Проверки работоспособности
CycleCloud предлагает два механизма проверки работоспособности виртуальных машин. Проверка работоспособности узла — это более новая функция, которая выполняет проверки на этапе подготовки и предотвращает присоединение неработоспособных виртуальных машин, а HealthCheck периодически запускает их после присоединения виртуальной машины к кластеру в качестве узла.
Проверки работоспособности узла
Проверки работоспособности узла могут обнаружить неработоспособное оборудование, прежде чем виртуальной машине будет разрешено присоединиться к кластеру CycleCloud. В текущей версии этой функции будут выполняться скрипты проверка работоспособности, встроенные в официальные образы AzureHPC, которые можно найти в разделе /opt/azurehpc/test/azurehpc-health-checks/. Источник этих скриптов находится в репозитории проверок работоспособности узла AzureHPC, но обратите внимание, что версия, встроенная в версию кластера образа AzureHPC, может быть не последней доступной в репозитории.
Требования
Текущая версия проверок работоспособности узла поддерживает только образы AzureHPC, выпущенные после 7 ноября 2023 г. (содержащие azurehpc-health-checks версии 2.0.6 или более поздней) и пользовательские образы, производные от них. Проверки работоспособности узла в настоящее время не поддерживаются в Windows.
Включение проверок работоспособности узла для кластеров Slurm
Форма создания кластера Slurm предлагает флажок для включения проверок работоспособности узла на вкладке Дополнительные параметры . Установите флажок, чтобы включить проверки работоспособности узла для массива узлов HPC кластера. Если вы хотите включить проверки работоспособности узла для других массивов узлов (или для других типов кластеров), необходимо использовать пользовательский шаблон кластера.
Проверки работоспособности узла можно отключить в работающем кластере, просто сняв флажок. Нет необходимости уменьшать масштаб массива узлов, чтобы изменения вступили в силу.
Основные сведения о результатах проверок работоспособности узла
После того как виртуальная машина пройдет проверку работоспособности, она перейдет к этапу настройки программного обеспечения.
Если на виртуальной машине не удается выполнить какие-либо скрипты проверка работоспособности, в CycleCloud будет отправлено сообщение об ошибке, и виртуальная машина автоматически не сможет присоединиться к кластеру.
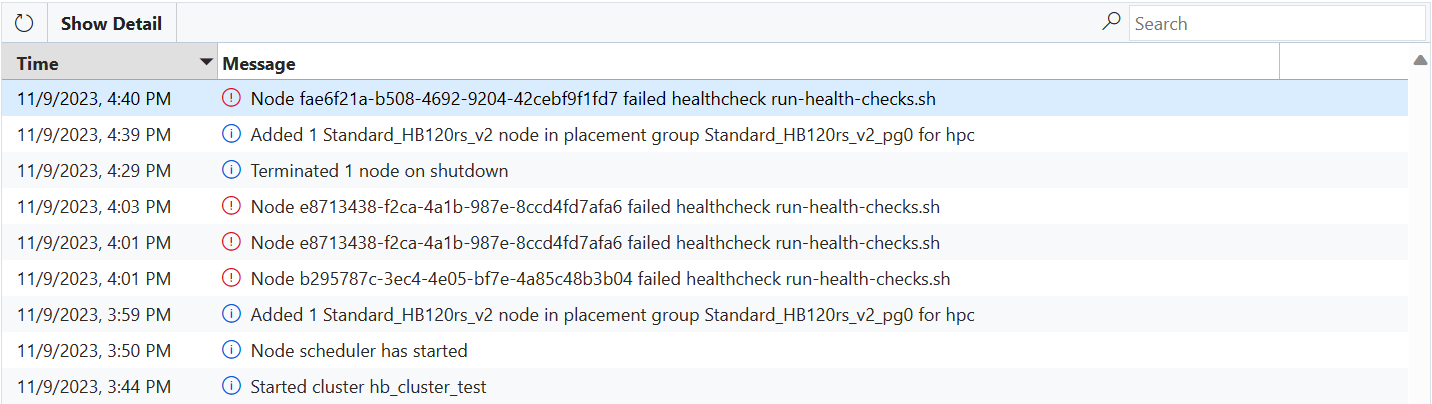
Если виртуальная машина запущена в NodeArray с включенной избыточной подготовкой (например, массивом узлов Slurm hpc), виртуальная машина должна быть автоматически заменена в рамках избыточной подготовки. В этом случае никаких действий не требуется, и для присоединения к кластеру будут выбраны работоспособные виртуальные машины (хотя на странице кластера появится сообщение об ошибке, указывающее, что одна или несколько виртуальных машин не выполнили проверку).
Если виртуальная машина запущена для одного узла, массив узлов с избыточной подготовкой отключен (например, массив узлов Slurm htc) или если больше виртуальных машин не выполняют проверки работоспособности, чем поддерживается избыточной подготовкой, узел переместится в состояние Сбой, и выделение завершится ошибкой. CycleCloud может попытаться повторно создать образ виртуальной машины, чтобы устранить проблему, но в случае сбоя повторного образа узел потребуется завершить работу и заменить (вручную администратором или автоматически с помощью автомасштабирования).
Примечание
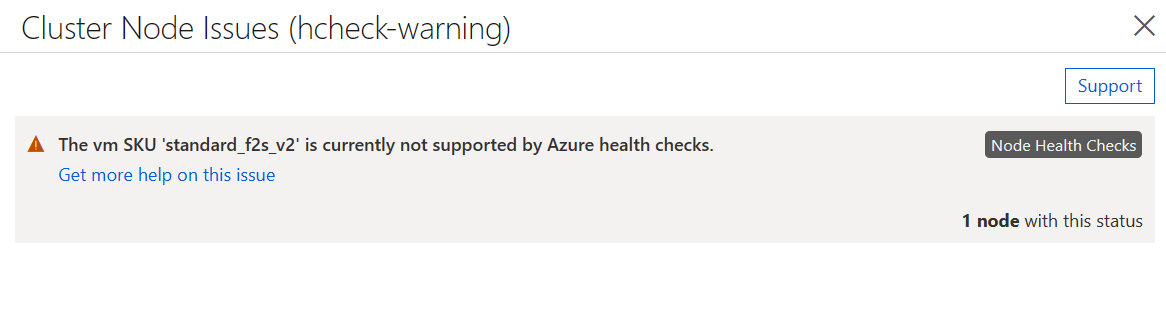
Если вы включили проверки работоспособности узла, но образ виртуальной машины не соответствует приведенным выше требованиям, все виртуальные машины смогут присоединиться к кластеру, но состояние будет содержать предупреждение о том, что проверки не поддерживаются.
Справочник по атрибутам
| attribute | Тип | Определение |
|---|---|---|
| EnableNodeHealthChecks | Логическое | (Необязательно) Включение проверок работоспособности узла при загрузке для этого узла или массива узлов |
Проверка работоспособности
Azure CycleCloud предоставляет механизм завершения виртуальных машин, которые находятся в неработоспособном состоянии, называемом HealthCheck. Системные и пользовательские скрипты (Python и Bash) выполняются периодически (5 минут в Windows, 10 минут в Linux) для определения общей работоспособности виртуальной машины. HealthCheck позволяет администраторам определять условия, при которых виртуальные машины должны быть завершены без необходимости вручную отслеживать и исправлять.
Встроенные скрипты HealthCheck
Виртуальные машины с поддержкой CycleCloud поставляются с двумя скриптами HealthCheck по умолчанию:
- Скрипт converge_timeout завершит работу экземпляра, который не завершил настройку программного обеспечения в течение четырех часов после запуска. Этот период времени ожидания можно контролировать с помощью
cyclecloud.keepalive.timeoutпараметра (определяется в секундах). - Скрипт scheduled_shutdown ищет файлы создателя в $JETPACK_HOME/run/scheduled_shutdown которые содержат одну строку, в которой указано время завершения работы в секундах Unix , а также вторую строку (необязательно) с объяснением. Если текущее время позже самой ранней метки времени в файлах, виртуальная машина считается неработоспособной.
Принцип работы
Скрипты HealthCheck находятся в каталоге $JETPACK_HOME/config/healthcheck.d . Linux поддерживает скрипты Python и Bash, а Windows — только скрипты Python. Скрипт должен определять работоспособность виртуальной машины. Если виртуальная машина оказалась неработоспособной, сценарий должен завершить работу с состоянием 254, которое указывает cycleCloud на то, что виртуальная машина неработоспособна и должна быть завершена.
При входе в виртуальную машину, на которой выполняется HealthCheck, вы можете не завершить работу виртуальной машины, выполнив команду jetpack keepalive. В экземплярах Linux можно указать временной интервал в часах или forever в windows forever — это единственный вариант.
Примечание
Если виртуальная машина определена как неработоспособная, агент HealthCheck выполнит запрос на завершение работы этой виртуальной машины в CycleCloud. Виртуальная машина никогда не будет завершена локально с помощью shutdown команды . В случае, если виртуальная машина не может взаимодействовать с CycleCloud, она будет оставаться в состоянии, даже если она неработоспособна до тех пор, пока не будет достигнут cycleCloud.
Пример
В качестве простого примера мы напишем скрипт HealthCheck, который гарантирует, что виртуальная машина Linux неактивна более 24 часов. Этот скрипт можно использовать для имитации вытеснений с низким приоритетом, чтобы проверить, как рабочий процесс реагирует на вытеснение виртуальной машины. Этот скрипт будет помещен в /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
Примечание
Этот скрипт можно разместить на виртуальной машине с помощью проекта CycleCloud или путем добавления его непосредственно при создании пользовательского образа.