Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
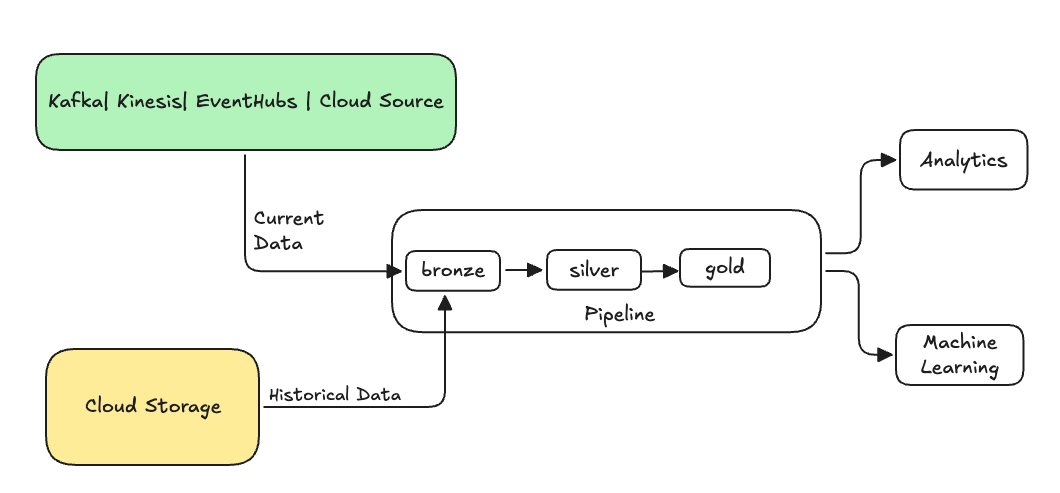
В инженерии данных обратное заполнение относится к процессу ретроспективной обработки исторических данных через конвейер данных, предназначенный для обработки текущих или потоковых данных.
Как правило, это отдельный поток отправки данных в существующие таблицы. На следующем рисунке показан поток данных для обратной записи, передающий исторические данные в бронзовые таблицы вашего конвейера.
Некоторые сценарии, для которых может потребоваться обратное заполнение:
- Обработка исторических данных из устаревшей системы для обучения модели машинного обучения или создания информационной панели анализа тенденций.
- Повторно обработайте подмножество данных из-за проблемы с качеством данных вышестоящими источниками данных.
- Ваши бизнес-требования изменились, и вам нужно заполнить данные за другой период времени, который не был охвачен первоначальным конвейером.
- Бизнес-логика изменилась, и вам нужно повторно обработать как исторические, так и текущие данные.
Обратная заливка в декларативных конвейерах Spark Lakeflow поддерживается специализированным потоком добавления, который использует параметр ONCE. Для получения дополнительной информации о параметре см. append_flow или ONCE.
Соображения при заполнении исторических данных в потоковую таблицу
- Как правило, добавьте данные в бронзовую потоковую таблицу. Нижние серебряные и золотые слои будут собирать новые данные из бронзового слоя.
- Убедитесь, что конвейер может обрабатывать повторяющиеся данные корректно, если одни и те же данные добавляются несколько раз.
- Убедитесь, что схема исторических данных совместима с текущей схемой данных.
- Учтите объем данных и время обработки согласно SLA, и соответствующим образом настройте кластер и размеры пакетов.
Пример: Добавление заполнения пробелов в существующий конвейер
В этом примере предположим, что у вас есть конвейер, который использует необработанные данные регистрации событий из источника облачного хранилища, начиная с 01 января 2025 г. Позже вы понимаете, что хотите заполнить предыдущие три года исторических данных для последующих отчетов и анализа случаев использования. Все данные отображаются в одном расположении, секционируемом по годам, месяцам и дням в формате JSON.
Начальный конвейер
Ниже приведен начальный код пайплайна, который постепенно загружает необработанные данные о регистрации событий из облачного хранилища.
Питон
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Здесь мы используем modifiedAfter параметр автозагрузчика, чтобы убедиться, что мы не обрабатываем все данные из пути облачного хранилища. Инкрементная обработка прекращается на этой границе.
Подсказка
Другие источники данных, такие как Kafka, Kinesis и Центры событий Azure, имеют эквивалентные параметры чтения для достижения такого же поведения.
Резервные данные за предыдущие 3 года
Теперь необходимо добавить один или несколько потоков для восстановления предыдущих данных. В этом примере выполните следующие действия.
- Используйте поток
append once. В этом случае выполняется однократное обновление данных без продолжения процесса впоследствии. Код остается в конвейере, и если конвейер полностью обновляется, дозаполнение выполняется повторно. - Создайте три потока бэкфилла, по одному на каждый год, поскольку в этом случае данные разделяются по годам в пути. Для Python мы параметризируем создание потоков, но в SQL мы повторяем код три раза один раз для каждого потока.
Если вы работаете над собственным проектом и не используете бессерверные вычисления, возможно, потребуется обновить максимальное количество рабочих ролей для конвейера. Увеличение максимального числа рабочих ролей гарантирует, что у вас есть ресурсы для обработки исторических данных, продолжая обрабатывать текущие потоковые данные в ожидаемом уровне обслуживания.
Подсказка
Если вы используете бессерверные вычисления с расширенным автомасштабированием (по умолчанию), кластер автоматически увеличивает размер при увеличении нагрузки.
Питон
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Эта реализация выделяет несколько важных шаблонов.
Разделение проблем
- Инкрементная обработка не зависит от операций заполнения задним числом.
- Каждый поток имеет собственные параметры конфигурации и оптимизации.
- Существует четкое различие между инкрементальными и операциями заполнения.
Управляемое выполнение
- Использование параметра
ONCEгарантирует, что каждая операция обратного заполнения выполняется ровно один раз. - Поток обратной заполнения остается в графе конвейера, но становится неактивным после завершения. Он готов к использованию при полном обновлении автоматически.
- В определении конвейерного процесса существует четкий аудиторский след операций обратного заполнения.
Оптимизация обработки
- Вы можете разделить большое обратное заполнение на несколько небольших обратных заполнений для более быстрой обработки или её контроля.
- Использование расширенного автомасштабирования динамически масштабирует размер кластера на основе текущей нагрузки кластера.
Эволюция схемы
- Использование
schemaEvolutionMode="addNewColumns"обрабатывает изменения схемы корректно. - У вас есть согласованное определение схемы для исторических и текущих данных.
- Существует безопасная обработка новых столбцов в новых данных.