Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Точное управление доступом позволяет ограничить доступ к определенным данным с помощью представлений, фильтров строк и маск столбцов. На этой странице объясняется, как бессерверные вычисления используются для обеспечения точного контроля доступа на выделенных вычислительных ресурсах.
Замечание
Выделенные вычислительные ресурсы — это универсальные вычислительные системы или системы для задач, настроенные с выделенным режимом доступа (ранее режим доступа с одним пользователем). Смотрите режимы доступа.
Требования
Чтобы использовать выделенные вычисления для запроса представления или таблицы с детализированными элементами управления доступом:
- Выделенный вычислительный ресурс должен находиться в Databricks Runtime 15.4 LTS или более поздней версии.
- Рабочая область должна быть включена для бессерверных вычислений.
Если выделенный вычислительный ресурс и рабочая область соответствуют этим требованиям, фильтрация данных выполняется автоматически.
Как работает фильтрация данных на выделенных вычислительных ресурсах
Каждый раз, когда запрос обращается к объекту базы данных с точными элементами управления доступом, выделенный вычислительный ресурс передает запрос бессерверным вычислительным ресурсам рабочей области для выполнения фильтрации данных. Затем отфильтрованные данные передаются между бессерверными и выделенными вычислительными ресурсами с помощью временных файлов во внутреннем облачном хранилище рабочей области.
Azure Databricks передает отфильтрованные данные с помощью Cloud Fetch, функции, позволяющей записывать временные результирующие наборы во внутреннее хранилище рабочих областей (корневое хранилище DBFS рабочей области). Azure Databricks автоматически выполняет операцию очистки для этих файлов, помечая их на удаление через 24 часа и окончательно удаляя их через еще 24 часа.
Эта функция применяется к следующим объектам базы данных:
- динамические представления
- Таблицы с фильтрами строк или масками столбцов
-
Представления, созданные на основе таблиц, на которые у пользователя нет
SELECTправ - материализованные представления
- Потоковые таблицы
На следующей схеме у пользователя есть привилегии на SELECT, table_1, view_2 и table_w_rls, на которые применены фильтры строк. У пользователя нет привилегий SELECT для table_2, на который есть ссылка в view_2.

Запрос на table_1 полностью обрабатывается выделенным вычислительным ресурсом, так как фильтрация не требуется. Запросы view_2 и table_w_rls требуют фильтрации данных для возврата данных, к которым у пользователя есть доступ. Эти запросы обрабатываются функцией фильтрации данных на бессерверных вычислениях.
Поддержка операций записи
В Databricks Runtime 16.3 и более поздних версиях можно делать запись в таблицы, имеющие фильтры строк или маски столбцов, используя следующие опции:
-
MERGE INTO Команда SQL, которую можно использовать для достижения
INSERT,UPDATE, иDELETEфункциональности. - Операция слияния Delta.
- API
DataFrame.write.mode("append").
Для достижения функциональности INSERT, UPDATE и DELETE можно использовать промежуточную таблицу и предложения MERGE INTO инструкции с условиями WHEN MATCHED и WHEN NOT MATCHED.
Ниже приведен пример использования UPDATE с помощью MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
Ниже приведен пример использования INSERT с помощью MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
Ниже приведен пример удаления с помощью MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Поддержка DDL, SHOW, DESCRIBE и других команд
В Databricks Runtime 17.1 и более поздних версиях можно использовать следующие команды в сочетании с детально контролируемыми доступом объектами для выделенных вычислений:
- Инструкции DDL
- Инструкции SHOW
- Инструкции DESCRIBE
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 и выше)
При необходимости эти команды автоматически выполняются на бессерверных вычислениях.
Некоторые команды не поддерживаются, включая VACCUM, RESTOREи REORG TABLE.
Затраты на бессерверные вычисления
Клиентам взимается плата за бессерверные вычислительные ресурсы, выполняющие операции фильтрации данных. Сведения о ценах см. в разделе "Уровни платформы" и "Надстройки".
Пользователи с доступом могут запросить таблицу system.billing.usage, чтобы узнать, сколько с них было списано. Например, следующий запрос разбивает затраты на вычисления по пользователям:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Просмотр производительности запросов при использовании фильтрации данных
Пользовательский интерфейс Spark для выделенных вычислений отображает метрики, которые можно использовать для понимания производительности запросов. Для каждого запроса, выполняемого на вычислительном ресурсе, вкладка SQL/Dataframe отображает представление графа запросов. Если запрос был вовлечен в фильтрацию данных, пользовательский интерфейс отображает узел оператора RemoteSparkConnectScan в нижней части графа. На этом узле отображаются метрики, которые можно использовать для изучения производительности запросов. Просмотрите информацию о вычислительных процессах в интерфейсе Spark.
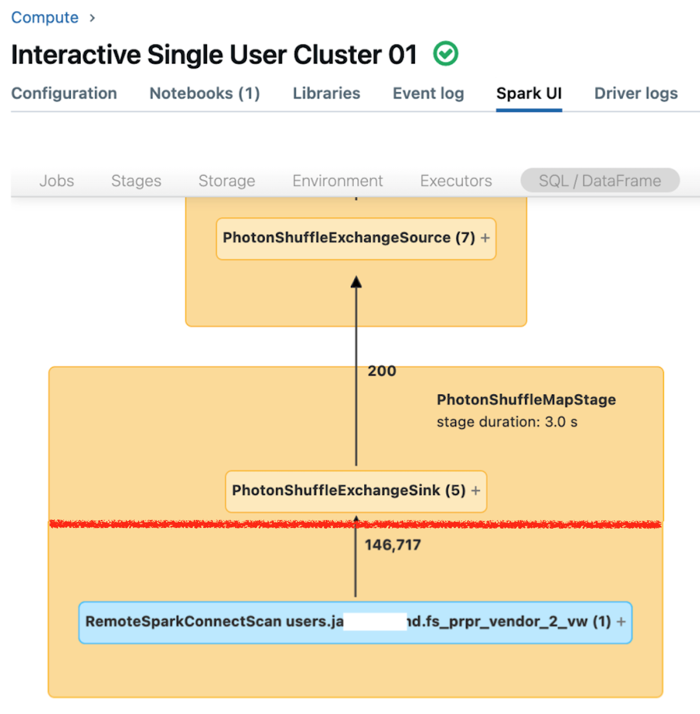
Разверните узел оператора RemoteSparkConnectScan, чтобы просмотреть метрики, которые касаются следующих вопросов:
- Сколько времени занимает фильтрация данных? Просмотрите "общее время удаленного выполнения".
- Сколько строк осталось после фильтрации данных? Просмотр результата по строкам
- Сколько данных (в байтах) было возвращено после фильтрации данных? Просмотрите "размер строк выходных данных".
- Сколько файлов данных было исключено благодаря секционированию и которые не нужно было считывать из хранилища? Просмотрите "Файлы, отрезаемые" и "Размер файлов, отрезаемых".
- Сколько файлов данных не удалось сократить и пришлось считывать из хранилища? Просмотрите "Считанные файлы" и "Размер считанных файлов".
- Из файлов, которые должны были быть прочитаны, сколько уже было в кэше? Просмотрите "Размер попаданий в кэш" и "Размер пропусков кэша".
Ограничения
В таблицах потоковой передачи поддерживаются только пакетные операции чтения. Таблицы с фильтрами строк или масками столбцов не поддерживают рабочие нагрузки потоковой передачи на выделенных вычислительных ресурсах.
Каталог по умолчанию (
spark.sql.catalog.spark_catalog) нельзя изменить.Функция
spark.catalog.listColumns()не поддерживается. Вместо этого можно использоватьSHOW COLUMNS INдля перечисления имен столбцов,SHOW PARTITIONSдля перечисления столбцов секций илиDESCRIBE TABLE [EXTENDED [AS JSON]]получения подробного описания таблицы.В Databricks Runtime 16.2 и ниже нет поддержки операций записи или обновления таблиц в таблицах с примененными фильтрами строк или масками столбцов.
В частности, операции DML, такие как
INSERT,DELETE,UPDATE,REFRESH TABLEиMERGE, не поддерживаются. Из этих таблиц можно читать только (SELECT).В Databricks Runtime 16.3 и более поздних версиях операции записи таблиц, такие как
INSERT,DELETEиUPDATEне поддерживаются, но могут быть выполнены с помощьюMERGE, которая поддерживается.При использовании
DeltaTable.forName()илиDeltaTable.forPath()на выделенной вычислительной мощности с таблицами с поддержкой FGAC поддерживаются только операцииmerge()иtoDF(). Для других операций DeltaTable используйте соответствующие команды SQL. Например, вместоhistory()используйтеDESCRIBE HISTORY, а вместоclone()используйтеSHALLOW CLONEилиDEEP CLONE.В Databricks Runtime 16.2 и ниже самосоединения блокируются по умолчанию при применении фильтрации данных, так как эти запросы могут возвращать различные моментальные снимки одной и той же удаленной таблицы. Однако эти запросы можно включить, задав
spark.databricks.remoteFiltering.blockSelfJoinsfalseдля вычислений, в которых выполняются эти команды.В Databricks Runtime 16.3 и более поздних версиях моментальные снимки автоматически синхронизируются между выделенными и бессерверными ресурсами вычислений. Из-за этой синхронизации запросы самосоединения, использующие функционал фильтрации данных, возвращают одинаковые моментальные снимки и включены по умолчанию. Исключения составляют материализованные представления и любые представления, материализованные представления и стриминговые таблицы, использующие Delta Sharing. Для этих объектов самосоединения блокируются по умолчанию, но эти запросы можно включить, установив
spark.databricks.remoteFiltering.blockSelfJoinsв false на вычислительных устройствах, на которых выполняются эти команды.Если вы включаете запросы самосоединения для материализованных представлений, любых представлений и потоковых таблиц, необходимо убедиться в отсутствии одновременных записей в присоединяемые объекты.
- Нет поддержки для образов Docker.
- Поддержка при использовании Databricks Container Services отсутствует.
- Необходимо открыть порты 8443 и 8444, чтобы обеспечить точное управление доступом на выделенных вычислительных ресурсах. См. статью Развертывание Azure Databricks в виртуальной сети Azure (внедрение виртуальной сети).