Пошаговая загрузка данных из Базы данных SQL Azure в Хранилище BLOB-объектов Azure с помощью портала Azure
Область применения: Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве показано, как создать фабрику данных Azure с конвейером, который загружает разностные данные из таблицы в службе "База данных SQL Azure" в Хранилище BLOB-объектов Azure.
В этом руководстве вы выполните следующие шаги:
- Подготовили хранилище данных для хранения значений предела.
- Создали фабрику данных.
- Создали связанные службы.
- Создали наборы данных источника, приемника и предела.
- Создание конвейера.
- Запуск конвейера.
- Осуществили мониторинг выполнения конвейера.
- Просмотр результатов
- Добавление новых данных в источник.
- Повторный запуск конвейера.
- Отслеживание второго запуска конвейера.
- Просмотр результатов второго запуска.
Обзор
Ниже приведена общая схема решения.

Ниже приведены важные действия для создания этого решения.
Выберите столбец для предела. Выберите один столбец в исходном хранилище данных, который можно использовать для создания среза новых или обновленных записей при каждом запуске. Как правило, данные в этом выбранном столбце (например, последнее_время_изменения или идентификатор) продолжают увеличиваться по мере создания или обновления строк. В качестве предела используется максимальное значение в этом столбце.
Подготовьте хранилище данных для хранения значений предела. В этом руководстве вы сохраните значение предела в базе данных SQL.
Создайте конвейер, используя следующий рабочий процесс:
Конвейер в этом решении содержит следующие действия:
- Создайте два действия поиска. Используйте первое действие поиска для получения последнего значения предела, а второе для получения нового значения предела. Эти значения передаются в действие копирования.
- Создайте действие копирования, копирующее строки из исходного хранилища данных со значениями столбцов предела, которые выше значений старого предела и меньше значений нового. Затем оно копирует разностные данные из исходного хранилища данных в хранилище BLOB-объектов в качестве нового файла.
- Создайте действие хранимой процедуры, которое обновляет значение предела для конвейера при последующем выполнении.
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Необходимые компоненты
- База данных SQL Azure. Используйте базу данных как исходное хранилище данных. Если у вас нет базы данных в Базе данных SQL Azure, вы можете создать ее, выполнив инструкции из статьи Краткое руководство. Создание отдельной базы данных в Базе данных SQL Azure.
- Хранилище Azure. В этом руководстве в качестве приемника будет использоваться хранилище BLOB-объектов. Если у вас нет учетной записи хранения, создайте ее, следуя действиям в разделе Создание учетной записи хранения. Создайте контейнер с именем adftutorial.
Создание таблицы источника данных в базе данных SQL
Откройте SQL Server Management Studio. В обозревателе сервера щелкните правой кнопкой мыши базу данных и выберите Создать запрос.
Выполните указанную ниже команду SQL для базы данных SQL, чтобы создать таблицу с именем
data_source_tableв качестве хранилища источника данных.create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');В этом руководстве в качестве столбца предела мы будем использовать LastModifytime. В следующей таблице показаны данные в хранилище источника данных.
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
Создание дополнительной таблицы в базе данных SQL для хранения значения верхнего предела
Выполните указанную ниже команду SQL для базы данных SQL, чтобы создать таблицу с именем
watermarktableдля хранения значения предела.create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Задайте значение по умолчанию верхнего предела, используя имя таблицы исходного хранилища данных. В этом руководстве используется таблица с именем data_source_table.
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')Просмотрите данные в таблице
watermarktable.Select * from watermarktableВыходные данные:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
Создание хранимой процедуры в базе данных SQL
Выполните указанную ниже команду, чтобы создать хранимую процедуру в базе данных SQL.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Создание фабрики данных
Запустите веб-браузер Microsoft Edge или Google Chrome. Сейчас только эти браузеры поддерживают пользовательский интерфейс фабрики данных.
В меню слева выберите Создать ресурс>Интеграция>Фабрика данных:
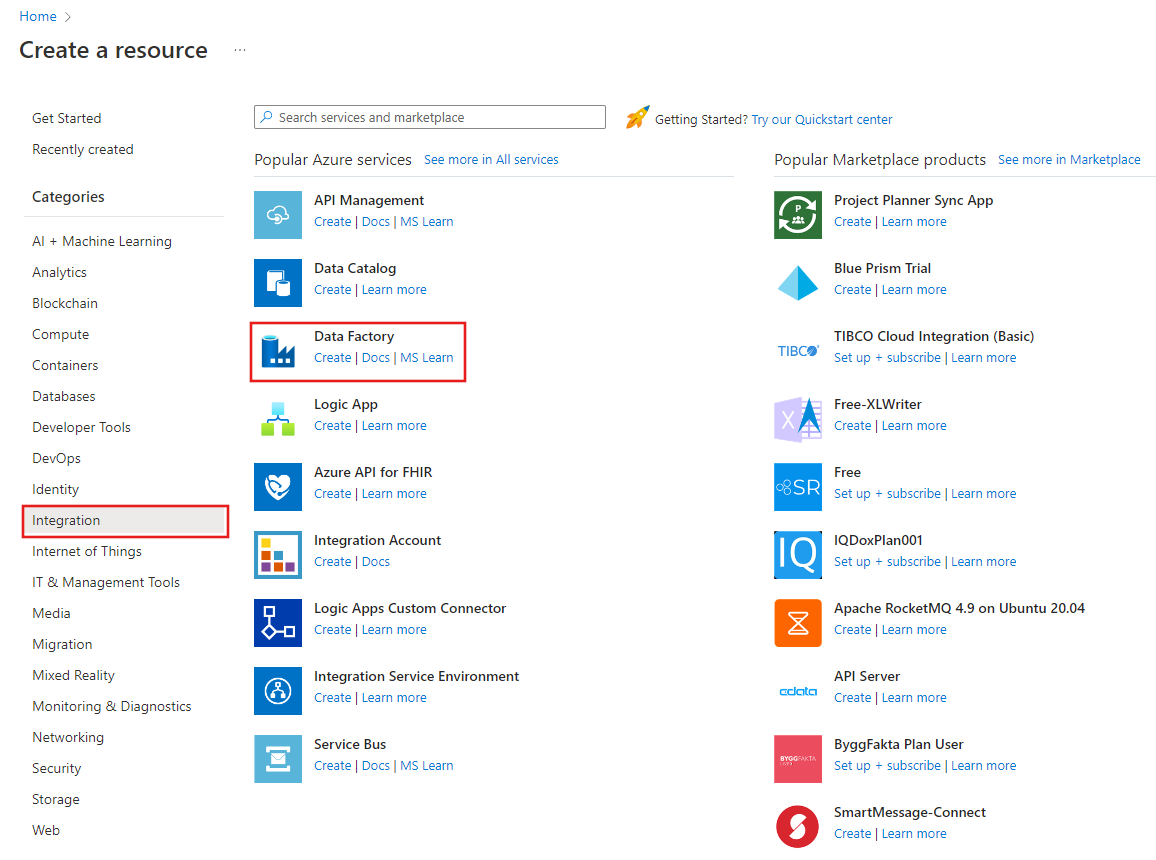
На странице Новая фабрика данных введите ADFIncCopyTutorialDF в поле Имя.
Имя фабрики данных Azure должно быть глобально уникальным. Если вы увидите красный восклицательный знак с указанным ниже текстом ошибки, введите другое имя фабрики данных (например, ваше_имя_ADFIncCopyTutorialDF) и попробуйте создать фабрику данных снова. Ознакомьтесь со статьей Фабрика данных Azure — правила именования, чтобы узнать правила именования для артефактов службы "Фабрика данных".
Имя фабрики данных ADFIncCopyTutorialDF недоступно.
Выберите подписку Azure, в рамках которой вы хотите создать фабрику данных.
Для группы ресурсов выполните одно из следующих действий.
Выберите Использовать существующуюи укажите существующую группу ресурсов в раскрывающемся списке.
Выберите Создать новуюи укажите имя группы ресурсов.
Сведения о группах ресурсов см. в статье, где описывается использование групп ресурсов для управления ресурсами Azure.
Укажите V2 при выборе версии.
Укажите расположение фабрики данных. В раскрывающемся списке отображаются только поддерживаемые расположения. Хранилища данных (служба хранилища Azure, База данных SQL Azure, Управляемый экземпляр SQL Azure и т. д.) и вычислительные ресурсы (HDInsight и т. д.), используемые фабрикой данных, могут располагаться в других регионах.
Нажмите кнопку Создать.
Когда завершится создание, откроется страница Фабрика данных, как показано на рисунке ниже.
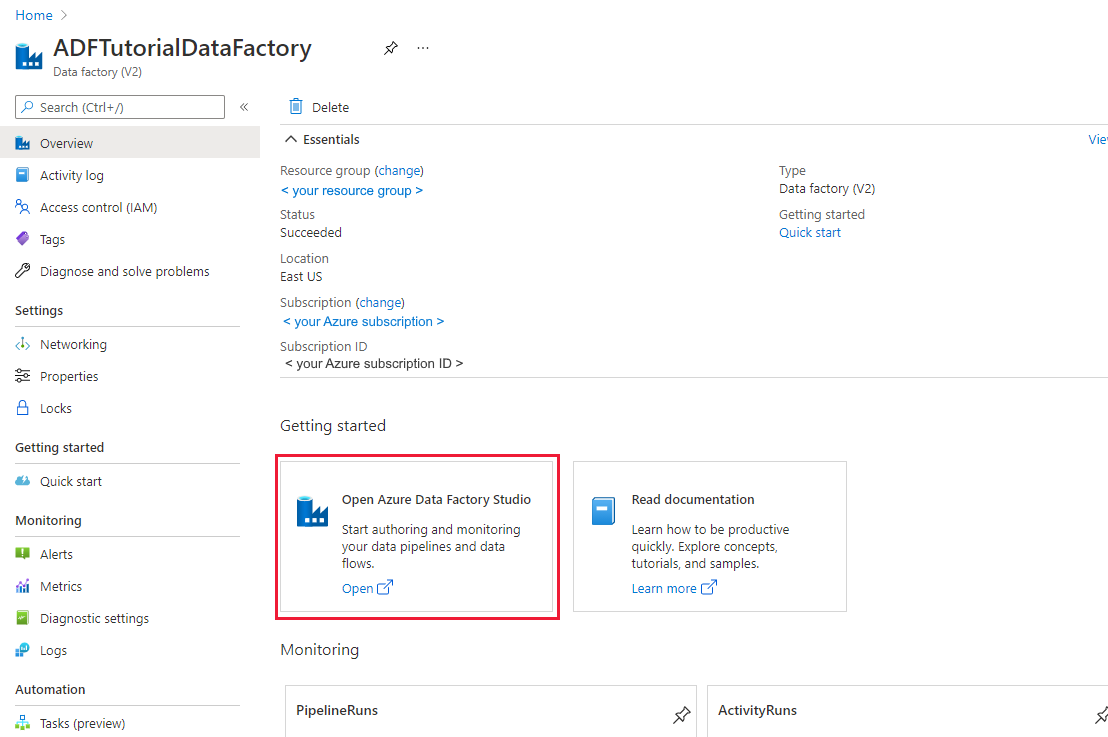
Нажмите кнопку Открыть на элементе Open Azure Data Factory Studio (Открыть студию Фабрики данных Azure), чтобы запустить пользовательский интерфейс Фабрики данных Azure на отдельной вкладке.
Создание конвейера
В этом руководстве вы создадите конвейер с двумя действиями поиска, одним действием копирования и одним действием хранимой процедуры, связанными в одном конвейере.
На домашней странице пользовательского интерфейса Фабрики данных выберите элемент Orchestrate (Оркестрация).
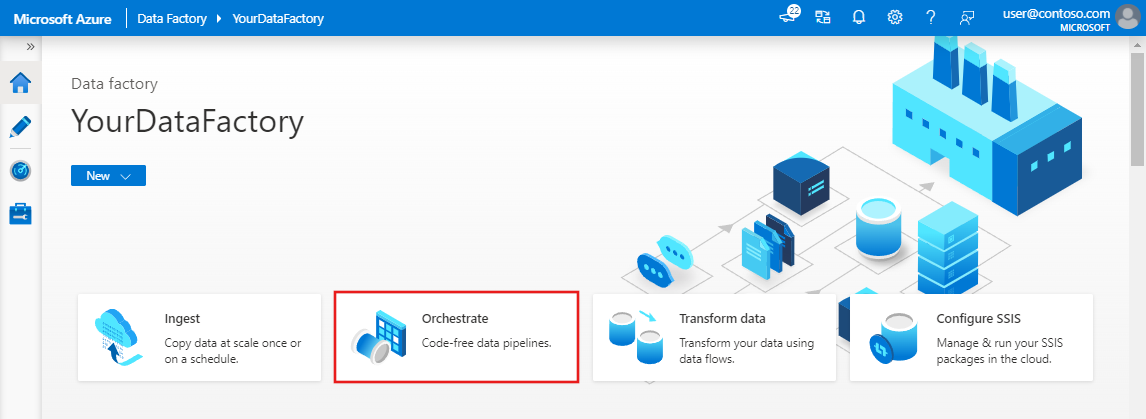
На общей панели в разделе Свойства укажите значение IncrementalCopyPipeline для параметра Имя. Затем сверните панель, щелкнув значок Свойства в правом верхнем углу.
Теперь добавьте первое действие поиска, которое получает старое значение нижнего предела. На панели Действия разверните элемент Общие и перетащите действие Поиск в область конструктора конвейера. Введите для нового действия имя LookupOldWaterMarkActivity.
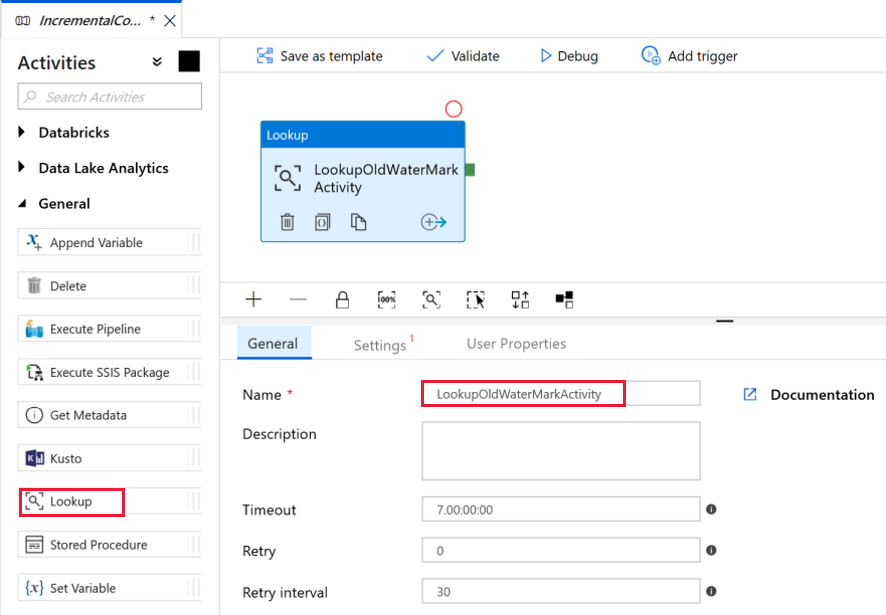
Перейдите на вкладку Параметры и щелкните + Создать в области Source Dataset (Исходный набор данных). На этом шаге вы создадите набор данных для представления данных в таблице watermarktable. В этой таблице содержится старый нижний предел, который использовался в предыдущей операции копирования.
В окне Новый набор данных выберите База данных SQL Microsoft Azure и щелкните Продолжить. Откроется новая вкладка для этого набора данных.
В окне Установка свойств набора данных введите WatermarkDataset в поле Имя.
В поле Связанная служба, выберитесоздать, а затем выполните следующие действия:
Введите AzureSqlDatabaseLinkedService в поле Имя.
Выберите нужный сервер в списке Имя сервера.
Выберите Имя базы данныхиз раскрывающегося списка.
Введите имя пользователя и пароль.
Чтобы проверить подключение к базе данных SQL, нажмите кнопку Проверить подключение.
Нажмите кнопку Готово.
Убедитесь, что значение AzureSqlDatabaseLinkedService выбрано в списке Связанная служба.
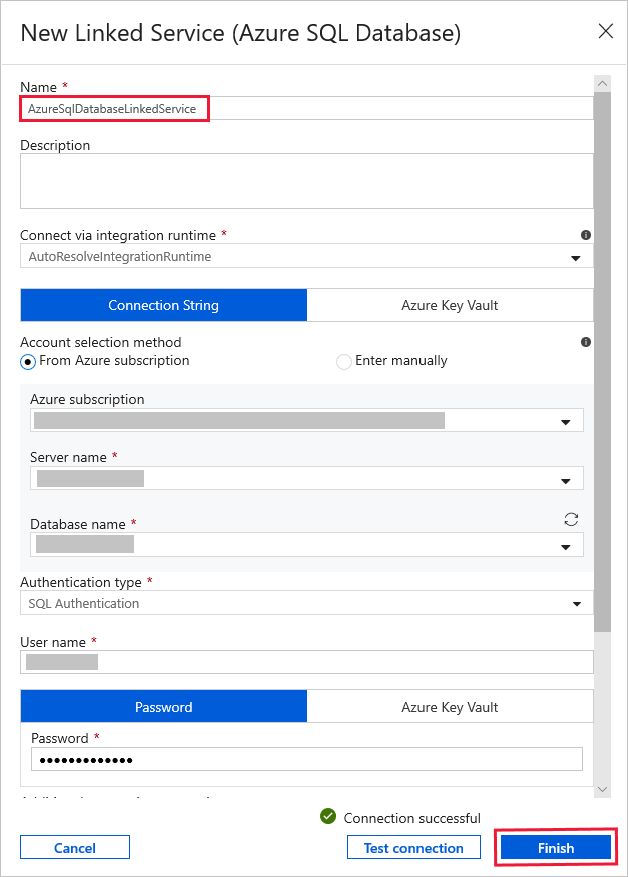
Выберите Готово.
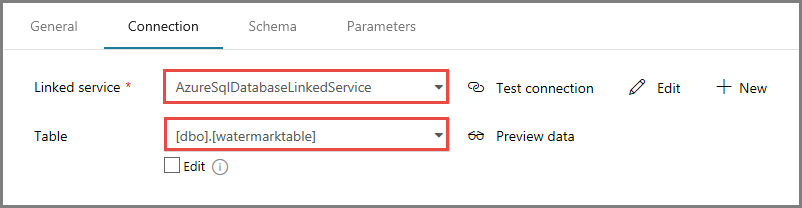
На вкладке Подключение выберите [dbo].[watermarktable] для Таблицы. Если вы хотите просмотреть данные в таблице, нажмите кнопку Просмотр данных.
Перейдите в редактор конвейера, щелкнув вкладку конвейера вверху или имя конвейера в представлении в виде дерева слева. В окне свойств для действия Поиск убедитесь в том, что в поле Исходный набор данных выбран вариант WatermarkDataset.
На панели Действия разверните элемент Общие и перетащите еще одно действие Поиск в область конструктора конвейера, а затем назовите его LookupNewWaterMarkActivity на вкладке Общие в окне свойств. Это действие поиска получает новое значение нижнего предела из таблицы, где хранятся исходные данные для копирования в приемник.
В окне свойств второго действия Поиск перейдите на вкладку Параметры и нажмите кнопку Создать. Здесь вы создаете набор данных, который будет указывать на исходную таблицу с новым значением нижнего предела (максимального значения LastModifyTime).
В окне Новый набор данных выберите База данных SQL Microsoft Azure и щелкните Продолжить.
В окне Настройки свойств введите SourceDataset для Имя. Выберите AzureSqlDatabaseLinkedService в списке Связанная служба.
Выберите [dbo].[ data_source_table] в списке "Таблица". Запрос для этого набора данных вы создадите позднее в этом руководстве. Этот запрос будет более приоритетным, чем указанная на этом шаге таблица.
Выберите Готово.
Перейдите в редактор конвейера, щелкнув вкладку конвейера вверху или имя конвейера в представлении в виде дерева слева. В окне свойств для действия Поиск, убедитесь, что в поле Исходный набор данных выбран вариант SourceDataset.
Выберите Запрос в поле Использовать запрос и введите следующий запрос, который выбирает максимальное значение LastModifytime из таблицы data_source_table. Убедитесь, что установлен флажок First row only (Только первая строка).
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table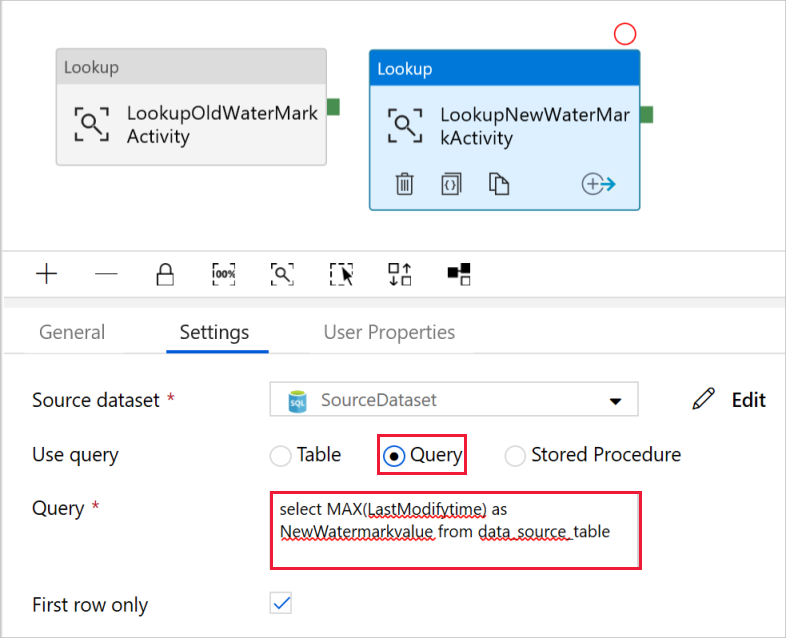
В панели элементов Действия разверните Перемещение и Преобразование и перетащите действие Копирование из этой панели элементов, а затем присвойте ему имя IncrementalCopyActivity.
Соедините оба действия поиска с действием копирования, перетащив зеленую кнопку от действия поиска к действию копирования. Когда цвет границы для действия копирования изменится на синий, отпустите кнопку мыши.
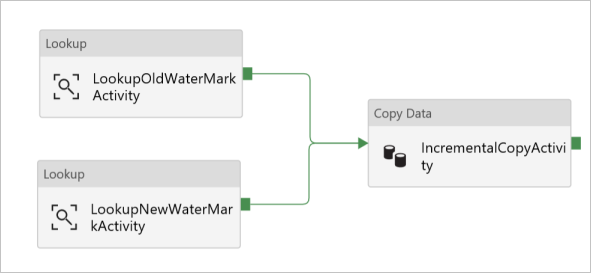
Выберите действие Копирование и проверьте его свойства в окне Свойства.
Откройте вкладку Источник в окне Свойства и выполните здесь следующие действия.
Выберите SourceDataset в поле Source Dataset (Исходный набор данных).
Выберите Запрос в поле Использовать запрос.
Введите следующий запрос SQL в поле Запрос.
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'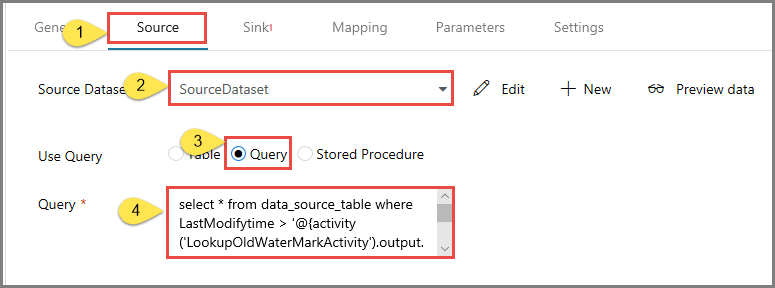
Перейдите на вкладку Приемник и нажмите кнопку + Создать в поле Sink Dataset (Целевой набор данных).
В этом руководстве в качестве целевого хранилища данных используется хранилище BLOB-объектов Azure. Поэтому выберите Хранилище BLOB-объектов и нажмите кнопку Продолжить в окне Новый набор данных.
На странице Выбор формата выберите тип формата данных, а затем нажмите кнопку Продолжить.
В окне Установка свойств введите SinkDataset для Имя. В разделе Связанная служба выберите + Создать. На этом шаге вы создадите подключение (связанную службу) для хранилища BLOB-объектов Azure.
В окне New Linked Service (Azure Blob Storage) (Новая связанная служба (хранилище BLOB-объектов Azure)) выполните следующие действия:
- Введите AzureStorageLinkedService в поле имени.
- Выберите учетную запись хранения в списке Storage account name (Имя учетной записи хранения).
- Проверьте соединение и нажмите кнопку Готово.
Убедитесь, что окно Установка свойствAzureStorageLinkedService выбрано в списке Связанная служба. Выберите Готово.
Перейдите на вкладку Подключения в SinkDataset и выполните следующие действия:
- В поле Путь к файлу введите adftutorial/incrementalcopy. Здесь adftutorial обозначает имя контейнера больших двоичных объектов, а incrementalcopy — имя папки в нем. В этом фрагменте кода предполагается, что у вас есть контейнер BLOB-объектов с именем adftutorial в хранилище BLOB-объектов. Создайте контейнер (если его еще нет) или присвойте ему имя имеющегося контейнера. Фабрика данных Azure автоматически создает целевую папку incrementalcopy, если она еще не существует. Можно также нажать кнопку Обзор рядом с полем Путь к файлу, чтобы перейти к нужной папке в контейнере больших двоичных объектов.
- Для части Файл в поле Путь файла выберите Добавить динамическое содержимое [Alt+P], а затем введите
@CONCAT('Incremental-', pipeline().RunId, '.txt')в открывшемся окне. Выберите Готово. Это выражение динамически создает имя файла. Каждый запуск конвейера имеет уникальный идентификатор. Действие копирования использует этот идентификатор запуска при создании имени файла.
Перейдите в редактор конвейера, щелкнув вкладку конвейера вверху или имя конвейера в представлении в виде дерева слева.
На панели элементов Действия разверните элемент Общие, а затем перетащите действие Хранимая процедура с панели элементов Действия в область конструктора конвейера. Соедините результаты действия Копирование, обозначенные зеленым цветом, с действием Хранимая процедура.
Выберите действие хранимой процедуры в конструкторе конвейера и замените его имя значением StoredProceduretoWriteWatermarkActivity.
Перейдите на вкладку Учетная запись SQL и выберите AzureSqlDatabaseLinkedService в списке Связанная служба.
Перейдите на вкладку Хранимая процедура и выполните здесь следующие действия:
В качестве имени хранимой процедуры выберите usp_write_watermark.
Чтобы указать значения для параметров хранимой процедуры, щелкните Импорт параметров и введите следующие значения:
Имя. Тип значение LastModifiedtime Дата/время @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName Строка @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 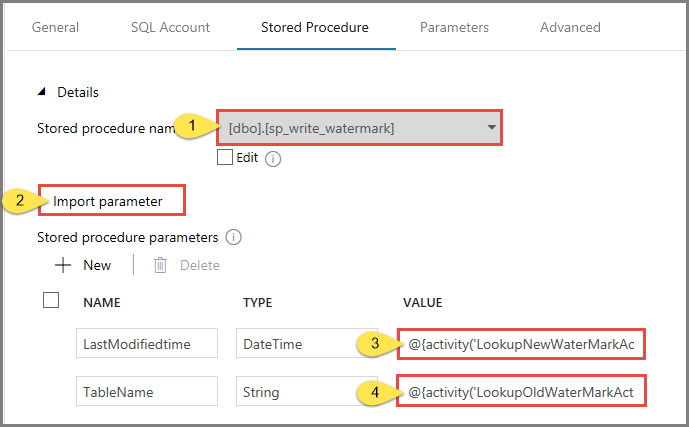
Чтобы проверить настройки конвейера, нажмите кнопку Проверить на панели инструментов. Убедитесь, что проверка завершается без ошибок. Чтобы закрыть окно отчета о проверке конвейера, нажмите >>.
Опубликуйте сущности (связанные службы, наборы данных и конвейеры) в службе фабрики данных Azure, щелкнув Опубликовать все. Дождитесь сообщения об успешном завершении публикации.
Активация выполнения конвейера
Щелкните Добавить триггер на панели инструментов, а затем Запустить сейчас.
На странице Запуск конвейера нажмите кнопку Готово.
Мониторинг конвейера
Перейдите на вкладку Мониторинг слева. Вы увидите состояние выполнения конвейера, активированного ручным триггером. С помощью ссылок в столбце Имя конвейера вы можете просмотреть подробные сведения о выполнении и повторно запустить конвейер.
Чтобы просмотреть сведения о выполнениях действий, связанных с выполнением конвейера, щелкните ссылку в столбце Имя конвейера. Чтобы просмотреть сведения о выполнениях действий, щелкните ссылку Сведения (значок очков) в столбце Имя действия. Выберите Все запуски конвейеров в верхней части окна, чтобы вернуться к представлению "Выполнения конвейеров". Чтобы обновить список, нажмите кнопку Обновить.
Проверьте результаты.
Подключитесь к учетной записи хранения Azure с помощью специальных средств, например Обозревателя службы хранилища Azure. Убедитесь, что целевой файл создан в папке incrementalcopy в контейнере adftutorial.
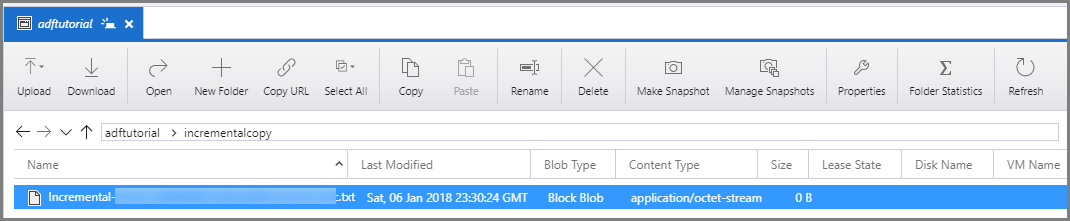
Откройте целевой файл и убедитесь, что все данные скопированы из таблицы data_source_table в файл большого двоичного объекта.
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000Проверьте последнее значение из
watermarktable. Вы увидите, что значение предела было обновлено.Select * from watermarktableРезультат выглядит так:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
Добавление новых данных в источник
Добавьте новые данные в базу данных (хранилище источника данных).
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
Обновленные данные в базе данных выглядят так:
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
Запуск второго конвейера
Перейдите на вкладку "Изменить ". Щелкните конвейер в представлении дерева, если он не открыт в конструкторе.
Щелкните Добавить триггер на панели инструментов, а затем Запустить сейчас.
Отслеживание второго запуска конвейера.
Перейдите на вкладку Мониторинг слева. Вы увидите состояние выполнения конвейера, активированного ручным триггером. Ссылки в столбце Имя конвейера позволят вам просмотреть подробные сведения о действиях и повторно выполнить конвейер.
Чтобы просмотреть сведения о выполнениях действий, связанных с выполнением конвейера, щелкните ссылку в столбце Имя конвейера. Чтобы просмотреть сведения о выполнениях действий, щелкните ссылку Сведения (значок очков) в столбце Имя действия. Выберите Все запуски конвейеров в верхней части окна, чтобы вернуться к представлению "Выполнения конвейеров". Чтобы обновить список, нажмите кнопку Обновить.
Проверка второго выходного файла
В хранилище BLOB-объектов вы увидите, что был создан другой файл. В этом руководстве новый файл имеет имя
Incremental-<GUID>.txt. Открыв этот файл, вы увидите записи двух строк.6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000Проверьте последнее значение из
watermarktable. Вы увидите, что значение предела было обновлено снова.Select * from watermarktableОбразец вывода:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
Связанный контент
В этом руководстве вы выполнили следующие шаги:
- Подготовили хранилище данных для хранения значений предела.
- Создали фабрику данных.
- Создали связанные службы.
- Создали наборы данных источника, приемника и предела.
- Создание конвейера.
- Запуск конвейера.
- Осуществили мониторинг выполнения конвейера.
- Просмотр результатов
- Добавление новых данных в источник.
- Повторный запуск конвейера.
- Отслеживание второго запуска конвейера.
- Просмотр результатов второго запуска.
В этом руководстве с помощью конвейера показано, как скопировать данные из одной таблицы в Базе данных SQL в Хранилище BLOB-объектов. Перейдите к следующему руководству, чтобы узнать о копировании данных из нескольких таблиц в Базе данных SQL Server в Базу данных SQL.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по