Моделирование данных Graph с помощью Azure Cosmos DB для Apache Gremlin
Область применения: ![]() Гремлин
Гремлин
В этой статье приведены рекомендации по использованию моделей данных графа. Эти рекомендации жизненно важны для обеспечения масштабируемости и производительности системы базы данных графа по мере развития данных. Эффективная модель данных особенно важна для крупномасштабных графов.
Требования
Процесс, описанный в этом руководстве, исходит из следующих предположений:
- Сущности в проблемной области определены. Эти сущности предназначены для использования атомарным образом для каждого запроса. Другими словами, система базы данных не предназначена для получения данных одной сущности в нескольких запросах.
- Существует понимание требований для чтения и записи для системы базы данных. Эти требования помогут оптимизировать модель данных графа.
- Принципы стандарта графа свойства Apache Tinkerpop хорошо понятны.
Зачем нужна графовая база данных?
Решение базы данных графа можно оптимально использовать, если сущности и связи в домене данных имеют следующие характеристики:
- Сущности являются часто подключаемыми через описательные связи. Преимуществом этого сценария является сохранение связей в хранилище.
- Существуют циклические связи или сущности, ссылающиеся на самих себя. Этот шаблон часто является проблемой при использовании реляционных или документных баз данных.
- Между сущностями есть динамически развивающиеся связи. Этот шаблон хорошо подходит для иерархических или древовидных данных с несколькими уровнями.
- Между сущностями есть связи "многие ко многим".
- Существуют требования к записи и чтению для сущностей и связей.
Если указанные выше критерии выполнены, подход к базе данных графа, скорее всего, дает преимущества для сложности запросов, масштабируемости модели данных и производительности запросов.
На следующем шаге нужно определить, будет ли использоваться граф в целях аналитики или транзакций. Если граф предназначен для тяжелых вычислений и рабочих нагрузок обработки данных, следует изучить соединитель Cosmos DB Spark и библиотеку GraphX.
Как использовать объекты графов
Стандарт графа свойств Apache Tinkerpop определяет два типа объектов: вершины и края.
Ниже приведены рекомендации по свойствам в объектах графа.
| Object | Свойство | Тип | Примечания. |
|---|---|---|---|
| Модель | Идентификатор | Строка | Уникально применяется на секцию. Если значение не предоставляется при вставке, сохраняется автоматически созданный GUID. |
| Модель | Этикетка | Строка | Это свойство используется для определения типа сущности, которую представляет вершина. Если значение не указано, используется вершина значения по умолчанию. |
| Модель | Свойства | Строка, логический, числовый | Список отдельных свойств, которые хранятся в виде пар "ключ — значение", в каждой вершине. |
| Модель | Ключ раздела | Строка, логический, числовый | Это свойство определяет, где хранятся вершины и исходящие края. Узнайте больше о секционировании графов. |
| Microsoft Edge | Идентификатор | Строка | Уникально применяется на секцию. Автоматически создается по умолчанию. Ребра обычно не должны быть уникальным образом извлечены идентификатором. |
| Microsoft Edge | Этикетка | Строка | Это свойство используется для определения типа связи двух вершин. |
| Microsoft Edge | Свойства | Строка, логический, числовый | Список отдельных свойств, которые хранятся в виде пар "ключ — значение", в каждом ребре. |
Примечание.
Ребрам не требуется значение ключа секции, так как значение автоматически назначается на основе исходной вершины. Дополнительные сведения см. в разделе "Использование секционированного графа" в Azure Cosmos DB.
Рекомендации по моделированию сущностей и связей
Следующие рекомендации помогут вам при подходе к моделированию данных для базы данных графа Apache Gremlin для Azure Cosmos DB. Эти инструкции предполагают наличие определения домена данных и запросов для него.
Примечание.
Следующие шаги представлены в виде рекомендаций. Прежде чем рассматривать ее как готовую к работе, необходимо оценить и протестировать окончательную модель. Кроме того, рекомендации относятся к реализации API Gremlin в Azure Cosmos DB.
Моделирование вершин и свойств
Первым шагом для создания модели данных графов является сопоставление каждой идентифицируемой сущности с объектом вершины. Одно-одно сопоставление всех сущностей с вершинами должно быть начальным шагом и предметом изменения.
Сопоставление свойств одной сущности в качестве отдельных вершин является одной из распространенных ошибок. Рассмотрим следующий пример, где одна и та же сущность представлена двумя разными способами:
Свойства на основе вершин: при таком подходе для описания свойств сущности используются три отдельных вершины и два ребра. Хотя при таком подходе может уменьшиться избыточность, он увеличивает сложность модели. Это может привести к дополнительной задержке, увеличению сложности запросов и повышению вычислительных затрат. Эта модель также может вызвать трудности при секционировании.
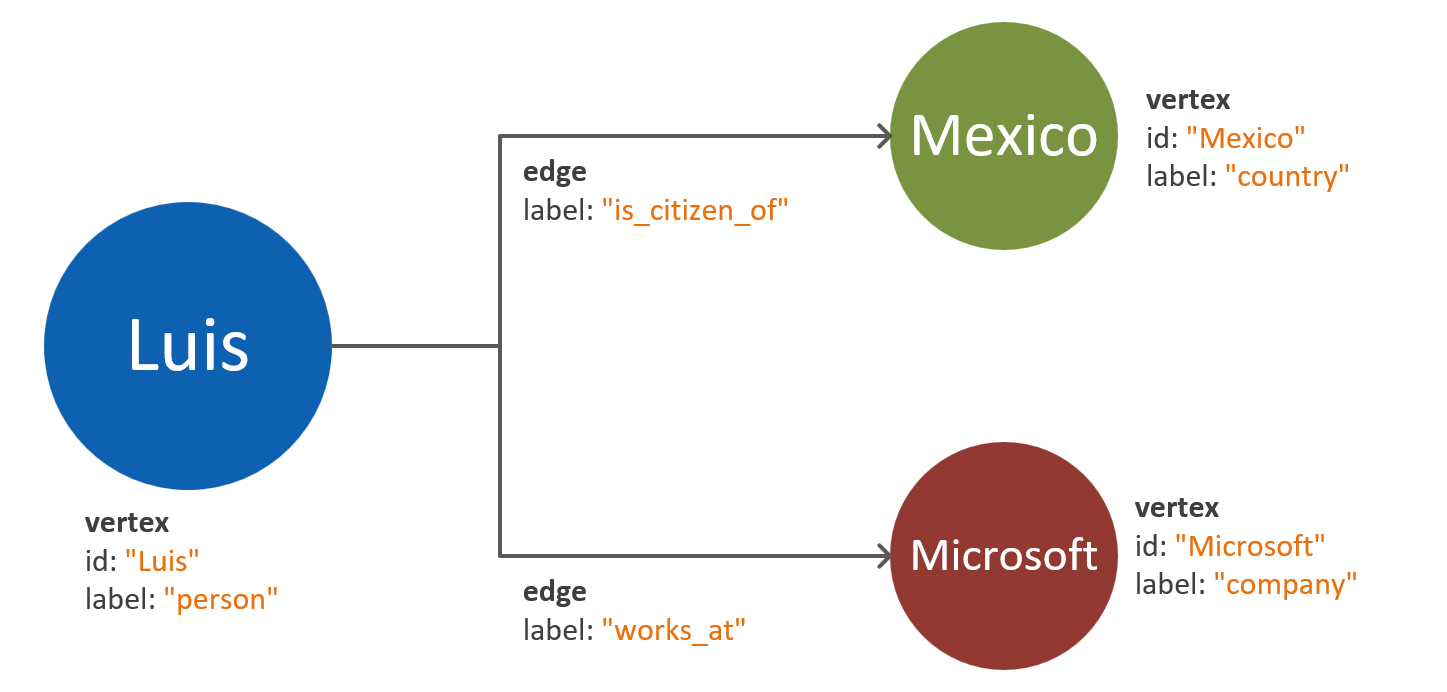
Вершины с внедренными свойствами: в этом подходе для представления всех свойств сущности внутри вершины используется список пар "ключ — значение". Такой подход снижает сложность модели, что приводит к более простым запросам и более экономичным обходам.

Примечание.
На предыдущих схемах показана упрощенная модель графа, которая сравнивает только два способа деления свойств сущности.
Шаблон вершин с внедренными свойствами обычно обеспечивает более производительный и масштабируемый подход. Подход по умолчанию к новой модели данных графа должен гравитироваться к этому шаблону.
Однако существуют сценарии, в которых ссылка на свойство может предоставить преимущества. Например, если упоминаемое свойство часто обновляется. Используйте отдельную вершину для представления свойства, которое постоянно изменяется, чтобы свести к минимуму количество операций записи, необходимых обновлению.
Модели отношений с пограничными направлениями
После моделирования вершин можно добавить ребра для обозначения связей между ними. Первый аспект, который необходимо оценить, — это направление связи.
Пограничные объекты имеют направление по умолчанию, за которым следует обход при использовании out() или outE() функциях. При использовании естественного направления повышается эффективность операции, так как все вершины хранятся с исходящими от них ребрами.
Однако обход в противоположном направлении края с помощью in() функции всегда приводит к запросу между секциями. Узнайте больше о секционировании графов. Если нужно постоянно выполнять обход с использованием функции in(), мы рекомендуем добавить ребра в обоих направлениях.
Вы можете определить направление края с помощью .to() или .from() предикатов с .addE() шагом Gremlin. либо используя библиотеку массового исполнителя для API Gremlin.
Примечание.
Объекты ребер имеют направление по умолчанию.
Метки отношений
Использование описательных меток для связи может повысить эффективность операций разрешения ребер. Этот шаблон можно применить следующим образом:
- Создание меток для связи с использованием условий, не являющихся универсальными.
- Связывание метки исходной вершины с меткой целевой вершины с использованием имени связи.
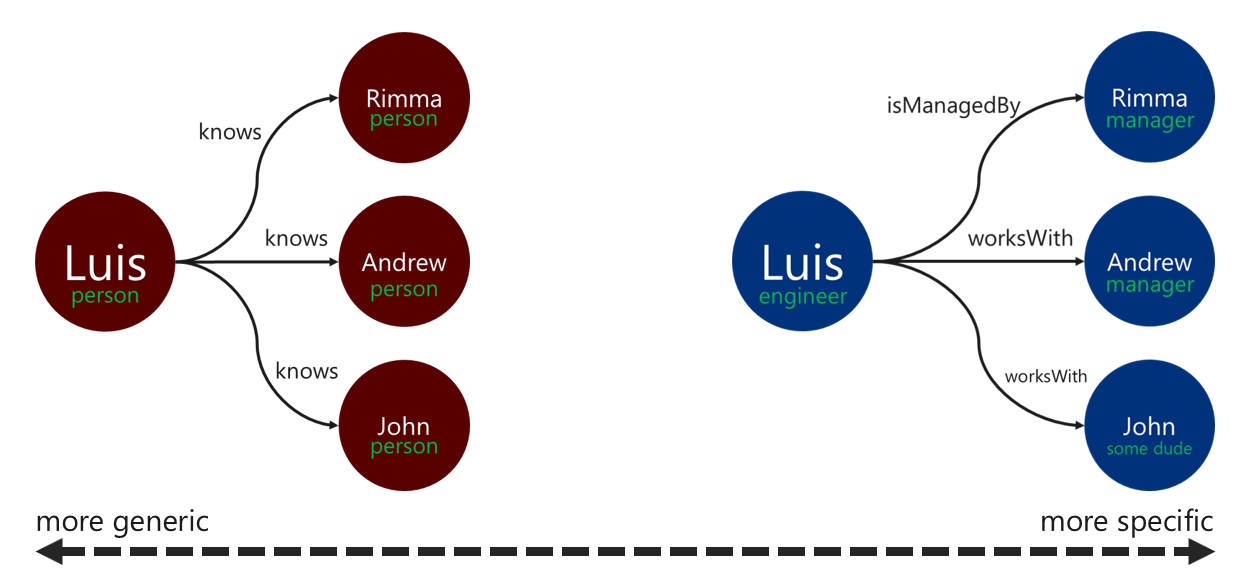
Чем более конкретная метка, которую обходщик использует для фильтрации краев, тем лучше. Это решение может оказать значительное влияние на затраты на запросы. Вы можете оценить стоимость запроса в любое время с помощью шага executionProfile.
Следующие шаги
- Ознакомьтесь со списком поддерживаемых шагов Gremlin.
- Узнайте больше о секционировании графовых баз данных, чтобы обрабатывать крупномасштабные графы.
- Оцените запросы Gremlin с помощью шага профиля выполнения.
- Модель данных разработки графов сторонних разработчиков.