Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Внимание
Azure Cosmos DB для PostgreSQL больше не поддерживается для новых проектов. Не используйте эту службу для новых проектов. Вместо этого используйте одну из этих двух служб:
Используйте Azure Cosmos DB для NoSQL как распределенное решение базы данных, предназначенное для крупномасштабных сценариев с соглашением об уровне доступности (SLA) 99.999%, мгновенным автомасштабированием и автоматическим переключением в случае отказа в нескольких регионах.
Используйте функцию эластичных кластеров Базы данных Azure для PostgreSQL для сегментированного PostgreSQL с помощью расширения Citus с открытым кодом.
В этом руководстве вы узнаете, как использовать Azure Cosmos DB для PostgreSQL:
- Создание кластера
- Использование служебной программы psql для создания схемы
- Сегментирование таблиц по узлам
- Загрузка образцовых данных
- Запрос данных арендатора
- Обмен данными между клиентами
- Настройка схемы для каждого клиента
Необходимые компоненты
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Создание кластера
Войдите в портал Azure и выполните следующие действия, чтобы создать кластер Azure Cosmos DB для PostgreSQL:
Перейдите к разделу Создание кластера Azure Cosmos DB for PostgreSQL на портале Azure.
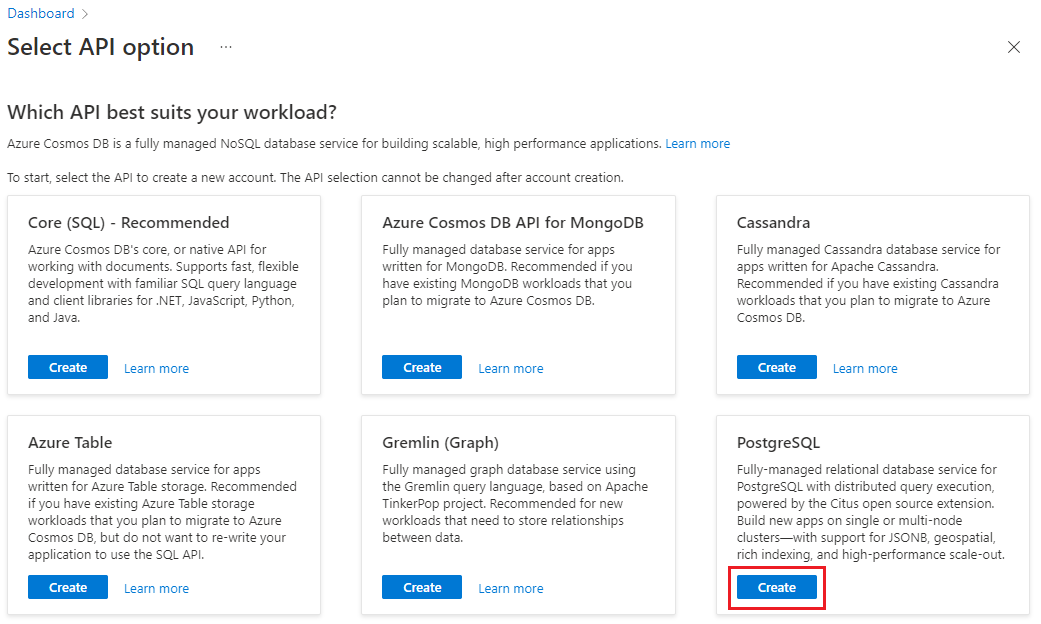
В форме кластера Create a Azure Cosmos DB for PostgreSQL:
Укажите сведения на вкладке Основные сведения.
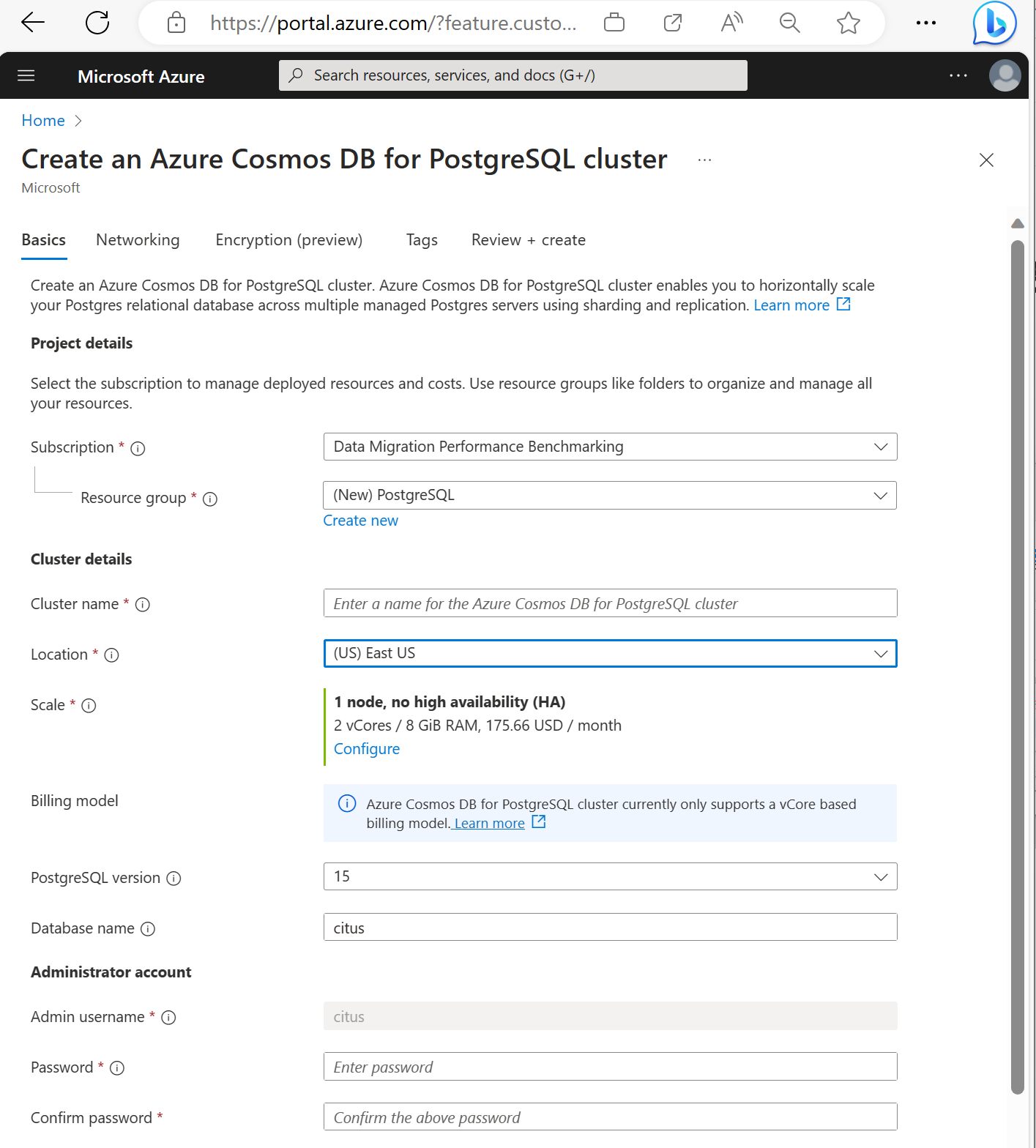
Назначение большинства параметров очевидно из их названия, но примите во внимание следующее:
- Имя кластера определяет DNS-имя, используемое для подключения приложений, в форме
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Вы можете выбрать основную версию PostgreSQL, например 15. Azure Cosmos DB для PostgreSQL всегда поддерживает последнюю версию Citus для выбранной основной версии Postgres.
- Для имени администратора должно быть установлено значение
citus. - Вы можете оставить имя базы данных по умолчанию citus или определить только имя базы данных. После подготовки кластера невозможно переименовать базу данных.
- Имя кластера определяет DNS-имя, используемое для подключения приложений, в форме
Выберите Далее: Сеть в нижней части экрана.
На экране "Сеть" выберите "Разрешить общедоступный доступ" из служб и ресурсов Azure в этом кластере.
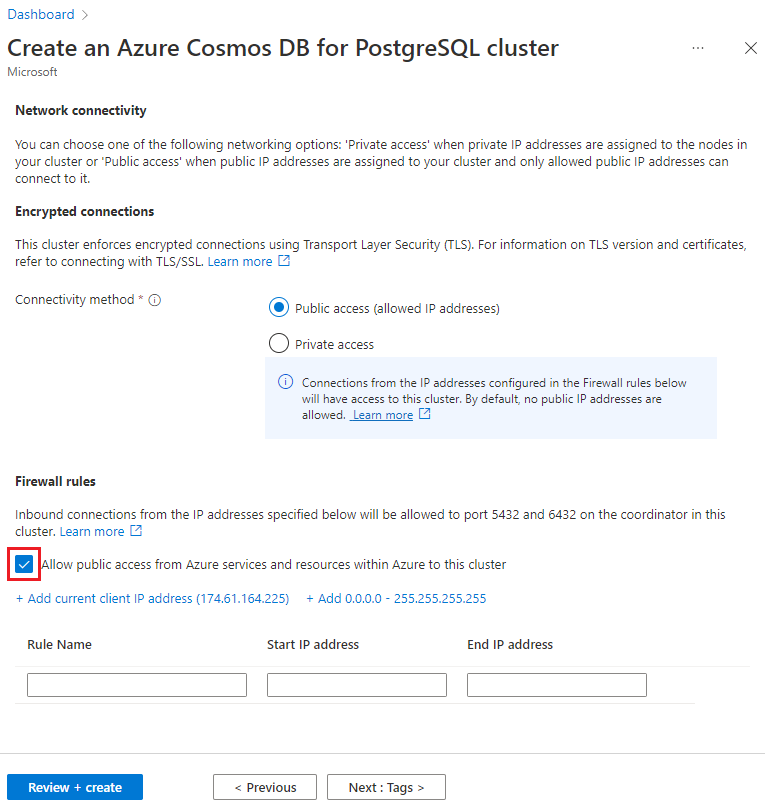
Выберите элемент Просмотр и создание, а по завершении проверки нажмите кнопку Создать, чтобы создать кластер.
Подготовка занимает несколько минут. Страница перенаправляется на мониторинг развертывания. Когда состояние изменится с Выполняется развертывание на Развертывание выполнено, выберите элемент Перейти к ресурсу.
Использование служебной программы psql для создания схемы
После подключения к Azure Cosmos DB для PostgreSQL с помощью psql можно выполнить некоторые основные задачи. В этом руководстве описывается создание веб-приложения, которое позволяет рекламодателям отслеживать свои рекламные кампании.
Это приложение могут использовать несколько организаций сразу, поэтому мы создадим таблицу для списка организаций и еще одну — для рекламных кампаний. В консоли psql выполните следующие команды:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Каждая кампания оплачивает показ рекламных объявлений. Добавьте таблицу и для рекламных объявлений, выполнив в psql следующий код после приведенного выше:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Теперь мы добавим отслеживание статистики кликов и показов для каждого рекламного объявления:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Теперь новые таблицы отображаются в полном списке таблиц, который можно получить в psql, выполнив следующую команду:
\dt
Мультитенантные приложения могут применять уникальность только в пределах каждого клиента, поэтому все первичные и внешние ключи должны включать идентификатор компании.
Сегментирование таблиц по узлам
Развертывание Azure Cosmos DB для PostgreSQL сохраняет строки таблиц на разных узлах на основе значения указанного пользователем столбца. Этот "столбец распределения" определяет, какому клиенту принадлежит какая строка.
Давайте установим столбец распределения как company_id, который является идентификатором арендатора. Выполните в psql такие функции:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Внимание
Чтобы воспользоваться функциями производительности Azure Cosmos DB для PostgreSQL, необходимо распространять таблицы или использовать сегментирование на основе схем. Если вы не распределяете таблицы или схемы, рабочие узлы не могут помочь выполнять запросы, связанные с их данными.
Загрузка образцовых данных
Теперь в обычной командной строке (вне psql) скачайте примеры наборов данных:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Перейдите в psql и выполните массовую загрузку данных. Команду psql нужно выполнять в том же каталоге, куда вы скачали файлы данных.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Теперь эти данные будут распределены между рабочими узлами.
Запрос данных арендатора
Когда приложение запросит данные одного клиента, база данных сможет выполнить такой запрос на одном рабочем узле. Запросы по одному клиенту фильтруются по идентификатору клиента. Например, следующий запрос фильтрует company_id = 5 по рекламным объявлениям и показам. Попробуйте выполнить его в psql и изучите результаты.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Обмен данными между клиентами
До сих пор все таблицы распределялись посредством company_id. Но некоторые данные не относятся естественным образом к какому-либо конкретному арендатору и могут использоваться совместно. Например, в нашем примере платформы для показа рекламы всем организациям будет полезно получать сведения о местоположении аудитории на основе IP-адресов.
Создайте таблицу для совместно используемой географической информации. Выполните следующие команды в psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Теперь сделайте geo_ips "ссылочной таблицей", чтобы копия этой таблицы хранилась на каждом рабочем узле.
SELECT create_reference_table('geo_ips');
Заполните ее данными из примера. Не забудьте, что эту команду нужно выполнять в psql в том же каталоге, куда вы скачали набор данных.
\copy geo_ips from 'geo_ips.csv' with csv
Объединение таблицы clicks с geo_ips эффективно на всех узлах. Ниже приведено соединение, позволяющее найти расположение всех, кто щелкнул объявление 290. Попробуйте выполнить запрос в PSQL.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Настройка схемы для каждого клиента
Каждому клиенту может потребоваться хранить собственные сведения, которые не нужны другим пользователям. Но при этом все клиенты используют общую инфраструктуру с идентичной схемой базы данных. Куда же разместить эти дополнительные данные?
Есть хороший выход — использовать открытый тип столбца, например JSONB в PostgreSQL. В нашей схеме в таблице clicks есть поле типа JSONB с именем user_data.
Компания (например, компания пять) может использовать этот столбец для отслеживания, использует ли пользователь мобильное устройство.
Следующий запрос позволяет найти, кто совершает больше кликов: посетители с мобильных или с классических устройств.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Мы оптимизируем этот запрос для одной организации, создав частичный индекс.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Теоретически мы можем создать индексы GIN по каждому ключу и значению в столбце.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Очистка ресурсов
На предыдущих шагах вы создали ресурсы Azure в кластере. Если вы не ожидаете, что эти ресурсы потребуются в будущем, удалите кластер. Нажмите кнопку "Удалить" на странице обзора кластера. При появлении всплывающего запроса подтвердите имя кластера и нажмите кнопку "Удалить".
Следующие шаги
В этом руководстве вы узнали, как подготовить кластер. Вы подключились к ней с помощью psql, создали схему и выполнили распределение данных. Вы научились запрашивать данные по одному или нескольким клиентам, а также настраивать схему для каждого клиента.
- Сведения о типах узлов кластера
- Определение оптимального начального размера кластера