CI/CD с Jenkins в Azure Databricks
Примечание.
В этой статье описывается решение Jenkins, которое не предоставляется и не поддерживается Databricks. Чтобы связаться с поставщиком, см. справку по Jenkins.
Существует множество средств CI/CD, которые можно использовать для управления и запуска конвейеров CI/CD. В этой статье показано, как использовать сервер автоматизации Jenkins. CI/CD — это конструктивный шаблон, поэтому шаги и этапы, описанные в этой статье, можно использовать во всех средствах с небольшими изменениями для языка определения конвейера. Кроме того, большая часть кода в этом примере конвейера запускает стандартный код Python, который можно вызывать в других инструментах. Общие сведения о CI/CD в Azure Databricks см. в статье "Что такое CI/CD в Azure Databricks?".
Дополнительные сведения об использовании Azure DevOps с Azure Databricks см. в статье об непрерывной интеграции и доставке в Azure Databricks с помощью Azure DevOps.
Рабочий процесс разработки CI/CD
Databricks предлагает следующий рабочий процесс для разработки CI/CD с помощью Jenkins:
- Создайте репозиторий или используйте существующий репозиторий с сторонним поставщиком Git.
- Подключите локальный компьютер разработки к одному и тому же стороннему репозиторию. Инструкции см. в документации сторонних поставщиков Git.
- Извлеките все существующие обновленные артефакты (например, записные книжки, файлы кода и скрипты сборки) из стороннего репозитория на локальный компьютер разработки.
- При необходимости создайте, обновите и протестируйте артефакты на локальном компьютере разработки. Затем отправьте все новые и измененные артефакты с локального компьютера разработки в сторонний репозиторий. Инструкции см. в докуменации стороннего поставщика Git.
- Повторите шаги 3 и 4 по мере необходимости.
- Используйте Jenkins периодически в качестве интегрированного подхода к автоматическому извлечению артефактов из стороннего репозитория на локальный компьютер разработки или рабочую область Azure Databricks; создание, тестирование и запуск кода на локальном компьютере разработки или рабочей области Azure Databricks; и отчеты о тестах и выполнении результатов. Хотя вы можете запускать Jenkins вручную, в реальных реализациях вы научите стороннему поставщику Git запускать Jenkins каждый раз, когда происходит определенное событие, например запрос на вытягивание репозитория.
Остальная часть этой статьи использует пример проекта, чтобы описать один из способов использования Jenkins для реализации предыдущего рабочего процесса разработки CI/CD.
Сведения об использовании Azure DevOps вместо Jenkins см. в статье Об непрерывной интеграции и доставке в Azure Databricks с помощью Azure DevOps.
Настройка локального компьютера разработки
В примере этой статьи Jenkins используется для указания интерфейса командной строки Databricks и пакетов активов Databricks выполнить следующие действия:
- Создайте файл колеса Python на локальном компьютере разработки.
- Разверните созданный файл колеса Python вместе с дополнительными файлами Python и записными книжками Python с локального компьютера разработки в рабочей области Azure Databricks.
- Проверьте и запустите загруженный файл колеса Python и записные книжки в этой рабочей области.
Чтобы настроить локальный компьютер разработки, чтобы указать рабочей области Azure Databricks выполнить этапы сборки и отправки для этого примера, выполните следующие действия на локальном компьютере разработки:
Шаг 1. Установка необходимых средств
На этом шаге на локальном компьютере разработки устанавливается интерфейс командной строки Databricks, Jenkins jqи средства сборки колес Python. Эти средства необходимы для выполнения этого примера.
Установите Интерфейс командной строки Databricks версии 0.205 или более поздней, если это еще не сделано. Jenkins использует интерфейс командной строки Databricks для передачи тестового примера и выполнения инструкций в рабочую область. См. статью "Установка или обновление интерфейса командной строки Databricks".
Установите и запустите Jenkins, если это еще не сделано. См. статью об установке Jenkins для Linux, macOS или Windows.
Установите jq. В этом примере используется
jqдля анализа некоторых выходных данных команды в формате JSON.Используется
pipдля установки средств сборки колес Python со следующей командой (для некоторых систем может потребоваться использоватьpip3вместоpip):pip install --upgrade wheel
Шаг 2. Создание конвейера Jenkins
На этом шаге вы используете Jenkins для создания конвейера Jenkins для примера этой статьи. Jenkins предоставляет несколько различных типов проектов для создания конвейеров CI/CD. Конвейеры Jenkins предоставляют интерфейс для определения этапов в конвейере Jenkins с помощью кода Groovy для вызова и настройки подключаемых модулей Jenkins.
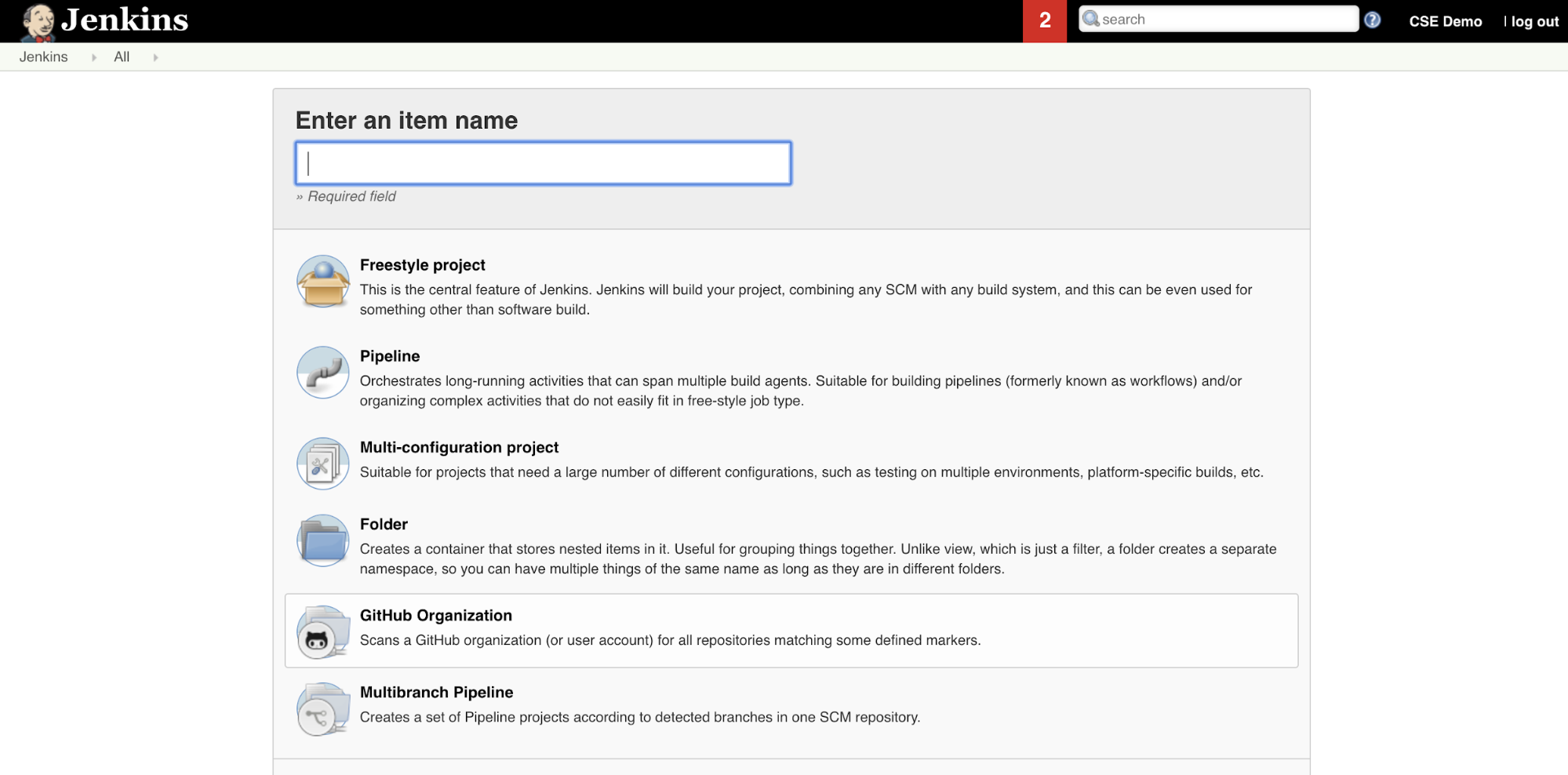
Чтобы создать конвейер Jenkins в Jenkins, выполните следующие действия.
- После запуска Jenkins на панели мониторинга Jenkins нажмите кнопку "Создать элемент".
- Введите имя элемента для конвейера Jenkins, например
jenkins-demo. - Щелкните значок типа проекта конвейера.
- Щелкните OK. Откроется страница настройки конвейера Jenkins.
- В области конвейера в раскрывающемся списке "Определение" выберите сценарий конвейера из SCM.
- В раскрывающемся списке SCM выберите Git.
- Для URL-адреса репозитория введите URL-адрес репозитория, размещенного поставщиком Git третьей части.
- В поле "Описатель ветви" введите
*/<branch-name><branch-name>имя ветви в репозитории, которую вы хотите использовать, например*/main. - Для пути к скрипту введите
Jenkinsfile, если он еще не задан. Далее вы создадитеJenkinsfileэту статью. - Снимите флажок "Упрощенный флажок", если он уже установлен.
- Нажмите кнопку Сохранить.
Шаг 3. Добавление глобальных переменных среды в Jenkins
На этом шаге вы добавите три глобальных переменных среды в Jenkins. Jenkins передает эти переменные среды в интерфейс командной строки Databricks. Интерфейс командной строки Databricks должен иметь значения для этих переменных среды для проверки подлинности в рабочей области Azure Databricks. В этом примере для субъекта-службы используется проверка подлинности OAuth на компьютере (хотя и другие типы проверки подлинности также доступны). Сведения о настройке проверки подлинности OAuth M2M для рабочей области Azure Databricks см. в статье "Использование субъекта-службы для проверки подлинности с помощью Azure Databricks".
Ниже приведены три глобальных переменных среды для этого примера:
DATABRICKS_HOSTЗадайте URL-адрес рабочей области Azure Databricks, начиная сhttps://. См. Имена экземпляров рабочей области, URL-адреса и идентификаторы.DATABRICKS_CLIENT_ID, задайте идентификатор клиента субъекта-службы, который также называется его идентификатором приложения.DATABRICKS_CLIENT_SECRETДля этого задайте секрет Azure Databricks OAuth субъекта-службы.
Чтобы задать глобальные переменные среды в Jenkins, на панели мониторинга Jenkins:
- На боковой панели нажмите кнопку "Управление Jenkins".
- В разделе "Конфигурация системы" щелкните "Система".
- В разделе "Глобальные свойства" установите флажки переменные среды с плитками.
- Нажмите кнопку "Добавить", а затем введите имя и значение переменной среды. Повторите это для каждой дополнительной переменной среды.
- После добавления переменных среды нажмите кнопку "Сохранить", чтобы вернуться на панель мониторинга Jenkins.
Проектирование конвейера Jenkins
Jenkins предоставляет несколько различных типов проектов для создания конвейеров CI/CD. В этом примере реализуется конвейер Jenkins. Конвейеры Jenkins предоставляют интерфейс для определения этапов в конвейере Jenkins с помощью кода Groovy для вызова и настройки подключаемых модулей Jenkins.
Определение конвейера Jenkins записывается в текстовый файл с именем Jenkinsfile, который, в свою очередь, проверяется в репозитории системы управления версиями проекта. Для получения дополнительной информации см. Конвейеры Jenkins. Ниже приведен конвейер Jenkins для примера этой статьи. В этом примере Jenkinsfileзамените следующие заполнители:
- Замените
<user-name>имя<repo-name>пользователя и репозитория, размещенные сторонним поставщиком Git. В этой статье в качестве примера используется URL-адрес GitHub. - Замените
<release-branch-name>именем ветви выпуска в репозитории. Например, это может бытьmain. - Замените
<databricks-cli-installation-path>путь на локальном компьютере разработки, где установлен интерфейс командной строки Databricks. Например, в macOS это может быть/usr/local/bin. - Замените
<jq-installation-path>путь на локальном компьютере разработки, гдеjqустанавливается. Например, в macOS это может быть/usr/local/bin. - Замените
<job-prefix-name>на некоторую строку, чтобы однозначно определить задания Azure Databricks, созданные в рабочей области в этом примере. Например, это может бытьjenkins-demo. - Обратите внимание, что
BUNDLETARGETзадано значениеdev,которое является именем целевого объекта набора ресурсов Databricks, определенного далее в этой статье. В реальных реализациях вы измените это на имя собственного целевого объекта пакета. Дополнительные сведения о целевых объектах пакетов приведены далее в этой статье.
Ниже приведено Jenkinsfileзначение, которое необходимо добавить в корневой каталог репозитория:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Оставшаяся часть этой статьи описывает каждый этап в этом конвейере Jenkins и как настроить артефакты и команды для Jenkins для запуска на этом этапе.
Извлечение последних артефактов из стороннего репозитория
Первый этап в этом конвейере Checkout Jenkins, этап, определяется следующим образом:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
На этом этапе убедитесь, что рабочий каталог, который Jenkins использует на локальном компьютере разработки, имеет последние артефакты из вашего стороннего репозитория Git. Как правило, Jenkins задает для этого рабочего каталога <your-user-home-directory>/.jenkins/workspace/<pipeline-name>значение . Это позволяет на том же локальном компьютере разработки хранить собственную копию артефактов в разработке отдельно от артефактов, которые Jenkins использует из стороннего репозитория Git.
Проверка пакета активов Databricks
Второй этап в этом конвейере Jenkins, Validate Bundle этап, определяется следующим образом:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
На этом этапе убедитесь, что пакет ресурсов Databricks, определяющий рабочие процессы для тестирования и запуска артефактов, является синтаксически правильным. Наборы ресурсов Databricks, известные как пакеты, позволяют выразить полные данные, аналитику и проекты машинного обучения в виде коллекции исходных файлов. См. раздел "Что такое пакеты ресурсов Databricks?".
Чтобы определить пакет для этой статьи, создайте файл с именем databricks.yml в корне клонированного репозитория на локальном компьютере. В этом примере databricks.yml файла замените следующие заполнители:
- Замените
<bundle-name>уникальным программным именем пакета. Например, это может бытьjenkins-demo. - Замените
<job-prefix-name>на некоторую строку, чтобы однозначно определить задания Azure Databricks, созданные в рабочей области в этом примере. Например, это может бытьjenkins-demo. Оно должно соответствовать значениюJOBPREFIXв Jenkinsfile. - Замените
<spark-version-id>идентификатором версии databricks Runtime для кластеров заданий, например13.3.x-scala2.12. - Замените
<cluster-node-type-id>идентификатор типа узла для кластеров заданий, напримерStandard_DS3_v2. - Обратите внимание, что
devвtargetsсопоставлении совпадает с файломBUNDLETARGETJenkinsfile. Целевой объект пакета определяет узел и связанное поведение развертывания.
Ниже приведен databricks.yml файл, который должен быть добавлен в корневой каталог репозитория для правильной работы этого примера:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Дополнительные сведения о файле см. в databricks.yml разделе "Конфигурации пакета ресурсов Databricks".
Развертывание пакета в рабочей области
Третий этап конвейера Jenkins, который Deploy Bundleназывается, определяется следующим образом:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
На этом этапе выполняется два действия:
artifactТак как для файла заданоwhlсопоставлениеdatabricks.yml, это указывает Databricks CLI создать файл колесика Python с помощьюsetup.pyфайла в указанном расположении.- После создания файла колес Python на локальном компьютере разработки интерфейс командной строки Databricks развертывает созданный файл колеса Python вместе с указанными файлами Python и записными книжками в рабочей области Azure Databricks. По умолчанию пакеты ресурсов Databricks развертывают файл колесика Python и другие файлы
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Чтобы включить сборку колесика Python, как указано в databricks.yml файле, создайте следующие папки и файлы в корне клонированного репозитория на локальном компьютере.
Чтобы определить логику и модульные тесты для файла колеса Python, в который будет выполняться записная книжка, создайте два файла с именем addcol.py и test_addcol.pyдобавьте их в структуру папок, именуемую python/dabdemo/dabdemo в папке репозитория Libraries , визуализированную следующим образом (многоточие указывает на пропущенные папки в репозитории для краткости):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Файл addcol.py содержит функцию библиотеки, которая встроена позже в файл колесика Python, а затем установлена в кластере Azure Databricks. Это простая функция, которая добавляет новый столбец, заполненный литералом, в кадр данных Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Файл test_addcol.py содержит тесты для передачи объекта mock DataFrame в функцию, определенную with_status в addcol.py. Затем выполняется сравнение результата с объектом DataFrame, содержащим предполагаемые значения. Если значения совпадают, в этом случае они выполняются, тест проходит:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Чтобы разрешить Databricks CLI правильно упаковать этот код библиотеки в файл колесика Python, создайте два файла с именем __init__.py и в той же папке, что и __main__.py предыдущие два файла. Кроме того, создайте файл с именем setup.py в папке python/dabdemo , визуализируемый следующим образом (многоточие указывает на пропущенные папки для краткости):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Файл __init__.py содержит номер версии библиотеки и его автор. Замените <my-author-name> своим именем:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Файл __main__.py содержит точку входа библиотеки:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Файл setup.py содержит дополнительные параметры для создания библиотеки в файл колесика Python. Замените <my-url>, <my-author-name>@<my-organization>а <my-package-description> также значимыми значениями:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Проверка логики компонента колеса Python
Этап Run Unit Tests , четвертый этап этого конвейера Jenkins, используется pytest для проверки логики библиотеки, чтобы убедиться, что она работает как построенная. Этот этап определяется следующим образом:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
На этом этапе для выполнения задания записной книжки используется интерфейс командной строки Databricks. Это задание запускает записную книжку Python с именем run-unit-test.pyфайла. Эта записная книжка выполняется pytest в логике библиотеки.
Чтобы запустить модульные тесты для этого примера, добавьте файл записной книжки Python со следующим содержимым в корневой каталог run_unit_tests.py клонированного репозитория на локальном компьютере:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Использование встроенного колеса Python
Пятый этап этого конвейера Jenkins под названием Run Notebookзапускает записную книжку Python, которая вызывает логику в встроенном файле колеса Python, как показано ниже.
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
На этом этапе выполняется интерфейс командной строки Databricks, который, в свою очередь, указывает рабочей области выполнять задание записной книжки. Эта записная книжка создает объект DataFrame, передает его в функцию библиотеки with_status , выводит результат и сообщает результаты выполнения задания. Создайте записную книжку, добавив файл dabdaddemo_notebook.py записной книжки Python со следующим содержимым в корне клонированного репозитория на локальном компьютере разработки:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Оценка результатов выполнения задания записной книжки
Этап Evaluate Notebook Runs , шестой этап этого конвейера Jenkins, оценивает результаты предыдущего задания записной книжки. Этот этап определяется следующим образом:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
На этом этапе выполняется интерфейс командной строки Databricks, который, в свою очередь, указывает рабочей области выполнять задание файла Python. Этот файл Python определяет критерии сбоя и успешности выполнения задания записной книжки и сообщает об этом сбое или результате успешного выполнения. Создайте файл с именем evaluate_notebook_runs.py со следующим содержимым в корневом каталоге клонированного репозитория на локальном компьютере разработки:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Результаты импорта и отчета о тестах
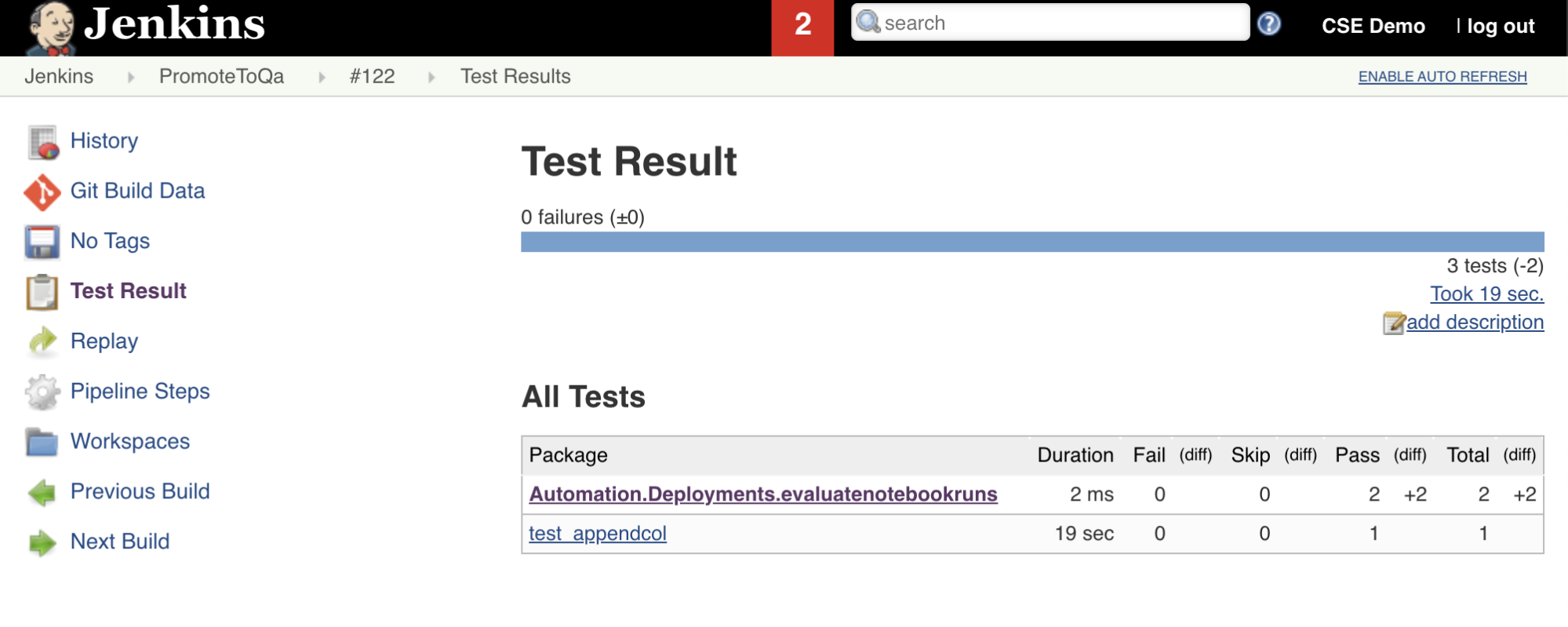
Седьмой этап в этом конвейере Jenkins с названием Import Test Resultsиспользует интерфейс командной строки Databricks для отправки результатов теста из рабочей области на локальный компьютер разработки. Восьмой и заключительный этап, который Publish Test Resultsназывается, публикует результаты теста в Jenkins с помощью подключаемого junit модуля Jenkins. Это позволяет визуализировать отчеты и панели мониторинга, связанные с состоянием результатов теста. Эти этапы определяются следующим образом:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Отправка всех изменений кода в сторонний репозиторий
Теперь необходимо отправить содержимое клонированного репозитория на локальный компьютер разработки в сторонний репозиторий. Перед отправкой необходимо сначала добавить следующие записи .gitignore в файл в клонированного репозитория, так как, вероятно, не следует отправлять рабочие файлы внутреннего пакета ресурсов Databricks, отчеты о проверке, файлы сборки Python и кэши Python в сторонний репозиторий. Как правило, вы хотите создать новые отчеты проверки и последние сборки колес Python в рабочей области Azure Databricks, а не использовать потенциально устаревшие отчеты проверки и сборки колес Python:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Запуск конвейера Jenkins
Теперь вы готовы запустить конвейер Jenkins вручную. Для этого на панели мониторинга Jenkins сделайте следующее:
- Щелкните имя конвейера Jenkins.
- На боковой панели нажмите кнопку "Создать сейчас".
- Чтобы просмотреть результаты, щелкните последнюю версию запуска конвейера (например,
#1) и нажмите кнопку "Выходные данные консоли".
На этом этапе завершается цикл интеграции и развертывания на конвейере CI/CD. Автоматизация этого процесса позволяет гарантировать, что код протестирован и развернут с помощью эффективного, стабильного и повторяемого процесса. Чтобы указать стороннему поставщику Git запускать Jenkins каждый раз, когда происходит определенное событие, например запрос на вытягивание репозитория, ознакомьтесь с документацией сторонних поставщиков Git.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по