Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Создайте агент ИИ и разверните его с помощью Databricks Apps. Databricks Apps обеспечивает полный контроль над кодом агента, конфигурацией сервера и рабочим процессом развертывания. Этот подход идеально подходит, если требуется настраиваемое поведение сервера, версии на основе Git или локальная среда разработки.
Подсказка
Если ваш агент использует только средства, размещённые в Azure Databricks, и ему не требуется пользовательская логика между вызовами инструментов, можно использовать API Supervisor (бета-версия), чтобы Azure Databricks управлял циклом агента.
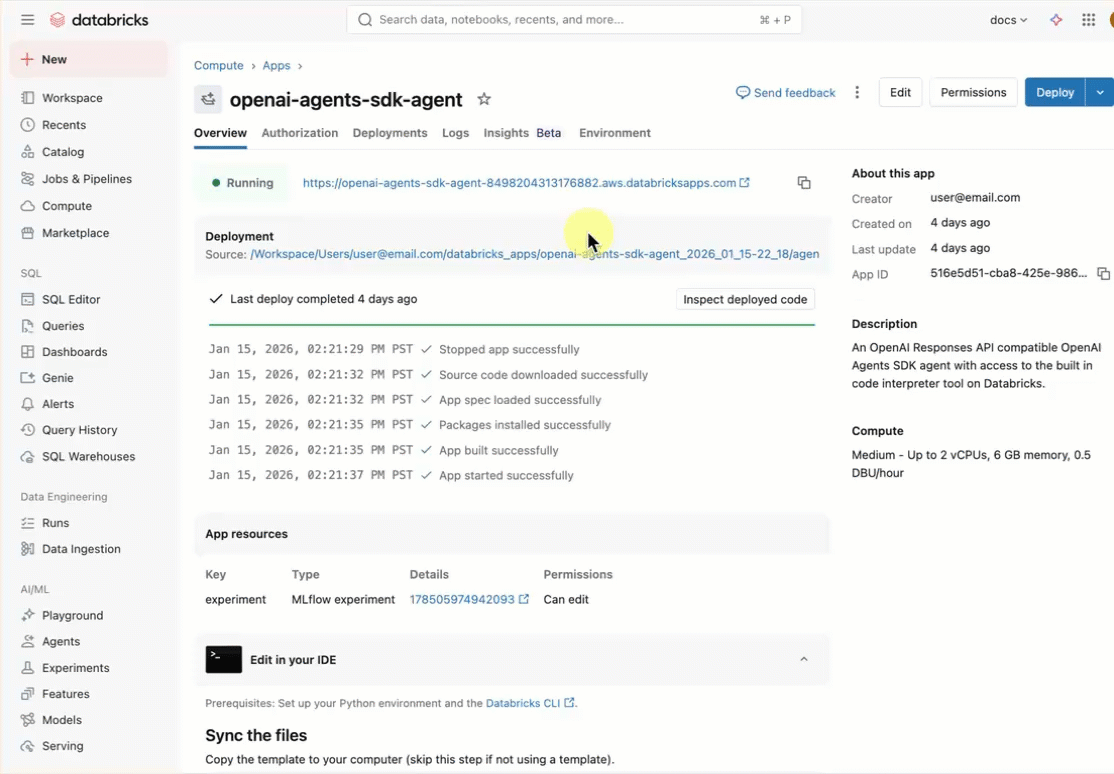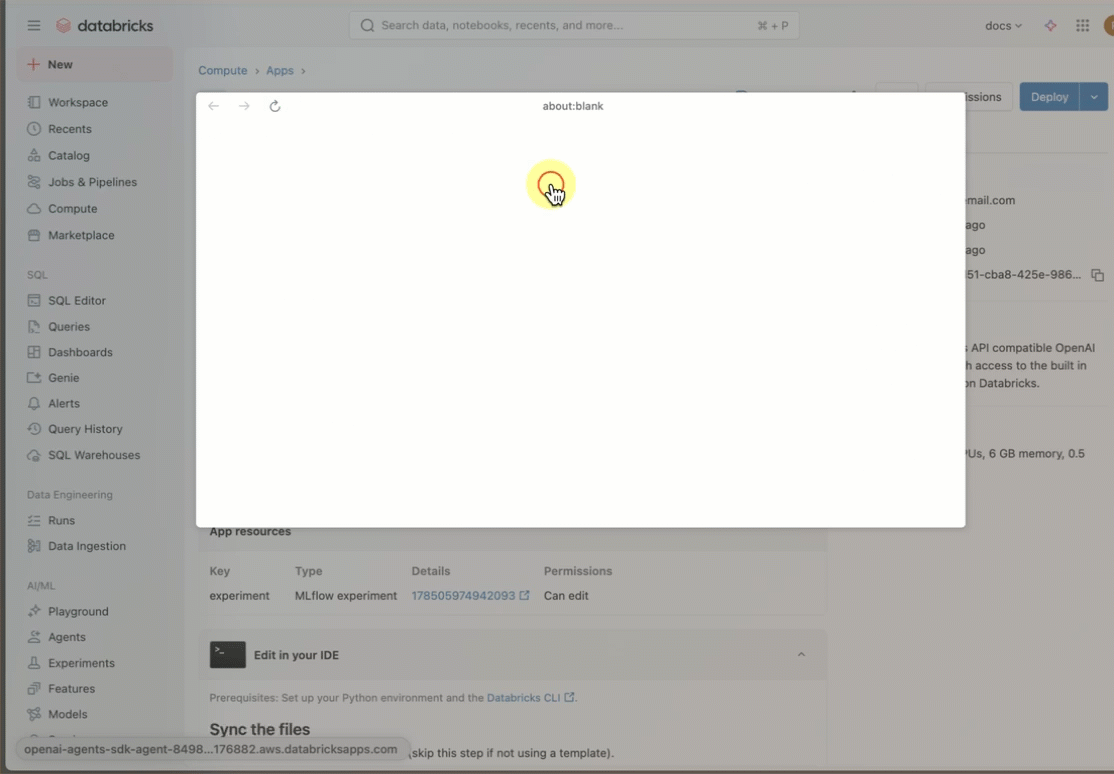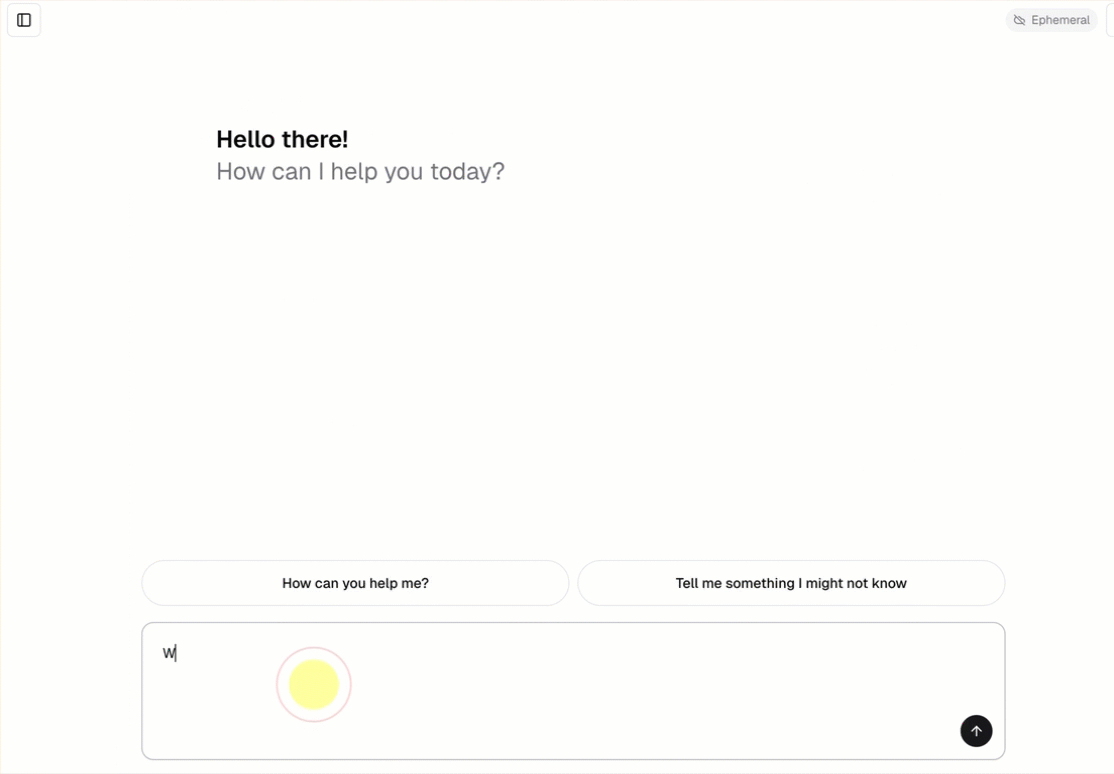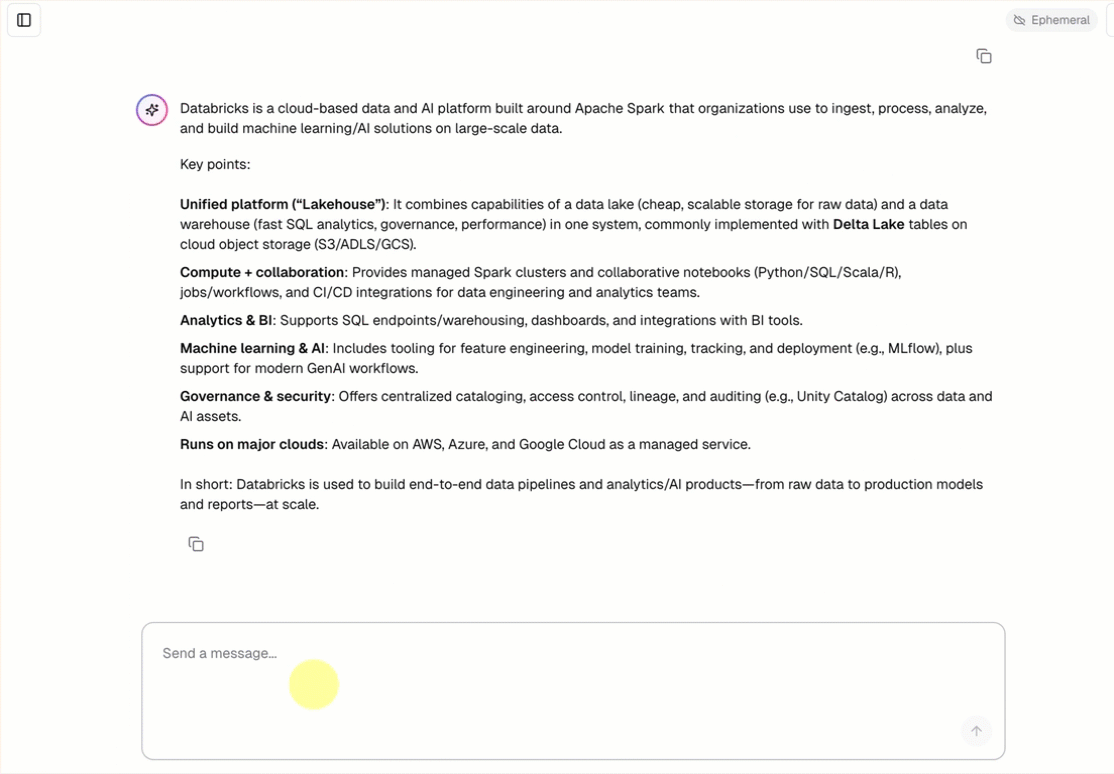
Каждый шаблон разговорного агента включает встроенный пользовательский интерфейс чата (показан выше) без необходимости дополнительной настройки. Пользовательский интерфейс чата поддерживает потоковые ответы, рендеринг markdown, аутентификацию Databricks и необязательное сохранение истории чата.
Требования
Включите Приложения Databricks в рабочей области. См. статью "Настройка рабочей области Databricks Apps" и среды разработки.
Шаг 1. Клонирование шаблона приложения агента
Начните с использования готового шаблона агента из репозитория шаблонов приложений Databricks.
В этом руководстве используется шаблон agent-openai-agents-sdk, который включает:
- Агент, созданный с помощью пакета SDK агента OpenAI
- Стартовый код для приложения агента с REST API для общения и интерактивного интерфейса чата
- Код для оценки агента с помощью MLflow
Выберите один из следующих путей для настройки шаблона:
Пользовательский интерфейс рабочей области
Установите шаблон приложения с помощью пользовательского интерфейса рабочей области. Это устанавливает приложение и развертывает его в вычислительном ресурсе в рабочей области. Затем вы можете синхронизировать файлы приложений с локальной средой для дальнейшего развития.
В рабочей области Databricks нажмите кнопку +Создать>приложение.
Щелкните Агенты>Agent - OpenAI Agents SDK.
Создайте новый эксперимент MLflow с именем
openai-agents-templateи завершите оставшуюся часть настройки для установки шаблона.После создания приложения щелкните URL-адрес приложения, чтобы открыть пользовательский интерфейс чата.
После создания приложения скачайте исходный код на локальный компьютер, чтобы настроить его:
Скопируйте первую команду в разделе "Синхронизация файлов"

В локальном терминале выполните скопированную команду.
Клонирование из GitHub
Чтобы начать работу с локальной среды, клонируйте репозиторий agent-openai-agents-sdk шаблонов агента и откройте каталог:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Шаг 2. Понять приложение агента
Шаблон агента демонстрирует рабочую архитектуру с этими ключевыми компонентами. Дополнительные сведения о каждом компоненте см. в следующих разделах:

Дополнительные сведения о каждом компоненте см. в следующих разделах:
 Встроенный пользовательский интерфейс чата
Встроенный пользовательский интерфейс чата
Шаблон агента автоматически извлекает и запускает шаблон приложения чата в качестве внешнего интерфейса. Этот интерфейс чата упакован в то же развертывание приложений Databricks и обслуживается вместе с вашим агентом, поэтому дополнительная настройка не требуется.
Пользовательский интерфейс чата можно настроить непосредственно в проекте. Дополнительные сведения о функциях приложения чата, в том числе о том, как включить журнал сохраняемых чатов и сбор отзывов пользователей, см. в статье "Создание и предоставление общего доступа к пользовательскому интерфейсу чата с помощью Приложений Databricks".
 MLflow AgentServer
MLflow AgentServer
Асинхронный сервер FastAPI, обрабатывающий запросы агента со встроенной трассировкой и наблюдаемостью.
AgentServer предоставляет конечную точку /invocations для запроса агента и автоматически управляет маршрутизацией запросов, ведением журнала и обработкой ошибок.

ResponsesAgent Интерфейс
Databricks рекомендует использовать MLflow ResponsesAgent для создания агентов.
ResponsesAgent позволяет создавать агенты с любой сторонней платформой, а затем интегрировать ее с функциями ИИ Databricks для надежного ведения журнала, трассировки, оценки, развертывания и мониторинга.

См. примеры по созданию ResponsesAgent в документации MLflow — ResponsesAgent для обслуживания моделей.
ResponsesAgent предоставляет следующие преимущества:
Расширенные возможности агента
- Поддержка нескольких агентов
- Потоковая передача выходных данных: передавайте выходные данные небольшими блоками.
- Подробная история сообщений вызова инструментов: Возвращает несколько сообщений, включая промежуточные сообщения вызова инструментов, для повышения качества и более эффективного управления диалогами.
- Поддержка подтверждения активации инструмента
- Поддержка долговременно работающего инструмента
Оптимизация разработки, развертывания и мониторинга
-
Создание агентов с помощью любой платформы: обертывание любого существующего агента с помощью
ResponsesAgentинтерфейса для обеспечения совместимости с ИИ-площадкой, оценкой агента и мониторингом агентов. - Интерфейсы разработки с типизацией: создание кода агента с использованием типизированных классов Python, что позволяет использовать преимущества автозаполнения в записных книжках и интегрированной среды разработки.
- Автоматическая трассировка: MLflow автоматически агрегирует потоковые ответы в трассировках для упрощения оценки и отображения.
-
Совместимо со схемой OpenAI
Responses: См. OpenAI: Ответы против ChatCompletion.
-
Создание агентов с помощью любой платформы: обертывание любого существующего агента с помощью
 Пакет SDK для агентов OpenAI
Пакет SDK для агентов OpenAI
Шаблон использует пакет SDK для агентов OpenAI в качестве фреймворка агентов для управления беседами и управления инструментами. Вы можете создавать агенты с помощью любой платформы. Ключ заключается в обёртывании вашего агента с помощью интерфейса MLflow ResponsesAgent.
 Серверы MCP (протокол контекста модели)
Серверы MCP (протокол контекста модели)
Шаблон подключается к серверам Databricks MCP, чтобы предоставить агентам доступ к средствам и источникам данных. См. протокол контекста модели (MCP) в Databricks.
Создание агентов с помощью помощников по написанию кода ИИ
Databricks рекомендует использовать помощников по программированию на основе ИИ, таких как Claude, Cursor и Copilot, для создания агентов. Используйте предоставленные навыки агента и /.claude/skillsAGENTS.md файл, чтобы помочь помощникам ИИ понять структуру проекта, доступные инструменты и рекомендации. Агенты могут автоматически считывать эти файлы для разработки и развертывания приложений Databricks.
Шаг 3. Добавьте инструменты вашему агенту
Предоставьте своим агентам такие возможности, как запросы к базам данных, поиск документов или вызов внешних API путем подключения к серверам MCP. Шаблон агента включает подключение сервера MCP по умолчанию. Чтобы добавить дополнительные средства, настройте дополнительные серверы MCP в коде агента и предоставьте необходимые разрешения.databricks.yml
Ознакомьтесь с инструментами агента ИИ для поддерживаемых типов инструментов и примеров кода.
Определите инструменты локальной функции Python
Для операций, не требующих внешних источников данных или API, определите средства непосредственно в коде агента. Эти инструменты выполняются в том же процессе, что и агент, и полезны для преобразований данных, вычислений или вспомогательных операций.
Пакет SDK для агентов OpenAI
@function_tool Используйте декоратор из пакета SDK для агентов OpenAI:
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
LangGraph
Используйте декоратор @tool из LangChain.
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
Локальные средства функций не требуют предоставления ресурсов, databricks.yml так как они выполняются в процессе агента.
Разделы расширенной разработки
Потоковая передача ответов
Потоковая передача ответов
Потоковая передача позволяет агентам отправлять ответы в блоках в режиме реального времени вместо ожидания полного ответа. Чтобы реализовать потоковую передачу данных с помощью ResponsesAgent, выведите ряд разностных событий, за которым следует окончательное событие завершения.
-
Отправка разностных событий: отправка нескольких
output_text.deltaсобытий с одинаковымиitem_idдля потоковой передачи фрагментов текста в режиме реального времени. -
Завершите с событием "done": отправьте финальное
response.output_item.doneсобытие с тем жеitem_id, что и разностные события, содержащие полный итоговый выходной текст.
Каждое разностное событие передает фрагмент текста клиенту. Последнее готовое событие содержит полный текст ответа и сигнал Databricks выполнить следующее:
- Отслеживайте выходные данные агента с помощью трассировки MLflow
- Агрегированные потоковые ответы в таблицах вывода шлюза искусственного интеллекта
- Отображение полных выходных данных в пользовательском интерфейсе игровой площадки ИИ
Распространение ошибок потоковой передачи
Mosaic AI распространяет все ошибки, возникающие при потоковой передаче, с последним токеном под databricks_output.error. Ответственность за правильную обработку и отображение этой ошибки лежит на вызывающем клиенте.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Пользовательские входные и выходные данные
Пользовательские входные и выходные данные
В некоторых сценариях могут потребоваться дополнительные данные агента, такие как client_type, или выходные данные, такие как ссылки на источник извлечения session_id, которые не должны быть включены в журнал чата для будущих взаимодействий.
В этих сценариях MLflow ResponsesAgent изначально поддерживает поля custom_inputs и custom_outputs. Вы можете получить доступ к пользовательским входным данным в приведенных выше примерах платформы с помощью request.custom_inputs.
Приложение для оценки агента не поддерживает создание трассировок для агентов с дополнительными полями ввода.
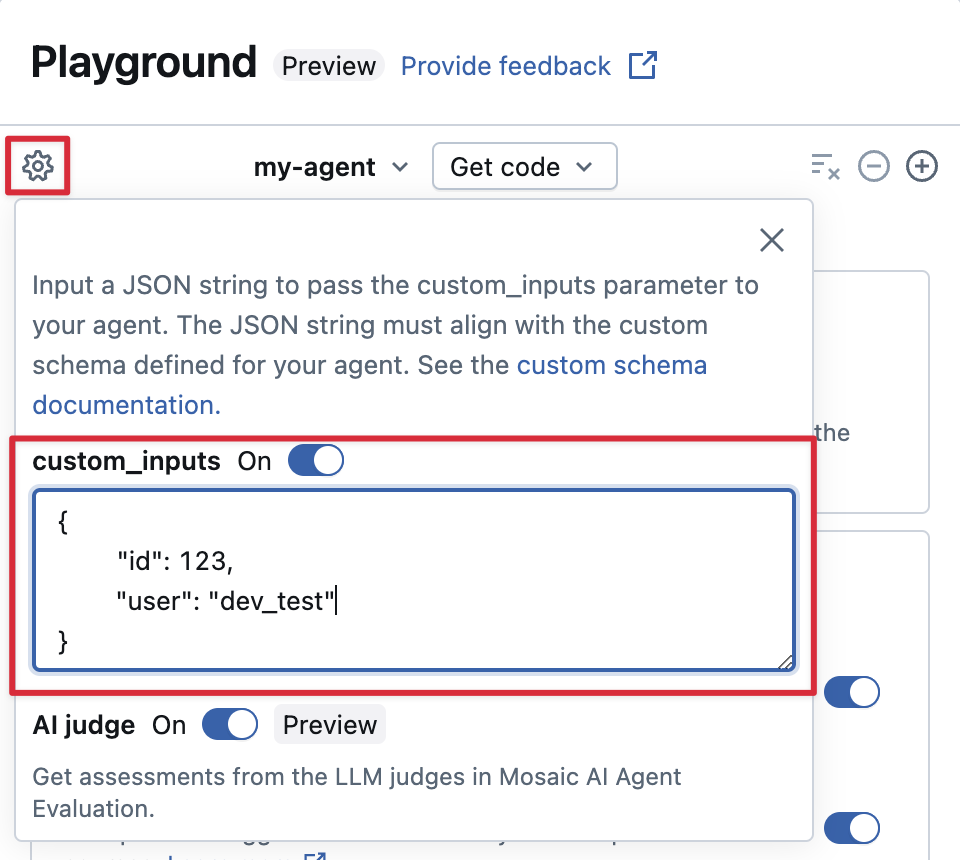
Предоставьте custom_inputs в приложении "Игровая площадка ИИ" и в приложении для обзора
Если агент принимает дополнительные входные данные с помощью custom_inputs поля, вы можете вручную указать эти входные данные как в игровой площадке ИИ , так и в приложении проверки.
На игровой площадке ИИ или в приложении проверки агента выберите

Включите custom_inputs.
Укажите объект JSON, соответствующий определенной схеме входных данных агента.
Пользовательские схемы извлекателя
Пользовательские схемы извлекателя
Агенты ИИ обычно используют средства извлечения для поиска и запроса неструктурированных данных из индексов векторного поиска. Например, средства извлечения см. в разделе "Подключение агентов к неструктурированным данным".
Отслеживайте этих ретриверов с помощью вашего агента, используя интервалы MLflow RETRIEVER, чтобы задействовать функции продукта Databricks, такие как:
- Автоматическое отображение ссылок на извлеченные исходные документы в пользовательском интерфейсе игровой площадки ИИ
- Автоматическое выполнение оценки обоснованности и релевантности в системе оценки агентов
Заметка
Databricks рекомендует использовать средства извлечения, предоставляемые пакетами Databricks AI Bridge, такими как databricks_langchain.VectorSearchRetrieverTool и databricks_openai.VectorSearchRetrieverTool, так как они уже соответствуют схеме извлекателя MLflow. См. статью "Разработка средства извлечения локально с помощью AI Bridge".
Если агент включает диапазоны извлекателя с пользовательской схемой, вызовите mlflow.models.set_retriever_schema при определении агента в коде. Это сопоставляет выходные столбцы извлекателя с ожидаемыми полями MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: The Largest Open Source AI Engineering Platform'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Заметка
Столбец doc_uri особенно важен при оценке производительности извлекателя.
doc_uri — это основной идентификатор документов, возвращаемых извлекателем, позволяющий сравнивать их с эталонными оценочными наборами данных. См. раздел "Оценочные наборы" (MLflow 2).
Шаг 4. Локальное запуск приложения агента
Настройте локальную среду:
Установите
uv(диспетчер пакетов Python),nvm(диспетчер версий узла) и cli Databricks:-
uvУстановка -
nvmУстановка - Выполните следующую команду, чтобы использовать узел 20 LTS:
nvm use 20 -
databricks CLIУстановка
-
Измените каталог на папку
agent-openai-agents-sdk.Запустите предоставленные скрипты быстрого запуска, чтобы установить зависимости, настроить среду и запустить приложение.
uv run quickstart uv run start-app
В браузере перейдите на http://localhost:8000, чтобы открыть встроенный интерфейс чата и начать чат с агентом.
Шаг 5. Настройка проверки подлинности
Агенту требуется проверка подлинности для доступа к ресурсам Azure Databricks. Databricks Apps предоставляет два метода проверки подлинности: авторизация приложений (субъект-служба) и авторизация пользователей (от имени пользователя). Вы можете настроить любой из них через пользовательский интерфейс рабочей области или декларативно в databricks.yml с помощью пакетов декларативной автоматизации. Шаблоны агентов поставляются с databricks.yml, так что этот путь используется по умолчанию при запуске от шаблона.
Полный справочник, включая все поддерживаемые типы ресурсов, значения разрешений и сквозное databricks.yml пошаговое руководство, см. в разделе "Проверка подлинности для агентов ИИ".
Авторизация приложений (по умолчанию)
Авторизация приложения использует служебный принципал, который Azure Databricks автоматически создает для вашего приложения. Все пользователи имеют одинаковые разрешения.
Вариант 1. Пользовательский интерфейс рабочей области
- Щелкните "Изменить" на домашней странице приложения.
- Перейдите к шагу "Настройка ".
- В разделе "Ресурсы приложения" добавьте ресурс эксперимента MLflow с разрешением
Can Edit. - Для других ресурсов (индексы векторного поиска, пространства Genie, обслуживающие конечные точки, хранилища SQL, функции каталога Unity, Lakebase), нажмите кнопку +Добавить ресурс и задайте каждое разрешение.
Вариант 2. Декларативные пакеты автоматизации
Объявите каждый ресурс, который агент использует в resources.apps.<app>.resourcesdatabricks.yml. Разверните пакет, чтобы предоставить субъекту-службе объявленные разрешения:
resources:
apps:
my_agent:
name: 'my-agent'
source_code_path: ./
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run my_agent
Полный список типов ресурсов см. в разделе "Авторизация приложений".
Авторизация пользователей
Авторизация пользователя позволяет агенту действовать с отдельными разрешениями каждого пользователя. Используйте это, если требуется управление доступом на уровне пользователей или аудиторские журналы.
Добавьте этот код в агент:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Important
Инициализируйте get_user_workspace_client() внутри ваших функций @invoke или @stream, а не во время запуска приложения. Учетные данные пользователя существуют только при обработке запроса.
Настройте, какие api-интерфейсы Azure Databricks агент может вызывать от имени пользователя, объявляя области.
Вариант 1. Пользовательский интерфейс рабочей области
- В пользовательском интерфейсе Azure Databricks перейдите к настройкам Авторизация.
- В разделе "Авторизация пользователя" нажмите кнопку +Добавить область и выберите области.
- Сохраните и перезапустите приложение.
Вариант 2. Декларативные пакеты автоматизации
Добавьте области доступа в приложении в databricks.yml:
resources:
apps:
my_agent:
name: 'my-agent'
source_code_path: ./
user_api_scopes:
- sql
- dashboards.genie
- serving.serving-endpoints
databricks bundle deploy
databricks bundle run my_agent
Список доступных областей и полные инструкции по настройке см. в разделе "Авторизация пользователей".
Шаг 6. Оценка агента
Шаблон содержит код оценки агента. См. agent_server/evaluate_agent.py для получения дополнительной информации. Оцените релевантность и безопасность ответов агента, выполнив следующие действия в терминале:
uv run agent-evaluate
Шаг 7. Разверните агента в приложениях Databricks
После настройки проверки подлинности разверните агент в Databricks. Убедитесь, что у вас установлен и настроен интерфейс командной строки Databricks .
Если вы клонировали репозиторий локально, создайте приложение Databricks перед его развертыванием. Если вы создали приложение с помощью пользовательского интерфейса рабочей области, пропустите этот шаг, так как приложение и эксперимент MLflow уже настроены.
databricks apps create agent-openai-agents-sdkСинхронизация локальных файлов с рабочей областью. См . статью "Развертывание приложения".
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"Разверните приложение Databricks.
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
Для всех будущих обновлений агента продолжайте его синхронизацию и повторное развертывание.
Шаг 8. Запрос развернутого агента
В следующем примере используется быстрый curl запрос с маркером OAuth. Персональные токены доступа (PATs) не поддерживаются для приложений Databricks.
Полный список методов запроса, включая клиент Databricks OpenAI и REST API, см. раздел Запросите агента, развернутого на Azure Databricks.
Создайте маркер OAuth с помощью интерфейса командной строки Databricks:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Используйте маркер для запроса агента:
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Ограничения
- Поддерживаются только средние и большие размеры вычислений. См. Настройка вычислительных ресурсов для приложения Databricks.
- В настоящее время пользовательский интерфейс чата проверки MLflow не поддерживает агенты, развернутые в приложениях Databricks. Чтобы оценить существующие трассировки, используйте сеансы маркировки, которые работают независимо от метода развертывания. Databricks создает поддержку отзывов и обратной связи прямо в шаблон чат-бота.