Подключение к Облачному хранилищу Google
В этой статье описывается, как настроить подключение из Azure Databricks для чтения и записи таблиц и данных, хранящихся в облачном хранилище Google (GCS).
Для чтения или записи из контейнера GCS необходимо создать присоединенную учетную запись службы и связать ее с учетной записью службы. Вы подключаетесь к контейнеру непосредственно с ключом, создаваемым для учетной записи службы.
Доступ к контейнеру GCS напрямую с помощью ключа учетной записи облачной службы Google
Для чтения и записи непосредственно в контейнер необходимо настроить ключ, определенный в конфигурации Spark.
Шаг 1. Настройка учетной записи облачной службы Google с помощью Google Cloud Console
Необходимо создать учетную запись службы для кластера Azure Databricks. Databricks рекомендует предоставить этой учетной записи службы наименьшие привилегии, необходимые для выполнения задач.
Щелкните IAM и Admin в области навигации слева.
Щелкните "Учетные записи службы".
Нажмите кнопку " + СОЗДАТЬ УЧЕТНУЮ ЗАПИСЬ СЛУЖБЫ".
Введите имя и описание учетной записи службы.
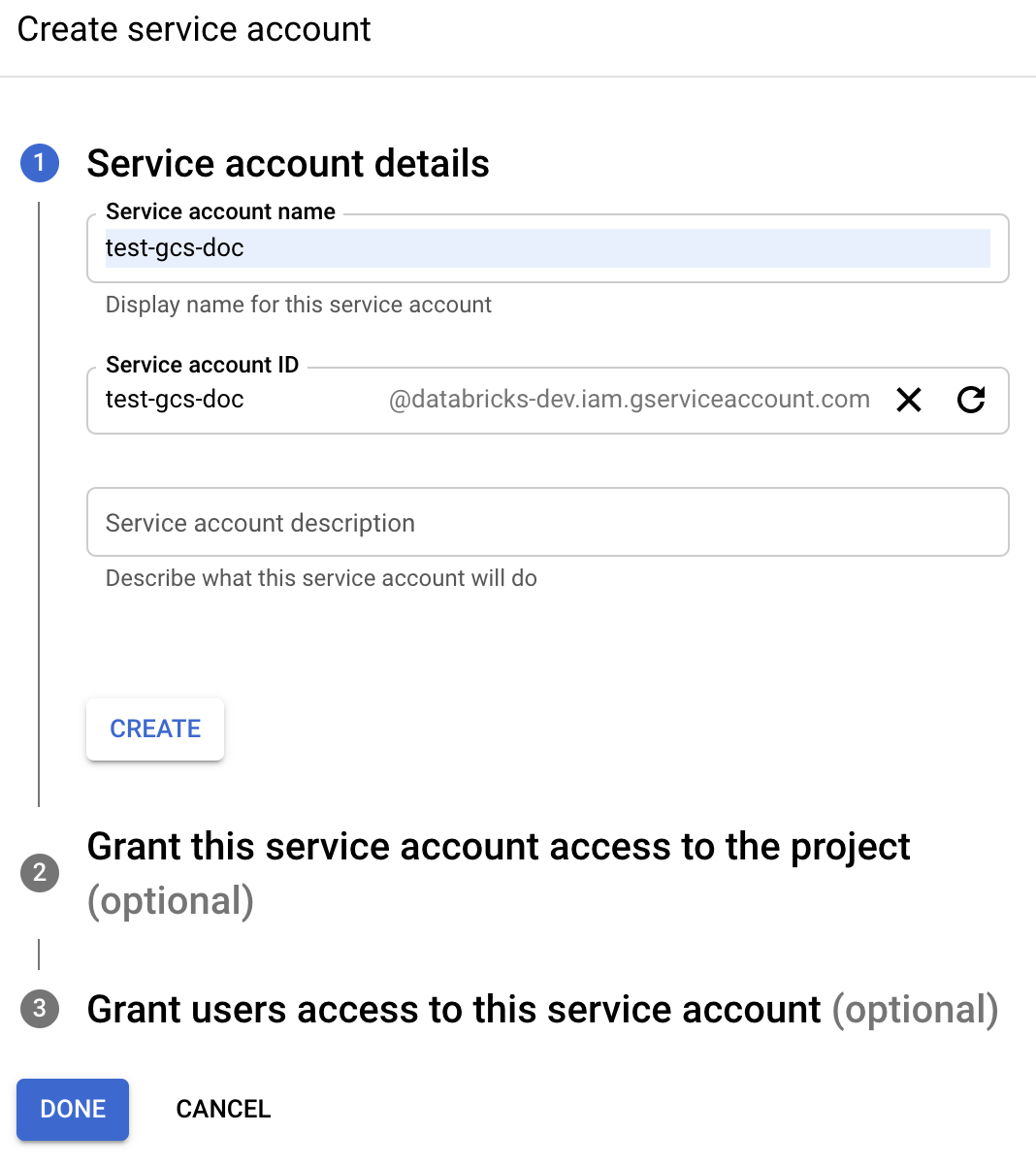
Нажмите Создать.
Щелкните CONTINUE (Продолжить).
Нажмите кнопку "ГОТОВО".
Шаг 2. Создание ключа для доступа к контейнеру GCS напрямую
Предупреждение
Ключ JSON, создаваемый для учетной записи службы, является закрытым ключом, который должен предоставляться только авторизованным пользователям, так как он управляет доступом к наборам данных и ресурсам в учетной записи Google Cloud.
- В консоли Google Cloud в списке учетных записей служб щелкните только что созданную учетную запись.
- В разделе "Ключи" нажмите кнопку ADD KEY Create new key(Добавить ключ>).
- Примите тип ключа JSON .
- Нажмите Создать. Файл ключа скачан на компьютер.
Шаг 3. Настройка контейнера GCS
Создание контейнера
Если у вас еще нет контейнера, создайте его:
Щелкните хранилище в левой области навигации.
Нажмите кнопку CREATE BUCKET.
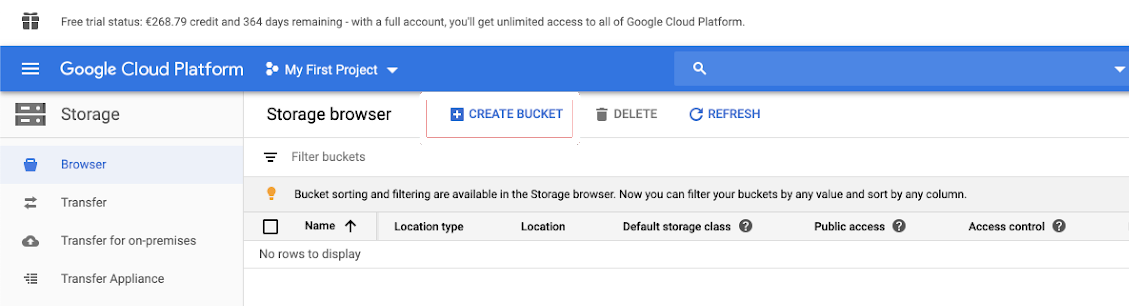
Нажмите Создать.
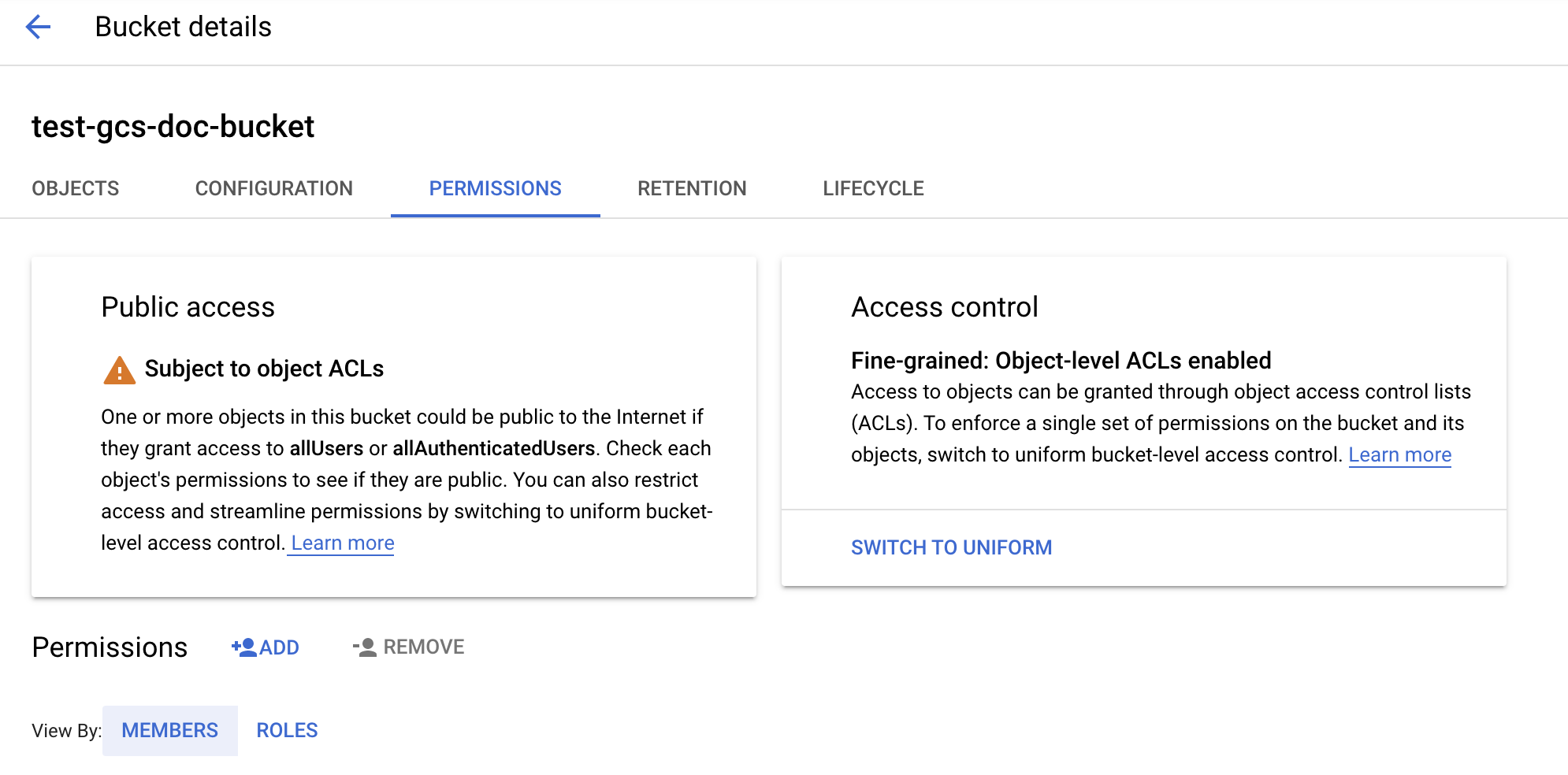
Настройка контейнера
Настройте сведения о контейнере.
Выберите вкладку Разрешения .
Рядом с меткой "Разрешения" нажмите кнопку "ДОБАВИТЬ".
Предоставьте администратору хранилища разрешение учетной записи службы в контейнере из ролей облачного хранилища.
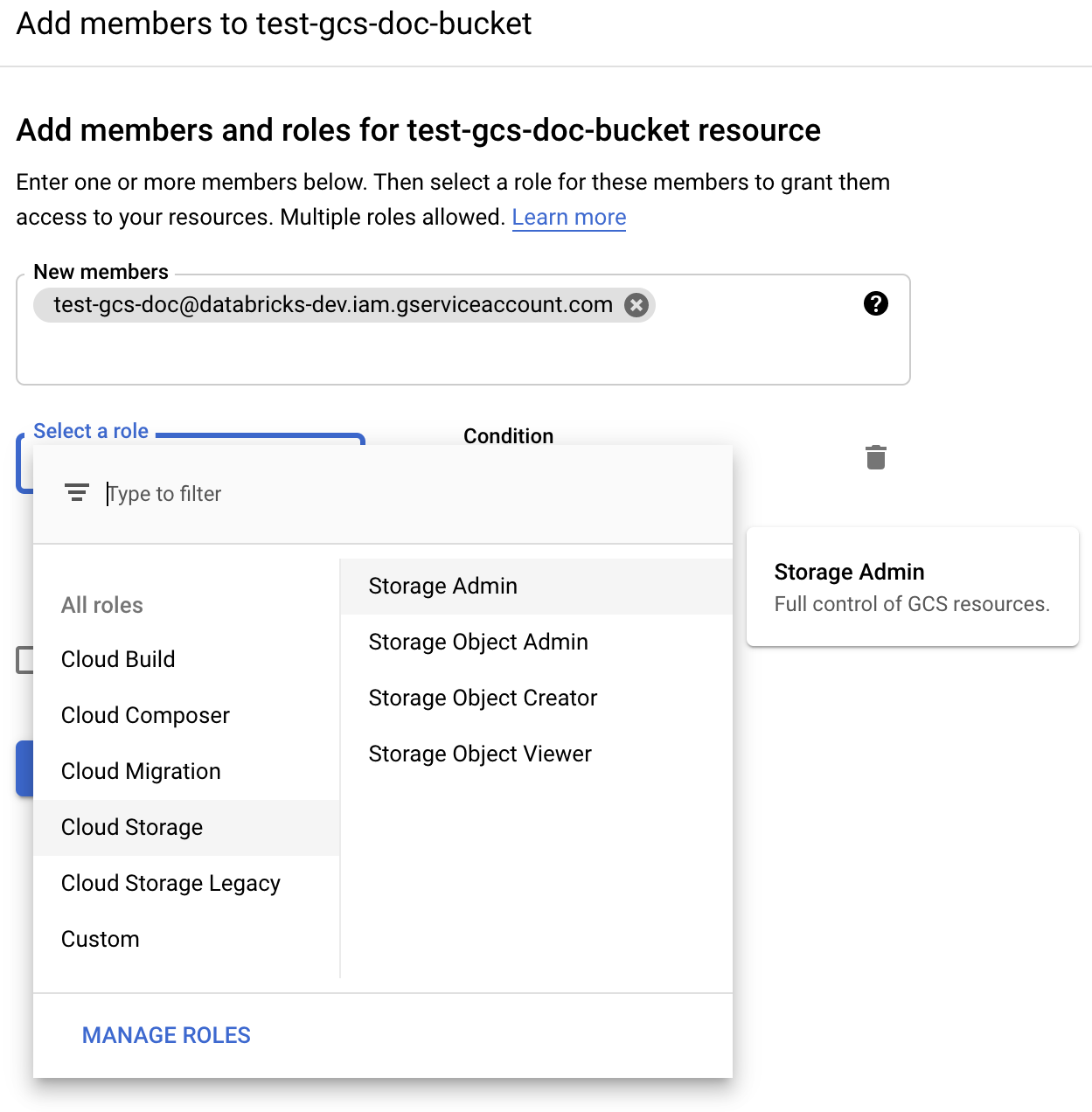
Щелкните СОХРАНИТЬ.
Шаг 4. Поместите ключ учетной записи службы в секреты Databricks
Databricks рекомендует использовать области секретов для хранения всех учетных данных. Вы можете поместить закрытый ключ и идентификатор закрытого ключа из файла JSON ключа в области секретов Databricks. Вы можете предоставить пользователям, служебным учетным записям и группам в рабочей области доступ для чтения секретных областей. Это защищает ключ учетной записи службы, позволяя пользователям получать доступ к GCS. Сведения о создании области секретов см. в разделе "Управление секретами".
Шаг 5. Настройка кластера Azure Databricks
На вкладке "Конфигурация Spark" настройте глобальную конфигурацию или конфигурацию для каждого контейнера. В следующих примерах ключи задаются с помощью значений, хранящихся в виде секретов Databricks.
Примечание.
Используйте управление доступом к кластеру и управление доступом к записной книжке вместе для защиты доступа к учетной записи службы и данным в контейнере GCS. Ознакомьтесь с разрешениями вычислений и совместной работой с помощью записных книжек Databricks.
Глобальная конфигурация
Используйте эту конфигурацию, если предоставленные учетные данные должны использоваться для доступа ко всем контейнерам.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
Замените <client-email>, <project-id> значениями этих точных имен полей из файла JSON ключа.
Конфигурация для каждого контейнера
Используйте эту конфигурацию, если необходимо настроить учетные данные для определенных контейнеров. Синтаксис конфигурации для каждого контейнера добавляет имя контейнера в конец каждой конфигурации, как показано в следующем примере.
Внимание
Конфигурации для каждого контейнера можно использовать в дополнение к глобальным конфигурациям. При указании конфигурации для каждого контейнера заменяют глобальные конфигурации.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
Замените <client-email>, <project-id> значениями этих точных имен полей из файла JSON ключа.
Шаг 6. Чтение из GCS
Для чтения из контейнера GCS используйте команду чтения Spark в любом поддерживаемом формате, например:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Чтобы записать в контейнер GCS, используйте команду записи Spark в любом поддерживаемом формате, например:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Замените <bucket-name> именем контейнера, созданного на шаге 3. Настройка контейнера GCS.