Что такое озера данных?
Озеро данных — это система управления данными, которая объединяет преимущества озер данных и хранилищ данных. В этой статье описывается шаблон архитектуры Lakehouse и то, что можно сделать с ним в Azure Databricks.
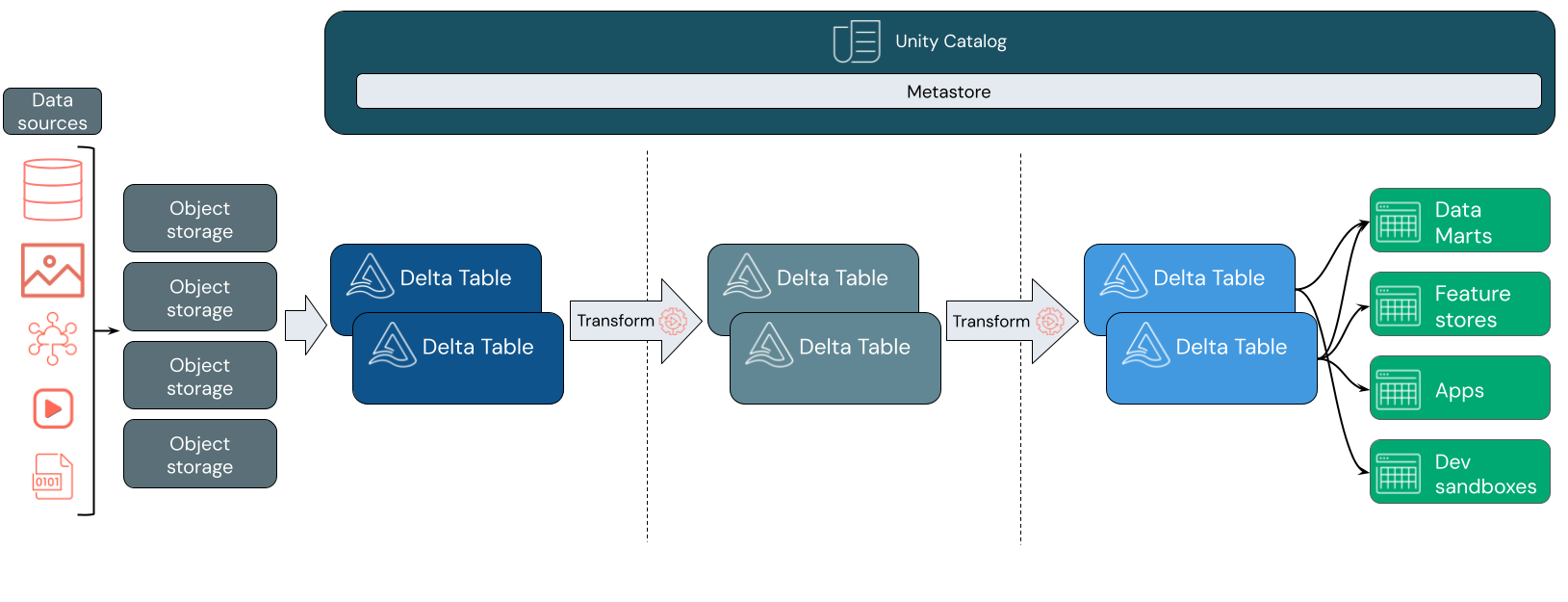
Что используется для озера данных?
Озера данных предоставляют масштабируемые возможности хранения и обработки для современных организаций, которые хотят избежать изолированных систем для обработки различных рабочих нагрузок, таких как машинное обучение (ML) и бизнес-аналитика (BI). Озеро данных может помочь установить один источник истины, исключить избыточные затраты и обеспечить свежесть данных.
Озера данных часто используют шаблон конструктора данных, который постепенно улучшает, обогащает и обновляет данные по мере перемещения по слоям промежуточного и преобразования. Каждый слой озера может включать один или несколько слоев. Этот шаблон часто называется архитектурой медальона. Дополнительные сведения см. в статье "Что такое архитектура медальона lakehouse?"
Как работает Databricks lakehouse?
Databricks основан на Apache Spark. Apache Spark включает масштабируемый модуль, работающий на вычислительных ресурсах, отложенных от хранилища. Дополнительные сведения см. в статье Apache Spark в Azure Databricks
Databricks lakehouse использует две дополнительные ключевые технологии:
- Delta Lake: оптимизированный уровень хранения, поддерживающий транзакции ACID и принудительное применение схемы.
- Каталог Unity: унифицированное, точное решение для управления данными и искусственным интеллектом.
Прием данных
На уровне приема пакетная или потоковая передача данных поступает из различных источников и в различных форматах. Этот первый логический слой предоставляет место для того, чтобы данные приземлились в его необработанном формате. При преобразовании этих файлов в таблицы Delta можно использовать возможности применения схемы Delta Lake для проверка для отсутствующих или непредвиденных данных. Каталог Unity можно использовать для регистрации таблиц в соответствии с моделью управления данными и необходимыми границами изоляции данных. Каталог Unity позволяет отслеживать происхождение данных по мере преобразования и усовершенствования, а также применять единую модель управления для обеспечения конфиденциальности конфиденциальных данных и безопасности.
Обработка данных, курирование и интеграция
После проверки можно начать курирование и уточнение данных. Специалисты по обработке и анализу данных и специалисты по машинному обучению часто работают с данными на этом этапе, чтобы начать объединение или создание новых функций и завершить очистку данных. После тщательного очистки данных его можно интегрировать и реорганизовать в таблицы, предназначенные для удовлетворения конкретных бизнес-потребностей.
Подход для записи схемы, в сочетании с возможностями эволюции схемы Delta, означает, что вы можете вносить изменения в этот слой без необходимости переписать нижестоящую логику, которая служит данным для конечных пользователей.
Обслуживание данных
Последний слой служит чистым, обогащенным данным для конечных пользователей. Окончательные таблицы должны использоваться для обслуживания данных для всех вариантов использования. Единая модель управления означает, что вы можете отслеживать происхождение данных в один источник истины. Макеты данных, оптимизированные для различных задач, позволяют конечным пользователям получать доступ к данным для приложений машинного обучения, инженерии данных и бизнес-аналитики и отчетности.
Дополнительные сведения о Delta Lake см. в статье "Что такое Delta Lake?" Дополнительные сведения о каталоге Unity см. в статье "Что такое каталог Unity?"
Возможности Озера Databricks
Lakehouse, построенный на Databricks, заменяет текущую зависимость от озер данных и хранилищ данных для современных компаний данных. Некоторые ключевые задачи, которые можно выполнить, включают:
- Обработка данных в режиме реального времени: обработка потоковых данных в режиме реального времени для немедленного анализа и действий.
- Интеграция данных: объединяйте данные в одной системе, чтобы обеспечить совместную работу и установить единый источник истины для вашей организации.
- Эволюция схемы. Изменение схемы с течением времени для адаптации к изменению бизнес-потребностей без нарушения существующих конвейеров данных.
- Преобразования данных. Использование Apache Spark и Delta Lake обеспечивает скорость, масштабируемость и надежность данных.
- Анализ данных и отчеты. Выполнение сложных аналитических запросов с подсистемой, оптимизированной для рабочих нагрузок хранения данных.
- Машинное обучение и ИИ. Применение методов расширенной аналитики ко всем данным. Используйте машинное обучение для обогащения данных и поддержки других рабочих нагрузок.
- Управление версиями данных и происхождение данных: обслуживание журнала версий для наборов данных и отслеживания происхождения данных, чтобы обеспечить наличие и трассировку данных.
- Управление данными. Используйте единую систему для управления доступом к данным и выполнения аудита.
- Общий доступ к данным: упрощение совместной работы путем предоставления общего доступа к курируемым наборам данных, отчетам и аналитическим сведениям между командами.
- Операционная аналитика: мониторинг метрик качества данных, метрик качества модели и смещения путем применения машинного обучения к данным мониторинга Lakehouse.
Lakehouse и Data Lake и хранилище данных
Хранилища данных имеют решения бизнес-аналитики (BI) около 30 лет, развиваясь как набор рекомендаций по проектированию систем, управляющих потоком данных. Корпоративные хранилища данных оптимизируют запросы для отчетов бизнес-аналитики, но могут занять несколько минут или даже часов, чтобы создать результаты. Разработанные для данных, которые вряд ли будут изменяться с высокой частотой, хранилища данных стремятся предотвратить конфликты между одновременно выполняемыми запросами. Многие хранилища данных основаны на защищаемых форматах, которые часто ограничивают поддержку машинного обучения. Хранилище данных в Azure Databricks использует возможности Databricks lakehouse и Databricks SQL. Дополнительные сведения см. в статье "Что такое хранилище данных в Azure Databricks?".
Благодаря технологическим достижениям в области хранения данных и экспоненциальному увеличению типов и объемов данных озера данных получили широкое распространение за последнее десятилетие. Озера данных хранят и обрабатывают данные экономично и эффективно. Озера данных часто противопоставляются хранилищам данных: хранилище данных предоставляет чистые, структурированные данные для аналитики бизнес-аналитики, в то время как озеро данных постоянно и экономично хранит данные любого характера в любом формате. Многие организации используют озера данных для обработки и анализа данных и машинного обучения, но не для отчетов BI из-за их непроверяемого характера.
Хранилище озера данных объединяет преимущества озер данных и хранилищ данных и предоставляет следующие возможности:
- Открытый прямой доступ к данным, хранящимся в стандартных форматах данных.
- Протоколы индексирования, оптимизированные для машинного обучения и обработки данных.
- Низкая задержка запросов и высокая надежность для бизнес-аналитики и расширенной аналитики.
Объединение оптимизированного слоя метаданных с проверенными данными, хранящимися в стандартных форматах в облачном хранилище объектов, data lakehouse позволяет специалистам по обработке и анализу данных создавать модели из одних и того же отчета бизнес-аналитики, управляемого данными.
Следующий шаг
Дополнительные сведения о принципах и рекомендациях по реализации и эксплуатации озера с помощью Databricks см. в статье "Общие сведения о хорошо архитекторе озера данных"