Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Azure Cosmos DB для MongoDB позволяет использовать индексирование для ускорения производительности запросов. В этой статье показано, как управлять и оптимизировать индексы для ускорения извлечения данных и повышения эффективности.
Индексирование для сервера MongoDB версии 3.6 и более поздних версий
Azure Cosmos DB для сервера MongoDB версии 3.6+ автоматически индексирует _id поле и ключ сегментов (только в сегментированных коллекциях). API обеспечивает уникальность _id поля для каждого ключа сегмента.
API для MongoDB работает по-разному от Azure Cosmos DB для NoSQL, который индексирует все поля по умолчанию.
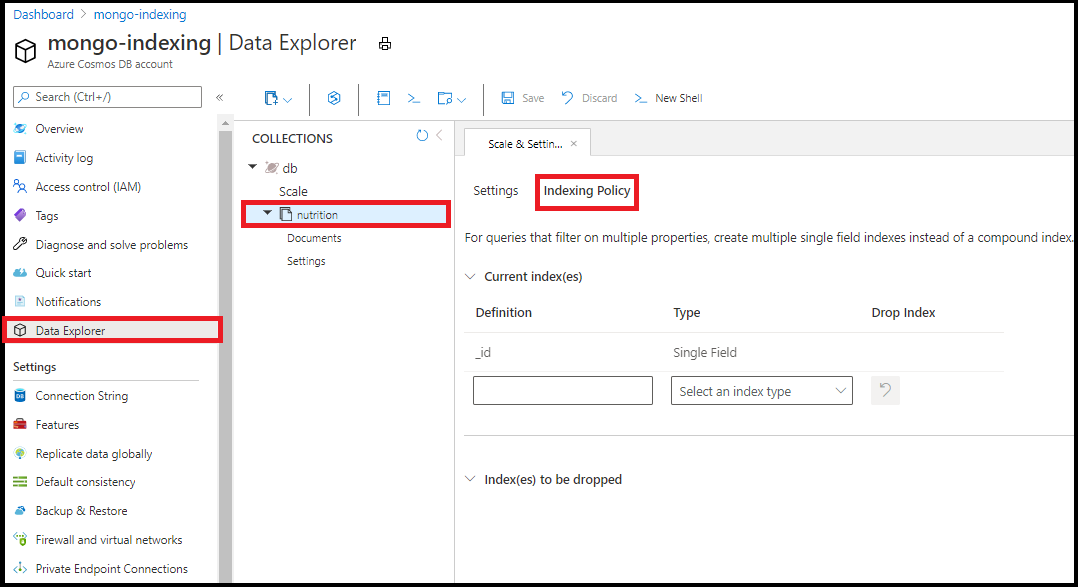
Изменение политики индексирования
Измените политику индексирования в Data Explorer на портале Azure. Добавьте индексы с одним полем и подстановочными знаками из редактора политики индексирования в Обозревателе данных:
Примечание.
Создавать составные индексы с помощью редактора политики индексирования в обозревателе данных нельзя.
Типы индексов
Одно поле
Создайте индекс в любом отдельном поле. Порядок сортировки индекса одного поля не имеет значения. Используйте следующую команду, чтобы создать индекс в поле name:
db.coll.createIndex({name:1})
Создайте один и тот же индекс поля на name портале Azure:
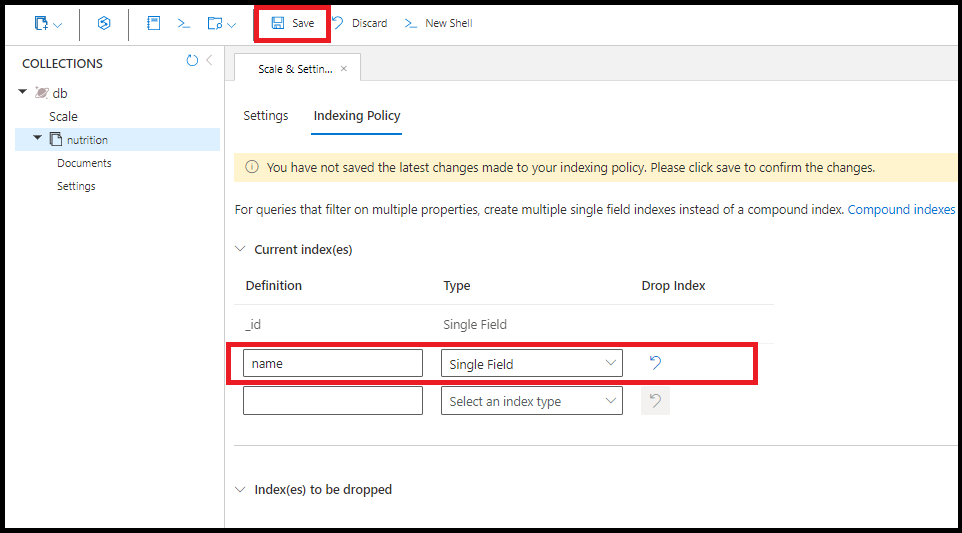
Запрос использует несколько индексов одного поля, где они доступны. Создайте до 500 индексов одного поля для каждой коллекции.
Составные индексы (MongoDB Server версии 3.6 и более поздних)
В API для MongoDB используйте составные индексы с запросами, которые сортируют несколько полей одновременно. Для запросов с несколькими фильтрами, которые не требуют сортировки, вместо одного составного индекса следует создавать несколько индексов по одному полю, чтобы сэкономить на затратах на индексирование.
Составной индекс или индексы одного поля для каждого поля в составном индексе приводят к одинаковой производительности фильтрации в запросах.
Составные индексы в вложенных полях по умолчанию не поддерживаются из-за ограничений массивов. Если вложенное поле не имеет массива, индекс работает должным образом. Если вложенное поле содержит массив в любом месте пути, это значение игнорируется в индексе.
Например, составной индекс, people.dylan.age содержащий в данном случае, работает, так как в пути нет массива:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Тот же составной индекс не работает в этом случае, так как в пути есть массив:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Включите эту функцию для учетной записи базы данных, включив функцию EnableUniqueCompoundNestedDocs.
Примечание.
Не удается создать составные индексы массивов.
Следующая команда создает составной индекс по полям name и age:
db.coll.createIndex({name:1,age:1})
Составные индексы можно использовать для эффективной сортировки по нескольким полям одновременно, как показано в следующем примере:
db.coll.find().sort({name:1,age:1})
Предыдущий составной индекс также можно использовать для эффективной сортировки в запросе с противоположным порядком сортировки по всем полям. Приведем пример:
db.coll.find().sort({name:-1,age:-1})
Однако последовательность путей в составном индексе должна точно соответствовать запросу. Ниже приведен пример запроса, требующего дополнительного составного индекса:
db.coll.find().sort({age:1,name:1})
Многоключевые индексы
Azure Cosmos DB создает многоключевые индексы для индексирования содержимого в массивах. Если вы индексируете поле со значением массива, Azure Cosmos DB автоматически индексирует каждый элемент в массиве.
Геопространственные индексы
Многие геопространственные операторы используют геопространственные индексы. Azure Cosmos DB для MongoDB поддерживает 2dsphere индексы. API пока не поддерживает 2d индексы.
Ниже приведен пример создания геопространственного индекса по полю location.
db.coll.createIndex({ location : "2dsphere" })
Текстовые индексы
Azure Cosmos DB для MongoDB не поддерживает текстовые индексы. Для запросов поиска текста в строках используйте интеграцию поиска ИИ Azure с Azure Cosmos DB.
Индексы с подстановочными знаками
Используйте индексы подстановочных знаков для поддержки запросов к неизвестным полям. Представьте коллекцию, которая содержит данные о семействах.
Ниже приведена часть примера документа в этой коллекции:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Ниже приведен другой пример с другим набором свойств в children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
Документы в этой коллекции могут иметь множество различных свойств. Чтобы индексировать все данные в массиве children , создайте отдельные индексы для каждого свойства или создайте один подстановочный индекс для всего children массива.
Создание индекса с подстановочными знаками
Используйте следующую команду, чтобы создать индекс подстановочного знака для любых свойств в children:
db.coll.createIndex({"children.$**" : 1})
- В отличие от MongoDB, индексы с подстановочными знаками могут поддерживать несколько полей в предикатах запросов. Нет разницы в производительности запросов, если вместо создания отдельного индекса для каждого свойства используется один подстановочный индекс.
Создайте следующие типы индексов с помощью синтаксиса подстановочных знаков:
- Одно поле
- Геопространственные данные
Индексирование всех свойств
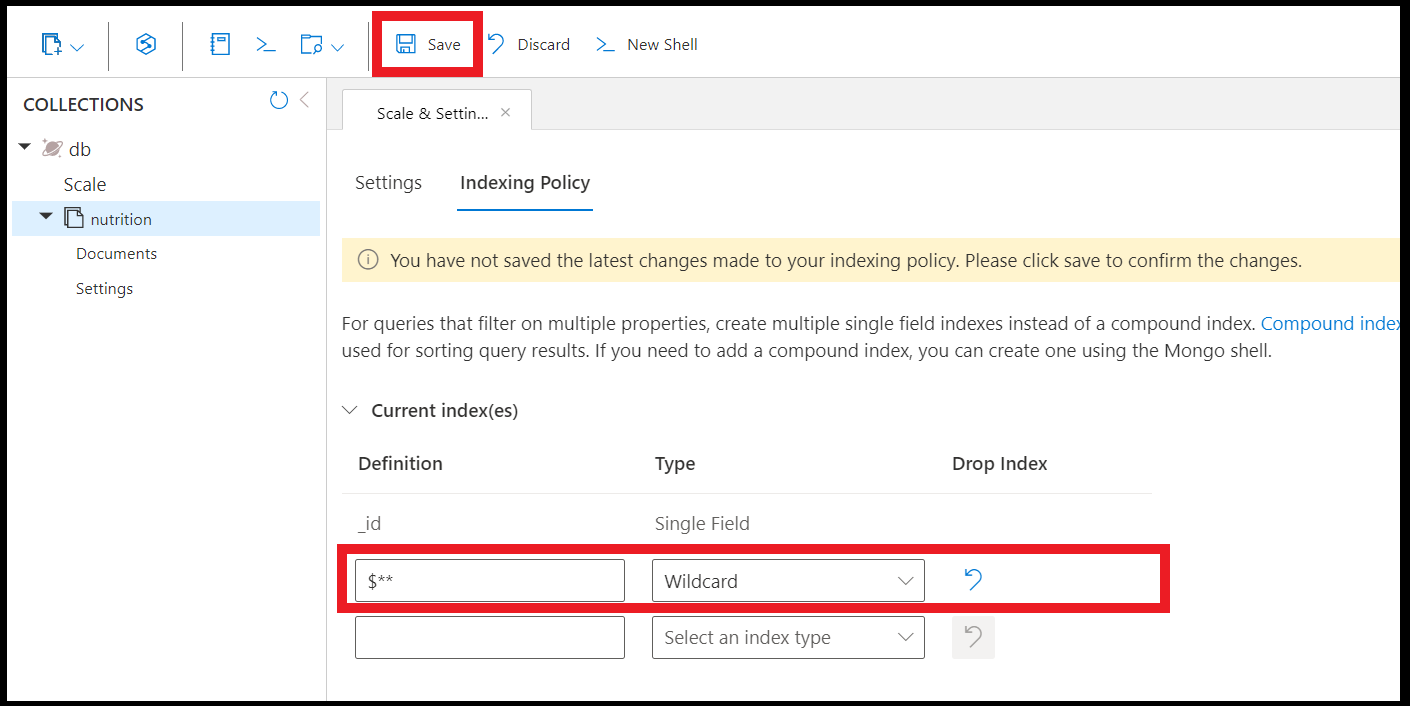
Создайте индекс подстановочного знака во всех полях с помощью следующей команды:
db.coll.createIndex( { "$**" : 1 } )
Создайте индексы подстановочных знаков с помощью обозревателя данных на портале Azure:
Примечание.
Если вы только начинаете разработку, начните с подстановочного индекса во всех полях. Этот подход упрощает разработку и упрощает оптимизацию запросов.
Документы с большим количеством полей могут иметь высокую плату за операции записи и обновления. Если у вас есть рабочая нагрузка с высокой нагрузкой на запись, используйте отдельные индексированные пути вместо подстановочных знаков.
Ограничения
Индексы подстановочных знаков не поддерживают ни один из следующих типов или свойств индексов:
Составные
TTL
Уникальный
В отличие от MongoDB, в Azure Cosmos DB для MongoDB нельзя использовать индексы подстановочных знаков для:
Создание индекса типа wildcard, включающего несколько конкретных полей.
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )создание универсального индекса, исключающего несколько конкретных полей.
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
В качестве альтернативы создайте несколько подстановочных индексов.
Свойства индекса
Следующие операции являются общими для учетных записей, использующих проводной протокол версии 4.0 и более ранних версий. Дополнительные сведения о поддерживаемых индексах и индексированных свойствах.
Уникальные индексы
Уникальные индексы помогают убедиться, что два или более документов не имеют одинакового значения для индексированных полей.
Выполните следующую команду, чтобы создать уникальный индекс в student_id поле:
db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
Для сегментированных коллекций укажите ключ сегмента (секции) для создания уникального индекса. Все уникальные индексы в сегментированной коллекции являются составными индексами, а одно из полей — ключ сегментов. Ключ сегментов должен быть первым полем в определении индекса.
Выполните следующие команды, чтобы создать сегментированную коллекцию с именем coll (с university ключом сегментирования) и уникальным индексом в student_iduniversity полях:
db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
Если вы опустите "university":1 предложение в предыдущем примере, появится следующее сообщение об ошибке:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Ограничения
Создайте уникальные индексы, пока коллекция пуста.
Учетные записи Azure Cosmos DB для MongoDB с непрерывным резервным копированием не поддерживают создание уникального индекса для существующей коллекции. Для такой учетной записи уникальные индексы должны создаваться в момент создания коллекции, что должно и может быть сделано только с помощью команд расширения коллекции.
db.runCommand({customAction:"CreateCollection", collection:"coll", shardKey:"student_id", indexes:[
{key: { "student_id" : 1}, name:"student_id_1", unique: true}
]});
Уникальные индексы в вложенных полях по умолчанию не поддерживаются из-за ограничений массивов. Если вложенное поле не имеет массива, индекс работает должным образом. Если вложенное поле имеет массив в любом месте пути, это значение игнорируется в уникальном индексе, а уникальность не сохраняется для этого значения.
Например, уникальный индекс people.tom.age работает в этом случае, так как в пути нет массива:
{
"people": {
"tom": {
"age": "25"
},
"mark": {
"age": "30"
}
}
}
Но не работает в этом случае, так как в пути есть массив:
{
"people": {
"tom": [
{
"age": "25"
}
],
"mark": [
{
"age": "30"
}
]
}
}
Эту функцию можно включить для учетной записи базы данных, включив функцию EnableUniqueCompoundNestedDocs.
Индексы срока жизни
Чтобы срок действия документов истекал в коллекции, создайте индекс времени жизни (TTL). Индекс TTL — это индекс по полю _ts со значением expireAfterSeconds.
Пример:
db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Предыдущая команда удаляет все документы в db.coll коллекции, которые были изменены более 10 секунд назад.
Примечание.
Поле _ts зависит от Azure Cosmos DB и недоступно для клиентов MongoDB. Это зарезервированное (системное) свойство, содержащее метку времени последнего изменения документа.
Отслеживание хода индексирования
Версия 3.6 для Azure Cosmos DB для MongoDB поддерживает currentOp() команду для отслеживания хода выполнения индекса в экземпляре базы данных. Эта команда возвращает документ с сведениями о выполняемых операциях в экземпляре базы данных.
currentOp Используйте команду для отслеживания всех выполняемых операций в собственном MongoDB. В Azure Cosmos DB для MongoDB эта команда отслеживает только операцию индекса.
Ниже приведены некоторые примеры использования currentOp команды для отслеживания хода выполнения индекса:
Получите ход выполнения индекса для коллекции:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Получите ход выполнения индекса для всех коллекций в базе данных:
db.currentOp({"command.$db": <databaseName>})Получите ход выполнения индекса для всех баз данных и коллекций в учетной записи Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Примеры отображения прогресса индексации
Сведения о ходе выполнения индекса показывают процент хода выполнения текущей операции индекса. Ниже приведены примеры формата выходного документа для различных этапов выполнения индекса:
Операция индекса для коллекции foo и "bar" базы данных, которая составляет 60 процентов завершена, содержит следующий выходной документ. В поле
Inprog[0].progress.totalв качестве целевого процента выполнения отображается значение 100.{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 60 %", "progress": { "done": 60, "total": 100 }, ... } ], "ok": 1 }Если операция индекса только что запущена в базе данных foo и bar, выходной документ может показать 0 процентов хода выполнения, пока он не достигнет измеримого уровня.
{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 0 %", "progress": { "done": 0, "total": 100 }, ... } ], "ok": 1 }После завершения операции индекса выходной документ отображает пустые
inprogоперации.{ "inprog" : [], "ok" : 1 }
Обновления фонов индекса
Обновления индекса всегда выполняются в фоновом режиме, независимо от значения, заданного для свойства фонового индекса. Так как обновления индекса используют единицы запросов (ЕЗ) в более низком приоритете, чем другие действия базы данных, изменения индекса не вызывают простоя для операций записи, обновления или удаления.
Добавление нового индекса не влияет на доступность чтения. Запросы используют новые индексы только после завершения преобразования индекса. Во время преобразования обработчик запросов продолжает использовать существующие индексы, поэтому вы увидите аналогичную производительность чтения, как и перед началом изменения индексирования. Добавление новых индексов не рискует неполными или несогласованными результатами запроса.
При удалении индексов и немедленном выполнении запросов, которые фильтруют эти удаленные индексы, результаты могут быть несогласованными и неполными до завершения преобразования индекса. Обработчик запросов не предоставляет согласованные или полные результаты для запросов, которые фильтруют только что удаленные индексы. Большинство разработчиков не сбрасывают индексы, а затем немедленно запрашивают их, поэтому эта ситуация вряд ли будет.
Примечание.
Вы можете отслеживать ход индексирования.
Команда reIndex
Команда reIndex повторно создает все индексы в коллекции. В редких случаях выполнение reIndex команды может устранить проблемы с производительностью запросов или другими проблемами с индексами в коллекции. Если у вас возникли проблемы с индексированием, попробуйте восстановить индексы с reIndex помощью команды.
reIndex Выполните команду с помощью следующего синтаксиса:
db.runCommand({ reIndex: <collection> })
Используйте следующий синтаксис, чтобы проверить, улучшает ли выполнение reIndex команды производительность запросов в коллекции:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Образец вывода:
{
"database": "myDB",
"collection": "myCollection",
"provisionedThroughput": 400,
"indexes": [
{
"v": 1,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "myDB.myCollection",
"requiresReIndex": true
},
{
"v": 1,
"key": {
"b.$**": 1
},
"name": "b.$**_1",
"ns": "myDB.myCollection",
"requiresReIndex": true
}
],
"ok": 1
}
Если reIndex улучшает производительность запросов, требуется значение TrueReIndex . Если reIndex это свойство не улучшает производительность запросов, это свойство опущено.
Миграция коллекций с индексами
Вы можете создавать только уникальные индексы, если в коллекции нет документов. Популярные средства миграции MongoDB пытаются создать уникальные индексы после импорта данных. Чтобы обойти эту проблему, вручную создайте соответствующие коллекции и уникальные индексы, а не позволить средству миграции попробовать. Это можно mongorestore сделать с помощью флага --noIndexRestore в командной строке.
Индексирование для MongoDB версии 3.2
Функции индексирования и значения по умолчанию отличаются для учетных записей Azure Cosmos DB, использующих протокол подключения MongoDB версии 3.2. Проверьте версию учетной записи в версии feature-support-36.md#protocol-support и обновите до версии 3.6 в upgrade-version.md.
Если вы используете версию 3.2, в этом разделе рассматриваются основные отличия от версий 3.6 и более поздних версий.
Удаление индексов по умолчанию (версия 3.2)
В отличие от версий 3.6 и более поздних, Azure Cosmos DB для MongoDB версии 3.2 индексирует каждое свойство по умолчанию. Используйте следующую команду, чтобы удалить эти индексы по умолчанию для коллекции (coll):
db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
После удаления индексов по умолчанию добавьте дополнительные индексы, как и в версии 3.6 и более поздних версий.
Составные индексы (версия 3.2)
Составные индексы ссылаются на несколько полей в документе. Чтобы создать составной индекс, обновите до версии 3.6 или 4.0 в upgrade-version.md.
Индексы с подстановочными знаками (версия 3.2)
Чтобы создать индекс подстановочного знака, обновите до версии 4.0 или 3.6 в upgrade-version.md.