Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье описывается, как использовать MLOps на платформе Databricks для оптимизации производительности и долгосрочной эффективности систем машинного обучения (ML). Она содержит общие рекомендации по архитектуре MLOps и описывает обобщенный рабочий процесс с помощью платформы Databricks, которую можно использовать в качестве модели для процесса разработки машинного обучения в рабочей среде. Изменения этого рабочего процесса для приложений LLMOps см. в рабочих процессах LLMOps.
Дополнительные сведения см. в статье "Большая книга MLOps".
Что собой представляет MLOps?
MLOps — это набор процессов и автоматизированных шагов по управлению кодом, данными и моделями для повышения производительности, стабильности и долгосрочной эффективности систем машинного обучения. Он объединяет DevOps, DataOps и ModelOps.
Ресурсы ML, такие как код, данные и модели, разрабатываются поэтапно: от ранних этапов разработки, не имеющих жестких ограничений доступа и не подвергающихся тщательному тестированию, через промежуточный этап тестирования до конечного этапа производства, который строго контролируется. Платформа Databricks позволяет управлять этими ресурсами на одной платформе с помощью единого управления доступом. Вы можете разрабатывать приложения для работы с данными и приложения ML на одной платформе, что снижает риски и задержки, связанные с перемещением данных.
Общие рекомендации по работе с MLOps
В этом разделе содержатся некоторые общие рекомендации по использованию MLOps в Databricks со ссылками на дополнительные сведения.
Создание отдельной среды для каждого этапа
Среда выполнения — это место, где модели и данные создаются или используются кодом. Каждая среда выполнения состоит из вычислительных экземпляров, их сред выполнения и библиотек, а также автоматических заданий.
В Databricks рекомендуется создавать отдельные среды для разных этапов разработки кода ML и модели с четко определенными переходами между этапами. Рабочий процесс, описанный в этой статье, следует этому процессу. При этом используются распространенные имена этапов:
Другие конфигурации также можно использовать для удовлетворения конкретных потребностей вашей организации.
Управление доступом и управление версиями
Управление доступом и управление версиями — это ключевые аспекты любого процесса, связанного с выполнением операций с программным обеспечением. В Databricks рекомендуется следующее:
- Использовать Git для управления версиями. Конвейеры и код должны храниться в Git для управления версиями. Перемещение логики ML между этапами можно интерпретировать как перемещение кода из ветви разработки в промежуточную ветвь и в ветвь выпуска. Используйте папки Git Databricks для интеграции с поставщиком Git и синхронизации записных книжек и исходного кода с рабочими областями Databricks. Databricks также предоставляет дополнительные инструменты для интеграции с Git и контроля версий; см. Варианты использования инструментов разработчика.
- Храните данные в архитектуре lakehouse с помощью таблиц Delta. Данные должны храниться в архитектуре типa lakehouse в вашем облачном аккаунте. Как необработанные данные, так и таблицы признаков должны храниться в виде таблиц Delta с возможностью управления доступом, чтобы можно было определить, кто может их читать и изменять.
- Управление разработкой моделей с помощью MLflow. Вы можете использовать MLflow для отслеживания процесса разработки модели и сохранения моментальных снимков кода, параметров модели, метрик и других метаданных.
- Используйте модели в каталоге Unity для управления жизненным циклом модели. Используйте модели в каталоге Unity для управления управлением версиями моделей, управлением и состоянием развертывания.
Развертывание кода, а не моделей
В большинстве случаев Databricks рекомендует в процессе разработки ML повышать уровень кода, а не модели, перемещая его из одной среды в другую. Перемещение ресурсов проекта таким образом гарантирует, что весь код в процессе разработки ML проходит одни и те же процессы проверки кода и интеграционного тестирования. Также гарантируется, что продуктовая версия модели обучена с использованием продуктового кода. Более подробное описание вариантов и компромиссов см. в статье Шаблоны развертывания модели.
Рекомендуемый рабочий процесс MLOps
В следующих разделах описывается типичный рабочий процесс MLOps, охватывающий каждый из трех этапов: разработка, стадия тестирования и продакшн.
В этом разделе термины "специалист по обработке и анализу данных" и "инженер ML" используются как архетипические персонажи; конкретные роли и обязанности в рабочем процессе MLOps будут отличаться в разных командах и организациях.
Этап разработки
Основное внимание на этапе разработки уделяется экспериментированию. Специалисты по обработке и анализу данных разрабатывают признаки и модели и выполняют эксперименты для оптимизации производительности модели. Выходные данные процесса разработки — это код конвейера ML, который может включать вычисления признаков, обучение модели, вывод и мониторинг.
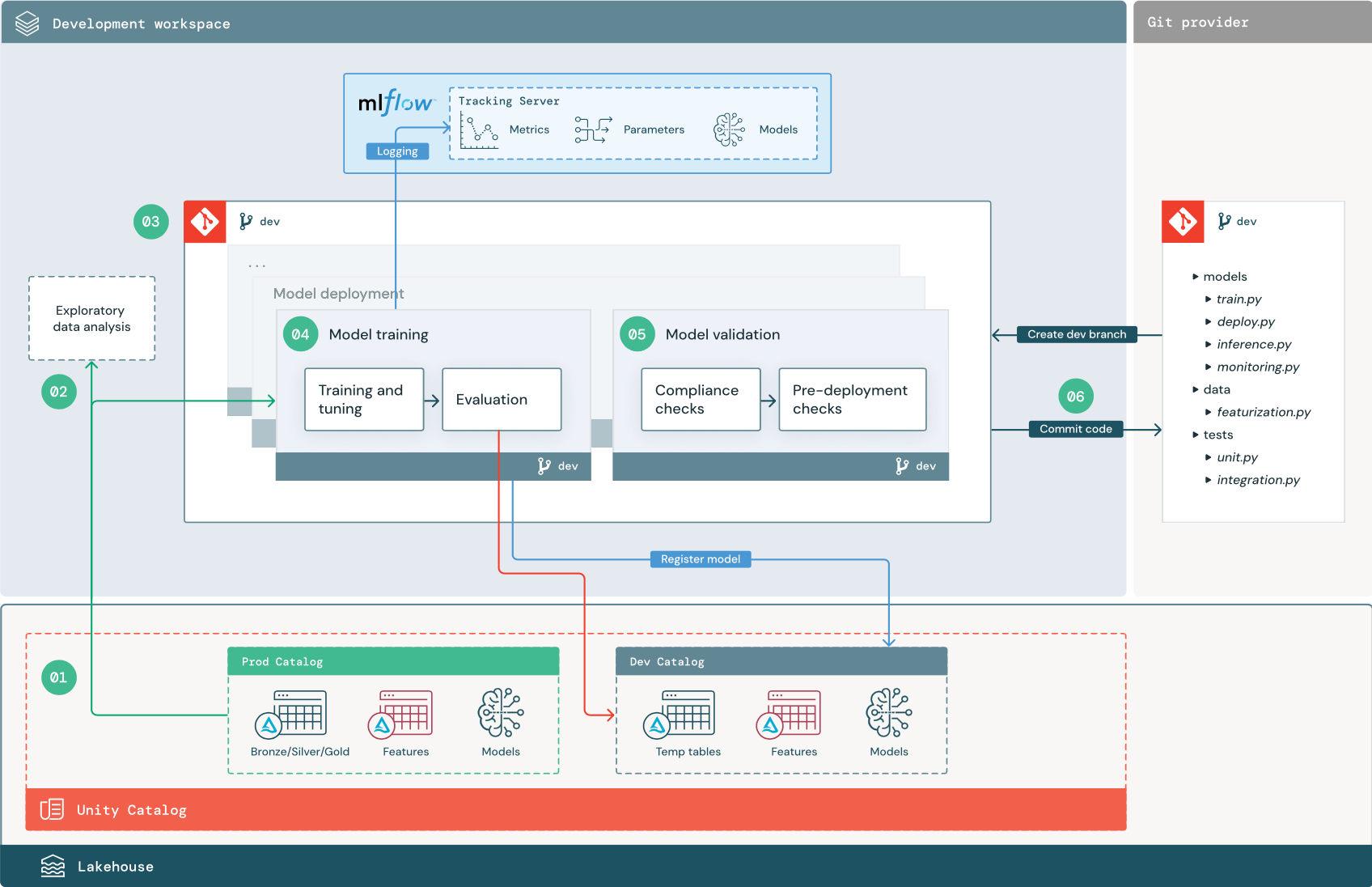
Пронумерованные шаги соответствуют числам, указанным на схеме.
1. Источники данных
Среда разработки представлена каталогом разработки в каталоге Unity. Специалисты по обработке и анализу данных имеют доступ на чтение и запись в каталог разработки, так как они создают временные данные и таблицы компонентов в рабочей области разработки. Модели, созданные на этапе разработки, регистрируются в каталоге разработчиков.
В идеале специалисты по обработке и анализу данных, работающие в рабочей области разработки, также имеют доступ только для чтения к рабочим данным в каталоге prod. Предоставление специалистам по обработке и анализу данных доступа к рабочим данным, таблицам вывода и таблицам метрик в каталоге prod позволяет им анализировать текущие прогнозы и производительность рабочей модели. Специалисты по обработке и анализу данных также должны загружать рабочие модели для экспериментирования и анализа.
Если невозможно предоставить доступ только для чтения к каталогу prod, моментальный снимок производственных данных можно сохранить в каталог разработчиков, чтобы позволить научным сотрудникам по данным разрабатывать и оценивать проектный код.
2. Разведочный анализ данных
Специалисты по обработке и анализу данных изучают и анализ данных в интерактивном итеративном процессе с помощью записных книжек. Цель состоит в том, чтобы оценить, имеют ли доступные данные потенциал для решения бизнес-проблемы. На этом этапе дата-сайентист начинает определять этапы подготовки и фичеризации данных для обучения модели. Этот нерегламентированный процесс обычно не является частью конвейера, который будет развернут в других средах выполнения.
AutoML ускоряет этот процесс путем создания базовых моделей для набора данных. AutoML выполняет и записывает набор пробных версий и предоставляет записную книжку Python с исходным кодом для каждого пробного запуска, чтобы можно было просматривать, воспроизводить и изменять код. AutoML также вычисляет сводную статистику по набору данных и сохраняет эти сведения в записной книжке, которую можно просмотреть.
3. Код
Репозиторий кода содержит все конвейеры, модули и другие файлы проекта для проекта машинного обучения. Специалисты по обработке и анализу данных создают новые или обновленные конвейеры в ветви разработки (dev) репозитория проекта. Начиная с EDA и начальных этапов проекта, специалисты по обработке и анализу данных должны работать в репозитории для совместного использования кода и отслеживания изменений.
4. Обучение модели (разработка)
Специалисты по данным разрабатывают поток обучения модели в среде разработки, используя таблицы из каталогов разработки или продакшн.
Этот конвейер включает две задачи:
Обучение и настройка. Процесс обучения фиксирует параметры модели, метрики и артефакты на сервере отслеживания MLflow. После обучения и настройки гиперпараметров окончательный модельный артефакт регистрируется на сервере отслеживания, чтобы записать связь между моделью, входными данными, на которые она была обучена, и кодом, использованным для ее создания.
Оценка. Оцените качество модели, протестировав удерживаемые данные. Результаты этих тестов записываются на сервер отслеживания MLflow. Цель оценки заключается в том, чтобы определить, работает ли недавно разработанная модель лучше, чем текущая рабочая модель. Учитывая достаточные разрешения, любую производственную модель, зарегистрированную в каталоге производства, можно загрузить в рабочую область разработки и сопоставить с недавно обученной моделью.
Если требования к управлению вашей организации включают дополнительные сведения о модели, ее можно сохранить с помощью отслеживания MLflow. Типичные артефакты — это обычные текстовые описания и интерпретации модели, такие как графики, созданные с помощью SHAP. Конкретные требования к управлению могут поступать от сотрудника по управлению данными или заинтересованных лиц бизнеса.
Выходные данные конвейера обучения модели — это артефакт модели машинного обучения, хранящийся на сервере отслеживания MLflow для среды разработки. Если конвейер выполняется в области стадирования или релизной области, артефакт модели сохраняется на сервере отслеживания MLflow для этой области.
По завершении обучения модели зарегистрируйте модель в каталоге Unity. Настройте код конвейера, чтобы зарегистрировать модель в каталоге, соответствующем среде, в которой был выполнен конвейер модели; в этом примере каталог разработки.
Рекомендуемая архитектура позволяет развернуть рабочий процесс с несколькими задачами Databricks, в котором первая задача — конвейер обучения модели, а затем задачи проверки и развертывания моделей. Задача обучения модели дает универсальный код ресурса (URI) модели, который может использовать задача проверки модели. Вы можете использовать значения задач для передачи этого URI в модель.
5. Проверка и развертывание модели (разработка)
Помимо конвейера обучения модели, в среде разработки разрабатываются другие конвейеры, такие как проверка моделей и конвейеры развертывания модели.
Проверка модели. Конвейер проверки модели принимает универсальный код ресурса (URI) модели из конвейера обучения модели, загружает модель из каталога Unity и выполняет проверки.
Проверки зависят от контекста. Они могут включать основные проверки, такие как подтверждение формата и необходимые метаданные, а также более сложные проверки, которые могут потребоваться для строго регулируемых отраслей, таких как предопределенные проверки соответствия и подтверждение производительности модели на выбранных срезах данных.
Основная функция конвейера проверки модели — определить, должна ли модель перейти к шагу развертывания. Если модель проходит предразвертывательную проверку, ей может быть присвоен псевдоним "Challenger" в каталоге Unity. Если проверка завершается ошибкой, процесс завершается. Рабочий процесс можно настроить для уведомления пользователей о сбое проверки. См. , чтобы добавить уведомления к заданию.
Развертывание модели. Конвейер развертывания модели обычно либо напрямую повышает недавно обученную модель "Challenger" до статуса "Чемпион" с помощью обновления псевдонима, либо облегчает сравнение между существующей моделью "Чемпион" и новой моделью "Challenger". Этот конвейер также может настроить любую необходимую инфраструктуру вывода, например конечные точки службы моделей. Подробные сведения о шагах, связанных с конвейером развертывания модели, см. в разделе Production.
6. Код фиксации
После разработки кода для обучения, проверки, развертывания и других конвейеров инженер по обработке и анализу данных фиксирует изменения ветви разработки в системе управления версиями.
Этап подготовки
Основное внимание на этом этапе уделяется тестированию кода конвейера ML, чтобы убедиться, что он готов к промышленной эксплуатации. Весь код конвейера машинного обучения тестируется на этом этапе, включая код для обучения моделей, а также конвейеры проектирования функций, код вывода и т. д.
Инженеры ML создают конвейер CI для реализации модульных и интеграционных тестов, выполняемых на этом этапе. Выходные данные процесса подготовки — это релизная ветка, которая активирует систему CI/CD для запуска продакшен этапа.
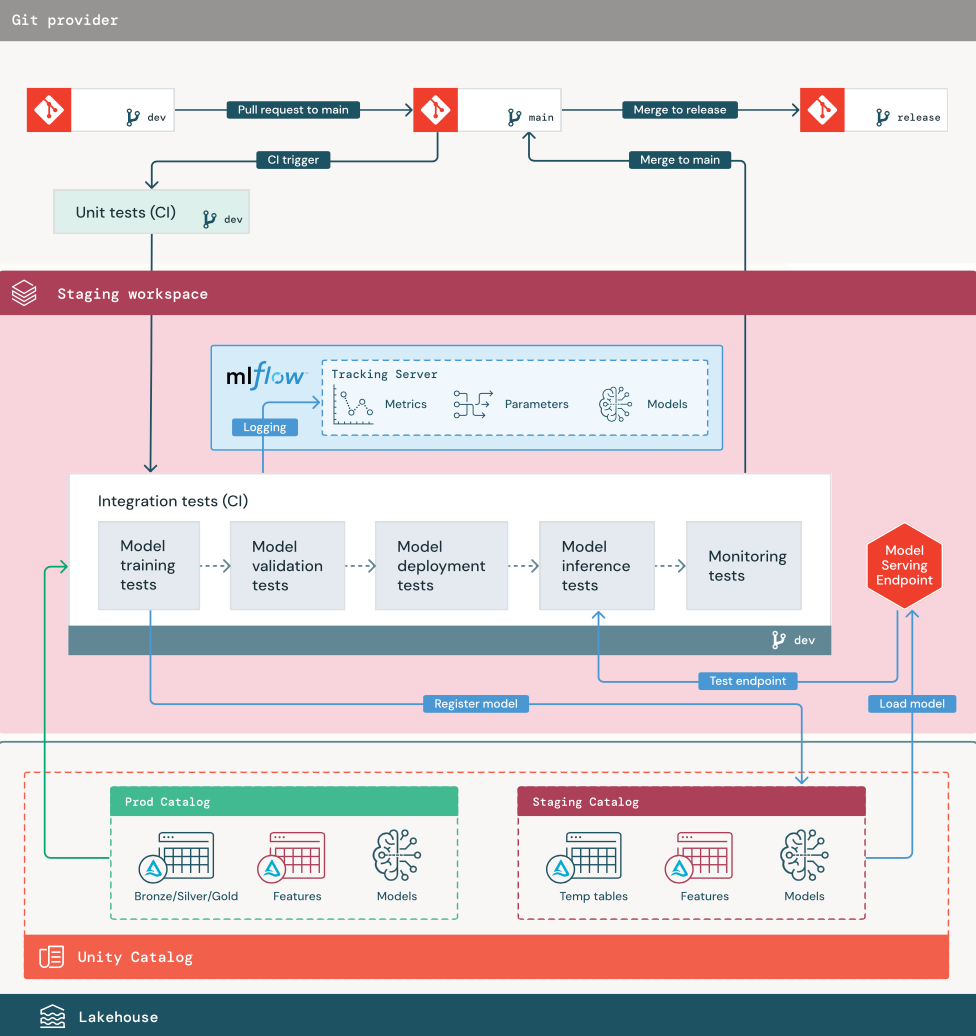
1. Данные
Промежуточная среда должна иметь собственный каталог в каталоге Unity для тестирования конвейеров машинного обучения и регистрации моделей в каталоге Unity. Этот каталог отображается как промежуточный каталог на схеме. Ресурсы, записанные в этот каталог, обычно временные и сохраняются только до завершения тестирования. В среде разработки также может потребоваться доступ к промежуточному каталогу для отладки.
2. Код слияния
Специалисты по обработке и анализу данных разрабатывают конвейер обучения модели в среде разработки с помощью таблиц из каталогов разработки или рабочей среды.
Пулл-реквест. Процесс развертывания начинается при создании pull запроса против главной ветви проекта в системе управления исходным кодом.
Модульные тесты (CI). Запрос pull request автоматически собирает исходный код и запускает модульные тесты. Если модульные тесты завершаются ошибкой, pull request отклоняется.
Модульные тесты являются частью процесса разработки программного обеспечения и постоянно выполняются и добавляются в базу кода во время разработки любого кода. Выполнение модульных тестов в рамках конвейера CI гарантирует, что изменения, внесенные в ветвь разработки, не нарушают существующую функциональность.
3. Интеграционные тесты (CI)
Затем процесс CI выполняет интеграционные тесты. Интеграционные тесты запускают все конвейеры (включая проектирование признаков, обучение моделей, вывод и мониторинг), чтобы убедиться в их правильной совместной работе. Промежуточная среда должна соответствовать производственной среде настолько близко, насколько это разумно.
При развертывании приложения машинного обучения с выводом в режиме реального времени необходимо создать и проверить инфраструктуру обслуживания в промежуточной среде. Это включает активацию конвейера развертывания модели, который создает конечную точку обслуживания в промежуточной среде и загружает модель.
Чтобы сократить время, необходимое для выполнения тестов интеграции, некоторые шаги могут сключиться на компромисс между точностью тестирования и скоростью или стоимостью. Например, если модели являются дорогостоящими или трудоемкими для обучения, можно использовать небольшие подмножества данных или выполнять меньше итераций обучения. Для обслуживания моделей в зависимости от рабочих требований можно выполнять полномасштабное нагрузочное тестирование в тестах интеграции или просто тестировать небольшие пакетные задания или запросы к временной конечной точке.
4. Слияние в промежуточную ветвь
Если все тесты проходят, новый код объединяется в основную ветвь проекта. Если тесты не проходят, система CI/CD должна уведомлять пользователей и публиковать результаты в pull request.
Можно запланировать периодические тесты интеграции в главной ветви. Это хорошая идея, если ветвь часто обновляется, и несколько пользователей одновременно создают pull requests.
5. Создание релизной ветки
После прохождения тестов CI и объединения ветви разработки в основную ветвь инженер машинного обучения создает релизную ветвь, которая запускает систему CI/CD для обновления заданий на продакшене.
Производственный этап
Инженеры машинного обучения имеют рабочую среду, в которой развертываются и выполняются конвейеры машинного обучения. Эти конвейеры активируют обучение модели, проверяют и развертывают новые версии модели, публикуют прогнозы в подчиненных таблицах или приложениях и отслеживают весь процесс, чтобы избежать снижения производительности и нестабильности.
Специалисты по обработке и анализу данных обычно не могут выполнять запись или вычисления в рабочей среде. Однако важно, чтобы они имели доступ к результатам тестирования, журналам, артефактам модели, состоянию производственного конвейера и таблицам мониторинга. Эта видимость позволяет им выявлять и диагностировать проблемы в производстве и сравнивать производительность новых моделей с текущими моделями в производстве. Вы можете предоставить специалистам по обработке и анализу данных доступ только для чтения к ресурсам в производственном каталоге в этих целях.

Пронумерованные шаги соответствуют числам, указанным на схеме.
Обучить модель
Этот конвейер может активироваться изменениями кода или автоматическими заданиями переобучения. На этом шаге таблицы из рабочего каталога используются для следующих действий.
Обучение и настройка. Во время процесса обучения логи записываются на сервер отслеживания MLflow в производственной среде. Эти журналы включают метрики модели, параметры, теги и саму модель. Если вы используете таблицы признаков, модель регистрируется в MLflow с помощью клиента Databricks Feature Store, который упаковывает модель с информацией о подстановке признаков, используемой во время вывода.
Во время разработки специалисты по обработке и анализу данных могут протестировать множество алгоритмов и гиперпараметров. В рабочем коде обучения обычно рассматриваются только наиболее распространенные варианты. Ограничение настройки таким образом экономит время и может уменьшить отклонение от настройки при автоматическом переобучении.
Если специалисты по обработке и анализу данных имеют доступ только для чтения к рабочему каталогу, они могут определить оптимальный набор гиперпараметров для модели. В этом случае конвейер обучения модели, развернутый в рабочей среде, можно выполнить с помощью выбранного набора гиперпараметров, обычно включенного в конвейер в виде файла конфигурации.
Оценка. Качество модели оценивается путем тестирования на резервных производственных данных. Результаты этих тестов записываются на сервер отслеживания MLflow. На этом шаге используются метрики оценки, указанные специалистами по обработке и анализу данных на этапе разработки. Эти метрики могут включать пользовательский код.
Регистрация модели. После завершения обучения модели артефакт модели сохраняется в качестве зарегистрированной версии модели по указанному пути в рабочем каталоге Unity Catalog. Задача обучения модели дает универсальный код ресурса (URI) модели, который может использовать задача проверки модели. Вы можете использовать значения задач для передачи этого URI в модель.
2. Проверка модели
Этот конвейер использует URI модели из шага 1 и загружает модель из каталога Unity. Затем он выполняет серию проверок. Эти проверки зависят от вашей организации и варианта использования, а также могут включать такие функции, как основные проверки формата и метаданные, оценки производительности для выбранных срезов данных и соответствие требованиям организации, таким как проверки соответствия тегам или документации.
Если модель успешно проходит все проверки, можно назначить псевдоним "Challenger" версии модели в каталоге Unity. Если модель не проходит все проверки, процесс завершается, и пользователи могут автоматически получать уведомления. Теги можно использовать для добавления атрибутов ключ-значение в зависимости от результатов этих проверок. Например, можно создать тег "model_validation_status" и задать значение "ОЖИДАНИЕ" на время выполнения тестов, а затем обновить его на "ПРОЙДЕНО" или "НЕУДАЧА" после завершения конвейера.
Поскольку модель зарегистрирована в Unity Catalog, учёные данных, работающие в среде разработки, могут загрузить эту версию модели из продуктового каталога, чтобы изучить, если модель не проходит проверку. Независимо от результата результаты записываются в зарегистрированную модель в рабочем каталоге с помощью заметок для версии модели.
3. Развертывание модели
Как и конвейер проверки, конвейер развертывания модели зависит от организации и варианта использования. В этом разделе предполагается, что вы назначили только что проверенную модель псевдонимом Challenger и что существующую рабочую модель назначили псевдоним "Чемпион". Перед развертыванием новой модели первым шагом является подтверждение того, что она работает как минимум так же хорошо, как и текущая рабочая модель.
Сравните "CHALLENGER" с моделью CHAMPION. Вы можете выполнить это сравнение в автономном режиме или в сети. Автономное сравнение вычисляет обе модели по заданному набору данных и отслеживает результаты с помощью сервера отслеживания MLflow. Для обслуживания модели в режиме реального времени может потребоваться выполнить более длительные онлайн-сравнения, такие как тесты A/B или постепенное развертывание новой модели. Если версия модели "Challenger" показывает лучшие результаты в сравнении, она заменяет текущий псевдоним на "Чемпион".
Обслуживание моделей и профилирование данных позволяют автоматически собирать и отслеживать таблицы вывода, содержащие данные запроса и ответа для конечной точки.
Если нет существующей модели "Чемпион", можно сравнить модель "Challenger" с бизнес-эвристикой или другим порогом для использования в качестве базовой линии.
Описанный здесь процесс полностью автоматизирован. Если необходимы шаги утверждения вручную, вы можете настроить их с помощью уведомлений о рабочих процессах или обратного вызова CI/CD из конвейера развертывания модели.
Разверните модель. Конвейеры инференции для пакетной или потоковой передачи можно настроить для использования модели с псевдонимом "Чемпион". Для вариантов использования в режиме реального времени необходимо настроить инфраструктуру для развертывания модели в качестве конечной точки REST API. Эту конечную точку можно создавать и настраивать с помощью Model Serving. Если конечная точка уже используется для текущей модели, можно обновить конечную точку с помощью новой модели. Служба моделей выполняет обновление без простоя, сохраняя существующую конфигурацию до тех пор, пока новая не будет готова.
4. Обслуживание моделей
При настройке конечной точки обслуживания модели укажите имя модели в каталоге Unity и версию, которая будет обслуживаться. Если версия модели была обучена с помощью признаков из таблиц в каталоге Unity, модель сохраняет зависимости для признаков и функций. Сервис моделей автоматически использует этот граф зависимостей для поиска признаков из соответствующих онлайн-хранилищ во время вывода. Этот подход также можно использовать для применения функций для предварительной обработки данных или вычислений функций по запросу во время оценки модели.
Вы можете создать одну конечную точку с несколькими моделями и указать трафик конечной точки, разделенный между этими моделями, что позволяет проводить онлайн-сравнения "Чемпион" и "Challenger".
5. Инференс: пакетный или потоковый
Конвейер вывода считывает последние данные из рабочего каталога, выполняет функции для вычисления функций по запросу, загружает модель "Чемпион", оценивает данные и возвращает прогнозы. Пакетный или потоковый вывод, как правило, является наиболее экономичным вариантом для случаев использования с более высокой пропускной способностью и более высокой задержкой. В сценариях, где требуются прогнозы с низкой задержкой, но прогнозы могут быть вычислены в автономном режиме, эти пакетные прогнозы можно опубликовать в хранилище значений ключей в Интернете, например DynamoDB или Cosmos DB.
Зарегистрированная модель в каталоге Unity ссылается на ее псевдоним. Инференционный конвейер настроен для загрузки и применения версии модели "Чемпион". Если версия "Чемпион" обновляется до новой версии модели, конвейер вывода автоматически использует новую версию для следующего выполнения. Таким образом шаг развертывания модели отделяется от конвейеров вывода.
Пакетные задания обычно публикуют прогнозы в таблицы в производственном каталоге, в плоские файлы или через подключение JDBC. Задания потоковой передачи обычно публикуют прогнозы в таблицах каталога Unity или в очереди сообщений, такие как Apache Kafka.
6. Профилирование данных
Профилирование данных отслеживает статистические свойства, такие как смещение данных и производительность модели, входные данные и прогнозы моделей. Вы можете создавать оповещения на основе этих метрик или публиковать их на панелях мониторинга.
- Прием данных. Этот конвейер читает журналы из пакетного, потокового или интерактивного инференса.
- Проверка точности и смещения данных. Конвейер вычисляет метрики о входных данных, прогнозах модели и производительности инфраструктуры. Специалисты по обработке и анализу данных указывают метрики данных и моделей во время разработки, а инженеры ML определяют метрики инфраструктуры. Можно также определить пользовательские метрики.
- Публикация метрик и настройка оповещений. Конвейер записывает в таблицы в производственном каталоге для анализа и создания отчетов. Эти таблицы следует настроить для чтения из среды разработки, чтобы специалисты по обработке и анализу имели доступ. Вы можете использовать Databricks SQL для создания панелей мониторинга для отслеживания производительности модели, а также настроить задание мониторинга или средство панели мониторинга для отправки уведомления, когда метрика превышает указанный порог.
- Инициировать переобучение модели. Если метрики мониторинга указывают на проблемы с производительностью или изменения входных данных, специалист по обработке и анализу данных может потребоваться разработать новую версию модели. Вы можете настроить оповещения SQL, чтобы уведомить специалистов по обработке и анализу данных, когда это произойдет.
7. Переобучение
Эта архитектура поддерживает автоматическую переобучение с помощью приведенного выше конвейера обучения модели. Databricks рекомендует начинать с запланированного, периодического переобучения и перехода на активированное переобучение при необходимости.
- Запланировано. Если новые данные доступны регулярно, можно создать запланированное задание для запуска кода обучения модели на основе последних доступных данных. См. статью "Автоматизация заданий с расписаниями и триггерами"
- Запущено. Если конвейер мониторинга может выявлять проблемы с производительностью модели и отправлять оповещения, он также может активировать переобучение. Например, если распределение входящих данных значительно изменяется или если производительность модели снижается, автоматическое переобучение и повторное развертывание могут повысить производительность модели с минимальным вмешательством человека. Это можно сделать через оповещение SQL, чтобы проверить, является ли метрика аномальной (например, проверка смещения или качества модели по пороговому значению). Оповещение можно настроить для использования веб-перехватчика в качестве назначения, который впоследствии может активировать рабочий процесс обучения.
Если конвейер переобучения или другие конвейеры демонстрируют проблемы с производительностью, специалисту по обработке и анализу данных возможно потребуется вернуться в среду разработки для проведения дополнительных экспериментов, чтобы устранить проблемы.