Заметка
Доступ к этой странице требует авторизации. Вы можете попробовать войти в систему или изменить каталог.
Доступ к этой странице требует авторизации. Вы можете попробовать сменить директорию.
Это важно
Эта функция доступна в общедоступной предварительной версии.
В этой статье описывается использование редактора конвейеров Lakeflow для разработки и отладки конвейеров ETL (извлечения, преобразования и загрузки) в декларативных конвейерах Lakeflow Spark (SDP).
Замечание
Редактор Конвейеров Lakeflow включен по умолчанию. Его можно отключить или повторно включить, если он отключен. См. Включение редактора конвейеров Lakeflow и обновленный мониторинг.
Что такое редактор потоков Lakeflow?
Редактор Конвейеров Lakeflow — это интегрированная среда разработки для разработки конвейеров. Он объединяет все задачи разработки конвейеров на одной поверхности, поддерживая рабочие процессы на основе кода, организацию кода на основе папок, выборочное выполнение, предварительный просмотр данных и графы конвейеров. Интегрированная с платформой Azure Databricks, она также включает управление версиями, проверки кода и запланированные запуски.
Обзор пользовательского интерфейса редактора конвейеров Lakeflow
На следующем изображении показан редактор конвейеров Lakeflow.
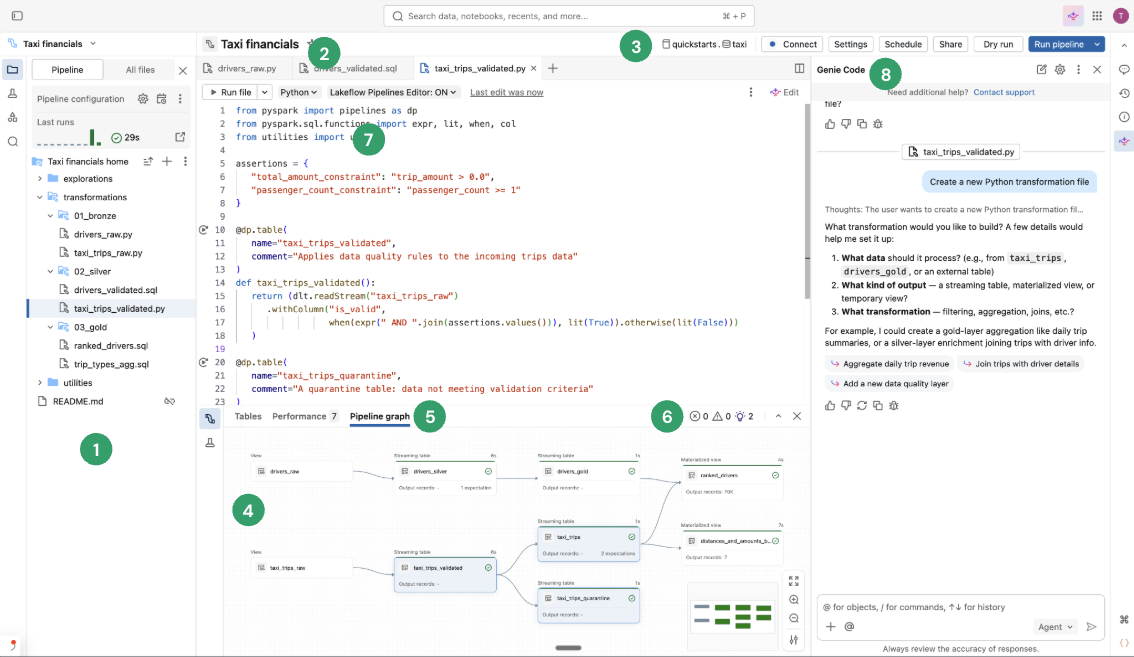
На изображении показаны следующие функции:
- Браузер ресурсов конвейера: создание, удаление, переименование и упорядочение ресурсов конвейера. Также включает сочетания клавиш для конфигурации конвейера.
- Редактор кода с несколькими файлами с вкладками: работа между несколькими файлами кода, связанными с конвейером.
- Панель инструментов для конкретного конвейера: включает параметры конфигурации конвейера и выполняет действия на уровне конвейера.
- Интерактивный ациклический граф (DAG) — получение обзора таблиц, открытие нижней панели предварительных просмотров данных и выполнение других действий, связанных с таблицами.
- Предварительный просмотр данных: проверьте данные потоковых таблиц и материализованных представлений.
- Аналитика выполнения на уровне таблицы: получение аналитических сведений о выполнении для всех таблиц или одной таблицы в конвейере. Аналитические сведения относятся к последнему запуску конвейера.
- Панель проблем: эта функция суммирует ошибки во всех файлах в конвейере, и вы можете перейти к месту возникновения ошибки внутри определенного файла. Он дополняет индикаторы ошибок, прикрепленных к коду.
- Выборочное выполнение. Редактор кода имеет функции пошаговой разработки, такие как возможность обновления таблиц только в текущем файле с помощью действия запуска файла или одной таблицы.
- Структура папок конвейера по умолчанию: новые конвейеры включают предопределенную структуру папок и пример кода, который можно использовать в качестве отправной точки для конвейера.
- Упрощенное создание конвейера: укажите имя, каталог и схему, в которой таблицы должны создаваться по умолчанию, и конвейер создается с помощью параметров по умолчанию. Позже можно изменить Настройки на панели инструментов редактора конвейера.
Создание конвейера ETL
Чтобы создать новый конвейер ETL с помощью редактора конвейеров Lakeflow, выполните следующие действия:
В верхней части боковой панели щелкните
 Новый и выберите
Новый и выберите  Конвейер ETL.
Конвейер ETL.В верхней части можно указать уникальное имя конвейера.
Под именем можно увидеть каталог по умолчанию и схему, выбранные для вас. Измените их, чтобы предоставить конвейеру разные значения по умолчанию.
Каталог по умолчанию и схема по умолчанию — это место, в котором наборы данных считываются или записываются, когда наборы данных не соответствуют каталогу или схеме в коде. Дополнительные сведения см. в разделе "Объекты базы данных" в Azure Databricks .
Выберите предпочтительный вариант для создания конвейера, выбрав один из следующих вариантов:
- Начните с примера кода в SQL , чтобы создать новую структуру конвейера и папок, включая пример кода в SQL.
- Начните с примера кода в Python , чтобы создать новую структуру конвейера и папок, включая пример кода в Python.
- Начните с одного преобразования , чтобы создать новую структуру конвейера и папок с новым пустым файлом кода.
- Добавьте существующие ресурсы для создания конвейера, который можно связать с файлами кода exisitng в рабочей области.
В конвейере ETL можно использовать файлы исходного кода SQL и Python. При создании конвейера и выборе языка для примера кода язык предназначен только для примера кода, включенного в конвейер по умолчанию.
При выборе вы будете перенаправлены в только что созданный конвейер.
Конвейер ETL создается со следующими параметрами по умолчанию:
- Каталог Unity
- Текущий канал
- Бессерверные вычисления
- Режим разработки отключен. Этот параметр влияет только на запланированные запуски конвейера. Запуск конвейера из редактора по умолчанию всегда происходит в режиме разработки.
Эти параметры можно настроить на панели инструментов конвейера.
Кроме того, можно создать конвейер ETL из браузера рабочей области:
- Щелкните рабочую область на левой панели.
- Выберите любую папку, включая папки Git.
- Щелкните "Создать " в правом верхнем углу и щелкните конвейер ETL.
Вы также можете создать конвейер ETL на странице заданий и конвейеров:
- В рабочей области щелкните на
 Задания и конвейеры на боковой панели.
Задания и конвейеры на боковой панели. - В меню Создать нажмите Конвейер ETL.
Открытие существующего конвейера ETL
Существует несколько способов открытия существующего конвейера ETL в редакторе Конвейеров Lakeflow:
Откройте любой исходный файл, связанный с конвейером:
- Щелкните рабочее пространство на боковой панели.
- Перейдите в папку с файлами исходного кода для конвейера.
- Щелкните файл исходного кода, чтобы открыть конвейер в редакторе.
Откройте недавно измененный конвейер:
- В редакторе можно перейти к другим конвейерам, которые вы недавно изменили, щелкнув имя конвейера в верхней части браузера активов и выбрав другой конвейер из появиющегося списка последних.
- Из редактора, на странице Последние на левой боковой панели, откройте конвейер или файл, сконфигурированный в качестве исходного кода для конвейера.
При просмотре потока данных в пределах продукта, вы можете редактировать его:
- На странице мониторинга конвейера щелкните
 Изменение конвейера.
Изменение конвейера. - На странице "Запуски заданий" на левой боковой панели щелкните вкладку "Задания и конвейеры" и затем щелкните
 Затем Изменить конвейер.
Затем Изменить конвейер. - При редактировании задания и добавлении задачи конвейера можно нажать
 , когда вы выбираете конвейер в разделе Конвейер.
, когда вы выбираете конвейер в разделе Конвейер.
- На странице мониторинга конвейера щелкните
Если вы просматриваете все файлы в браузере активов и открываете файл исходного кода из другого конвейера, баннер отображается в верхней части редактора, предлагая открыть связанный конвейер.
Браузер ресурсов конвейера
При редактировании конвейера в левой боковой панели рабочей области используется специальный режим, называемый браузером ресурсов конвейера. По умолчанию браузер ресурсов конвейера фокусируется на корневом каталоге конвейера и папках и файлах в корневом каталоге. Вы также можете выбрать отображение всех файлов, чтобы увидеть файлы за пределами корневого каталога пайплайна. Вкладки, открытые в редакторе конвейера при редактировании конкретного конвейера, запоминаются, и при переключении на другой конвейер восстанавливаются вкладки, которые были открыты в последний раз, когда вы редактировали этот конвейер.
Замечание
Редактор также имеет контексты для редактирования ФАЙЛОВ SQL (называемых редактором Databricks SQL) и общего контекста для редактирования файлов рабочей области, которые не являются файлами SQL или файлами конвейера. Каждый из этих контекстов запоминает и восстанавливает вкладки, которые вы открыли при последнем открытии этого контекста. Контекст можно переключить из верхней части левой боковой панели. Щелкните заголовок, чтобы выбрать между рабочими областями, редактором SQL или недавно измененными конвейерами.
При открытии файла на странице браузера рабочей области он открывается в соответствующем редакторе для этого файла. Если файл связан с конвейером, то это редактор Lakeflow Pipelines.
Чтобы открыть файл, который не является частью конвейера, но сохранить контекст конвейера, откройте файл на вкладке "Все файлы " браузера ресурсов.
В браузере активов конвейера есть две вкладки:
- Конвейер. Здесь можно найти все файлы, связанные с конвейером. Вы можете создавать, удалять, переименовать и упорядочивать их в папках. Эта вкладка также включает сочетания клавиш для конфигурации конвейера и графическое представление последних запусков.
- Все файлы: все остальные ресурсы рабочей области доступны здесь. Это может быть полезно для поиска файлов для добавления в конвейер или просмотра других файлов, связанных с конвейером, таких как ФАЙЛ YAML, определяющий пакеты ресурсов Databricks.
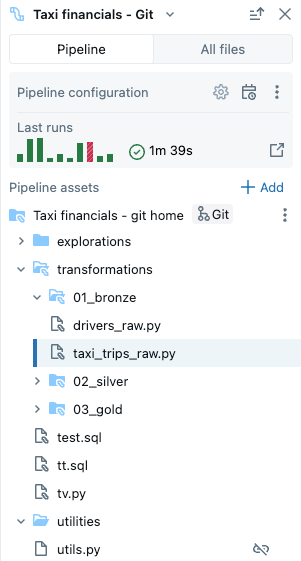
В конвейере можно использовать следующие типы файлов:
- Файлы исходного кода: эти файлы являются частью определения исходного кода конвейера, который можно увидеть в параметрах. Databricks рекомендует всегда хранить файлы исходного кода в корневой папке конвейера; в противном случае они отображаются в разделе внешнего файла в нижней части браузера и имеют менее широкий набор функций.
- Файлы, отличные от исходного кода: эти файлы хранятся в корневой папке конвейера, но не являются частью определения исходного кода конвейера.
Это важно
Необходимо использовать браузер ресурсов конвейера на вкладке "Конвейер" для управления файлами и папками для конвейера. Это правильно обновляет параметры конвейера. Перемещение или переименование файлов и папок из браузера рабочей области или вкладка "Все файлы " разбивает конфигурацию конвейера, а затем ее необходимо устранить вручную в параметрах.
Корневая папка
Браузер ресурсов конвейера привязан к корневой папке конвейера. При создании нового конвейера корневая папка конвейера создается в домашней папке пользователя и называется таким же, как имя конвейера.
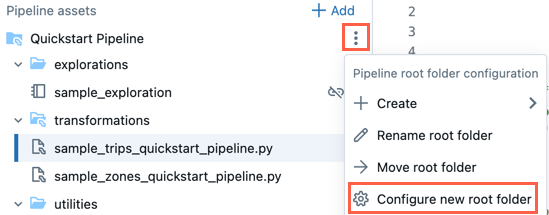
Корневую папку можно изменить в браузере ресурсов конвейера. Это полезно, если вы создали конвейер в папке, а затем хотите переместить все в другую папку. Например, вы создали конвейер в обычной папке и хотите переместить исходный код в папку Git для управления версиями.
- Щелкните наверху корневой папки, чтобы открыть его дополнительное меню.
- Нажмите кнопку "Настроить новую корневую папку".
- В разделе "Корневая папка конвейера" щелкните
 и выберите другую папку в качестве корневой папки конвейера.
и выберите другую папку в качестве корневой папки конвейера. - Нажмите кнопку Сохранить.
На ![]() корневой папки можно также нажать кнопку "Переименовать корневую папку ", чтобы переименовать имя папки. Здесь можно также щелкнуть "Переместить корневую папку ", чтобы переместить корневую папку, например в папку Git.
корневой папки можно также нажать кнопку "Переименовать корневую папку ", чтобы переименовать имя папки. Здесь можно также щелкнуть "Переместить корневую папку ", чтобы переместить корневую папку, например в папку Git.
Вы также можете изменить корневую папку конвейера в параметрах:
- Нажмите кнопку "Параметры".
- В разделе "Ресурсы кода" щелкните "Настройка путей".
- Щелкните , чтобы изменить папку в корневой папке конвейера.
- Нажмите кнопку Сохранить.
Замечание
Если изменить корневую папку конвейера, список файлов, отображаемый браузером ресурсов конвейера, затронут, так как файлы в предыдущей корневой папке отображаются как внешние файлы.
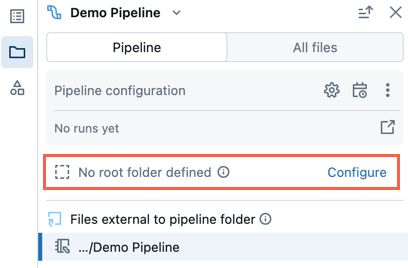
Существующий конвейер без корневой папки
Существующий конвейер, созданный с помощью устаревшего интерфейса редактирования записной книжки , не будет настроена корневая папка. При открытии конвейера, который не имеет настроенной корневой папки, вам будет предложено создать корневую папку и упорядочить исходные файлы внутри неё.
Вы можете отклонить это уведомление и продолжить редактирование пайплайна, не задавая корневую папку.
Если позже вы хотите настроить корневую папку для конвейера, выполните следующие действия:
- В браузере ресурсов конвейера нажмите кнопку "Настроить".
- Щелкните , чтобы выбрать корневую папку в корневой папке конвейера.
- Нажмите кнопку Сохранить.
Структура папок по умолчанию
При создании нового конвейера создается структура папок по умолчанию. Это рекомендуемая схема для организации исходных и неисходных файлов кода потока, как описано ниже.
Небольшое количество примеров файлов кода создаются в этой структуре папок.
| Имя папки | Рекомендуемое расположение для этих типов файлов |
|---|---|
<pipeline_root_folder> |
Корневая папка, содержащая все папки и файлы для конвейера. |
transformations |
Файлы исходного кода, такие как файлы кода Python или SQL с определениями таблиц. |
explorations |
Файлы кода, отличные от исходного кода, такие как записные книжки, запросы и файлы кода, используемые для анализа аналитических данных. |
utilities |
Файлы, отличные от исходного кода, с модулями Python, которые можно импортировать из других файлов кода. Если вы выбрали SQL в качестве языка для примера кода, эта папка не создается. |
Имена папок можно переименовать или изменить структуру, чтобы она соответствовала рабочему процессу. Чтобы добавить новую папку исходного кода, выполните следующие действия.
- Нажмите кнопку "Добавить " в браузере ресурсов конвейера.
- Щелкните "Создать папку исходного кода конвейера".
- Введите имя папки и нажмите кнопку "Создать".
Файлы исходного кода
Файлы исходного кода являются частью определения исходного кода конвейера. При запуске конвейера эти файлы оцениваются. Файлы и папки, входящие в определение исходного кода, имеют специальный значок с маленьким изображением конвейера.
Чтобы добавить новый файл исходного кода, выполните следующие действия.
- Нажмите кнопку "Добавить " в браузере ресурсов конвейера.
- Щелкните преобразование.
- Введите имя файла и выберите Python или SQL в качестве языка.
- Нажмите кнопку "Создать".
Вы также можете щелкнуть ![]() Для любой папки в браузере ресурсов конвейера можно добавить файл исходного кода.
Для любой папки в браузере ресурсов конвейера можно добавить файл исходного кода.
Папка transformations для исходного кода создается по умолчанию при создании нового конвейера. Эта папка является рекомендуемой папкой для исходного кода конвейера, например файлов кода Python или SQL с определениями таблиц конвейера.
Файлы, отличные от исходного кода
Файлы кода, отличные от исходного кода, хранятся в корневой папке конвейера, но не являются частью определения исходного кода конвейера. Эти файлы не оцениваются при запуске конвейера. Файлы, отличные от исходного кода, не могут быть внешними файлами.
Это можно использовать для файлов, связанных с работой в конвейере, который вы хотите хранить вместе с исходным кодом. Рассмотрим пример.
- Записные книжки, используемые для нерегламентированных исследований, выполняемых в декларативных конвейерах Spark, не относящихся к Lakeflow Spark, вычисляются вне жизненного цикла конвейера.
- Модули Python, которые не должны оцениваться с помощью исходного кода, если вы явно не импортируете эти модули в файлы исходного кода.
Чтобы добавить новый файл, отличный от исходного кода, выполните следующие действия.
- Нажмите кнопку "Добавить " в браузере ресурсов конвейера.
- Щелкните "Исследование" или "Утилита".
- Введите имя файла.
- Нажмите кнопку "Создать".
Вы также можете щелкнуть ![]() Для корневой папки конвейера или файла кода, отличного от исходного кода, можно добавить файлы, отличные от исходного кода, в папку.
Для корневой папки конвейера или файла кода, отличного от исходного кода, можно добавить файлы, отличные от исходного кода, в папку.
При создании нового конвейера по умолчанию создаются следующие папки для файлов, отличных от исходного кода:
| Имя папки | Description |
|---|---|
explorations |
Эта папка является рекомендованным местоположением для записных книжек, запросов, панелей мониторинга и других файлов, и их запуск на вычислительных ресурсах, отличных от декларативных конвейеров Lakeflow Spark, как вы обычно делаете это вне жизненного цикла выполнения конвейера. |
utilities |
Эта папка является рекомендуемым расположением для модулей Python, которые можно импортировать из других файлов с помощью прямых импортов, выраженных как from <filename> import, если их родительская папка иерархически находится под корневой папкой. |
Вы также можете импортировать модули Python, расположенные вне корневой папки, но в этом случае необходимо добавить путь sys.path к папке в код Python:
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
Внешние файлы
В разделе "Внешние файлы " браузера конвейера отображаются файлы исходного кода за пределами корневой папки.
Чтобы переместить внешний файл в корневую папку, например в папку transformations, выполните следующие действия:
- Щелкните Для файла в браузере ресурсов нажмите кнопку "Переместить".
- Выберите папку, в которую нужно переместить файл, и нажмите кнопку "Переместить".
Файлы, связанные с несколькими конвейерами
Значок отображается в заголовке файла, если файл связан с несколькими конвейерами. Он включает в себя количество связанных трубопроводов и позволяет переключаться между ними.
Раздел "Все файлы"
В дополнение к разделу Pipeline есть раздел "Все файлы ", где можно открыть любой файл в рабочей области. Здесь можно:
- Откройте файлы вне корневой папки на вкладке без выхода из редактора Конвейеров Lakeflow.
- Перейдите к файлам исходного кода другого конвейера и откройте их. Файл откроется в редакторе, и вы увидите баннер с опцией переключить фокус в редакторе на этот второй конвейер управляющих процессов.
- Переместите файлы в корневую папку конвейера.
- Включите файлы вне корневой папки в определение исходного кода конвейера.
Изменение исходных файлов конвейера
При открытии исходного файла конвейера из браузера рабочей области или браузера ресурсов конвейера, файл открывается на вкладке редактора в редакторе Lakeflow Pipelines. Открытие дополнительных файлов открывает отдельные вкладки, позволяя одновременно редактировать несколько файлов.
Замечание
Открытие файла, который не связан с конвейером, из обозревателя рабочей области откроет редактор в другом контексте (либо общий редактор рабочей области, либо, для SQL-файлов, редактор SQL).
При открытии файла, не относящегося к конвейеру, на вкладке «Все файлы» браузера ресурсов конвейера он открывается в новой вкладке в контексте конвейера.
Исходный код конвейера содержит несколько файлов. По умолчанию исходные файлы находятся в каталоге преобразований в браузере активов конвейера. Файлы исходного кода могут быть файлами Python (*.py) или SQL (*.sql). Источник может включать в себя сочетание файлов Python и SQL в одном конвейере, а код в одном файле может ссылаться на таблицу или представление, определенное в другом файле.
Вы также можете включить файлы Markdown (*.md) в папку tranformations . Файлы Markdown можно использовать для документации или заметок, но игнорируются при запуске обновления конвейера.
Следующие функции относятся к редактору Конвейеров Lakeflow.
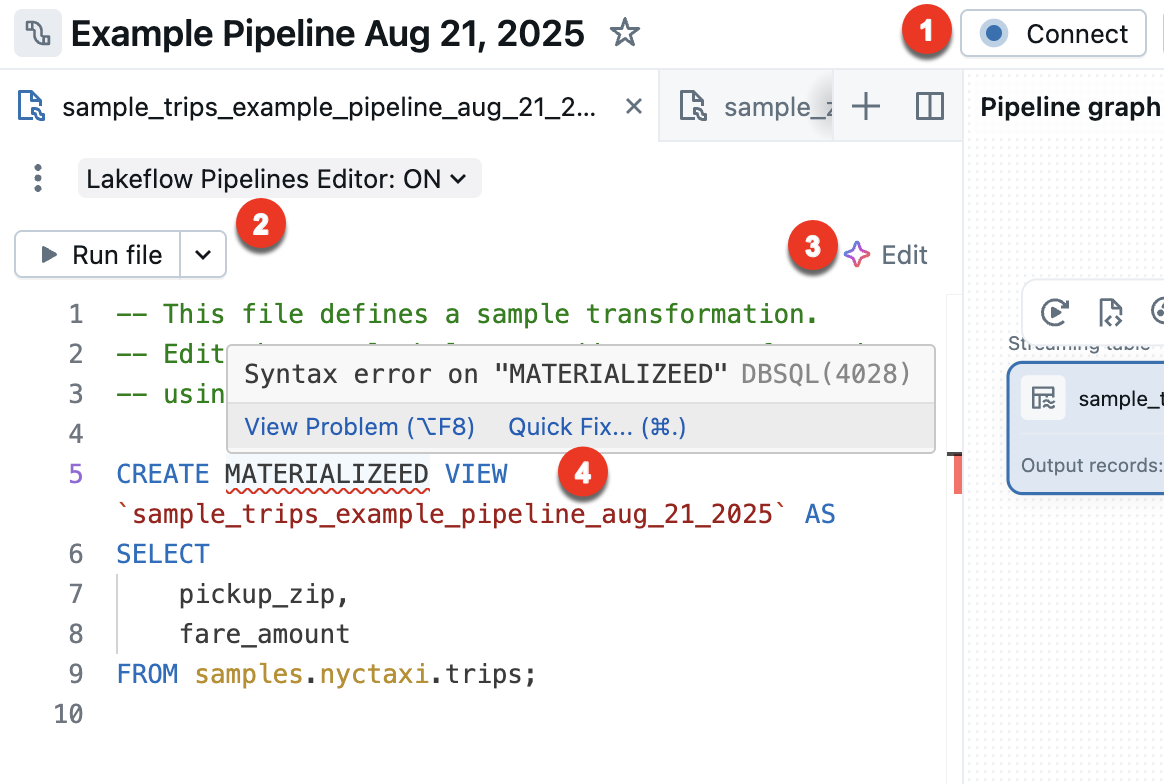
Подключение — подключение к бессерверным или классическим вычислениям для запуска конвейера. Все файлы, связанные с конвейером, используют одно и то же вычислительное подключение, поэтому после подключения вам не нужно подключаться к другим файлам в одном конвейере. Дополнительные сведения о параметрах вычислений см. в разделе "Параметры конфигурации вычислений".
Для файлов, отличных от конвейера, таких как исследовательская записная книжка, доступен вариант подключения, но применяется только к одному файлу.
Запустите файл. Запустите код для обновления таблиц, определенных в этом исходном файле. В следующем разделе описаны различные способы выполнения кода конвейера.
Изменение — используйте помощник Databricks для редактирования или добавления кода в файл.
Быстрое исправление . При возникновении ошибки в коде используйте помощник, чтобы устранить ошибку.
Нижняя панель также настраивается на основе текущей вкладки. Просмотр сведений о конвейере на нижней панели всегда доступен. Файлы, не связанные с конвейером, например, файлы редактора SQL, также выводятся на отдельной вкладке в нижней панели. На следующем рисунке показан вертикальный селектор вкладок, позволяющий переключать нижнюю панель между просмотром сведений о конвейере и информацией о выбранной записной книжке.
Запуск кода конвейера
У вас есть четыре варианта запуска кода конвейера:
Запуск всех файлов исходного кода в конвейере
Нажмите кнопку "Запуск конвейера" или "Запуск конвейера" с полным обновлением таблицы, чтобы запустить все определения таблиц во всех файлах, определенных как исходный код конвейера. Дополнительные сведения о типах обновления см. в разделе " Семантика обновления конвейера".
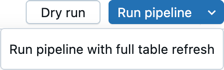
Вы также можете нажать кнопку "Сухой запуск" , чтобы проверить конвейер без обновления данных.
Запуск кода в одном файле
Нажмите кнопку "Запустить файл " или "Запустить файл" с полным обновлением таблицы , чтобы запустить все определения таблиц в текущем файле. Другие файлы в конвейере не оцениваются.
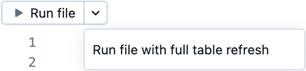
Этот параметр полезен для отладки при быстром редактировании и итерации файла. При выполнении кода в одном файле существуют побочные эффекты.
- Если другие файлы не оцениваются, ошибки в этих файлах не найдены.
- Таблицы, материализованные в других файлах, используют самую последнюю материализацию таблицы, даже если есть более последние исходные данные.
- Вы можете столкнуться с ошибками, если таблица, на которую имеется ссылка, еще не материализована.
- DAG может быть неверным или разрозненным для таблиц в других файлах, которые не были материализованы. Azure Databricks делает все возможное, чтобы обеспечить правильность графа, но не оценивает другие файлы для этого.
После завершения отладки и редактирования файла Databricks рекомендует запускать все файлы исходного кода в конвейере, чтобы убедиться, что конвейер работает сквозно, прежде чем помещать конвейер в рабочую среду.
Запуск кода для одной таблицы
Рядом с определением таблицы в файле исходного кода щелкните значок запуска таблицы
 таблицу", а затем выберите "Обновить таблицу " или "Полная таблица обновления " в раскрывающемся списке. Выполнение кода для одной таблицы имеет аналогичные побочные эффекты, как выполнение кода в одном файле.
таблицу", а затем выберите "Обновить таблицу " или "Полная таблица обновления " в раскрывающемся списке. Выполнение кода для одной таблицы имеет аналогичные побочные эффекты, как выполнение кода в одном файле.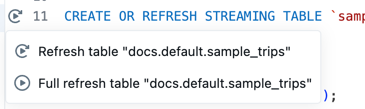
Замечание
Выполнение кода для одной таблицы доступно для потоковых таблиц и материализованных представлений. Приемники и представления не поддерживаются.
Запуск кода для набора таблиц
Вы можете выбрать таблицы из DAG, чтобы создать список таблиц для запуска. Наведите указатель мыши на таблицу в DAG, щелкните
и выберите команду "Выбрать таблицу для обновления". Выбрав таблицы для обновления, выберите опцию "Запуск " или "Запустить с полным обновлением " внизу DAG.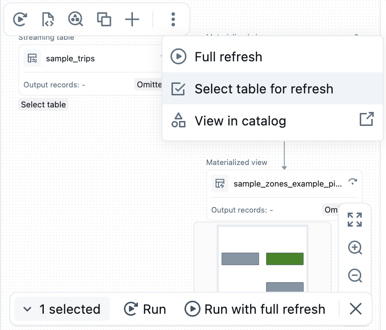
Граф конвейера, ориентированный ациклический граф (DAG)
После запуска или проверки всех файлов исходного кода в конвейере отображается ациклический граф (DAG), называемый графом конвейера. На графе показан граф зависимостей таблицы. У каждого узла имеются различные состояния на протяжении жизненного цикла конвейера, такие как проверка, запуск или ошибка.
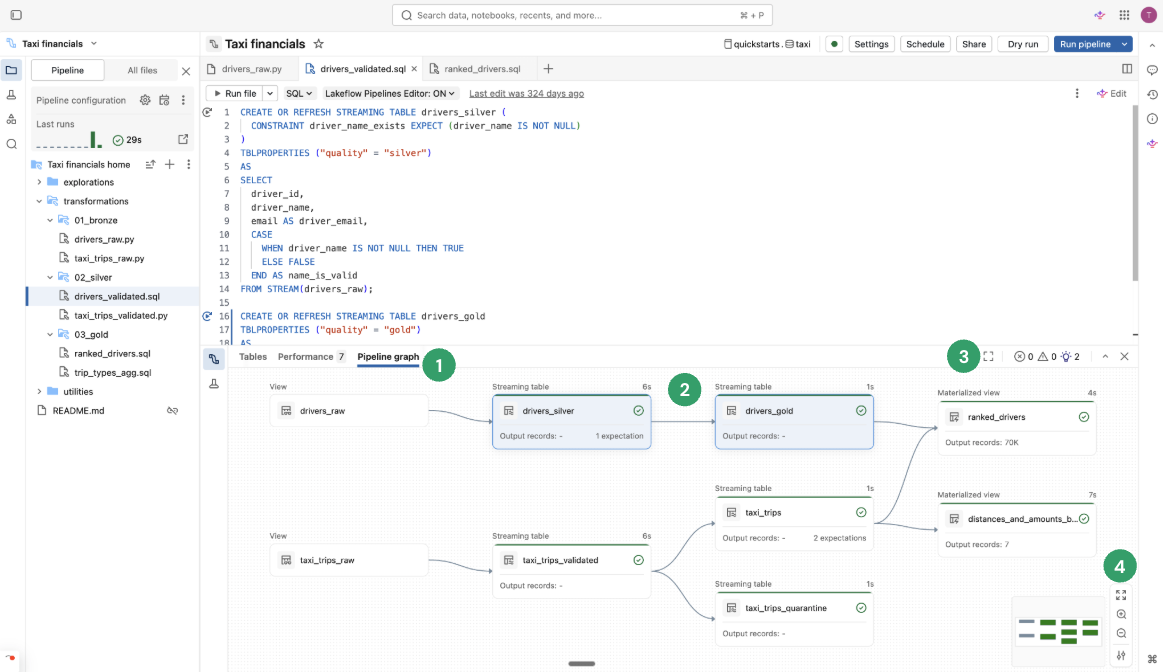
Вы можете включать и выключать график, щелкнув по значку графика в правой панели. Вы также можете увеличить граф. В правом нижнем углу есть дополнительные параметры, включая параметры ![]() Дополнительные параметры для отображения графа в вертикальном или горизонтальном макете.
Дополнительные параметры для отображения графа в вертикальном или горизонтальном макете.
При наведении указателя мыши на узел отображается панель инструментов с параметрами, включая обновление запроса. Щелкнув правой кнопкой мыши узел, вы можете выбрать те же параметры в контекстном меню.
Щелчок по узлу показывает предварительный просмотр данных и определение таблицы. При редактировании файла таблицы, определенные в этом файле, выделены в графе.
Предварительные версии данных
В разделе предварительного просмотра данных показаны примеры данных для выбранной таблицы.
Вы увидите предварительный просмотр данных таблицы при щелчке узла в направленном ациклическом графе (DAG).
Если таблица не выбрана, перейдите в раздел Таблицы и щелкните Просмотр данных![]() . Если вы выбрали таблицу, нажмите кнопку "Все таблицы ", чтобы вернуться ко всем таблицам.
. Если вы выбрали таблицу, нажмите кнопку "Все таблицы ", чтобы вернуться ко всем таблицам.
При предварительном просмотре данных таблицы можно отфильтровать или отсортировать данные на месте. Если вы хотите выполнить более сложный анализ, можно использовать или создать записную книжку в папке "Исследование" (если вы сохранили структуру папок по умолчанию). По умолчанию исходный код в этой папке не выполняется во время обновления конвейера, поэтому можно создавать запросы без влияния на выходные данные конвейера.
Аналитические сведения о выполнении
Вы можете просмотреть аналитические сведения о выполнении таблицы о последнем обновлении конвейера на панелях в нижней части редактора.
| Panel | Description |
|---|---|
| Tables | Перечисляет все таблицы, их состояния и метрики. Если выбрать одну таблицу, вы увидите метрики и производительность для этой таблицы и вкладку для предварительного просмотра данных. |
| Performance | Журнал запросов и профили для всех потоков в этом конвейере. Вы можете получить доступ к метрикам выполнения и подробным планам запросов во время и после выполнения. Дополнительные сведения см. в истории запросов для конвейеров. |
| Панель проблем | Щелкните панель для упрощенного представления ошибок и предупреждений для конвейера. Вы можете щелкнуть запись, чтобы просмотреть дополнительные сведения, а затем перейти к месту в коде, где произошла ошибка. Если ошибка находится в файле, отличном от отображаемого в данный момент, это перенаправляет вас в файл, в котором находится ошибка. Щелкните "Просмотреть сведения" , чтобы просмотреть соответствующую запись журнала событий для получения полных сведений. Щелкните Просмотреть журналы , чтобы просмотреть полный журнал событий. Индикаторы ошибок, прикрепленных к коду, отображаются для ошибок, связанных с определенной частью кода. Чтобы получить дополнительные сведения, щелкните значок ошибки или наведите указатель мыши на красную линию. Появится всплывающее окно с дополнительными сведениями. Затем можно нажать кнопку "Быстрое исправление" , чтобы выявить набор действий для устранения ошибки. |
| Журнал событий | Все события, произошедшие во время последнего запуска конвейера. Щелкните Просмотреть журналы или любую запись в панели вопросов. |
Конфигурация конвейера
Конвейер можно настроить из редактора конвейера. Вы можете внести изменения в параметры конвейера, расписание или разрешения.
К каждому из них можно получить доступ из кнопки в заголовке редактора или из значков в браузере активов (левая боковая панель).
Параметры (или выберите значок шестеренка в браузере
 ресурсов):
ресурсов):Параметры конвейера можно изменить на панели параметров, включая общие сведения, корневую папку и конфигурацию исходного кода, конфигурацию вычислений, уведомления, дополнительные параметры и многое другое.
Расписание (или выберите
 в браузере активов):
в браузере активов):Вы можете создать одно или несколько расписаний для конвейера в диалоговом окне расписания. Например, если вы хотите запускать его ежедневно, вы можете установить это здесь. Он создает задание для запуска конвейера в выбранном расписании. Можно добавить новое расписание или удалить существующее расписание из диалогового окна расписания.
Поделиться (или, в
в обозревателе ресурсов выберите  ):
):Вы можете управлять разрешениями в конвейере для пользователей и групп из диалогового окна разрешений конвейера.
Журнал событий
Журнал событий можно опубликовать для конвейера в каталоге Unity. По умолчанию журнал событий для конвейера отображается в пользовательском интерфейсе и доступен для запроса владельцем.
- Откройте параметры.
- Щелкните
 Стрелка рядом с дополнительными параметрами.
Стрелка рядом с дополнительными параметрами. - Нажмите кнопку "Изменить дополнительные параметры".
- В разделе "Журналы событий" нажмите кнопку "Опубликовать в каталоге".
- Укажите имя, каталог и схему для журнала событий.
- Нажмите кнопку Сохранить.
События вашего конвейера публикуются в указанной вами таблице.
Дополнительные сведения об использовании журнала событий конвейера см. в статье "Запрос журнала событий".
Среда конвейера
Вы можете создать среду для исходного кода, добавив зависимости в параметры.
- Откройте параметры.
- В разделе "Среда" щелкните "Изменить среду".
- Выберите Добавьте зависимость, чтобы добавить зависимость, как при добавлении в файл
requirements.txt. Дополнительные сведения о зависимостях см. в разделе "Добавление зависимостей в записную книжку".
Databricks рекомендует закрепить версию с помощью ==. См . пакет PyPI.
Среда применяется ко всем файлам исходного кода в конвейере.
Уведомления
Вы можете добавлять уведомления с помощью параметров конвейера.
- Откройте параметры.
- В разделе "Уведомления" нажмите кнопку "Добавить уведомление".
- Добавьте один или несколько адресов электронной почты и укажите события, которые вы хотите отправить на эти адреса.
- Нажмите кнопку "Добавить уведомление".
Замечание
Создайте пользовательские ответы на события, включая уведомления или настраиваемую обработку, с помощью Python перехватчиков событий.
Мониторинг конвейеров
Azure Databricks также предоставляет функции для мониторинга запущенных конвейеров. В редакторе отображаются результаты и аналитические сведения о выполнении последнего запуска. Он оптимизирован для эффективной итерации при интерактивной разработке вашего конвейера.
Страница мониторинга конвейера позволяет просматривать исторические запуски, что полезно при выполнении конвейера по расписанию с помощью задания.
Замечание
Существует стандартный режим мониторинга и обновленный режим мониторинга в предварительной версии. В следующем разделе описывается, как включить или отключить предварительный просмотр мониторинга. Сведения об обоих интерфейсах см. в разделе "Мониторинг конвейеров" в пользовательском интерфейсе.
Интерфейс мониторинга доступен на кнопке "Задания и конвейеры" в левой части рабочей области. Вы также можете перейти непосредственно на страницу мониторинга из редактора, щелкнув результаты выполнения в обозревателе объектов конвейера.

Дополнительные сведения о странице мониторинга см. в разделе "Мониторинг конвейеров" в пользовательском интерфейсе. Пользовательский интерфейс мониторинга включает возможность вернуться в редактор Конвейеров Lakeflow, выбрав "Изменить конвейер " из заголовка пользовательского интерфейса.
Активируйте редактор конвейеров Lakeflow и обновленный мониторинг
Предварительная версия редактора конвейеров Lakeflow включена по умолчанию. Его можно отключить или повторно включить с помощью приведенных ниже инструкций. Если включена предварительная версия редактора конвейеров Lakeflow, можно также включить обновленный интерфейс мониторинга (предварительная версия).
Предварительный просмотр должен быть включен, настроив параметр Редактора конвейеров Lakeflow для рабочей области. Дополнительные сведения об изменении параметров см. в статье "Управление предварительными версиями Azure Databricks ".
После активации предварительного просмотра редактор конвейеров Lakeflow можно включить несколькими способами:
При создании нового конвейера ETL включите редактор в декларативных конвейерах Spark Lakeflow с помощью переключателя Lakeflow Pipelines Editor.
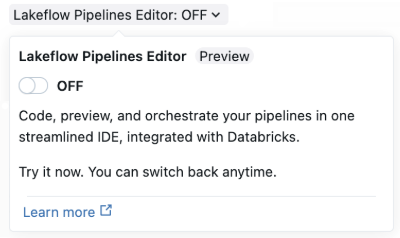
Страница расширенных параметров конвейера используется при первом включении редактора. Окно создания упрощенного конвейера используется при следующем создании нового конвейера.
Для существующего конвейера откройте записную книжку, используемую в конвейере, и включите переключатель редактора конвейеров Lakeflow в заголовке. Вы также можете перейти на страницу мониторинга конвейера и нажать кнопку "Параметры ", чтобы включить редактор конвейеров Lakeflow.
Редактор Pipelines Lakeflow можно включить из параметров пользователя:
- Щелкните значок пользователя в правой верхней области рабочей области, а затем нажмите кнопку "Параметры " и "Разработчик".
- Включите редактор конвейеров Lakeflow.
После включения переключателя редактора Конвейеров Lakeflow все конвейеры ETL используют редактор конвейеров Lakeflow по умолчанию. Редактор Lakeflow Pipelines можно активировать и деактивировать прямо в самой программе.
Замечание
Если вы отключите новый редактор конвейера, полезно оставить отзыв о том, почему вы отключили его. На переключателе есть кнопка "Отправить отзыв" для любых отзывов о новом редакторе.
Включение новой страницы мониторинга конвейера
Это важно
Эта функция доступна в общедоступной предварительной версии.
В рамках предварительной версии редактора конвейеров Lakeflow можно также включить новую страницу мониторинга конвейера для конвейера. Предварительная версия редактора конвейеров Lakeflow должна быть включена, чтобы включить страницу мониторинга конвейера. Если предварительная версия редактора включена, новая страница мониторинга также включена по умолчанию.
Щелкните "Задания" и "Конвейеры".
Щелкните имя любого конвейера, чтобы просмотреть сведения о конвейере.
В верхней части страницы включите обновленный пользовательский интерфейс мониторинга с помощью переключателя новой страницы конвейера .
Ограничения и известные проблемы
Ознакомьтесь со следующими ограничениями и известными проблемами редактора конвейера ETL в Декларативных конвейерах Spark Lakeflow:
Боковая панель браузера рабочей области не фокусируется на конвейере, если начать с открытия файла в
explorationsпапке или записной книжке, так как эти файлы или записные книжки не являются частью определения исходного кода конвейера.Чтобы ввести режим фокусировки конвейера в браузере рабочей области, откройте файл, связанный с конвейером.
Предварительные версии данных не поддерживаются для обычных представлений.
Модули Python не обнаружены из UDF, даже если они находятся в вашей корневой папке или упомянуты в вашем
sys.path. Доступ к этим модулям можно получить, добавив путь кsys.pathвнутри UDF, например:sys.path.append(os.path.abspath(“/Workspace/Users/path/to/modules”))%pip installне поддерживается для файлов (тип ассета по умолчанию в новом редакторе). В параметрах можно добавить зависимости. См. раздел Пайплайн среда.В качестве альтернативы, можно продолжать использовать
%pip installиз записной книжки, связанной с конвейером, в определении исходного кода.
Часто задаваемые вопросы
Почему файлы и не записные книжки используются для исходного кода?
Выполнение ноутбуков, основанных на ячейках, несовместимо с конвейерами. Стандартные функции записных книжек либо отключены, либо изменяются при работе с конвейерами, что приводит к путанице для пользователей, знакомых с поведением записной книжки.
В редакторе Pipelines Lakeflow редактор файлов используется в качестве основы для редактора первого класса для конвейеров. Функции специально нацелены на конвейеры, как например таблица выполнения
значок таблицы выполнения, а не на чрезмерное изменение знакомых функций с другим поведением.Можно ли использовать записные книжки в качестве исходного кода?
Да, вы можете. Однако некоторые функции, такие как Запуск таблицы или
Запуск файла, отсутствуют.Если у вас есть существующий конвейер с использованием ноутбуков, он по-прежнему работает в новом редакторе. Однако Databricks рекомендует переключиться на файлы для новых конвейеров данных.
Как добавить существующий код в только что созданный конвейер?
В новый конвейер можно добавить существующие файлы исходного кода. Чтобы добавить папку с существующими файлами, выполните следующие действия.
- Нажмите кнопку "Параметры".
- В разделе "Исходный код" щелкните "Настройка путей".
- Щелкните "Добавить путь " и выберите папку для существующих файлов.
- Нажмите кнопку Сохранить.
Вы также можете добавить отдельные файлы:
- Щелкните Все файлы в браузере активов конвейера.
- Перейдите к файлу, щелкните нажмите кнопку "Включить в конвейер".
Рассмотрите возможность перемещения этих файлов в корневую папку конвейера. Если они находятся вне корневой папки конвейера, они отображаются в разделе "Внешние файлы ".
Можно ли управлять исходным кодом конвейера в Git?
Вы можете управлять источником конвейера в Git, выбрав папку Git при первоначальном создании конвейера.
Замечание
Управление источником в папке Git добавляет управление версиями для исходного кода. Однако для управления версиями конфигурации Databricks рекомендует использовать пакеты ресурсов Databricks для определения конфигурации конвейера в файлах конфигурации пакета, которые могут храниться в Git (или другой системе управления версиями). Дополнительные сведения см. в разделе "Что такое пакеты ресурсов Databricks?".
Если вы изначально не создали конвейер в папке Git, можно переместить источник в папку Git. Databricks рекомендует использовать действие редактора для перемещения всей корневой папки в папку Git. Это обновляет все параметры соответствующим образом. См. корневую папку.
Чтобы переместить корневую папку в папку Git в обозревателе ресурсов конвейера:
- Щелкните .
- Щелкните Переместить корневую папку.
- Выберите новое расположение корневой папки и нажмите кнопку "Переместить".
Дополнительные сведения см. в разделе "Корневая папка ".
После перемещения вы увидите знакомый значок Git рядом с именем корневой папки.
Это важно
Чтобы переместить корневую папку конвейера, используйте браузер ресурсов конвейера и описанные выше действия. Перемещение другим способом нарушает конфигурации конвейера, и вам необходимо вручную настроить правильный путь к папке в параметрах.
- Щелкните
Можно ли использовать несколько конвейеров в одной корневой папке?
Вы можете, но Databricks рекомендует только один конвейер для каждой корневой папки.
Когда следует запустить тестовый запуск?
Нажмите кнопку "Сухой запуск" , чтобы проверить код, не обновляя таблицы.
Когда следует использовать временные представления и когда следует использовать материализованные представления в коде?
Используйте временные представления, если вы не хотите материализовать данные. Например, это шаг в последовательности шагов по подготовке данных, прежде чем он готов к материализации с помощью потоковой таблицы или материализованного представления, зарегистрированного в каталоге.