Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Фабрика данных Azure с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
Действие Azure Databricks Python в pipeline запускает файл Python в кластере Azure Databricks. Данная статья основана на материалах статьи о действиях преобразования данных , в которой приведен общий обзор преобразования данных и список поддерживаемых действий преобразования. Azure Databricks — это управляемая платформа для запуска Apache Spark.
Уделите 11 минут вашего времени, чтобы просмотреть следующее видео с кратким обзором и демонстрацией этой функции:
Добавьте действие Python для Azure Databricks в конвейер с пользовательским интерфейсом
Чтобы использовать действие Python для Azure Databricks в конвейере, выполните следующие действия:
Найдите Python в области действий конвейера и перетащите действие Python на холст конвейера.
Выберите новое действие Python на холсте, если оно еще не выбрано.
Перейдите на вкладку Azure Databricks, чтобы выбрать или создать связанную службу Azure Databricks, которая выполнит действие Python.
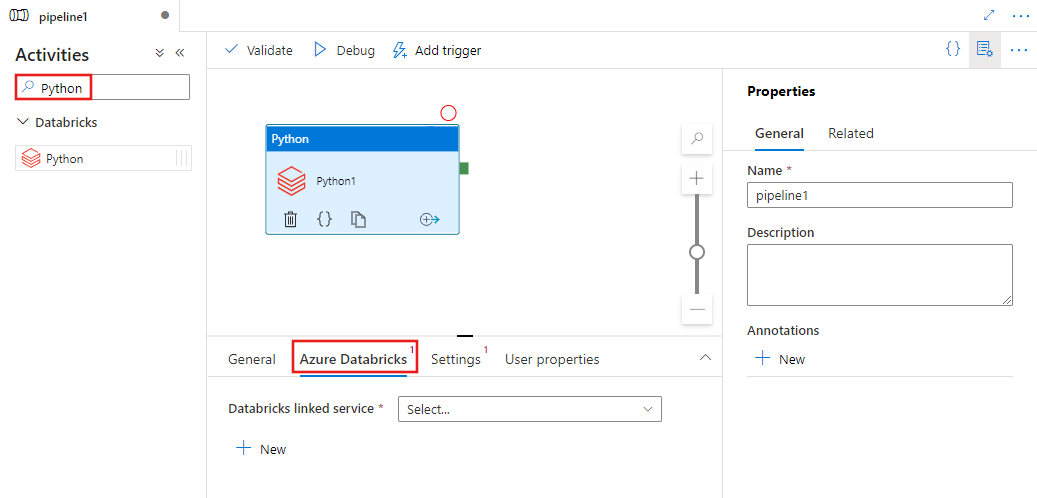
Перейдите на вкладку Settings и укажите путь в Azure Databricks в исполняемый файл Python, необязательные параметры, которые необходимо передать, и все дополнительные библиотеки, установленные в кластере для выполнения задания.
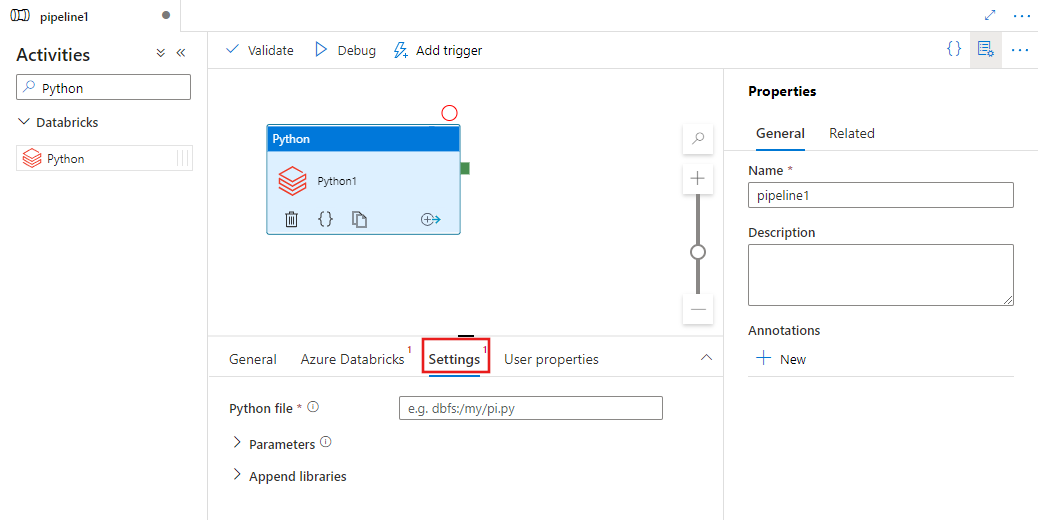
Определение действия Python в Databricks
Ниже приведен пример определения JSON для действия Databricks Python:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Свойства действия Databricks Python
В следующей таблице приведено описание свойств, используемых в определении JSON.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| имя | Имя действия в конвейере. | Да |
| описание | Текст, описывающий, что делает это действие. | Нет |
| тип | Для Databricks Python Activity тип действия — DatabricksSparkPython. | Да |
| имяСвязаннойСлужбы | Имя связанной службы Databricks, в которой выполняется действие Python. Дополнительные сведения об этой связанной службе см. в статье Связанные вычислительные службы. | Да |
| pythonFile | URI файла Python, который требуется выполнить. Поддерживаются только пути DBFS. | Да |
| параметры | Параметры командной строки, которые будут переданы в файл Python. Массив строк. | Нет |
| библиотеки | Список библиотек, которые должны быть установлены на кластере, на котором будет выполнено задание. Это может быть массив <string, object> | Нет |
Поддерживаемые библиотеки для деятельности Databricks
В приведенном выше определении действия Databricks необходимо указать следующие типы библиотек: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Дополнительные сведения см. в документации Databricks по типам библиотек.
Отправка библиотеки в Databricks
Вы можете использовать пользовательский интерфейс рабочей области:
Использование пользовательского интерфейса рабочей области Databricks
Чтобы получить путь к dbfs библиотеки, добавленной с помощью пользовательского интерфейса, можно использовать интерфейс командной строки Databricks.
Обычно библиотеки Jar, добавленные с помощью пользовательского интерфейса, хранятся в каталоге dbfs:/FileStore/jars. Вы можете перечислить все через интерфейс командной строки: databricks fs ls dbfs:/FileStore/job-jars.
Или можно использовать интерфейс командной строки Databricks:
Затем выполните Копирование библиотеки с помощью интерфейса командной строки Databricks
Используйте интерфейс командной строки Databricks (действия по установке)
Например, чтобы скопировать JAR-файл в dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar