Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Конвейеры Lakeflow представляют несколько новых конструкций кода Python для определения материализованных представлений и потоковых таблиц в конвейерах. Поддержка Python для разработки конвейеров основана на основах API PySpark DataFrame и Структурированной потоковой передачи.
Для пользователей, незнакомых с Python и DataFrames, Databricks рекомендует использовать интерфейс SQL. См. раздел "Разработка кода конвейеров Lakeflow с помощью SQL". Сведения о выборе между двумя интерфейсами см. в разделе "Выбор между SQL и Python".
Полное справочное руководство по синтаксису Python для конвейеров Lakeflow см. в разделе Справочник по языку Python для конвейеров Lakeflow.
Основы Python для разработки конвейеров
Код Python, создающий наборы данных для конвейера, должен возвращать объекты DataFrame.
Все API Python для конвейеров Lakeflow реализованы в модуле pyspark.pipelines. Код конвейера, реализованный с помощью Python, должен явно импортировать pipelines модуль в верхней части источника Python. В наших примерах мы используем следующую команду импорта и используем dp в примерах для ссылки pipelines.
from pyspark import pipelines as dp
Замечание
Apache Spark™ включает декларативные конвейеры , начиная с Spark 4.1, доступные pyspark.pipelines через модуль. Среда выполнения Databricks расширяет эти возможности с открытым исходным кодом с помощью дополнительных API и интеграции для управляемого рабочего использования.
Код, написанный с помощью модуля с открытым исходным кодом pipelines , выполняется без изменений в Azure Databricks. Следующие функции не являются частью Apache Spark:
dp.create_auto_cdc_flowdp.create_auto_cdc_from_snapshot_flow@dp.expect(...)
Конвейер считывает и записывает данные по умолчанию в каталог и схему, указанную во время настройки конвейера. См. Задайте целевой каталог и схему.
Код Python для конкретного конвейера отличается от других типов кода Python одним критическим образом: код конвейера Python не вызывает функции, которые выполняют прием данных и преобразование для создания наборов данных. Вместо этого конвейеры Lakeflow интерпретируют функции-декораторы из модуля dp во всех файлах исходного кода, настроенных для конвейера, и строят граф потоков данных.
Это важно
Чтобы избежать непредвиденного поведения при запуске конвейера, не включайте код, который может иметь побочные эффекты в функциях, определяющих наборы данных. Чтобы узнать больше, смотрите справочник Python.
Создание материализованного представления или потоковой таблицы с помощью Python
Используйте @dp.table для создания таблицы потоковой передачи из результатов потокового чтения. Используйте @dp.materialized_view для создания материализованного представления из результатов пакетного чтения.
По умолчанию материализованное представление и имена потоковой таблицы выводятся из имен функций. В следующем примере кода показан базовый синтаксис для создания материализованного представления и потоковой таблицы:
Замечание
Обе функции ссылаются на одну и ту же таблицу в каталоге samples и используют одну и ту же функцию-декоратор. В этих примерах подчеркивается, что единственное различие в базовом синтаксисе для материализованных представлений и потоковых таблиц заключается в использовании spark.read вместо spark.readStream.
Не все источники данных поддерживают потоковое чтение. Некоторые источники данных всегда должны обрабатываться с семантикой потоковой передачи.
from pyspark import pipelines as dp
@dp.materialized_view()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
При необходимости можно указать имя таблицы с помощью аргумента name в декораторе @dp.table. В следующем примере показан этот шаблон для материализованного представления и потоковой таблицы:
from pyspark import pipelines as dp
@dp.materialized_view(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Загрузка данных из хранилища объектов
Конвейеры поддерживают загрузку данных из всех форматов, поддерживаемых Azure Databricks. См. параметры формата данных .
Замечание
В этих примерах используются данные, доступные на /databricks-datasets, автоматически подключённые к вашей рабочей области. Databricks рекомендует использовать пути тома или облачные URI для ссылки на данные, хранящиеся в облачном хранилище объектов. См. статью Что такое тома каталога Unity?.
Databricks рекомендует использовать автозагрузчик и потоковые таблицы при настройке добавочных рабочих нагрузок приема данных, хранящихся в облачном хранилище объектов. См. раздел "Что такое автозагрузчик?".
В следующем примере создается потоковая таблица из JSON-файлов с помощью автозагрузчика:
from pyspark import pipelines as dp
@dp.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
В следующем примере используется пакетная семантика для чтения каталога JSON и создания материализованного представления:
from pyspark import pipelines as dp
@dp.materialized_view()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Проверка данных с учетом ожиданий
Вы можете использовать ожидания для установки и применения ограничений качества данных. См. Управление качеством данных, используя ожидания конвейера.
Следующий код использует @dp.expect_or_drop для определения ожидания с именем valid_data, которая удаляет записи, которые являются null во время приема данных:
from pyspark import pipelines as dp
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Выполните запрос к материализованным представлениям и потоковым таблицам, которые определены в вашем конвейере
В следующем примере определяются четыре набора данных:
- Потоковая таблица с именем
orders, которая загружает данные JSON. - Материализованное представление с именем
customers, которое загружает данные CSV. - Материализованное представление с именем
customer_orders, которое объединяет записи из наборов данныхordersиcustomers, преобразует метку времени заказа в дату и выбирает поляcustomer_id,order_number,stateиorder_date. - Материализованное представление под именем
daily_orders_by_state, которое агрегирует ежедневное количество заказов для каждого штата.
Замечание
При запросе представлений или таблиц в конвейере можно указать каталог и схему напрямую или использовать значения по умолчанию, настроенные в конвейере. В этом примере таблицы orders, customersи customer_orders записываются и считываются из каталога по умолчанию и схемы, настроенной для конвейера.
Устаревший режим публикации использует схему LIVE для выполнения запросов к другим материализованным представлениям и потоковым таблицам, определенным в конвейере обработки данных. В новых конвейерах синтаксис схемы LIVE автоматически игнорируется. См. LIVE схему (устаревшую версию).
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dp.materialized_view()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dp.materialized_view()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dp.materialized_view()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Создание таблиц в цикле for
Вы можете использовать циклы Python for для создания нескольких таблиц программным способом. Это может быть полезно, если у вас есть множество источников данных или целевых наборов данных, которые зависят только от нескольких параметров, что приводит к снижению общего объема кода для поддержания и уменьшения избыточности кода.
Цикл for оценивает логику в последовательном порядке, но после завершения планирования для наборов данных конвейер выполняет логику параллельно.
Это важно
При использовании этого шаблона для определения наборов данных убедитесь, что список значений, передаваемых в цикл for, всегда является аддитивным. Если набор данных, ранее определенный в конвейере, опущен из будущего запуска конвейера, этот набор данных удаляется автоматически из целевой схемы.
В следующем примере создаются пять таблиц, которые фильтруют заказы клиентов по регионам. Здесь имя региона используется для задания имени целевых материализованных представлений и фильтрации исходных данных. Временные представления используются для определения соединений из исходных таблиц, используемых при создании окончательных материализованных представлений.
from pyspark import pipelines as dp
from pyspark.sql.functions import collect_list, col
@dp.temporary_view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dp.temporary_view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dp.materialized_view(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Ниже приведен пример графа потока данных для этого конвейера:
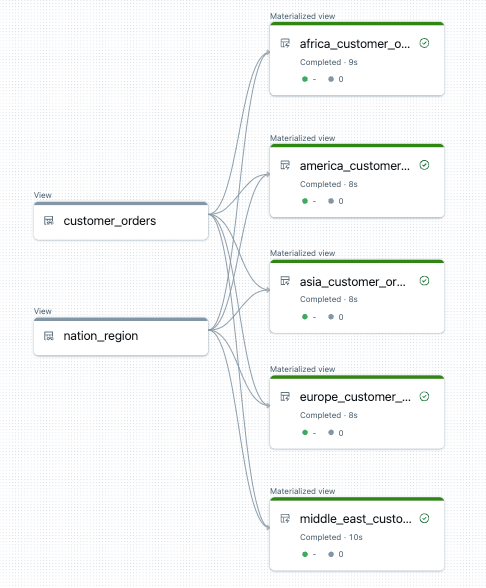
Устранение неполадок: цикл for создает множество таблиц с одинаковыми значениями
Модель отложенного выполнения, которую используют конвейеры для оценки кода Python, требует, чтобы ваша логика напрямую ссылалась на отдельные значения, когда функция, декорированная с помощью @dp.materialized_view(), вызывается.
В следующем примере демонстрируется два правильных подхода к определению таблиц с помощью цикла for. В обоих примерах каждое имя таблицы из списка tables явно упоминается в функции, аннотированной @dp.materialized_view().
from pyspark import pipelines as dp
# Create a parent function to set local variables
def create_table(table_name):
@dp.materialized_view(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dp.materialized_view()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized_view(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
В следующем примере не ссылается на ссылочные значения правильно. В этом примере создаются таблицы с отдельными именами, но все таблицы загружают данные из последнего значения в цикле for:
from pyspark import pipelines as dp
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized(name=t_name)
def create_table():
return spark.read.table(t_name)
Окончательное удаление записей из материализованного представления или потоковой таблицы
Чтобы окончательно удалить записи из материализованного представления или потоковой таблицы с включенными векторами удаления, например для соответствия GDPR, необходимо выполнить дополнительные операции в базовых таблицах Delta объекта. Чтобы обеспечить перманентное удаление записей из материализованного представления, см. удаление записей из материализованного представления с активными векторами удаления. Чтобы гарантировать удаление записей из потоковой таблицы, см. постоянное удаление записей из потоковой таблицы.