Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Это важно
Эта функция доступна в бета-версии.
В этой статье описывается использование редактора Конвейеров Lakeflow для разработки и отладки конвейеров ETL (извлечение, преобразование и загрузка) в декларативных конвейерах Lakeflow.
Сведения о разработке по умолчанию с помощью одной записной книжки в Декларативных конвейерах Lakeflow см. в статье "Разработка и отладка конвейеров ETL с помощью записной книжки в Декларативных конвейерах Lakeflow".
Что такое редактор потоков Lakeflow?
Редактор Конвейеров Lakeflow — это интегрированная среда разработки декларативных конвейеров Lakeflow. Он объединяет все задачи разработки конвейеров на одной поверхности, поддерживая рабочие процессы на основе кода, организацию кода на основе папок, выборочное выполнение, предварительный просмотр данных и графы конвейеров. Интегрированная с платформой Azure Databricks, она также включает управление версиями, проверки кода и запланированные запуски.
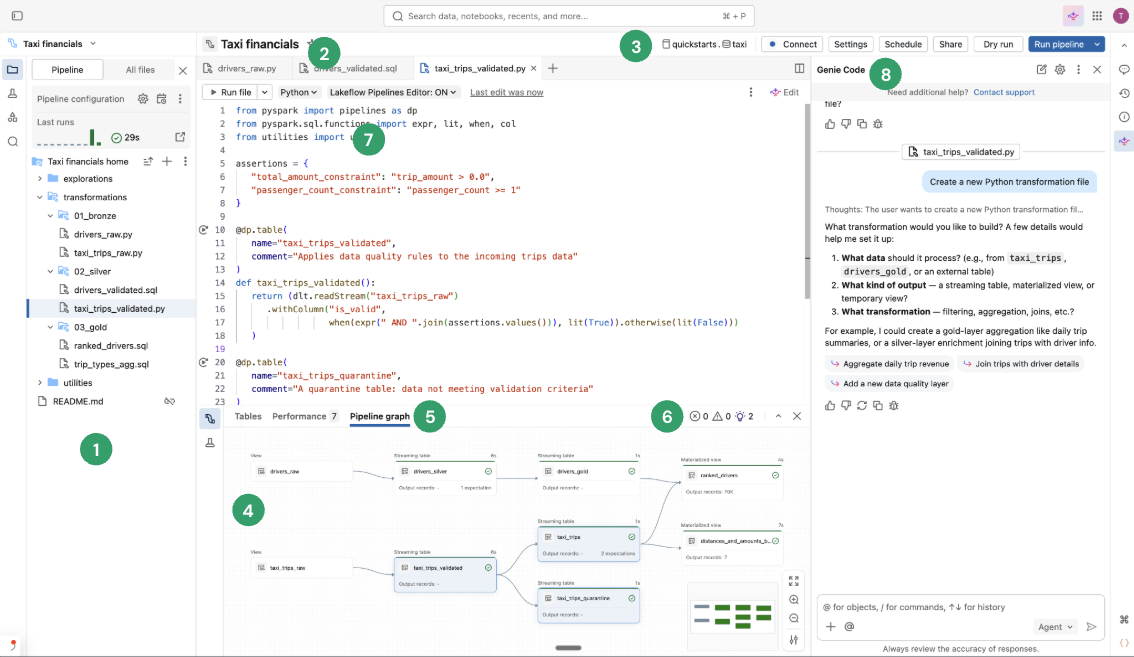
Обзор пользовательского интерфейса редактора конвейеров Lakeflow
Редактор Конвейеров Lakeflow имеет следующие функции:
- Браузер ресурсов конвейера: создание, удаление, переименование и упорядочение ресурсов конвейера.
- Редактор кода с несколькими файлами с вкладками: работа между несколькими файлами кода, связанными с конвейером.
- Панель инструментов для конкретного конвейера: включает конфигурацию конвейера и имеет действия выполнения на уровне конвейера.
- Интерактивный ациклический граф (DAG) — получение обзора таблиц, открытие нижней панели предварительных просмотров данных и выполнение других действий, связанных с таблицами.
- Предварительный просмотр данных: проверьте данные потоковых таблиц и материализованных представлений.
- Аналитика выполнения на уровне таблицы: получение аналитических сведений о выполнении для всех таблиц или одной таблицы в конвейере. Аналитические сведения относятся к последнему запуску конвейера.
- Панель проблем: эта функция суммирует ошибки во всех файлах в конвейере, и вы можете перейти к месту возникновения ошибки внутри определенного файла. Он дополняет индикаторы ошибок, прикрепленных к коду.
- Выборочное выполнение. Редактор кода имеет функции пошаговой разработки, такие как возможность обновления таблиц только в текущем файле с помощью действия запуска файла или одной таблицы.
- Структура папок конвейера по умолчанию: новые конвейеры включают предопределенную структуру папок и пример кода, который можно использовать в качестве отправной точки для конвейера.
- Упрощенное создание конвейера: укажите имя, каталог и схему, в которой таблицы должны создаваться по умолчанию, и конвейер создается с помощью параметров по умолчанию. Позже можно изменить Настройки на панели инструментов редактора конвейера.
Включение редактора конвейеров Lakeflow
Замечание
Сначала необходимо включить возможности разработчика конвейеров с несколькими файлами для рабочей области. Дополнительные сведения см. в статье "Управление предварительными версиями Azure Databricks ".
Если ваш уровень относится к профилю безопасности для соблюдения нормативных требований, свяжитесь с вашим представителем Azure Databricks, чтобы попробовать эту функцию.
Редактор ETL-конвейеров данных Lakeflow Pipelines можно включить несколькими способами.
При создании конвейера ETL включите редактор в Декларативных конвейерах Lakeflow с помощью переключателя редактора конвейера ETL .
Страница расширенных параметров конвейера используется при первом включении редактора. Окно создания упрощенного конвейера используется при следующем создании нового конвейера.
Для существующего конвейера откройте записную книжку, используемую в конвейере, и включите переключатель редактора конвейера ETL в заголовке. Вы также можете перейти на страницу мониторинга конвейера и нажать кнопку "Параметры ", чтобы включить редактор конвейеров Lakeflow.
После включения переключателя редактора конвейера ETL все конвейеры ETL будут использовать редактор конвейеров Lakeflow по умолчанию. Вы можете включить и отключить редактор конвейера ETL из редактора.
Кроме того, можно включить редактор Pipelines Lakeflow из параметров пользователя:
- Щелкните значок пользователя в правой верхней области рабочей области, а затем нажмите кнопку "Параметры " и "Разработчик".
- Включение вкладок для записных книжек и файлов.
- Включите многофайловый редактор конвейера ETL.
Создание конвейера ETL
Чтобы создать новый конвейер ETL с помощью редактора конвейеров Lakeflow, выполните следующие действия:
В верхней части боковой панели щелкните
 Новый и выберите
Новый и выберите  Конвейер ETL.
Конвейер ETL.В верхней части можно указать уникальное имя конвейера.
Под именем можно увидеть каталог по умолчанию и схему, выбранные для вас. Измените их, чтобы предоставить конвейеру разные значения по умолчанию.
Каталог по умолчанию и схема по умолчанию — это место, в котором наборы данных считываются или записываются, когда наборы данных не соответствуют каталогу или схеме в коде. Дополнительные сведения см. в разделе "Объекты базы данных" в Azure Databricks .
Выберите предпочтительный вариант для создания конвейера, выбрав один из следующих вариантов:
- Начните с примера кода в SQL , чтобы создать новую структуру конвейера и папок, включая пример кода в SQL.
- Начните с примера кода в Python , чтобы создать новую структуру конвейера и папок, включая пример кода в Python.
- Начните с одного преобразования , чтобы создать новую структуру конвейера и папок с новым пустым файлом кода.
- Добавьте существующие ресурсы для создания конвейера, который можно связать с файлами кода exisitng в рабочей области.
В конвейере ETL можно использовать файлы исходного кода SQL и Python. При создании конвейера и выборе языка для примера кода язык предназначен только для примера кода, включенного в конвейер по умолчанию.
При выборе вы будете перенаправлены в только что созданный конвейер.
Конвейер ETL создается со следующими параметрами по умолчанию:
Эти параметры можно настроить на панели инструментов конвейера.
Кроме того, можно создать конвейер ETL из браузера рабочей области:
- Щелкните рабочую область на левой панели.
- Выберите любую папку, включая папки Git.
- Щелкните "Создать " в правом верхнем углу и щелкните конвейер ETL.
Вы также можете создать конвейер ETL на странице заданий и конвейеров:
- В рабочей области щелкните на
 Задания и конвейеры на боковой панели.
Задания и конвейеры на боковой панели. - В меню Создать нажмите Конвейер ETL.
Открытие существующего конвейера ETL
Чтобы открыть существующий конвейер ETL в редакторе конвейеров Lakeflow, выполните следующие действия.
- Щелкните рабочее пространство на боковой панели.
- Перейдите в папку с файлами исходного кода для конвейера.
- Щелкните файл исходного кода, чтобы открыть конвейер в редакторе.
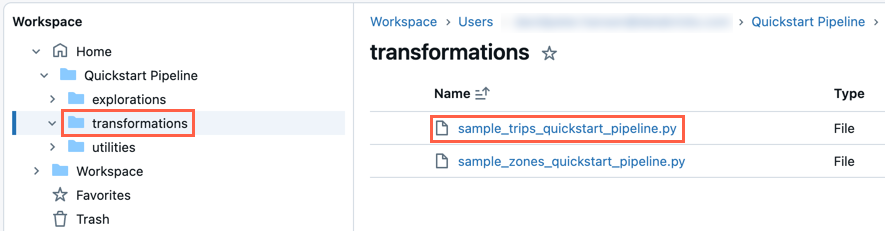
Вы также можете открыть существующий конвейер ETL следующим образом:
- На странице "Последние" на левой боковой панели откройте конвейер или файл, настроенный в качестве исходного кода для конвейера.
- На странице мониторинга конвейера нажмите кнопку "Изменить конвейер".
- На странице "Запуски заданий" на левой боковой панели щелкните вкладку "Задания и конвейеры" и затем щелкните
 Затем Изменить конвейер.
Затем Изменить конвейер. - При создании нового задания и добавлении задачи конвейера вы можете щелкнуть значок нового окна
 , когда выберете конвейер в разделе Конвейер.
, когда выберете конвейер в разделе Конвейер. - При редактировании конвейера можно щелкнуть имя конвейера в верхней части браузера активов, чтобы выбрать из списка недавно просматриваемых конвейеров.
- Если открыть файл исходного кода, настроенный в качестве исходного кода для другого конвейера из браузера активов, в верхней части редактора этого файла появится баннер, предлагающий открыть связанный конвейер. Чтобы открыть файл исходного кода, который не является частью конвейера, выберите все файлы в верхней части браузера ресурсов.
Браузер ресурсов конвейера
Редактор трубопроводов Lakeflow имеет специальный режим для боковой панели браузера рабочей области, называемый браузером ресурсов трубопровода и по умолчанию фокусирует панель на трубопроводе.
Щелкните имя конвейера в верхней части браузера, чтобы переключиться между недавно просматриваемых конвейеров.
В браузере активов есть две вкладки:
- Конвейер. Здесь можно найти все файлы, связанные с конвейером. Вы можете создавать, удалять, переименовать и упорядочивать их в папках.
- Все файлы: все остальные ресурсы рабочей области доступны здесь.
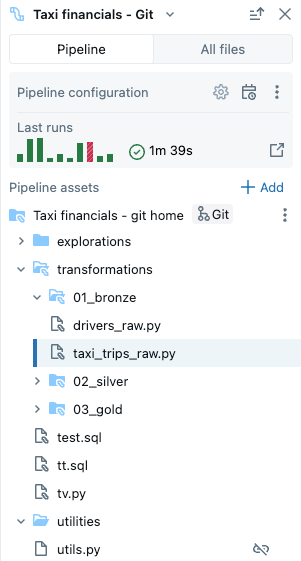
В конвейере можно использовать следующие типы файлов:
- Файлы исходного кода: эти файлы являются частью определения исходного кода конвейера, который можно увидеть в параметрах. Databricks рекомендует всегда хранить файлы исходного кода в корневой папке конвейера; в противном случае они будут отображаться в разделе внешнего файла в нижней части браузера и имеют менее широкий набор функций.
- Файлы, отличные от исходного кода: эти файлы хранятся в корневой папке конвейера, но не являются частью определения исходного кода конвейера.
Это важно
Необходимо использовать браузер ресурсов конвейера на вкладке "Конвейер" для управления файлами и папками для конвейера. Это приведет к правильному обновлению параметров конвейера. Перемещение или переименование файлов и папок из браузера рабочей области или из вкладки Все файлы приведет к разрыву конфигурации конвейера обработки, и затем вы должны вручную решить эту проблему в Параметрах.
Корневая папка
Браузер ресурсов конвейера привязан к корневой папке конвейера. При создании нового конвейера корневая папка конвейера создается в домашней папке пользователя и называется так же, как имя конвейера.
Корневую папку можно изменить в браузере ресурсов конвейера. Это полезно, если вы создали конвейер в папке, а затем хотите переместить все в другую папку. Например, вы создали конвейер в обычной папке и хотите переместить исходный код в папку Git для управления версиями.
- Щелкните наверху корневой папки, чтобы открыть его дополнительное меню.
- Нажмите кнопку "Настроить новую корневую папку".
- В разделе "Корневая папка конвейера" щелкните
 и выберите другую папку в качестве корневой папки конвейера.
и выберите другую папку в качестве корневой папки конвейера. - Нажмите кнопку "Сохранить".
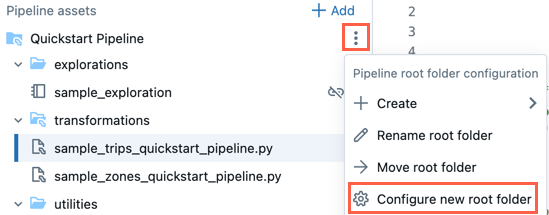
На ![]() корневой папки можно также нажать кнопку "Переименовать корневую папку ", чтобы переименовать имя папки. Здесь можно также щелкнуть "Переместить корневую папку ", чтобы переместить корневую папку, например в папку Git.
корневой папки можно также нажать кнопку "Переименовать корневую папку ", чтобы переименовать имя папки. Здесь можно также щелкнуть "Переместить корневую папку ", чтобы переместить корневую папку, например в папку Git.
Вы также можете изменить корневую папку конвейера в параметрах:
- Нажмите кнопку "Параметры".
- В разделе "Ресурсы кода" щелкните "Настройка путей".
- Щелкните , чтобы изменить папку в корневой папке конвейера.
- Нажмите кнопку "Сохранить".
Замечание
Если изменить корневую папку конвейера, список файлов, отображаемый браузером ресурсов конвейера, будет затронут, так как файлы в предыдущей корневой папке теперь будут отображаться как внешние файлы.
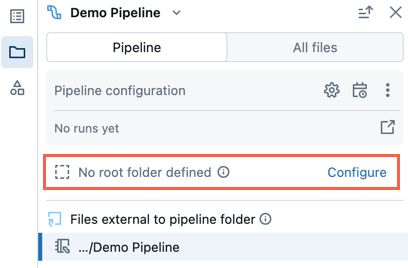
Существующий конвейер без корневой папки
Существующий конвейер, созданный в процессе разработки по умолчанию с помощью одного ноутбука в Декларативных конвейерах Lakeflow, не будет иметь настроенной корневой папки. Выполните следующие действия, чтобы настроить корневую папку для существующего конвейера:
- В браузере ресурсов конвейера нажмите кнопку "Настроить".
- Щелкните , чтобы выбрать корневую папку в корневой папке конвейера.
- Нажмите кнопку "Сохранить".
Структура папок по умолчанию
При создании нового конвейера создается структура папок по умолчанию. Это рекомендуемая схема для организации исходных и неисходных файлов кода потока, как описано ниже.
Небольшое количество примеров файлов кода создаются в этой структуре папок.
| Имя папки | Рекомендуемое расположение для этих типов файлов |
|---|---|
<pipeline_root_folder> |
Корневая папка, содержащая все папки и файлы для конвейера. |
explorations |
Файлы кода, отличные от исходного кода, такие как записные книжки, запросы и файлы кода, используемые для анализа аналитических данных. |
transformations |
Файлы исходного кода, такие как файлы кода Python или SQL с определениями таблиц. |
utilities |
Файлы, отличные от исходного кода, с модулями Python, которые можно импортировать из других файлов кода. Если вы выбрали SQL в качестве языка для примера кода, эта папка не будет создана. |
Имена папок можно переименовать или изменить структуру, чтобы она соответствовала рабочему процессу. Чтобы добавить новую папку исходного кода, выполните следующие действия.
- Нажмите кнопку "Добавить " в браузере ресурсов конвейера.
- Щелкните "Создать папку исходного кода конвейера".
- Введите имя папки и нажмите кнопку "Создать".
Файлы исходного кода
Файлы исходного кода являются частью определения исходного кода конвейера. При запуске конвейера эти файлы оцениваются. Файлы и папки, входящие в определение исходного кода, имеют специальный значок с маленьким изображением конвейера.
Чтобы добавить новый файл исходного кода, выполните следующие действия.
- Нажмите кнопку "Добавить " в браузере ресурсов конвейера.
- Щелкните Преобразование.
- Введите имя файла и выберите Python или SQL в качестве языка.
- Нажмите кнопку "Создать".
Вы также можете щелкнуть ![]() Для любой папки в браузере ресурсов конвейера можно добавить файл исходного кода.
Для любой папки в браузере ресурсов конвейера можно добавить файл исходного кода.
Папка transformations для исходного кода создается по умолчанию при создании нового конвейера. Эта папка является рекомендуемой папкой для исходного кода конвейера, например файлов кода Python или SQL с определениями таблиц конвейера.
Файлы, отличные от исходного кода
Файлы кода, отличные от исходного кода, хранятся в корневой папке конвейера, но не являются частью определения исходного кода конвейера. Эти файлы не оцениваются при запуске конвейера. Файлы, отличные от исходного кода, не могут быть внешними файлами.
Это можно использовать для файлов, связанных с работой в конвейере, который вы хотите хранить вместе с исходным кодом. Рассмотрим пример.
- Записные книжки, которые вы используете для нерегламентированных исследований и выполняете на нетиповых декларативных конвейерах Lakeflow, обрабатываются вне жизненного цикла конвейера.
- Модули Python, которые не должны оцениваться с помощью исходного кода, если вы явно не импортируете эти модули в файлы исходного кода.
Чтобы добавить новый файл, отличный от исходного кода, выполните следующие действия.
- Нажмите кнопку "Добавить " в браузере ресурсов конвейера.
- Щелкните "Исследование" или "Утилита".
- Введите имя файла.
- Нажмите кнопку "Создать".
Вы также можете щелкнуть ![]() Для корневой папки конвейера или файла кода, отличного от исходного кода, можно добавить файлы, отличные от исходного кода, в папку.
Для корневой папки конвейера или файла кода, отличного от исходного кода, можно добавить файлы, отличные от исходного кода, в папку.
При создании нового конвейера по умолчанию создаются следующие папки для файлов, отличных от исходного кода:
| Имя папки | Описание |
|---|---|
explorations |
Эта папка является рекомендуемым местом для записных книжек, запросов, панелей мониторинга и других файлов, которые следует запускать на вычислительных ресурсах, не относящихся к декларативным конвейерам Lakeflow, как это обычно делается вне жизненного цикла выполнения конвейера. Важно. Они не должны быть добавлены в качестве исходного кода для конвейера. Конвейер может выдать ошибку, так как эти файлы, скорее всего, содержат произвольный код, отличный от декларативных конвейеров Lakeflow. |
utilities |
Эта папка является рекомендуемым расположением для модулей Python, которые можно импортировать из других файлов с помощью прямых импортов, выраженных как from <filename> import, если их родительская папка иерархически находится под корневой папкой. |
Вы также можете импортировать модули Python, расположенные вне корневой папки, но в этом случае необходимо добавить путь sys.path к папке в код Python:
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
внешние файлы;
В разделе "Внешние файлы " браузера конвейера отображаются файлы исходного кода за пределами корневой папки.
Чтобы переместить внешний файл в корневую папку, например в папку transformations, выполните следующие действия:
- Щелкните Для файла в браузере ресурсов нажмите кнопку "Переместить".
- Выберите папку, в которую нужно переместить файл, и нажмите кнопку "Переместить".
Файлы, связанные с несколькими конвейерами
Значок отображается в заголовке файла, если файл связан с несколькими конвейерами. Он включает в себя количество связанных трубопроводов и позволяет переключаться между ними.
Раздел "Все файлы"
В дополнение к разделу Pipeline есть раздел "Все файлы ", где можно открыть любой файл в рабочей области. Здесь можно:
- Откройте файлы вне корневой папки на вкладке без выхода из редактора Конвейеров Lakeflow.
- Перейдите к файлам исходного кода другого конвейера и откройте их. Файл откроется в редакторе, и вы увидите баннер с опцией переключить фокус в редакторе на этот второй конвейер управляющих процессов.
- Переместите файлы в корневую папку конвейера.
- Включите файлы вне корневой папки в определение исходного кода конвейера.
Запуск кода конвейера
У вас есть три варианта запуска кода конвейера:
Запустите все файлы исходного кода в конвейере: нажмите кнопку "Запустить конвейер " или "Запустить конвейер" с полным обновлением таблицы , чтобы запустить все определения таблиц во всех файлах, определенных как исходный код конвейера.
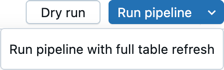
Вы также можете нажать кнопку "Сухой запуск" , чтобы проверить конвейер без обновления данных.
Запустите код в одном файле: нажмите кнопку "Запустить файл " или "Выполнить файл" с полным обновлением таблицы , чтобы запустить все определения таблиц в текущем файле.
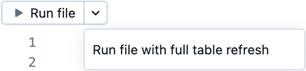
Запустите код для одной таблицы: щелкните для определения DLT Run Table Iconтаблицы в файле исходного кода и нажмите кнопку "Обновить таблицу" или "Полная таблица обновления".
Направленный ациклический граф (DAG)
После запуска или проверки всех файлов исходного кода в потоке вы увидите ориентированный ациклический граф (DAG). На графе показан граф зависимостей таблицы. У каждого узла имеются различные состояния на протяжении жизненного цикла конвейера, такие как проверка, запуск или ошибка.
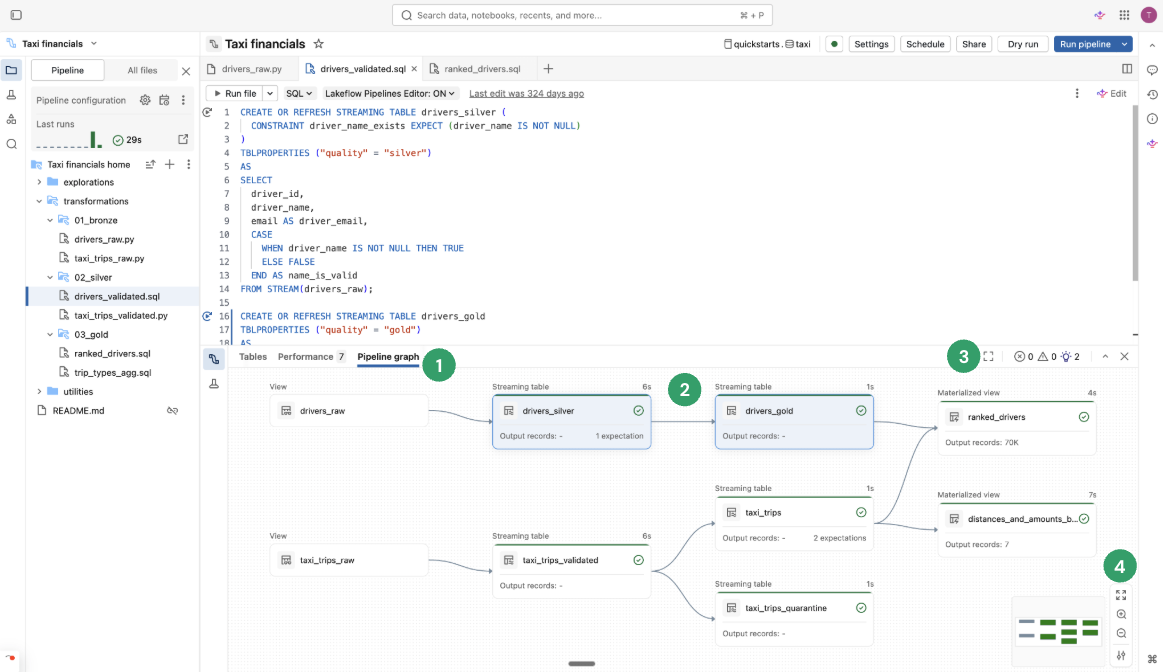
Вы можете включать и выключать график, щелкнув по значку графика в правой панели. Вы также можете увеличить граф. В правом нижнем углу есть дополнительные параметры, включая параметры ![]() Дополнительные параметры для отображения графа в вертикальном или горизонтальном макете.
Дополнительные параметры для отображения графа в вертикальном или горизонтальном макете.
При наведении указателя мыши на узел отображается панель инструментов с параметрами, включая обновление запроса. Щелкнув правой кнопкой мыши узел, вы можете выбрать те же параметры в контекстном меню.
Щелчок по узлу показывает предварительный просмотр данных и определение таблицы. При редактировании файла таблицы, определенные в этом файле, выделены в графе.
Предварительные версии данных
В разделе предварительного просмотра данных показаны примеры данных для выбранной таблицы.
Вы увидите предварительный просмотр данных таблицы при щелчке узла в направленном ациклическом графе (DAG).
Если таблица не выбрана, перейдите в раздел Таблицы и щелкните Просмотр предварительного просмотра данных![]() . Если вы выбрали таблицу, нажмите кнопку "Все таблицы ", чтобы вернуться ко всем таблицам.
. Если вы выбрали таблицу, нажмите кнопку "Все таблицы ", чтобы вернуться ко всем таблицам.
Аналитические сведения о выполнении
Вы можете просмотреть аналитические сведения о выполнении таблицы о последнем обновлении конвейера на панелях в нижней части редактора.
| Панель | Описание |
|---|---|
| Таблицы | Перечисляет все таблицы, их состояния и метрики. Если выбрать одну таблицу, вы увидите метрики и производительность для этой таблицы и вкладку для предварительного просмотра данных. |
| Производительность | Журнал запросов и профили для всех потоков в этом конвейере. Вы можете получить доступ к метрикам выполнения и подробным планам запросов во время и после выполнения. См. историю запросов Access для декларативных конвейеров Lakeflow для получения дополнительной информации. |
| Панель проблем | Щелкните панель, чтобы просмотреть упрощенное представление ошибок и предупреждений для конвейера. Вы можете щелкнуть запись, чтобы просмотреть дополнительные сведения, а затем перейти к месту в коде, где произошла ошибка. Если ошибка находится в файле, отличном от отображаемого в данный момент, вы будете перенаправлены в файл, в котором находится ошибка. Щелкните "Просмотреть сведения" , чтобы просмотреть соответствующую запись журнала событий для получения полных сведений. Щелкните Просмотреть журналы , чтобы просмотреть полный журнал событий. Индикаторы ошибок, прикрепленных к коду, отображаются для ошибок, связанных с определенной частью кода. Чтобы получить дополнительные сведения, щелкните значок ошибки или наведите указатель мыши на красную линию. Появится всплывающее окно с дополнительными сведениями. Затем можно нажать кнопку "Быстрое исправление" , чтобы выявить набор действий для устранения ошибки. |
| Журнал событий | Все события, произошедшие во время последнего запуска конвейера. Щелкните Просмотреть журналы или любую запись в панели вопросов. |
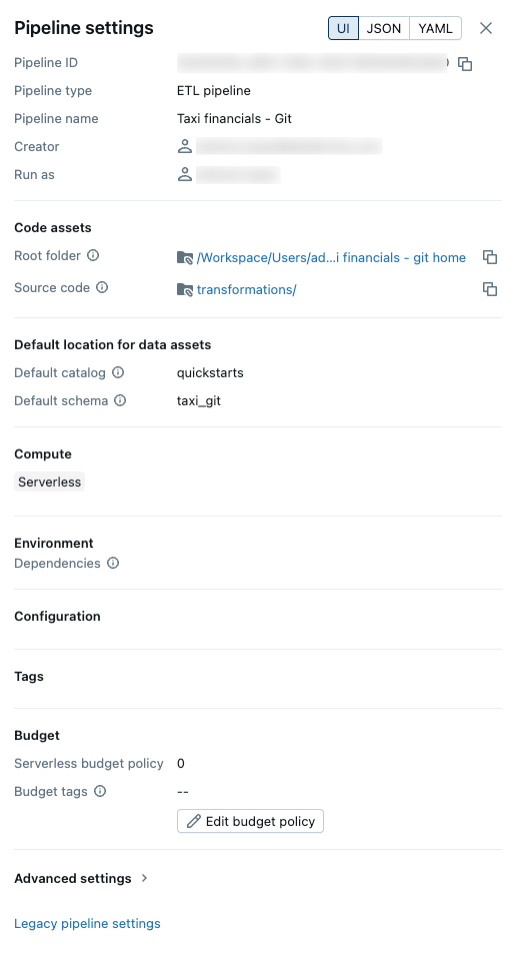
Параметры конвейера
Чтобы открыть панель настроек конвейера, щелкните «Параметры» на панели инструментов или кликните на ![]() В мини-карте браузера ресурсов конвейера.
В мини-карте браузера ресурсов конвейера.
Журнал событий
Журнал событий для конвейера недоступен, пока не настроите его в параметрах.
- Откройте раздел Параметры.
- Щелкните
 Стрелка рядом с дополнительными параметрами.
Стрелка рядом с дополнительными параметрами. - Нажмите кнопку "Изменить дополнительные параметры".
- Выберите "Опубликовать журнал событий" в хранилище метаданных.
- Укажите имя, каталог и схему для журнала событий.
- Нажмите кнопку "Сохранить".
Теперь события конвейера будут опубликованы в указанной таблице.
Окружающая среда
Вы можете создать среду для исходного кода, добавив зависимости в параметры.
- Откройте раздел Параметры.
- В разделе "Среда" щелкните "Изменить среду".
- Выберите Добавьте зависимость, чтобы добавить зависимость, как при добавлении в файл
requirements.txt. Дополнительные сведения о зависимостях см. в разделе "Добавление зависимостей в записную книжку".
Databricks рекомендует закрепить версию с помощью ==. См . пакет PyPI.
Среда применяется ко всем файлам исходного кода в конвейере.
Уведомления
Вы можете добавлять уведомления с помощью параметров конвейера прежних версий.
- Откройте раздел Параметры.
- Внизу панели параметров конвейера щелкните настройки устаревшего конвейера.
- В разделе "Уведомления" нажмите кнопку "Добавить уведомление".
- Добавьте один или несколько адресов электронной почты и укажите события, которые вы хотите отправить на эти адреса.
- Нажмите кнопку "Добавить уведомление".
Ограничения и известные проблемы
Ознакомьтесь со следующими ограничениями и известными проблемами редактора конвейеров ETL в Декларативных конвейерах Lakeflow:
Боковая панель браузера рабочей области не будет сосредоточиться на конвейере, если начать с открытия файла в
explorationsпапке или записной книжке, так как эти файлы или записные книжки не являются частью определения исходного кода конвейера.- Чтобы ввести режим фокусировки конвейера в браузере рабочей области, откройте файл, связанный с конвейером.
Предварительные версии данных не поддерживаются для обычных представлений.
Обновления с несколькими таблицами можно выполнять только на странице мониторинга конвейера. Используйте мини-карточку в браузере конвейера, чтобы перейти на эту страницу.
 может отображаться в неправильной позиции из-за упаковки строк в коде.
может отображаться в неправильной позиции из-за упаковки строк в коде.%pip installне поддерживается для файлов (тип ассета по умолчанию в новом редакторе). В параметрах можно добавить зависимости. См. раздел "Среда".В качестве альтернативы, можно продолжать использовать
%pip installиз записной книжки, связанной с конвейером, в определении исходного кода.
Вопросы и ответы
Почему файлы и не записные книжки используются для исходного кода?
Выполнение на основе ячеек в блокнотах несовместимо с декларативными конвейерами Lakeflow. Таким образом, нам пришлось отключить функции или изменить их поведение, что привело к путанице.
В редакторе конвейеров Lakeflow редактор файлов служит основой для передового редактора Lakeflow для декларативных конвейеров. Функции предназначены явно для декларативных конвейеров Lakeflow, таких как
, а не перегрузка знакомых функций с другим поведением.Можно ли использовать записные книжки в качестве исходного кода?
Да, вы можете. Однако некоторые функции, такие как
или файл run, не будут присутствовать.Если у вас есть существующий конвейер с использованием ноутбуков, он всё ещё будет работать в новом редакторе. Однако Databricks рекомендует переключиться на файлы для новых конвейеров данных.
Как добавить существующий код в только что созданный конвейер?
В новый конвейер можно добавить существующие файлы исходного кода. Чтобы добавить папку с существующими файлами, выполните следующие действия.
- Нажмите кнопку "Параметры".
- В разделе "Исходный код" щелкните "Настройка путей".
- Щелкните "Добавить путь " и выберите папку для существующих файлов.
- Нажмите кнопку "Сохранить".
Вы также можете добавить отдельные файлы:
- Щелкните Все файлы в браузере активов конвейера.
- Перейдите к файлу, щелкните нажмите кнопку "Включить в конвейер".
Рассмотрите возможность перемещения этих файлов в корневую папку конвейера. Если они находятся вне корневой папки конвейера, они будут отображаться в разделе "Внешние файлы ".
Можно ли управлять исходным кодом конвейера в Git?
Вы можете управлять источником конвейера в Git, выбрав папку Git при первоначальном создании конвейера. После создания конвейера без управления версиями можно переместить источник в папку Git. Databricks рекомендует использовать действие редактора для перемещения всей корневой папки в папку Git. Это приведет к обновлению всех параметров соответствующим образом. См. корневую папку.
Чтобы переместить корневую папку в папку Git в обозревателе ресурсов конвейера:
- Щелкните .
- Щелкните Переместить корневую папку.
- Выберите новое расположение корневой папки и нажмите кнопку "Переместить".
Дополнительные сведения см. в разделе "Корневая папка ".
После перемещения вы увидите знакомый значок Git рядом с именем корневой папки.
Это важно
Чтобы переместить корневую папку конвейера, используйте браузер ресурсов конвейера и описанные выше действия. Перемещение его любым другим способом приведет к разрыву конфигураций конвейера и необходимо вручную настроить правильный путь к папке в параметрах.
- Щелкните
Можно ли использовать несколько конвейеров в одной корневой папке?
Вы можете, но Databricks рекомендует только один конвейер для каждой корневой папки.
Когда следует запустить тестовый запуск?
Нажмите кнопку "Сухой запуск" , чтобы проверить код, не обновляя таблицы.
Когда следует использовать временные представления и когда следует использовать материализованные представления в коде?
Используйте временные представления, если вы не хотите материализовать данные. Например, это шаг в последовательности шагов по подготовке данных, прежде чем он готов к материализации с помощью потоковой таблицы или материализованного представления, зарегистрированного в каталоге.