Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
На этой странице описывается визуализация происхождения данных с помощью обозревателя каталогов, системных таблиц происхождения данных и REST API.
Обзор происхождения данных
Каталог Unity фиксирует происхождение данных среды выполнения в запросах, выполняемых в Azure Databricks. Родословная поддерживается для всех языков и фиксируется на уровне столбца. Данные о происхождении включают записные книжки, задания и панели мониторинга, связанные с данным запросом. Родословную можно визуализировать в Catalog Explorer почти в реальном времени и получать программно с использованием системных таблиц родословной и REST API Databricks.
Lineage также может включать внешние ресурсы и рабочие процессы, выполняемые за пределами Azure Databricks. Эта функция внешних метаданных происхождения доступна в общедоступной предварительной версии. См. Собственное происхождение данных.
Линейность собирается во всех рабочих областях, подключенных к метахранилищу Unity Catalog. Это означает, что родословная, зафиксированная в одной рабочей области, видна в любой другой рабочей области, которая разделяет это хранилище метаданных. В частности, таблицы и другие объекты данных, зарегистрированные в хранилище метаданных, видны пользователям, имеющим по крайней мере BROWSE разрешения на эти объекты во всех рабочих областях, подключенных к хранилищу метаданных. Однако подробные сведения об объектах на уровне рабочей области, таких как записные книжки и панели мониторинга в других рабочих областях, маскируются (см. ограничения происхождения и разрешения на происхождение).
Данные о происхождении сохраняются в течение одного года.
На следующем рисунке представлен пример графика происхождения.
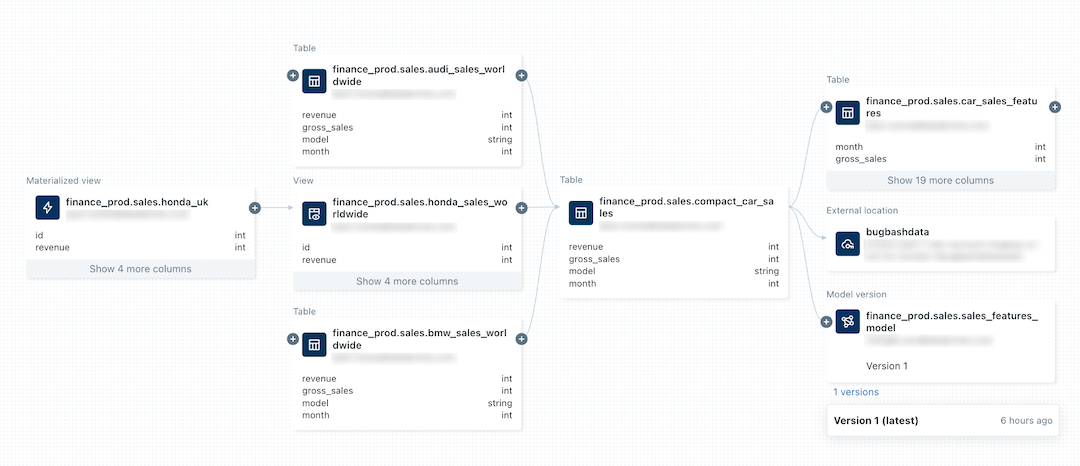
Сведения об отслеживании происхождения модели машинного обучения см. в статье Отслеживание происхождения данных модели в каталоге Unity.
Требования
Для записи происхождения данных с помощью каталога Unity:
- Таблицы должны быть зарегистрированы в хранилище метаданных каталога Unity.
- Внешние ресурсы (не зарегистрированные в хранилище метаданных каталога Unity) необходимо добавить в качестве внешних объектов метаданных в каталоге Unity, настроенных для связи с другими защищаемыми объектами, зарегистрированными в хранилище метаданных каталога Unity. См. Собственное происхождение данных.
- Запросы должны выполняться с использованием Spark DataFrame (например, функций Spark SQL, возвращающих DataFrame) или интерфейсов SQL Databricks, таких как записные книжки и редактор запросов SQL.
Чтобы просмотреть происхождение данных, выполните приведенные действия.
- У вас должна быть привилегия
BROWSEкак минимум в каталоге-родителе таблицы или представления. Родительский каталог также должен быть доступен из рабочей области. См. раздел Ограничение доступа к каталогу для определенных рабочих областей. - Для записных книжек, заданий или панелей мониторинга необходимо иметь разрешения на эти объекты, как определено параметрами управления доступом в рабочей области. Дополнительные сведения см. в разделе "Разрешения происхождения".
- Для конвейера с поддержкой Unity Catalog необходимо иметь разрешение CAN VIEW на конвейер.
Требования к вычислениям:
- Для отслеживания происхождения потоков данных между таблицами Delta требуется Databricks Runtime 11.3 LTS или новее.
- Для отслеживания происхождения столбцов для рабочих нагрузок Декларативных конвейеров Lakeflow требуется среда выполнения Databricks 13.3 LTS или более поздней версии.
Требования к сети:
- Возможно, потребуется обновить правила исходящего брандмауэра, чтобы разрешить подключение к конечной точке Центров событий в плоскости управления Azure Databricks. Обычно это актуально, если рабочая область Azure Databricks развертывается в собственной виртуальной сети (также известной как инъекция виртуальной сети). Чтобы получить конечную точку Пакетов событий для вашего региона рабочего пространства, см. раздел хранилище метаданных, хранилище артефактов BLOB, хранилище системных таблиц, хранилище журналов BLOB и IP-адреса конечных точек Пакетов событий. Сведения о настройке определяемых пользователем маршрутов (UDR) для Azure Databricks см. в разделе Пользовательские параметры маршрутизации для Azure Databricks.
Просмотр происхождения данных с помощью обозревателя каталогов
Чтобы использовать обозреватель каталогов для просмотра происхождения таблиц:
В рабочей области Azure Databricks щелкните
 Каталог.
Каталог.Найдите или просмотрите вашу таблицу.
Перейдите на вкладку "Происхождение". Откроется панель происхождения и отображает связанные таблицы.
Чтобы просмотреть интерактивный граф происхождения данных, нажмите Просмотреть график происхождения данных.
По умолчанию в графе отображается один уровень. Щелкните значок
 на узле, чтобы отобразить дополнительные подключения, если они доступны.
на узле, чтобы отобразить дополнительные подключения, если они доступны.Щелкните стрелку, соединяющую узлы в графе связей, чтобы открыть панель подключения Lineage.
Панель подключения родословной отображает детали соединения, включая исходные и целевые таблицы, записные книжки и задания.
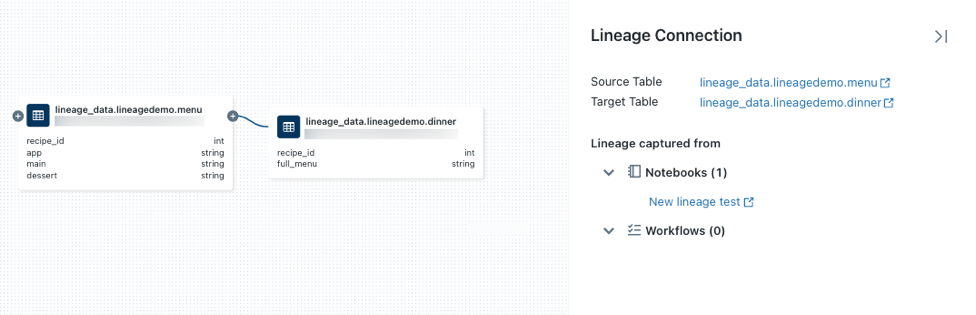
Чтобы отобразить записную книжку, связанную с таблицей, выберите записную книжку на панели Lineage connection или закройте граф происхождения и щелкните "Записные книжки".
Чтобы открыть записную книжку на новой вкладке, щелкните имя записной книжки.
Чтобы просмотреть происхождение на уровне столбцов, щелкните столбец в графе, чтобы отобразить ссылки на связанные столбцы. Например, щелкая по столбцу
full_menuв этом примере графика, выводятся исходные столбцы, из которых был получен данный столбец.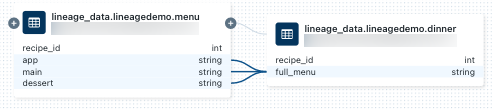
Просмотр происхождения заданий
Чтобы просмотреть происхождение заданий, перейдите на вкладку "Происхождение таблицы", выберите "Задания" и выберите "Вниз". Имя задания отображается в разделе "Имя задания" в качестве потребителя таблицы.
Просмотр истории панели мониторинга
Чтобы просмотреть происхождение панели мониторинга, перейдите на вкладку "Происхождение таблицы" и щелкните "Панели мониторинга". Панель мониторинга отображается в разделе "Имя панели мониторинга " в качестве потребителя таблицы.
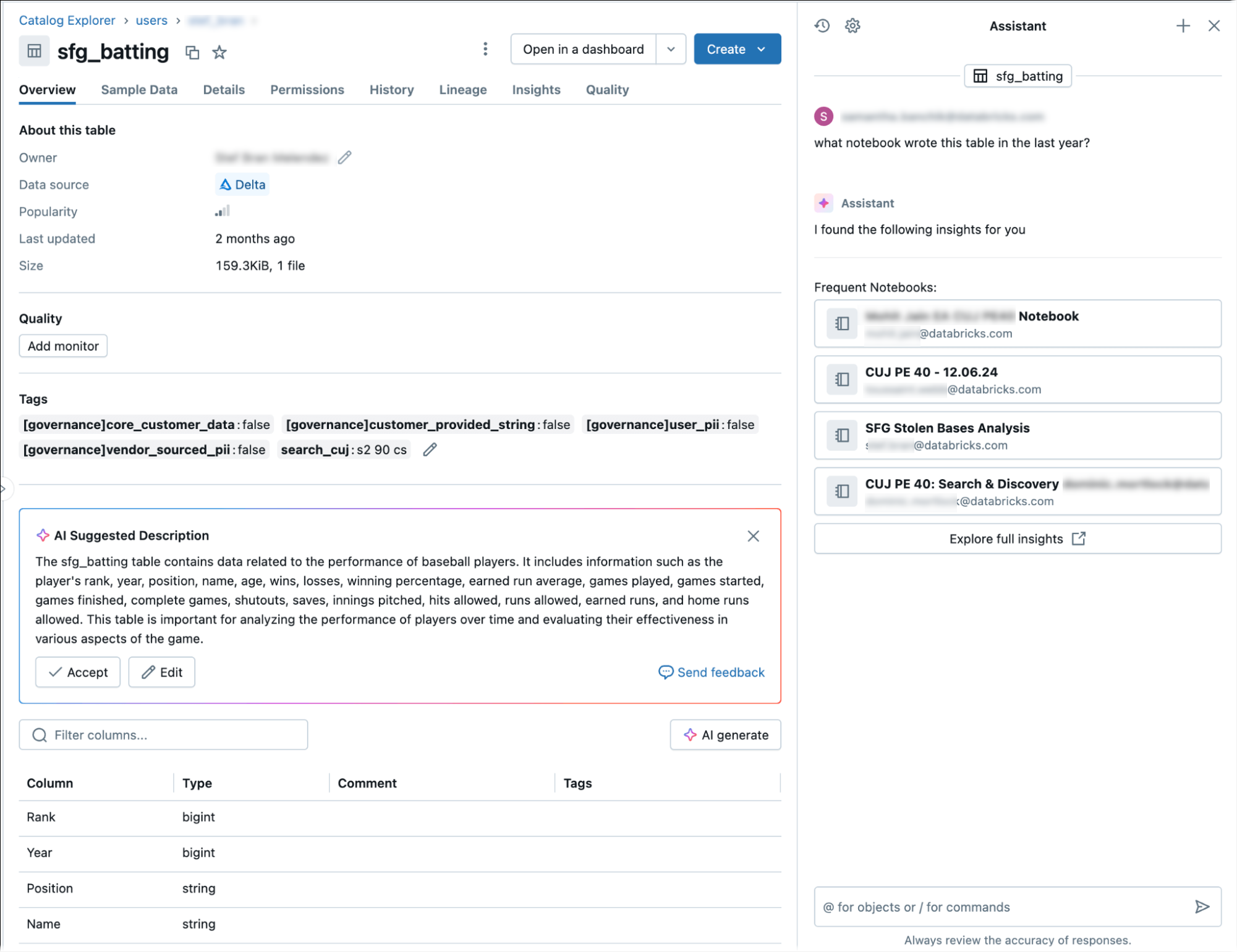
Узнайте происхождение таблицы с помощью ассистента Databricks
Помощник по Databricks предоставляет подробные сведения о происхождении таблиц и аналитике.
Чтобы получить сведения о происхождении с помощью помощника, выполните следующие действия:
- На боковой панели рабочей области щелкните Каталог.
- Просмотрите или найдите каталог, щелкните имя каталога, а затем щелкните значок помощника по продукту - цвет в правом верхнем углу.
- В командной строке помощника введите следующее:
- /getTableLineages для просмотра вышестоящих и подчиненных зависимостей.
- /getTableInsights для доступа к аналитическим сведениям на основе метаданных, таким как действия пользователей и шаблоны запросов.
Эти запросы позволяют помощнику отвечать на вопросы, такие как "показать нижестоящие зависимости" или "кто чаще всего запрашивает эту таблицу".
Данные о происхождении запросов с использованием системных таблиц
Системные таблицы происхождения можно использовать для программного запроса данных происхождения. Подробные инструкции см. в статье Мониторинг действий учетной записи с помощью системных таблиц и Справочник системных таблиц родословной.
Если рабочая область находится в регионе, который не поддерживает системные таблицы происхождения, вместо этого можно использовать REST API data lineage для получения данных происхождения программным способом.
Получение происхождения данных с помощью REST API происхождения данных
API происхождения данных позволяет получить происхождение таблиц и столбцов. Однако если рабочая область находится в регионе, поддерживающем системные таблицы происхождения, следует использовать системные запросы таблиц вместо REST API. Системные таблицы — это лучший вариант для программного извлечения данных происхождения. Большинство регионов поддерживают системные таблицы происхождения.
Внимание
Чтобы получить доступ к REST API Databricks, необходимо пройти проверку подлинности.
Восстановление происхождения таблицы
В этом примере извлекаются данные о происхождении для таблицы dinner.
Запрос
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Замените <workspace-instance>.
В этом примере используется файл .netrc.
Ответ
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Получение происхождения столбцов
В этом примере извлекаются данные столбцов для таблицы dinner.
Запрос
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Замените <workspace-instance>.
В этом примере используется файл .netrc.
Ответ
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Разрешения на происхождение данных
Графики происхождения используют ту же модель разрешений, что и Unity Catalog. Таблицы и другие объекты данных, зарегистрированные в хранилище метаданных каталога Unity, видны только пользователям, имеющим по крайней мере BROWSE разрешения на эти объекты. Если у пользователя нет прав BROWSE или SELECT в таблице, они не могут изучить его происхождение. Графы происхождения отображают объекты каталога Unity во всех рабочих областях, связанных с метахранилищем, если у пользователя есть соответствующие разрешения на объекты.
Например, выполните следующие команды для userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
Когда userA просматривает график происхождения для таблицы lineage_data.lineagedemo.menu, они увидят таблицу menu. Они не смогут просматривать сведения о связанных таблицах, например нижестоящей lineage_data.lineagedemo.dinner таблице. Таблица dinner отображается в виде узла masked на экране для userA, и userA не может развернуть граф, чтобы отобразить подчиненные таблицы из тех, к которым они не имеют разрешения на доступ.
При выполнении следующей команды для выдачи BROWSE разрешения userB пользователю, он сможет просматривать граф для любой таблицы в схеме lineage_data.
GRANT BROWSE on lineage_data to `userB@company.com`;
Аналогичным образом пользователи родословной данных должны иметь определенные разрешения для просмотра объектов рабочей области, таких как панели мониторинга, задания и блокноты. Кроме того, они могут просматривать только подробные сведения об объектах рабочей области при входе в рабочую область, в которой были созданы эти объекты. Подробная информация об объектах уровня рабочей области в других рабочих областях скрывается в графе родословной.
Дополнительные сведения об управлении доступом к защищаемым объектам в каталоге Unity см. в статье Управление привилегиями в каталоге Unity. Дополнительные сведения об управлении доступом к объектам рабочей области, таким как записные книжки, задания и панели мониторинга, см. списки управления доступом.
Ограничения происхождения
Происхождение данных имеет следующие ограничения. Эти ограничения также применяются к системным таблицам происхождения:
Хотя линейная структура агрегируется для всех рабочих пространств, подключенных к одному хранилищу метаданных каталога Unity, сведения об объектах рабочего пространства, таких как ноутбуки и панели мониторинга, отображаются только в том рабочем пространстве, в котором они были созданы.
Поскольку линейность вычисляется в однолетнем скользящем окне, данные, собранные более одного года назад, не показываются. Например, если задание или запрос считывает данные из таблицы А и записывается в таблицу B, связь между таблицей A и таблицей B отображается только в течение одного года. Данные о происхождении можно фильтровать по временным интервалам в течение одного года.
Задания, использующие запрос API заданий
runs submitили тип заданияspark submit, недоступны в представлениях родословной. Линия происхождения на уровне таблицы и столбца по-прежнему зафиксирована для этих рабочих процессов, но ссылка на выполнение задания не зафиксирована.Если таблица или представление переименованы, цепочка связи не сохраняется для переименованной таблицы или представления.
Если схема или каталог переименованы, происхождение данных не фиксируется для таблиц и представлений в переименованном каталоге или схеме.
Если вы используете контрольные точки набора данных Spark SQL, родословная не записывается.
Каталог Unity в большинстве случаев фиксирует зависимости из декларативных конвейеров Lakeflow. Однако в некоторых случаях полное покрытие происхождения невозможно гарантировать, например, когда потоки данных используют закрытые таблицы.
Lineage не записывает функции стека.
Глобальные временные представления не фиксируются в линейности.
Таблицы в
system.information_schemaне фиксируются в линейности.Каталог Unity фиксирует происхождение данных до уровня столбца настолько, насколько это возможно. Однако в некоторых случаях невозможно записать происхождение на уровне столбцов. К ним относятся:
Не удается зафиксировать происхождение столбцов, если источник или целевой объект указан как путь (пример:
select * from delta."s3://<bucket>/<path>"). Линейность столбцов поддерживается только в том случае, если и источник, и приемник ссылаются по имени таблицы (пример:select * from <catalog>.<schema>.<table>).Использование общих табличных выражений (CTEs), переименование столбцов, определяемых пользователем функций (ОПФ), или устойчивых распределенных наборов данных (RDD), которые могут скрыть сопоставление между исходными и целевыми столбцами.
Полный линейдж на уровне столбцов по умолчанию не отслеживается для операций
MERGE.Вы можете включить запись происхождения для
MERGEопераций, задав для свойства Spark значениеspark.databricks.dataLineage.mergeIntoV2Enabledtrue. Включение этого флага может замедлить производительность запросов, особенно в рабочих нагрузках, включающих очень широкие таблицы.