Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ПРИМЕНИМО К: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Data Factory в Microsoft Fabric — это следующее поколение Фабрика данных Azure с более простой архитектурой, встроенным ИИ и новыми функциями. Если вы не знакомы с интеграцией данных, начните с Fabric Data Factory. Существующие рабочие нагрузки ADF могут обновляться до Fabric для доступа к новым возможностям в области обработки и анализа данных, аналитики в режиме реального времени и отчетов.
В этом руководстве вы используете пользовательский интерфейс Фабрика данных Azure для создания конвейера, который копирует и преобразует данные из источника Azure Data Lake Storage (ADLS) 2-го поколения в приемник ADLS 2-го поколения с помощью потока данных сопоставления. Шаблон конфигурации, приведенный в этом кратком руководстве, можно расширить при преобразовании данных с использованием функции сопоставления потоков данных
Данное руководство предназначено для отображения потоков данных в целом. Потоки данных доступны как в Фабрика данных Azure, так и в конвейерах Synapse. Если вы не знакомы с потоками данных в конвейерах Azure Synapse, следуйте Поток данных с помощью Azure Synapse Pipelines.
В этом руководстве вы выполните следующие шаги:
- Создали фабрику данных.
- Создайте конвейер с операцией Поток данных.
- Постройте карту потока данных с четырьмя преобразованиями.
- тестовый запуск конвейера;
- Контролировать действие Поток данных.
Предварительные условия
- подписка Azure. Если у вас нет подписки Azure, создайте учетную запись free Azure перед началом работы.
- Учетная запись Azure Data Lake Storage 2-го поколения. Хранилище ADLS используется в качестве хранилища данных источника и приемника. Если у вас нет учетной записи хранения, ознакомьтесь с Создание учетной записи хранения Azure, чтобы создать ее.
- Скачайте MoviesDB.csv здесь. Чтобы получить файл из GitHub, скопируйте содержимое в текстовый редактор, чтобы сохранить его локально в виде файла .csv. Отправьте файл в учетную запись хранения в контейнере с именем sample-data.
Создание фабрики данных
На этом этапе вы создадите фабрику данных и откроете пользовательский интерфейс службы "Фабрика данных" для создания конвейера в фабрике данных.
Откройте Microsoft Edge или Google Chrome. В настоящее время пользовательский интерфейс фабрики данных поддерживается только в веб-браузерах Google Chrome и Microsoft Edge.
В верхнем меню выберите Создать ресурс>Аналитика>Фабрика данных :
На странице "Новая фабрика данных " в разделе "Имя" введите ADFTutorialDataFactory.
Имя фабрики данных Azure должно быть уникальным в мире. Если вы увидите сообщение об ошибке касающееся значения имени, введите другое имя для фабрики данных. (Например, yournameADFTutorialDataFactory.) Правила именования артефактов фабрики данных см. в правилах именования фабрики данных.
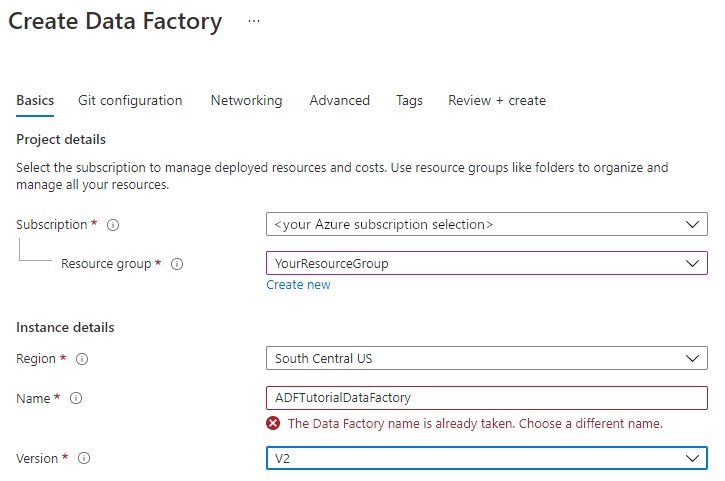
Выберите подписку Azure, в которой требуется создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий.
Выберите "Использовать существующий" и выберите существующую группу ресурсов из раскрывающегося списка.
Выберите "Создать" и введите имя группы ресурсов.
Дополнительные сведения о группах ресурсов см. в статье Использовать группы ресурсов для управления ресурсами Azure.
В разделе "Версия" выберите версию 2.
В разделе "Регион" выберите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые местоположения. Хранилища данных (например, служба хранилища Azure и база данных SQL) и вычислительные ресурсы (например, Azure HDInsight), используемые фабрикой данных, могут находиться в других регионах.
Выберите Просмотр + Создание, а затем выберите Создать.
После завершения создания вы увидите уведомление в центре уведомлений. Выберите "Перейти к ресурсу", чтобы перейти на страницу фабрики данных.
Выберите "Запустить студию" , чтобы запустить студию Фабрики данных на отдельной вкладке.
Создание конвейера с действием Поток данных
На этом шаге создается конвейер, содержащий действие Поток данных.
На домашней странице Фабрика данных Azure выберите Orchestrate.
Теперь открылась возможность для нового трубопровода. На вкладке "Общие " для свойств конвейера введите TransformMovies для имени конвейера.
В области Действия разверните аккордеон Перемещение и преобразование. Перетащите активность Поток данных из панели инструментов на холст конвейера.
Назовите действие потока данных DataFlow1.
В верхней строке холста конвейера переместите ползунок Поток данных debug в положение "включено". Режим отладки позволяет в интерактивном режиме тестировать логику преобразования в динамическом кластере Spark. Поток данных кластеры занимают 5–7 минут, чтобы прогреть, и пользователям рекомендуется сначала включить отладку, если планируется выполнить разработку Поток данных. Дополнительные сведения см. в разделе "Режим отладки".

Построение логики преобразования в интерфейсе потока данных
На этом шаге создается поток данных, который принимает moviesDB.csv в хранилище ADLS и объединяет средний рейтинг комедий с 1910 по 2000 год. Затем вы записываете этот файл обратно в хранилище ADLS.
На панели под холстом перейдите к параметрам действия потока данных и выберите "Создать", расположенный рядом с полем потока данных. Откроется холст потока данных.
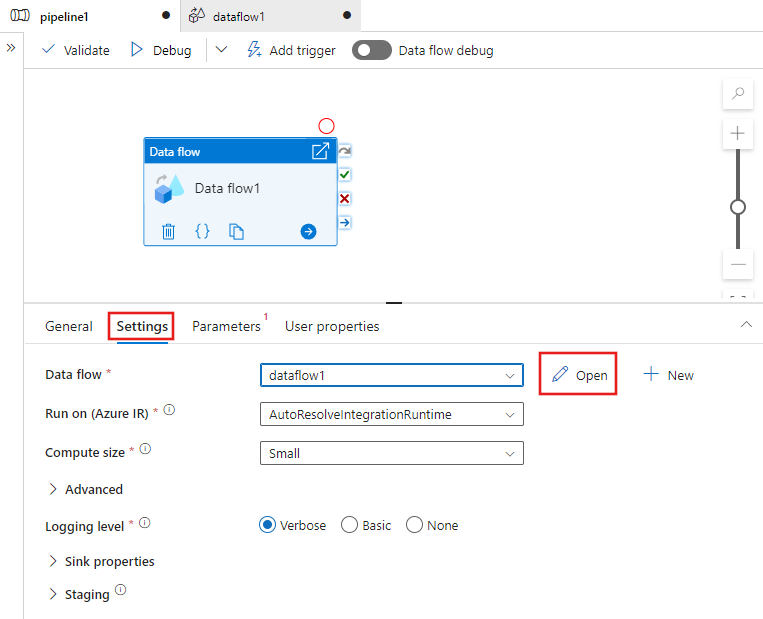
В области "Свойства " в разделе "Общие" назовите поток данных: TransformMovies.
На холсте потока данных добавьте источник, выбрав поле "Добавить источник ".
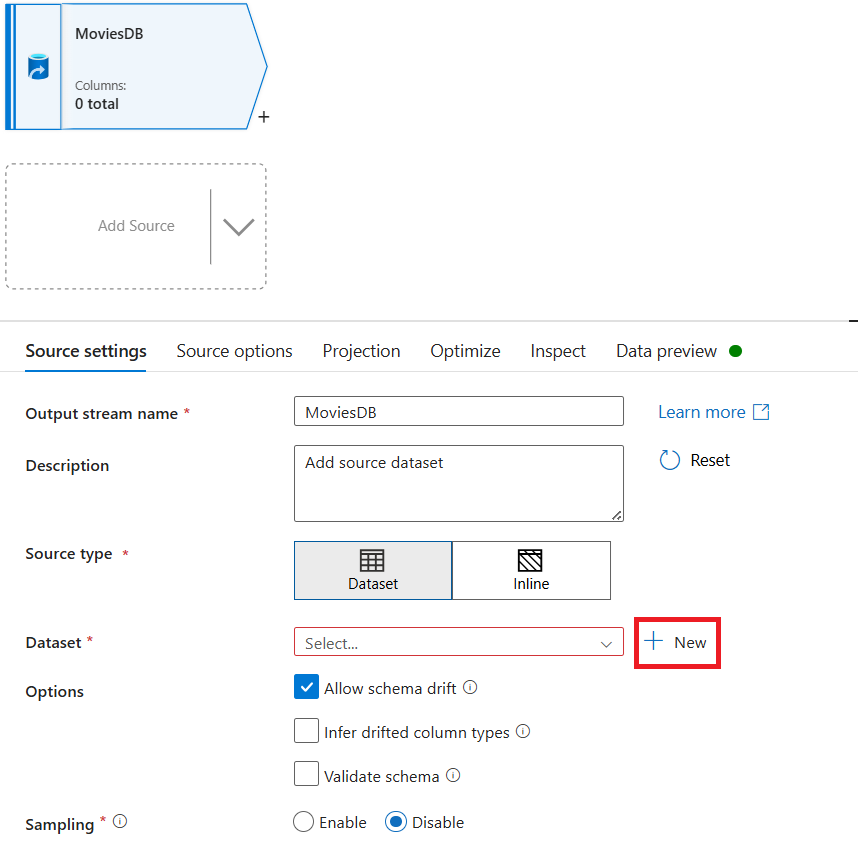
Присвойте исходному файлу MoviesDB имя. Выберите Создать, чтобы создать исходный набор данных.
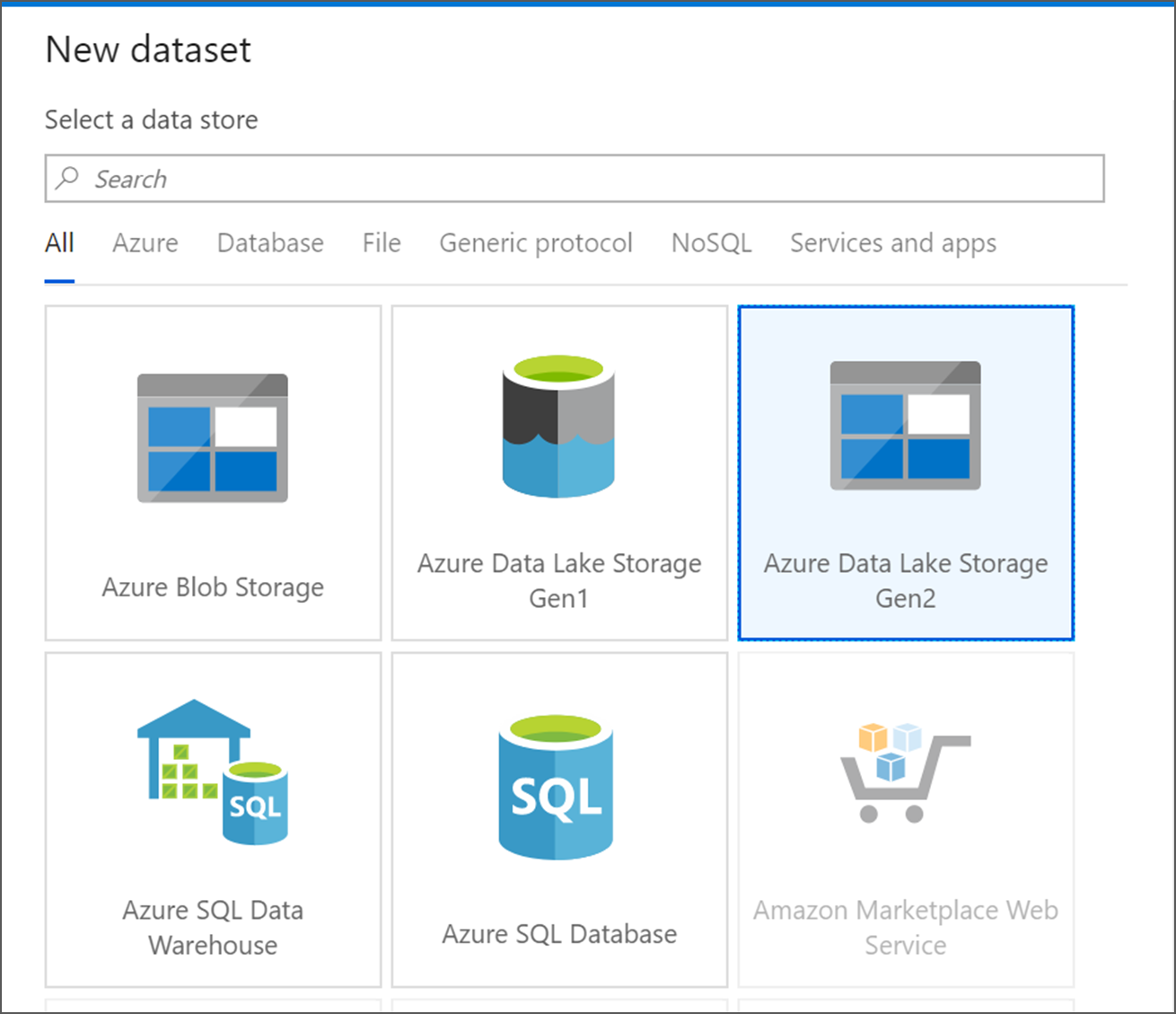
Выберите Azure Data Lake Storage 2-го поколения. Нажмите Продолжить.
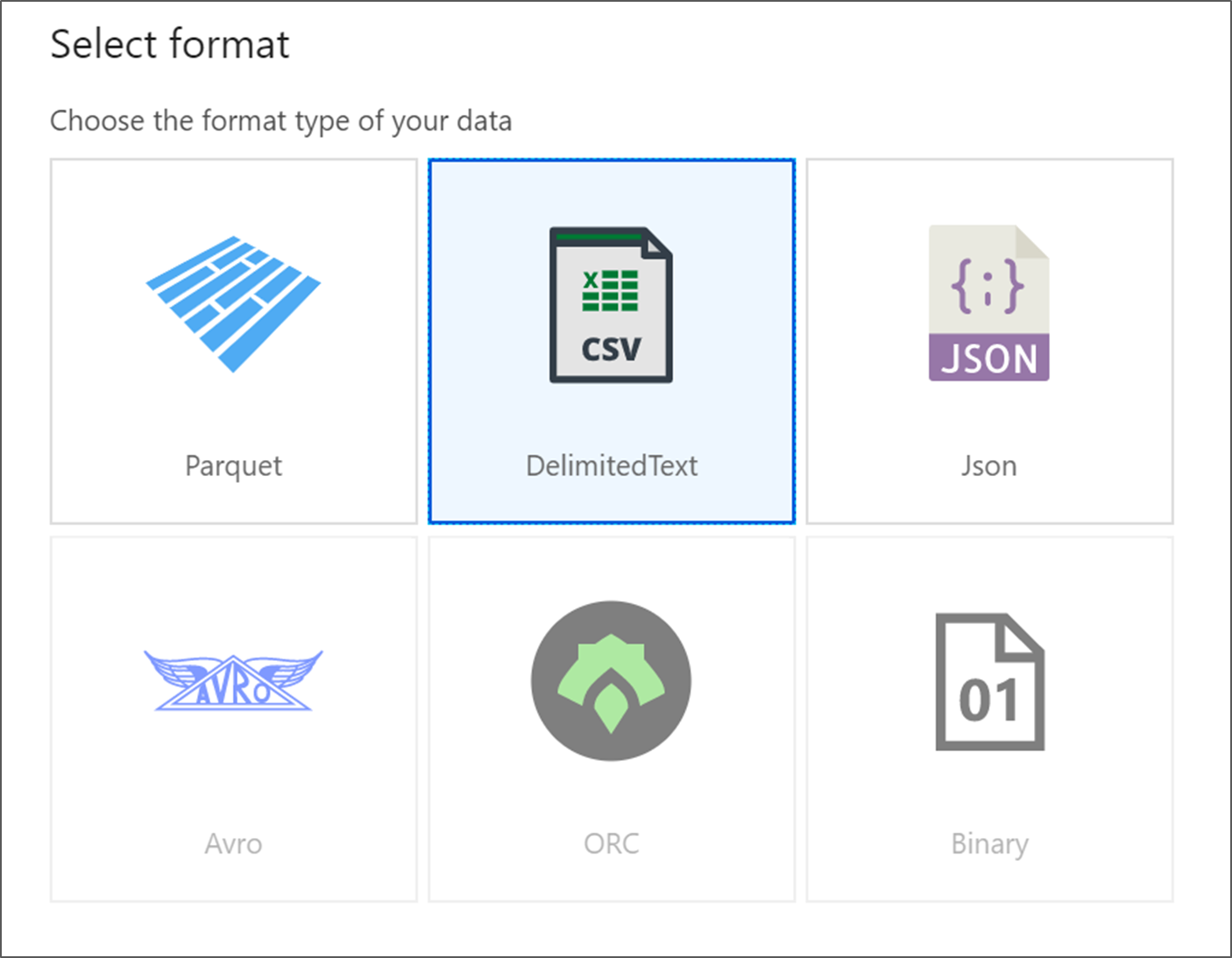
Выберите DelimitedText. Нажмите Продолжить.
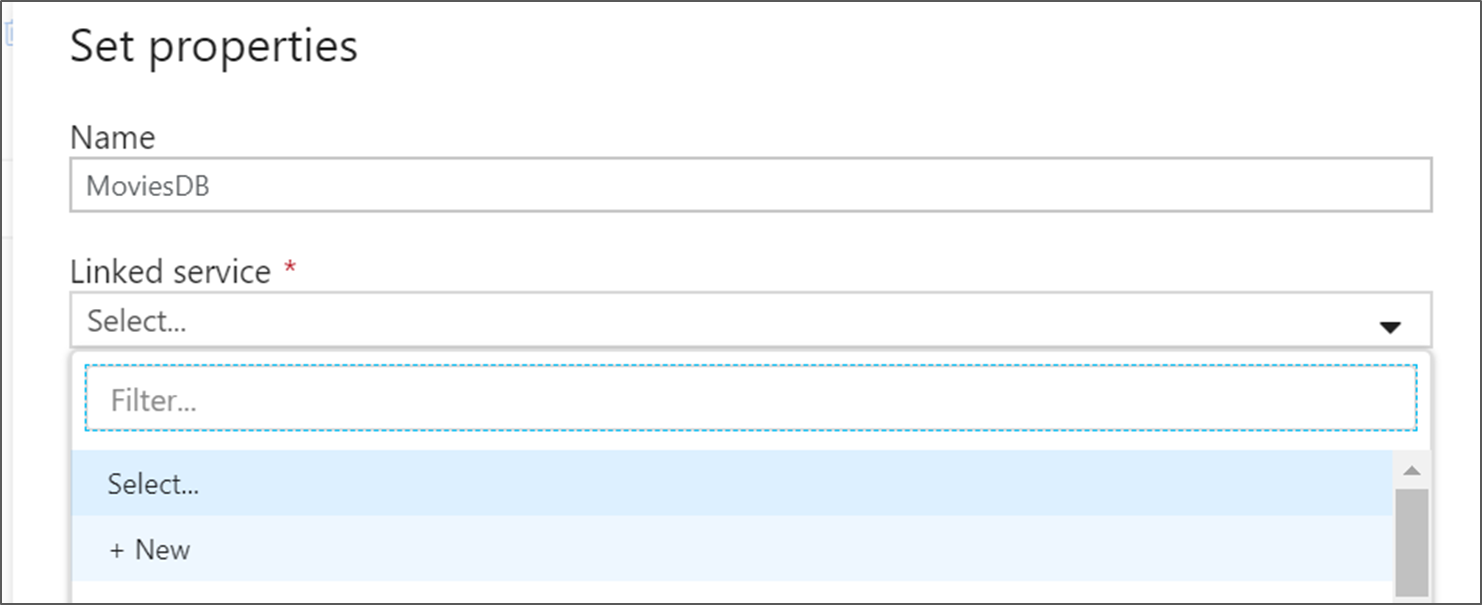
Назовите набор данных MoviesDB. В раскрывающемся списке связанной службы нажмите кнопку "Создать".
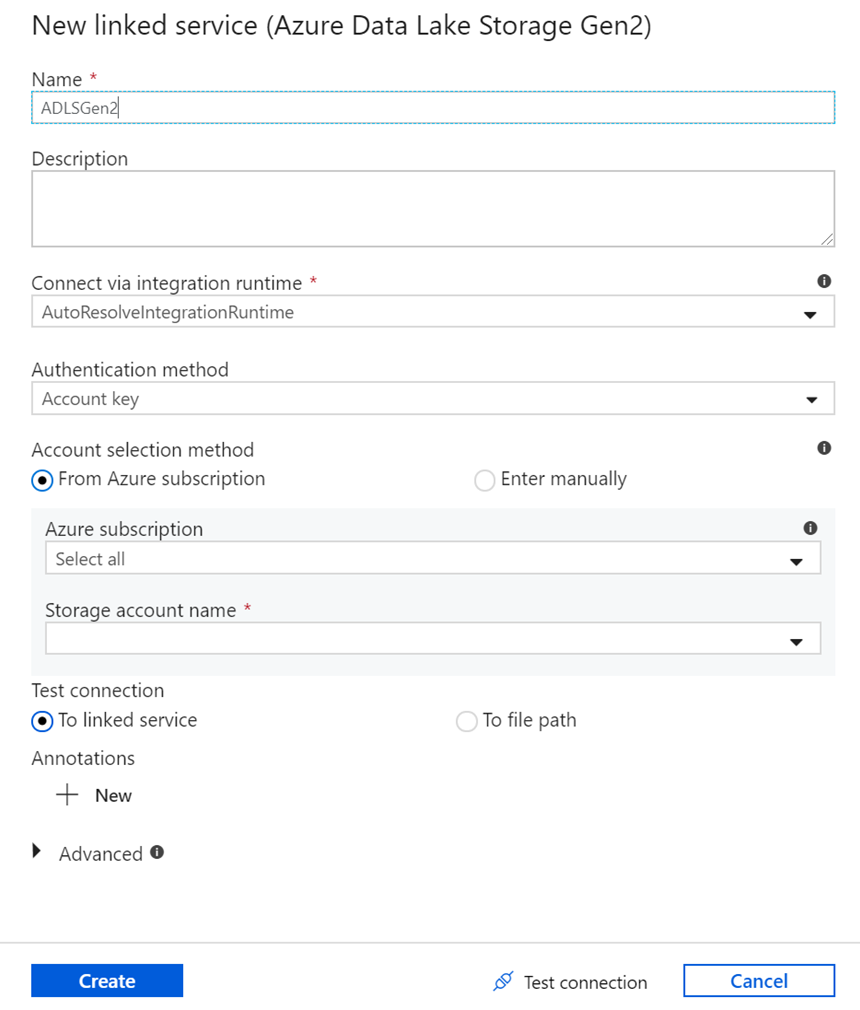
На экране создания связанной службы назовите службу ADLS 2-го поколения ADLSGen2 и укажите метод проверки подлинности. Затем введите учетные данные подключения. В этом руководстве мы используем ключ учетной записи для подключения к нашей учетной записи хранения. Чтобы проверить правильность ввода учетных данных, можно выбрать тестовое подключение . Нажмите кнопку "Создать" по завершении.
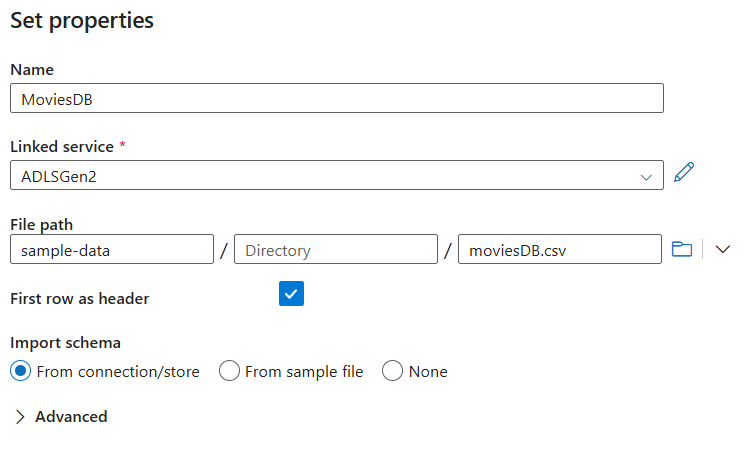
Вернувшись на экран создания набора данных, введите расположение файла в поле пути к файлу . В этом кратком руководстве файл moviesDB.csv находится в контейнере sample-data. Если файл содержит заголовки, проверьте первую строку в качестве заголовка. Выберите Из подключения/хранилища, чтобы импортировать схему заголовка напрямую из файла, находящегося в хранилище. После завершения нажмите кнопку "ОК".
Если кластер отладки запущен, откройте вкладку Предварительный просмотр данных преобразования источника и нажмите кнопку Обновить, чтобы получить моментальный снимок данных. Предварительный просмотр данных дает возможность убедиться, что преобразование настроено правильно.
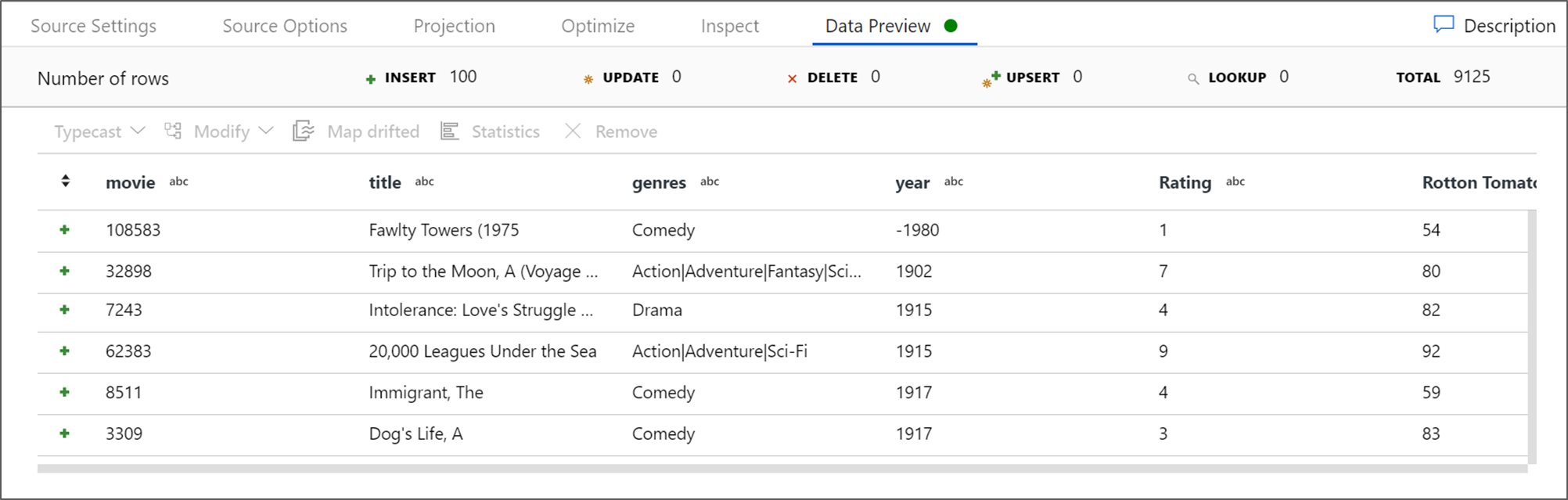
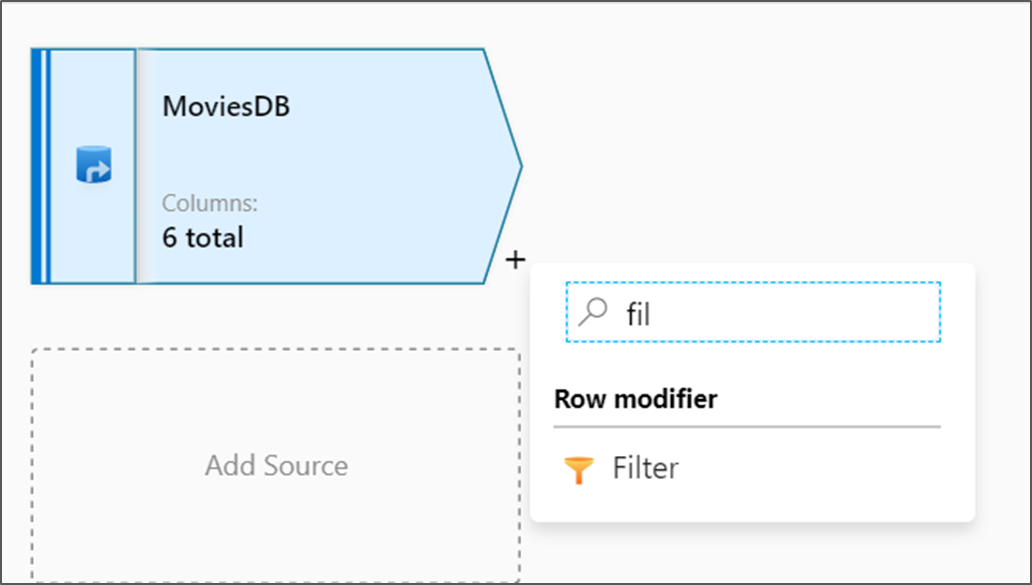
Выберите значок "плюс" рядом с узлом источника на холсте потока данных, чтобы добавить новое преобразование. Первое преобразование, добавляемое, — фильтр.
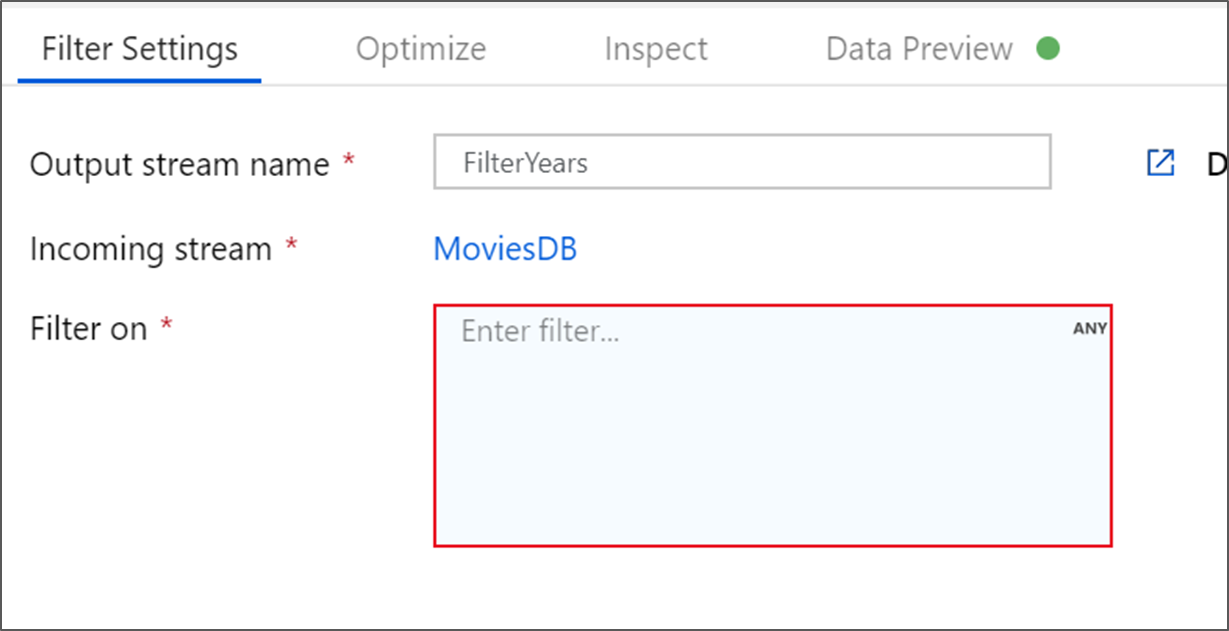
Назовите преобразование фильтра FilterYears. Выберите поле выражения рядом с Фильтр и затем Открыть построитель выражений. Здесь вы указываете условие фильтрации.
Построитель выражений потока данных позволяет интерактивно создавать выражения для использования в различных преобразованиях. Выражения могут включать встроенные функции, столбцы из входной схемы и задаваемые пользователем параметры. Дополнительные сведения о создании выражений см. в построителе выражений Поток данных.
В этом кратком руководстве будут отфильтрованы фильмы в жанре комедия, которые вышли между 1910 и 2000 годами. В связи с тем, что в настоящее время год является строкой, ее необходимо преобразовать в целое число с помощью функции
toInteger(). Используйте операторы "больше или равно" (>=) и "меньше или равно" (<=) для сравнения с годовыми значениями 1910 и 2000. Объедините эти выражения с помощью оператора AND (&&). Выражение будет выглядеть следующим образом:toInteger(year) >= 1910 && toInteger(year) <= 2000Чтобы узнать, какие фильмы являются комедиями, можно использовать функцию
rlike(), позволяющую найти слово "комедия" в жанрах столбца. Объедините выражениеrlikeс сравнением года, чтобы получить:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Если у вас есть активный кластер отладки, можно проверить логику, выбрав "Обновить ", чтобы просмотреть выходные данные выражения по сравнению с используемыми входными данными. Существует несколько правильных ответов на вопрос, как можно реализовать эту логику с помощью языка выражений потока данных.
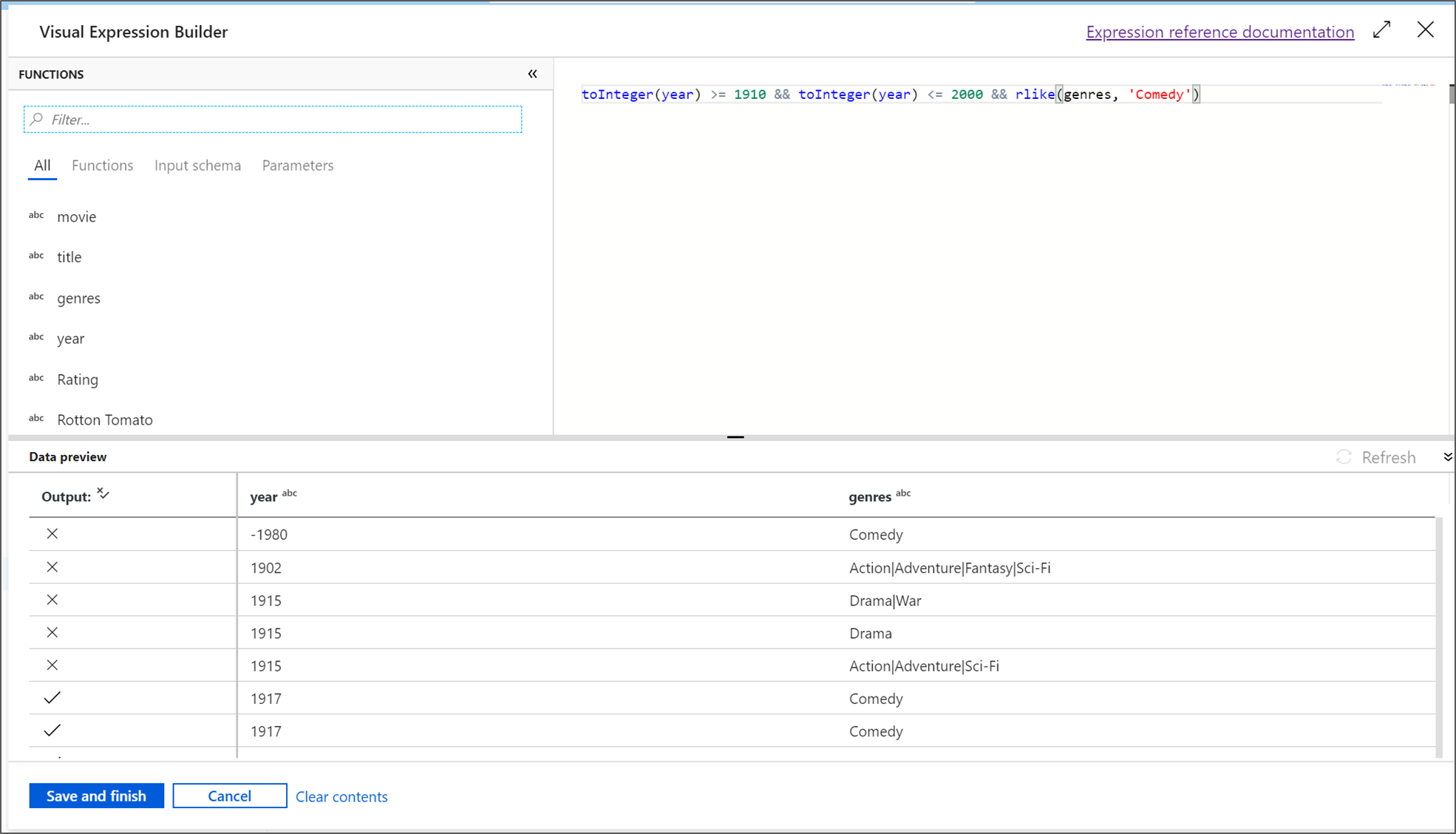
После завершения работы с выражением нажмите кнопку "Сохранить и готово ".
Получите предварительную версию данных , чтобы убедиться, что фильтр работает правильно.
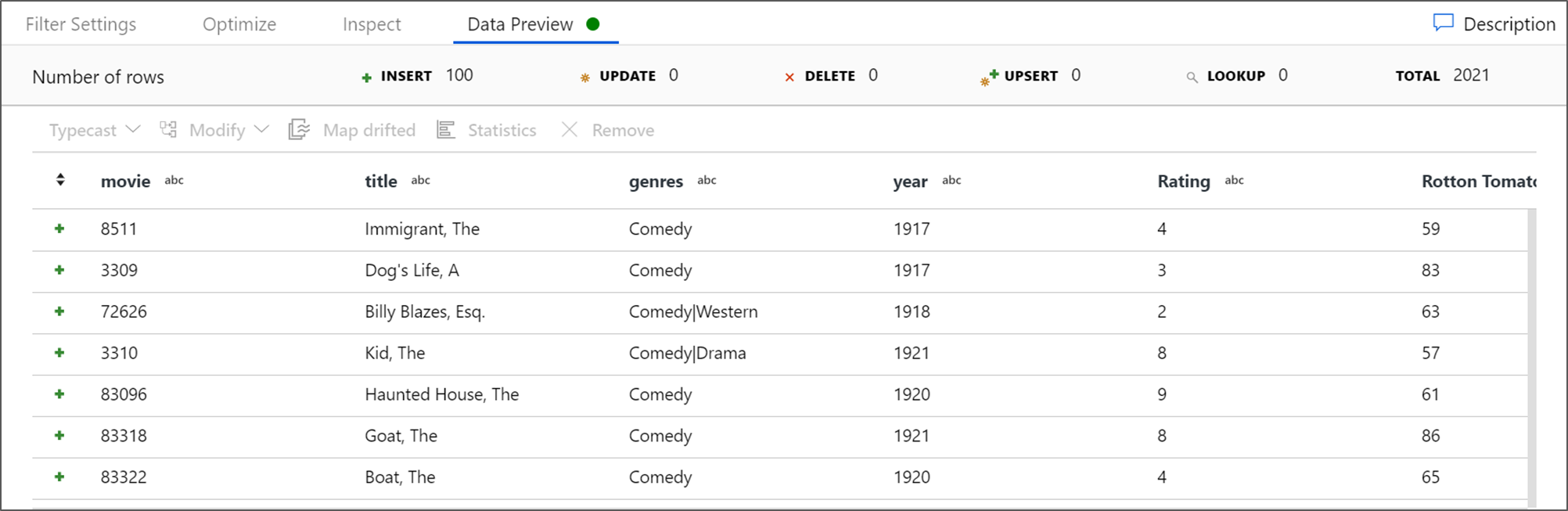
Следующее преобразование, который вы добавите, — это преобразование Агрегата в модификаторе схемы.
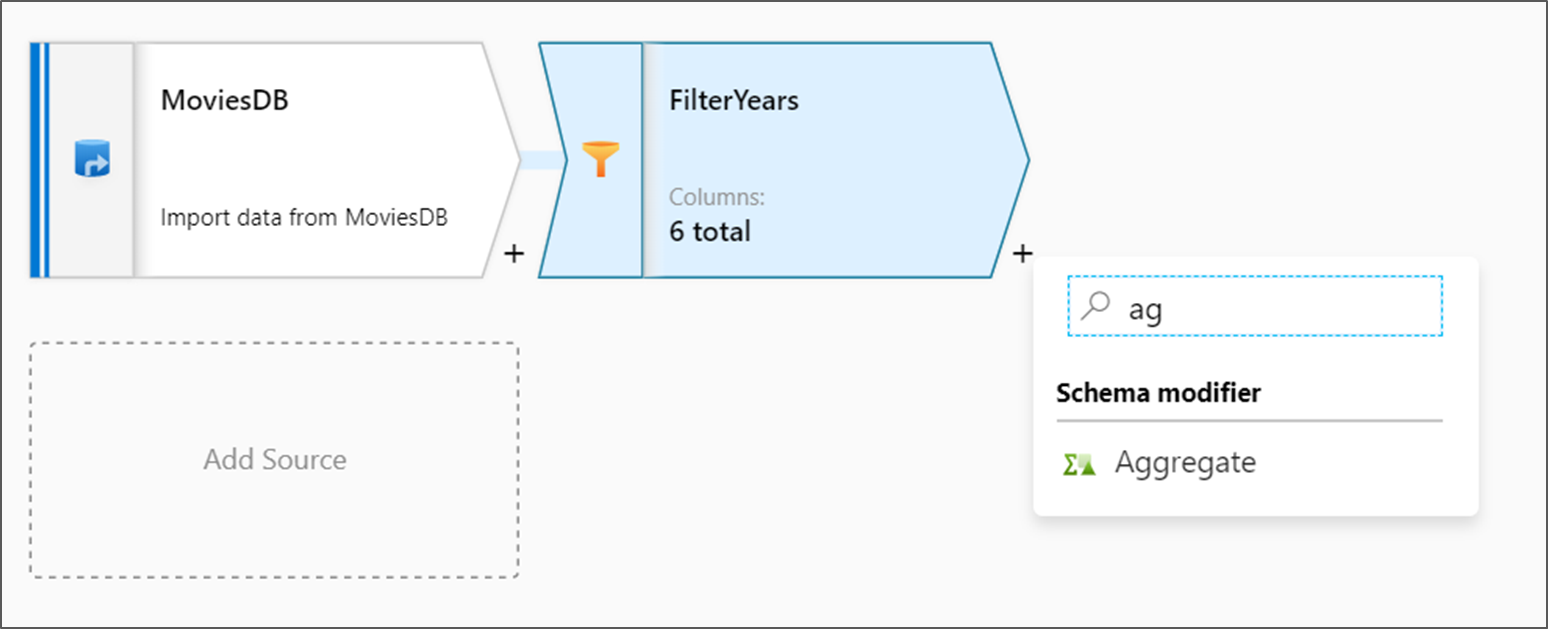
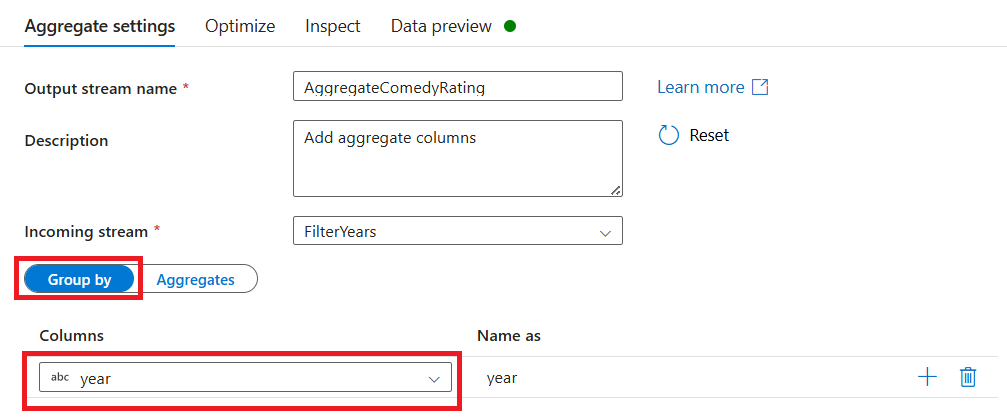
Назовите ваше агрегированное преобразование AggregateComedyRatings. На вкладке "Группа по " выберите год в раскрывающемся списке, чтобы сгруппировать агрегаты по году фильм вышел.
Перейдите на вкладку "Агрегаты ". В левом текстовом поле назовите агрегатный столбец AverageComedyRating. Выберите правое поле выражения, чтобы ввести статистическое выражение с помощью построителя выражений.
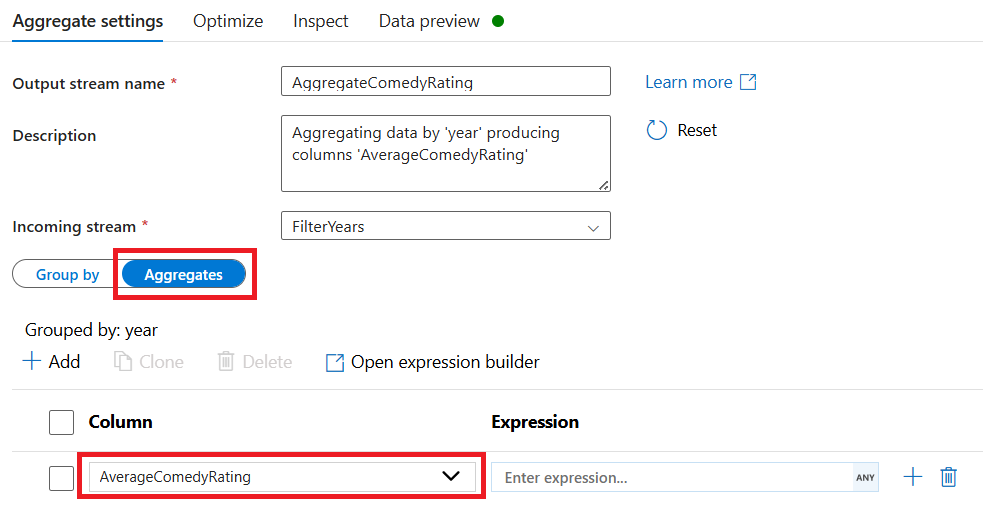
Чтобы получить среднее значение рейтинга столбца, используйте агрегатную
avg()функцию. Так как оценка является строкой иavg()принимает числовые входные данные, мы должны преобразовать значение в число через функциюtoInteger(). Это выражение выглядит следующим образом:avg(toInteger(Rating))Нажмите кнопку "Сохранить" и "Готово " после завершения.

Перейдите на вкладку "Просмотр данных" , чтобы просмотреть выходные данные преобразования. Обратите внимание, что есть только два столбца: year и AverageComedyRating.
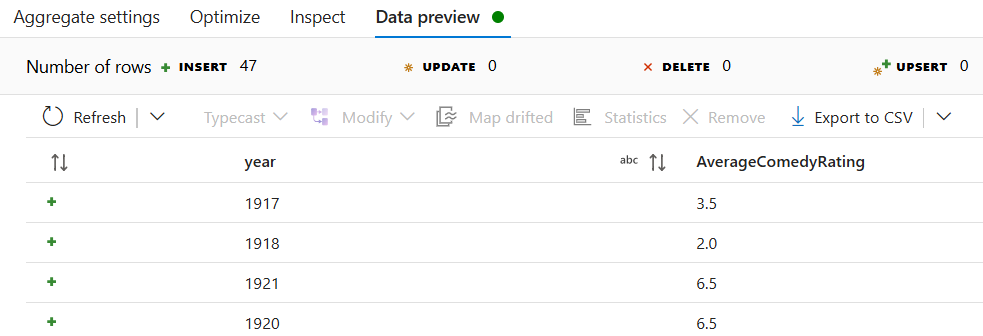
Затем необходимо добавить преобразование Слив под Назначение.
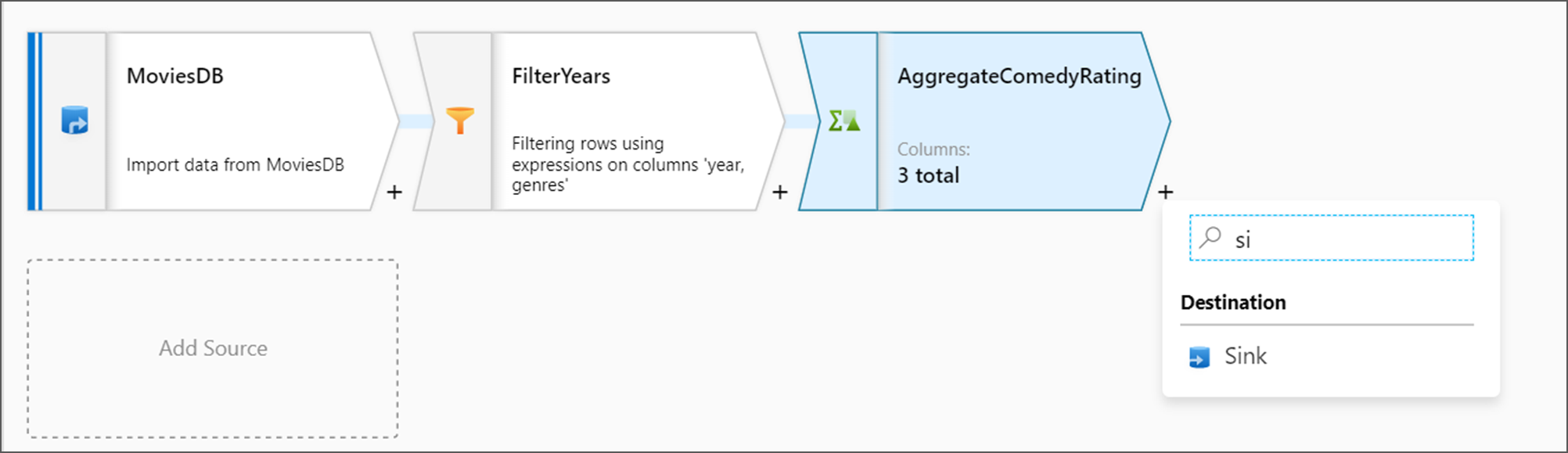
Назовите раковину Sink. Выберите Новое, чтобы создать набор данных приемника.
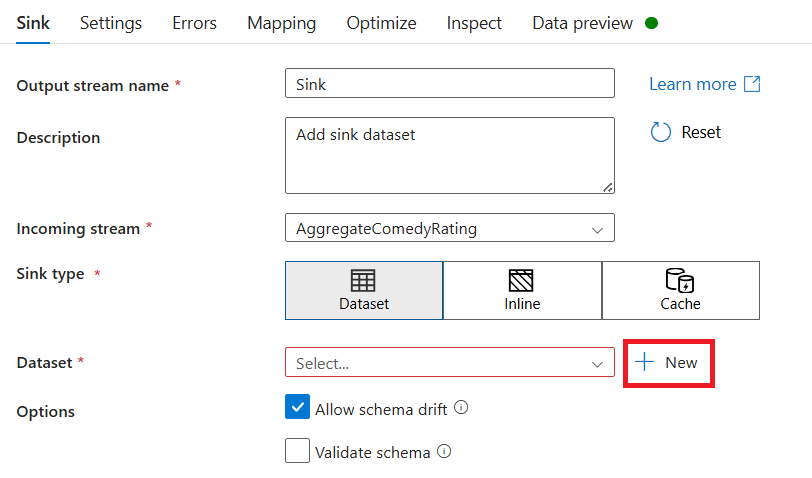
Выберите Azure Data Lake Storage 2-го поколения. Нажмите Продолжить.
Выберите DelimitedText. Нажмите Продолжить.
Назовите набор данных приемника MoviesSink. В качестве связанной службы выберите связанную службу ADLS 2-го поколения, созданную на шаге 6. Введите выходную папку для записи данных. В этом кратком руководстве мы записываем данные в папку output в контейнере sample-data. Папка не обязательно должна существовать заранее и может быть создана динамически. Задайте первую строку в качестве заголовка true и выберите "Нет " для схемы импорта. Нажмите кнопку "Готово".
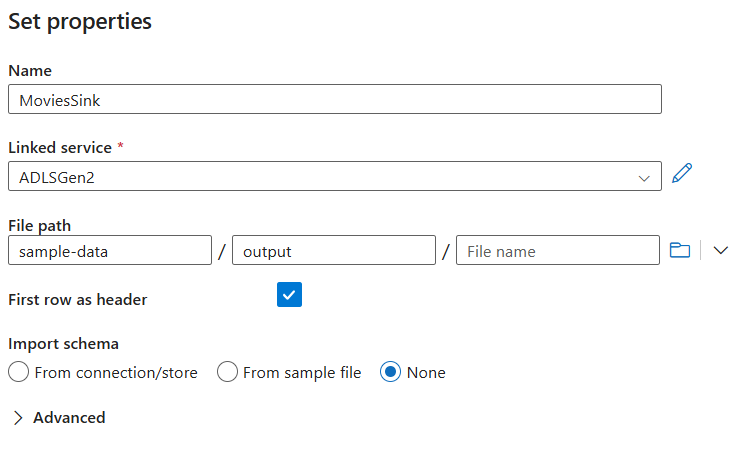
Теперь создание потока данных завершено. Все готово для его запуска в конвейере.
Запуск и мониторинг потока данных
Перед публикацией можно выполнить отладку конвейера. На этом шаге вы активируете отладочный запуск конвейера потока данных. Хотя предварительный просмотр данных не записывает данные, отладочный запуск записывает данные в приемник.
Перейдите на холст конвейера. Нажмите кнопку Отладка, чтобы запустить отладку.
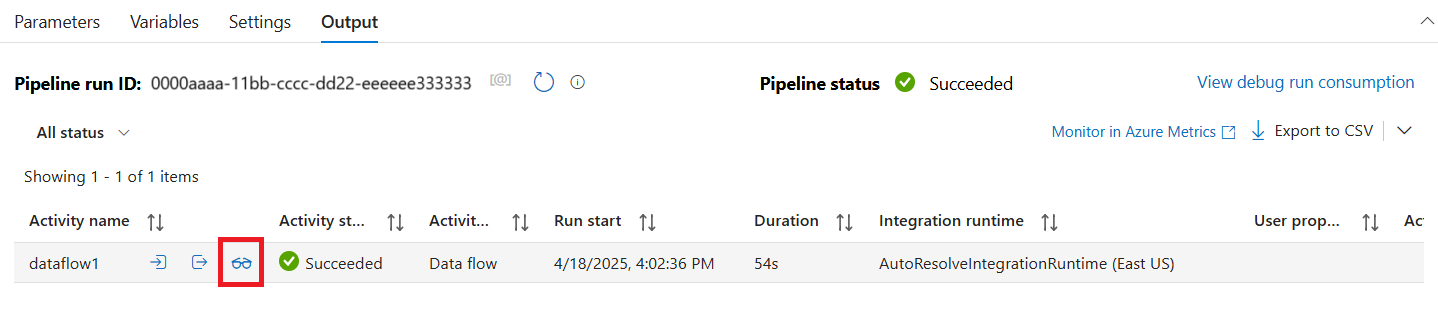
Отладка конвейера активностей Поток данных использует активный кластер отладки, но все равно требует не менее минуты на инициализацию. Ход выполнения можно отслеживать на вкладке Вывод. После успешного запуска наведите курсор на запуск и выберите значок с изображением очков для открытия панели мониторинга.
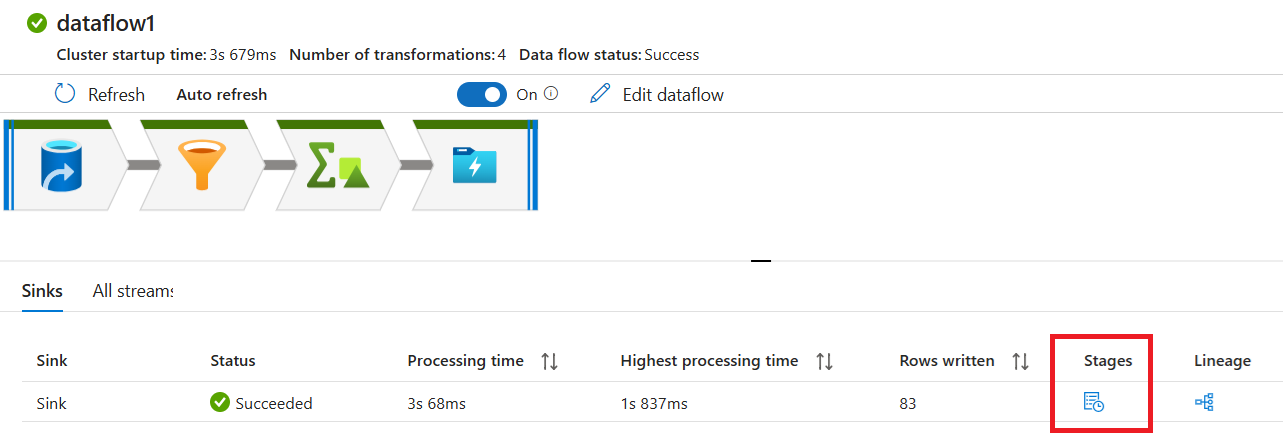
В области мониторинга нажмите кнопку "Этапы ", чтобы просмотреть количество строк и времени, потраченных на каждом шаге преобразования.
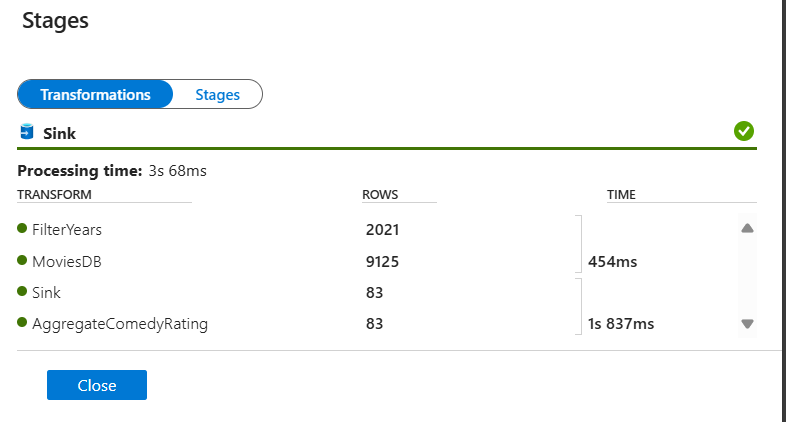
Щелкните преобразование, чтобы получить подробные сведения о столбцах и секционировании данных.
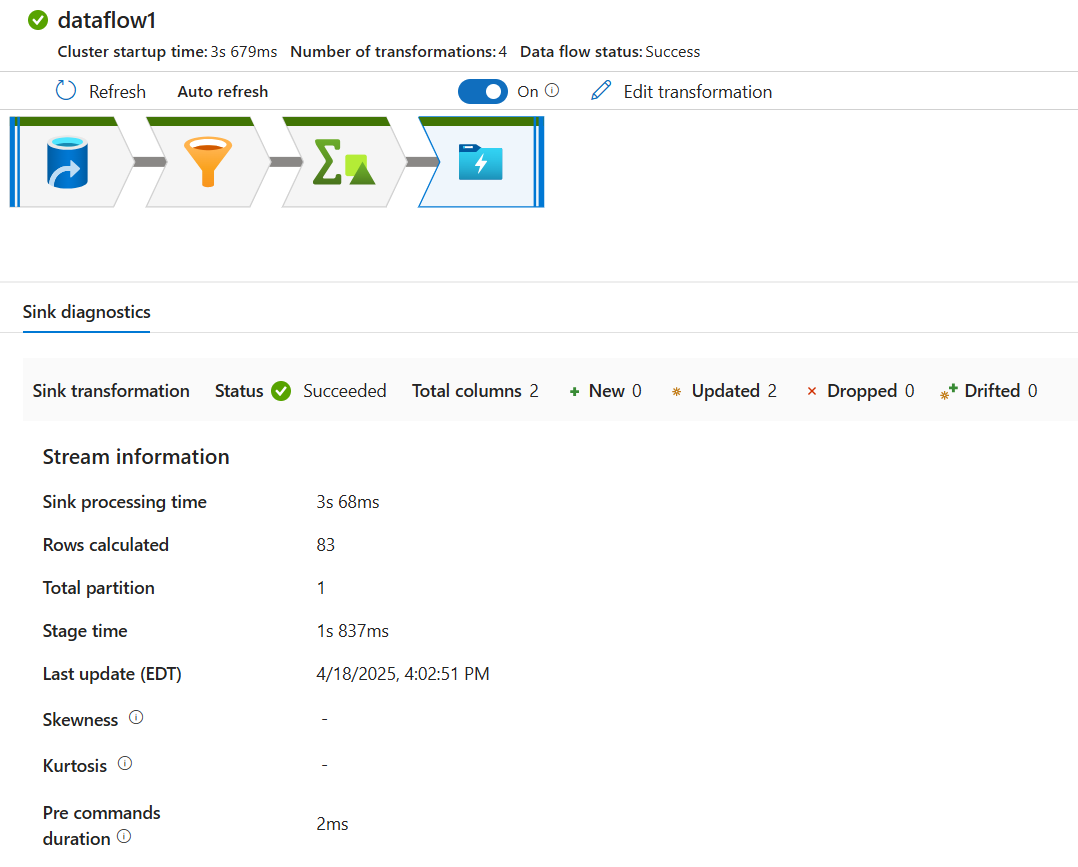
Если все действия в этом кратком руководстве выполнены правильно, то в папку приемника должны быть записаны 83 строки и 2 столбца. Вы можете убедиться в правильности данных, проверив хранилище объектов BLOB.
Связанный контент
Процесс в этом руководстве обрабатывает поток данных, который вычисляет средний рейтинг комедий с 1910 по 2000 год и записывает данные в ADLS. Вы научились выполнять следующие задачи:
- Создали фабрику данных.
- Создайте конвейер с операцией Поток данных.
- Постройте карту потока данных с четырьмя преобразованиями.
- тестовый запуск конвейера;
- Контролировать действие Поток данных.
Дополнительные сведения о языке выражений потока данных.