Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Простой и понятный план аварийного восстановления — критически важный компонент облачной платформы анализа данных, такой как Azure Databricks. Важно, чтобы ваши группы данных могли использовать платформу Azure Databricks даже в редких случаях сбоя поставщика облачных служб на уровне региональной службы, независимо от того, вызвана ли региональная катастрофа, например ураган или землетрясение, или другой источник.
Azure Databricks часто является основной частью общей экосистемы данных, которая включает множество служб, включая входящую обработку данных как для пакетной, так и для потоковой передачи, облачное хранилище, например ADLS (для рабочих областей, созданных до 6 марта 2023 г., хранилище BLOB-объектов Azure), последующие инструменты и службы, такие как приложения для бизнес-аналитики и средства оркестрации. В некоторых сценариях использования перебои в обслуживании на региональном уровне могут быть особенно чувствительны.
В этой статье описаны основные понятия и передовые методы для успешного межрегионального аварийного восстановления на платформе Databricks.
Гарантии высокой доступности внутри региона
В то время как остальная часть этого раздела посвящена реализации межрегионного аварийного восстановления, важно понимать, что azure Databricks обеспечивает высокий уровень доступности в одном регионе. Гарантии высокого уровня доступности в регионе охватывают следующие компоненты:
Доступность плоскости управления Databricks
Плоскость управления Databricks устойчива к зональным сбоям и должна автоматически восстанавливаться в течение 15 минут после зонального сбоя. Обычное зональное тестирование сбоев проверяет это.
Все службы уровня управления без отслеживания состояния могут обрабатывать потери отдельных виртуальных машин, а также всех виртуальных машин в всей зоне автоматически. Данные рабочей области хранятся в базах данных, реплицируемых между зонами в регионе. Учетные записи хранения, используемые для обслуживания образов среды выполнения Databricks, также избыточны в регионе, а все регионы имеют вторичные учетные записи хранения, используемые при отключении основного. Ознакомьтесь с регионами Azure Databricks.
Устойчивость к зональным сбоям поддерживается только при выходе из строя одной зоны и доступна только в регионах Azure, поддерживающих несколько зон.
Доступность плоскости вычислений
Доступность рабочей области зависит от доступности плоскости управления (как описано выше). Данные в корневом каталоге DBFS не затрагиваются, если учетная запись хранения для DBFS Root настроена с зонально-избыточным хранилищем (ZRS) или гео-зонально-избыточным хранилищем (GZRS) (по умолчанию — геоизбыточное хранилище (GRS)).
Узлы для кластеров извлекаются из разных зон доступности, запрашивая эти узлы у поставщика вычислений Azure, при условии наличия достаточной емкости в оставшихся зонах для выполнения запроса. Если узел потерян, диспетчер кластеров запрашивает узлы замены от поставщика вычислений Azure, который извлекает их из доступных AZ. Единственным исключением является потеря узла драйвера. В этом случае диспетчер кластеров перезапускает задание и кластер.
Обзор аварийного восстановления
Аварийное восстановление включает набор политик, инструментов и процедур, обеспечивающих восстановление или дальнейшую работу жизненно важной технологической инфраструктуры и систем после возникшего естественным образом или в результате действий человека сбоя. Масштабная облачная платформа, такая как Azure, обслуживает множество клиентов и обладает встроенными механизмами защиты от однократных сбоев. Например, регион — это группа зданий, подключенных к разным источникам питания, благодаря чему сбой в одном из них не приведет к отключению всего региона. Однако в облачном регионе могут возникать сбои, и масштабы перебоев и их влияние на организацию могут быть разными.
Прежде чем реализовать план аварийного восстановления, важно понять разницу между аварийным восстановлением (DR) и высокой доступностью (HA).
Высокий уровень доступности характеризует устойчивость системы. Высокая доступность обеспечивает минимальный уровень работоспособности, который обычно определяется с точки зрения постоянства бесперебойной работы или процента времени доступности. Высокий уровень доступности реализуется на месте (в том же регионе, что и основная система) в качестве элемента основной системы. Например, облачные службы, такие как Azure, имеют службы высокой доступности, такие как ADLS (для рабочих областей, созданных до 6 марта 2023 г., хранилище BLOB-объектов Azure). Высокий уровень доступности не требует от клиента Azure Databricks серьезных подготовительных действий.
И напротив, план аварийного восстановления требует принятия и внедрения решений, подходящих для конкретной организации на случай более масштабного регионального сбоя в работе критических систем. В этой статье рассматриваются широко используемые термины, связанные с аварийным восстановлением, распространенные решения и некоторые рекомендации по использованию планов аварийного восстановления на платформе Azure Databricks.
Терминология
Терминология регионов
В этой статье используются следующие определения регионов:
Основной регион: географический регион, в котором пользователи выполняют типичные ежедневные интерактивные и автоматизированные рабочие нагрузки аналитики данных.
Дополнительный регион. географический регион, в который ИТ-специалисты временно перемещают рабочие нагрузки аналитики данных во время простоя в основном регионе.
Геоизбыточное хранилище: Azure имеет геоизбыточное хранилище в разных регионах для сохраняемого хранилища с помощью асинхронного процесса репликации хранилища.
Внимание
Для процессов аварийного восстановления Databricks рекомендует не использовать геоизбыточное хранилище для дублирования данных между регионами, таких как ADLS (для рабочих областей, созданных до 6 марта 2023 г., хранилище BLOB-объектов Azure), которое Azure Databricks создает для каждой рабочей области в подписке Azure. В общем случае следует использовать Deep Clone для таблиц Delta и по возможности преобразовывать данные из других форматов в Delta, чтобы также использовать Deep Clone.
Терминология состояния развертывания
В этой статье используются приведенные ниже определения состояния развертывания.
Активное развертывание. Пользователи могут подключаться к активному развертыванию рабочей области Azure Databricks и запускать рабочие нагрузки. Задания периодически планируются с помощью планировщика Azure Databricks или других механизмов. Потоки данных также можно запускать в этой системе развертывания. В некоторых документах активное развертывание может называться горячим.
Пассивное развертывание: в пассивном развертывании процессы не выполняются. ИТ-команды могут настроить автоматизированные процедуры для развертывания кода, конфигурации и других объектов re:[Databricks] в пассивном развертывании. Развертывание становится активным только в том случае, если текущее активное развертывание отключено. В некоторых документах пассивное развертывание может называться холодным.
Внимание
Проект может также содержать несколько пассивных развертываний в разных регионах, позволяющих решать проблемы с региональными простоями.
Как правило, команда имеет только одно активное развертывание за раз, в том, что называется стратегией активного пассивного аварийного восстановления. Существует менее распространенная стратегия аварийного восстановления под названием активный — активный, в рамках которой одновременно есть два активных развертывания.
Терминология аварийного восстановления
Существует два важных широко распространенных термина, которые ваша команда должна хорошо понимать:
Целевая точка восстановления(RPO) — это максимальный целевой период, в течение которого данные (транзакции) в ИТ-службе могут теряться по причине серьезного происшествия. В развертывании Azure Databricks основные данные клиента не хранятся. Это хранится в отдельных системах, таких как ADLS или Azure Blob Storage (для рабочих областей, созданных до 6 марта 2023 г.), либо в других источниках данных, находящихся под вашим контролем. Некоторые объекты, например задания и записные книжки, частично или полностью хранятся на уровне управления Azure Databricks. Для Azure Databricks RPO определяется как максимальный целевой период, в течение которого объекты, такие как изменения заданий и записных книжек, могут быть потеряны. Кроме того, вы несете ответственность за определение RPO для данных ваших клиентов в ADLS (для рабочих областей, созданных до 6 марта 2023 г., в хранилище объектов BLOB Azure) или других источников данных под вашим контролем.
Целевое время восстановления(RTO) — это целевой период (и уровень обслуживания), в течение которого бизнес-процесс должен быть восстановлен после аварии.
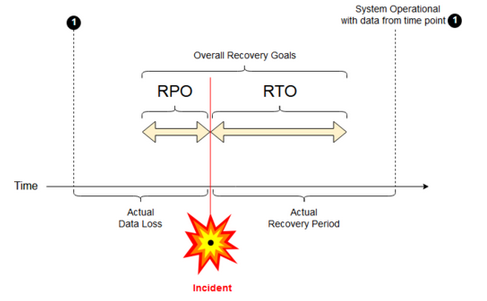
Аварийное восстановление и повреждение данных
Решение для аварийного восстановления не исключает риск повреждения данных. Поврежденные данные в основном регионе реплицируются из основного региона в дополнительный и повреждаются в обоих регионах. Для устранения таких проблем существуют другие методы, например дельта-путешествие во времени.
Типичный процесс восстановления
Сценарий аварийного восстановления Azure Databricks обычно выполняется следующим образом:
В критической службе, используемой в основном регионе, происходит сбой. Это может быть служба источника данных или сеть, влияющая на развертывание Azure Databricks.
Вы изучаете ситуацию вместе с поставщиком облачных услуг.
Если вы придете к выводу, что ваша компания не может ждать устранения проблемы в первичном регионе, вы можете решить переключиться на резервный регион.
Убедитесь, что та же проблема не затрагивает дополнительный регион.
Переключитесь на резервный регион.
- Остановите всю работу в рабочей области. Пользователи останавливают рабочие нагрузки. Пользователям или администраторам предлагается создать резервную копию последних изменений, если это возможно. Задания завершаются, если они еще не завершились из-за сбоя.
- Запустите процедуру восстановления во вторичном регионе. Процедура восстановления обновляет маршрутизацию и переименовывает подключения и сетевой трафик в дополнительный регион.
- После тестирования объявите вторичный регион работоспособным. Теперь выполнение рабочих нагрузок можно возобновить. Пользователи могут входить в теперь активное развертывание. Вы можете активировать запланированные или отложенные задания.
Для подробных инструкций в контексте Azure Databricks см. Тестирование отказоустойчивости.
В какой-то момент проблема в основном регионе устранена, и вы подтверждаете этот факт.
Выполните возврат к основному региону.
- Остановите все операции в дополнительном регионе.
- Запустите процедуру восстановления в основном регионе. Процедура восстановления изменит маршруты, имена подключений и параметры сетевого трафика для возврата в основной регион.
- При необходимости выполните репликацию данных обратно в основной регион. Чтобы снизить сложность этой процедуры, можно минимизировать объем данных, которые требуется реплицировать. Например, если при выполнении в дополнительном развертывании некоторые задания доступны только для чтения, то, возможно, вам не потребуется реплицировать эти данные обратно в основное развертывание в основном регионе. Однако у вас может быть одно рабочее задание, которое должно выполняться и может потребоваться репликация данных обратно в основной регион.
- Протестируйте развертывание в основном регионе.
- Объявите основной регион рабочим и что это ваша активная зона развертывания. Возобновите выполнение рабочих нагрузок.
Дополнительные сведения о восстановлении в основном регионе см. в разделе Тестовое восстановление (отказоустойчивость).
Внимание
При выполнении этих действий может произойти потеря части данных. Организация должна определить, потеря какого объема данных считается приемлемой и что можно сделать для устранения ее последствий.
Шаг 1. Понимание бизнес-потребностей
Ваш первый шаг — анализ и определение своих бизнес-потребностей. Определите, какие службы для работы с данными являются критически важными и каковы их ожидаемые RPO и RTO.
Исследуйте пределы устойчивости каждой системы в реальном мире. Помните, что аварийное восстановление, переключение на резервные ресурсы и восстановление работы могут быть дорогостоящими и нести другие риски. Другие риски могут включать повреждение данных, дублирование данных (если вы записываете в неправильное расположение хранилища), а также пользователи, которые войдут в систему и вносят изменения в неправильных местах.
Составьте схему всех точек интеграции Azure Databricks, влияющих на ваш бизнес:
- Должно ли ваше решение для аварийного восстановления поддерживать интерактивные процессы, автоматизированные процессы или и то, и другое?
- Какие службы работы с данными вы используете? Некоторые могут быть установлены на территории компании.
- Как входные данные попадают в облако?
- Кто потребляет эти данные? Какие нижестоящие процессы их используют?
- Необходимо ли учитывать сторонние интеграции, о которых следует знать в связи с изменениями в стратегиях аварийного восстановления?
Определите средства или стратегии распространения информации для своего плана аварийного восстановления:
- Какие средства вы будете использовать для оперативного изменения параметров сети?
- Можно ли заранее настроить конфигурацию и сделать ее модульной с целью более естественного и удобного развертывания решений для аварийного восстановления?
- Какие средства связи и каналы будут уведомлять внутренние команды и сторонних участников (интеграции, потребителей на следующем этапе) об изменениях в переключении и восстановлении аварийных систем? Как подтвердить их подтверждение?
- Какие средства или особые ресурсы поддержки потребуются?
- Какие службы, если таковые есть, будут отключены до полного восстановления?
Шаг 2. Выбор процесса, соответствующего бизнес-потребностям
Решение должно реплицировать правильные данные в плоскости управления, плоскости вычислений и источниках данных. Избыточные рабочие области для аварийного восстановления должны быть связаны с различными уровнями управления в разных регионах. Необходимо периодически синхронизировать эти данные с помощью решения на основе скриптов: средства синхронизации или рабочего процесса CI/CD. Не требуется синхронизировать данные из самой сети вычислительной плоскости, например с рабочих узлов Databricks Runtime.
Если вы используете функцию внедрения виртуальной сети (она доступна не во всех подписках и типах развертывания), то можете обеспечить согласованное развертывание этих сетей в обоих регионах с помощью инструментов на основе шаблонов, таких как Terraform.
Кроме того, нужно по мере необходимости организовать репликацию источников данных в разных регионах.
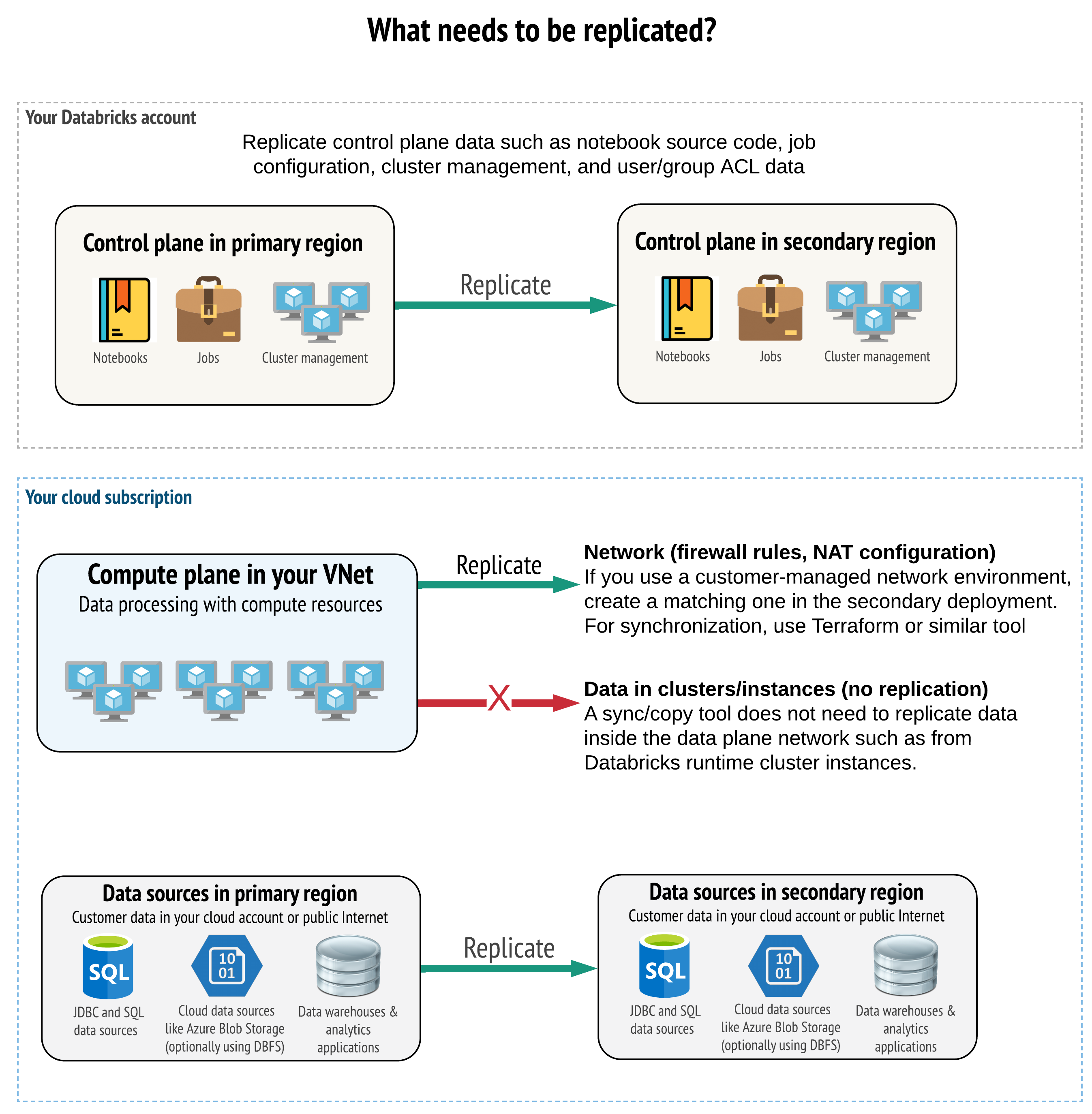
Общие рекомендации
Ниже приведены общие рекомендации для успешной разработки плана аварийного восстановления.
Узнайте, какие процессы критически важны для бизнеса и должны выполняться в аварийном восстановлении.
Четко определите, какие службы участвуют, какие данные обрабатываются, что такое поток данных и где он хранится.
Изолируйте службы и данные, насколько это возможно. Например, создайте отдельный контейнер облачного хранилища для данных аварийного восстановления или перенесите объекты Azure Databricks, которые потребуются при аварии, в отдельную рабочую область.
Вы несете ответственность за поддержание целостности между основными и резервными развертываниями для других объектов, которые не хранятся в Контрольной Плоскости Databricks.
Предупреждение
Одна из лучших практик состоит в том, чтобы не хранить данные в корневом каталоге ADLS (если рабочее пространство было создано до 6 марта 2023 года, используется хранилище BLOB-объектов Azure), которое используется для корневого доступа DBFS рабочей области. Корневое хранилище DBFS не поддерживается для рабочих данных клиента. Databricks также рекомендует не хранить библиотеки, файлы конфигурации или скрипты инициализации в этом расположении.
Для репликации и обеспечения избыточности источников данных, где это возможно, рекомендуется использовать собственные средства Azure, позволяющие реплицировать данные в регионы аварийного восстановления.
Выбор стратегии решения для восстановления
Типичные решения для аварийного восстановления включают две (или больше) рабочие области. Вы можете выбрать один из нескольких стратегий. Оцените возможную продолжительность перебоев в работе (несколько часов или даже сутки), объем усилий по обеспечению полной работоспособности рабочего пространства, а также усилия по восстановлению (фейлбек) в основной область.
Стратегия активного-пассивного решения
Решение "активный — пассивный" является наиболее распространенным и самым простым решением, и именно оно в первую очередь рассматривается в этой статье. Активно-пассивное решение синхронизирует изменения данных и объектов из активного развертывания в пассивное развертывание. При желании можно создать несколько пассивных развертываний в разных регионах, но в этой статье рассматривается подход, связанный с одним пассивным развертыванием. При возникновении случая аварийного восстановления пассивное развертывание во вторичном регионе станет активным развертыванием.
Существует два основных варианта этой стратегии:
- Унифицированное (корпоративное) решение: ровно один набор активных и пассивных развертываний, охватывающих всю организацию.
- Решения по отделам и проектам: в каждом отделе или проектной области используется свое решение для аварийного восстановления. В некоторых организациях возникает необходимость разделить детали аварийного восстановления между отделами и использовать разные основные и дополнительные регионы для каждой команды, основываясь на уникальных потребностях каждой команды.
Существуют и другие варианты, например, использование пассивного развертывания в сценариях с доступом только для чтения. Если у вас есть рабочие нагрузки, доступные только для чтения, например запросы пользователей, они могут работать в пассивном решении в любое время, если они не изменяют данные или объекты Azure Databricks, такие как записные книжки или задания.
Стратегия «активный-активный»
В решении "активный — активный" все процессы обработки данных в обоих регионах всегда выполняются параллельно. Специалисты по эксплуатации должны сделать так, чтобы процесс обработки данных, например задание, помечался как завершенный только после его успешного завершения в обоих регионах. Изменение объектов в рабочей среде невозможно, и должен соблюдаться строгий процесс продвижения CI/CD из среды разработки/промежуточной среды в рабочую среду.
Стратегия на базе решения типа "активный — активный" является наиболее сложной, и так как работы выполняются в обеих регионах, это связано с дополнительными финансовыми затратами.
Как и в случае со стратегией "активный — пассивный", ее можно реализовать как единое общекорпоративное решение или распределить по отделам.
В зависимости от вашего рабочего процесса, может не понадобиться эквивалентная рабочая область в дополнительной системе для всех рабочих областей. Например, возможно, в рабочей области для разработки или промежуточной среды нет необходимости в дубликате. При наличии правильно спроектированного конвейера разработки эти рабочие области при необходимости можно легко восстановить.
Выбор инструментов
Существует два основных подхода к выбору инструментов для максимальной синхронизации данных между рабочими областями в основном и дополнительном регионах:
- Клиент синхронизации, который копирует данные из основного региона в дополнительный: клиент синхронизации отправляет рабочие данные и ресурсы из основного региона в дополнительный. Как правило, это выполняется на запланированной основе.
- Инструменты CI/CD для параллельного развертывания: для рабочего кода и ресурсов используйте средства CI/CD, которые отправляют изменения в рабочие системы одновременно в оба региона. Например, при отправке кода и ресурсов из промежуточной среды/среды разработки в рабочую среду система CI/CD делает их доступными в обоих регионах одновременно. Основная идея состоит в том, чтобы рассматривать все артефакты в рабочей области Azure Databricks как инфраструктуру как код. Большинство артефактов можно одновременно развертывать как в основной, так и в дополнительной рабочей области, однако некоторые артефакты может потребоваться развернуть только после события аварийного восстановления. Описание инструментов и средств см. в разделе Скрипты автоматизации, примеры и прототипы.
На схеме ниже представлены различия этих двух подходов.
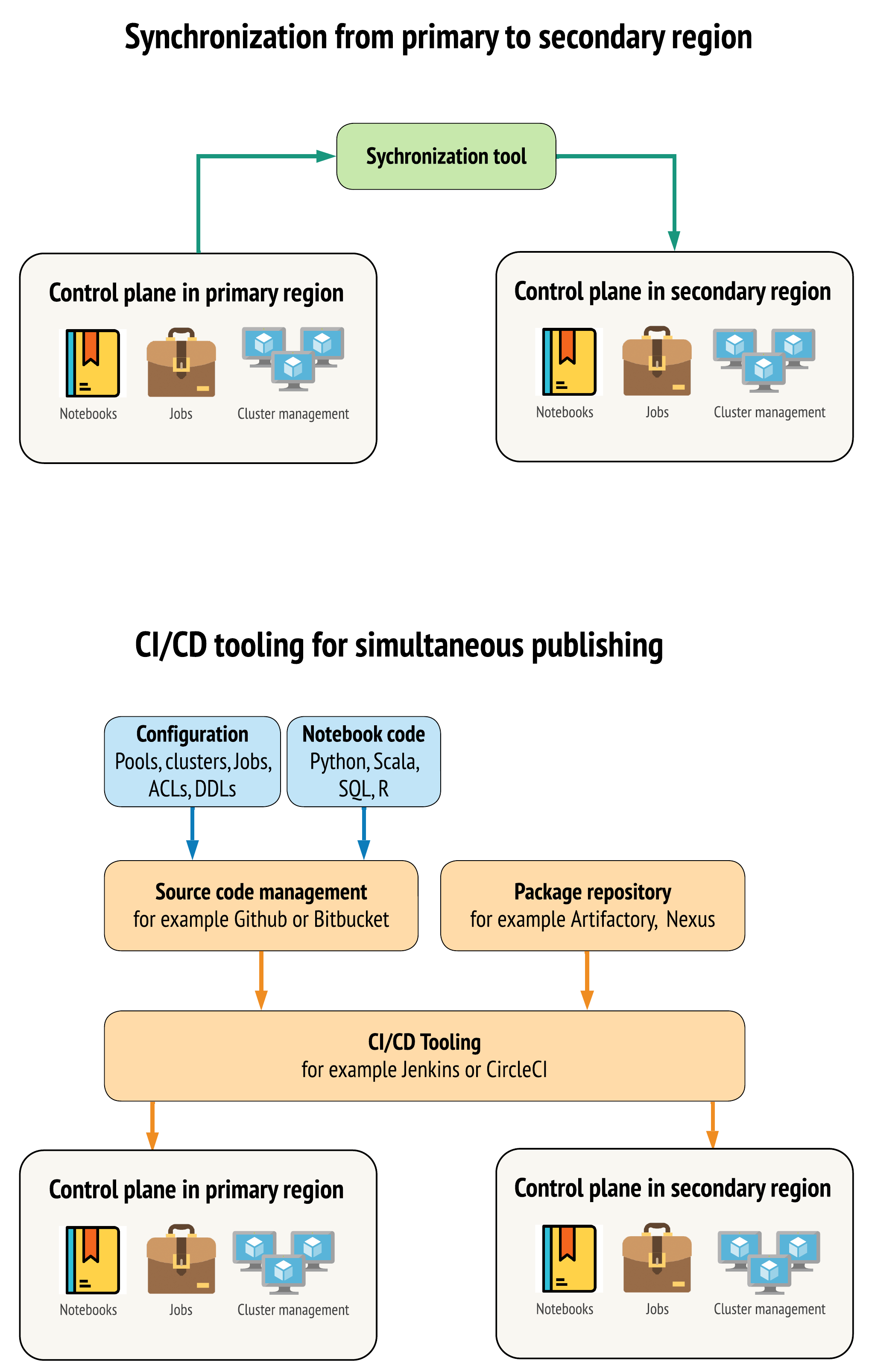
В зависимости от конкретных потребностей подходы можно сочетать. Например, используйте CI/CD для исходного кода записной книжки, но используйте синхронизацию для конфигурации, таких как пулы и элементы управления доступом.
В таблице ниже объясняется, как работать с данными разных типов с использованием каждого из инструментов.
| Описание | Как работать с инструментами CI/CD | Как работать со средством синхронизации |
|---|---|---|
| Исходный код: экспортированный исходный код записных книжек и исходный код упакованных библиотек | Проведите совместное развертывание в основном и дополнительном развертываниях. | Синхронизируйте исходный код с основного на вторичный. |
| Пользователи и группы | Управляйте метаданными как конфигурацией в Git. В качестве альтернативы для обеих рабочих областей можно использовать одного поставщика удостоверений (IdP). Совместно разверните данные пользователей и групп на основных и дополнительных платформах. | Используйте SCIM или другие средства автоматизации для обоих регионов. Создавать вручную не рекомендуется, но если необходимо, это должно быть сделано одновременно для обоих. При использовании ручной настройки создайте запланированный автоматизированный процесс для сравнения списка пользователей и групп между двумя развертываниями. |
| Конфигурации пула | Можно использовать шаблоны в Git. Проведите совместное развертывание в основном и дополнительном развертываниях. При этом значение min_idle_instances на вторичном должно быть равно нулю до события аварийного восстановления. |
Пулы, созданные с любым min_idle_instances, синхронизированные с вторичной рабочей областью через API или CLI. |
| Job configurations (Конфигурация заданий) | Можно использовать шаблоны в Git. Для основного развертывания разверните определение задания в исходном виде. Для дополнительного развертывания установите для задания нулевую степень параллелизма. Это отключает выполнение задания в этом развертывании и предотвращает дополнительные запуски. Измените значение конкуренции после того, как дополнительное развертывание станет активным. | Если задания по какой-либо причине выполняются в существующих кластерах <interactive>, клиент синхронизации должен сопоставить с соответствующим cluster_id во вторичной рабочей области. |
| Списки управления доступом (ACL) | Можно использовать шаблоны в Git. Проведите совместное развертывание записных книжек, папок и кластеров в основном и дополнительном развертываниях. Удерживайте данные заданий до события восстановления после аварии. | API разрешений может задать элементы управления доступом для кластеров, заданий, пулов, записных книжек и папок. Клиент синхронизации должен сопоставить идентификаторы объектов для каждого объекта во вторичной рабочей области. Databricks рекомендует создать карту идентификаторов объектов из основной в дополнительную рабочую область и синхронизировать эти объекты перед репликацией управления доступом. |
| Библиотеки | Включите их в исходный код и шаблоны кластеров и заданий. | Синхронизируйте пользовательские библиотеки из централизованных репозиториев, DBFS или облачного хранилища (его можно подключить). |
| Скрипты инициализации кластера | Включите в исходный код, если вы предпочитаете. | Чтобы упростить синхронизацию, по возможности храните скрипты инициализации в основной рабочей области в общей папке или в небольшом количестве папок. |
| Точки подключения | Включите их в исходный код, если для создания использовались только задания на основе записных книжек или Command API. | Используйте задания, которые могут выполняться как действия Фабрики данных Azure (ADF). Обратите внимание, что конечные точки хранилища могут меняться, так как рабочие области будут находиться в разных регионах. Свою роль также играет стратегия аварийного восстановления данных. |
| Метаданные таблицы | Включите их в исходный код, если для создания использовались только задания на основе записных книжек или Command API. Это относится как к внутреннему хранилищу метаданных Azure Databricks, так и к настроенному внешнему хранилищу метаданных. | Сравните определения метаданных между хранилищами с использованием Spark Catalog API или метода "Отображение создания таблицы" с помощью записной книжки или скриптов. Обратите внимание, что таблицы базового хранилища могут быть связаны с различными регионами и быть разными в разных экземплярах хранилища метаданных. |
| Секреты | Включите их в исходный код, если для создания использовался только Command API. Обратите внимание, что содержание некоторых секретов может потребовать изменений между основной и второстепенной частью. | Секреты создаются в обеих рабочих областях через API. Обратите внимание, что содержание некоторых секретов может потребовать изменений между основной и второстепенной частью. |
| Конфигурации кластера | Можно использовать шаблоны в Git. Выполните совместное развертывание в основных и вторичных развертываниях, однако развертывания во вторичных развертываниях следует завершить до события аварийного восстановления. | Кластеры создаются после их синхронизации с дополнительной рабочей областью с помощью API или интерфейса командной строки. При необходимости их можно завершить явным образом в зависимости от настроек автоматического завершения. |
| Разрешения для записных книжек, заданий и папок | Можно использовать шаблоны в Git. Проведите одновременное развертывание в основном и дополнительном развертываниях. | Создайте копию с помощью API разрешений. |
Выберите регионы и несколько второстепенных рабочих областей.
Вам потребуется полный контроль над триггером события аварийного восстановления. Вы можете активировать его в любой момент и по любой причине. Вы должны взять на себя ответственность за стабилизацию процесса аварийного восстановления перед тем, как вернуться к нормальной работе. Как правило, это означает, что необходимо создать несколько рабочих областей Azure Databricks для удовлетворения производственных и аварийного восстановления потребностей, а также выбрать вторичный регион резервного копирования.
В Azure проверьте репликацию данных, а также доступность различных продуктов и типов виртуальных машин.
Шаг 3. Подготовка рабочих пространств и одноразовое копирование
Если рабочая область уже находится в рабочем режиме, для синхронизации пассивного развертывания с активным обычно выполняется однократная операция копирования. В рамках этой однократной операции копирования выполняются следующие действия:
- Репликация данных: Репликация с помощью облачного решения репликации или операции глубокого клонирования Delta.
- Создание токенов: используйте функцию создания токенов, чтобы автоматизировать репликацию и будущие рабочие нагрузки.
- Репликация рабочей области: выполняйте репликацию рабочей области с использованием методов, описанных на шаге 4 "Подготовка источников данных".
- Проверка рабочей области: проведите тестирование, чтобы убедиться, что рабочая область и процесс могут успешно выполняются и обеспечивают ожидаемые результаты.
Последующие действия копирования и синхронизации выполняются быстрее после первоначальной однократной операции копирования. Все логи из ваших инструментов также фиксируют, что и когда изменилось.
Шаг 4. Подготовка источников данных
Azure Databricks может обрабатывать самые разные источники данных с помощью технологий пакетной обработки и потоков данных.
Пакетная обработка из источников данных
При обработке данных в пакетах обычно он находится в источнике данных, который можно легко реплицировать или доставлять в другой регион.
Например, данные могут быть регулярно передаваться в облачное хранилище. В режиме аварийного восстановления для дополнительного региона необходимо проследить за тем, что файлы отправлялись в хранилище дополнительного региона. Рабочие нагрузки должны считывать данные из хранилища вторичного региона и записывать данные в хранилище вторичного региона.
Потоки данных
Обработка потока данных является более сложной задачей. Потоковые данные могут поступать из различных источников, обрабатываться и отправляться в решение для потоковой передачи.
- Очередь сообщений, например Kafka
- Поток отслеживания изменений данных базы данных
- Файловая непрерывная обработка
- Файловая обработка по расписанию, также известная как однократный триггер
Во всех этих случаях необходимо настроить источники данных для работы в режиме аварийного восстановления и использовать дополнительное развертывание в дополнительном регионе.
Модуль записи потока хранит контрольную точку со сведениями об обработанных данных. Эта контрольная точка может содержать расположение данных (обычно это облачное хранилище), которое требуется изменить, чтобы обеспечить успешный перезапуск потока. Например, подпапка source в папке контрольной точки может содержать файловую облачную папку.
Эта контрольная точка должна своевременно реплицироваться. Рассмотрите возможность синхронизации интервала контрольных точек с новым решением для облачной репликации.
Обновление контрольной точки является функцией модуля записи и, следовательно, относится к приему потока данных или обработке и хранению в другом источнике потоковой передачи.
Для рабочих нагрузок потоковой передачи контрольные точки должны быть настроены в хранилище, управляемом клиентом, чтобы их можно было реплицировать в дополнительный регион для возобновления рабочей нагрузки с момента последнего сбоя. Вы также можете запустить дополнительный потоковый процесс параллельно с основным.
Шаг 5. Реализация и тестирование решения
Периодически тестируйте свою конфигурацию аварийного восстановления, чтобы убедиться, что она работает правильно. Нет смысла поддерживать решение для аварийного восстановления, если его нельзя использовать в нужный момент. Некоторые компании переключаются между регионами каждые несколько месяцев. Переключение регионов по регулярному графику позволяет проверить обоснованность предположений и работоспособность процессов, а также их соответствие потребностям в плане восстановления. Это также гарантирует, что сотрудники организации будут знакомы с политиками и процедурами для экстренных ситуаций.
Внимание
Регулярно тестируйте свое решение для аварийного восстановления в реальных условиях.
Если вы обнаружите, что отсутствует объект или шаблон и по-прежнему должны полагаться на информацию, хранящуюся в основной рабочей области, изменить план, чтобы удалить эти препятствия, реплицировать эти сведения в вторичной системе или сделать его доступным другим способом.
Проверьте все необходимые изменения организации в процессах и конфигурации в целом. План аварийного восстановления влияет на конвейер развертывания, и ваша команда должна знать, что именно необходимо синхронизировать. После настройки рабочих областей аварийного восстановления необходимо убедиться, что вся инфраструктура (обслуживаемая вручную и программно), задания, записные книжки, библиотеки и другие объекты рабочей области доступны в дополнительном регионе.
Обсудите со своей командой, как расширить стандартные рабочие процессы и конвейеры конфигурации для развертывания изменений во всех рабочих областях. Управляйте идентичностями пользователей во всех рабочих пространствах. Не забудьте настроить для новых рабочих областей такие средства, как автоматизация заданий и мониторинг.
Спланируйте и протестируйте изменения в средствах настройки.
- Прием данных: узнайте, где находятся источники данных и откуда они получают данные. По возможности параметризуйте источник и подготовьте отдельный шаблон конфигурации для работы с дополнительными развертываниями и дополнительными регионами. Подготовьте план для переключения на резерв и проверьте все допущения.
- Изменения в выполнении: если у вас есть планировщик для активации заданий или других действий, может потребоваться настроить отдельный планировщик, который работает с дополнительным развертыванием или его источниками данных. Подготовьте план для переключения на резерв и проверьте все допущения.
- Интерактивное подключение: подумайте, как на конфигурацию, проверку подлинности и сетевые подключения могут повлиять региональные сбои с точки зрения использования REST API, средств CLI и других служб, таких как JDBC/ODBC. Подготовьте план для переключения на резерв и проверьте все допущения.
- Изменения в автоматизации: для всех инструментов автоматизации подготовьте план на случай отказа и проверьте все предположения.
- Выходные данные: для всех инструментов и программ, создающих выходные данные или журналы, подготовьте план для переключения на резервный ресурс и проверьте все предположения.
Тестируйте отработку отказа
Аварийное восстановление может инициироваться в различных сценариях. Оно может быть вызвано непредвиденным сбоем. Некоторые ключевые функции могут отключиться, включая облачную сеть, облачное хранилище и другие основные сервисы. У вас может не быть возможности корректно завершить работу системы, и возникает необходимость провести восстановление. Однако этот процесс может инициироваться завершением работы или запланированным отключением либо даже периодическим переключением активных развертываний между двумя регионами.
При тестировании отработки отказа подключитесь к системе и запустите процесс завершения работы. Убедитесь, что все задания выполнены, а кластеры остановлены.
Клиент синхронизации (или средства CI/CD) могут реплицировать соответствующие объекты и ресурсы Azure Databricks в дополнительную рабочую область. Чтобы активировать дополнительную рабочую область, в процесс можно включить некоторые или все из следующих компонентов:
- Запустите проверки, чтобы убедиться, что платформа обновлена.
- Отключите пулы и кластеры в основном регионе, чтобы, если восстановится работа службы после сбоя, основной регион не начал обработку новых данных.
- Процесс восстановления:
- Проверьте дату последней синхронизации данных. См. [терминология](# dr-terminology). Сведения об этом шаге зависят от способа синхронизации данных и уникальных бизнес-потребностей.
- Стабилизируйте свои источники данных и обеспечьте их доступность. Включите все внешние источники данных, такие как Azure Cloud SQL, и Delta Lake, Parquet или другие файлы.
- Найдите точку восстановления потокового вещания. Настройте процесс, чтобы перезапустить его и подготовить процесс для выявления и устранения потенциальных дубликатов (Delta Lake упрощает этот процесс).
- Завершите процесс потока данных и проинформируйте своих пользователей.
- Запустите соответствующие пулы (или увеличьте
min_idle_instancesдо соответствующей цифры). - Запустите соответствующие кластеры (если они не завершены).
- Измените режим параллельного выполнения заданий и запустите необходимые задания. Это могут быть однократные или периодические запуски.
- Для внешних средств, использующих URL-адрес или доменное имя рабочей области Azure Databricks, обновите конфигурации с учетом нового уровня управления. Например, обновите URL-адреса для REST API и подключений JDBC/ODBC. URL-адрес веб-приложения Azure Databricks для клиента изменяется при изменении уровня управления, поэтому уведомляйте пользователей вашей организации о новом URL-адресе.
Тестирование восстановления (откат)
Процесс отмены аварийного переключения легче контролировать и его можно выполнять в течение окна обслуживания. Этот план может включать некоторые или все из следующих элементов:
- Получите подтверждение, что основной регион восстановлен.
- Отключите пулы и кластеры в дополнительном регионе, чтобы он не начал обработку новых данных.
- Синхронизируйте новые или измененные ресурсы в дополнительной рабочей области обратно в основное развертывание. В зависимости от структуры скриптов отработки отказа одни и те же скрипты можно выполнять для синхронизации объектов из дополнительного региона (региона аварийного восстановления) с основным (рабочим) регионом.
- Синхронизируйте новые изменения данных с основным развертыванием. Чтобы гарантировать отсутствие потери данных, можно использовать аудиторские следы журналов и Delta таблиц.
- Остановите все рабочие нагрузки в регионе аварийного восстановления.
- Измените URL-адреса заданий и пользователей на основной регион.
- Запустите проверки, чтобы убедиться, что платформа обновлена.
- Запустите соответствующие пулы (или увеличьте
min_idle_instancesдо соответствующей цифры). - Запустите соответствующие кластеры (если они не завершены).
- Измените параллельные запуски заданий и выполняйте соответствующие задания. Это могут быть однократные или периодические запуски.
- При необходимости настройте дополнительный регион для последующего аварийного восстановления.
Скрипты автоматизации, примеры и прототипы
Скрипты автоматизации, которые можно использовать в проектах аварийного восстановления:
- Databricks рекомендует использовать Databricks Terraform Provider для помощи в разработке вашего собственного процесса синхронизации.
- Примеры и прототипы скриптов также см. в разделе Средства миграции рабочей области Databricks. Помимо объектов Azure Databricks, реплицируйте все соответствующие конвейеры Фабрики данных Azure, чтобы они ссылались на связанную службу, сопоставленную с дополнительной рабочей областью.
- Проект Databricks Sync (DBSync) — это средство синхронизации объектов, которое выполняет резервное копирование, восстановление и синхронизацию рабочих областей Databricks.