Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:
![]() NoSQL
NoSQL
![]() Mongodb
Mongodb
![]() Кассандра
Кассандра
![]() Гремлин
Гремлин
![]() Таблица
Таблица
Azure Cosmos DB является базовой службой Azure, поэтому она развернута во всех регионах Azure по всему миру, включая общедоступные, национальные облака, облака Министерства обороны (DOD) и государственных организаций.
На высоком уровне данные контейнера Azure Cosmos DB являются горизонтально секционированными на несколько наборов реплик, которые реплицируют операции записи, в каждом регионе. Наборы реплик надежно фиксируют операции записи с помощью кворума большинства.
Каждый регион содержит все части данных контейнера Azure Cosmos DB и может выполнять операции чтения, а также операции записи при включенной функции записи в нескольких регионах. Если ваша учетная запись Azure Cosmos DB распределена по регионам N Azure, будут по крайней мере N x 4 копии всех данных.
В центре обработки данных мы развертываем и управляем службой Azure Cosmos DB на больших группах машин, каждая из которых имеет выделенное локальное хранилище. В центре обработки данных Azure Cosmos DB развертывается во многих кластерах, каждый из которых потенциально запускает несколько поколений оборудования. Компьютеры в кластере обычно распределяются между 10–20 доменами сбоя для обеспечения высокой доступности в пределах региона. На следующем рисунке показана топология глобальной системы распространения Azure Cosmos DB:
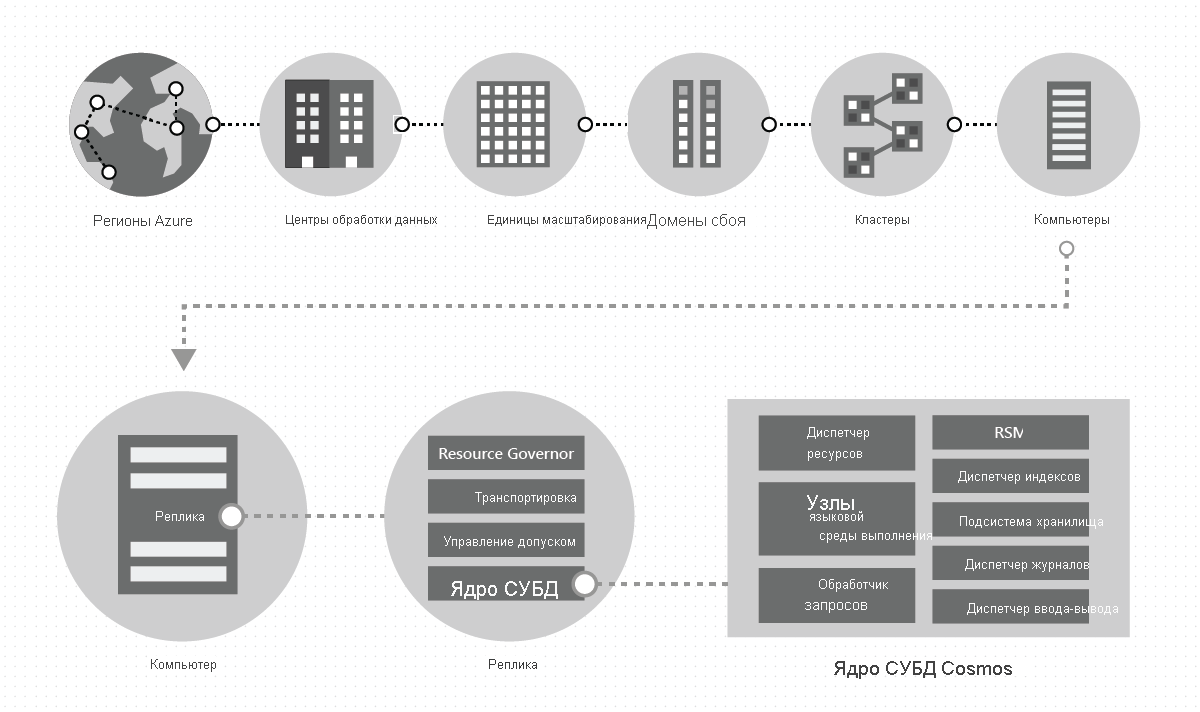
Глобальное распределение в Azure Cosmos DB готово. В любое время с несколькими щелчками или программным путем с одним вызовом API можно добавить или удалить географические регионы, связанные с базой данных Azure Cosmos DB. База данных Azure Cosmos DB, в свою очередь, состоит из набора контейнеров Azure Cosmos DB. В Azure Cosmos DB контейнеры служат логическими единицами распределения и масштабируемости. Создаваемые коллекции, таблицы и графы —это только контейнеры Azure Cosmos DB. Контейнеры полностью независимы от схем и предоставляют область для запроса. Данные в контейнере Azure Cosmos DB автоматически индексируются при приеме. Автоматическое индексирование позволяет пользователям запрашивать данные без трудностей управления схемами или индексами, особенно в глобально распределенной инфраструктуре.
В определенном регионе данные в контейнере распределяются с использованием ключа раздела, который вы предоставляете и который прозрачно управляется базовыми физическими разделами (локальное распределение).
Каждая физическая секция также реплицируется по географическим регионам (глобальное распределение).
Когда приложение с помощью Azure Cosmos DB эластично масштабирует пропускную способность в контейнере Azure Cosmos DB или использует больше хранилища, Azure Cosmos DB прозрачно обрабатывает операции управления секциями (разделение, клонирование, удаление) во всех регионах. Независимо от масштаба, распределения или сбоев, Azure Cosmos DB продолжает предоставлять единый системный образ данных в контейнерах, которые глобально распределены по любому количеству регионов.
Как показано на следующем рисунке, данные в контейнере распределяются по двум измерениям — в пределах региона и в разных регионах по всему миру.
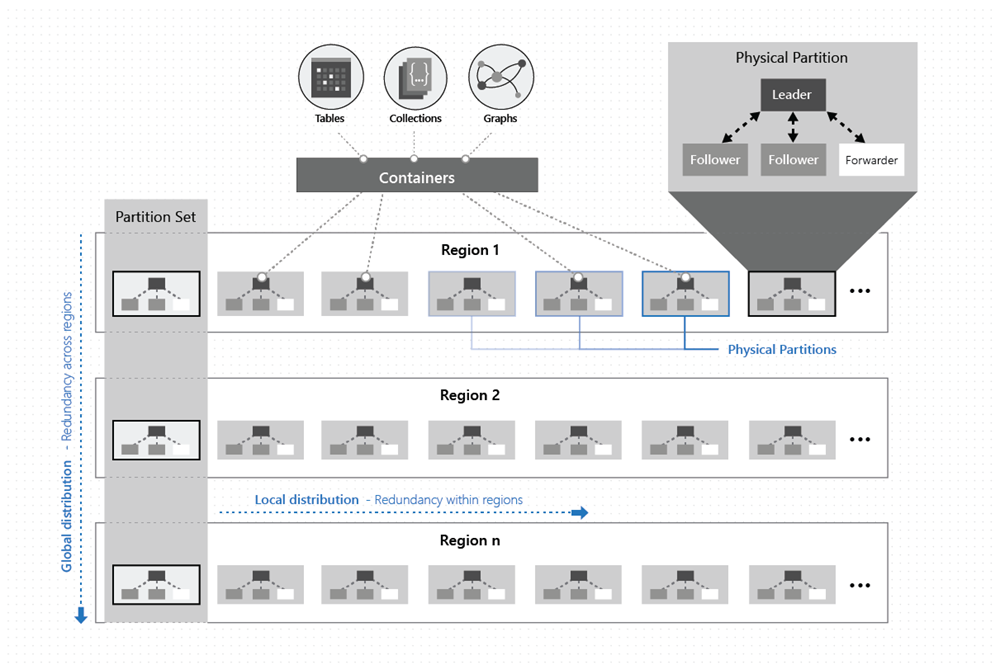
Физическая партиция реализуется группой реплик, которую называют набором реплик. Каждая машина содержит сотни реплик, соответствующих различным физическим секциям в рамках фиксированного набора процессов, как показано на предыдущем рисунке. Реплики, соответствующие физическим секциям, динамически размещаются и сбалансировано распределяют нагрузки между машинами в кластере и центрах обработки данных в пределах региона.
Реплика однозначно принадлежит клиенту Azure Cosmos DB. Каждая реплика размещает экземпляр ядра СУБД Azure Cosmos DB, который управляет ресурсами, а также связанными индексами. Ядро базы данных Azure Cosmos DB функционирует на основе системы типов atom-record-sequence (ARS). Движок не зависит от понятия схемы данных, размывая границы между структурой и значениями экземпляров записей. Azure Cosmos DB достигает полной независимости от схем, автоматически индексируя все при вводе данных, что позволяет пользователям запрашивать глобально распределенные данные без необходимости управлять схемами или индексами.
Ядро СУБД Azure Cosmos DB состоит из компонентов, включая реализацию нескольких примитивов координации, языковых сред выполнения, обработчика запросов и подсистемы хранения и индексирования, отвечающих за хранение транзакций и индексирование данных соответственно. Чтобы обеспечить устойчивость и высокую доступность, ядро СУБД сохраняет свои данные и индексы на дисках SSD и реплицирует их среди экземпляров ядра СУБД в наборах реплик соответственно. Большие арендаторы имеют более высокую шкалу пропускной способности и хранения и могут иметь либо более крупные реплики, либо большее количество реплик, или и то и другое. Каждый компонент системы полностью асинхронен — ни один поток никогда не блокирует другой, и каждый поток работает кратковременно без каких-либо ненужных переключателей потоков. Ограничение скорости и обратное давление передаются по всему стеку от контроля допуска до всех путей ввода-вывода. Ядро СУБД Azure Cosmos DB предназначено для использования точного параллелизма и обеспечения высокой пропускной способности при работе в неустраченных объемах системных ресурсов.
Глобальное распределение Azure Cosmos DB зависит от двух ключевых абстракций — наборов реплик и наборов партиций. Набор реплик — это модульный элемент для координации, а набор разделов — это динамическая структура одного или нескольких географически распределенных физических разделов. Чтобы понять, как работает глобальное распределение, необходимо понимать эти две ключевые абстракции.
Наборы реплик
Физическая секция, которая материализуется как самоуправляемая и динамически сбалансированная по нагрузке группа реплик, распределенная между несколькими доменами сбоя, называется набором реплик. Этот набор совместно реализует протокол реплицированного состояния машины, чтобы сделать данные в физической секции доступными, устойчивыми и согласованными. Членство в наборе реплик N является динамическим — оно постоянно меняется между NMin и NMax на основе сбоев, административных операций и времени для повторного создания или восстановления неудачных реплик. Исходя из изменений членства, протокол репликации также перенастраивает размер кворумов чтения и записи. Для равномерного распределения пропускной способности, назначенной физической партиции, мы используем две идеи.
Во-первых, стоимость обработки запросов на запись на ведущем узле выше, чем стоимость применения обновлений на ведоме. Соответственно, лидеру выделено больше системных ресурсов, чем подписчикам.
Во-вторых, насколько это возможно, кворум чтения для заданного уровня согласованности состоит исключительно из реплик подписчиков. Мы избегаем контакта с лидером для выполнения операций чтения, если этого не требуется. Мы используем ряд идей из исследований, посвященных взаимосвязи загрузки и емкости в системах на основе кворума для пяти моделей согласованности, поддерживаемых Azure Cosmos DB.
Наборы разбиений
Группа физических секций, одна из каждой из настроенных с помощью регионов базы данных Azure Cosmos DB, состоит для управления одним набором ключей, реплицируемых во всех настроенных регионах. Этот более высокий координационный примитив называется набором секций — географически распределенное динамическое наложение физических секций, управляющих заданным набором ключей. Хотя данная физическая секция (набор реплик) находится в пределах кластера, набор секций может охватывать несколько кластеров, центры обработки данных и географические регионы, как показано на следующем рисунке.
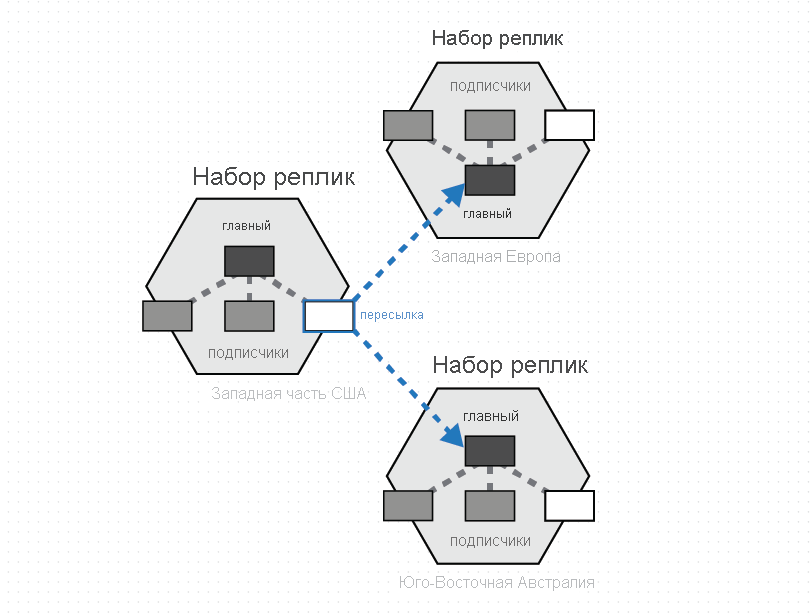
Набор секций можно считать географически распределенным "супернабором реплик", который состоит из нескольких наборов реплик, обладающих тем же набором ключей. Аналогично набору реплик, членство в наборе секций также является динамическим. Оно изменяется на основе неявных операций управления физическими секциями для добавления и удаления новых секций в заданный набор секций (например, при горизонтальном масштабировании пропускной способности контейнера, добавлении и удалении региона в базу данных Azure Cosmos DB или при возникновении сбоев). Благодаря тому что каждая из секций (набора секций) управляет членством в наборе секций в пределах своего собственного набора реплик, членство является полностью децентрализованным и высокодоступным. Во время перенастройки набора секций также устанавливается топология наложения между физическими секциями. Топология динамически выбирается на основе уровня согласованности, географического расстояния и доступной пропускной способности сети между исходными и целевыми физическими секциями.
Служба позволяет настроить базы данных Azure Cosmos DB с одним регионом записи или несколькими регионами записи, а в зависимости от выбора наборы секций настроены для приема записей в одном или всех регионах. Система использует двухуровневый вложенный протокол консенсуса — один уровень работает в репликах набора реплик физического раздела, принимая записи, а другой работает на уровне набора разделов, чтобы обеспечить полные гарантии упорядочения всех зафиксированных записей в наборе разделов. Этот многоуровневый вложенный консенсус имеет решающее значение для реализации наших строгих соглашений об уровне обслуживания для обеспечения высокой доступности, а также реализации моделей согласованности, которые Azure Cosmos DB предлагает своим клиентам.
Разрешение конфликтов
Наша разработка для распространения обновлений, разрешения конфликтов и отслеживания причин вдохновляется предыдущей работой по алгоритмам эпидемии и системе Bayou. Хотя ядра идей сохранились и обеспечивают удобную основу для сравнения при проектировании системы Azure Cosmos DB, они также претерпели значительные изменения, так как мы применяли их к системе Azure Cosmos DB. Это было необходимо, потому что предыдущие системы не были разработаны ни для управления ресурсами, ни для масштаба, требуемого для работы Azure Cosmos DB, ни для обеспечения таких возможностей, как ограниченная согласованность задержки обновления, а также строгих и комплексных соглашений об уровне обслуживания, которые Azure Cosmos DB предоставляет своим клиентам.
Помните, что набор секций распределяется по нескольким регионам и следует протоколу репликации Azure Cosmos DB (многорегионные записи), чтобы реплицировать данные между физическими секциями, содержащими заданный набор секций. Каждая физическая секция (из набора секций) принимает записи и обычно обслуживает запросы чтения от клиентов, находящихся в этом регионе. Записи, принятые физическим разделом в регионе, надежно сохраняются и обеспечивается их высокая доступность в пределах физического раздела, прежде чем они будут подтверждены клиенту. Эти предварительные записи распространяются на другие физические секции в наборе секций с помощью канала защиты от энтропии. Клиенты могут запрашивать либо предварительные, либо зафиксированные записи путем передачи заголовка HTTP-запроса. Распространение защиты от энтропии (включая частоту распространения) является динамическим, основанным на топологии набора секций, региональной близости физических секций и настроенном уровне согласованности. В множестве разделов Azure Cosmos DB следует основной схеме обработки транзакций с динамически выбранным арбитром. Выбор арбитра динамический. Он является неотъемлемой частью перенастройки набора секций на основе топологии наложения. Заказы зафиксированных записей (включая многострочные или пакетные обновления) гарантируются.
Мы используем закодированные векторные часы (содержащие идентификатор региона и логические часы, соответствующие каждому уровню консенсуса в наборе реплик и наборе секций соответственно) для отслеживания причинно-следственных связей и версий векторов, чтобы обнаружить и разрешить конфликты обновления. Топология и алгоритм выбора одноранговых узлов предназначены для обеспечения фиксированного и минимального хранения и минимальных нагрузок на сеть версий векторов. Алгоритм гарантирует строгое свойство конвергенции.
Для баз данных Azure Cosmos DB, настроенных с несколькими регионами записи, система предлагает ряд гибких политик автоматического разрешения конфликтов для разработчиков, в том числе:
- Приоритет последней записи (LWW), при котором по умолчанию используется свойство метки времени, определяемое системой (на основе протокола синхронизации времени). Azure Cosmos DB также позволяет указать любое другое пользовательское числовое свойство, которое будет использоваться для разрешения конфликтов.
- Определенная приложением политика пользовательского разрешения конфликтов (выраженная через процедуры слияния), которая предназначена для применения к конфликтам семантики, определяемой приложением. Эти процедуры вызываются при обнаружении конфликтов "запись — запись" во время обработки транзакции в базе данных на стороне сервера. Система гарантирует только однократное выполнение слияния в рамках протокола обязательств. Вам доступно несколько примеров разрешения конфликтов.
Модели согласованности
Независимо от того, настроена ли база данных Azure Cosmos DB с одним или несколькими регионами записи, можно выбрать из пяти четко определенных моделей согласованности. При наличии нескольких регионов записи, ниже перечислены несколько примечательных аспектов уровней согласованности:
Согласованность ограниченного устаревания гарантирует, что все операции чтения будут находиться в пределах K префиксов или T секунд от последней записи в любом из регионов. Кроме того, операции чтения с согласованностью ограниченного устаревания гарантируют монотонность и постоянность префикса. Протокол против энтропии работает с ограничением скорости и гарантирует, что префиксы не накапливаются, и обратное давление на записи не применяется. Согласованность сеанса гарантирует монотонное чтение, монотонную запись, чтение ваших собственных писем, запись после чтения и гарантии постоянного префикса по всему миру. Базы данных с заданной строгой согласованностью лишены преимущества, обеспечиваемого наличием нескольких регионов для записи (малая задержка записи, высокий уровень доступности для записи), вследствие их синхронной репликации в регионах.
Здесь описана семантика пяти моделей согласованности в Azure Cosmos DB и математически описана с помощью высокоуровневых спецификаций TLA+.
Следующие шаги
Узнайте, как настроить глобальное распределение, используя следующие статьи:
- Добавление и удаление регионов из учетной записи базы данных
- Создание пользовательской политики разрешения конфликтов
- Вы пытаетесь выполнить планирование ресурсов для миграции в Azure Cosmos DB? Для планирования ресурсов можно использовать сведения об имеющемся кластере базы данных.
- Если вам известно только количество виртуальных ядер и серверов в существующем кластере баз данных, прочитайте об оценке единиц запроса с использованием виртуальных ядер (vCores) или виртуальных процессоров (vCPUs).
- Если вам известна стандартная частота запросов для текущей рабочей нагрузки базы данных, ознакомьтесь со статьей о расчете единиц запросов с помощью планировщика ресурсов Azure Cosmos DB