Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Используйте векторный поиск в Azure Cosmos DB с клиентской библиотекой Python. Эффективно хранить и запрашивать векторные данные в приложениях.
В этом кратком руководстве используется пример набора данных отеля в файле JSON, содержащем векторы из модели text-embedding-3-small. Набор данных включает имена отелей, расположения, описания и векторные внедрения.
Найдите пример кода с подготовкой ресурсов в GitHub.
Предпосылки
подписка Azure
- Если у вас нет подписки Azure, создайте бесплатную учетную запись.
Существующий доступ к плоскости данных ресурсов Azure Cosmos DB
- Если у вас нет ресурса, создайте новый ресурс
- Брандмауэр, настроенный для разрешения доступа к IP-адресу клиента
- Назначенные роли управления доступом на основе ролей (RBAC):
- Встроенный участник данных Cosmos DB (плоскость данных)
- Идентификатор роли:
00000000-0000-0000-0000-000000000002
-
- Настраиваемый домен
- Назначенная роль управления доступом на основе ролей (RBAC):
- Пользователь OpenAI в службе Cognitive Services
- Идентификатор роли:
5e0bd9bd-7b93-4f28-af87-19fc36ad61bd
-
text-embedding-3-smallмодель, развернутая
Создание файла данных с векторами
Создайте каталог данных для файла данных отелей:
mkdir dataСкачайте файл данных raw с векторами в каталог
data:curl -o data/HotelsData_toCosmosDB_Vector.json https://raw.githubusercontent.com/Azure-Samples/cosmos-db-vector-samples/refs/heads/main/data/HotelsData_toCosmosDB_Vector.json
Создание проекта Python
Создайте новый соседний каталог для вашего проекта на том же уровне, что и каталог данных, и откройте его в Visual Studio Code.
mkdir vector-search-quickstart code vector-search-quickstartВ терминале создайте и активируйте виртуальную среду Python:
python -m venv .venvsource .venv/bin/activateСоздайте файл в корневом каталоге
requirements.txtпроекта со следующим содержимым:azure-cosmos>=4.7.0 azure-identity>=1.18.0 openai>=1.57.0 python-dotenv>=1.0.1Установите необходимые пакеты:
pip install -r requirements.txt- azure-cosmos — клиентская библиотека Azure Cosmos DB для операций с базами данных
- azure-identity — библиотека проверки подлинности Azure для подключений без пароля (управляемого удостоверения)
- openai — пакет SDK OpenAI для создания внедрения с помощью Azure OpenAI
-
Python-dotenv — загружает переменные среды из
.envфайла
Создайте файл в корневом каталоге
.envпроекта для переменных среды:# Identity for local developer authentication with Azure CLI AZURE_TOKEN_CREDENTIALS=AzureCliCredential # Azure OpenAI Embedding Settings AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small AZURE_OPENAI_EMBEDDING_API_VERSION=2024-08-01-preview AZURE_OPENAI_EMBEDDING_ENDPOINT= # Cosmos DB configuration AZURE_COSMOSDB_ENDPOINT= # Data file DATA_FILE_WITH_VECTORS=../data/HotelsData_toCosmosDB_Vector.json FIELD_TO_EMBED=Description EMBEDDED_FIELD=DescriptionVector EMBEDDING_DIMENSIONS=1536Замените значения заполнителей в
.envфайле собственными сведениями:-
AZURE_OPENAI_EMBEDDING_ENDPOINT: URL-адрес конечной точки ресурса Azure OpenAI -
AZURE_COSMOSDB_ENDPOINT: URL-адрес конечной точки Azure Cosmos DB
-
Общие сведения о схеме документа
Прежде чем создавать приложение, понять, как векторы хранятся в документах Azure Cosmos DB. Каждый документ отеля содержит следующее:
-
Стандартные поля:
HotelId,HotelName,Description,Categoryи т. д. -
Поле вектора:
DescriptionVectorмассив из 1536 чисел с плавающей запятой, представляющий семантический смысл описания отеля.
Ниже приведен упрощенный пример структуры документа отеля:
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "This classic hotel is fully-refurbished...",
"Rating": 3.6,
"DescriptionVector": [
-0.04886505,
-0.02030743,
0.01763356,
...
// 1536 dimensions total
]
}
Ключевые моменты, касающиеся хранения эмбеддингов:
- Массивы векторов хранятся в виде стандартных массивов JSON в документах
-
Политика векторов определяет путь (), тип данных (
/DescriptionVectorfloat32), измерения (1536) и функцию расстояния (косинус) - Политика индексирования создает векторный индекс в поле вектора для эффективного поиска сходства.
- Поле вектора должно быть исключено из стандартного индексирования для оптимизации производительности вставки
Эти политики определены в шаблонах Bicep для метрик расстояния для этого примера проекта. Дополнительные сведения о векторных политиках и индексировании см. в разделе Поиск векторов в Azure Cosmos DB.
Создание файлов кода для векторного поиска
Создайте каталог src для файлов Python. Добавьте два файла: vector_search.py и utils.py для реализации векторного поиска:
mkdir src
touch src/__init__.py
touch src/vector_search.py
touch src/utils.py
Создание кода для векторного поиска
Вставьте следующий код в vector_search.py файл.
"""Azure Cosmos DB NoSQL Vector Search — main entry point.
Loads hotel data, bulk-inserts into the selected container (DiskANN or
QuantizedFlat), generates a query embedding via Azure OpenAI, and
executes a VectorDistance() similarity search.
"""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
sys.path.insert(0, str(Path(__file__).parent))
from utils import (
get_clients_passwordless,
get_clients,
insert_data,
print_search_results,
read_file_return_json,
validate_field_name,
get_query_activity_id,
)
# ---------------------------------------------------------------------------
# Load environment
# ---------------------------------------------------------------------------
load_dotenv()
ALGORITHM_CONFIGS: dict[str, dict[str, str]] = {
"diskann": {
"container_name": "hotels_diskann",
"algorithm_name": "DiskANN",
},
"quantizedflat": {
"container_name": "hotels_quantizedflat",
"algorithm_name": "QuantizedFlat",
},
}
def _build_config() -> dict[str, str | int]:
"""Build runtime configuration from environment variables."""
return {
"query": "quintessential lodging near running trails, eateries, retail",
"db_name": os.getenv("AZURE_COSMOSDB_DATABASENAME", "Hotels"),
"algorithm": os.getenv("VECTOR_ALGORITHM", "diskann").strip().lower(),
"data_file": os.getenv("DATA_FILE_WITH_VECTORS", "../data/HotelsData_toCosmosDB_Vector.json"),
"embedded_field": os.getenv("EMBEDDED_FIELD", "DescriptionVector"),
"embedding_dimensions": int(os.getenv("EMBEDDING_DIMENSIONS", "1536")),
"deployment": os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "text-embedding-3-small"),
"distance_function": os.getenv("VECTOR_DISTANCE_FUNCTION", "cosine"),
}
def main() -> None:
"""Run the vector search demonstration."""
config = _build_config()
# Try passwordless auth first, fall back to key-based
clients = get_clients_passwordless()
if not clients["ai_client"] or not clients["db_client"]:
clients = get_clients()
ai_client = clients["ai_client"]
db_client = clients["db_client"]
try:
algorithm = config["algorithm"]
if algorithm not in ALGORITHM_CONFIGS:
valid = ", ".join(ALGORITHM_CONFIGS)
raise ValueError(
f"Invalid algorithm '{algorithm}'. Must be one of: {valid}"
)
if not ai_client:
raise RuntimeError(
"Azure OpenAI client is not configured. "
"Please check your environment variables."
)
if not db_client:
raise RuntimeError(
"Cosmos DB client is not configured. "
"Please check your environment variables."
)
algo_cfg = ALGORITHM_CONFIGS[algorithm]
container_name = algo_cfg["container_name"]
database = db_client.get_database_client(config["db_name"])
print(f"Connected to database: {config['db_name']}")
container = database.get_container_client(container_name)
print(f"Connected to container: {container_name}")
print(f"\n📊 Vector Search Algorithm: {algo_cfg['algorithm_name']}")
print(f"📏 Distance Function: {config['distance_function']}")
# Verify the container exists
try:
container.read()
except Exception as e:
status_code = getattr(e, "status_code", None)
if status_code == 404:
raise RuntimeError(
f"Container or database not found. Ensure database "
f"'{config['db_name']}' and container '{container_name}' "
f"exist before running this script."
) from e
raise
data_path = Path(__file__).parent.parent / config["data_file"]
data = read_file_return_json(str(data_path))
insert_data(container, data)
embedding_response = ai_client.embeddings.create(
model=config["deployment"],
input=[config["query"]],
)
query_embedding = embedding_response.data[0].embedding
safe_field = validate_field_name(config["embedded_field"])
query_text = (
f"SELECT TOP 5 c.HotelName, c.Description, c.Rating, "
f"VectorDistance(c.{safe_field}, @embedding) AS SimilarityScore "
f"FROM c "
f"ORDER BY VectorDistance(c.{safe_field}, @embedding)"
)
print("\n--- Executing Vector Search Query ---")
print(f"Query: {query_text}")
print(
f"Parameters: @embedding (vector with {len(query_embedding)} dimensions)"
)
print("--------------------------------------\n")
results = list(
container.query_items(
query=query_text,
parameters=[{"name": "@embedding", "value": query_embedding}],
enable_cross_partition_query=True,
)
)
# Extract diagnostics
response_headers = container.client_connection.last_response_headers
activity_id = get_query_activity_id(response_headers)
if activity_id:
print(f"Query activity ID: {activity_id}")
request_charge_raw = response_headers.get("x-ms-request-charge", "0") if response_headers else "0"
try:
request_charge = float(request_charge_raw)
except (ValueError, TypeError):
request_charge = 0.0
print_search_results(results, request_charge)
except Exception as error:
print(f"App failed: {error}", file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
main()
Этот код:
- Настраивает либо векторный алгоритм
DiskANN, либоquantizedFlatна основе переменных среды. - Подключается к Azure OpenAI и Azure Cosmos DB с помощью проверки подлинности без пароля.
- Загружает предварительно векторные данные отеля из JSON-файла.
- Вставляет данные в соответствующий контейнер.
- Создает внедрение для запроса естественного языка (
quintessential lodging near running trails, eateries, retail). -
VectorDistanceВыполняет SQL-запрос, чтобы получить первые 5 самых семантических аналогичных отелей, ранжированных по оценке сходства. - Обрабатывает ошибки для отсутствующих клиентов, неверного выбора алгоритма и несуществующих контейнеров/баз данных.
Общие сведения о коде. Создание внедрения с помощью Azure OpenAI
Код создает внедрения для текста запроса:
embedding_response = ai_client.embeddings.create(
model=config["deployment"], # OpenAI embedding model, e.g. "text-embedding-3-small"
input=[config["query"]], # List of description strings to embed
)
query_embedding = embedding_response.data[0].embedding
Этот вызов API OpenAI для client.embeddings.create преобразует текст, такой как "квинтэссенциальное размещение вблизи беговых дорожек", в вектор размерностью 1536, который отражает его семантический смысл. Дополнительные сведения о создании встраиваний см. в документации Azure для OpenAI.
Общие сведения о коде. Хранение векторов в Azure Cosmos DB
Все документы с векторными массивами вставляются с помощью upsert_item функции:
for item in data:
doc = {"id": item["HotelId"], **item}
response = container.upsert_item(body=doc)
Эта операция вставляет документы отеля в контейнер, включая предварительно созданные DescriptionVector массивы. Каждый документ получает id поле, сопоставленное с HotelId, и функция обрабатывает upserts, чтобы документы можно было безопасно вставлять.
Общие сведения о коде. Выполнение поиска сходства векторов
Код выполняет векторный поиск с помощью VectorDistance функции:
query_text = (
f"SELECT TOP 5 c.HotelName, c.Description, c.Rating, "
f"VectorDistance(c.{safe_field}, @embedding) AS SimilarityScore "
f"FROM c "
f"ORDER BY VectorDistance(c.{safe_field}, @embedding)"
)
results = list(
container.query_items(
query=query_text,
parameters=[{"name": "@embedding", "value": query_embedding}],
enable_cross_partition_query=True,
)
)
Этот код создает параметризованный SQL-запрос, использующий функцию VectorDistance для сравнения вектора вложения запроса (@embedding) с полем хранимого вектора каждого документа (DescriptionVector), возвращая топ-5 отелей с их именами и оценками сходства, упорядоченных от наиболее похожих к наименее похожим. Встраиваемый запрос передается в качестве параметра, чтобы избежать инъекций, и поступает из предыдущего вызова Azure OpenAI embeddings.create.
Что возвращает этот запрос:
- Топ-5 самых похожих отелей на основе векторного расстояния
- Свойства отеля:
HotelName,DescriptionRating -
SimilarityScore: числовое значение, указывающее, насколько похож каждый отель на запрос - Результаты, отсортированные от наиболее похожих к наименее похожим
Дополнительные сведения о функции см. в VectorDistanceдокументации VectorDistance.
Создание служебных функций
Вставьте следующий код в utils.py:
"""Shared utilities for Azure Cosmos DB NoSQL vector search.
Provides client initialization (passwordless and key-based), JSON I/O,
bulk insert with RU tracking, field validation, and result formatting.
"""
import json
import os
import re
import time
from typing import Any, Optional
def get_clients() -> dict[str, Any]:
"""Get Azure OpenAI and Cosmos DB clients using key-based authentication.
Returns dict with 'ai_client' and 'db_client' (either may be None if
the required environment variables are missing).
"""
from azure.cosmos import CosmosClient
from openai import AzureOpenAI
ai_client = None
db_client = None
api_key = os.getenv("AZURE_OPENAI_EMBEDDING_KEY", "")
api_version = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "")
endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT", "")
deployment = os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "")
if api_key and api_version and endpoint and deployment:
ai_client = AzureOpenAI(
api_key=api_key,
api_version=api_version,
azure_endpoint=endpoint,
azure_deployment=deployment,
)
cosmos_endpoint = os.getenv("AZURE_COSMOSDB_ENDPOINT", "")
cosmos_key = os.getenv("AZURE_COSMOSDB_KEY", "")
if cosmos_endpoint and cosmos_key:
db_client = CosmosClient(url=cosmos_endpoint, credential=cosmos_key)
return {"ai_client": ai_client, "db_client": db_client}
def get_clients_passwordless() -> dict[str, Any]:
"""Get Azure OpenAI and Cosmos DB clients using DefaultAzureCredential.
Uses managed identity / Azure CLI credentials for passwordless auth.
Returns dict with 'ai_client' and 'db_client' (either may be None).
"""
from azure.cosmos import CosmosClient
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from openai import AzureOpenAI
ai_client = None
db_client = None
api_version = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "")
endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT", "")
deployment = os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "")
if api_version and endpoint and deployment:
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
credential, "https://cognitiveservices.azure.com/.default"
)
ai_client = AzureOpenAI(
api_version=api_version,
azure_endpoint=endpoint,
azure_deployment=deployment,
azure_ad_token_provider=token_provider,
)
cosmos_endpoint = os.getenv("AZURE_COSMOSDB_ENDPOINT", "")
if cosmos_endpoint:
credential = DefaultAzureCredential()
db_client = CosmosClient(url=cosmos_endpoint, credential=credential)
return {"ai_client": ai_client, "db_client": db_client}
def read_file_return_json(file_path: str) -> list[dict[str, Any]]:
"""Read a JSON file and return its parsed contents."""
print(f"Reading JSON file from {file_path}")
try:
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
except FileNotFoundError:
print(f"Error: File '{file_path}' not found")
raise
except json.JSONDecodeError as e:
print(f"Error: Invalid JSON in file '{file_path}': {e}")
raise
def write_file_json(file_path: str, json_data: Any) -> None:
"""Serialize data to a JSON file."""
try:
with open(file_path, "w", encoding="utf-8") as f:
json.dump(json_data, f, indent=2, ensure_ascii=False)
print(f"Wrote JSON file to {file_path}")
except IOError as e:
print(f"Error writing to file '{file_path}': {e}")
raise
def _get_document_count(container: Any) -> int:
"""Return the number of documents in a Cosmos DB container."""
query = "SELECT VALUE COUNT(1) FROM c"
results = list(container.query_items(query=query, enable_cross_partition_query=True))
return results[0] if results else 0
def insert_data(
container: Any, data: list[dict[str, Any]]
) -> dict[str, Any]:
"""Bulk-insert documents into a Cosmos DB container.
Skips insertion if the container already has documents.
Each item gets an 'id' field mapped from 'HotelId'.
Returns a dict with total, inserted, failed, skipped, and requestCharge.
"""
existing_count = _get_document_count(container)
if existing_count > 0:
print(f"Container already has {existing_count} documents. Skipping insert.")
return {
"total": 0,
"inserted": 0,
"failed": 0,
"skipped": existing_count,
"requestCharge": 0.0,
}
print(f"Inserting {len(data)} items...")
inserted = 0
failed = 0
total_request_charge = 0.0
start_time = time.time()
for item in data:
doc = {"id": item["HotelId"], **item}
try:
response = container.upsert_item(body=doc)
inserted += 1
ru = _extract_ru_from_headers(container.client_connection.last_response_headers)
total_request_charge += ru
except Exception as e:
status_code = getattr(e, "status_code", None)
if status_code == 409:
inserted += 1
else:
failed += 1
print(f" Insert failed for item {item.get('HotelId', '?')}: {e}")
duration = time.time() - start_time
print(f"Bulk insert completed in {duration:.2f}s")
print(f"\nInsert Request Charge: {total_request_charge:.2f} RUs\n")
return {
"total": len(data),
"inserted": inserted,
"failed": failed,
"skipped": 0,
"requestCharge": total_request_charge,
}
def _extract_ru_from_headers(headers: Optional[dict[str, str]]) -> float:
"""Extract the request charge (RU) from Cosmos DB response headers."""
if not headers:
return 0.0
raw = headers.get("x-ms-request-charge", "0")
try:
return float(raw)
except (ValueError, TypeError):
return 0.0
def validate_field_name(field_name: str) -> str:
"""Validate a field name is a safe SQL identifier.
Prevents NoSQL injection when interpolating field names into queries.
Allows only letters, digits, and underscores; must start with a letter
or underscore.
Raises ValueError if the field name is invalid.
"""
pattern = re.compile(r"^[A-Za-z_][A-Za-z0-9_]*$")
if not pattern.match(field_name):
raise ValueError(
f'Invalid field name: "{field_name}". '
"Field names must start with a letter or underscore and "
"contain only letters, numbers, and underscores."
)
return field_name
def print_search_results(
search_results: list[dict[str, Any]],
request_charge: Optional[float] = None,
) -> None:
"""Print vector search results in a consistent format."""
print("\n--- Search Results ---")
if not search_results:
print("No results found.")
return
for i, result in enumerate(search_results, 1):
score = result.get("SimilarityScore", 0.0)
name = result.get("HotelName", "Unknown")
print(f"{i}. {name}, Score: {score:.4f}")
if request_charge is not None:
print(f"\nVector Search Request Charge: {request_charge:.2f} RUs")
print("")
def get_query_activity_id(response_headers: Optional[dict[str, str]]) -> Optional[str]:
"""Extract the activity ID from Cosmos DB query response headers."""
if not response_headers:
return None
return response_headers.get("x-ms-activity-id")
def get_bulk_operation_rus(headers: Optional[dict[str, str]]) -> float:
"""Extract total RU cost from Cosmos DB response headers."""
return _extract_ru_from_headers(headers)
Этот модуль служебной программы предоставляет следующие ключевые функции:
-
get_clients_passwordless: создает и возвращает клиентов для Azure OpenAI и Azure Cosmos DB, используя аутентификацию без пароля. Включение RBAC в обоих ресурсах и вход в Azure CLI -
insert_data: вставляет данные в контейнер Azure Cosmos DB и отслеживает единицы запросов (ЕЗ) для каждой операции. -
print_search_results: выводит результаты векторного поиска, включая оценку и название отеля -
validate_field_name: проверяет наличие имени поля в данных -
get_bulk_operation_rus: извлекает общую стоимость единиц запросов (RU) из заголовков ответа Azure Cosmos DB
Проверка подлинности с помощью Azure CLI
Войдите в Azure CLI перед запуском приложения, чтобы приложение могло безопасно получить доступ к ресурсам Azure.
az login
Код использует локальную аутентификацию разработчика для доступа к Azure Cosmos DB и Azure OpenAI с использованием функции get_clients_passwordless из utils.py. При установке AZURE_TOKEN_CREDENTIALS=AzureCliCredentialвы детерминированно выбираете учетные данные DefaultAzureCredential , которые используются в своей цепочке учетных данных. Функция использует DefaultAzureCredential из azure-identity, которая выполняет упорядоченную цепочку поставщиков учетных данных, но учитывает переменную среды, чтобы сначала разрешить Azure CLI учетные данные. Узнайте больше о том, как аутентифицировать приложения Python для служб Azure с помощью библиотеки Azure Identity.
Запуск приложения
VECTOR_ALGORITHM Используйте переменную среды, чтобы выбрать реализацию векторного индекса для выполнения. Переменная управляет Azure Cosmos DB контейнером, к которому подключается приложение.
Linux или MacOS:
VECTOR_ALGORITHM=diskann python -m src.vector_search
Виндоус:
$env:VECTOR_ALGORITHM="diskann"; python -m src.vector_search
В журнале приложений и выходных данных отображается следующее:
- Состояние подключения контейнера
- Состояние вставки данных
- Результаты поиска с именами отелей и оценками сходства
Connected to database: Hotels
Connected to container: hotels_diskann
📊 Vector Search Algorithm: DiskANN
📏 Distance Function: cosine
Reading JSON file from ..\data\HotelsData_toCosmosDB_Vector.json
Container already has 50 documents. Skipping insert.
--- Executing Vector Search Query ---
Query: SELECT TOP 5 c.HotelName, c.Description, c.Rating, VectorDistance(c.DescriptionVector, @embedding) AS SimilarityScore FROM c ORDER BY VectorDistance(c.DescriptionVector, @embedding)
Parameters: @embedding (vector with 1536 dimensions)
--------------------------------------
Query activity ID: <ACTIVITY_ID>
--- Search Results ---
1. Royal Cottage Resort, Score: 0.4991
2. Country Comfort Inn, Score: 0.4786
3. Nordick's Valley Motel, Score: 0.4635
4. Economy Universe Motel, Score: 0.4461
5. Roach Motel, Score: 0.4388
Vector Search Request Charge: 5.33 RUs
Метрики расстояния
Azure Cosmos DB поддерживает три функции расстояния для сходства векторов:
| Функция расстояния | Диапазон показателей | Интерпретация | Лучше всего подходит для |
|---|---|---|---|
| Cosine (по умолчанию) | от 0.0 до 1.0 | Более высокие оценки (ближе к 1.0) указывают на большее сходство | Общее сходство текста, встраивания Azure OpenAI (используемые в этом кратком руководстве) |
| Эвклидан (L2) | 0.0 до ∞ | Lower = больше сходства | Пространственные данные, когда важна значимость |
| Dot Product | -∞ до +∞ | Более высокий = более похожий | Когда величины векторов нормализуются |
Функция расстояния задается в политике внедрения вектора при создании контейнера. Это предоставляется в инфраструктуре в примере репозитория. Он определяется как часть определения контейнера.
{
name: 'hotels_diskann'
partitionKeyPaths: [
'/HotelId'
]
indexingPolicy: {
indexingMode: 'consistent'
automatic: true
includedPaths: [
{
path: '/*'
}
]
excludedPaths: [
{
path: '/_etag/?'
}
{
path: '/DescriptionVector/*'
}
]
vectorIndexes: [
{
path: '/DescriptionVector'
type: 'diskANN'
}
]
}
vectorEmbeddingPolicy: {
vectorEmbeddings: [
{
path: '/DescriptionVector'
dataType: 'float32'
dimensions: 1536
distanceFunction: 'cosine'
}
]
}
}
Этот код Bicep определяет конфигурацию контейнера Azure Cosmos DB для хранения документов отеля с возможностями векторного поиска.
| Недвижимость | Description |
|---|---|
partitionKeyPaths |
Разделяет документы по HotelId для распределенного хранения. |
indexingPolicy |
Настраивает автоматическое индексирование во всех свойствах документа (/*) за исключением поля системы _etag и массива DescriptionVector для оптимизации производительности записи. Вместо этого поля векторов не требуют стандартного индексирования, так как они используют специализированную vectorIndexes конфигурацию. |
vectorIndexes |
Создает индекс DiskANN или quantizedFlat на пути /DescriptionVector для эффективного поиска сходства. |
vectorEmbeddingPolicy |
Определяет характеристики векторного поля: float32 тип данных с 1536 измерениями (соответствующими text-embedding-3-small выходным данным модели) и косинусом в качестве функции расстояния для измерения сходства между векторами во время запросов. |
Интерпретация показателей сходства
В примере выходных данных с использованием сходства косинуса:
- 0.4991 (Royal Cottage Resort) - Наибольшее сходство, лучшее совпадение для "жилье поблизости от беговых троп, ресторанов, розничной торговли"
- 0.4388 (Roach Motel) - Низкое сходство, всё ещё актуальна, но менее подходящая
- Оценки ближе к 1.0 указывают на более сильную семантику сходства
- Оценки около 0 указывают на небольшое сходство
Важные заметки:
- Абсолютные значения оценки зависят от модели внедрения и данных
- Сосредоточьтесь на относительном ранжировании , а не на абсолютных пороговых значениях
- Эмбеддинги Azure OpenAI лучше всего работают с косинусным сходством
Подробные сведения о функциях расстояния см. в разделе "Что такое функции расстояния"?
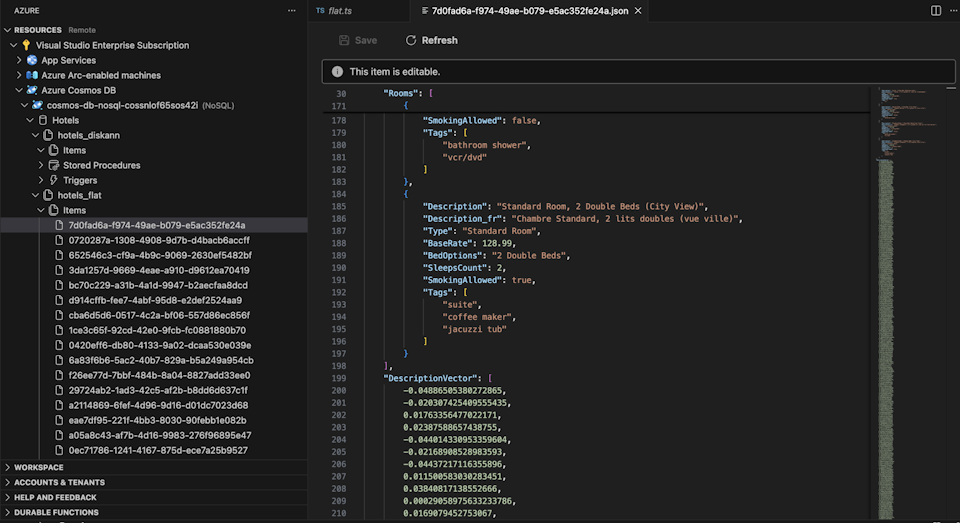
Просмотр данных и управление ими в Visual Studio Code
Выберите расширение Cosmos DB в Visual Studio Code для подключения к учетной записи Azure Cosmos DB.
Просмотрите данные и индексы в базе данных Hotels.

Очистите ресурсы
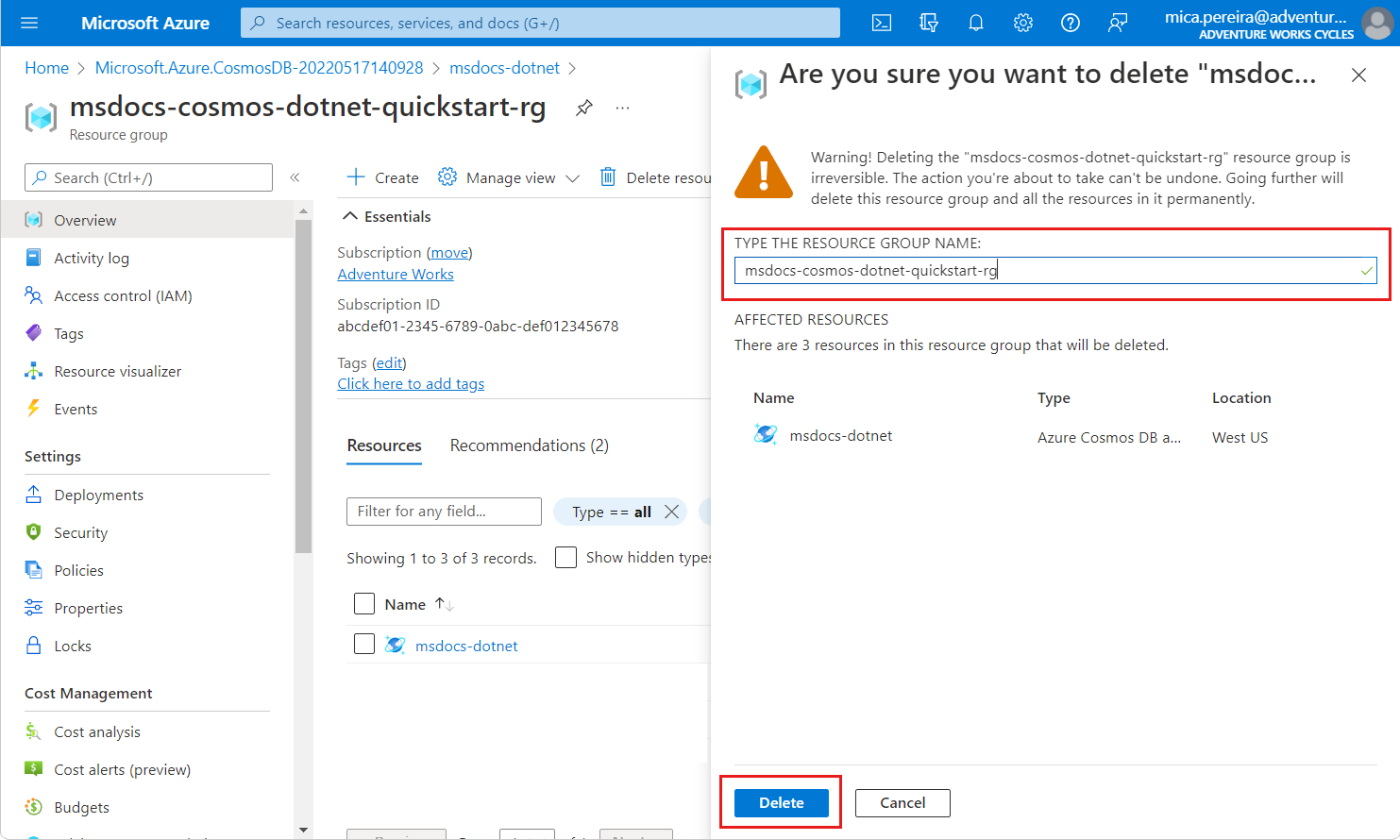
Если вам больше не нужен API для учетной записи NoSQL, можно удалить соответствующую группу ресурсов.
Перейдите к группе ресурсов, созданной ранее на портале Azure.
Tip
В этом кратком руководстве мы рекомендовали имя
msdocs-cosmos-quickstart-rg.Выберите команду Удалить группу ресурсов.
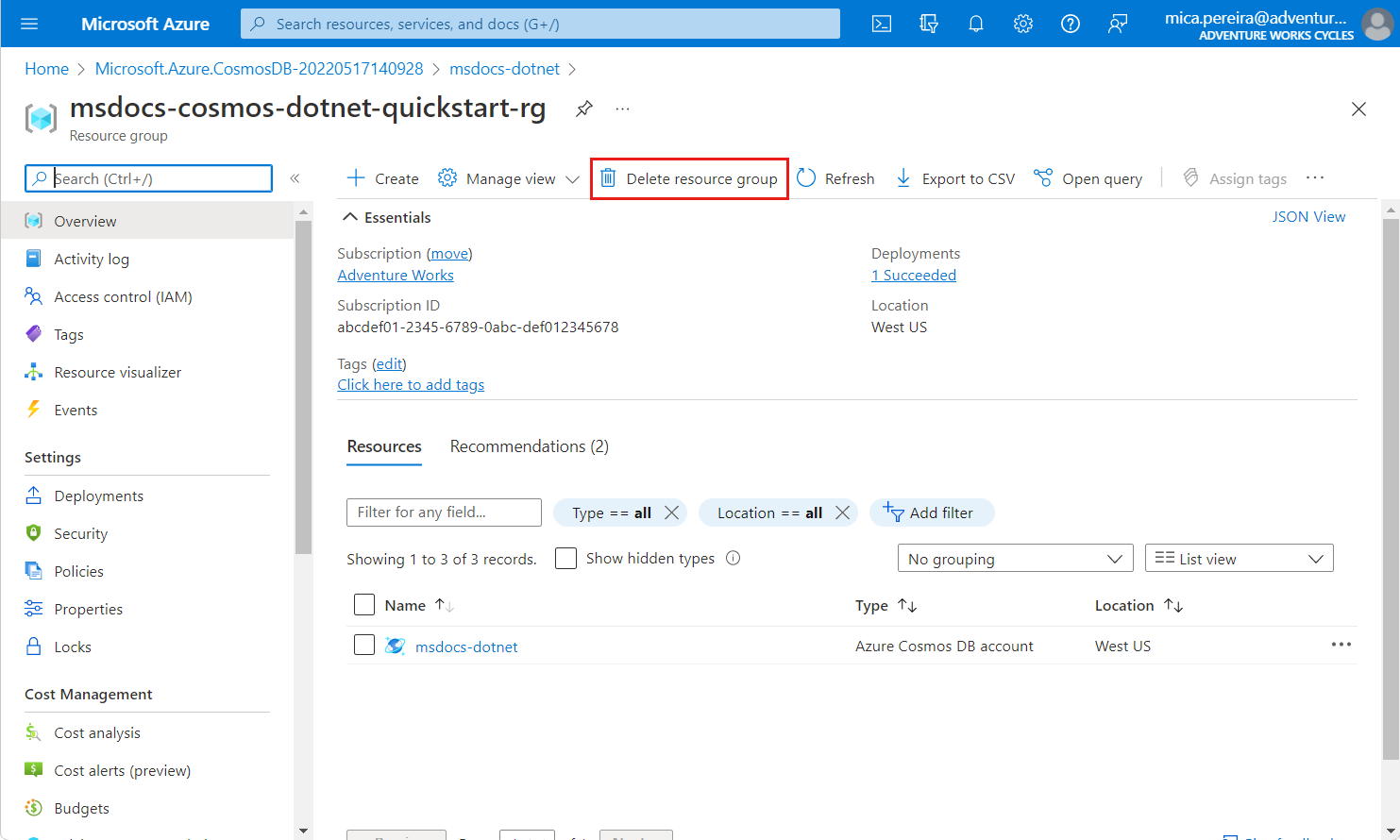
В диалоговом окне "Удалить" введите имя группы ресурсов и нажмите кнопку "Удалить".