Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure
Фабрика данных Azure  Azure Synapse Analytics
Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этом руководстве с помощью портала Azure вы создадите конвейер фабрики данных, который преобразует данные, используя действие Hive в кластере HDInsight, находящемся в виртуальной сети Azure (VNet). В этом руководстве вы выполните следующие шаги:
- Создали фабрику данных.
- Создание локальной среды выполнения интеграции
- Создание связанных службы хранилища Azure и службы Azure HDInsight.
- Создание конвейера с действием Hive.
- Активация выполнения конвейера.
- Мониторинг конвейера
- Проверка выходных данных
Если у вас нет подписки Azure, создайте бесплатную учетную запись, прежде чем приступить к работе.
Предварительные требования
Примечание.
Мы рекомендуем использовать модуль Azure Az PowerShell для взаимодействия с Azure. Чтобы начать работу, см. статью Установка Azure PowerShell. Дополнительные сведения см. в статье Перенос Azure PowerShell с AzureRM на Az.
Учетная запись хранения Azure. Создайте скрипт Hive и отправьте его в хранилище Azure. Выходные данные скрипта Hive хранятся в этой учетной записи хранения. В этом примере кластер HDInsight использует эту учетную запись хранения Azure в качестве основного хранилища.
Виртуальная сеть Azure. Если у вас нет виртуальной сети Azure, создайте ее, выполнив эти инструкции. В этом примере HDInsight находится в виртуальной сети Azure. Ниже приведен образец конфигурации виртуальной сети Azure.
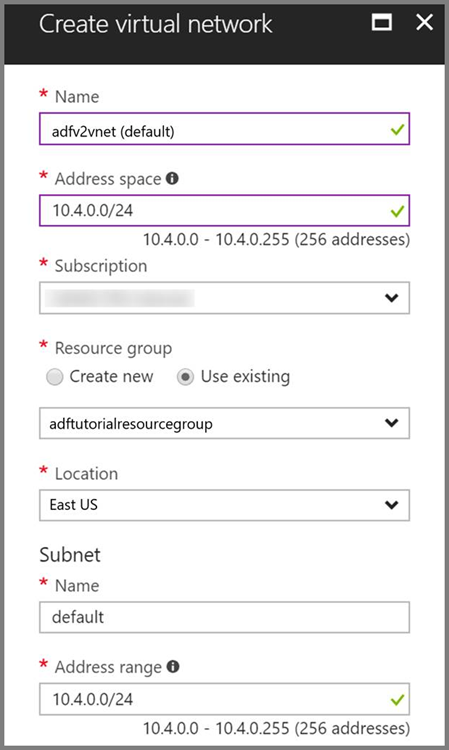
Кластер HDInsight. Создайте кластер HDInsight и присоедините его к виртуальной сети, созданной на предыдущем шаге, следуя указаниям в статье Расширение возможностей HDInsight с помощью виртуальной сети Azure. Ниже приведен образец конфигурации HDInsight в виртуальной сети.
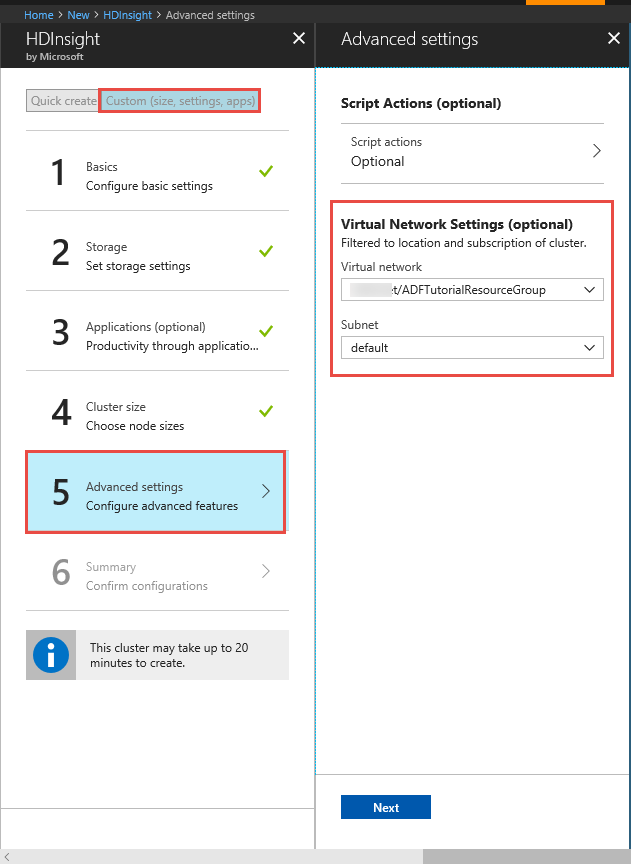
Azure PowerShell. Следуйте инструкциям по установке и настройке Azure PowerShell.
Виртуальная машина. Создайте виртуальную машину Azure и присоедините ее к той же виртуальной сети, которая содержит кластер HDInsight. Дополнительные сведения см. в разделе Создание виртуальных машин.
Отправка скрипта Hive в вашу учетную запись хранилища BLOB-объектов
Создайте файл Hive SQL с именем hivescript.hql со следующим содержимым:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableВ хранилище BLOB-объектов Azure создайте контейнер с именем adftutorial, если он не существует.
Создайте папку с именем hivescripts.
Отправьте файл hivescript.hql во вложенную папку hivescripts.
Создание фабрики данных
Если вы еще не создали фабрику данных, выполните действия, описанные в кратком руководстве по созданию фабрики данных с помощью портала Azure и студии Фабрики данных Azure. После создания перейдите к фабрике данных на портале Azure.

Выберите Открыть на плитке Открыть Azure Data Factory Studio, чтобы запустить приложение интеграции данных в отдельной вкладке.
Создание локальной среды выполнения интеграции
Поскольку кластер Hadoop находится в виртуальной сети, локальную среду выполнения интеграции (IR) следует устанавливать в той же виртуальной сети. В этом разделе вы создадите виртуальную машину, присоедините ее к этой же виртуальной сети и установите на ней локальную среду выполнения интеграции. Локальная среда IR позволяет службе фабрики данных передавать запросы на обработку службе вычислений (например, HDInsight) в пределах виртуальной сети. Она также позволяет перемещать данные в пределах виртуальной сети из Azure в хранилища данных и наоборот. Локальная среда IR используется в том случае, когда хранилище данных или вычислительный ресурс находятся в той же локальной среде.
В пользовательском интерфейсе фабрики данных Azure щелкните Подключения в нижней части окна, перейдите на вкладку Integration Runtimes (Среды выполнения интеграции) и нажмите кнопку + Создать на панели инструментов.
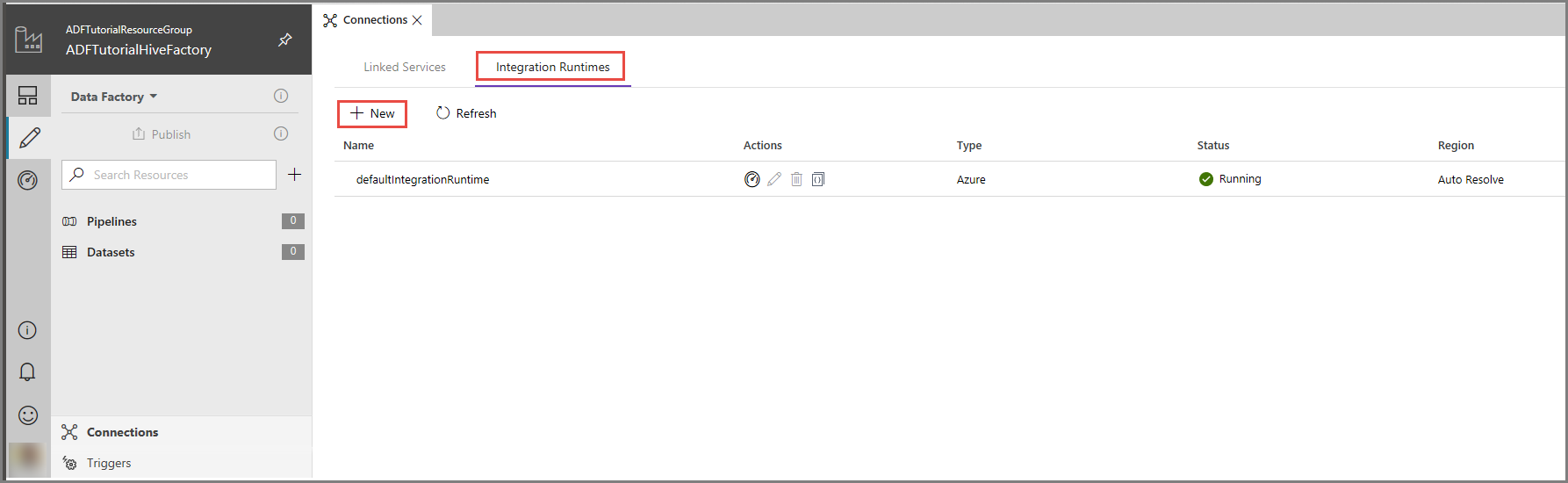
В окне Integration Runtime Setup (Настройка среды выполнения интеграции) выберите вариант Perform data movement and dispatch activities to external computes (Выполнить перемещение данных и передать действия на внешние вычислительные ресурсы), затем щелкните Next (Далее).
Выберите Частная сеть и нажмите кнопку Далее.
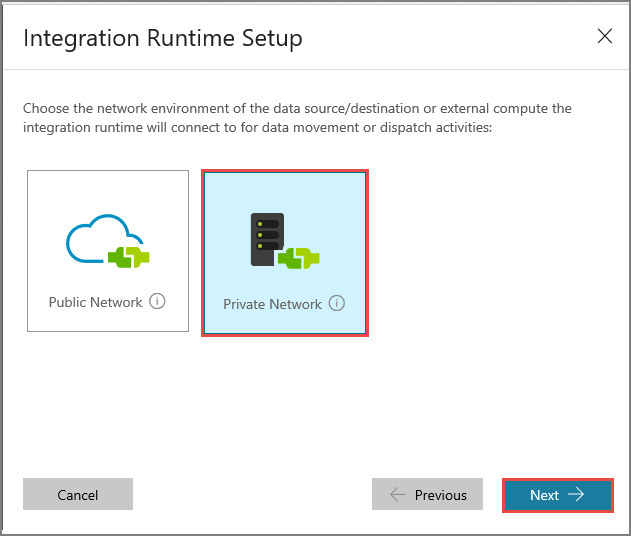
Введите MySelfHostedIR для параметра Name (Имя) и щелкните Next (Далее).
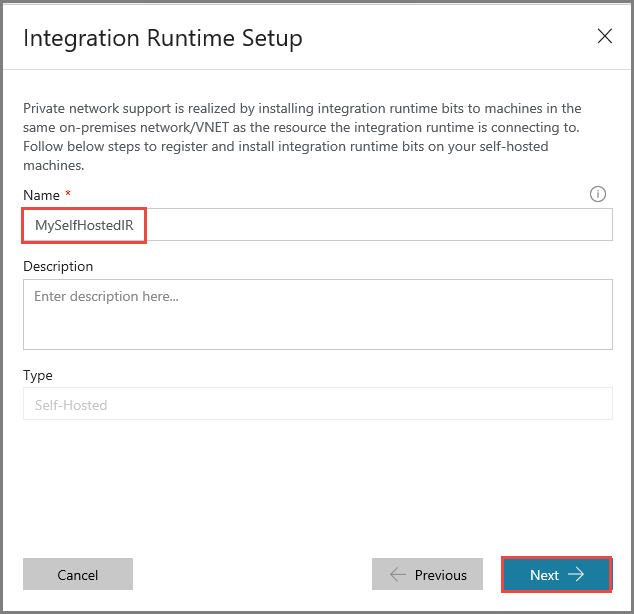
Скопируйте ключ аутентификации для среды IR, нажав кнопку Copy (Копировать), и сохраните этот ключ. Оставьте это окно открытым. Ключ вам потребуется для регистрации среды IR, установленной на виртуальной машине.
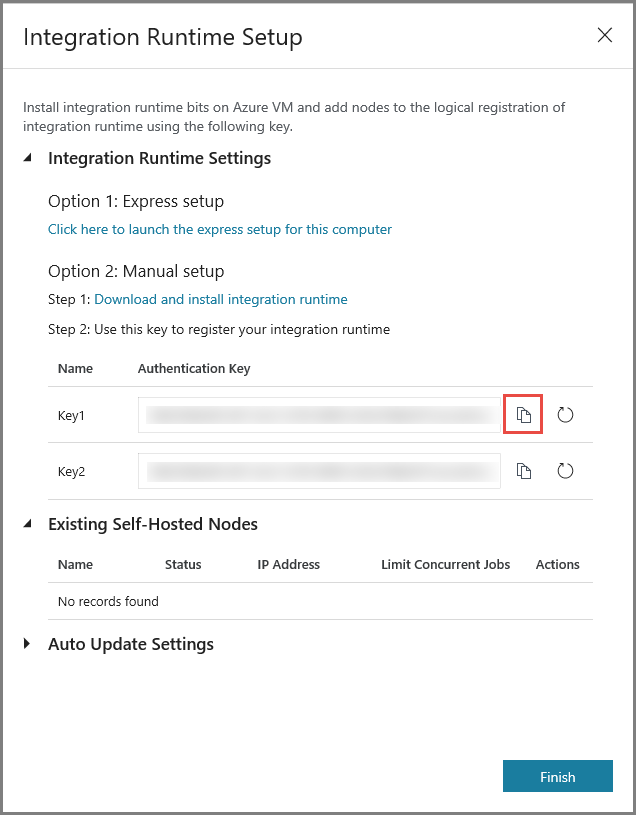
Установка среды IR на виртуальной машине
На виртуальной машине Azure скачайте локальную среду выполнения интеграции. Используйте ключ аутентификации, полученный на предыдущем шаге, чтобы вручную зарегистрировать локальную среду IR.
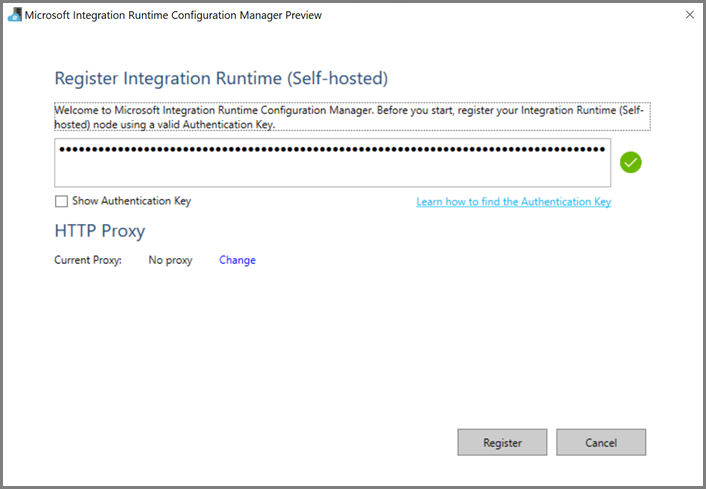
Когда локальная среда IR будет успешно зарегистрирована, вы увидите следующее сообщение.
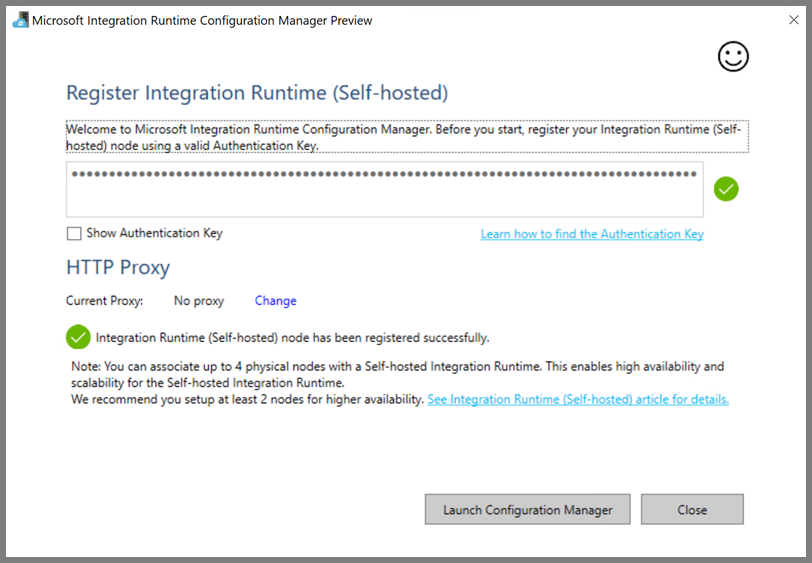
Щелкните Запустить Configuration Manager. Когда узел будет подключен к облачной службе, отобразится следующая страница:
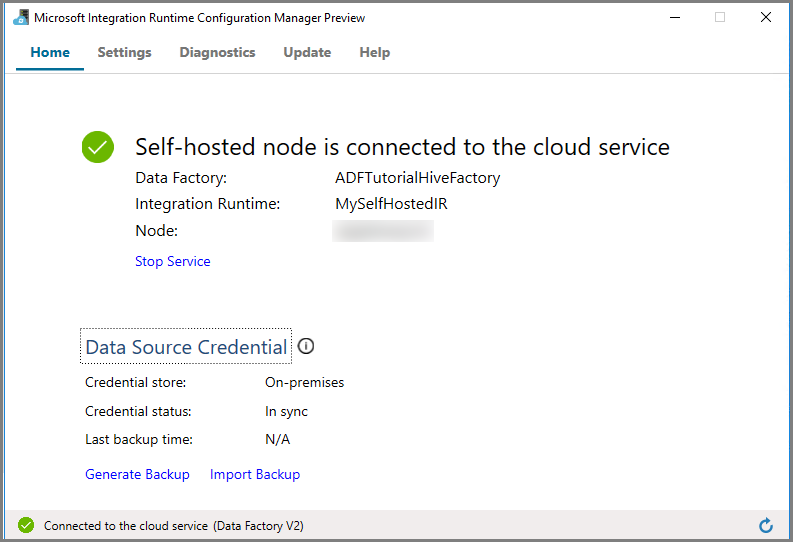
Локальная среда IR в пользовательском интерфейсе фабрики данных Azure
В пользовательском интерфейсе фабрики данных Azure вы можете найти имя и текущее состояние локальной виртуальной машины.
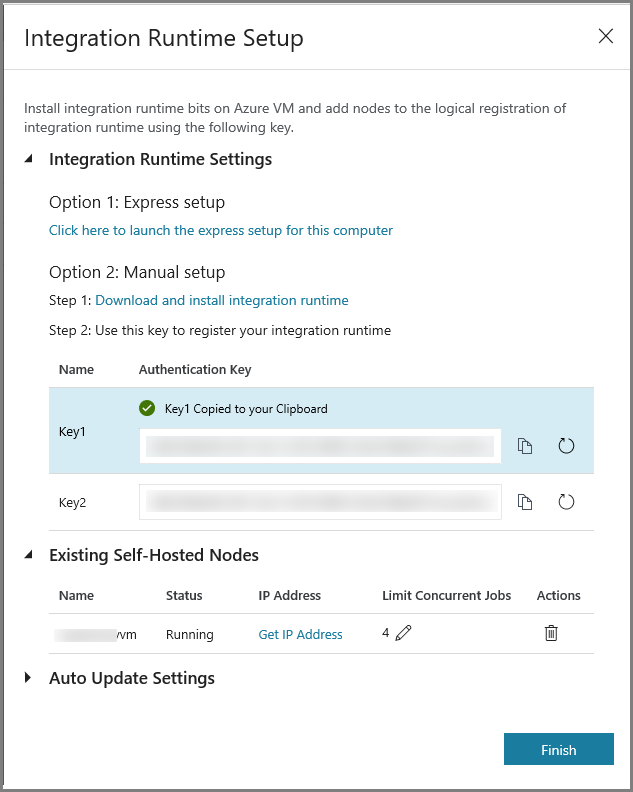
Щелкните Finish (Готово), чтобы закрыть окно Integration Runtime Setup (Настройка среды выполнения интеграции). Теперь вы увидите созданную локальную среду в списке сред IR.

Создание связанных служб
Создайте и разверните две связанные службы в этом разделе:
- Связанную службу хранилища Azure, которая связывает учетную запись хранения Azure с фабрикой данных. Это основное хранилище, которое использует кластер HDInsight. В нашем примере эта же учетная запись хранения Azure пригодится еще для хранения скрипта Hive и его выходных данных.
- Связанная служба HDInsight. Фабрика данных Azure отправляет скрипт Hive в этот кластер HDInsight для выполнения.
Создание связанной службы хранения Azure
Перейдите на вкладку Связанные службы и щелкните Создать.
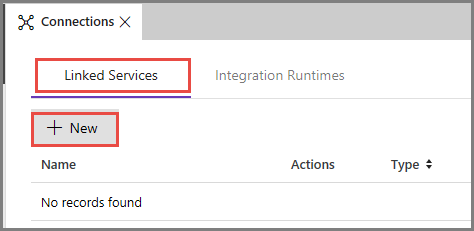
В окне New Linked Service (Новая связанная служба) выберите хранилище BLOB-объектов Azure и щелкните Continue (Продолжить).
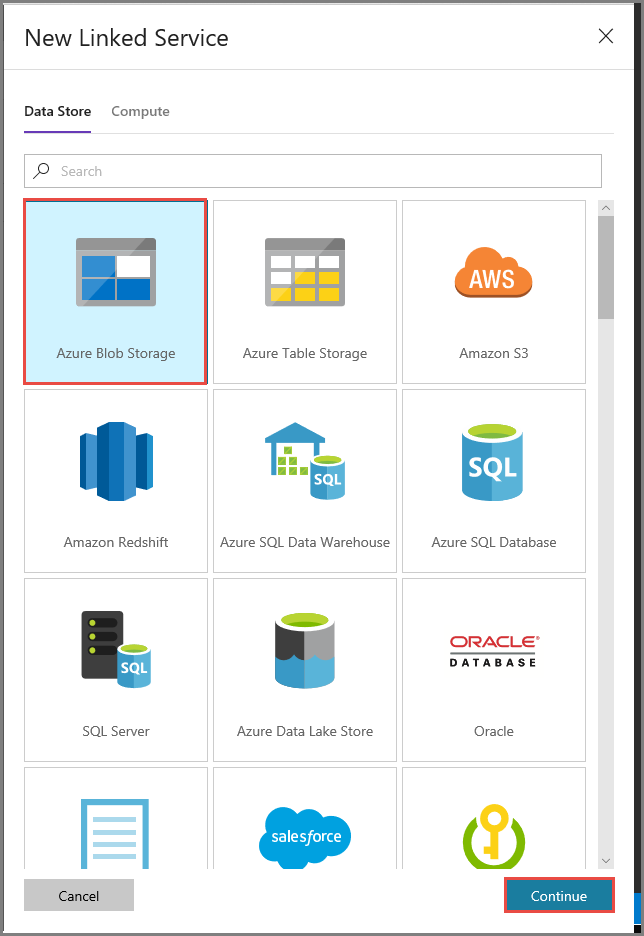
В окне New Linked Service (Новая связанная служба) выполните следующие действия:
Введите AzureStorageLinkedService в поле имени.
Выберите MySelfHostedIR для параметра Connect via integration runtime (Подключиться через среду выполнения интеграции).
В поле Storage account name (Имя учетной записи хранения) выберите нужную учетную запись хранения.
Щелкните Test connection (Проверить подключение), чтобы проверить подключение к учетной записи хранения.
Нажмите кнопку Сохранить.
Создание связанной службы HDInsight
Снова щелкните Создать, чтобы создать еще одну связанную службу.
Перейдите на вкладку Compute (Вычисления), выберите Azure HDInsight и щелкните Continue (Продолжить).
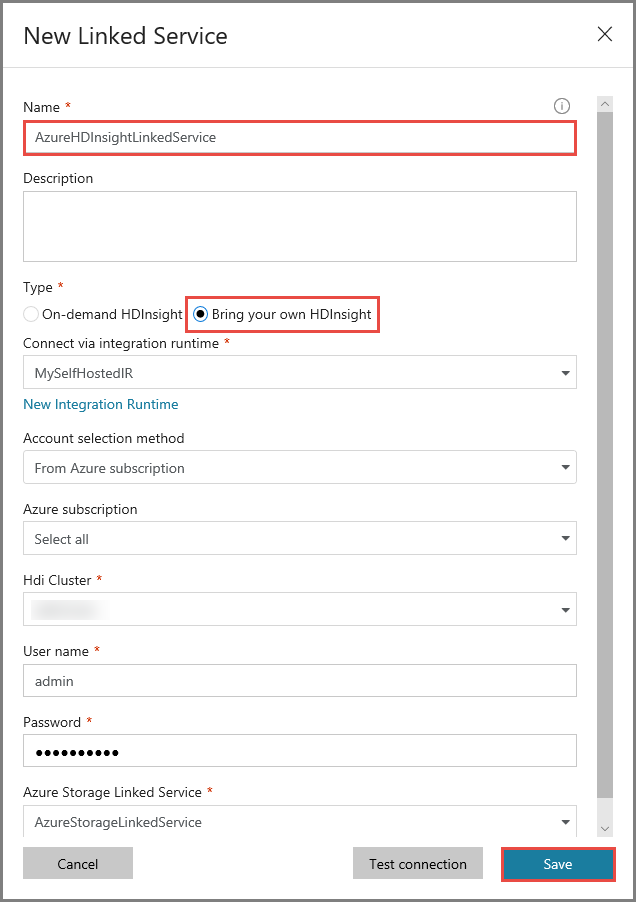
В окне New Linked Service (Новая связанная служба) выполните следующие действия:
Введите AzureHDInsightLinkedService в поле имени.
Выберите Bring your own HDInsight (Подключить свой кластер HDInsight).
Выберите кластер HDInsight в поле HDI cluster (Кластер HDI).
Введите имя пользователя для кластера HDInsight.
Введите пароль для этого пользователя.
В этой статье предполагается, что у вас есть доступ к кластеру через Интернет. Например, что вы можете подключиться к кластеру по адресу https://clustername.azurehdinsight.net. Этот адрес использует общедоступный шлюз, который будет недоступен, если вы использовали группы безопасности сети или определяемые пользователем маршруты для ограничения доступа через Интернет. Чтобы фабрика данных могла отправлять задания в кластер HDInsight в виртуальной сети Azure, необходимо настроить виртуальную сеть Azure таким образом, чтобы URL-адрес был разрешен в частный IP-адрес шлюза, используемого HDInsight.
На портале Azure откройте виртуальную сеть, в которой находится HDInsight. Откройте сетевой интерфейс, используя имя, которое начинается с
nic-gateway-0. Запишите частный IP-адрес. Например, 10.6.0.15.Если ваша виртуальная сеть Azure имеет DNS-сервер, обновите запись DNS, чтобы URL-адрес кластера HDInsight
https://<clustername>.azurehdinsight.netможно было разрешить в10.6.0.15. Если у вас нет DNS-сервера в виртуальной сети Azure, вы можете применить временное решение. Отредактируйте файлы hosts (C:\Windows\System32\drivers\etc) на всех виртуальных машинах, зарегистрированных в качестве узлов локальной среды IR, добавив в них следующую запись:10.6.0.15 myHDIClusterName.azurehdinsight.net
Создание конвейера
На этом этапе создайте конвейер с действием Hive. Это действие выполняет скрипт Hive для получения данных из примера таблицы и сохранения их по пути, который вы определили.
Обратите внимание на следующие аспекты:
- scriptPath указывает путь к скрипту Hive в учетной записи хранения Azure, используемой для MyStorageLinkedService. Путь учитывает регистр.
- Выходные данные выступают в качестве аргумента, используемого в скрипте Hive. Используйте формат
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/, который должен указывать на существующую папку в службе хранилища Azure. Путь учитывает регистр.
В пользовательском интерфейсе фабрики данных щелкните знак + (плюс) на панели слева и выберите вариант Конвейер.
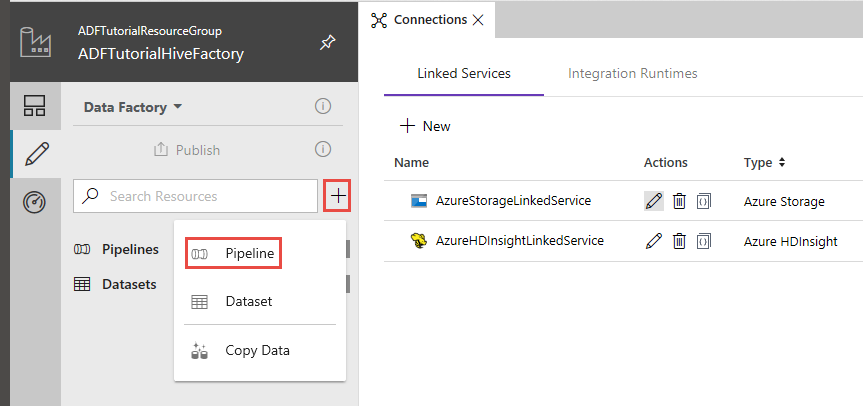
На панели инструментов Действия разверните HDInsight и перетащите действие Hive в область конструктора конвейера.
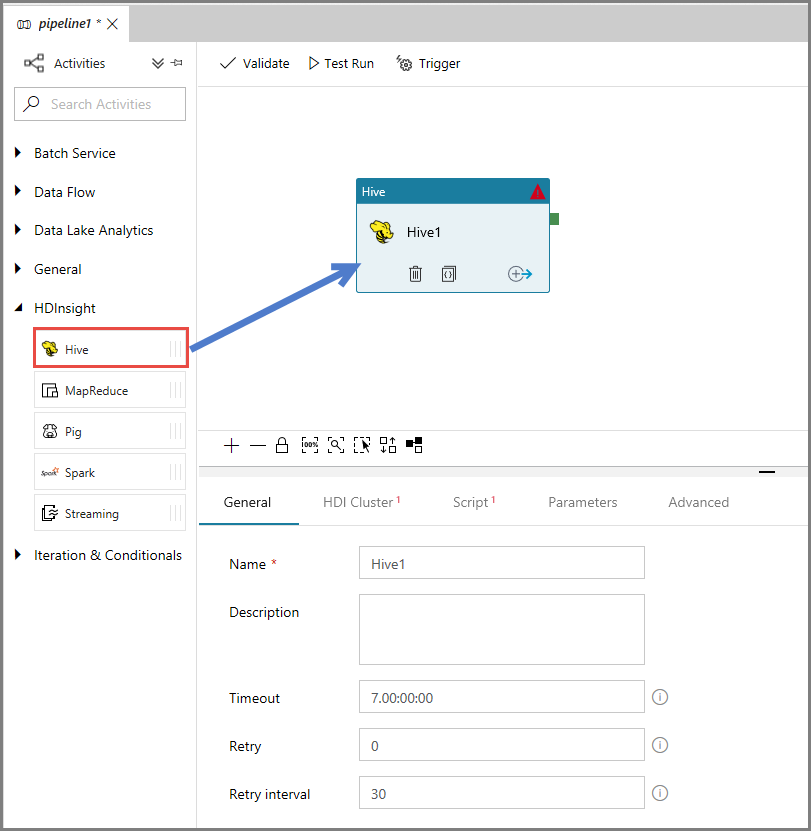
В окне свойств перейдите на вкладку HDI Cluster (Кластер HDI) и выберите AzureHDInsightLinkedService в качестве связанной службы HDInsight.

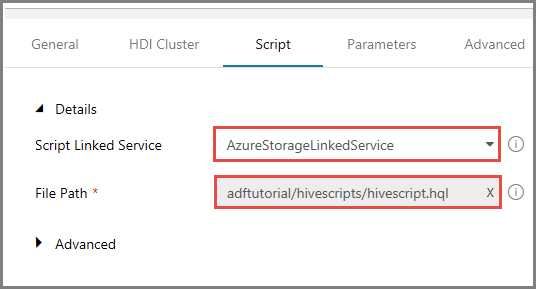
Переключитесь на вкладку Scripts (Скрипты) и выполните следующие действия:
Введите AzureStorageLinkedService в качестве имени связанной службы.
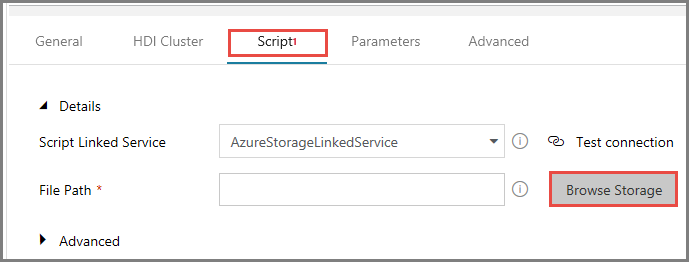
В области File Path (Путь к файлу) щелкните Browse Storage (Поиск в хранилище).
В окне Choose a file or folder (Выберите файл или папку) перейдите к папке hivescripts контейнера adftutorial, выберите файл hivescript.hql и щелкните Finish (Готово).
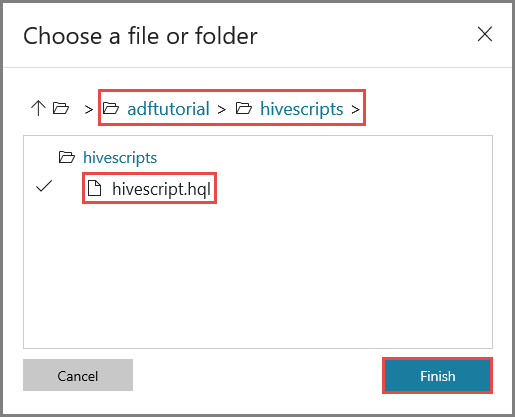
Убедитесь, что в поле File Path (Путь к файлу) появилось значение adftutorial/hivescripts/hivescript.hql.
На вкладке Script (Скрипт) разверните раздел Advanced (Дополнительно).
Щелкните действие Auto-fill from script (Заполнить автоматически из скрипта) в области Parameters (Параметры).
Введите значение для параметра Output (Вывод) в следующем формате:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Например:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.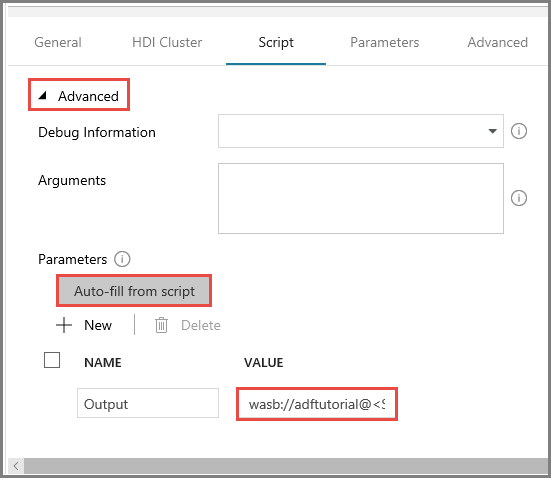
Чтобы опубликовать артефакты в фабрике данных, щелкните Опубликовать.
Активация выполнения конвейера
Прежде всего проверьте работу конвейера, нажав кнопку Проверить на панели инструментов. Закройте окно выходных данных проверки конвейера, щелкнув стрелку вправо (>>).
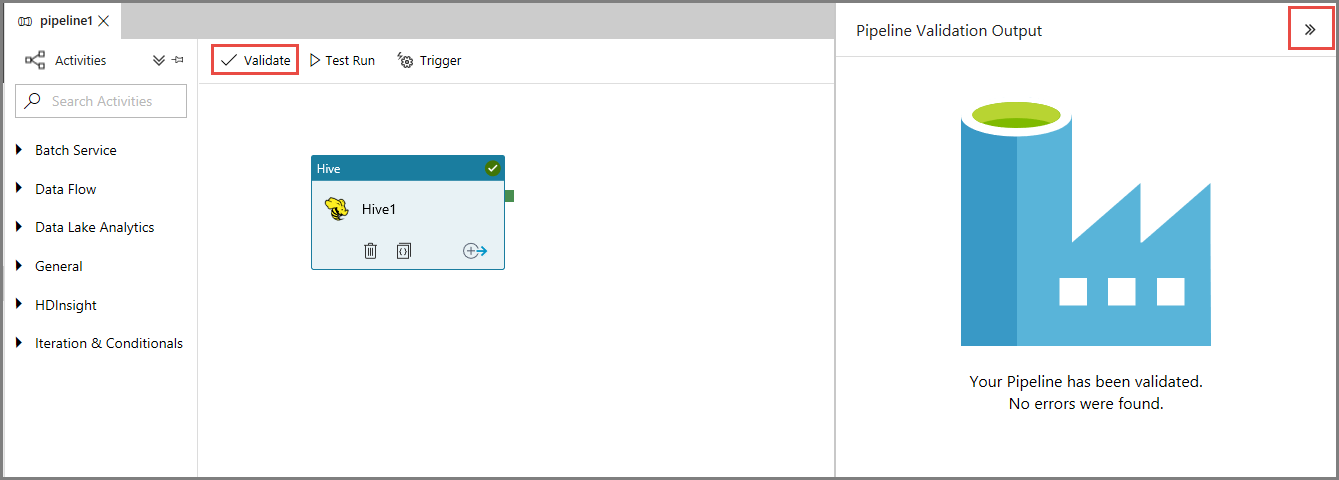
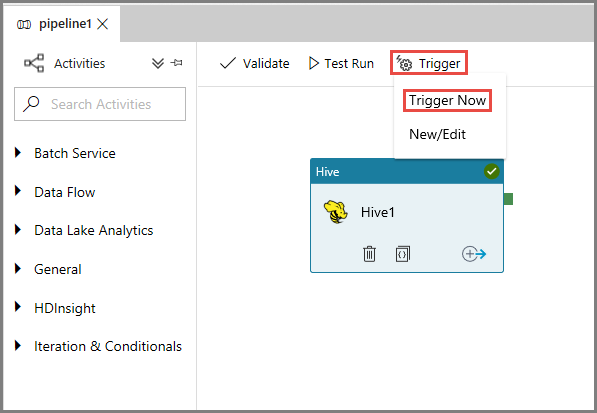
Чтобы активировать конвейер, щелкните "Триггер" на панели инструментов, а затем Trigger Now (Активировать сейчас).
Мониторинг конвейера
Перейдите на вкладку Мониторинг слева. Вы увидите, что запуск конвейера появится в списке Pipeline Runs (Запуски конвейера).
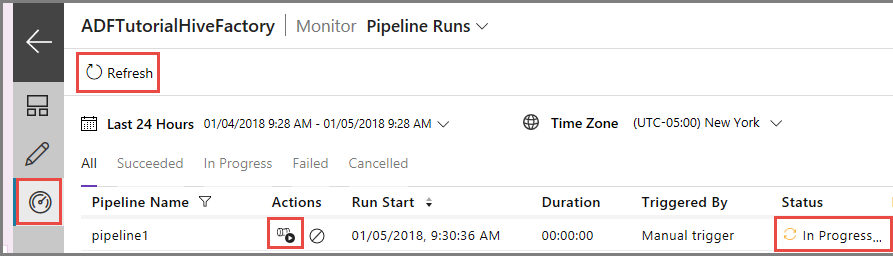
Щелкните Refresh (Обновить), чтобы обновить этот список.
Чтобы просмотреть запуски действий, связанные с этим запуском конвейера, щелкните View Activity Runs (Просмотр запусков действий) в столбце Действие. Другие ссылки в столбце действий позволяют остановить и заново запустить конвейер.
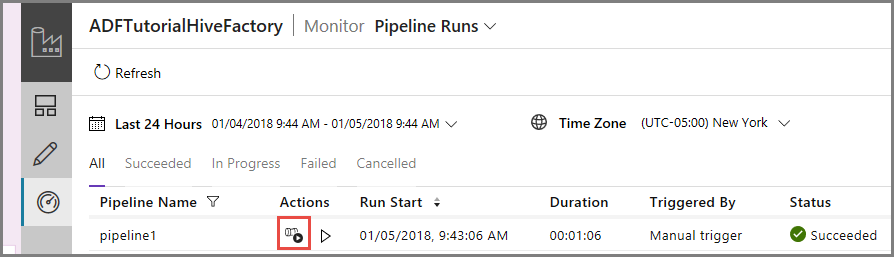
Здесь вы видите сведения об одном выполнении действия, поскольку в конвейере типа HDInsightHive определено только одно действие. Чтобы вернуться к представлению запусков конвейера, щелкните ссылку Pipelines (Конвейеры) в верхней части окна.
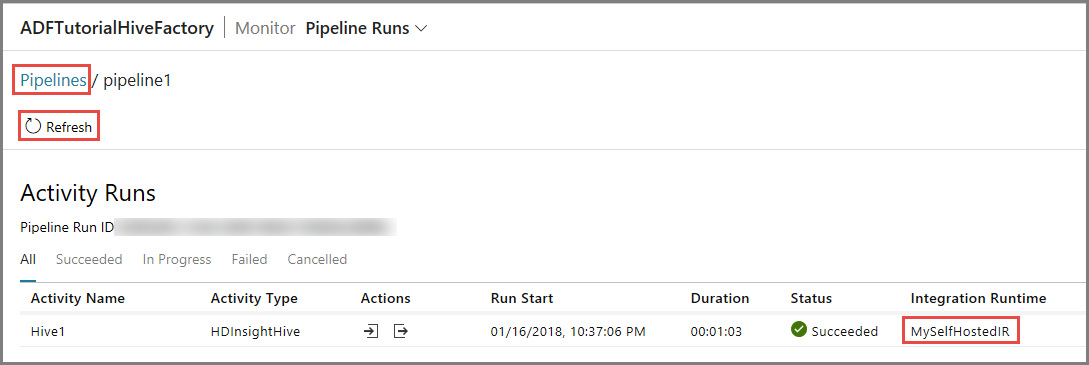
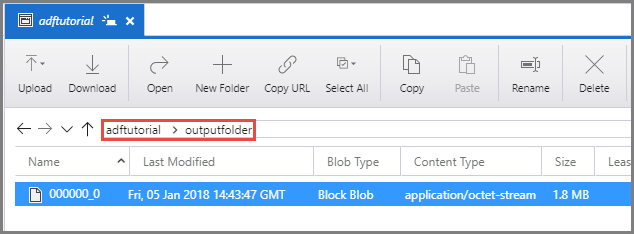
Убедитесь, что выходной файл появился в папке outputfolder конвейера adftutorial.
Связанный контент
В этом руководстве вы выполнили следующие шаги:
- Создали фабрику данных.
- Создание локальной среды выполнения интеграции
- Создание связанных службы хранилища Azure и службы Azure HDInsight.
- Создание конвейера с действием Hive.
- Активация выполнения конвейера.
- Мониторинг конвейера
- Проверка выходных данных
Перейдите к следующему руководству, чтобы узнать о преобразовании данных с помощью кластера Spark в Azure:
Branching and chaining activities in a Data Factory pipeline (Ветвление и создание цепного потока управления фабрики данных)