Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ: Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
Непрерывная интеграция — это способ автоматического тестирования каждого изменения, внесенного в базу кода. Непрерывная поставка следует за этапом тестирования, который выполняется во время непрерывной интеграции, и переносит изменения в промежуточную или рабочую систему.
В Фабрике данных Azure под непрерывными интеграцией и поставкой (CI/CD) подразумевается перемещение конвейеров Фабрики данных из одной среды (разработки, тестирования, рабочей) в другую. Фабрика данных Azure использует шаблоны Azure Resource Manager для хранения конфигурации различных сущностей Фабрики данных Azure (конвейеры, наборы данных, потоки данных и т. д.). Существуют два рекомендуемых метода перемещения фабрики данных в другую среду.
- Автоматизированное развертывание с помощью интеграции Фабрики данных с Azure Pipelines.
- Отправка шаблона Resource Manager вручную с помощью интеграции пользовательского интерфейса Фабрики данных с Azure Resource Manager.
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Чтобы узнать, как выполнить миграцию на модуль Az PowerShell, см. Перенос Azure PowerShell с AzureRM на Az.
Жизненный цикл CI/CD
Примечание.
Дополнительные сведения см. в статье Улучшения непрерывного развертывания.
Ниже приведен обзор примера жизненного цикла CI/CD в фабрике данных Azure, настроенной с помощью Azure Repos Git. Дополнительные сведения о настройке репозитория Git см. в статье Система управления версиями в Фабрике данных Azure.
Фабрика данных для разработки создается и настраивается с помощью Azure Repos Git. Все разработчики должны иметь разрешение на создание ресурсов Фабрики данных, таких как конвейеры и наборы данных.
Разработчик создает ветвь компонента для внесения изменений. Подписанные фиксации не поддерживаются в фабрике данных. Он отлаживает запуски конвейера с самыми последними изменениями. Дополнительные сведения об отладке запуска конвейера см. в статье Итеративные разработка и отладка в Фабрике данных Azure.
После того, как разработчик доволен изменениями, он создает pull-запрос от своей функциональной ветви в основную или совместную ветвь, чтобы коллеги могли их проанализировать.
После утверждения пулл-реквеста и объединения изменений в основной ветке, эти изменения публикуются в среде разработки.
Когда команда готова развернуть изменения в тестовой среде или среде пользовательского приемочного тестирования (UAT), она переходит к релизу в Azure Pipelines и развертывает требуемую версию фабрики разработки в среде UAT. Это развертывание выполняется как часть задачи Azure Pipelines и использует параметры шаблона Resource Manager, чтобы применить соответствующую конфигурацию.
После проверки изменений в тестовой фабрике выполните развертывание в фабрике эксплуатации с помощью следующей задачи выпуска конвейера.
Примечание.
Только фабрика для разработки будет связана с репозиторием Git. В тестовой и рабочей фабрике не должно быть связанного с ними репозитория Git. Их следует обновлять только через конвейер Azure DevOps или шаблон управления ресурсами.
На приведенном ниже рисунке показаны различные этапы этого жизненного цикла.
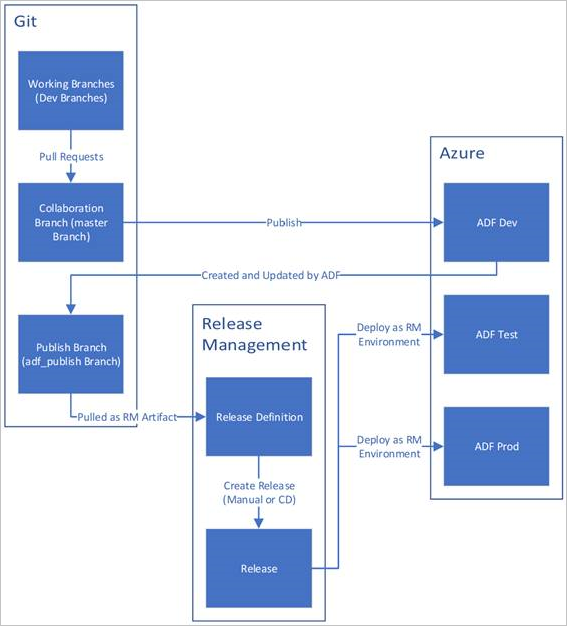
Лучшие практики для CI/CD
Если вы используете интеграцию Git с фабрикой данных и у вас есть конвейер CI/CD, перемещающий изменения из среды разработки в тестовую, а затем в рабочую, рекомендуем следующее:
Интеграция Git. Настройте интеграцию Git только для своей фабрики данных для разработки. Изменения в тестовую и рабочую среду развертываются в рамках процесса CI/CD и не требуют интеграции с Git.
Сценарий, выполняемый до и после развертывания. Перед шагом развертывания с помощью Resource Manager в CI/CD необходимо выполнить определенные задачи, такие как остановка и перезапуск триггеров и выполнение очистки. Рекомендуется использовать сценарии PowerShell до и после задачи развертывания. Дополнительные сведения см. в разделе Обновление активных триггеров. В нижней части этой страницы команда фабрики данных предоставила сценарий, который необходимо использовать.
Примечание.
Используйте PrePostDeploymentScript.Ver2.ps1, если требуется отключить или включить только те триггеры, которые были изменены, а не отключать и не включать все триггеры во время CI/CD.
Предупреждение
Для запуска скрипта обязательно используйте PowerShell Core в задаче ADO.
Предупреждение
Если вы не используете последние версии PowerShell и модуля Фабрики данных, во время выполнения команд могут возникнуть ошибки десериализации.
Среды выполнения интеграции и общий доступ. Средства выполнения интеграции не меняются часто и похожи на всех стадиях в CI/CD. Поэтому фабрика данных ожидает, что вы будете иметь одинаковое имя, тип и подтип среды выполнения интеграции на всех этапах CI/CD. Если вы хотите совместно использовать среды выполнения интеграции на всех этапах, рассмотрите возможность использования тернарной фабрики только для хранения общих сред выполнения интеграции. Эту общую фабрику можно использовать во всех средах в качестве связанного типа среды выполнения интеграции.
Примечание.
Общий доступ к среде выполнения интеграции доступен только для локальных сред выполнения интеграции. Среды выполнения интеграции Azure SSIS не поддерживают общий доступ.
Управляемое развертывание частной конечной точки. Если частная конечная точка уже существует в фабрике и вы пытаетесь развернуть шаблон ARM, содержащий частную конечную точку с таким же именем, но с измененными свойствами, развертывание завершится ошибкой. Другими словами, можно успешно развернуть частную конечную точку, если она имеет те же свойства, что и та, которая уже существует в фабрике. Если какое-либо свойство различается в разных средах, его можно переопределить путем параметризации и указания соответствующего значения во время развертывания.
Key Vault. При использовании связанных служб, сведения о соединении которых хранятся в Azure Key Vault, рекомендуется сохранять отдельные хранилищах ключей для разных сред. Вы также можете настроить отдельные уровни разрешений для каждого из хранилища ключей. Например, вы не хотите, чтобы у участников вашей команды были разрешения на доступ к секретам рабочей среды. При таком подходе рекомендуем сохранять одинаковые имена секретов на всех этапах. Если вы сохраняете одни и те же имена секретов, вам не нужно параметризовать каждую строку подключения в средах CI/CD, так как единственное, что изменяется — это имя хранилища ключей, которое является отдельным параметром.
Именование ресурса. Из-за ограничений шаблона ARM при развертывании могут возникать проблемы, если в именах ресурсов содержатся пробелы. Команда по разработке Фабрики данных Azure рекомендует использовать в именах ресурсов вместо пробелов символы "_" или "-". Например, "Pipeline_1" будет более предпочтительным вариантом, чем "Pipeline 1".
Изменение репозитория. ADF автоматически управляет содержимым репозитория GIT. Изменение или добавление вручную несвязанных файлов или папок в папку данных репозитория ADF Git может привести к ошибкам загрузки ресурсов. Например, наличие файлов .bak может привести к сбою ADF CI/CD, поэтому их следует удалить для загрузки ADF.
Управление уязвимостями и флажки функций. При работе в команде бывают случаи, когда можно слить изменения, но вы не хотите, чтобы их запускали в средах, таких как с повышенными привилегиями, как PROD и QA. Для отработки этого сценария группа ADF рекомендует концепцию DevOps использования флажков функций. В ADF вы можете сочетать глобальные параметры и условное действие, чтобы скрыть логику, основанную на этих флагах среды.
Инструкции по настройке флага функции см. в видеоинструкции ниже:
Неподдерживаемые функции
Ожидаемо, что Фабрика данных не допускает выборочного отбора фиксаций или публикации ресурсов. Публикации будут включать все изменения, внесенные в фабрику данных.
- Сущности фабрики данных зависят друг от друга. Например, триггеры зависят от конвейеров, а конвейеры зависят от наборов данных и других конвейеров. Выборочная публикация подмножества ресурсов может привести к непредвиденному поведению и ошибкам.
- В редких случаях, когда требуется выборочная публикация, рассмотрите возможность использования исправления. Дополнительные сведения см. в статье Устранение неполадок в производственной среде без остановки системы.
Команда Фабрики данных Azure не рекомендует назначать средства управления Azure RBAC отдельным компонентам в фабрике данных (конвейеры, наборы данных и т. д.). Например, если разработчик имеет доступ к конвейеру или набору данных, он также должен иметь доступ ко всем конвейерам или наборам данных в фабрике данных. Если вы считаете, что вам необходимо внедрить большое количество ролей Azure в пределах фабрики данных, подумайте о развертывании второй фабрики данных.
Вы не можете публиковать из частных веток.
В настоящее время вы не можете размещать проекты на Bitbucket.
Сейчас вы не можете экспортировать или импортировать оповещения и матрицы как параметры.
Частичные шаблоны ARM в ветви публикации больше не поддерживаются с 1 ноября 2021 г. Если проект использовал эту функцию, перейдите в поддерживаемый механизм развертывания, используя:
ARMTemplateForFactory.jsonилиlinkedTemplatesфайлы.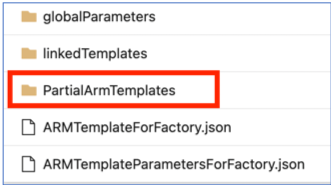
Связанный контент
- Улучшения в области непрерывного развертывания
- Автоматизация непрерывной интеграции с помощью выпусков Azure Pipelines
- Вручную продвигать шаблон Resource Manager в каждую среду
- Использование настраиваемых параметров в шаблоне Resource Manager
- Шаблоны Linked Resource Manager
- Использование производственной среды для срочных исправлений
- Пример скрипта до и после развертывания