dcount() (статистическая функция)
Вычисляет количество различных значений, принимаемых скалярным выражением в сводной группе.
Значения NULL игнорируются и не учитываются при вычислении.
Примечание
Статистическая функция dcount() в основном полезна для оценки кратности огромных наборов. Он торгует точностью за производительность и может возвращать результат, который зависит от выполнения. Порядок входных данных может влиять на выходные данные.
Примечание
Эта функция используется в сочетании с оператором summarize.
Синтаксис
dcount(expr[,точность])
Дополнительные сведения о соглашениях о синтаксисе.
Параметры
| Имя | Тип | Обязательно | Описание |
|---|---|---|---|
| expr | string |
✔️ | Входные данные, уникальные значения которых подсчитываются. |
| Точность | int |
Значение, определяющее запрошенную точность оценки. Значение по умолчанию — 1. Поддерживаемые значения см. в разделе Точность оценки . |
Возвращаемое значение
Возвращает оценку количества различных значений expr в группе.
Пример
В этом примере показано, сколько типов штормовых событий произошло в каждом состоянии.
StormEvents
| summarize DifferentEvents=dcount(EventType) by State
| order by DifferentEvents
Показанная таблица результатов содержит только первые 10 строк.
| Состояние | События DifferentEvents |
|---|---|
| Техас | 27 |
| Калифорния | 26 |
| ПЕНСИЛЬВАНИЯ | 25 |
| Грузия | 24 |
| Иллинойс | 23 |
| МЭРИЛЕНД | 23 |
| СЕВЕРНАЯ КАРОЛИНА | 23 |
| Мичиган | 22 |
| Флорида | 22 |
| ОРЕГОН | 21 |
| Канзас | 21 |
| ... | ... |
Точность оценки
Эта функция использует вариант алгоритма HyperLogLog (HLL), который выполняет стохастическую оценку кратности набора. Алгоритм предоставляет "рычаг управления", который можно использовать для выравнивания точности и времени выполнения под размер памяти:
| Точность | Ошибка (%) | Число записей |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0,28 | 217 |
| 4 | 0.2 | 218 |
Примечание
Столбец "число записей" — это количество 1-байтных счетчиков в реализации HLL.
Алгоритм включает в себя некоторые положения для выполнения идеального подсчета (нулевой ошибки), если кратность набора достаточно мала:
- если уровень точности равен
1, возвращаются значения 1000; - если уровень точности равен
2, возвращаются значения 8000.
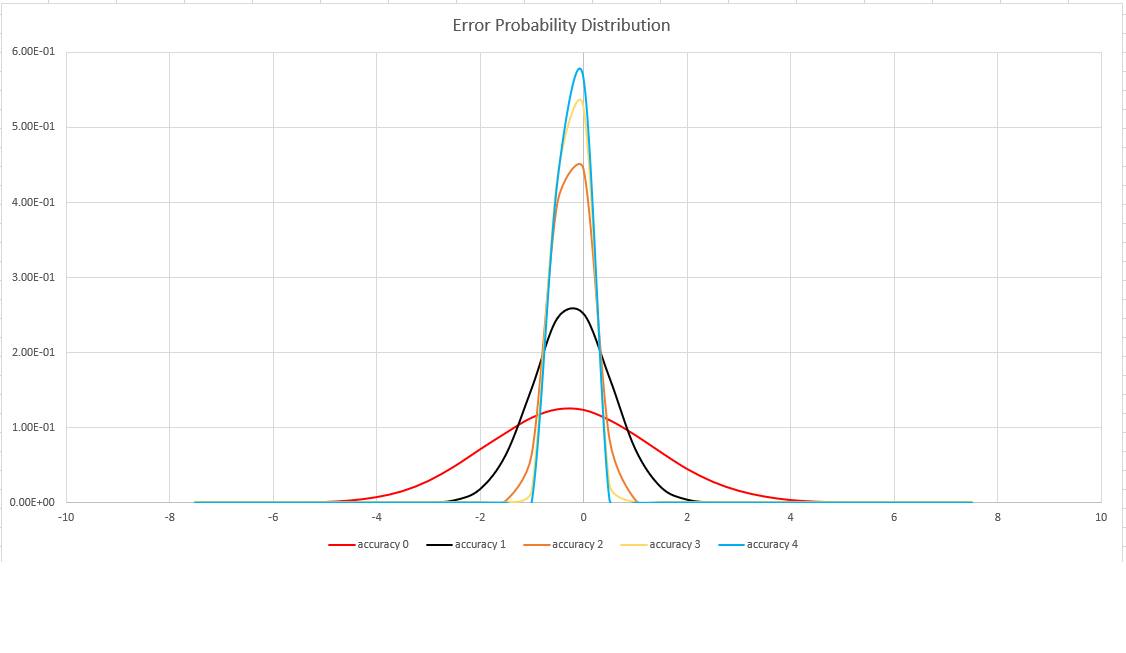
Границы погрешности — вероятностная, а не теоретическая граница. Значение является стандартным отклонением распределения погрешностей (сигма). 99,7 % оценок будут иметь относительную погрешность в 3 сигмы.
На следующем изображении показана функция распределения вероятности относительной погрешности оценки (в процентах) для всех поддерживаемых параметров точности:
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по