Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Вы создаете и развертываете конвейер ETL (извлечение, преобразование и загрузка) с использованием захвата измененных данных (CDC), Lakeflow Pipelines для оркестрации данных и Auto Loader. Конвейер ETL реализует шаги для чтения данных из исходных систем, преобразования этих данных на основе требований, таких как проверки качества данных и отмена дублирования данных, а также запись данных в целевую систему, например хранилище данных или озеро данных.
В этом руководстве вы будете использовать данные из customers таблицы в базе данных MySQL для:
- Извлеките изменения из транзакционной базы данных с помощью Debezium или другого средства и сохраните их в облачное хранилище объектов (S3, ADLS или GCS). В этом руководстве вы пропускаете настройку внешней системы CDC и вместо этого создаются фиктивные данные, чтобы упростить руководство.
- Используйте автозагрузчик для добавочной загрузки сообщений из облачного хранилища объектов и хранения необработанных сообщений в
customers_cdcтаблице. Автозагрузчик определяет схему и обрабатывает эволюцию схемы. - Создайте таблицу
customers_cdc_cleanдля проверки качества данных с помощью ожиданий. Например,idникогда не должно бытьnull, потому что оно используется для выполнения операций upsert. - Выполните операцию
AUTO CDC ... INTOна очищенных данных CDC, чтобы внести изменения в итоговую таблицуcustomers. - Покажите, как конвейер может создать таблицу типа 2 медленно меняющегося измерения (SCD2), чтобы отслеживать все изменения.
Цель состоит в том, чтобы принять необработанные данные практически в реальном времени и создать таблицу для вашей группы аналитиков, обеспечивая качество данных.
В этом руководстве используется архитектура medallion Lakehouse, в которой происходят получение необработанных данных через бронзовый слой, очистка и проверка данных с серебряным слоем, а также применение измерительного моделирования и агрегирование с помощью золотого слоя. Дополнительные сведения см. в статье об архитектуре medallion lakehouse.
Реализованный поток выглядит следующим образом:
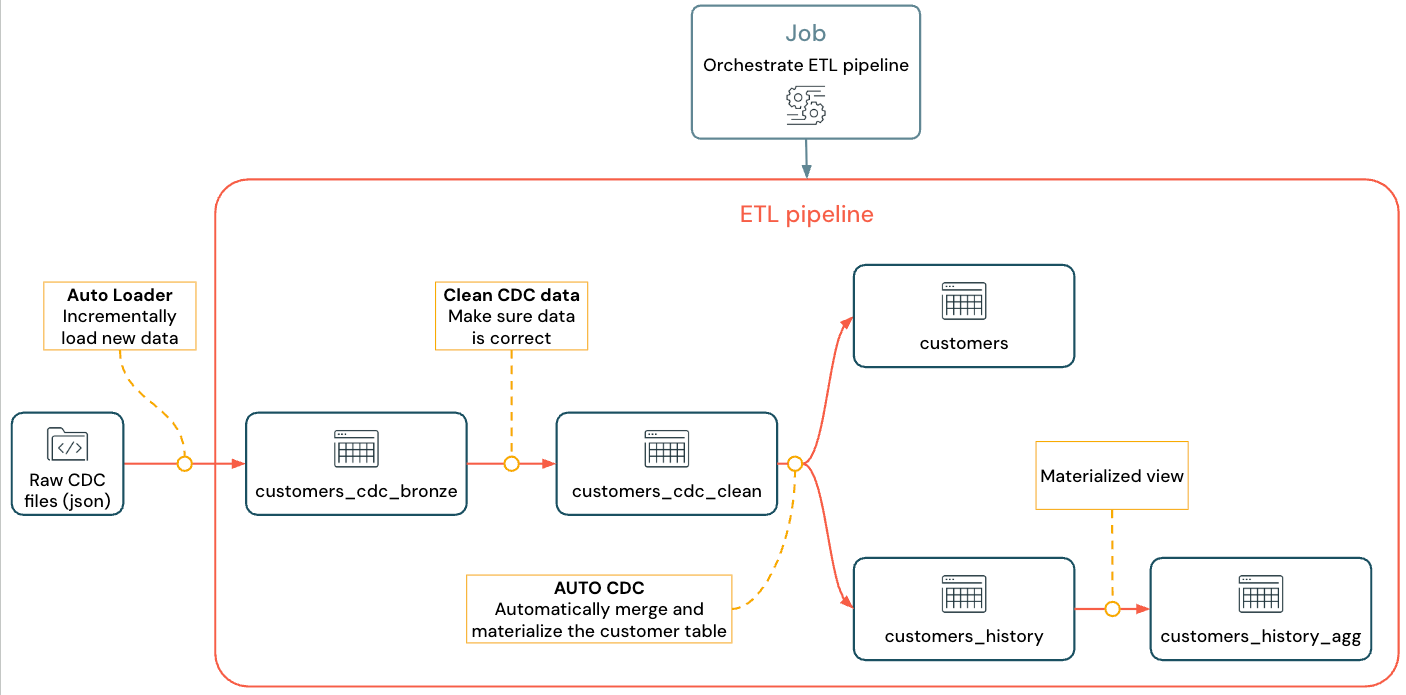
Дополнительные сведения о конвейерах, Auto Loader и CDC см. в разделах Spark Declarative Pipelines, Что такое Auto Loader? и Отслеживание изменений данных и моментальные снимки
Требования
Чтобы завершить работу с этим руководством, необходимо выполнить следующие требования:
- Unity Catalog включен в вашей рабочей области.
- Бессерверные вычисления доступны в рабочей области (включена по умолчанию в рабочих областях с каталогом Unity). Бессерверные конвейеры Lakeflow недоступны во всех регионах рабочей области. См. сведения о функциях с ограниченной региональной доступностью для доступных регионов. Если бессерверные вычисления недоступны, шаги должны работать с вычислительными ресурсами по умолчанию для рабочей области.
- Разрешение на создание вычислительного ресурса или доступ к вычислительному ресурсу.
- Разрешения на создание новой схемы в каталоге. Необходимые разрешения:
USE CATALOGиCREATE SCHEMA. - Разрешения на создание нового тома в существующей схеме. Необходимые разрешения:
USE SCHEMAиCREATE VOLUME. - Полный набор привилегий, необходимых для создания, запуска, обновления и просмотра конвейеров и их выходных данных, см. в статье "Управление удостоверениями, разрешениями и привилегиями для конвейеров".
Изменение записи данных в конвейере ETL
Запись измененных данных (CDC) — это процесс, который записывает изменения записей, сделанных в транзакционной базе данных (например, MySQL или PostgreSQL) или хранилище данных. CDC фиксирует такие операции, как удаление данных, добавление и обновление, обычно в виде потока для повторной материализации таблиц в внешних системах. CDC обеспечивает добавочную загрузку при устранении необходимости в массовой загрузке обновлений.
Замечание
Чтобы упростить это руководство, пропустите настройку внешней системы CDC. Предположим, что он выполняет и сохраняет данные CDC в виде JSON-файлов в облачном хранилище объектов (S3, ADLS или GCS). В этом руководстве используется библиотека Faker для генерации данных, используемых в руководстве.
Запись CDC
Доступны различные средства CDC. Одним из ведущих решений открытый код является Debezium, но другие реализации, которые упрощают создание источников данных, таких как Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate и AWS DMS.
В этом руководстве вы используете данные CDC из внешней системы, например Debezium или DMS. Debezium фиксирует каждую измененную строку. Обычно он отправляет журнал изменений данных в разделы Kafka или сохраняет их в виде файлов.
Необходимо получить сведения CDC из таблицы customers (формат JSON), убедиться, что они правильные, а затем материализовать таблицу клиентов в "Lakehouse".
Входные данные CDC из Debezium
Для каждого изменения вы получите сообщение JSON, содержащее все поля обновляемой строки (id, , firstname, lastnameemail). address Сообщение также содержит дополнительные метаданные:
-
operation: код операции, обычно (DELETE,APPEND,UPDATE). -
operation_date: метка даты и времени записи для каждого операционного действия.
Такие инструменты, как Debezium, могут создавать более сложные выходные данные, например, показывать значение строки до изменения, но в этом руководстве они опущены для упрощения.
Шаг 1. Создание конвейера
Создайте конвейер ETL для запроса источника данных CDC и создания таблиц в рабочей области.
В рабочей области щелкните
 Новый на боковой панели и выберите конвейер ETL. Откроется редактор конвейера с именем конвейера по умолчанию, например
Новый на боковой панели и выберите конвейер ETL. Откроется редактор конвейера с именем конвейера по умолчанию, например New Pipeline <date> <time>.Выберите имя и введите описательное имя, например
Pipelines with CDC tutorial.Справа от имени щелкните каталог и схему, чтобы выбрать значения по умолчанию, для которых у вас есть разрешения на запись.
Этот каталог и схема используются по умолчанию, если в коде не указан каталог или схема. Код может записываться в любой каталог или схему, указав полный путь. В этом руководстве используются значения по умолчанию, указанные здесь.
(Необязательно) В исходном файле
my_transformation, созданном для вас, выберите Python или SQL из раскрывающегося списка языков, чтобы задать язык для файла.Щелкните
 Используйте пример кода.
Используйте пример кода.
Откроется редактор Конвейеров Lakeflow с примерами файлов в конвейере. Вы добавите собственные файлы преобразования в последующих шагах. Затем настройте образцы данных для импорта для урока.
Шаг 2. Создание примера данных для импорта в этом руководстве
Этот шаг не нужен, если вы импортируете собственные данные из существующего источника. Для этого руководства создайте поддельные данные в качестве примера для руководства. Создайте записную книжку для запуска скрипта создания данных Python. Этот код необходимо запустить только один раз, чтобы создать тестовые данные, поэтому создайте его в папке explorations конвейера, которая не используется в процессе обновления конвейера.
Замечание
Этот код использует Faker для генерации образцов данных CDC. Faker доступен для автоматической установки, поэтому в этом руководстве используется %pip install faker. Вы также можете установить зависимость от faker для блокнота. См. статью "Добавление зависимостей в записную книжку".
В редакторе конвейеров Lakeflow, в боковой панели браузера активов слева от редактора, щелкните
Добавьте, затем выберите "Исследование".Присвойте ему Name, например
Setup data, выберите Python. Вы можете оставить папку назначения по умолчанию, которая является новойexplorationsпапкой.Нажмите кнопку "Создать". При этом создается записная книжка в новой папке.
Введите следующий код в первой ячейке. Необходимо изменить определение
<my_catalog><my_schema>и соответствовать каталогу по умолчанию и схеме, выбранной в предыдущей процедуре:%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Чтобы создать набор данных, используемый в руководстве, введите SHIFT + ВВОД , чтобы запустить код:
Необязательно. Чтобы просмотреть данные, используемые в этом руководстве, введите следующий код в следующей ячейке и запустите код. Обновите каталог и схему, чтобы он соответствовал пути из предыдущего кода.
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Это создает большой набор данных (с поддельными данными CDC), который можно использовать в остальной части руководства. В следующем шаге данные загружаются с помощью Auto Loader.
Шаг 3. Пошаговая загрузка данных с помощью Auto Loader
Следующим шагом является импорт необработанных данных из поддельного облачного хранилища в бронзовый слой.
Это может быть сложно по нескольким причинам, так как вы должны:
- Работайте в большом масштабе, потенциально обрабатывая миллионы небольших файлов.
- Определить схему и тип JSON.
- Обработка плохих записей с неправильной схемой JSON.
- Обратите внимание на эволюцию схемы (например, новый столбец в таблице клиента).
Автозагрузчик упрощает процесс приема данных, включая автоматическое определение структуры и адаптацию схемы, одновременно обеспечивая масштабирование для обработки миллионов входящих файлов. Автозагрузчик доступен в Python с помощью cloudFiles и в SQL с помощью SELECT * FROM STREAM read_files(...) и может использоваться с различными форматами (JSON, CSV, Apache Avro и т. д.):
Определение таблицы в виде потоковой таблицы гарантирует, что вы используете только новые входящие данные. Если вы не определяете ее как потоковую таблицу, она сканирует и получает все доступные данные. Дополнительные сведения см. в таблицах потоковой передачи .
Чтобы принять входящие данные CDC с помощью автозагрузчика, скопируйте и вставьте следующий код в файл кода, созданный с помощью конвейера (вызывается
my_transformation.pyилиmy_transformation.sql). Вы можете использовать Python или SQL на основе языка, выбранного при создании конвейера. Обязательно замените<catalog>и<schema>на те, которые настроены вами как умолчания для конвейера.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" )Щелкните
 Запустите файл или запустите конвейер чтобы начать обновление подключенного конвейера. С одним исходным файлом в конвейере они функционально эквивалентны.
Запустите файл или запустите конвейер чтобы начать обновление подключенного конвейера. С одним исходным файлом в конвейере они функционально эквивалентны.
По завершении обновления в редактор передается новая информация о вашем конвейере данных.
- Граф конвейера, который также называется направленным ациклическим графом (DAG), на боковой панели справа от кода, отображает одну таблицу.
customers_cdc_bronze - Сводка обновления отображается в верхней части браузера ресурсов конвейера.
- Сведения о созданной таблице отображаются на нижней панели и можно просматривать данные из таблицы, выбрав ее.
Это необработанные данные бронзового слоя, импортированные из облачного хранилища. На следующем шаге очистите данные для создания таблицы Silver Layer.
Шаг 4. Очистка и ожидания для отслеживания качества данных
После определения бронзового слоя создайте серебряный слой, добавив ожидания для контроля качества данных. Проверьте следующие условия:
- Идентификатор никогда не должен быть
null. - Тип операции CDC должен быть допустимым.
- JSON должен быть правильно прочитан автозагрузчиком.
Строки, которые не соответствуют этим условиям, удаляются.
Дополнительные сведения см. в статье "Управление качеством данных с ожиданиями конвейера ".
На боковой панели браузера ресурсов конвейера нажмите
Добавить, а затем Преобразование.Введите Name (например,
customers_silver) и выберите язык (Python или SQL) для файла исходного кода..pyРасширение.sqlдобавляется на основе выбранного языка. Вы можете смешивать и сопоставлять языки в конвейере, поэтому вы можете выбрать один из них для этого шага.Чтобы создать серебряный слой с очищенной таблицей и наложить ограничения, скопируйте и вставьте следующий код в новый файл (выберите Python или SQL на основе языка файла).
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Щелкните
Запустите файл или запустите конвейер чтобы начать обновление подключенного конвейера.Так как теперь есть два исходных файла, они не делают то же самое, но в этом случае выходные данные одинаковы.
- Запуск конвейера выполняет весь конвейер, включая код из шага 3. Если бы ваши входные данные обновлялись, это привело бы к учету любых изменений из этого источника в бронзовом слое. Это не выполняет код из этапа подготовки данных, так как это находится в папке экспериментов и не является частью источника для вашего конвейера.
- Запуск файла запускает только текущий исходный файл. В этом случае без обновления ваших входных данных это создает серебряные данные из кэшированной бронзовой таблицы. Было бы полезно запустить только этот файл для ускорения итерации при создании или редактировании кода конвейера.
После завершения обновления вы увидите, что график конвейера теперь отображает две таблицы (с серебряным слоем в зависимости от бронзового слоя), а на нижней панели отображаются сведения для обеих таблиц. В верхней части браузера активов конвейера теперь отображается время нескольких запусков, но сведения приводятся только для самого последнего запуска.
Затем создайте финальную версию золотого слоя таблицы customers.
Шаг 5. Материализация таблицы клиентов с помощью потока AUTO CDC
До этого момента таблицы просто передавали данные CDC на каждом этапе. Теперь создайте customers таблицу, чтобы она содержала как актуальное представление, так и была репликой оригинальной таблицы, а не списком операций CDC, которые его создали.
Это нетривиальное для реализации вручную. Необходимо учитывать такие вещи, как дедупликация данных, чтобы сохранить последнюю строку.
Однако конвейеры решают эти проблемы с помощью операции AUTO CDC.
На боковой панели браузера ресурсов конвейера щелкните
Добавление и преобразование.Введите Name и выберите язык (Python или SQL) для нового файла исходного кода. Вы можете снова выбрать любой язык для этого шага, но использовать правильный код ниже.
Чтобы обработать данные CDC с помощью
AUTO CDC, скопируйте и вставьте следующий код в новый файл.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Щелкните
Запустите файл , чтобы запустить обновление подключенного конвейера.
После завершения обновления вы увидите, что график конвейера отображает 3 таблицы, переходя от бронзы к серебру до золота.
Шаг 6. Отслеживание журнала обновлений с медленно изменяющимся типом измерения 2 (SCD2)
Часто требуется создать таблицу для отслеживания всех изменений, в результате APPEND, UPDATE и DELETE.
- Вы хотите сохранить историю всех изменений в таблице.
- Возможность трассировки: вы хотите увидеть, какая операция произошла.
SCD2 с конвейерами Lakeflow
Delta поддерживает поток данных изменений (CDF), а table_change может запрашивать изменения таблицы в SQL и Python. Однако основной вариант использования CDF заключается в том, чтобы записывать изменения в конвейере, а не создавать полное представление изменений таблицы с самого начала.
Реализация становится особенно сложной, если у вас есть неупорядоченные события. Если необходимо выполнить последовательность изменений по метке времени и получить изменения, которые произошли в прошлом, необходимо добавить новую запись в таблицу SCD и обновить предыдущие записи.
Конвейеры Lakeflow удаляют эту сложность. Вы можете создать отдельную таблицу, содержащую все изменения с начала времени, которая будет поддерживаться конвейером автоматически. Эта таблица поддерживает оптимизацию макета данных, например кластеризацию жидкости и автоматическую обработку записей вне порядка на основе _sequence_by. См. раздел "Использование кластеризации жидкости" для таблиц.
Чтобы создать таблицу SCD2, используйте параметр STORED AS SCD TYPE 2 в SQL или stored_as_scd_type="2" в Python.
Замечание
Кроме того, можно ограничить столбцы, которые функция отслеживает, с помощью параметра: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
На боковой панели браузера ресурсов конвейера щелкните
Добавление и преобразование.Введите Name и выберите язык (Python или SQL) для нового файла исходного кода.
Скопируйте и вставьте следующий код в новый файл.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Щелкните
Запустите файл , чтобы запустить обновление подключенного конвейера.
После завершения обновления диаграмма конвейера включает новую customers_history таблицу, которая также зависит от серебряной таблицы, а на нижней панели отображаются сведения обо всех 4 таблицах.
Шаг 7. Создание материализованного представления, которое отслеживает, кто наиболее часто менял свои данные.
customers_history Таблица содержит все исторические изменения, внесенные пользователем в информацию. Создайте простое материализованное представление на золотом слое, которое отслеживает, кто изменил свою информацию больше всего. Это можно использовать для анализа обнаружения мошенничества или рекомендаций пользователей в реальном мире. Кроме того, применение изменений с помощью SCD2 уже удалило дубликаты, поэтому вы можете напрямую подсчитать количество строк по идентификатору пользователя.
На боковой панели браузера ресурсов конвейера щелкните
Добавление и преобразование.Введите Name и выберите язык (Python или SQL) для нового файла исходного кода.
Скопируйте и вставьте следующий код в новый исходный файл.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count_distinct("address").alias("address_count"), count_distinct("email").alias("email_count"), count_distinct("firstname").alias("firstname_count"), count_distinct("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count(distinct address) as address_count, count(distinct email) AS email_count, count(distinct firstname) AS firstname_count, count(distinct lastname) AS lastname_count FROM customers_history GROUP BY idЩелкните
Запустите файл , чтобы запустить обновление подключенного конвейера.
После завершения обновления в графе конвейера будет новая таблица, которая зависит от customers_history таблицы, и ее можно просмотреть на нижней панели. Теперь конвейер завершен. Вы можете протестировать его, выполнив полный конвейер выполнения. Единственное, что осталось, — запланировать регулярное обновление конвейера.
Шаг 8. Создание задания для запуска конвейера ETL
Затем создайте рабочий процесс, чтобы автоматизировать прием, обработку и анализ данных в конвейере с помощью задания Databricks.
- В верхней части редактора нажмите кнопку "Расписание ".
- Если появится диалоговое окно "Расписания" , нажмите кнопку "Добавить расписание".
- Откроется диалоговое окно создания расписания , в котором можно создать задание для запуска конвейера по расписанию.
- При необходимости присвойте заданию имя.
- По умолчанию расписание выполняется один раз в день. Вы можете принять это значение по умолчанию или задать собственное расписание. При выборе дополнительно можно задать определенное время выполнения задания. Выбор дополнительных параметров позволяет создавать уведомления при выполнении задания.
- Нажмите кнопку "Создать", чтобы применить изменения и создать задание.
Теперь задание будет выполняться ежедневно, чтобы поддерживать актуальность вашего потока обработки данных. Вы можете снова выбрать расписание , чтобы просмотреть список расписаний. Вы можете управлять расписаниями для конвейера из этого диалогового окна, включая добавление, редактирование или удаление расписаний.
Щелкнув имя расписания (или задания), вы перейдете на страницу задания в списке заданий и конвейеров . Здесь вы можете просмотреть сведения о выполнении заданий, включая журнал запусков, или запустить задание сразу с помощью кнопки "Запустить сейчас ".
Дополнительные сведения о выполнении заданий см. в разделе "Мониторинг заданий Lakeflow ".
Дополнительные ресурсы
- Декларативные конвейеры Spark
- Руководство. Создание конвейера ETL с помощью конвейеров Lakeflow
- Слежение за изменением данных и моментальные снимки данных
- API-интерфейсы AUTO CDC: упрощение отслеживания измененных данных с помощью конвейеров
- Преобразование конвейера в проект пакета
- Что такое автозагрузчик?