Рекомендации по масштабированию подготовленной пропускной способности (ЕЗ/с)
Область применения: ![]() Nosql
Nosql ![]() Mongodb
Mongodb ![]() Кассандра
Кассандра ![]() Гремлин
Гремлин ![]() Таблица
Таблица
В этой статье описаны лучшие практики и стратегии масштабирования пропускной способности (ЕЗ) вашей базы данных или контейнера (коллекции, таблицы или графа). Эти концепции применимы, когда вы увеличиваете либо предоставленные вручную ЕЗ, либо автомасштабируемые максимальные ЕЗ любого ресурса для любого из API Azure Cosmos DB.
Необходимые компоненты
- Если вы новичок в секционировании и масштабировании в Azure Cosmos DB, рекомендуется сначала прочитать статью Секционирование и горизонтальное масштабирование в Azure Cosmos DB.
- Если вы планируете масштабировать ЕЗ из-за исключений 429, ознакомьтесь с руководством в разделе Диагностика и устранение исключений Azure Cosmos DB request rate too large (429) (Слишком большой объем запросов Azure Cosmos DB (429)). Перед увеличением ЕЗ определите основную причину проблемы и выясните, является ли увеличение количества ЕЗ правильным решением.
Историческая справка масштабирования ЕЗ
Когда вы отправляете запрос на увеличение количества ЕЗ вашей базы данных или контейнера, в зависимости от запрашиваемого количества ЕЗ и текущего расположения физических разделов, операция масштабирования будет выполнена либо мгновенно, либо асинхронно (обычно 4-6 часов).
- Мгновенное вертикальное масштабирование
- Если запрашиваемые вами ЕЗ могут быть поддержаны текущей схемой физических секций, Azure Cosmos DB не нужно разделять или добавлять новые секции.
- В результате операция сразу же завершится, и ЕЗ будут доступны для использования.
- Асинхронное вертикальное масштабирование
- Если запрашиваемая ЕЗ превышает поддерживаемые физическим макетом секции, Azure Cosmos DB будет разделять существующие физические разделы. Это происходит до тех пор, пока у ресурса не будет минимальное количество разделов, необходимых для поддержки запрашиваемого количества ЕЗ.
- В результате операция может занять некоторое время (обычно 4–6 часов). Каждый физический раздел может поддерживать максимум 10 000 ЕЗ (относится ко всем API) пропускной способности и 50 ГБ памяти (относится ко всем API, кроме Cassandra, которая имеет 30 ГБ памяти).
Примечание.
Если вы выполните операцию обхода отказа в регионе вручную или добавления/удаления нового региона во время выполнения операции асинхронного увеличения масштаба, операция увеличения масштаба пропускной способности будет приостановлена. Она будет автоматически возобновлена после завершения операции отработки отказа или добавления/удаления региона.
- Мгновенное вертикальное уменьшение масштаба
- Для уменьшения масштаба Azure Cosmos DB не нужно выполнять разделение или добавлять новые секции.
- В результате операция сразу же завершится, и ЕЗ будут доступны для использования.
- Главным результатом этой операции является уменьшение количества ЕЗ на физическую секцию.
Как масштабировать ЕЗ без изменения макета секций
Шаг 1. Найдите текущее количество физических секций.
Перейдите в раздел Аналитика>Пропускная способность>Нормализованное потребление на единицу запроса (%) по PartitionKeyRangeID. Подсчитайте количество отдельных идентификаторов PartitionKeyRangeIds.
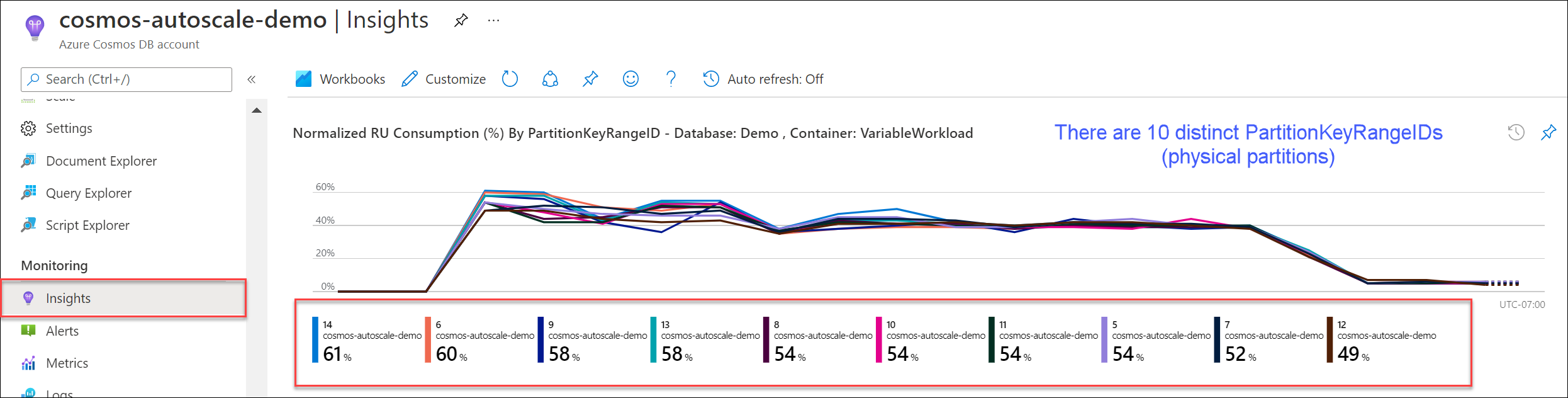
Примечание.
На диаграмме будет не более 50 идентификаторов PartitionKeyRangeIds. Если ваш ресурс имеет более 50 идентификаторов, вы можете использовать REST API Azure Cosmos DB для подсчета общего количества секций.
Каждый PartitionKeyRangeId сопоставляется с одной физической секцией и назначается для хранения данных для диапазона возможных значений хэша.
Azure Cosmos DB распределяет ваши данные по логическим и физическим секциям на основе ключа раздела для обеспечения горизонтального масштабирования. По мере написания данных Azure Cosmos DB использует хэш значения ключа секции, чтобы определить, на каком логическом и физическом разделе находятся данные.
Шаг 2. Расчет максимальной пропускной способности по умолчанию
Наибольшее количество ЕЗ, до которого можно выполнить масштабирование без запуска Azure Cosmos DB для разделения на секции, равно Current number of physical partitions * 10,000 RU/s. Это значение можно получить от поставщика ресурсов Azure Cosmos DB. Выполните запрос GET для объектов параметров пропускной способности базы данных или контейнера и получите instantMaximumThroughput это свойство. Это значение также доступно на странице "Масштаб и параметры" базы данных или контейнера на портале.
Пример
Предположим, у нас есть существующий контейнер с пятью физическими секциями и пропускной способностью 30 000 ЕЗ, обеспечиваемой вручную. Мы можем мгновенно увеличить количество ЕЗ до 5 * 10 000 ЕЗ = 50 000 ЕЗ. Аналогично, если бы у нас был контейнер с автомасштабируемым максимальным количеством ЕЗ — 30 000 ЕЗ (масштабируется в диапазоне 3000 — 30 000 ЕЗ), мы могли бы мгновенно увеличить максимальное количество ЕЗ до 50 000 ЕЗ (масштабируется в диапазоне 5000 — 50 000 ЕЗ).
Совет
Если вы увеличиваете количество ЕЗ для ответа на слишком большие исключения (429), рекомендуется сначала увеличить количество ЕЗ до максимального, которое поддерживаются текущим расположением физических секций, и оценить, достаточно ли новых ЕЗ перед дальнейшим увеличением.
Как обеспечить равномерное распределение данных при асинхронном масштабировании
Общие сведения
Когда вы увеличиваете количество ЕЗ сверх текущего количества физических секций * 10 000 ЕЗ, Azure Cosmos DB разделяет существующие разделы, пока новое количество разделов не будет = ROUNDUP(requested RU/s / 10,000 RU/s). Во время разделения родительские секции разделяются на две дочерних.
Например, предположим, у нас есть контейнер с тремя физическими секциями и пропускной способностью 30 000 ЕЗ, обеспечиваемой вручную. Если мы увеличим пропускную способность до 45 000 ЕЗ, Azure Cosmos DB разделит две из существующих физических секций так, что в общей сложности будет ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 физических секций.
Примечание.
Во время разделения приложения всегда могут принимать или запрашивать данные. Клиентские пакеты SDK и сервис Azure Cosmos DB автоматически обрабатывают этот сценарий и гарантируют, что запросы направляются в правильную физическую секцию, поэтому никаких дополнительных действий от пользователя не требуется.
Если у вас есть рабочая нагрузка, которая очень равномерно распределена по хранилищу и объему запросов — обычно это достигается путем разделения по полям высокой кратности, таким как /id — рекомендуется при масштабировании установить ЕЗ таким образом, чтобы все секции были разделены равномерно.
Чтобы понять, почему, давайте рассмотрим пример, где у нас есть существующий контейнер с 2 физическими секциями, 20 000 ЕЗ и 80 ГБ данных.
Благодаря выбору хорошего ключа секции с высокой кратностью, данные примерно равномерно распределены в обоих физических секциях. Каждой физической секции отводится примерно 50 % ключевого пространства, которое определяется как общий диапазон возможных значений хэша.
Кроме того, Azure Cosmos DB равномерно распределяет ЕЗ по всем физическим секциям. В результате каждая физическая секция имеет 10 000 ЕЗ и 50 % (40 ГБ) от общего объема данных. На схеме ниже показано текущее состояние.

Теперь предположим, что мы хотим увеличить количество ЕЗ с 20 000 ЕЗ до 30 000 ЕЗ.
Если мы просто увеличим количество ЕЗ до 30 000 ЕЗ, только один из разделов будет разделен. После разделения мы будем иметь:
- Одна секция, содержащая 50 % данных (эта секция не была разделена)
- Две секции, которые содержат 25 % данных в каждой из них (это итоговая часть родительской секции, которая была разделена)
Так как Azure Cosmos DB равномерно распространяет ЕЗ во всех физических секциях, каждая физическая секция по-прежнему будет получать 10 000 ЕЗ. Однако сейчас мы имеем отклонение в хранении и распределении запросов.
На следующей диаграмме мы видим, что секции 3 и 4 (дочерние секции от секции 2) имеют по 10 000 ЕЗ для обслуживания запросов на 20 ГБ данных, а секция 1 имеет 10 000 ЕЗ для обслуживания запросов на вдвое больший объем данных (40 ГБ).

Для поддержания равномерного распределения хранилища мы можем сначала увеличить количество ЕЗ, чтобы обеспечить разделение каждой секции. Затем мы можем уменьшить ЕЗ до желаемого уровня.
Итак, если мы начинаем с двух физических секций, чтобы гарантировать, что секции будут равномерными после разделения, нам нужно установить ЕЗ таким образом, чтобы в итоге у нас было четыре физических секции. Для этого сначала установим ЕЗ = 4 * 10 000 ЕЗ на раздел = 40 000 ЕЗ. Затем, после завершения разделения, мы можем снизить наше количество ЕЗ до 30 000 ЕЗ.
В результате на следующей диаграмме мы видим, что каждая физическая секция получает 30 000 ЕЗ / 4 = 7500 ЕЗ для обслуживания запросов на 20 ГБ данных. В целом, мы поддерживаем равномерное хранение и распределение запросов по секциям.
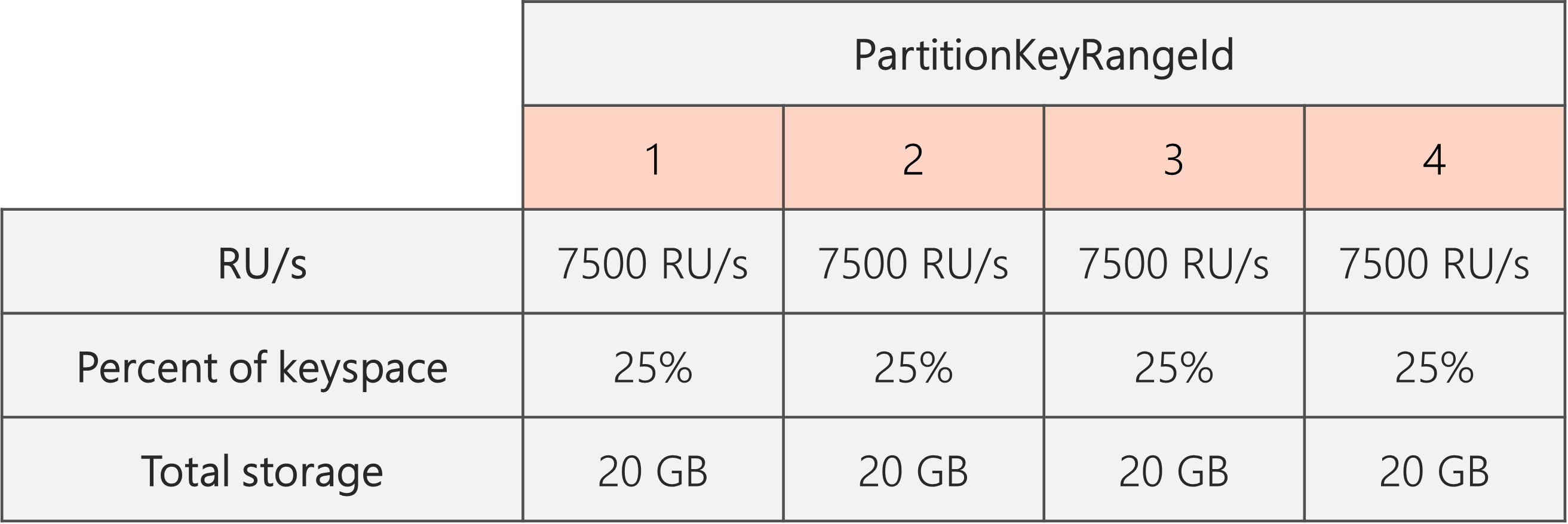
Общая формула
Шаг 1. Увеличьте количество ЕЗ, чтобы гарантировать равномерное разделение всех секций
В общем, если у вас есть начальное количество физических секций P, и вы хотите установить желаемое количество ЕЗ S:
Увеличьте количество ЕЗ до: 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). Это дает наиболее близкое к желаемому значение ЕЗ, которое обеспечит равномерное распределение всех секций.
Примечание.
Когда вы увеличиваете ЕЗ базы данных или контейнера, это может повлиять на минимальное количество ЕЗ, до которого вы можете опуститься в будущем. Как правило, минимальный ЕЗ/с равен MAX(400 ЕЗ/с, текущее хранилище в ГБ * 1 ЕЗ/с, самый высокий ЕЗ/с, когда-либо подготовленный / 100). Например, если самый высокий показатель ЕЗ, до которого вы когда-либо масштабировали, составляет 100 000 ЕЗ, то самый низкий показатель ЕЗ, который вы можете установить в будущем, составляет 1000 ЕЗ. Узнайте больше о минимальном значении ЕЗ.
Шаг 2. Понижение количества ЕЗ до нужного
Например, предположим, что у нас есть пять физических секций, 50 000 ЕЗ и мы хотим масштабироваться до 150 000 ЕЗ. Сначала мы должны установить: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200 000 ЕЗ, а затем снизить до 150 000 ЕЗ.
Когда мы увеличили масштаб до 200 000 ЕЗ, самый низкий уровень ЕЗ, указанный вручную, который мы можем установить в будущем, составляет 2000 ЕЗ. Самое низкое значение максимального автомасштабирования ЕЗ, которое мы можем установить, составляет 20 000 ЕЗ (масштабируется в диапазоне от 2000 до 20 000 ЕЗ). Поскольку наше целевое количество составляет 150 000 ЕЗ, минимальное количество на нас не влияет.
Оптимизация ЕЗ для передачи больших данных
Если вы планируете миграцию или ввод большого объема данных в Azure Cosmos DB, рекомендуется установить ЕЗ контейнера таким образом, чтобы Azure Cosmos DB заранее подготовил физические секции, необходимые для хранения общего объема данных, которые вы планируете ввести. В противном случае во время ввода данных Azure Cosmos DB может потребоваться разделить на секции, что увеличит время ввода данных.
Мы можем воспользоваться тем, что во время создания контейнера Azure Cosmos DB использует эвристическую формулу стартового количества ЕЗ для расчета количества физических секций, с которых нужно начать.
Шаг 1. Просмотр выбора секции
Следуйте лучшим рекомендациям при выборе ключа секции, чтобы обеспечить равномерное распределение тома запросов и хранилища после миграции.
Шаг 2. Расчет количества необходимых физических секций
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Каждая физическая секция может содержать не более 50 ГБ хранилища (30 ГБ для API для Cassandra). Значение Target data per physical partition in GB зависит от того, насколько полно должны быть упакованы физические секции и насколько вырастет хранилище после миграции.
Например, если вы предполагаете, что объем хранилища будет продолжать расти, вы можете установить значение 30 ГБ. Предполагая, что вы выбрали хороший ключ секции, который равномерно распределяет хранение, каждая секция будет заполнена на ~60 % (30 ГБ из 50 ГБ). По мере записи будущих данных они могут храниться на существующем наборе физических секций, не требуя от службы немедленного добавления новых физических секций.
Напротив, если вы считаете, что объем хранилища после миграции существенно не увеличится, вы можете установить более высокое значение, например, 45 ГБ. Это означает, что каждая секция будет заполнена на ~90 % (45 ГБ из 50 ГБ). Это минимизирует количество физических секций, по которым распределяются данные, что означает, что каждая физическая секция может получить большую долю от общего объема предоставленных ЕЗ.
Шаг 3. Вычисление количества единиц запросов в секунду для начала для всех секций
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Начнем с примера с произвольным количеством целевых единиц запросов в секунду на физическую секцию.
Initial throughput per physical partition= 10 000 ЕЗ/с на физическую секцию при использовании автомасштабирования или баз данных общей пропускной способностиInitial throughput per physical partition= 6000 ЕЗ/с на физическую секцию при использовании ручной пропускной способности
Пример
Предположим, что у нас есть 1 ТБ (1000 ГБ) данных, которые мы планируем ввести, и мы хотим использовать пропускную способность вручную. Каждая физическая секция в Azure Cosmos DB имеет емкость 50 ГБ. Предположим, что мы стремимся заполнить секции на 80 % (40 ГБ), оставляя место для будущего увеличения.
Это означает, что для 1 ТБ данных потребуется 1000 ГБ / 40 ГБ = 25 физических секций. Чтобы убедиться, что мы получим 25 физических секций, если мы используем пропускную способность вручную, мы сначала обеспечим 25 * 6000 ЕЗ = 150 000 ЕЗ. Затем, после создания контейнера, чтобы помочь приему данных выполнится быстрее, мы увеличиваем количество ЕЗ до 250 000 ЕЗ перед началом приема данных (происходит мгновенно, поскольку у нас уже есть 25 физических секций). Это позволит каждой секции получить не более 10 000 ЕЗ.
Если мы используем автомасштабируемую пропускную способность или базу данных с общей пропускной способностью, чтобы получить 25 физических секций, мы сначала предоставим 25 * 10 000 ЕЗ = 250 000 ЕЗ. Поскольку мы уже достигли максимального значения ЕЗ, которое можно поддерживать с 25 физическими секциями, мы не будем увеличивать количество предоставляемых ЕЗ перед загрузкой.
Теоретически, при 250 000 ЕЗ и 1 ТБ данных, если мы предположим, что документы размером 1 кб и 10 ЕЗ, необходимых для записи, теоретически загрузка может завершиться за: 1000 ГБ * (1 000 000 кб / 1 ГБ) * (1 документ / 1 кб) * (10 ЕЗ / документ) * (1 сек / 250 000 ЕЗ) * (1 час / 3600 секунд) = 11,1 часа.
Этот расчет является приблизительным, предполагая, что клиент, выполняющий загрузку, может полностью заполнить пропускную способность и распределить записи по всем физическим секциям. В качестве лучшей практики рекомендуется "перемешивать" данные на стороне клиента. Это гарантирует, что каждую секунду клиент записывает данные во множество отдельных логических (и, следовательно, физических) секций.
После завершения миграции мы можем снизить количество ЕЗ или включить автомасштабирование по мере необходимости.
Следующие шаги
- Отслеживание нормализованного потребления единиц измерения в секунду вашей базы данных или контейнера.
- Диагностика и устранение неполадок: слишком большая частота запросов (429) исключений
- Включение автомасштабирования в базе данных или контейнере.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по