющий значение NULL, определяет тип данных столбца. Любой документ с типом данных, где первое вхождение не отлично от NULL, не будет представлен в аналитическом хранилище. - Для пулов Spark и функции отслеживания изменений данных в Azure Data Factory в Azure Synapse: от
NULLдоINT. Эволюция от значений NULL к типам данных, отличным от INT, не поддерживается для пулов Spark и регистрации изменений данных в Azure Data Factory в Azure Synapse. Первое ненулевое значение должно быть целым числом, и любой документ с другим типом данных не будет представлен в аналитическом хранилище. - С
floatнаinteger. Все документы представлены в аналитическом хранилище. - С
integerнаfloat. Все документы представлены в аналитическом хранилище. Но чтобы прочитать эти данные с помощью бессерверных пулов SQL в Azure Synapse, необходимо использовать предложение WITH для преобразования столбца вvarchar. После этого первоначального преобразования можно снова преобразовать его в число. Посмотрите пример ниже, где первоначальное значение num было целым числом, а второе — float.
- Для бессерверных пулов SQL в Azure Synapse: от
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Свойства, которые не соответствуют типу данных базовой схемы, не будут представлены в аналитическом хранилище. Например, рассмотрим два документа, приведенных ниже. Первый из них определяет базовую схему аналитического хранилища. Второй документ, где
id— это"2", не имеет четко определенной схемы, поскольку свойство"code"— это строка, а в первом документе"code"— это число. В этом случае аналитическое хранилище регистрирует тип данных"code"какintegerна время существования контейнера. Второй документ будет по-прежнему включен в аналитическое хранилище, но его свойство"code"включено не будет.{"id": "1", "code":123}{"id": "2", "code": "123"}
Примечание.
Указанное выше условие не применяется к свойствам со значением NULL. Например, {"a":123} and {"a":NULL} по-прежнему четко определено.
Примечание.
При обновлении "code" документа "1" до строки в транзакционном хранилище условие выше не меняется. В аналитическом хранилище "code" будет храниться как integer, поскольку в настоящее время мы не поддерживаем сброс схемы.
- Типы массивов должны содержать один повторяющийся тип. Например,
{"a": ["str",12]}не является четко определенной схемой, так как массив содержит сочетание целочисленных и строковых типов.
Примечание.
Если аналитическое хранилище Azure Cosmos DB соответствует представлению четко определенной схемы, а приведенная выше спецификация нарушается определенными элементами, эти элементы не будут включаться в аналитическое хранилище.
В отношении разных типов четко определенной схемы реализуется другое поведение:
- Пулы Spark в Azure Synapse представляют эти значения как
undefined. - Бессерверные пулы SQL в Azure Synapse представляют эти значения как
NULL.
- Пулы Spark в Azure Synapse представляют эти значения как
В отношении явных значений
NULLтребуется другое поведение:- Пулы Spark в Azure Synapse считывают эти значения как
0(ноль) и какundefinedтолько столбец имеет значение, отличное от NULL. - Бессерверные пулы SQL в Azure Synapse считывают эти значения как
NULL.
- Пулы Spark в Azure Synapse считывают эти значения как
В отношении отсутствующих значений требуется другое поведение:
- Пулы Spark в Azure Synapse представляют эти столбцы как
undefined. - Бессерверные пулы SQL в Azure Synapse представляют эти столбцы как
NULL.
- Пулы Spark в Azure Synapse представляют эти столбцы как
Обходные решения для репрезентативных задач
Возможно, старый документ с неправильной схемой использовался для создания базовой схемы аналитического хранилища контейнера. На основе всех правил, представленных выше, вы можете получить NULL определенные свойства при запросе аналитического хранилища с помощью Azure Synapse Link. Удаление или обновление проблемных документов не поможет, так как сброс базовой схемы в настоящее время не поддерживается. Возможные решения:
- Чтобы перенести данные в новый контейнер, убедитесь, что все документы имеют правильную схему.
- Чтобы отказаться от свойства с неправильной схемой и добавить новый с другим именем, который имеет правильную схему во всех документах. Пример. У вас есть миллиарды документов в контейнере Orders , где свойство состояния является строкой. Но первый документ в этом контейнере имеет состояние , определенное целым числом. Таким образом, один документ будет иметь правильно представленный статус , и все остальные документы будут иметь
NULL. Вы можете добавить свойство status2 ко всем документам и начать использовать его вместо исходного свойства.
Представление схемы с полной достоверностью
Представление схемы с полной достоверностью предназначено для работы с полноценными схемами полиморфизма в рабочих данных, не зависящих от схемы. В этом представлении схемы элементы не удаляются из аналитического хранилища, даже если нарушаются четко определенные ограничения схемы (не являющиеся полями или массивами смешанных типов данных).
Это достигается путем преобразования конечных свойств операционных данных в аналитическое хранилище в виде пар JSONkey-value, где тип данных — это key и содержимое свойства .value Это представление объекта JSON позволяет выполнять запросы без неоднозначности и анализировать каждый тип данных по отдельности.
Другими словами, в полном представлении схемы точности каждый тип данных каждого свойства каждого документа создаст key-valueпару в объекте JSON для этого свойства. Каждое из них подсчитывается как одно из максимального ограничения свойств 1000.
Например, рассмотрим пример документа в хранилище транзакций.
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
Вложенный объект address является свойством в корневом уровне документа и будет представлен в виде столбца. Каждое конечное свойство в объекте address будет представлено как объект JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}
В отличие от четко определенного представления схемы, метод полной точности позволяет использовать варианты типов данных. Если следующий документ в этой коллекции приведенного выше примера имеет streetNo строку, он будет представлен в аналитическом хранилище как "streetNo":{"string":15850}. В хорошо определенном методе схемы он не будет представлен.
Сопоставление типов данных для полной схемы точности
Ниже приведена карта типов данных MongoDB и их представления в аналитическом хранилище в полном представлении схемы точности. Приведенная ниже карта не является допустимой для учетных записей API NoSQL.
| Тип исходных данных | Суффикс | Пример |
|---|---|---|
| Двойной | ".float64" | 24,99 |
| Массив | .array | ["a", "b"] |
| Бинарный | ".binary" | 0 |
| Логический | .Bool | Истина |
| Int32 | .int32" | 123 |
| Int64 | .int64" | 255486129307 |
| Отсутствует | ". NULL" | Отсутствует |
| Строка | ".string" | ABC |
| Метка времени | ".timestamp" | Метка времени(0, 0) |
| ObjectId (идентификатор объекта) | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Документ | «.object» | {"a": "a"} |
В отношении явных значений
NULLтребуется другое поведение:- Пулы Spark в Azure Synapse будут считывать эти значения как
0(ноль). - Бессерверные пулы SQL в Azure Synapse будут считывать эти значения как
NULL.
- Пулы Spark в Azure Synapse будут считывать эти значения как
В отношении отсутствующих значений требуется другое поведение:
- Пулы Spark в Azure Synapse будут представлять эти столбцы как
undefined. - Бессерверные пулы SQL в Azure Synapse будут представлять эти столбцы как
NULL.
- Пулы Spark в Azure Synapse будут представлять эти столбцы как
Ожидается другое поведение в отношении значений
timestamp:- Пулы Spark в Azure Synapse считывают эти значения как
TimestampType,DateTypeилиFloat. Он зависит от диапазона и способа создания метки времени. - Бессерверные пулы SQL Server в Azure Synapse будут считывать эти значения, начиная
DATETIME2от0001-01-01времени9999-12-31. Значения за пределами этого диапазона не поддерживаются и вызывают сбой выполнения запросов. Если это ваш случай, вы можете:- Удалите столбец из запроса. Чтобы сохранить представление, можно создать новое зеркальное отображение этого столбца свойств, но в поддерживаемом диапазоне. И используйте его в запросах.
- Для преобразования и загрузки данных в новый формат в одном из поддерживаемых приемников используйте сбор данных из аналитического хранилища без затрат на ЕЗ.
- Пулы Spark в Azure Synapse считывают эти значения как
Использование полной схемы точности с Spark
Spark будет управлять каждым типом данных в качестве столбца при загрузке в объект DataFrame. Предположим, что коллекция с приведенными ниже документами.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Хотя первый документ имеет число и rating в формате UTC, второй документ имеет timestamprating и timestamp в виде строк. Предположим, что эта коллекция была загружена без DataFrame преобразования данных, выходные данные этого df.printSchema() объекта:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
В четко определенном представлении rating схемы оба и timestamp второй документ не будут представлены. В полной схеме точности можно использовать следующие примеры для индивидуального доступа к каждому значению каждого типа данных.
В приведенном ниже примере можно использовать PySpark для выполнения агрегирования:
df.groupBy(df.item.string).sum().show()
В приведенном ниже примере можно использовать PySQL для выполнения другой статистической обработки:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Использование полной схемы точности с SQL
В следующем примере синтаксиса можно использовать те же документы, что и в приведенном выше примере Spark:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Вы можете реализовать преобразования с помощью castconvert любой другой функции T-SQL для управления данными. Можно также скрыть сложные структуры типов данных с помощью представлений.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
Работа с полем MongoDB _id
Поле MongoDB _id является фундаментальным для каждой коллекции в MongoDB и изначально имеет шестнадцатеричное представление. Как видно из приведенной выше таблицы, полная схема точности сохранит ее характеристики, создавая задачу для визуализации в Azure Synapse Analytics. Для правильной визуализации необходимо преобразовать тип данных _id, как показано ниже:
Работа с полем MongoDB _id в Spark
Приведенный ниже пример работает в версиях Spark 2.x и 3.x:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
Работа с полем MongoDB _id в SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
Работа с полем MongoDB id
Свойство id в контейнерах MongoDB автоматически переопределяется с помощью представления свойства Base64 свойства "_id" в аналитическом хранилище. Поле "id" предназначено для внутреннего использования приложениями MongoDB. В настоящее время единственным решением является переименование свойства "id" в то, что отличается от "id".
Полная схема точности для учетных записей API для NoSQL или Gremlin
Можно использовать полную схему точности для учетных записей API для NoSQL вместо параметра по умолчанию, задав тип схемы при включении Synapse Link в учетной записи Azure Cosmos DB в первый раз. Ниже приведены рекомендации по изменению типа представления схемы по умолчанию.
- В настоящее время если включить Synapse Link в учетной записи API NoSQL с помощью портал Azure, она будет включена как хорошо определенная схема.
- В настоящее время, если вы хотите использовать полную схему точности с учетными записями API NoSQL или Gremlin, необходимо задать ее на уровне учетной записи в той же команде CLI или PowerShell, которая будет включать Synapse Link на уровне учетной записи.
- В настоящее время Azure Cosmos DB для MongoDB несовместим с этой возможностью изменения представления схемы. Все учетные записи MongoDB имеют полный тип представления схемы.
- Сопоставление типов данных схемы Full Fidelity, указанное выше, недопустимо для учетных записей API NoSQL, использующих типы данных JSON. В качестве примера
floatиintegerзначения представлены какnumв аналитическом хранилище. - Невозможно сбросить тип представления схемы, от четко определенного до полной точности или наоборот.
- В настоящее время схемы контейнеров в аналитическом хранилище определяются при создании контейнера, даже если Synapse Link не включено в учетной записи базы данных.
- Контейнеры или графы, созданные до включения Synapse Link с полной схемой точности на уровне учетной записи, будут иметь хорошо определенную схему.
- Контейнеры или графы, созданные после включения Synapse Link с полной схемой точности на уровне учетной записи, будут иметь полную схему точности.
Необходимо принять решение о типе представления схемы вместе с включением Synapse Link в учетной записи с помощью Azure CLI или PowerShell.
С помощью Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Примечание.
В приведенной выше команде замените create на update для существующих учетных записей.
С помощью PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Примечание.
В приведенной выше команде замените New-AzCosmosDBAccount на Update-AzCosmosDBAccount для существующих учетных записей.
Аналитический срок жизни (TTL)
Аналитический срок жизни (ATTL) указывает, как долго данные должны храниться в аналитическом хранилище для контейнера.
Аналитическое хранилище включено, если для значения ATTL установлено значение, отличающееся от NULL и 0. После его включения операции вставки, обновления и удаления в операционных данных автоматически синхронизируются из хранилища транзакций в аналитическое хранилище независимо от конфигурации для срока жизни транзакций. Хранением этих данных о транзакциях в аналитическом хранилище можно управлять на уровне контейнера, указав свойство AnalyticalStoreTimeToLiveInSeconds.
Возможные конфигурации ATTL:
Если задано
0значение: аналитическое хранилище отключено и данные не реплицируются из хранилища транзакций в аналитическое хранилище. Откройте вариант поддержки, чтобы отключить аналитическое хранилище в контейнерах.Если поле опущено, ничего не происходит, а предыдущее значение сохраняется.
Если задано значение
-1: аналитическое хранилище сохраняет все исторические данные независимо от хранения данных в хранилище транзакций. Этот параметр указывает на бесконечное время хранения операционных данных в аналитическом хранилище.Если задано любое положительное целое число
n: срок хранения элементов в аналитическом хранилище истечет черезnсекунд после их последнего изменения в хранилище транзакций. Этот параметр можно использовать, если требуется сохранить операционные данные в течение ограниченного периода времени в аналитическом хранилище независимо от хранения данных в хранилище транзакций
Учитывайте следующие факторы.
- После активации аналитического хранилища с заданным значением ATTL, это значение можно обновить до другого допустимого значения позднее.
- Хотя параметр TTTL можно установить на уровне контейнера или элемента, ATTL можно задать только на уровне контейнера.
- Длительное хранение операционных данных в аналитическом хранилище можно обеспечить, задав ATTL >= TTTL на уровне контейнера.
- Аналитическое хранилище может быть создано для зеркалирования хранилища транзакций путем установки ATTL равным TTTL.
- Если ATTL больше TTTL, через некоторое время вы будете иметь только данные из аналитического хранилища. Эти данные доступны только для чтения.
- В настоящее время мы не удаляем данные из аналитического хранилища. Если вы настроили atTL на любое положительное целое число, данные не будут включены в запросы, и вы не будете выставляться за него. Но если вы измените ATTL обратно
-1, все данные будут отображаться снова, вы начнете выставляться за весь объем данных.
Сведения о том, как включить аналитическое хранилище в контейнере.
На портале Azure для параметра ATTL (если он включен) устанавливается значение по умолчанию -1. Это значение можно изменить на "n" секунд, перейдя к параметрам контейнера в разделе "Обозреватель данных".
В пакете SDK для управления Azure, пакетах SDK для Azure Cosmos DB, PowerShell или интерфейсе командной строки Azure можно включить параметр ATTL, задав для него значение -1 или "n" секунд.
Дополнительные сведения см. в разделе Настройка аналитического времени жизни для контейнера.
Экономичный анализ исторических данных
Распределение данных по уровням означает разделение данных между инфраструктурами хранилища, оптимизированными для различных сценариев. Таким образом повышается общая производительность и экономичность всего стека данных. С помощью аналитического хранилища Azure Cosmos DB теперь поддерживается автоматическое распределение данных из хранилища транзакций в аналитическое хранилище с различными макетами данных. При использовании аналитического хранилища, оптимизированного с точки зрения стоимости хранилища по сравнению с хранилищем транзакций, можно хранить более длинные горизонты операционных данных для исторического анализа.
После включения аналитического хранилища в зависимости от потребностей хранения данных транзакционных рабочих нагрузок можно настроить свойство "время жизни в хранилище транзакций" (transactional TTL), чтобы записи автоматически удалялись из хранилища транзакций по истечении определенного периода времени. Аналогично, "время жизни в аналитическом хранилище" (analytical TTL) позволяет управлять жизненным циклом данных, хранимых в аналитическом хранилище, которое не зависит от хранилища транзакций. Включив аналитическое хранилище и настроив свойства TTL для транзакционного и аналитического хранилищ, можно эффективно распределять данные и определять срок их хранения для двух хранилищ.
Примечание.
Если analytical TTL задано значение, превышающее transactional TTL значение, контейнер будет иметь данные, которые существуют только в аналитическом хранилище. Эти данные доступны только для чтения, и в настоящее время мы не поддерживаем TTL на уровне документов в аналитическом хранилище. Если для данных контейнера может потребоваться обновление или удаление в определенный момент времени, не используйте значение analytical TTL больше transactional TTL. Эта возможность рекомендуется для данных, которые не будут нуждаться в обновлениях или удалениях в будущем.
Примечание.
Если ваш сценарий не требует физического удаления, можно применить подход с логическим удалением или обновлением. Вставьте в хранилище транзакций другую версию того же документа, которая существует только в аналитическом хранилище, но требует логического удаления или обновления. Эта версия может иметь флаг, указывающий, что это удаление или обновление документа с истекшим сроком. Обе версии одного документа будут совместно существовать в аналитическом хранилище, при этом приложение должно учитывать только последнюю версию.
Устойчивость
Аналитическое хранилище использует службу хранилища Azure и обеспечивает следующую защиту от физического сбоя:
- По умолчанию учетные записи базы данных Azure Cosmos DB выделяют аналитическое хранилище в учетных записях локально избыточного хранилища (LRS). LRS обеспечивает устойчивость объектов как минимум на уровне 99,999999999 % (11 девяток) в течение заданного года.
- Если для зоны настроена георегиональная учетная запись базы данных, она выделяется в учетных записях, избыточных между зонами (ZRS). Необходимо включить Зоны доступности в регионе учетной записи базы данных Azure Cosmos DB, чтобы иметь аналитические данные этого региона, хранящегося в хранилище, избыточном между зонами. ZRS обеспечивает устойчивость ресурсов хранилища как минимум на уровне 99,9999999999 % (12 девяток) в течение определенного года.
Дополнительные сведения о устойчивости служба хранилища Azure см. в этой ссылке.
Резервное копирование
Хотя аналитическое хранилище имеет встроенную защиту от физических сбоев, для случайного удаления или обновления в хранилище транзакций может потребоваться резервное копирование. В таких случаях вы можете восстановить контейнер и использовать восстановленный контейнер для заполнения данных в исходном контейнере или полностью перестроить аналитическое хранилище (при необходимости).
Примечание.
В настоящее время для аналитического хранилища не выполняется резервное копирование, поэтому его невозможно восстановить. Учитывайте это при планировании политики резервного копирования.
Synapse Link и, следовательно, аналитическое хранилище имеют разные уровни совместимости с режимами резервного копирования Azure Cosmos DB:
- Режим периодичного резервного копирования полностью совместим с Synapse Link, и эти 2 функции можно использовать в одной учетной записи базы данных.
- Synapse Link для учетных записей баз данных с использованием режима непрерывного резервного копирования — это общедоступная версия.
- Режим непрерывного резервного копирования для учетных записей с поддержкой Synapse Link находится в общедоступной предварительной версии. В настоящее время невозможно выполнить миграцию в непрерывную резервную копию, если вы отключили Synapse Link в любой из коллекций в учетной записи Cosmos DB.
Политики резервного копирования
Существуют две возможные политики резервного копирования и понять, как их использовать, следующие сведения о резервных копиях Azure Cosmos DB очень важны:
- Исходный контейнер восстанавливается без аналитического хранилища в обоих режимах резервного копирования.
- Azure Cosmos DB не поддерживает перезапись контейнеров из восстановления.
Теперь давайте посмотрим, как использовать резервное копирование и восстановление при наличии аналитического хранилища.
Восстановление контейнера в случае, когда TTTL >= ATTL
Если значение transactional TTL равно или больше analytical TTL, все данные в аналитическом хранилище сохраняются в транзакционном хранилище. В случае восстановления возможны две ситуации:
- С использованием восстановленного контейнера в качестве замены исходного контейнера. Чтобы перестроить аналитическое хранилище, просто включите Synapse Link на уровне учетной записи и на уровне контейнера.
- С использованием восстановленного контейнер в качестве источника данных для заполнения или обновления данных в исходном контейнере. В этом случае аналитическое хранилище будет автоматически отражать операции с данными.
Восстановление контейнера в случае, когда TTTL < ATTL
Если значение transactional TTL меньше analytical TTL, некоторые данные существуют только в аналитическом хранилище и не будут доступны в восстановленном контейнере. Опять же, у вас есть две возможные ситуации:
- С использованием восстановленного контейнера в качестве замены исходного контейнера. В этом случае при включении Synapse Link на уровне контейнера в новое аналитическое хранилище будут включены только данные, которые находились в хранилище транзакций. Но обратите внимание, что аналитическое хранилище исходного контейнера остается доступным для запросов до тех пор, пока существует исходный контейнер. Возможно, вам потребуется изменить приложение, чтобы отправлять запросы к обоим хранилищам.
- С использованием восстановленного контейнер в качестве источника данных для резервного заполнения или обновления данных в исходном контейнере:
- Аналитическое хранилище автоматически отражает операции с данными, которые хранятся в транзакционном хранилище.
- При повторной вставке данных, которые ранее были удалены из хранилища транзакций вследствие
transactional TTL, эти данные будут дублироваться в аналитическом хранилище.
Пример:
- Для контейнера
OnlineOrdersзадано значение TTTL, равное одному месяцу, а ATTL — одному году. - Если восстановить его до
OnlineOrdersNewи включить аналитическое хранилище для его перестройки, в хранилище транзакций и аналитическом хранилище будут присутствовать данные только за один месяц. - Исходный контейнер
OnlineOrdersне удаляется, а его аналитическое хранилище остается доступным. - Новые данные принимаются только в
OnlineOrdersNew. - Аналитические запросы выполнят операцию UNION ALL из аналитических хранилищ, пока исходные данные еще актуальны.
Если вы хотите удалить исходный контейнер, но не хотите потерять данные из его аналитического хранилища, вы можете сохранить аналитическое хранилище исходного контейнера в другой службе данных Azure. Synapse Analytics может выполнять операции объединения для данных, сохраненных в разных расположениях. Пример. Запрос Synapse Analytics объединяет данные аналитического хранилища с внешними таблицами в Хранилище BLOB-объектов Azure, Azure Data Lake Store и т. д.
Важно отметить, что данные в аналитическом хранилище имеют схему, отличную от схемы, которая существует в хранилище транзакций. Хотя вы можете без затрат на выполнение запросов создавать моментальные снимки данных своего аналитического хранилища и экспортировать их в любую службу данных Azure, мы не можем гарантировать использование этих моментальных снимков для передачи данных обратно в хранилище транзакций. Этот процесс не поддерживается.
Глобальное распределение
Если вы используете глобально распределенную учетную запись Azure Cosmos DB, после включения аналитического хранилища для контейнера он будет доступен во всех регионах этой учетной записи. Любые изменения в операционных данных глобально реплицируются во всех регионах. Это позволяет эффективно выполнять аналитические запросы по отношению к ближайшей региональной копии данных в Azure Cosmos DB.
Секционирование
Секционирование аналитического хранилища никак не зависит от секционирования в хранилище транзакций. По умолчанию данные в аналитическом хранилище не секционируются. Если в аналитических запросах есть часто используемые фильтры, вы можете применить секционирование по значениям этих полей, чтобы повысить производительность таких запросов. Дополнительные сведения см. в статьях о настраиваемом секционировании и настройке настраиваемого секционирования.
Безопасность
Проверка подлинности с помощью аналитического хранилища . Поддерживаемые методы проверки подлинности зависят от того, включены ли сетевые функции.
Проверка подлинности на основе ключей. Этот сценарий поддерживается для всех учетных записей во всех сценариях, в том числе без поддержки частных конечных точек или виртуальной сети.
Служебная учетная запись или управляемое удостоверение: Использование проверки подлинности Entra Id или управляемого удостоверения поддерживается только для учетных записей, которые не используют частные конечные точки или включают доступ к виртуальной сети. Чтобы использовать этот тип проверки подлинности, пользователи должны применить RBAC уровня данных и создать новую роль с правами только для чтения с перечисленными ниже действиями с данными.
- Добавьте настраиваемую роль MyAnalyticsReadOnlyRole с помощью PowerShell и сопоставьте действия RBAC "readMetadata" и "readAnalytics" с ролью.
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- Перечислите определения ролей учетной записи, чтобы получить новый идентификатор определения роли.
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- Создайте назначение роли, назначив новую роль субъекту Synapse MSI.
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
Сетевая изоляция с использованием частных конечных точек. Сетевым доступом к данным в транзакционных хранилищах и хранилищах аналитических данных можно управлять независимо друг от друга. Сетевая изоляция выполняется с помощью отдельных управляемых частных конечных точек для каждого хранилища в пределах управляемых виртуальных сетей в рабочих областях Azure Synapse. Дополнительные сведения см. в статье Настройка частных конечных точек для хранилища аналитических данных. Примечание. При включении этой проверки подлинности необходимо использовать проверку подлинности на основе ключей. См. предыдущий раздел.
Шифрование неактивных данных — шифрование аналитического хранилища включено по умолчанию.
Шифрование с использованием ключей, управляемых клиентом. Можно легко автоматически и прозрачно шифровать данные в транзакционных хранилищах и хранилищах аналитических данных, используя одни и те же ключи, управляемые клиентом. Azure Synapse Link поддерживает только настройку ключей, управляемых клиентом, с помощью управляемого удостоверения учетной записи Azure Cosmos DB. Вам нужно настроить управляемое удостоверение учетной записи в политике доступа Azure Key Vault до того, как вы включите Azure Synapse Link в своей учетной записи. Дополнительные сведения см. в статье Настройка ключей, управляемых клиентом, с помощью управляемых удостоверений учетных записей Azure Cosmos DB.
Примечание.
Если вы изменяете учетную запись базы данных с первой стороны на системную или назначенную пользователем identy и включите Azure Synapse Link в учетной записи базы данных, вы не сможете вернуться к удостоверению первой стороны, так как не удается отключить Synapse Link из учетной записи базы данных.
Поддержка нескольких сред выполнения Azure Synapse Analytics
Аналитическое хранилище оптимизировано для обеспечения масштабируемости, эластичности и производительности для аналитических рабочих нагрузок без какой-либо зависимости от времени выполнения вычислений. Технология хранения самостоятельно оптимизирует рабочие нагрузки аналитики без вмешательства вручную.
Данные в аналитическом хранилище Azure Cosmos DB можно запрашивать одновременно из разных сред выполнения аналитики, поддерживаемых Azure Synapse Analytics. Azure Synapse Analytics поддерживает Apache Spark и бессерверный пул SQL с аналитическим хранилищем Azure Cosmos DB.
Примечание.
Чтение данных из аналитического хранилища можно выполнять только с помощью среды выполнения Azure Synapse Analytics. Верно и обратное: среда выполнения Azure Synapse Analytics может считывать данные только из аналитического хранилища. Только процесс автоматической синхронизации может изменять данные в аналитическом хранилище. Вы можете записывать данные обратно в хранилище транзакций Azure Cosmos DB с помощью пула Azure Synapse Analytics Spark с помощью встроенного пакета SDK OLTP для Azure Cosmos DB.
Цены
Аналитическое хранилище соответствует модели ценообразования на основе потребления, в которой вы платите за:
Хранилище — объем данных, хранящихся в аналитическом хранилище в течение месяца, включая исторические данные в соответствии с аналитическим TTL.
Аналитические операции записи: полностью управляемая синхронизация обновлений операционных данных в хранилище транзакций (автоматическая синхронизация).
Аналитические операции чтения: операции чтения, выполняемые для аналитического хранилища из сред выполнения пула Spark в Azure Synapse Analytics и бессерверного пула SQL.
Цены на аналитическое хранилище определяются отдельно от модели ценообразования для хранилища транзакций. В аналитическом хранилище нет понятия подготовленных ЕЗ. Подробные сведения о модели ценообразования для аналитического хранилища см. на странице цен для Azure Cosmos DB.
Доступ к данным в аналитическом хранилище можно получить только с помощью Azure Synapse Link, что выполняется в средах выполнения Azure Synapse Analytics: пулы Azure Synapse Apache Spark и бессерверные пулы SQL Azure Synapse. Подробные сведения о модели ценообразования для доступа к данным аналитического хранилища см. на странице цен для Azure Synapse Analytics.
Чтобы получить общую оценку затрат для включения аналитического хранилища для контейнера Azure Cosmos DB с точки зрения аналитического хранилища, можно воспользоваться планировщиком ресурсов Azure Cosmos DB и получить оценку затрат на аналитическое хранилище и операции записи.
Оценки операций чтения аналитического хранилища не включаются в калькулятор затрат Azure Cosmos DB, так как они являются функцией аналитической рабочей нагрузки. Но как высокоуровневая оценка, сканирование 1 ТБ данных в аналитическом хранилище обычно приводит к 130 000 аналитических операций чтения и приводит к стоимости $ 0,065. Например, если вы используете бессерверные пулы SQL Azure Synapse для выполнения этой проверки 1 ТБ, это будет стоить $ 5,00 в соответствии со страницей цен Azure Synapse Analytics. Окончательная общая стоимость этого сканирования на 1 ТБ будет $ 5,065.
Хотя приведенная выше оценка относится к сканированию 1 ТБ данных в аналитическом хранилище, применение фильтров уменьшает объем сканируемых данных, и это определяет точное количество аналитических операций чтения для модели ценообразования с тарификацией по мере использования. Подтверждение концепции для аналитической рабочей нагрузки позволит более точно оценить аналитические операции чтения. Эта оценка не включает затраты на Azure Synapse Analytics.
Следующие шаги
Дополнительные сведения см. в следующих документах: