Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как использовать Apache Kafka в качестве источника или приемника при выполнении рабочих нагрузок структурированной потоковой передачи в Azure Databricks.
Дополнительные сведения о Kafka см. в документации по Kafka.
Чтение данных из Kafka
Ниже приведен пример потокового чтения из Kafka:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "latest")
.load()
)
Azure Databricks также поддерживает пакетную семантику чтения для источников данных Kafka, как показано в следующем примере:
df = (spark
.read
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "<topic>")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
)
Для добавочной пакетной загрузки Databricks рекомендует использовать Kafka с Trigger.AvailableNow. См. инструкции по настройке добавочной пакетной обработки.
В Databricks Runtime 13.3 LTS и более поздних версиях Azure Databricks предоставляет функцию SQL для чтения данных Kafka. Потоковая передача с помощью SQL поддерживается только в декларативных конвейерах Lakeflow или с таблицами потоковой передачи в Databricks SQL. См. табличную функцию read_kafka.
Настройка средства чтения структурированной потоковой передачи Kafka
Azure Databricks предоставляет ключевое слово kafka в качестве формата данных для настройки подключений к Kafka 0.10+.
Ниже приведены наиболее распространенные конфигурации для Kafka:
Есть несколько способов указания разделов для подписки. Необходимо указать только один из следующих параметров:
| Вариант | значение | Описание |
|---|---|---|
| подписка | Разделенный запятыми список разделов. | Список разделов, на который нужно подписаться. |
| шаблон подписки | Строка регэкспа Java. | Шаблон, используемый для подписки на разделы. |
| назначить | Строка в формате JSON {"topicA":[0,1],"topic":[2,4]}. |
Конкретные разделы topicPartitions для использования. |
Другие важные конфигурации:
| Вариант | значение | Значение по умолчанию | Описание |
|---|---|---|---|
| kafka.bootstrap.servers | Разделенный запятыми список host:port. | пусто | [Обязательно] Конфигурация Kafka bootstrap.servers. Если данные из Kafka отсутствуют, сначала проверьте список адресов брокера. Если список адресов брокера неверный, ошибки могут не возникнуть. Это обусловлено тем, что клиент Kafka предполагает, что брокеры в конечном счете станут доступны, и в случае ошибок сети будет повторять попытки бесконечно. |
| сбойПриПотереДанных |
true или false. |
true |
[Необязательно] Происходит ли сбой запроса, если возможно, что данные были потеряны. Запросы могут постоянно завершаться сбоем считывания данных из Kafka во многих сценариях, таких как удаление разделов, усечение разделов перед обработкой и т. д. Мы пытаемся с применением консервативного подхода определить, могут ли данные быть потеряны. Иногда это может привести к ложным сигналам. Установите этот параметр на false, если он не работает должным образом или если вы хотите, чтобы запрос продолжался, несмотря на потерю данных. |
| minPartitions | Целое число >= 0, 0 = отключено. | 0 (отключено) | [Необязательно] Минимальное число разделов для считывания из Kafka. С помощью minPartitions параметра Spark можно настроить произвольный минимум секций для чтения из Kafka. Обычно в Spark осуществляется сопоставление разделов Kafka с разделами Spark, использующими данные из Kafka, в соотношении 1-1. Если для параметра minPartitions задано значение, превышающее количество разделов Kafka, Spark разобьет большие разделы Kafka на меньшие части. Этот параметр можно задать в периоды пиковых нагрузок, перекоса данных и, если поток данных начинает отставать, чтобы увеличить скорость обработки. Это связано с инициализацией потребителей Kafka при каждом триггере, что может повлиять на производительность, если вы используете SSL при подключении к Kafka. |
| kafka.group.id | Идентификатор группы потребителей Kafka. | не задано | [Необязательно] Идентификатор группы для использования при чтении данных из Kafka. Следует использовать с осторожностью. По умолчанию каждый запрос формирует уникальный идентификатор группы для чтения данных. Это гарантирует, что каждый запрос будет иметь собственную группу потребителей, которая не сталкивается с помехами со стороны других потребителей и, следовательно, может считывать все разделы подписанных тем. В некоторых сценариях (например, при авторизации на основе группы Kafka) возможно, потребуется использовать определенные идентификаторы авторизованных групп для чтения данных. При необходимости можно задать идентификатор группы. Но это нужно сделать с особой осторожностью, так как это может привести к непредвиденному поведению.
|
| начальные смещения | самое раннее, самое позднее | последний | [Необязательно] Начальная точка при запуске запроса: либо "самая ранняя", что означает от самых ранних смещений, либо строка JSON, указывающая начальное смещение для каждого TopicPartition. В JSON значение -2 может использоваться как смещение для ссылки на самое раннее значение, а -1 — на последнее значение. Примечание. Для пакетных запросов использование последних данных (заданных неявно или с использованием -1 в json) не допускается. Для потоковых запросов это применяется только при запуске нового запроса, и возобновление всегда будет продолжаться с того места, где запрос остановился. Новообнаруженные секции при выполнении запроса начнут обработку с самого раннего момента. |
Сведения о других необязательных конфигурациях см. в статье Руководство по интеграции структурированной потоковой передачи Kafka.
Схема записей Kafka
Схема записей Kafka:
| Столбец | Тип |
|---|---|
| ключ | двоичный |
| значение | двоичный |
| тема | строка |
| разделение | INT |
| смещение | длинный |
| временная метка | длинный |
| тип временной метки | INT |
key и value всегда десериализуются как массивы байтов с ByteArrayDeserializer. Используйте операции DataFrame (например, cast("string")) для явной десериализации ключей и значений.
Запись данных в Kafka
Ниже приведен пример потоковой записи в Kafka:
(df
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.start()
)
Azure Databricks также поддерживает семантику пакетной записи в приемники данных Kafka, как показано в следующем примере:
(df
.write
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("topic", "<topic>")
.save()
)
Настройка модуля записи структурированной потоковой передачи Kafka
Внимание
Databricks Runtime 13.3 LTS и выше содержит более новую версию библиотеки kafka-clients, которая обеспечивает возможность идемпотентной записи по умолчанию. Если приемник Kafka использует версию 2.8.0 или ниже с настроенными ACL, но без включенного IDEMPOTENT_WRITE, запись завершается ошибкой org.apache.kafka.common.KafkaException:Cannot execute transactional method because we are in an error state.
Чтобы устранить эту ошибку, обновите до версии Kafka 2.8.0 или более поздней, или установите параметр .option(“kafka.enable.idempotence”, “false”) при настройке писателя структурированной потоковой передачи.
Схема, предоставленная DataStreamWriter, взаимодействует с приемником Kafka. Можно использовать следующие поля:
| Имя столбца | Обязательно или необязательно | Тип |
|---|---|---|
key |
необязательно |
STRING или BINARY |
value |
обязательно |
STRING или BINARY |
headers |
необязательно | ARRAY |
topic |
необязательный (игнорируется, если topic задан в качестве опции записи) |
STRING |
partition |
необязательно | INT |
Ниже приведены распространенные параметры при записи в Kafka:
| Вариант | значение | Значение по умолчанию | Описание |
|---|---|---|---|
kafka.boostrap.servers |
Список <host:port>, разделенный запятыми |
ничего | [Обязательно] Конфигурация Kafka bootstrap.servers. |
topic |
STRING |
не задано | [Необязательно] Устанавливает тему для записи всех строк. Этот параметр переопределяет любой столбец темы, имеющийся в данных. |
includeHeaders |
BOOLEAN |
false |
[Необязательно] Следует ли включать заголовки Kafka в строку. |
Сведения о других необязательных конфигурациях см. в статье Руководство по интеграции структурированной потоковой передачи Kafka.
Получение метрик Kafka
Вы можете получить среднее, минимальное и максимальное количество смещений, на которые потоковый запрос отстает от последнего доступного смещения среди всех подписанных тем, с использованием метрик avgOffsetsBehindLatest, maxOffsetsBehindLatestи minOffsetsBehindLatest. См. статью Чтение метрик в интерактивном режиме.
Примечание.
Доступно в Databricks Runtime 9.1 и в более поздних версиях.
Определите предполагаемое общее количество байтов, которые не были израсходованы в процессе обработки запроса из подписанных разделов, проверив значение estimatedTotalBytesBehindLatest. Эта оценка основана на пакетах, которые были обработаны за последние 300 секунд. Период, на котором основана оценка, можно изменить, задав для параметра bytesEstimateWindowLength другое значение. Например, чтобы задать для него значение 10 минут:
df = (spark.readStream
.format("kafka")
.option("bytesEstimateWindowLength", "10m") # m for minutes, you can also use "600s" for 600 seconds
)
Если вы выполняете поток в записной книжке, эти метрики можно просмотреть на вкладке "Необработанные данные " на панели мониторинга хода выполнения потокового запроса:
{
"sources": [
{
"description": "KafkaV2[Subscribe[topic]]",
"metrics": {
"avgOffsetsBehindLatest": "4.0",
"maxOffsetsBehindLatest": "4",
"minOffsetsBehindLatest": "4",
"estimatedTotalBytesBehindLatest": "80.0"
}
}
]
}
Подключение Azure Databricks к Kafka с помощью SSL
Чтобы включить SSL-подключения к Kafka, следуйте инструкциям в документации Confluent шифрование и проверка подлинности с помощью SSL. Вы можете указать описанные здесь конфигурации с префиксом с kafka. как параметры. Например, вы можете указать расположение хранилища доверия в свойстве kafka.ssl.truststore.location.
Databricks рекомендует вам:
- Храните сертификаты в облачном хранилище объектов. Доступ к сертификатам можно ограничить только кластерами, которые могут получить доступ к Kafka. См. сведения об управлении данными с помощью Azure Databricks.
- Храните пароли сертификатов как секреты в области секретов.
В следующем примере используются расположения хранилища объектов и секреты Databricks для включения SSL-подключения:
df = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", ...)
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.ssl.truststore.location", <truststore-location>)
.option("kafka.ssl.keystore.location", <keystore-location>)
.option("kafka.ssl.keystore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<keystore-password-key-name>))
.option("kafka.ssl.truststore.password", dbutils.secrets.get(scope=<certificate-scope-name>,key=<truststore-password-key-name>))
)
Подключение Kafka на HDInsight к Azure Databricks
Создайте кластер Kafka HDInsight.
Инструкции см. в статье Подключение к Kafka в HDInsight с помощью виртуальной сети Azure.
Настройте брокеры Kafka для объявления правильного адреса.
Следуйте инструкциям из раздела Настройка Kafka для рекламы IP-адресов. Если вы самостоятельно управляете Kafka на виртуальных машинах Azure, убедитесь, что в конфигурации
advertised.listenersброкеров задан внутренний IP-адрес узлов.Создайте кластер Azure Databricks.
Установите пиринг между кластером Kafka и кластером Azure Databricks.
Следуйте инструкциям из раздела Виртуальные одноранговые сети.
Аутентификация учетной записи службы с помощью Microsoft Entra ID и Azure Event Hubs
Azure Databricks поддерживает проверку подлинности заданий Spark со службами Центров событий. Эта проверка подлинности выполняется с помощью OAuth с идентификатором Microsoft Entra.
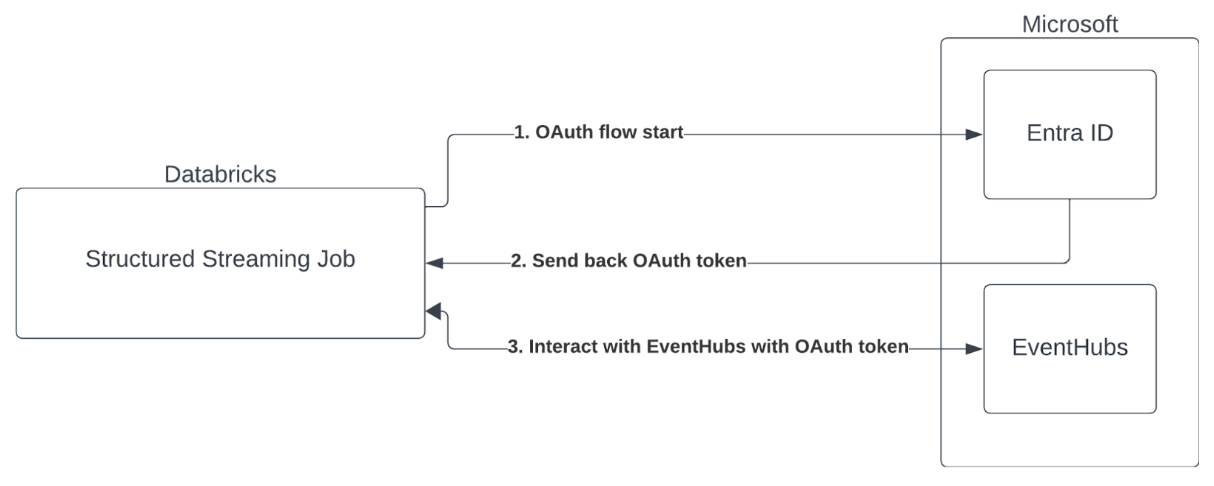
Azure Databricks поддерживает проверку подлинности Идентификатора Microsoft Entra с идентификатором клиента и секретом в следующих вычислительных средах:
- Databricks Runtime 12.2 LTS и более поздние версии на вычислительных устройствах, настроенных на выделенный режим доступа (ранее - режим доступа с одним пользователем).
- Databricks Runtime версии 14.3 LTS и выше для вычислительных ресурсов, настроенных на стандартный режим доступа (ранее назывался режимом общего доступа).
- Декларативные конвейеры Lakeflow, настроенные без каталога Unity.
Azure Databricks не поддерживает проверку подлинности идентификатора Microsoft Entra с сертификатом в любой вычислительной среде или в декларативных конвейерах Lakeflow, настроенных с помощью каталога Unity.
Эта проверка подлинности не работает на вычислениях с стандартным режимом доступа или в декларативных конвейерах каталога Unity Lakeflow.
Поддержка учетных данных службы каталога Unity для AWS MSK и Центров событий Azure
С момента выпуска DBR 16.1 Azure Databricks поддерживает учетные данные службы каталога Unity для проверки подлинности доступа к управляемой потоковой передаче AWS для Apache Kafka (MSK) и Центров событий Azure. Azure Databricks рекомендует этот подход для выполнения потоковой передачи Kafka в общих кластерах и при использовании бессерверных вычислений.
Чтобы использовать учетные данные службы каталога Unity для проверки подлинности, выполните следующие действия.
- Создайте учетные данные службы каталога Unity. Если вы не знакомы с этим процессом, ознакомьтесь с инструкциями по созданию учетных данных службы.
- Укажите имя учетных данных службы каталога Unity в качестве источника в конфигурации Kafka. Задайте для параметра
databricks.serviceCredentialимя учетных данных службы.
Примечание. Если вы предоставляете учетные данные службы каталога Unity в Kafka, не указывайте эти параметры, так как они больше не требуются:
kafka.sasl.mechanismkafka.sasl.jaas.configkafka.security.protocolkafka.sasl.client.callback.handler.classkafka.sasl.oauthbearer.token.endpoint.url
Настройка соединителя Структурированной потоковой передачи Kafka
Чтобы выполнить проверку подлинности с помощью идентификатора Microsoft Entra, необходимо иметь следующие значения:
Идентификатор клиента. Это можно найти во вкладке службы Microsoft Entra ID.
Идентификатор клиента (также известный как идентификатор приложения).
Секрет клиента. После того, как вы это получите, его необходимо добавить в качестве секрета в рабочую область Databricks. Чтобы добавить этот секрет, см. раздел "Управление секретами".
Тема EventHubs. Список тем вы можете найти в разделе "Центры событий" в разделе "Сущности" на конкретной странице пространства имен "Центры событий". Чтобы работать с несколькими темами, можно задать роль IAM на уровне Event Hubs.
Сервер EventHubs. Это можно найти на странице общей информации вашего конкретного пространства имен для Центров событий.
Кроме того, чтобы использовать Entra ID, необходимо указать Kafka использовать механизм SASL OAuth (SASL является общим протоколом, а OAuth - это тип 'механизма' SASL):
-
kafka.security.protocolдолжно бытьSASL_SSL -
kafka.sasl.mechanismдолжно бытьOAUTHBEARER -
kafka.sasl.login.callback.handler.classдолжно быть полным именем класса Java со значениемkafkashaded, предназначенным для обработчика обратного вызова авторизации в затемнённом классе Kafka. См. следующий пример для данного класса.
Пример
Далее рассмотрим работающий пример:
Питон
# This is the only section you need to modify for auth purposes!
# ------------------------------
tenant_id = "..."
client_id = "..."
client_secret = dbutils.secrets.get("your-scope", "your-secret-name")
event_hubs_server = "..."
event_hubs_topic = "..."
# -------------------------------
sasl_config = f'kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="{client_id}" clientSecret="{client_secret}" scope="https://{event_hubs_server}/.default" ssl.protocol="SSL";'
kafka_options = {
# Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers": f"{event_hubs_server}:9093",
"kafka.sasl.jaas.config": sasl_config,
"kafka.sasl.oauthbearer.token.endpoint.url": f"https://login.microsoft.com/{tenant_id}/oauth2/v2.0/token",
"subscribe": event_hubs_topic,
# You should not need to modify these
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class": "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
}
df = spark.readStream.format("kafka").options(**kafka_options)
display(df)
язык программирования Scala
// This is the only section you need to modify for auth purposes!
// -------------------------------
val tenantId = "..."
val clientId = "..."
val clientSecret = dbutils.secrets.get("your-scope", "your-secret-name")
val eventHubsServer = "..."
val eventHubsTopic = "..."
// -------------------------------
val saslConfig = s"""kafkashaded.org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required clientId="$clientId" clientSecret="$clientSecret" scope="https://$eventHubsServer/.default" ssl.protocol="SSL";"""
val kafkaOptions = Map(
// Port 9093 is the EventHubs Kafka port
"kafka.bootstrap.servers" -> s"$eventHubsServer:9093",
"kafka.sasl.jaas.config" -> saslConfig,
"kafka.sasl.oauthbearer.token.endpoint.url" -> s"https://login.microsoft.com/$tenantId/oauth2/v2.0/token",
"subscribe" -> eventHubsTopic,
// You should not need to modify these
"kafka.security.protocol" -> "SASL_SSL",
"kafka.sasl.mechanism" -> "OAUTHBEARER",
"kafka.sasl.login.callback.handler.class" -> "kafkashaded.org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler"
)
val scalaDF = spark.readStream
.format("kafka")
.options(kafkaOptions)
.load()
display(scalaDF)
Обработка потенциальных ошибок
Параметры потоковой передачи не поддерживаются.
Если вы пытаетесь использовать этот механизм проверки подлинности в декларативных конвейерах Lakeflow, настроенных с помощью каталога Unity, может появиться следующая ошибка:
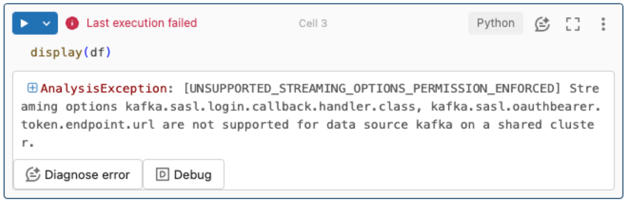
Чтобы устранить эту ошибку, используйте поддерживаемую конфигурацию вычислений. См. аутентификацию сервисного принципала с Microsoft Entra ID и Azure Event Hubs.
Не удалось создать новый
KafkaAdminClientобъект.Это внутренняя ошибка, вызываемая Kafka, если какие-либо из следующих параметров проверки подлинности неверны:
- Идентификатор клиента (также известный как идентификатор приложения)
- Идентификатор клиента
- Сервер EventHubs
Чтобы устранить ошибку, убедитесь, что значения верны для этих параметров.
Кроме того, эта ошибка может появиться при изменении параметров конфигурации, предоставленных по умолчанию в примере (которые вы попросили не изменять), например
kafka.security.protocol.Записи не возвращаются
Если вы пытаетесь отобразить или обработать кадр данных, но не получаете результаты, вы увидите следующее в пользовательском интерфейсе.
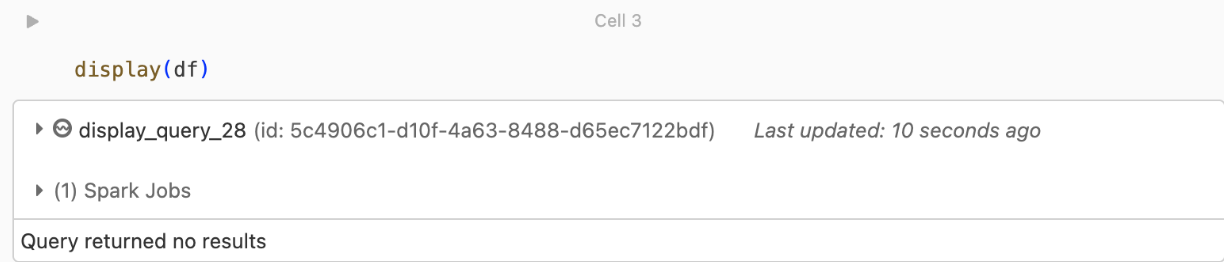
Это сообщение означает, что проверка подлинности прошла успешно, но EventHubs не возвращала никаких данных. Некоторые возможные причины (хотя и не являются исчерпывающими) являются:
- Вы указали неправильный раздел EventHubs .
- Для параметра конфигурации Kafka
startingOffsetsпо умолчанию используетсяlatest, и вы пока не получаете никаких данных через тему. Вы можете установитьstartingOffsets, чтобы начать чтение данных сearliest, начиная с самых ранних смещений Kafka.